
Аннотация
| Вид материала | Документы |
- Механизм воздействия инфразвука на вариации магнитного поля земли, 48.07kb.
- I. Пояснительная записка. Аннотация, 129.92kb.
- А. В. Жилкин, Д. А. Филиппов, С. Ю. Круглов, И. В. Шевченко фгуп «Горно-химический, 69.77kb.
- Аннотация рабочей программы дисциплины Аннотация дисциплины история культуры и искусства, 2388.24kb.
- Баталова Лариса Вячеславовна Аннотация, 126.98kb.
- В. Ю. Шевяхова Россия, Москва, мгу имени М. В. Ломоносова tamara@got ps msu su Аннотация:, 89.51kb.
- Карцев Евгений Александрович Аннотация: программа курса, 233.93kb.
- П. А. Столыпина и его значение для аграриев современной России Аннотация: Работа напечатана, 103.62kb.
- Аннотация программы дисциплины учебного плана и программ учебной и производственных, 24.01kb.
- Примерный учебный план 16 Аннотации программ учебных дисциплин профиля 20 > Аннотация, 1470.24kb.
Прикладное программное обеспечение для многоязыковой поддержки распределенных баз данных
A.B. Карнаухов(#), Э. Венгер(*), B.Н. Карнаухов(#), Н.С. Мерзляков(#),
Ж. ван Тинен(@), Е.В. Уханова(%), А. Хайдингер(+),
(#)Институт проблем передачи информации Российской Академии Наук
Россия, 127994, Москва, ГСП-4, Б.Каретный пер. д.19,
e-mail: avk@iitp.ru, victor.karnaukhov@iitp.ru, nick@iitp.ru,
(*)Комиссия научной визуализации Австрийской Академии Наук
Tech Gate Vienna, Donau-City-Strasse 1, Vienna, A-1220, Austria,
e-mail: emanuel.wenger@oeaw.ac.at
(@)Национальная библиотека Нидерландов,
Prins Willem Alexanderhof 5, P.Box 90407, 2509 LK The Hague, The Netherlands
e-mail: Gerard.vanthienen@kb.nl
(%)Государственный Исторический музей,
Россия, 103012, Москва, Красная пл., д. 1/2
e-mail: manuscript@shm.ru
(+)Комиссия палеографии и кодикологии средневековых рукописей
Австрийской Академии Наук, Postgasse 7-9 / 4 / 3, Vienna A-1010, Austria
e-mail: alois.haidinger@oeaw.ac.at
Ключевые слова: база данных, распределенная база данных, многоязыковая поддержка, водяной знак, прикладная программа.
Аннотация
Рассматриваются вопросы разработки и создания распределенных баз данных и прикладного математического обеспечения с многоязыковой поддержкой. Представлено решение данной задачи на примере разработки распределенной базы данных водяных знаков средневековых рукописей, первопечатных книг и других историко-архивных документов. Актуальность данной работы определяется тем, что существующие базы данных и электронные каталоги строятся, в основном, на основе таких коммерческих программных средств как Microsoft Access, Microsoft Excel, dBase и т.п. Такие небольшие базы данных являются, как правило, локальными и поддерживают только один язык, что резко ограничивает эффективность их совместного использования пользователями, работающими с другими языками. В силу этого, разработка и создание средств, с помощью которых эти небольшие локальные базы данных могут быть объединены и совместно использованы в рамках некоторой распределенной базы данных с многоязыковой поддержки, является крайне перспективной.
1Введение
Средневековые рукописи, первопечатные книги и многие другие историко архивные документы представляют важную часть культурного наследия. Исследование, каталогизация и реставрация этих исторических документов необходимы для сохранения этого наследия для будущего.
