
Ун-т «Дубна». Курс «Компьютерные сети»
| Вид материала | Лекция |
- Ун-т «Дубна». Курс «Компьютерные сети», 408.34kb.
- Ун-т «Дубна». Курс «Компьютерные сети», 488.73kb.
- Ун-т «Дубна». Курс «Компьютерные сети», 371.9kb.
- Ун-т «Дубна». Курс «Компьютерные сети», 560.01kb.
- Ун-т «Дубна». Курс «Компьютерные сети», 276.95kb.
- Ун-т «Дубна». Курс «Компьютерные сети», 547.71kb.
- Ун-т «Дубна». Курс «Компьютерные сети», 676.23kb.
- Урок по теме «Компьютерные сети. Интернет», 157.31kb.
- Ун-т «Дубна». Курс «Компьютерные сети», 611.15kb.
- Лекция Глобальные сети. Интернет. Корпоративные компьютерные сети, 89.75kb.
Ун-т «Дубна». Курс «Компьютерные сети».
Лекция 11.
- Задержки и потери данных в сетях.
- Методы управления трафиком.
- Методы контроля перегрузки
Основные направления управления трафиком.
С радикальным ростом трафика и появлением таких его видов как приложения реального времени, мультимедийный трафик, трафик групповой рассылки и т д., требования пользователей к качеству обслуживания существенно возросли.
С другой стороны, рост нагрузки на сеть приводит к перегрузкам и очередям. Поэтому возникает необходимость дифференцировать трафик по степени чувствительности к задержкам.
Эластичный трафик может в широких пределах приспосабливаться к задержкам и изменению пропускной способности.
- Электронная почта
- Передача файлов (ftp)
- Управление сетью (SNMP)
- Интерактивные приложения (доступ к WEB или к удаленным вычислительным системам)
Как правило, эти классы трафика чувствительны к потере пакетов.
^ Неэластичный трафик плохо адаптируется (или не адаптируется) к задержкам и изменениям пропускной способности объединенной сети. Примеры:
- трафик реального времени,
- мультимедийный трафик.
Неэластичный трафик выдвигает новые требования к качеству обслуживания.
- Требуется твердая минимальная пропускная способность.
- Чувствительность к задержкам, ограничения на максимальное время задержек.
Допускается незначительная потеря пакетов без значительного снижения качества и прекращения функционирования. Часто характеризуется равномерностью потока данных, т.е. постоянной битовой скоростью – «предсказуемость» трафика.
Все эти требования сложно удовлетворить в среде с неравномерным трафиком, переменными задержками в очередях и потерей данных при перегрузке.
- Необходим приоритет трафику с более высокими требованиями к качеству обслуживания, причем желательно об этих требованиях заявить заранее. Следовательно, желателен протокол, регламентирующий резервирование ресурсов.
- Эластичный трафик по-прежнему должен поддерживаться даже в условиях более низкого приоритета. В отличие от ТСР-приложений, неэластичные приложения при перегрузках не отключаются и не снижают требований. Поэтому при возникновении перегрузки неэластичный трафик продолжает создавать высокую нагрузку на сеть, тогда как эластичный в этих условиях окажется полностью вытесненным из объединенной сети. В этих условиях также должен помочь протокол резервирования.
Еще один важный фактор состоит в том, что работа сети в недогруженном режиме, когда максимальная пропускная способность сети существенно выше реальной, является неэкономичной. Необходимо организовать работу сети так, чтобы обеспечить приемлемое качество обслуживания разных классов трафика в условиях нагруженной сети (принято считать, что коэффициент нагрузки должен быть порядка 0.9 от максимальной пропускной способности сети).
^ Методы борьбы с перегрузками включают следующие основные направления.
1. Методы контроля перегрузки состоят в том, чтобы в условиях перегрузки или угрозы перегрузки и потери пакетов обеспечить снижение объема трафика и удержане коэффициента нагрузки каждого ресурса сети на уровне 0.9. Работа в этом направлении ведется уже более тридцати лет.
2. Алгоритмы обслуживания очередей (методы борьбы с перегрузкой) нужны для работы в периоды перегрузок, когда сетевое устройство не справляется с передачей пакетов на выходном интерфейсе в том темпе, в каком пакеты поступают. В этом случае необработанные пакеты накапливаются во входной очереди.
