
Конспект лекцій Суми Видавництво Сумду 2010
| Вид материала | Конспект |
Содержание2.7.3 Адекватність економічної інформації Синтаксична адекватність Семантична адекватність Прагматична адекватність 2.8 Кодування економічної інформації |
- Конспект лекцій Суми Видавництво Сумду 2009, 1181.15kb.
- Конспект лекцій Суми Видавництво Сумду 2009, 635.24kb.
- Конспект лекцій Суми Вид-во Сумду 2008, 1319.71kb.
- Конспект лекцій для студентів спеціальності "Правознавство", 1754.63kb.
- Конспект лекцій для студентів спеціальності 050104 "Фінанси", 2580.36kb.
- Конспект лекцій для студентів спеціальності 050201 "Менеджмент організацій", 1390.59kb.
- Конспект лекцій для студентів спеціальності 050104 «Фінанси» заочної форми навчання, 799.86kb.
- Конспект лекцій для студентів спеціальності 030508 «Фінанси І кредит», 3231.05kb.
- Історія філософії. Антропологія, 3690.91kb.
- Конспект лекцій з дисципліни «соціальне страхування», 3599.32kb.
Теорема. Якщо дві системи Х та У об’єднуються в одну, то ентропія об’єднаної системи дорівнює ентропії однієї з іі складових частин та додатку умовної ентропії другої частини відносно першої:
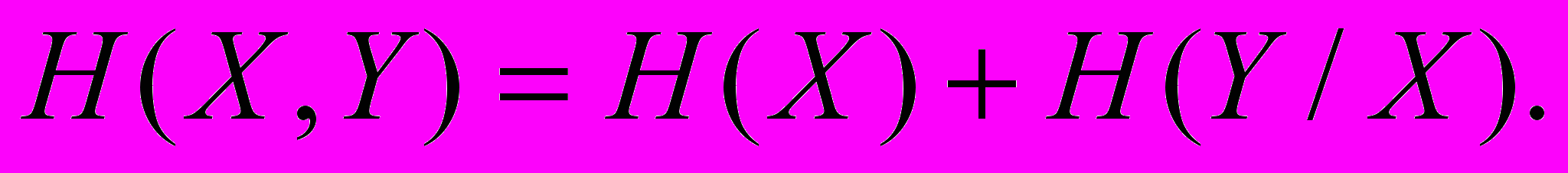
2.7.2 Ентропія та інформація
Кількість інформації будемо виміряти зменшенням ентропії тієї системи, для уточнення стану якої ці відомості призначені. Кількість інформації, здобутої при повному з’ясуванні стану деякої системи, дорівнює ентропії цієї системи. Тобто
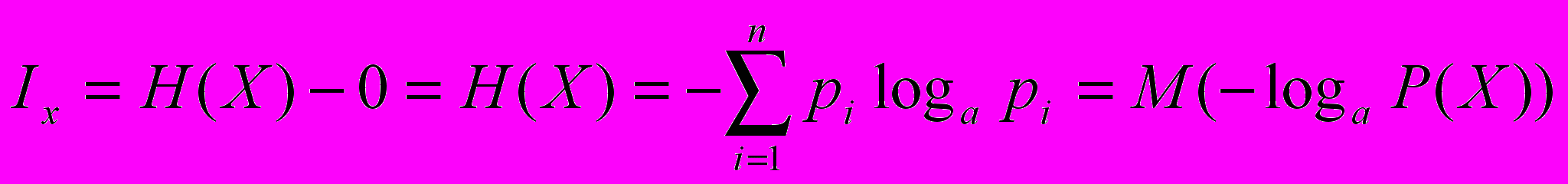 .
.Часткова інформація, отримана від окремого повідомлення, за умови, що система Х знаходиться в стані
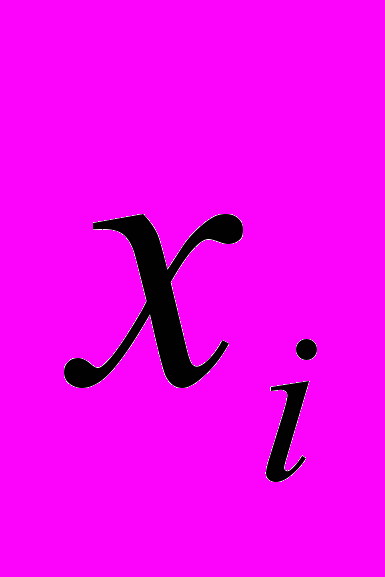 ,знаходиться за формулою
,знаходиться за формулою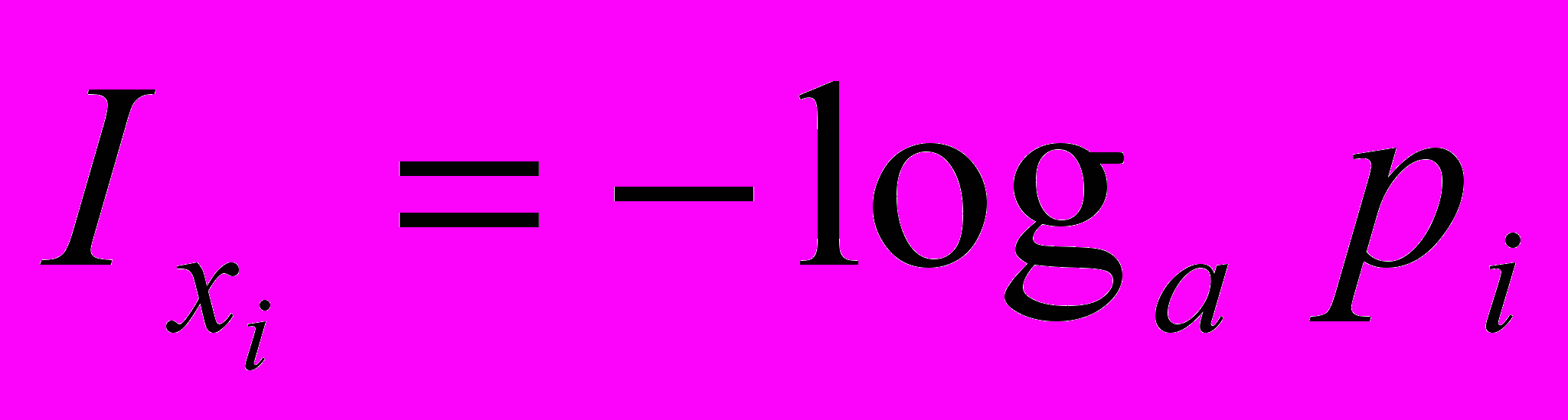 .
.Якщо всі можливі стани системи однаково рівноймовірні
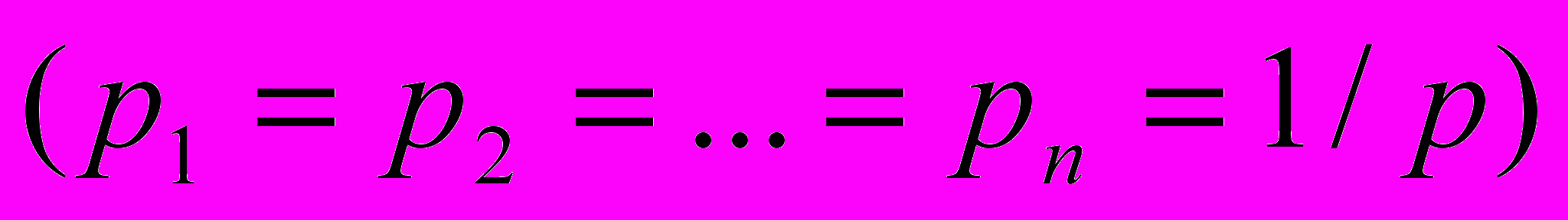 , то
, то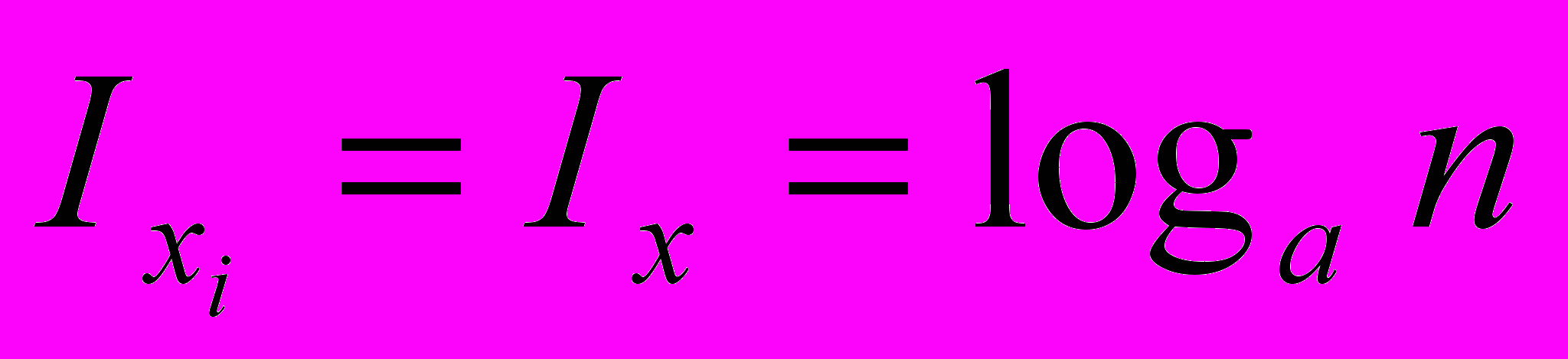 .
