
Конспект лекцій Суми Видавництво Сумду 2010
| Вид материала | Конспект |
- Конспект лекцій Суми Видавництво Сумду 2009, 1181.15kb.
- Конспект лекцій Суми Видавництво Сумду 2009, 635.24kb.
- Конспект лекцій Суми Вид-во Сумду 2008, 1319.71kb.
- Конспект лекцій для студентів спеціальності "Правознавство", 1754.63kb.
- Конспект лекцій для студентів спеціальності 050104 "Фінанси", 2580.36kb.
- Конспект лекцій для студентів спеціальності 050201 "Менеджмент організацій", 1390.59kb.
- Конспект лекцій для студентів спеціальності 050104 «Фінанси» заочної форми навчання, 799.86kb.
- Конспект лекцій для студентів спеціальності 030508 «Фінанси І кредит», 3231.05kb.
- Історія філософії. Антропологія, 3690.91kb.
- Конспект лекцій з дисципліни «соціальне страхування», 3599.32kb.
Серійна система служить для кодування аналогічних простих номенклатур і передбачає присвоєння серій номерам об'єктам, виділених в окремі групи за якою-небудь ознакою. У межах кожної серії об'єктам присвоюються номери по порядку. При цьому в кожну серію обов'язково включаються резервні коди, які можна присвоювати новим об'єктам даної номенклатури.
Переваги — найбільш економічна за кількістю розрядів; містить необхідний резерв вільних номерів для нових об'єктів.
Недоліки - важко встановити оптимальну кількість вільних номерів; важко запам'ятовувати.
Система повторення використовує літерні або цифрові позначення, які безпосередньо характеризують об'єкт, який кодується, (наприклад, вага, розмір об'єкта тощо) або асоціативно зв'язані з ним деякі дані, такі, як місце розміщення, адреса тощо.
Коди повторення в чистому вигляді використовують рідко, але вони можуть входити в комбіновані коди. Код повторення можна застосовувати, наприклад, для позначення дат (рік, місяць, число), розрядів робітників і робіт, синтетичних і аналітичних рахунків тощо.
Переваги - легко запам'ятовуються, оскільки вони виражають ознаки, що склались внаслідок їх природної і логічної обумовленості.
Недоліки - вузькість застосування.
Розрядна (позиційна) система - застосовується для кодування складних багатозначних номенклатур: кожній класифікаційній ознаці відводиться певна кількість розрядів (позицій), яка залежить від кількості об'єктів у відповідному класифікаційному угрупованні. Така система відповідає ієрархічній класифікації. Розрядна система забезпечує чіткість і логічність кодів, чітке виділення кожної класифікаційної ознаки, зручність для машинної обробки інформації, але разом з тим вимагає збільшення розрядності коду. Крім того, позиційні коди часто характеризуються великою складністю побудови і відсутністю необхідної гнучкості при їх структурному утворенні.
За розрядною системою можна побудувати коди матеріальних цінностей, коди причин і винуватців браку, простоювань устаткування.
Коди двозначних номенклатур (причин і винуватців браку, простоювань устаткування тощо) іноді називають матричними, або шаховими.
Комбінована система базується на різних поєднаннях принципів кодування за всіма розглянутими системами. Вона призначена для кодування великих багатозначних номенклатур, які характеризуються і підлеглістю, і незалежністю окремих класифікаційних ознак. Комбіновані коди при усій їх чіткості і логічності побудови мають найраціональнішу структуру, достатню гнучкість, її можна застосовувати як для ієрархічних, так і багатоаспектних номенклатур.
Незалежно від застосовуваної системи кодування коди номенклатур повинні бути передусім орієнтовані на машинну обробку інформації, мати по можливості мінімальну довжину, володіти достатньою надлишковістю і гнучкістю. Вони повинні служити не лише для економії пам'яті ЕОМ і пов'язаного з цим прискоренням обробки даних, але і для підвищення рівня автоматизації процесів обробки, до того ж повинні бути зручними для користувачів.