Во многих случаях эти документы не датированы, но знание даты, когда они были написаны или напечатаны, крайне необходимо для исторических исследований. До настоящего времени в исторических исследованиях для хронологической идентификации средневековых рукописей, первопечатных книг и других исторических документов, как правило, используются "ручные" методы. Наиболее широко распространенные методы идентификации основаны на анализе данных о бумаге, использованной в исследуемом историческом источнике, и в частности, данных о водяных знаках или филигранях. Сравнение датированных водяных знаков с недатированными является основным методом для определения возраста средневековых (бумажных) рукописей и первопечатных книг. Для этих целей широко используются стандартные каталоги водяных знаков1,2, содержащие тысячи контурных копий средневековых водяных знаков, полученных ручным срисовыванием изображений водяных знаков из датированных исторических документов. Хронологическая идентификация средневековых рукописей, первопечатных книг и других исторических документов при таком подходе осуществляется простым поиском идентичного водяного знака в каталогах, выполнением некоторых измерений с помощью линейки и анализе полученных данных. Крайне низкая эффективность и высокая трудоемкость идентификации такими методами очевидны. Поэтому для повышения эффективности этих работ все более широкое применение находят компьютеры, которые являются идеальными инструментальными средствами для получения, хранения, сравнения и каталогизации огромных объемов данных.
Первым шагом перехода на цифровые технологии в этой области было создание баз данных средневековых рукописей, первопечатных книг и содержащихся в них водяных знаков. Эти базы данных по существу представляли собой цифровые аналоги соответствующих каталогов и строились, в основном, на основе таких коммерческих программных средств как Microsoft Access, Microsoft Excel, dBase и т.п.
^
2Общий подход к созданию баз данных историко архивных документов с многоязыковой поддержкой
К настоящему времени во многих научно-исследовательских центрах уже разработаны и быстро развиваются большие базы данных средневековых рукописей, первопечатных книг и содержащихся в них водяных знаков3-8, объем данных в которых уже измеряется многими тысячами базовых записей. Вместе с тем даже такие большие базы данных являются, как правило, локальными и поддерживают только один язык, что резко ограничивает эффективность их совместного использования учеными, работающими в данной области исследований с аналогичными данными, но использующими другие языки. Поэтому следующие шаги перехода на цифровые технологии в данной области должны быть направлены на создание распределенных баз данных с многоязыковой поддержкой и на обеспечение телекоммуникационного доступа к данным.
Анализ известных баз данных историко-архивных документов показал, что каждая из существующих баз данных имеет свою специфику, отражающую научные интересы ее разработчиков и конечных пользователей, но вместе с тем все они содержат некий набор основных информационных материалов, тип и структура которых является практически одними и теми же во всех этих база данных. В качестве примера можно назвать набор метрических параметров, используемый для идентификации водяного знака, данные о содержащем его источнике: средневековой рукописи или первопечатной книге, месте их создания, составе, авторах, переплете, украшениях, писцах, водяных знаках и многие другие. Поэтому возможность объединения этих данных, в рамках единой распределенной базы данных представляется очень заманчивой и перспективной, т.к. такое объединение может обеспечить доступ конечных пользователей к информационным материалам всей объединенной системы.
Реляционная модель данных является де-факто стандартом для сложных баз данных и в силу этого обычно используется при проектировании и разработке базы данных средневековых рукописей, первопечатных книг и содержащихся в них водяных знаков. Все информационные материалы в таких база данных организованы в виде некоторой совокупности взаимосвязанных таблиц. Существующие базы данных обычно содержат более ста информационных полей для обеспечения квалифицированного описания только одной средневековой рукописи, первопечатной книги или содержащегося в них водяного знака. Естественно, что в базах данных такого типа большое количество полей данных является описательным и, следовательно, зависящим от используемого языка. Поэтому проблеме обеспечения многоязыковой поддержки должно было уделено большое внимание уже на стадии проектирования самой базы данных, при разработке структуры таблиц и триггеров проектируемой базы данных.