.Розглянемо систему з двома станами:
| xi | x1 | x2 |
| pi | p1 | p2 |
Для вимірювання інформації в двійкових одиницях можна умовно характеризувати її кількістю відповідей типу «так» або «ні», за допомогою яких можна здобувати таку саму інформацію. Максимальна інформація досягається за умови p1=p2=1/2 і Ix=1. Якщо інформація від будь-якого повідомлення дорівнює n двійковим одиницям, то вона рівносильна інформації, яка надається n відповідями «так» або «ні» на питання, поставлені таким чином, що «так» або «ні» однакової ймовірності.
Приклад. Дехто задумав ціле число від 1 до 8. Яку мінімальну кількість запитань типу «так» або «ні» треба поставити, щоб його вгадати?
Розв’язання. Знайдемо інформацію, яка знаходиться у повідомленні, яке число задумане. Всі значення Х від 1 до 8 рівноймовірні (р1=р2=…=р8=1/8), тому
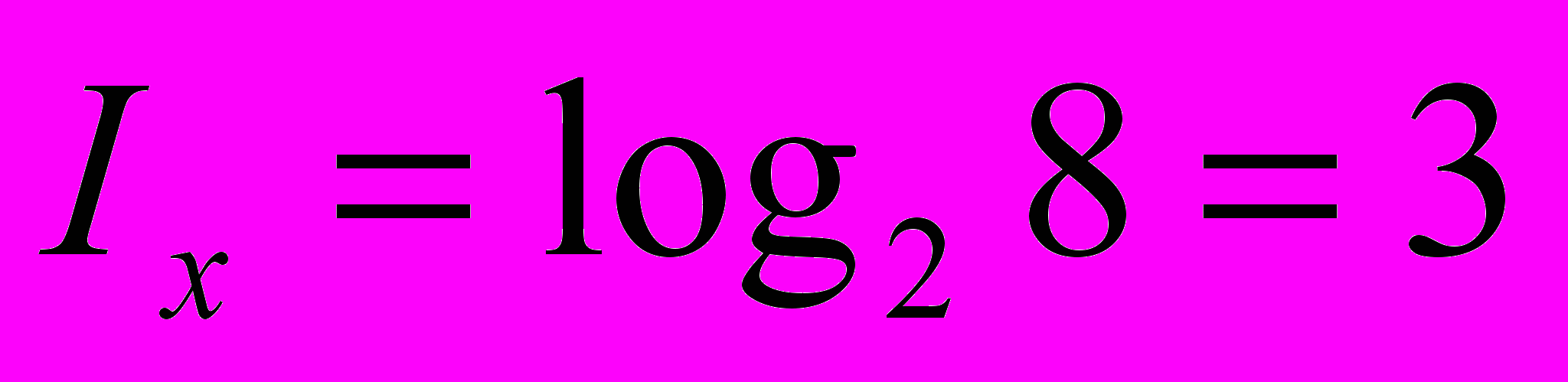 . Мінімальну кількість питань, які треба поставити для знаходження задуманого числа, не більше ніж 3.