2.8.2 Методи кодування економічної інформації
При виборі методу кодування слід пам'ятати, що цей метод має забезпечувати:
- однозначне визначення об'єкта у межах заданої множини;
- необхідну інформацію про об'єкт;
- використання як алфавіту коду десяткової цифри, так і літер української абетки, що зручно для машинної обробки і обробки даних людиною;
- якомога меншу довжину коду, що спрощує заповнення документів, спрощує їх перевірку, зменшує кількість помилок, розміри машинної пам'яті і час обробки;
- достатній резерв незайнятих кодів, щоб можна було кодувати нові об'єкти й угруповання, не порушуючи структури класифікатора;
- можливість автоматичного контролю помилок, наприклад, внесенням до коду контрольного розряду.
При кодуванні сукупності властивостей об'єктів, тобто при створенні інформаційного блока застосовують два основних методи створення коду: послідовного кодування на основі використання ієрархічної класифікації і паралельного кодування на основі фасетної класифікації.
1 Послідовне кодування. Код угруповання створюється на основі коду угруповання попереднього рівня додаванням до нього ще одного розряду (або групи розрядів). В ієрархічній класифікації використовується послідовність угруповань під назвами «клас», «підклас», «група», «підгрупа» і для позначення класу можна використовувати одну цифру, для підкласу - дві і т.д. На кожному рівні розподілу може бути до десяти номенклатур. У кожній вітці ієрархічної класифікації використовується своя сукупність властивостей. Значення властивості, записаної на певному розряді коду у вигляді цифр (групи цифр), залежить від значення цифр на попередніх розрядах.
При використанні послідовного методу логічно будується код (кодова комбінація), який має велику інформативність. Він дуже громіздкий і має складну структуру. Через негнучкість послідовного методу кодування його доцільно використовувати лише в тих випадках, коли техніко-економічна інформація змінюється у незначних розмірах або зовсім не змінюється протягом тривалого часу використання класифікаторів. Метод широко застосовується при розробленні загальнодержавних класифікаторів продукції, галузей і т. ін.
2 Паралельне кодування. При використанні фасетної класифікації кожне угруповання системи класифікації відповідає деякій сукупності значень властивостей об'єктів. При цьому кожне угруповання першого рівня поділу відповідає одному значенню, другого - значенню двох властивостей і т.ін. Для позначення кожної окремої ознаки незалежно використовується один або кілька розрядів коду. Структура коду сукупності властивостей відповідає фасетній формулі.
При застосуванні паралельного методу кодування на противагу послідовному значенню ознаки записане на будь-якому розряді коду не залежить від значень ознак, записаних на інших розрядах. Це дає змогу за конкретним кодом легко дізнатися, набором яких ознак описується розглядуваний об'єкт. Найчастіше ознака задається у вигляді кодової таблиці.
Паралельний метод кодування дає багатоаспектну класифікацію. Вона добре пристосована для машинної обробки і розв'язання різних економічних задач. Блокова побудова коду за фасетами спрощує його стандартизацію. До недоліків цього методу кодування належить менша інформативність порівняно з послідовним методом.
2.8.3 Задачі кодування повідомлень
Кодуванням називається відображення стану однієї системи за допомогою стану деякої іншої. Найбільш простим випадком кодування є випадок, коли обидві системи Х та У мають кінцеву кількість можливих станів.
Нехай маємо деяку систему Х ( наприклад, літери російської абетки), яка може випадковим чином прийняти один з можливих станів х1, х2,…,хn. Необхідно закодувати (відобразити) її за допомогою іншої системи У, можливі стани якої у1,у2,…,уm. Якщо m
Одне й те саме повідомлення можна закодувати різними способами. Оптимальним (найвигіднішим) способом кодування є такий код, при якому на передачу повідомлень використовується мінімальний час. Якщо при передачі кожного елементарного символу використовується один і той самий час, то оптимальним буде такий код, при якому на передачу повідомлення заданої довжини буде використана мінімальна кількість елементарних символів.