3. Методы резервирования ресурсов – относительно новый подход к обеспечению качества обслуживания, он возник в связи с дифференцированием трафика по различным параметрам. Реализован, в частности в рамках протокола RSVP.
4. Инжиниринг трафика – активно развиваемое в последнее время направление разработки методов оптимизации движения потоков по сети с целью обслужить больше потоков при тех же характеристиках сети без снижения качества. Пример: включение альтернативных маршрутов в таблицы маршрутизации, учет при маршрутизации загрузки линий, дифференцированная маршрутизация потоков в зависимости от класса трафика и т.д. Классический пример неэффективности маршрутизации на основе наименьшего количества промежуточных узлов – топология типа «рыба».
Виды задержек
Перемещаясь от отправителя к получателю, каждый пакет проходит через сеть маршрутизаторов и линий связи. Каждый узел на пути пакета вызывает различные виды задержек, наиболее значимыми из которых являются
- задержка узловой обработки,
- задержка ожидания,
- задержка передачи,
- задержка распространения.
Сумма всех перечисленных задержек называется суммарной узловой задержкой пакета.
Приняв пакет, маршрутизатор анализирует заголовок, определяет направление дальнейшей передачи пакета и отсылает его на нужную линию связи. Мгновенное начало передачи пакета возможно только тогда, когда линия связи свободна и по ней не ведется передача других пакетов. А также при отсутствии очереди на передачу. В противном случае пакет вынужден встать в очередь.
^ Задержка узловой обработки.
Время, необходимое для чтения заголовка и определения дальнейшего маршрута (плюс в ряде случаев проверка на искажения и др. виды анализа).
На высокоскоростных маршрутизаторах времена задержки составляют единицы микросекунд.
^ Задержка ожидания.
Задержка, которой подвергается пакет, находясь в очереди. Время ожидания зависит от числа пакетов в очереди и может значительно варьироваться в различных маршрутизаторах на пути пакета.
Доминирующая модель обслуживания в сетях с коммутацией пакетов – обслуживание пакетов в порядке их поступления в очередь (^ First In – First Out, Первым пришел – первым обслужен, FIFO). В этой модели наш пакет будет передан после обслуживания всех предыдущих пакетов.
При невысокой загрузке линии время ожидания нулевое или незначительное, но может многократно увеличиться при перегрузке.
Может составлять от нескольких микросекунд до нескольких миллисекунд.
Длина очереди на момент появления очередного пакета является функцией интенсивности характера трафика пакетов.
^ Задержка передачи (задержка накопления).
Суммарное время, требуемое для освобождения пакетом места в буфере.
Если L – длина пакета, а R - скорость передачи по линии связи, задержка передачи равна L/R. Может составлять от нескольких микросекунд до нескольких миллисекунд.
^ Задержка распространения.
Время, необходимое для передачи одного бита по физической линии. Не зависит от длины пакета. Определяется длиной линии и физическими свойствами передающей среды. Скорость распространения сигнала лежит в пределах от 2.е+8 м\с до 3.е+8 м\с, т.е. сравнима со скоростью света.
Как правило – несколько миллисекунд (длина линии, деленная на скорость).
Таким образом, задержка ожидания – единственная составляющая узловой задержки, которая может принимать разные значения для разных пакетов, в зависимости от загрузки сети.
Для ее оценки используются статистические величины – среднее время ожидания, дисперсия времени ожидания, вероятность превышения временем ожидания заданной величины.
Факторы, влияющие на задержку ожидания.
- Частота получения пакетов
- скорость передачи выходной линии связи
- закон распределения получаемых пакетов по времени, в частности – является ли получение пакетов периодическим или апериодическим (хаотическим)
Пусть a, R, L – соответственно средняя частота получения пакета в битах, скорость передачи по выходной линии в битах в секунду и длина пакета в битах. Тогда скорость получения данных маршрутизатором равна I=L*a/R бит\с. Это интенсивность трафика.
Пусть буфер бесконечно большой, т.е. очередь может иметь бесконечную длину. Тогда интенсивность трафика играет определяющую роль в оценке длины очереди. Если интенсивность больше 1, это означает, что средняя скорость приема информации превышает среднюю скорость ее передачи, что приводит к неограниченному росту очереди. Таким образом, нужно организовывать работу так, чтобы интенсивность всегда была меньше 1.