. Мінімальну кількість питань, які треба поставити для знаходження задуманого числа, не більше ніж 3.На практиці виникає потреба в спостереженні не над самою системою Х (вона є недосяжною для спостереження), а над іншою системою У, яка пов’язана з нею. Відмінність між системами Х та У може бути двох видів:
1 Відмінність за рахунок того, що деякі стани системи Х не знаходять відображення в системі У.
2 Відмінність за рахунок помилок, які виникають при вимірюванні параметрів системи Х та при передачі повідомлень.
Кількість інформації про систему Х, яке дає спостереження над системою У, обчислимо за формулою
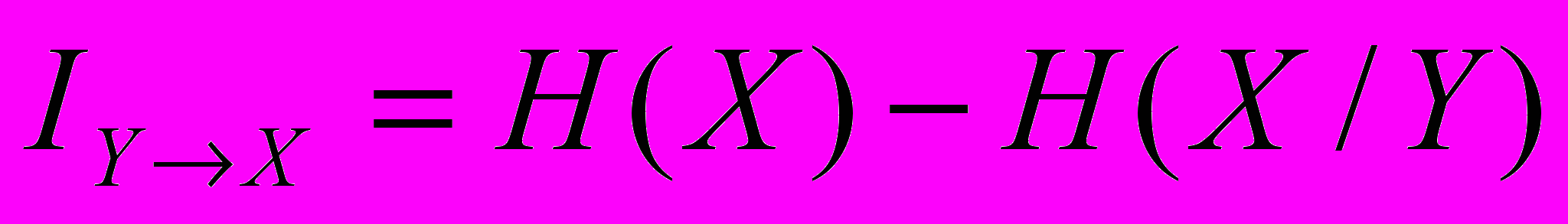 .
.Це є повна ( або середня) інформація про систему Х, яка знаходиться в системі У. Інформацію
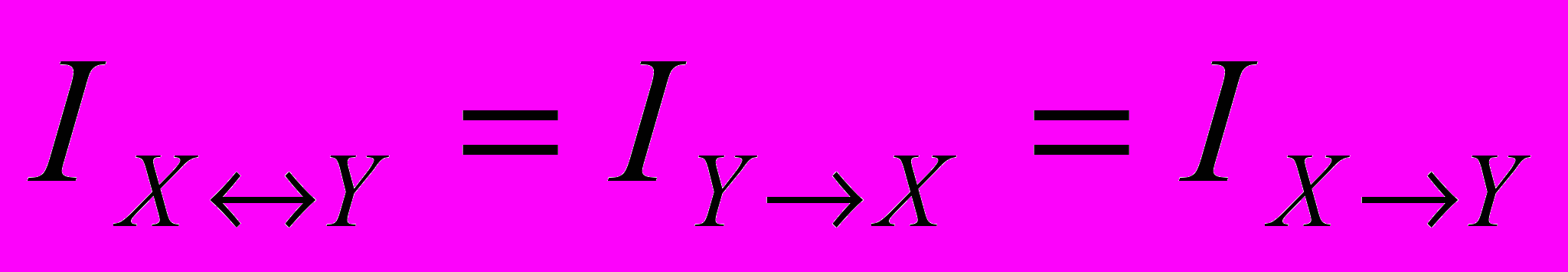 будемо називати повною взаємною інформацією, яка знаходиться у системах Х та У. Якщо Х та У незалежні, то
будемо називати повною взаємною інформацією, яка знаходиться у системах Х та У. Якщо Х та У незалежні, то 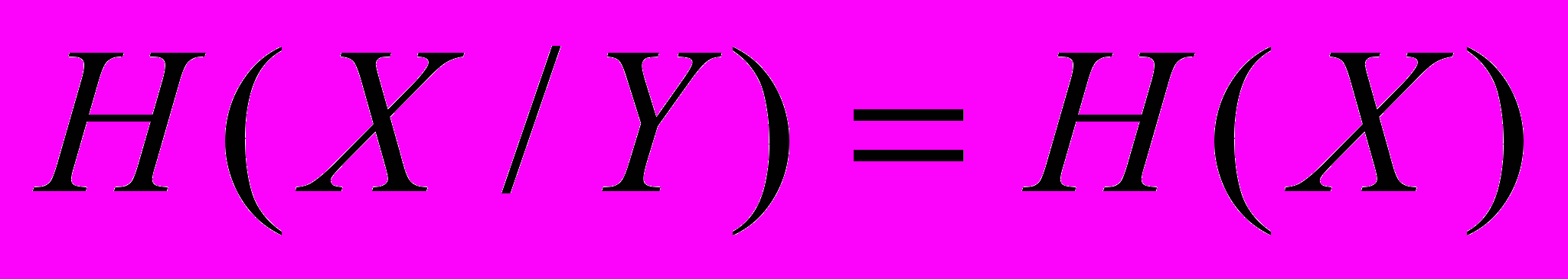 і
і 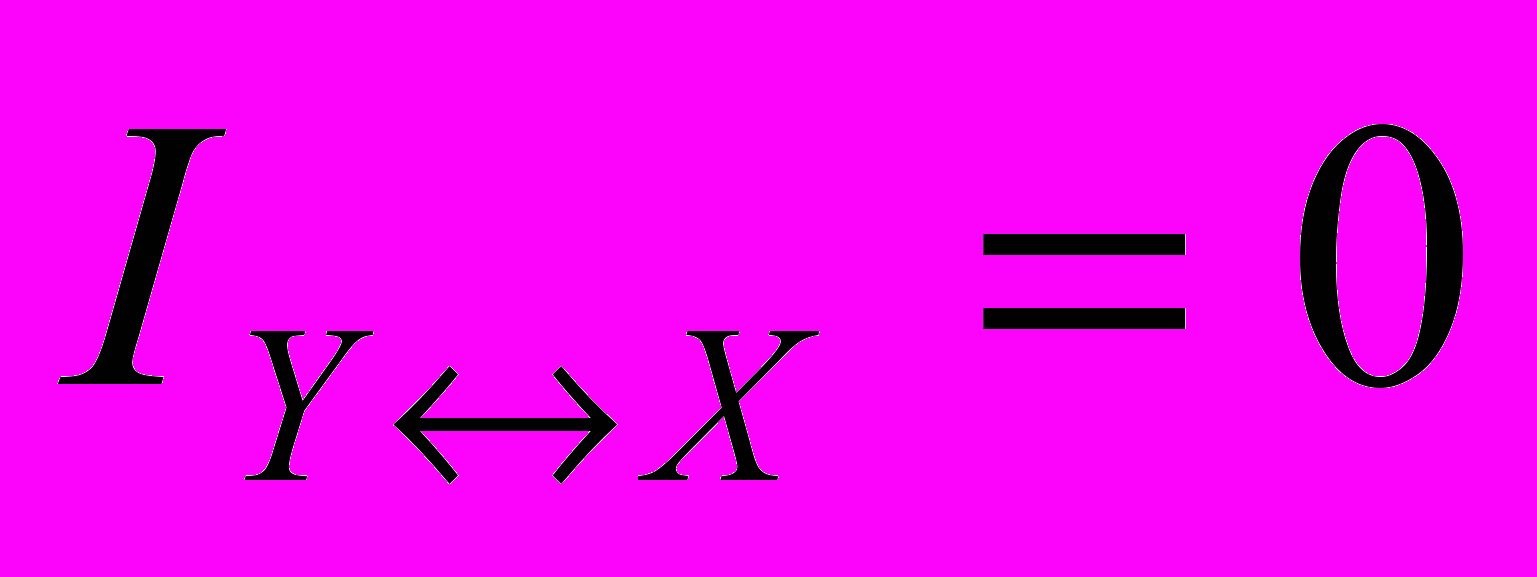 . У випадку коли стан системи Х повністю відповідає стану системи У і навпаки, то