Приклад
Необхідно закодувати двійковим кодом літери російської абетки так, щоб кожній літері відповідала певна комбінація елементарних символів «0» та «1» і щоб середня кількість цих символів на літеру тексту була мінімальною.
Розв’язання.
Розглянемо 32 літери російської абетки. Якщо не розрізняти літери «ъ» та «ь», а також додати проміжок між словами «-», то для кодування залишається 32 символи.
Перший метод. Не змінюючи порядки букв, занумерувати їх по порядку, надаючи їм номери від 0 до 31, а потім перевести нумерацію в двійкову систему числення. Так, число 25=1*24 + 1*23 +0*22 +0*21 +1*20 . У двійковій системі числення число 25 дорівнює 11001 ( (25)10=(11001)2). Таким чином будемо мати такий код; а ~ 00000; б ~ 00001; в ~ 00010; … я ~11110; «-» ~ 11111. У цьому коді витрачається на зображення кожної літери рівно 5 елементарних символів.
Другий метод. Побудуємо інший код, в якому на одну літеру буде в середньому припадати менша кількість елементарних символів. Для цього необхідно знати частоти літер у російському тексті. У таблиці 2.1 літери розміщені у спадчому порядку.
Таблиця 2.1 - Розміщення літер за частотами
| Літера | Частота | Літера | Частота | Літера | Частота | Літера | Частота |
| «-» | 0,145 | р | 0,041 | я | 0,019 | х | 0,009 |
| о | 0,095 | в | 0,039 | ы | 0,016 | ж | 0,008 |
| е | 0,074 | л | 0,036 | з | 0,015 | ю | 0,007 |
| а | 0,064 | к | 0,029 | ъ ь | 0,015 | ш | 0,006 |
| и | 0,064 | м | 0,026 | б | 0,015 | ц | 0,004 |
| т | 0,056 | д | 0,026 | г | 0,014 | щ | 0,003 |
| н | 0,056 | п | 0,024 | ч | 0,013 | э | 0,003 |
| с | 0,047 | у | 0,021 | й | 0,010 | ф | 0,002 |
Враховуючи табл.1, найбільш економічним буде код, в якому кожний елементарний символ буде передавати максимальну інформацію. У даному випадку інформація, яку дає цей символ, дорівнює ентропії системи і вона є максимальною, коли два стани рівноймовірні.
Такий спосіб побудови коду відомий під назвою « коду Шеннона-Фено». Він полягає у тому, що символи, які кодуються, поділяються на дві приблизно однакові рівноймовірні групи. Для першої групи символів на першому місці комбінації ставиться «0»; для другої групи – «1». Далі кожна група знову поділяється на дві приблизно рівноймовірні підгрупи. Для символів першої підгрупи на другому місці ставиться «0», а для другої підгрупи – «1» і т.д.
Побудова коду Шеннона-Фено на основі таблиці1 наведена в таблиці 2.2.
Таблиця 2.2 - Код Шеннона-Фено
| Літера | Двійкове число | Літера | Двійкове число | Літера | Двійкове число |
| «-» | 000 | к | 10111 | ч | 111100 |
| о | 001 | м | 11000 | й | 1111010 |
| е | 010 | д | 110010 | х | 1111011 |
| а | 0101 | п | 110011 | ж | 1111100 |
| и | 0110 | у | 110100 | ю | 1111101 |
| | | | | | |
| Продовження табл.2.2 | |||||
| т | 0111 | я | 110110 | ш | 11111100 |
| н | 1000 | ы | 110111 | ц | 11111101 |
| с | 1001 | з | 111000 | щ | 11111110 |
| р | 10100 | ъ ь | 111001 | э | 111111110 |
| в | 10101 | б | 111010 | ф | 111111111 |
| л | 10110 | г | 111011 | | |
Так, за допомогою коду таблиці 2.2 слово «теория» в двійковому коді має вигляд: 0111 010 001 10100 0110 110110.