Далее будем считать, что так оно и есть.
Если пакеты появляются периодически с периодом L/R секунд, то каждый раз пакет будет приходить в пустой буфер, следовательно, время ожидания будет равно 0.
Если пакеты приходят периодически, но их сразу несколько (N), то время ожидания уже не будет нулевым.
На практике типичным является появление пакетов в случайные моменты времени, т.е. время между появлением пакетов нельзя предсказать заранее.
В этом случае значение интенсивности трафика не дает возможности предсказать задержку ожидания, однако позволяет оценить зависимость задержки ожидания от скоростей приема и передачи пакетов. Если интенсивность близка к 0, значит, вероятность непустого буфера в момент получения пакета мала, т.е. время ожидания тоже близко к 0. Если же интенсивность имеет значение, близкое к 1, то возможны кратковременные превышения скорости приема над скоростью передачи, что ведет к появлению очередей и росту их длины. Чем ближе значение интенсивности к 1, тем выше вероятность увеличения очереди и времени ожидания.
^ Потеря пакетов
На практике бесконечных буферов не существует, более того, объем буферов маршрутизаторов не только конечен, но и ограничен, т.к. увеличение размера буфера существенно повышает стоимость маршрутизатора. Это значит, что на практике задержка ожидания не может быть бесконечной. Если буфер заполнен – для поступающего пакета не остается места, и он будет потерян, т.е. отправленный пакет не будет получен адресатом.
Чем выше интенсивность трафика, тем выше вероятность потери пакета. Таким образом, передача пакетов через узлы сети характеризуется не только задержками, но и потерями пакетов.
^ Общая задержка
Пусть на пути пакета находятся (N-1) маршрутизаторов. Нагрузка в сети такова, что очереди отсутствуют или пренебрежимо малы, время обработки пакета каждым маршрутизатором и отправителем равно Т_обр, время распространения сигнала по линии равно Т_расп, все узловые задержки равны между собой. Тогда общая задержка дается формулой
Т_общ = (Т_обр + Т_пер + Т_расп)*N.
^ Cледствия перегрузки.
Первый сценарий: Пренебрегаем ограниченной емкостью буферов. Пусть маршрутизатор имеет пропускную способность R, каждый хост направляет пакеты со скоростью in, всего хостов N. Тогда зависимость производительности маршрутизатора (объем переданной информации за единицу времени) от скорости передачи данных будет линейной при in
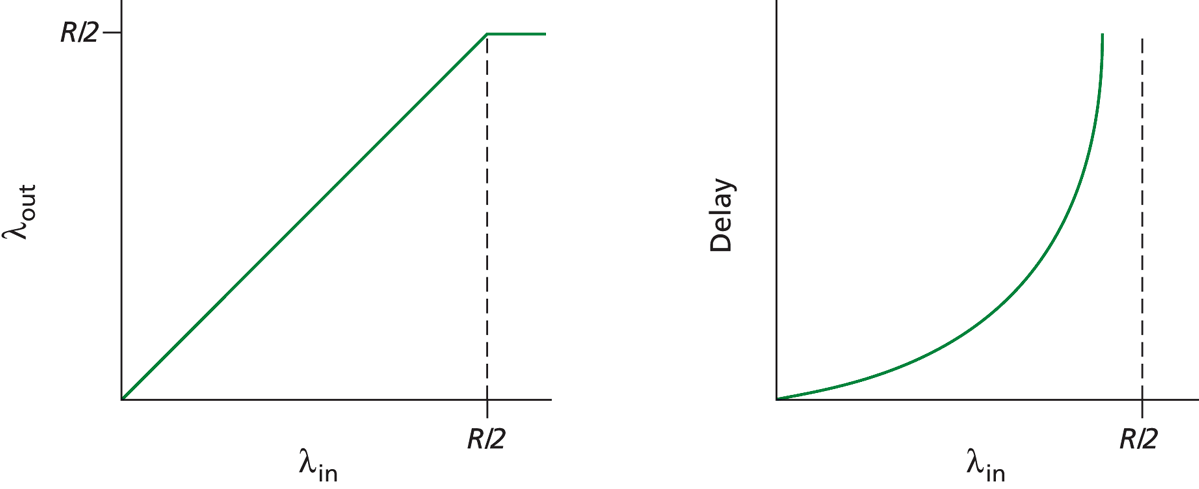
С одной стороны, достижение максимальной производительности хорошо, т.к. в этом случае ресурсы используются полностью. С другой стороны, при производительности, близкой к максимальной, у нас и задержки большие.