Построение базы данных, которая будет использоваться только в одном из поддерживаемых языков, не вызывает больших проблем при ее проектировании и создании. Современные базы данных, работающие под управлением современных СУБД (Систем Управления Базами Данных) и поддерживающие телекоммуникационный доступ к данным, предоставляют возможность одновременного использования информационных материалов базы данных во всех поддерживаемых языках. Регистрация в базе данных некоторого объекта в одном из поддерживаемых языков может быть организована таким образом, что данный объект будет зарегистрирован и во всех остальных поддерживаемых языках и, следовательно, будет доступен для пользователей, работающих в любом из поддерживаемых языков. При этом все информационные материалы, относящиеся к данному объекту, и не зависящие от языка, будут находиться в совместном использовании для всех поддерживаемых языков. Способы наполнения и использования зависящих от языка информационных материалов определяется конкретной реализацией базы данных и прикладного программного обеспечения. Для обеспечения независящей от используемого языка взаимосвязи данного объекта с другими объектами базы данных обычно используются вспомогательные поля данных, генерируемые, поддерживаемые и используемые СУБД и прикладным программным обеспечением. Следует отметить, что использование вспомогательных полей в реляционных базах данных широко распространено и обычно не вызывает проблем. В тех случаях, когда при создании вспомогательных полей данных избежать использования зависящих от языка терминов и символов нельзя, одним из возможных вариантов решения проблемы может служить использование распространенных и общепризнанных терминов и символов, используемых, например, в сети Интернет.
^
3База данных водяных знаков с многоязыковой поддержкой
Изложенный выше подход к построению баз данных историко-архивных документов с многоязыковой поддержкой был апробирован при создании и развитии базы данных водяных знаков средневековых рукописей5,8. База данных была создана в сотрудничестве Комиссии палеографии и кодикологии средневековых рукописей Австрийской АН (г. Вена, Австрия), Комиссии научной визуализации Австрийской АН (г. Вена, Австрия) и Института проблем передачи информации Российской АН (г. Москва, Россия). В первоначальном варианте базы данных была обеспечена поддержка только одного языка – немецкого. В данный момент количество зарегистрированных в базе данных водяных знаков уже приближается к 10000, а суммарный объем данных - к 1 Гбайт. Основная часть этих водяных знаков взята из средневековых рукописей и первопечатных книг, хранящихся в монастыре Клостерноебург (Klosterneuburg, Австрия). В настоящее время совместно с Национальной библиотекой Нидерландов (г. Гаага, Нидерланды) и Государственным историческим музеем (г. Москва, Россия) ведутся исследования по дальнейшему развитию и созданию распределенной базы данных с обеспечением многоязыкой поддержки, и в частности, поддержки голландского и русского языков.
В ходе выполнения этих исследований были разработаны оригинальные подходы к построению баз данных этого типа. Рассмотрим два из них, которые могут быть использованы при разработке и создании подобных баз данных. Первый из них связан регистрацией основного объекта базы данных - водяного знака, содержащегося в некоторой средневековой рукописи, первопечатной книге или другом историко-архивном документе. Второй подход касается вопросов классификации и описания типов водяных знаков с обеспечением многоязыковой поддержки.
Для регистрации водяного знака предлагается использовать вспомогательное поле данных алфавитно-цифрового типа (STRING), значение которого генерируется прикладным математическим обеспечением и содержит следующие данные:
- Код страны, в которой хранится источник, содержащий данный водяной знак;
- Код хранилища, в котором хранится источник, содержащий данный водяной знак;
- Код источника, содержащего данный водяной знак;
- Номер страницы источника, содержащей данный водяной знак.
Структура регистрационного номера может быть схематически представлена следующим образом:
<^ Код страны> <Код хранилища> <-> <Код источника> <_> <Номер страницы>.
Угловые скобки показаны здесь только в качестве разделителей полей и не используются при формировании самого номера. Символы “-” и “_” используются при формировании регистрационного номера. В качестве каждого из указанных выше кодов за исключением кода страны обычно используются цифровые коды. В качестве кода страны используется двухбуквенные сокращения названия стран, принятые в сети Интернет. Код хранилища генерируется программно или задается пользователем в виде четырехзначного числа уникального для каждой страны. В качестве кода источника обычно используется инвентарный, каталожный, регистрационный номер или некий другой идентификатор, который используется в каждом конкретном хранилище для однозначной идентификации хранящихся в них средневековых рукописей, первопечатных книг и других историко-архивных документов. Рассмотрим пример генерации регистрационного номера для водяного знака со страницы 194 манускрипта, хранящегося под инвентарным номером 1947 в хранилище, которому присвоен код 2000, и находящему в России. В соответствии с данным правилом ему будет присвоен регистрационный номер: RU2000 1947_107. Очевидно, что пользователь системы, знающий, что в России код 2000 присвоен Государственному историческому музею, уже из регистрационного номера имеет некоторую информацию об источнике, содержащем данный водяной знак.