Цей принцип кодування може бути застосований у тому випадку, коли помилки при кодуванні та при передачі повідомлень практично неможливі.
Третій метод. Враховуючи, що при об’єднанні залежних систем сумарна ентропія менша суми ентропій окремих систем, то інформація, яка передається відрізком пов’язаного тексту, завжди менша, ніж інформація, на один символ помножена на число символів. Враховуючи це, можна побудувати більш економічний код, якщо не кодувати окремо кожну літеру, а кодувати цілі блоки з літерів. Ці блоки необхідно розміщувати в порядку зменшення частот, і здійснювати кодування за допомогою коду Шеннона-Фено.
Знайдемо середню інформацію, яка припадає на один символ, та порівняємо її з максимально можливою інформацією, яка дорівнює двійковій одиниці. Для цього знайдемо середню інформацію, яка знаходиться в одній літері тексту, що передається (ентропію на одну літеру):
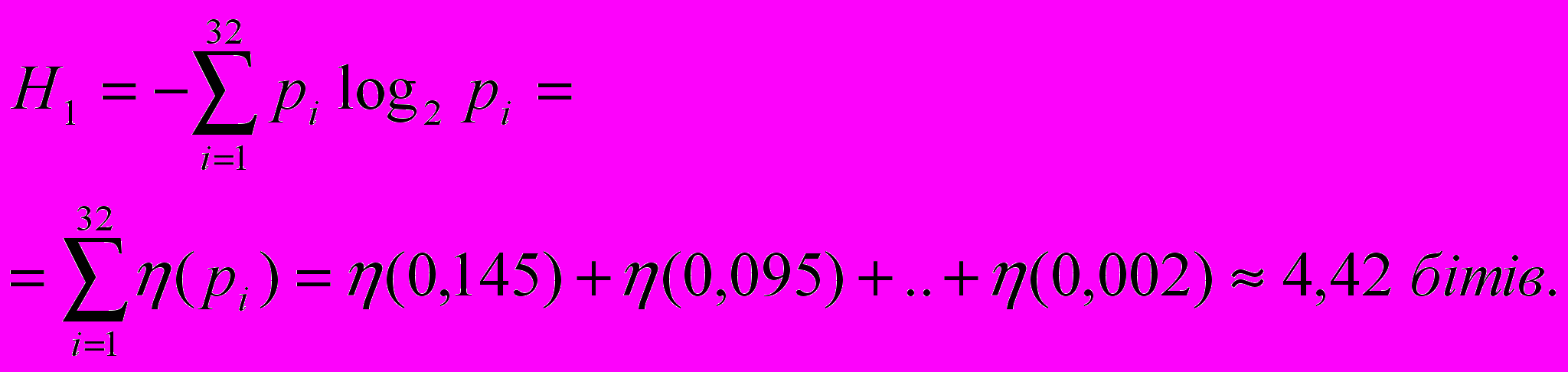
Враховуючи дані таблиць 2.1 та 2.2, знайдемо середню кількість елементарних символів на літеру:
nсер.=3*0,145+3*0,095+4*0,074+…+9*0,002=4,45.