Итак, чем ближе скорость передачи данных к пропускной способности линии связи, тем большими становятся задержки ожидания пакетов.
Или: если скорость, с которой пакеты прибывают и становятся в очередь, превышает скорость, с которой они могут быть оправлены дальше, размер очереди растет неограниченно, а задержка передачи пакета стремится к бесконечности.
^ Второй сценарий: Буферное пространство конечное. Два источника, один маршрутизатор, повторная передача каждого потерянного пакета. С1 – прилагаемая нагрузка, т.е. скорость передачи сегментов, включая как новые, так и повторные. Если бы хост «знал», заполнен буфер или нет и осуществлял бы передачу только тогда, когда там есть место – можно было бы полностью избежать потерь, т.е. С=С1. Это идеальный механизм.
Более реальный механизм – повторная передача осуществляется тогда, когда факт потери пакета достоверно установлен. С1=R/2: суммарная скорость делится на две составляющие – скорость новых данных и повторных пакетов.
Значит, потери пакетов, обусловленные переполнением буферов маршрутизатора, вынуждают передающую сторону делать повторные передачи.
^ Третий сценарий: Несколько маршрутизаторов. При потере пакета вследствие перегрузки одного из маршрутизаторов на его пути бесполезной оказывается работа всех маршрутизаторов, которые уже прошел наш пакет.
Методы контроля перегрузки
Все рассмотренные ниже методы реализуют механизм обратной связи, т.е. узел, «заметивший» перегрузку, каким-либо способом сигнализирует об этом либо соседним с ним узлам, либо конечным узам: источнику данных или адресату.
Противодавление. Аналогия с трубой, по которой течет жидкость. Если один конец закрываем, давление жидкости передается назад по трубе, и поток останавливается.
Реализуется передача информации о перегрузке предыдущим узлам, чтобы они снизили скорость. Таким образом, если буферы узла переполняются, поток пакетов к нему от предыдущего узлов, должен замедлиться и остановиться. В соседних узлах, в свою очередь, после снижения скорости передачи данных в ответ на сигнал, тоже буферы переполняются, и они сигнализируют, в свою очередь, предыдущим узлам. Если ситуация продлится, упомянутые предыдущие узлы останавливают потоки данных на своих входящих линиях и т.д. Это ограничения распространяется назад навстречу потоку данных к отправителям, которым приходится ограничить подачу новых пакетов в сеть. Реализация этого метода имеется в сетях X.25. В объединенных сетях применение данного подхода весьма ограничено.
^ Сдерживающий пакет. На перегруженном узле формируется управляющий пакет и передается назад узлу-источнику для ограничения потока данных. Пример – сообщение Sourse Quench (гашение источника) протокола ICMP, которое посылается маршрутизатором или хостом, вынужденным отвергать дейтаграммы из-за переполнения буфера. Сообщение посылается в ответ на каждую отбрасываемую дейтаграмму. Получив такое сообщение, хост-источник должен снизить скорость, с которой отправляет данные указанному получателю до тех пор, пока не перестанет получать подобные сообщения. Это относительно грубый метод борьбы с перегрузкой.
^ Неявная сигнализация о перегрузке. Отправитель делает заключение о перегрузке на основе косвенных признаков – задержки и потери пакетов. Если все отправители в сети способны обнаружить по этим признакам перегрузка и в ответ снижать скорость передачи данных – перегрузка сойдет на нет. Это эффективный метод в дейтаграммных конфигурациях (IP-сети), где нет средств явного установления факта перегрузки, поскольку IP-протокол не предоставляет никакой информации относительно перегрузки. Например, в рамках протокола ТСР, устанавливающего связь между оконечными системами, можно узнать об увеличении задержки и проинформировать узел-отправитель, чтобы тот принял меры.
^ Явная сигнализация о перегрузке. Сеть явно предупреждает оконечные системы о растущей перегрузке, а оконечные системы предпринимают меры для ее снижения. Уведомление источника может проходить по двум направлениям.