. У випадку коли стан системи Х повністю відповідає стану системи У і навпаки, то 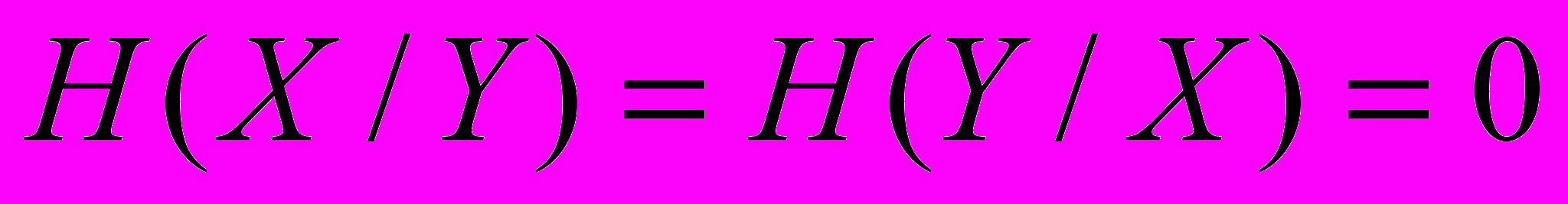 і
і 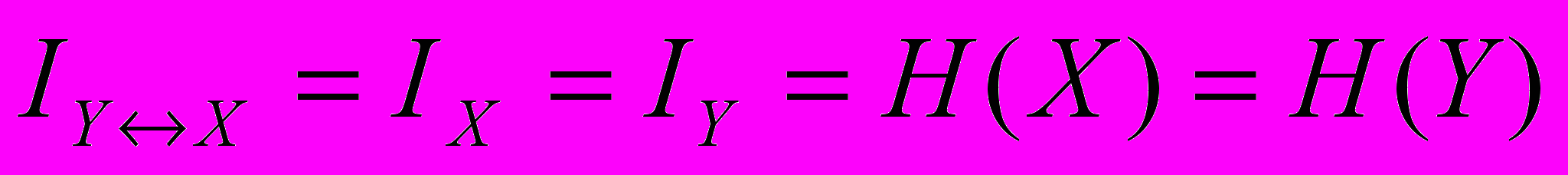 .
.Знайдемо повну взаємну інформацію через ентропії об’єднаної системи та її складових:
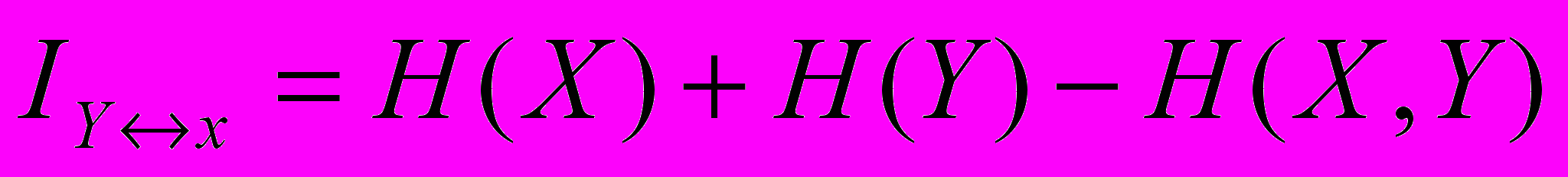 .
.Після певних перетворень, враховуючи вищеназване, маємо
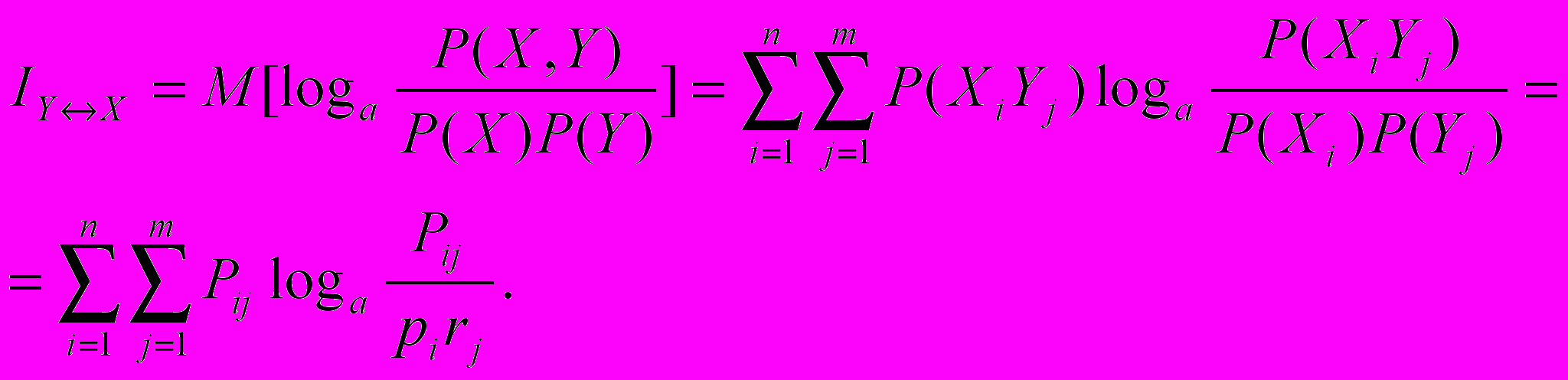 (1)
(1)Приклад 1. Маємо дві системи Х та У об’єднані в одну (Х,У). Ймовірність стану об’єднаної системи задано таблицею:
-
x1
x2
x3
y1
0,1
0,2
0
y2
0
0,3
0
y3
0
0,2
0,2
Знайти повні умовні ентропії
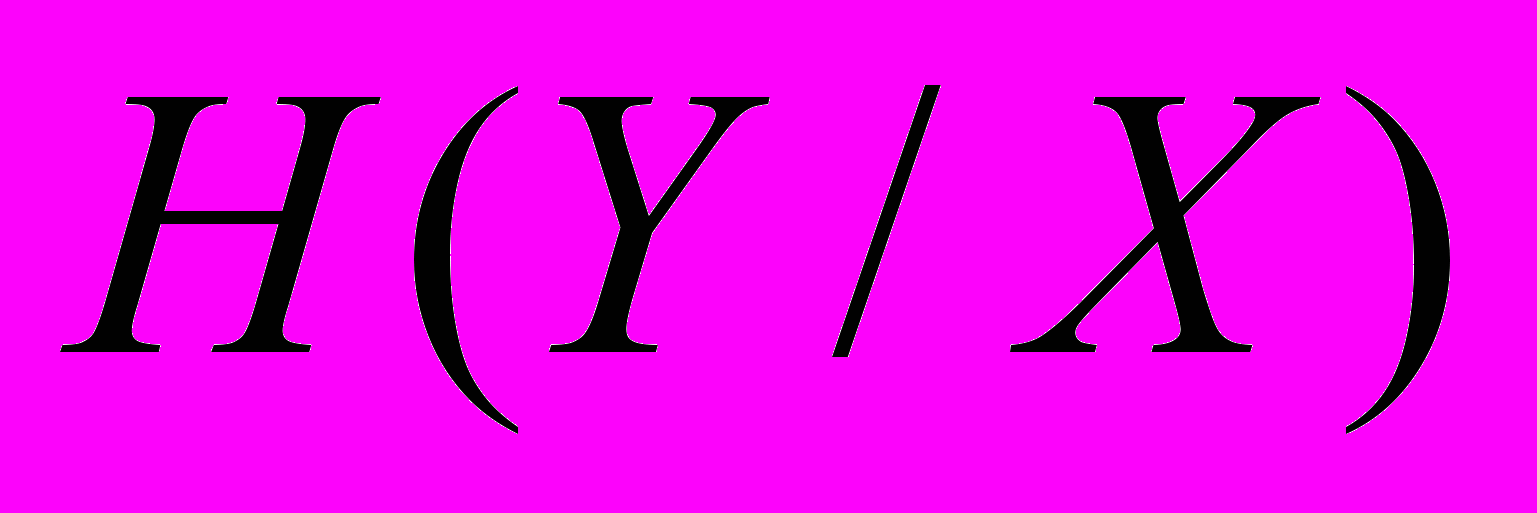 і
і 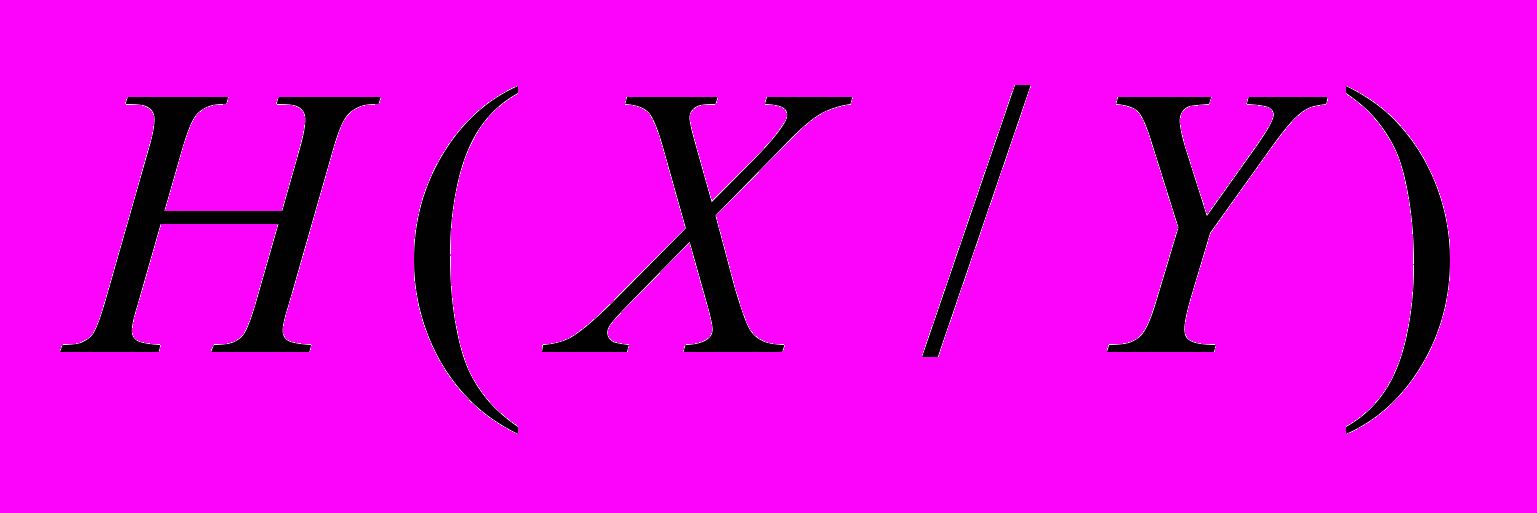 та повну взаємну інформацію
та повну взаємну інформацію 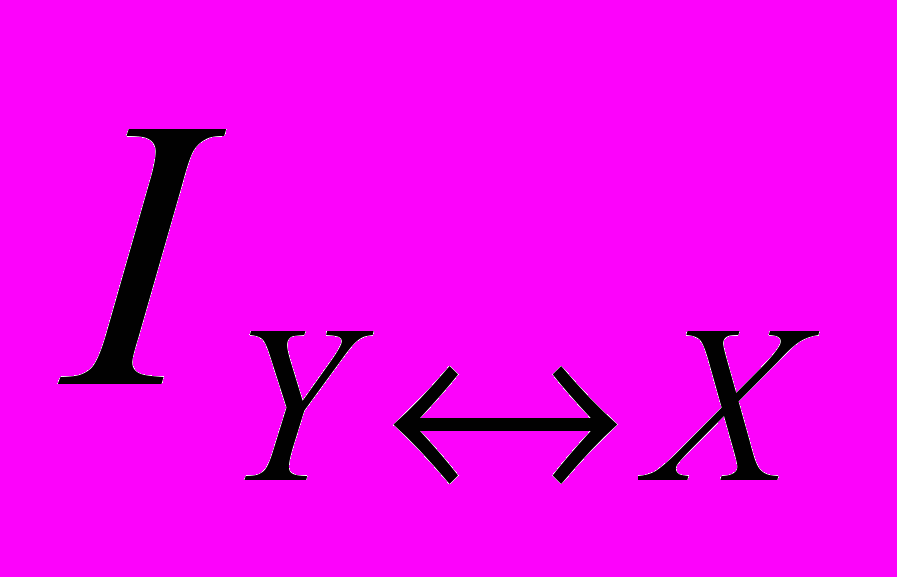 .
.Розв’язання.
Знайдемо ймовірності подій хi та уj: р1=0,1; р2=0,7; р3=0,2; r1=0,3; r2=0,3; r3=0,4
та отримаємо таблиці умовних ймовірностей Р(yj/xi) :
-
x1
x2
x3
y1
1
0,2/0,7
0
y2
0
0,3/0,7
0
y3
0
0,2/0,7
1
та Р(xi/yj)
-
x1
x2
x3
y1
0,1/0,3
0,2/0,3
0
y2
0
1
0
y3
0
0,2/0,4
0,2/0,4