Знайдемо інформацію на один символ:
перший метод:

другий метод
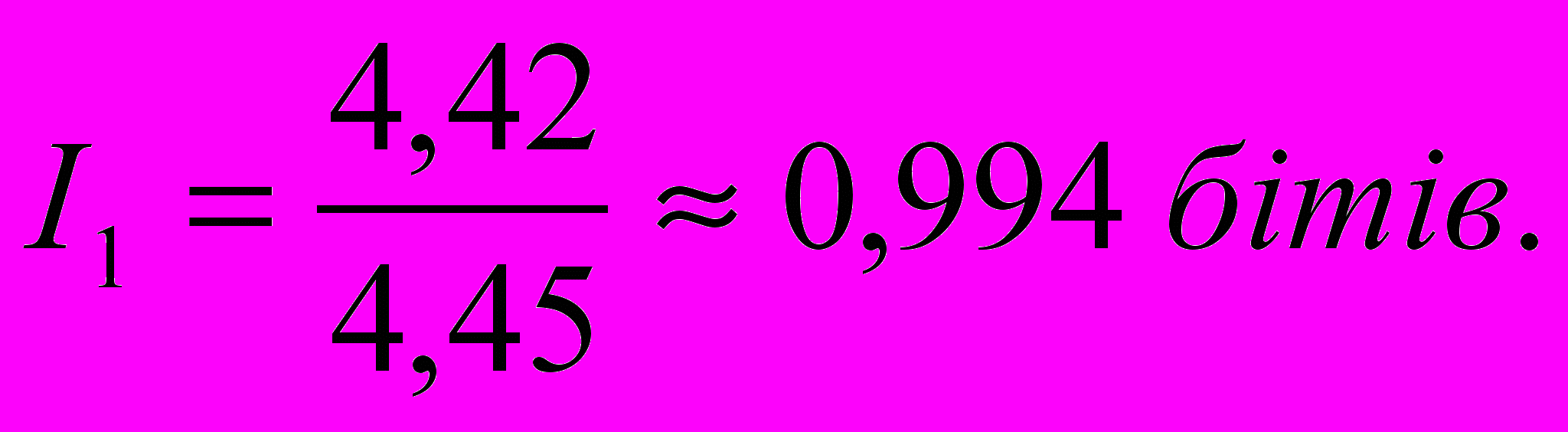
Таким чином, код, знайдений другим методом, є наближеним до оптимального.
2.8.4 Методи контролю правильності заповнення і переносу даних з первинних документів
Проектування процесів контролю правильності заповнення і переносу даних з первинних документів пов'язане із знанням методів забезпечення достовірності інформації в економічній інформаційній системі.
Більшість методів контролю базується на введенні і використанні надлишковості розрядів, реквізитів, записів. Можна застосовувати двократну і природну надлишковість.
Надлишкові розряди розраховуються згідно з визначеним алгоритмом перетворення значень контрольованого числа і записуються разом з контрольованим числом. Прикладом такого методу може служити контроль за модулем. Надлишкові реквізити є функцією від маніпулювання сукупністю контрольованих реквізитів. Переважно використовується операція підсумовування. Одержана контрольна сума записується у спеціально відведеній графі.
Надлишкові записи містять контрольну інформацію, що стосується блока записів або файлів загалом (наприклад, балансовий контроль).
Двократна надлишковість утворюється під час повторного переносу даних на машинний носій з подальшим порівнянням результатів, а природна - базується на розумно передбачуваних значеннях контрольованих реквізитів. До них належать контроль за модулем і контрольне підсумовування.
Контроль за модулем. Для розрахунку контрольного розряду широко використовують методи контролю за модулем 9,10,11,13. Їх суть у тому, що спочатку визначається сума S розрядів коду (сума добутків Пі, одержаних при множенні кожного розряду Рі на його вагу, або порядковий номер nі у коді, тобто Пі = Рі*nі), потім її ділять на вибраний модуль m і одержаний залишок d від ділення віднімають з того самого модуля. Одержана різниця R = m - d (або її молодший розряд) у вигляді контрольного розряду приписується до коду справа.
Приклад. Розрахувати контрольний розряд числа 24856 за модулем 9:
S= 2*5 + 4*4 + 8*3 + 5*2 + 6*1 = 66,
S/m = 66/9 = 7 (3), тобто (d=3),
R=m-d=9-3=6.
Отже, число з контрольним розрядом 248566. При вводі таких кодів в ЕОМ програмним шляхом виконуються необхідні контрольні обчислення.