- Назад. Встречная информация передается путем изменения битов в пакетах, направляемых обратно источнику, либо отправления источнику специальных управляющих пакетов напрямую.
- Вперед. Уведомление о перегрузке посылается в направлении движения пакетов, т.е. сообщается, что пакет встретил на своем пути перегруженные ресурсы. Информация может передаваться путем изменения соответствующих битов в пакетах с данными либо в специальных управляющих пакетах.
Явная сигнализация может осуществляться разными методами.
Установка бита в определенное значение называется двоичным методом явной сигнализации.
Методы кредита состоят в явном указании, сколько байтов или пакетов может передать источник. Когда кредит исчерпан, источник ждет дополнительного кредита для продолжения передачи данных. (Пример – размер скользящего окна в заголовке ТСР).
Методы регулирования скорости ориентированы на установку явного предела скорости передачи данных для источника по логическому соединению. Для борьбы с перегрузкой каждый узел на пути сообщения может уменьшить значение предела скорости в управляющем сообщении к источнику. Эта схема применяется в сетях АТМ.
Таким образом, в разных подходах контроль перегрузки может возлагаться на хосты (осуществляется транспортным уровнем) и\или на транзитные узлы (осуществляется сетевым уровнем).
- ^ Контроль перегрузки оконечными системами. В этом случае контроль за перегрузкой осуществляется транспортным уровнем путем явной и неявной сигнализации. В функции транспортного уровня входит установление факта перегрузки по характерным признакам (потеря пакетов, задержки). В рамках стека ТСР\IP контроль осуществляется в рамках протокола ТСР. Сигналом о наличии перегрузки служит потеря сегмента, реакцией на которую является уменьшение окна приема (явная сигнализация). В новых проектах ТСР признаком перегрузки служит увеличение времени оборота.
- ^ Контроль перегрузок с поддержкой на сетевом уровне. Предполагается наличие явной связи, с помощью которой сетевые устройства (маршрутизаторы) информируют оконечные системы о перегрузках в сети. Применяется в ABR сетей ATM и др., предлагается для ТСР\IP.
Контроль перегрузок в службе АВR в сетях АТМ.
Ячейки (пакеты) передаются через последовательность коммутаторов (маршрутизаторов) от отправителя к получателю. Среди ячеек с данными содержатся служебные ячейки управления ресурсами (Resourse management, RM). Они используются для обмена информацией о перегрузках между хостами и коммутаторами. Получатель отсылает RM-ячейки отправителю, иногда меняя их содержимое. Коммутатор может самостоятельно генерировать RM-ячейки и отправлять их нужным хостам. Таким образом, возможна как организация «прямой» обратной связи, так и обратной связи «через получателя».
^ Механизм контроля перегрузок в службе ABR (Available Bit Rate) основан на величине скорости передачи. Передающая сторона явно рассчитывает максимальную скорость, с которой может вестись передача, и при необходимости регулирует ее. Предусмотрены три возможности для оповещения получателя о перегрузках.
1. Каждая ячейка с данными содержит специальный бит EFCI (Explicit Forward Congestion Indication, явный признак перегрузки). При возникновении перегрузки коммутатор устанавливает этот бит в 1. Хосты назначения проверяют бит EFCI у всех принимаемых ячеек. Если при получении служебной RM-ячейки хост-получатель обнаруживает EFCI=1 в последней из принятых ячеек с данными, то бит CI, признак перегрузки в RM-ячейке, также устанавливается в 1, и в таком виде RM-ячейка отсылается передающей стороне.
2. Частота передачи RM-ячеек настраивается. По умолчанию RM-ячейки посылаются через каждые 32 ячейки с данными. В состав их входит, кроме CI, бит NI (no increase, запрет увеличения). Значения этих битов могут быть изменены коммутаторами. Бит CI устанавливается в 1 при значительной нагрузке, а NI – при умеренной. Получатель, при отсылке RM-ячейки обратно отправителю, может менять бит CI, а бит NI всегда оставляет неизменным.
3. RM-ячейки содержат поле двухбайтовое ER (Explicit Rate, явная частота). При возникновении перегрузки коммутатор может снизить значение, содержащееся в этом поле.
ABR-источники в сетях АТМ регулируют скорость передачи данных, как функцию значений CI, Ni и ER.