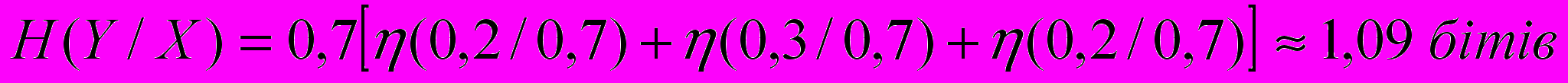 ;
;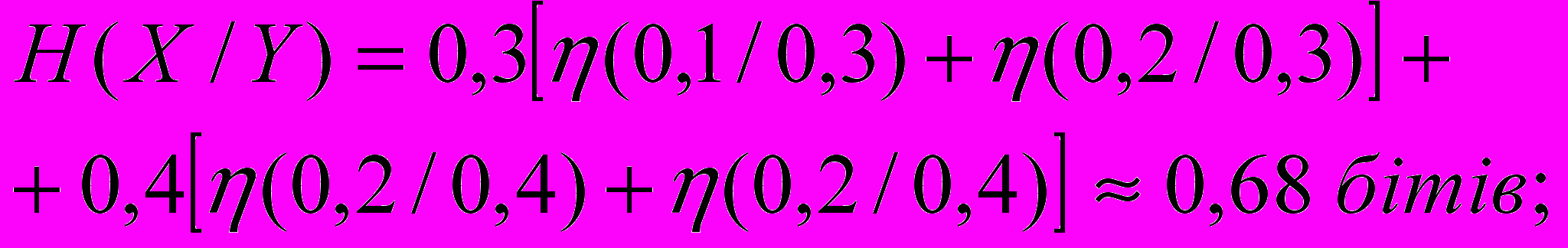 ,
,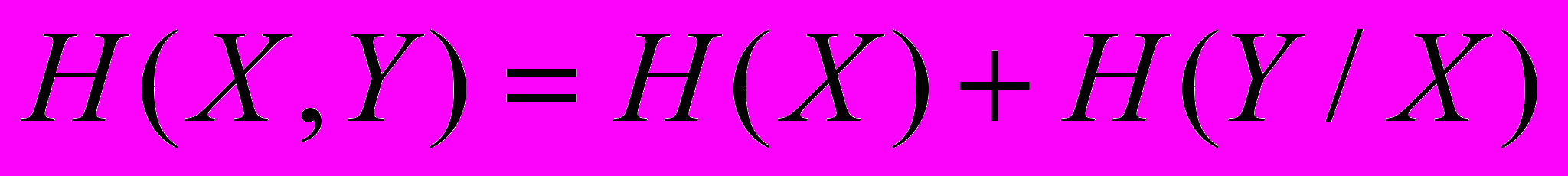 ,
,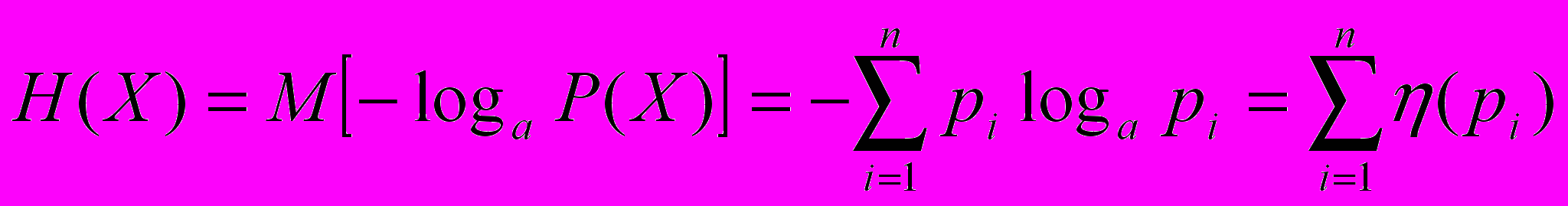 ,
,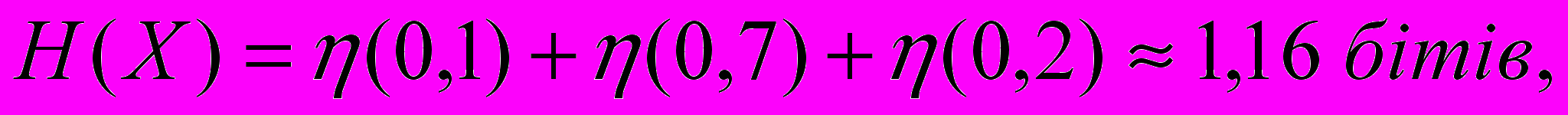
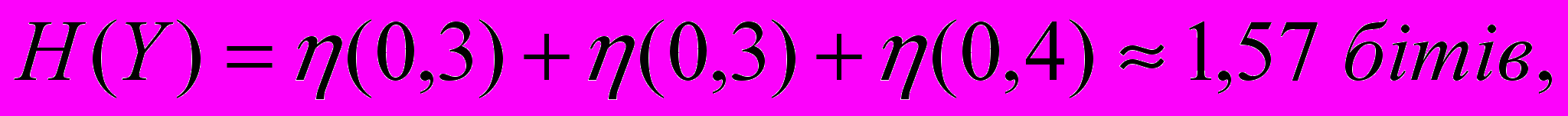
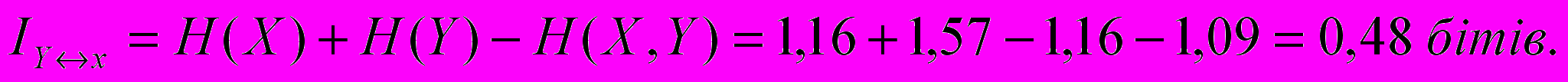
Приклад 2. Ймовірність отримання кредиту в банку дорівнює 20%. Припустимо, що завчасно робиться прогноз з отримання кредиту. Прогноз отримання кредиту буває помилковим приблизно в половині всіх випадків, а прогноз неотримання кредиту є помилковим в одному випадку з десяти. Яка кількість інформації в бітах знаходиться в повідомленні про отримання кредиту ?
Розв’язання. Запишемо такі події: А1-отримання кредиту; А2- неотримання кредиту; В1- прогноз видачі кредиту; В2 - прогноз невидачі кредиту:
Р(А1)=0,2 Р(А2)=0,8 Р(А1/В1)=0,5 Р(А1/В2)=1/10.
Будемо використовувати формулу повної ймовірності:
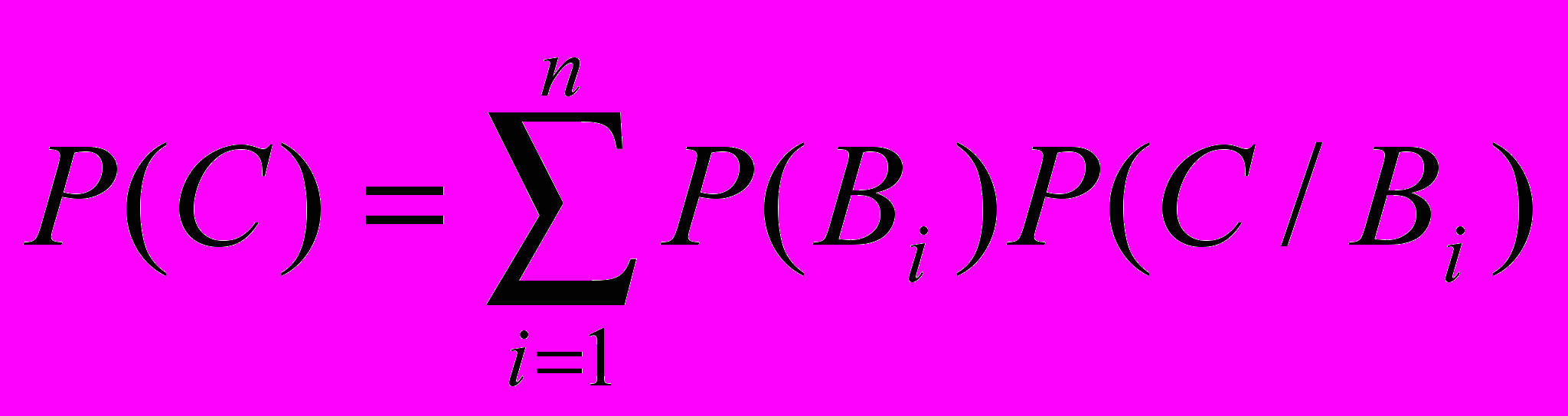 .
. Маємо:
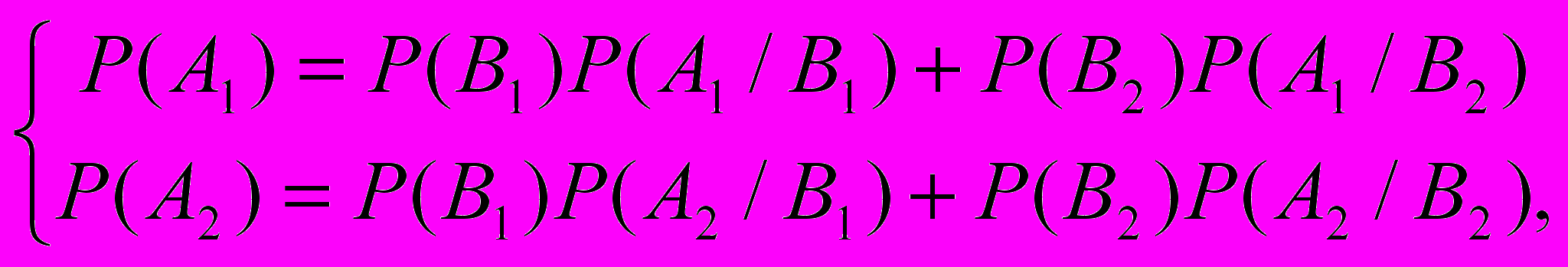
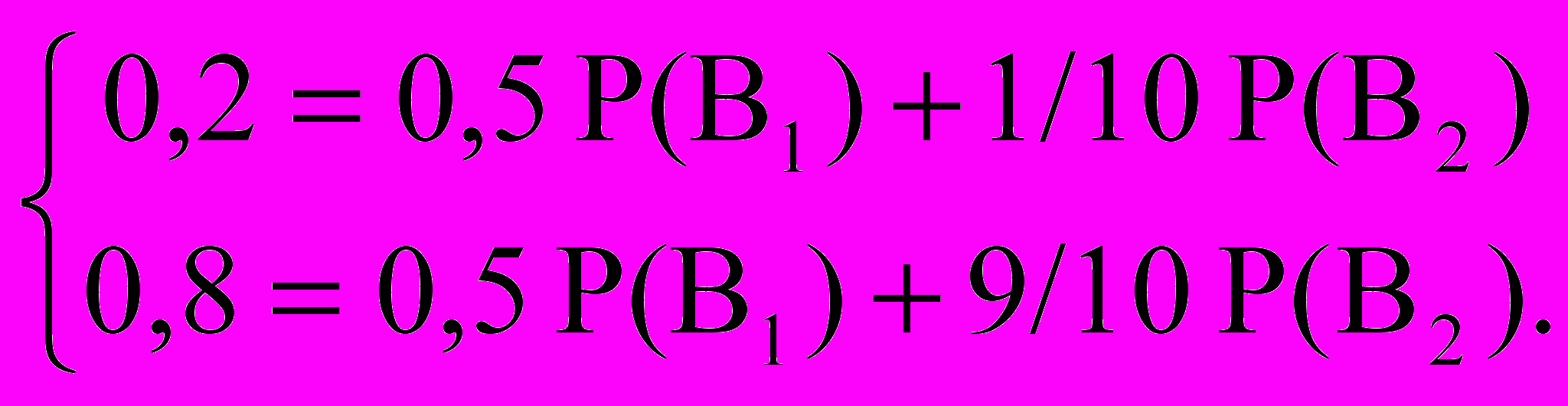
Знаходимо рішення системи Р(В1)=1/4 Р(В2)=3/4.