Контрольне підсумовування можна організувати за рядком або графою документа.
Контрольна сума-це сума усіх цифрових реквізитів в контролюючій послідовності. Визначається вона до переносу даних на машинний носій вручну за допомогою калькуляторів. Прикладом може служити пошук контрольних сум для нижченаведеного документа:
| Цех | Табельний номер | Код деталі | Кількість | Контрольна сума |
| 01 | 1000 | 202 | 30 | 1233 |
| 01 | 1000 | 103 | 10 | 1114 |
| 01 | 1000 | 301 | 20 | 1322 |
Після переносу даних на машинні носії контрольну суму знову підраховують, але вже за допомогою програми. Незбіг контрольних сум, підрахованих вручну і автоматично, свідчить про помилковий рядок. Використовуючи контрольну суму за графою документа, аналогічно можна виявити місцезнаходження помилки.
Досить часто в бухгалтерських розрахунках застосовуються надлишкові записи, які характеризують документ в цілому. До таких методів належить балансовий контроль. Припустимо, необхідно видати користувачу відомість такого змісту:
| П.І.П/б | Табельний номер | Заробітна плата | Утримано | До видачі на руки |
| А | 100 | 300,00 | 102,00 | 198,00 |
| В | 101 | 105,00 | 12,50 | 92,50 |
| С | 102 | 175,50 | 19,25 | 157,25 |
| | | 581,50 | 133,75 | 447,75 |
Контроль полягає в обчисленні і порівнянні сум:
581,50-133,75 = 447,75.
До методів, що базуються на природній надлишковості, належать :
- метод перевірки границь (метод "вилки");
- метод довідника;
- метод перевірки структури коду;
- метод перевірки сум і добутків.
Метод перевірки границь можливий, якщо множина дозволених значень контрольованого реквізиту знаходиться в деяких границях заборонених значень, тобто
АminА ≤ Аmax .
Допустимо, значення реквізиту "код складу" знаходиться в діапазоні від 1 до 12. Тоді контроль організується за допомогою правила вигляду: 1 ≤код складу ≤ 12.
Метод ефективний, якщо значення контрольованого реквізиту розміщені рівномірно на числовій осі.
Метод довідника базується на спеціально створених таблицях, де розміщуються правильні коди реквізитів (наприклад, коди постачальників). Під час контролю відбувається звертання до таблиці-довідника з метою пошуку контрольованого коду. Якщо такий код знайдений, вважається, що помилка відсутня.
При методі перевірки структури коду використовують окремі його розряди. Наприклад, п'ятирозрядний табельний номер має таку структуру:
- 1-й розряд - номер цеху;
- 2-й – 5-й розряди - номер робітника в цеху.
Якщо на підприємстві три цехи, то можна використати перший розряд для контролю шляхом порівняння його з цифрами 1, 2 або 3.
Метод перевірки сум і добутків передбачає наявність у документі, який вводять, сум і чисел, які складають ці суми. Таке саме відбувається з добутками. Припустимо, в документі зазначена кількість поставлених матеріалів за кварталами. Кількість за рік повинна дорівнювати сумі поставок за квартали.
Існують також методи автоматичного виправлення помилок. Вони базуються на розв'язанні системи рівнянь, кількість яких дорівнює сумі рядків і стовпців документа. Інформаційні елементи складаються з двох частин: власне, код реквізиту і його контрольного розряду (розраховується за модулем).
На сьогодні існують програмні системи, які забезпечують введення і контроль даних. Здебільшого ці пакети контролюють формат реквізиту, наявність заборонених символів, значення надлишкових розрядів, діапазон значень, номенклатуру значень за довідником, підсумкові суми.
Всі розглянуті вище методи контролю достовірності інформації реалізуються винятково програмним шляхом. Ті ж методи, які не вимагають цього, виконуються вручну на основі інструкцій. Наприклад, контроль правильності заповнення первинних документів.