Контроль перегрузок в ТСР-сетях
Особенности сетей на базе ТСР\IP, осложняющие контроль перегрузок.
- Протокол IP не требует соединений и не хранит информацию о своем состоянии, поэтому не имеет средств борьбы с перегрузкой на сетевом уровне.
- Протокол ТСР обеспечивает сквозное управление потоком и позволяет догадаться о наличии перегрузки только по косвенным признакам.
- Разные ТСР-соединения не могут сотрудничать между собой для управления перегрузкой и поддержания определенного уровня суммарного потока.
Фактически, основным инструментом регулирования трафика в рамках протокола ТСР для регулирования трафика является механизм скользящего окна. Он изначально был разработан для управления сквозным трафиком, но было придумано несколько алгоритмов динамического управления размером окна, что делает возможным обнаружение и предотвращение перегрузки, а также восстановление, если она возникла.
Подход, применяемый в рамках ТСР, состоит в ограничении скорости передачи данных в зависимости от наблюдаемой перегрузки. Если перегрузки нет, источник может увеличить скорость передачи данных. При наличии перегрузки скорость передачи принудительно снижается.
Возникают вопросы:
1. как ограничить скорость передачи данных
2. как источник определит наличие перегрузки между источником и приемником
3. каков алгоритм изменения скорости в зависимости от перегрузки
По п.1. Используется скользящее окно (окно перегрузки): объем неподтвержденных данных, которые может передать источник, не может превышать значение окна перегрузки. Таким образом, с одной стороны, обеспечивается конвейеризация, оптимизирующая передачу потока данных, а с другой стороны – регулируется скорость передачи пакетов.
По п.2. Событие «потеря пакета» фиксируется по истечении интервала ожидания квитанции. Потеря пакета является признаком перегрузки.
По п.3. Алгоритм изменения скорости основан на динамическом изменении двух параметров - размера скользящего окна и времени ожидания квитанции (среднее время оборота).
^ Основные особенности:
- мультипликативное снижение скорости при перегрузке. Скорость (размер окна) снижается в 2 раза, пока не достигнет максимального размера сегмента (MSS, maximal segment size).
- аддитивное увеличение скорости при отсутствии перегрузки. Отсутствие факта перегрузки может означать наличие неиспользуемых ресурсов на линии связи, что является убедительным поводом повысить нагрузку. Нарастание скорости происходит медленно и плавно. Если за время оборота не было потерь пакетов, ТСР немного увеличивает нагрузку.
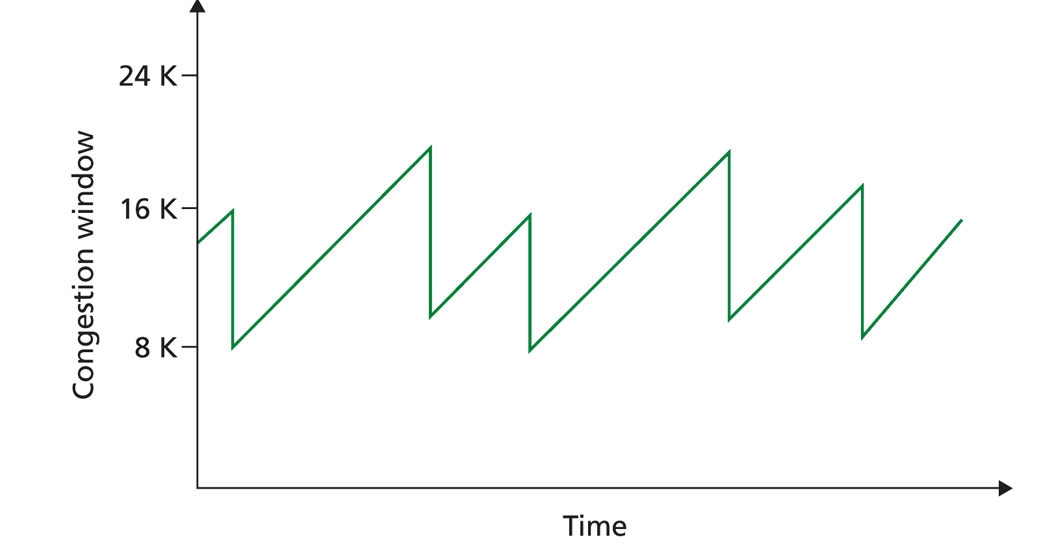
Таким образом, величина окна перегрузки циклически проходит через стадии линейного нарастания и резкого спада до половины текущего значения при потере пакета. Поэтому график величины окна перегрузки в зависимости от времени, напоминает зубья пилы.