Для знаходження кількості інформації застосовуємо формулу (1)
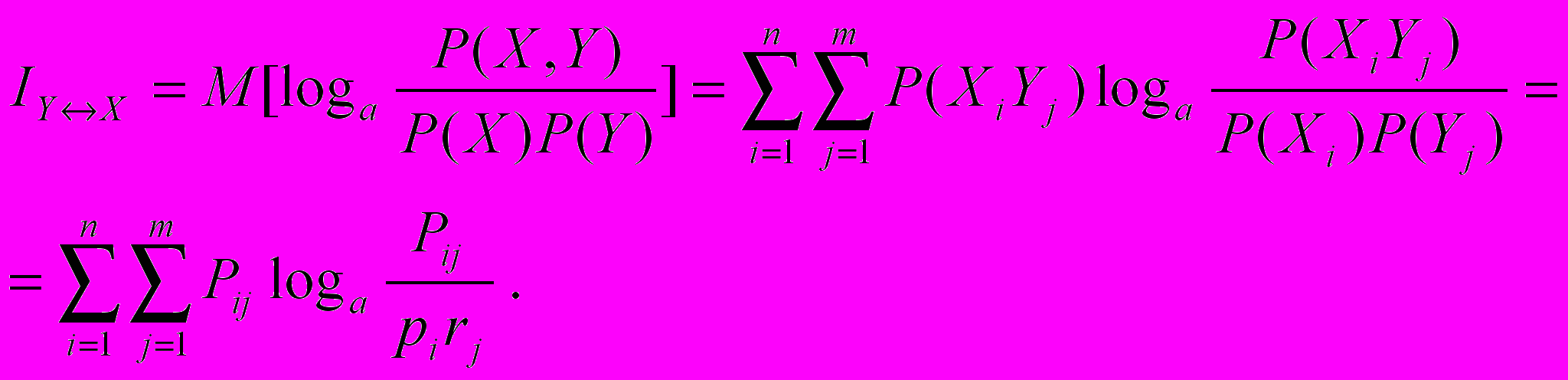
Враховуючи, що Р(АВ)=Р(В)Р(А/В), маємо:
Р(А1 В 1)=Р(В1 )Р(А 1/В1 )=1/8 ; Р(А1 В2)=3/40;
Р(А2 В1)=1/8; Р(А2 В2)=27/40;
IY↔X =0,12 бітів.
Іноді необхідно оцінити часткову інформацію про систему Х, яка знаходиться в окремому повідомленні, коли система У знаходиться в конкретному стані уj. Позначимо цю часткову інформацію
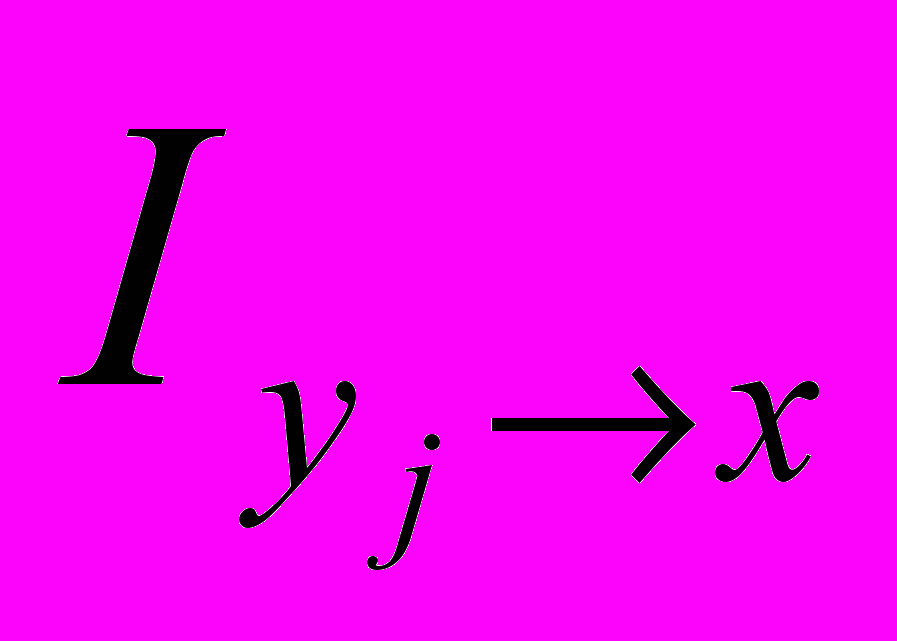 . Враховуючи, що
. Враховуючи, що 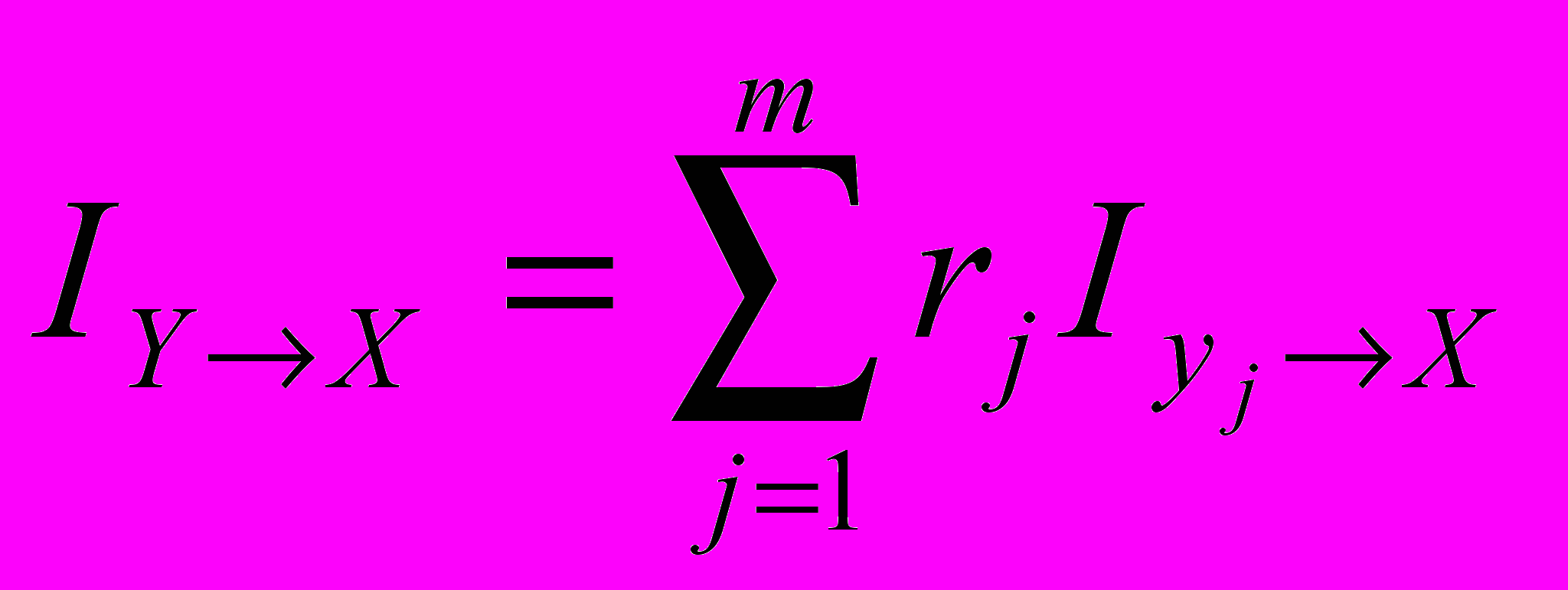 , а також (1)
, а також (1)маємо
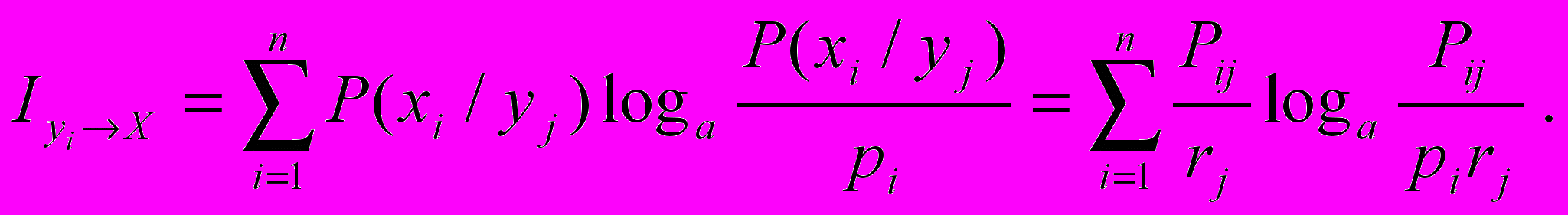
Для знаходження часткової інформації про подію хi, яка знаходиться в події уj, необхідно застосовувати формулу

Таким чином, часткова інформація про подію, яка отримується при повідомленні про іншу подію, дорівнює логарифму відношення ймовірності першої події після повідомлення до його ймовірності до повідомлення. Ця інформація може бути як додатною так і від’ємною.
Приклад. В урні маємо 3 білих та 4 чорних кулі. Витягли 4 кулі: 3 чорні та 1 білу. Знайти кількість інформації в бітах, яка знаходиться в спостережної події В відносно події А, наступна куля, яку будемо витягати, буде чорною.