- медленный старт. При установлении ТСР-соединения начальным значением окна перегрузки является величина MSS. Значит, начальная скорость передачи соединения составляет MSS/RTT, где RTT – время оборота. Поскольку такая скорость существенно ниже максимально возможной, линейное наращивание скорости в отсутствие перегрузки происходит нерационально, т.к. процесс тянется слишком долго. Поэтому на начальном этапе вместо линейного используется экспоненциальное увеличение размеров окна: размер окна возрастает вдвое после каждого истечения времени оборота, что обеспечивает быстрый рост скорости передачи. Экспоненциальный рост продолжается до первой потери пакета, далее идет уменьшение вдвое размеров окна, после чего окно увеличивается по линейному закону.
На самом деле алгоритм еще более сложный: есть дополнительные детали.
Устанавливается пороговое значение размера окна, ниже которого рост размера окна идет экспоненциально, а выше – уже по линейному закону. Порог может меняться в определенных ситуациях. Например, при потере пакета его величина устанавливается как половина текущего размера окна.
Реакция на истечение времени ожидания – переход в состояние медленного старта с уменьшением окна до минимального размера и экспоненциальным его увеличением, пока размер окна не достигнет половины своего значения до истечения времени ожидания, Далее размер окна увеличивается линейно.
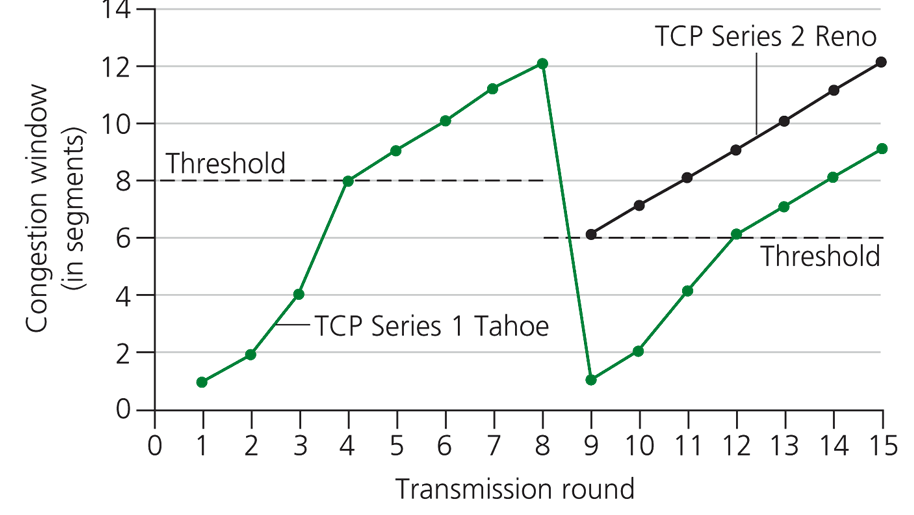
Реакция на пропущенный пакет – быстрая повторная передача и быстрое восстановление. Если пакет пропущен, а получен следующий за ним пакет – посылается повторное подтверждение приемы предыдущего пакета. И так каждый раз, пока не придет пропущенный. После приема трех подтверждающих квитанций происходит немедленная отправка пропущенного пакета, без ожидания истечения тайм-аута (быстрая повторная передача), размер окна уменьшается вдвое и затем увеличивается по линейному закону (быстрое восстановление).
При первичной и повторной передаче пакета время ожидания квитанции для него учитывается по-разному при расчете среднего времени оборота.
При первичной передаче пакета используется Алгоритм Якобсона.
Расчет усредненного времени ожидания с Увеличенным весом последних событий (т.к. они с большей вероятностью отражают будущее поведение) с учетом динамической оценки дисперсии.
Время ожидания RT – текущее, SRT – среднее.
SRT(K+1) = (1-g)*SRT(K) + g*RT(K+1); g=1/8=0.125
Serr(K+1) = RT(K+1) - SRT(K+1); текущее отклонение от среднего времени ожидания.