Розв’язання
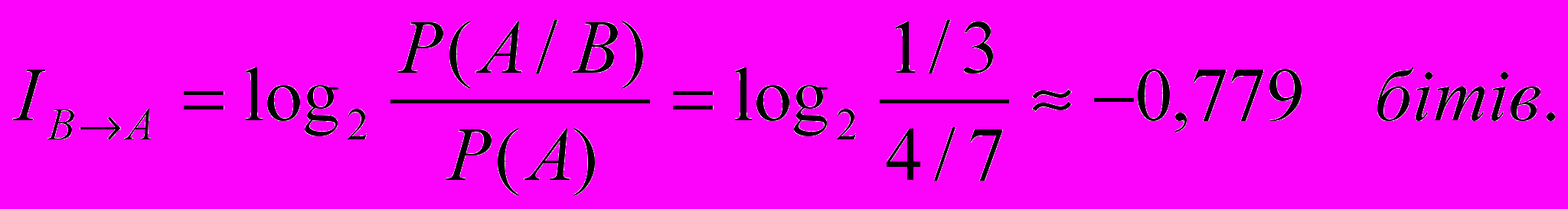
2.7.3 Адекватність економічної інформації
При створенні інформаційних систем обробки даних оцінюють економічну інформацію на об'єкті управління. Це необхідно для визначення ресурсів ІС, розрахунку потреби в управлінських кадрах, добору корисних відомостей для управлінських рішень і т. ін.
У світі ідей науки про знакові системи - семіотики, адекватність інформації, тобто відповідність змісту образу відображуваному об'єкту може виявитися у трьох формах: синтаксичній, семантичній, прагматичній.
Синтаксична адекватність пов'язана зі сприйняттям формально-структурних характеристик відображення абстраговано від змістових та споживчих (корисних) параметрів об'єктів. На синтаксичному рівні враховується тип носія і спосіб подання інформації, швидкість її передачі та обробки, розміри кодів, надійність і точність перетворення цих кодів і т. ін.
Розмір даних у повідомленнях вимірюється кількістю символів (розрядів), узятих для цього повідомлення алфавіту. Дуже часто інформація подається числовим кодом у тій чи іншій системі числення. Одна й та сама кількість рядків у різних системах числення може передавати різну кількість (число) станів відображуваного об'єкта. Справді, якщо N=mn , де m – основа системи числення; n- кількість розрядів (символів) в повідомленні, то N-кількість різноманітних відображуваних станів. Тому в різних системах числення один розряд має різну вагомість і відповідно змінюється одиниця вимірювання даних. Наприклад: повідомлення 10111011 у двійковій системі має розмір даних Vg=8 бітів, а повідомлення 275109 у десятковій системі має розмір Vg=6 дитів. У сучасних ЕОМ найпоширенішою одиницею вимірювання інформації є «байт», який дорівнює 8 бітам.
Розглянемо як приклад власну інформацію. Під власною інформацією будемо розуміти інформацію, яка знаходиться в даному конкретному повідомленні, яке дає одержувачу інформацію про можливість існування конкретного стану системи. Тоді кількість власної інформації, яка знаходиться в повідомленні Хi, знаходиться таким чином:
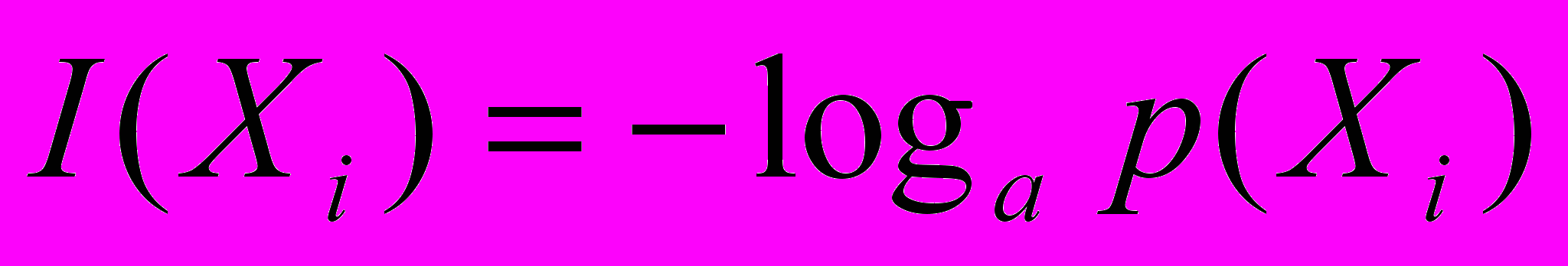 .
.Власна інформація має наступні властивості:
- Вона невід’ємна.
- Чим менша ймовірність появи повідомлення, тим більше інформації воно містить.
- Якщо повідомлення має ймовірність, яка дорівнює одиниці, то інформація, що в ньому міститься, дорівнює нулю.
- Вона має властивість адитивності. Кількість власної інформації декількох незалежних повідомлень дорівнює їх додатку:
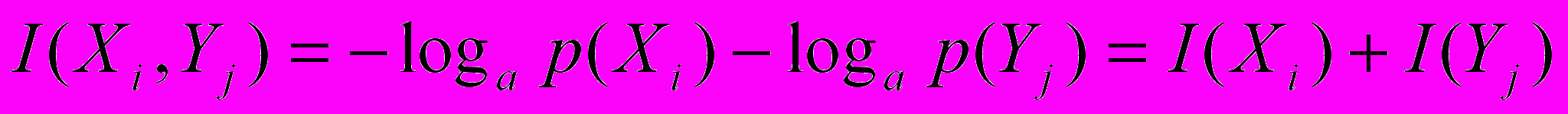 .
.Визначити кількість інформації на синтаксичному рівні неможливо без розгляду поняття невизначеності стану системи (ентропія системи). Здобування інформації про будь-яку систему завжди пов'язане зі зміною ступеня інформованості користувача про стан цієї системи.
Ступінь інформованості повідомлення визначається відношенням кількості інформації до розміру даних і характеризує лаконічність повідомлення:
 .
. Зі збільшенням V зменшуються обсяги робіт з переробки інформації (даних) у системі.
Семантична адекватність виражає відповідність образу, знаку та об'єкту, тобто відношення інформації та джерела її виникнення. Виявляється семантична інформація за наявності єдності інформації (об'єкта) і користувача. Семантичний аспект передбачає врахування змісту інформації: на цьому рівні аналізуються ті відомості, які відображає інформація, розглядаються змістові зв’язки між кодами подання інформації. Семантичні міри кількості інформації загалом не можуть бути безпосередньо використані для вимірювання значеннєвого змісту, оскільки стосуються знеособленої інформації, яка не відображає змістового ставлення до об'єкта.
Для вимірювання значеннєвого змісту інформації (ії кількості на семантичному рівні) найбільшого визнання здобула тезаурусна міра. Ідея цього методу була сформульована ще засновником кібернетики Н.Вінером і полягає в тому, що для розуміння та використання інформації її одержувач повинен володіти відповідним запасом знань.
Ю.І.Шнейдер пов'язує семантичні властивості інформації передусім зі здатністю користувача приймати відомості, що надходять, і використовує поняття «тезаурус користувача». Тезаурус можна тлумачити як сукупність відомостей, що їх мають система, користувач.
Якщо індивідуальний тезаурус користувач Sк відображає його знання про даний предмет, то кількість інформації Іс , яке знаходиться в повідомленні, можна оцінити за допомогою ступеня зміни цього тезауруса під впливом даного повідомлення. Кількість інформації Іс нелінійно залежить від стану індивідуального тезауруса користувача, хоча зміст повідомлення S є сталою величиною.
Залежно від співвідношення між значеннєвим змістом інформації S і тезаурусом користувача Sк змінюється кількість семантичної інформації Іс, яку сприймає користувач і яку він вносить далі до свого тезауруса. При Sк=0 користувач не сприймає, не розуміє інформації, що надходить; при Sк→ ∞ користувач усе знає, і тому інформація йому не потрібна. В обох випадках Іс=0.
Максимального значення Іс набуває при погодженні S з тезаурусом Sк,, коли інформація, що надходить, зрозуміла користувачеві і надає йому невідомі раніше (відсутні у його тезаурусі) відомості (рисунок 2.1).
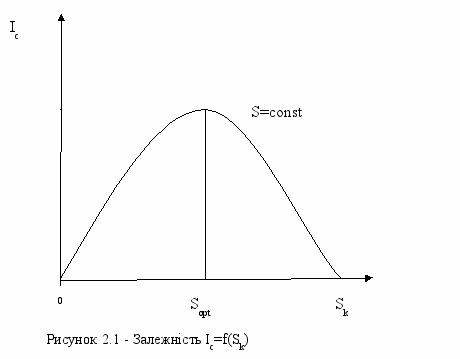
Отже, кількість семантичної інформації у відомостях, кількість нових знань, що їх дістає користувач, є величиною відносною: одне й те саме повідомлення може мати значеннєвий зміст для компетентного і бути беззмістовним (семантичний шум) для некомпетентноro користувача.
При розробленні інформаційного забезпечення комп'ютерних систем потрібно погодити величини S і Sк так, щоб інформація, яка циркулює в системі, була зрозумілою, доступною для сприйняття і, крім того, найбільш змістовною S, тобто
S = Ic /Vg.
Зі збільшенням змістовності інформації зростає семантична пропускна здатність ІС, оскільки щоб одержати одні й ті самі відомості, необхідно обробити менший обсяг даних.
Прагматична адекватність відображає відповідність інформації цілям управління, які реалізуються на її основі. Прагматичні властивості інформації виявляються лише за наявності єдності інформації (об'єкта), користувача і мети управління. А.А.Харкевич пропонує брати за міру цінності інформації кількість інформації, яка необхідна для досягнення поставленої мети. Цей підхід базується на статистичній теорії Шеннона і розглядає кількість інформації як приріст ймовірності досягнення мети. Кількість прагматичної інформації можна знайти за формулою
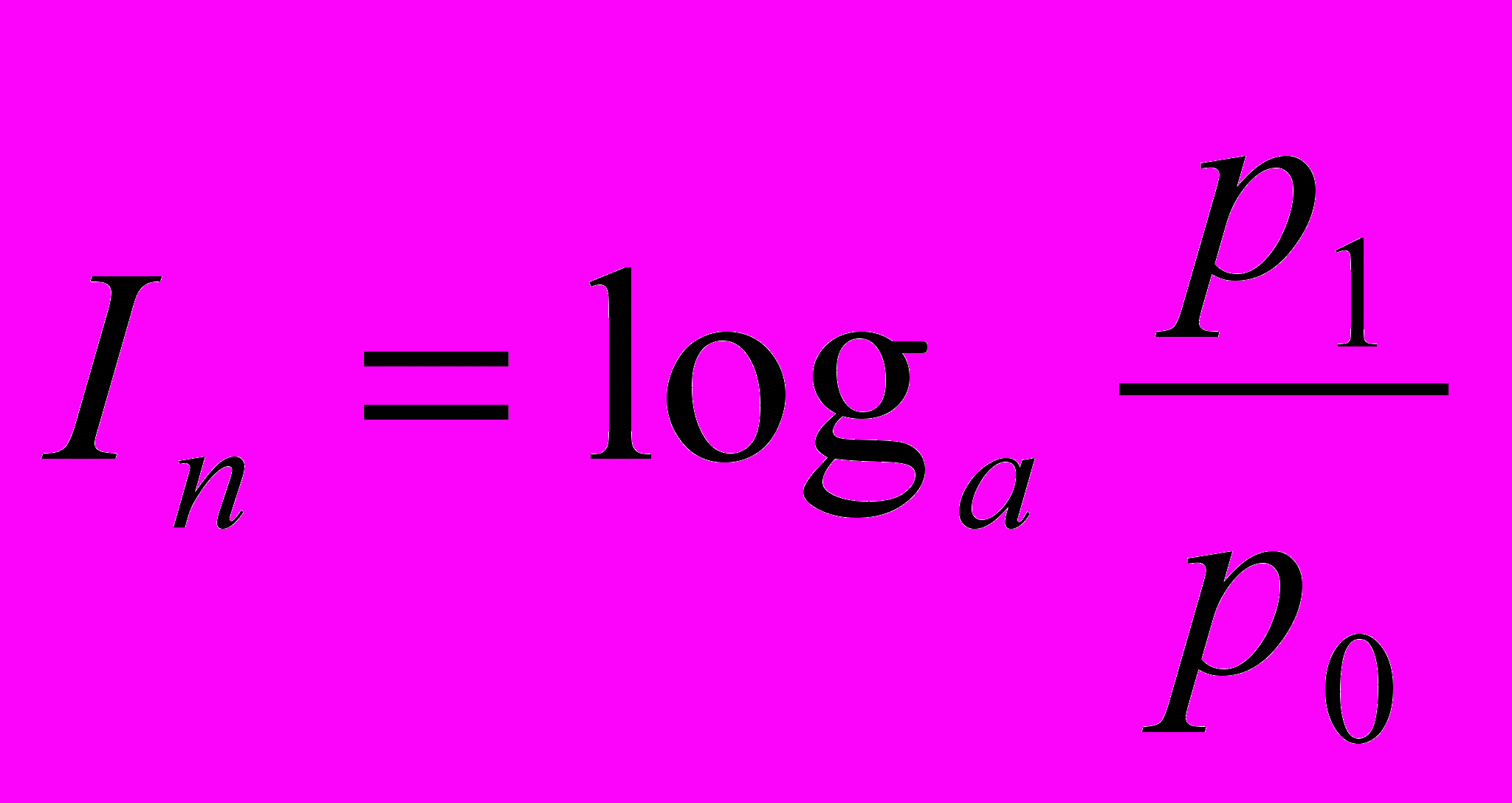 ,
,де p0- ймовірність досягнення мети до отримання інформації;
p1- ймовірність досягнення мети після отримання інформації.
Прагматична міра інформації означає корисність, цінність для управління. Ця міра величини відносна, і зумовлюється вона особливостями використання даної інформації у тій чи іншій системі.
Цінність інформації можна також вимірювати у тих самих одиницях, в яких вимірюється цільова функція управління системою. Наприклад: в інформаційній системі управління виробництвом цінність інформації визначається ефективністю здійснюваного на її основі економічного управління або приростом економічного ефекту функціонування системи управління, зумовленим прагматичними властивостями інформації:
Ib(y)=Eb(y)-E(y),
де Ib(y) - цінність інформаційного повідомлення b для системи управління у;
E(y) - очікуваний економічний ефект функціонування системи управління у;
Eb(y) - очікуваний ефект функціонування системи за умови, що для управління буде використано інформацію, яка міститься в повідомленні b.
2.8 Кодування економічної інформації
2.8.1 Системи кодування економічної інформації
Методи кодування техніко-економічної інформації, які використовуються при створенні класифікаторів, безпосередньо пов'язані з методами класифікації.
Кодування призначене для формалізованого опису семантики (назв) різноманітних аспектів даних, які використовуються в управлінні народним господарством, найчастіше у вигляді цифрових кодів. Таке подання найприйнятніше для підвищення ефективності автоматизованої обробки економічної інформації.
Під кодуванням розуміють процес позначення первинної множини об'єктів або повідомлень набором символів заданого алфавіту на основі сукупності певних правил. Залежно від використаних символів розрізняють цифрові, літерно-цифрові та літерні коди. Кількість символів у алфавіті називають основою коду. Залежно від основи коду вони бувають двійковими, десятковими, шістнадцятковими і т. ін. Залежно від використаних правил кодування коди можуть бути змінної чи постійної довжини. Основною вимогою, яку ставлять до кодування, є однозначне подання кожного об'єкта кодованої множини, тобто кожному об'єкту множини має відповідати єдиний код.
Системою кодування називають сукупність методів і правил позначення об'єктів заданої множини. Система кодування характеризується ємністю - кількістю кодів, що різняться між собою, тобто комбінацій, використаним алфавітом коду і правилами утворення коду.
Код характеризується довжиною, тобто кількістю використаних розрядів, структурою, яка відображає зміст окремих розрядів або груп розрядів коду.
У процесі кодування вирішуються дві основні проблеми - забезпечення ефективності і надійність обробки інформації. Якщо вирішення першої проблеми найчастіше пов'язане з намаганням зменшити довжину коду, то при вирішенні другої доводиться вводити ту чи іншу інформаційну надмірність. Тому комплексне вирішення пов'язане з пошуком певного оптимуму.
У процесі кодування економічної інформації необхідно розв'язати три основних завдання: однозначного позначення (ідентифікації) кожного об'єкта заданої множини, кодування деякої сукупності властивостей (атрибутів) об'єкта і забезпечення інформаційної надійності або достовірності на всіх етапах кодування, передавання, зберігання і обробки даних.
Код будь-якого об'єкта (запис інформації про об'єкт) складається з ідентифікаційної частини, інформаційного блока, який містить набір кодів, що відповідають властивостям даного об'єкта, і додаткових розрядів або блоків, які забезпечують захист усього коду від можливих помилок.
Мета кодування номенклатур економічних даних полягає в тому, щоб подати інформацію в компактній і зручній формі. Нагадаємо, що процес кодування-це присвоєння умовних позначень різним об'єктам визначеної номенклатури за встановленими правилами на базі прийнятого для цього алфавіту, а сукупність правил, за якими присвоюються коди окремим об'єктам номенклатур, являють собою метод або систему кодування.
Розрізняють порядкову, серійну, систему повторення, розрядну (позиційну) і комбіновану системи кодування.
Порядкова система застосовується для кодування однозначних, стабільних і простих номенклатур. Наприклад: категорії персоналу, статті витрат, види платежів до бюджету тощо. Вона передбачає присвоєння об'єктам цифрових номерів у порядку їх розміщення в номенклатурі з натурального ряду чисел без пропуску номерів. При використанні цього методу кожний об'єкт класифікованої множини кодується за допомогою поточного номера.
Переваги даної системи - простота побудови кодів, мала значущість, густота записів.
Недоліки - не передбачається групування об'єктів за ознаками; з появою нових об'єктів даної номенклатури порушується прийнята класифікація; відсутність у коді будь-якої інформації про об'єкт і відносна складність автоматичної обробки інформації при підбитті підсумків за групами об'єктів.