Sdev (K+1) = (1-h)*Sdev(K) + h*|Serr(K+1)|; h=1/4=0.25 - дисперсия
RTO(K+1) = SRT(K+1) + f*Sdev(K+1); f=2.
При повторной посылке пакета интервал ожидания удваивается либо используется алгоритм Карна.
(1) RTO(K+1) = SRT(K+1) + MAX[G,f*Sdev(K+1]; f=4, G – заданное минимальной значение дисперсии.
(2) Значение RT не используется для обновления SRT и Sdev.
(3) Увеличенное значение RTO используется до тех пор, пока не прибудет подтверждение для сегмента, переданного с первой попытки.
В последних спецификациях ТСР (2001) определена также возможность ограниченной передачи, позволяющая в условиях, когда количество данных для передачи ограниченно, отправить немного данных сверх лимита, определяемого текущим размером окна.
Можно показать, что динамическое изменение размеров окна обеспечивает выравнивание скоростей по всей линии связи, т.е. средняя скорость передачи составляет примерно R/K, где R - пропускная способность проблемной линии, К – количество ТСР-соединений, использующих эту линию. Таким образом, пропускная способность делится между всеми использующими ее линиями примерно поровну.
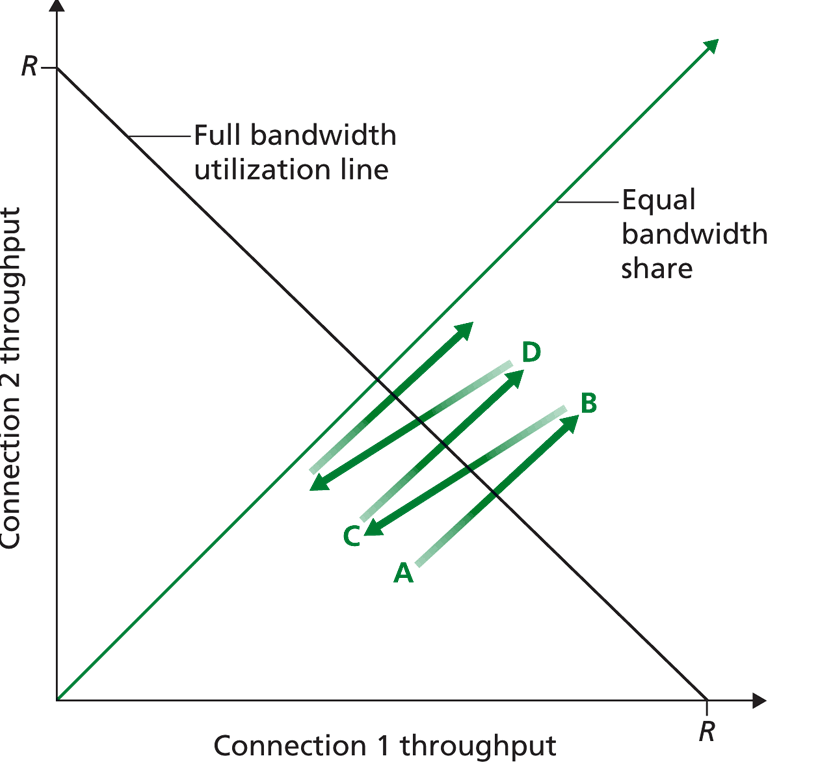
Многие мультимедиа- и Интернет приложения отказываются от ТСР-соединений в пользу UDP-протокола, поскольку снижение скорости при перегрузках для них нежелательно. Протокол UDP не ограничивает пропускную способность, но допускает потерю пакетов. При этом мультимедиа-приложения не регулируют скорость передачи, не взаимодействуют с другими соединениями, не обеспечивают выравнивание скоростей. Поэтому пропускная способность для ТСР-соединений существенно снижается.
Отрицательно сказывается на пропускной способности линий и обилие параллельных ТСР-соединений. Рост числа параллельных соединений, устанавливаемых приложениями (например, веб-браузерами для одновременной доставки нескольких объектов веб-страницы), увеличивает долю пропускной способности, «захватываемой» этим приложением в ущерб другим приложениям.
Одной из актуальных в настоящее время проблем является разработка механизмов контроля перегрузки, ограждающих пропускную способность Интернета от «губительного» воздействия UDP-соединений и параллельных ТСР-соединений.