Каждый из указанных кодов хранится в таблицах базы данных, обеспечивая необходимыми связями соответствующие им названия и описания стран, хранилищ и источников на всех поддерживаемых языках. Сокращенные названия стран, хранилищ и источников обычно используются в качестве тезаурусов при вводе и регистрации новых водяных знаков в базу данных. При регистрации водяного знака, страна, хранилище или источник которого еще не введены в базу данных, пользователь использует специальные интерфейсные формы для ввода и/или генерации необходимых данных. При этом формирование необходимых кодов обычно осуществляется системой автоматически. Генерируемые таким способом коды и сам регистрационный номер водяного знака являются практически независимыми от языка и на их основе обеспечиваются все необходимые связи в базе данных, требуемые для многоязыковой поддержки данных. Аналогичный подход используется для формирования регистрационных номеров водяных знаков, опубликованных в различных стандартных каталогах1,2. Сформированные таким методом регистрационные номера позволяют опытному пользователю однозначно определить место хранения водяного знака с заданным регистрационным номером даже без формирования запроса к базе данных.
Второй подход разработан для решения вопросов классификации и описания типов водяных знаков в базах данных с многоязыковой поддержкой. В настоящее время для классификации и словесного описания типов водяных знаков обычно используется иерархический метод, при котором первоначально определяется некоторый набор базовых типов (мотивов) водяных знаков. При необходимости в каждом из этих базовых типов могут быть определены дополнительные, уточняющие типы (подтипы), каждый из которых в свою очередь также может иметь свои дополнительные, уточняющие типы (подтипы) и т.д. Анализ существующих способов классификации и описания типов водяных знаков по этому методу показал, что количество соподчиненных уровней описания типов (подтипов) не превышает четырех. Поэтому для представления в базе данных каждого базового и соподчиненных типов/подтипов в виде, обеспечивающем многоязыковую поддержку, был предложен одиннадцатиразрядный цифровой код. Код содержит три первых разряда для регистрации мотива водяного знака и четыре пары последующих разрядов для кодов четырех соподчиненных типов/подтипов. Емкость этого кода достаточна для регистрации до 999 основных мотивов водяных знаков и до 100 подтипов водяных знаков в каждом из четырех возможных соподчиненных уровней. Генерация и поддержка кода также осуществляется программными средствами. Таким образом, все водяные знаки данного типа/подтипа, зарегистрированные в базе данных будут иметь один и тот же классификационный код вне зависимости от используемого языка.
Аналогичный подход может быть использован и для других полей данных, зависящих от используемого языка. Поэтому все определенные для данного водяного знака и данного классификационного кода взаимосвязи с другими зарегистрированными водяными знаками сохранятся при изменении языка, обеспечивая логическую целостность данных. При изменении используемого языка данных будет изменяться только словесное описание данного водяного знака.
^
4Прикладное программное обеспечение
Разработка и создание баз данных обычно не является конечной целью. Базы данных все чаще начинают играть роль одной из составных частей сложных интегрированных информационно-аналитических систем. Выполнение многих исторических исследований, проводимых с использованием баз данных, таких как датирование средневековых рукописей и классификация водяных знаков требуют интенсивного использования большинства хранящихся в базах данных информационных материалов. Эффективное решение этих задач может быть достигнуто путем разработки специальных цифровых технологий и создания прикладных программных средств архивирования, хранения, обработки и анализа данных, причем создаваемые технологии и программные средства должны обеспечивать многоязыковую поддержку и телекоммуникационный доступ к базам данных.
Проектирование, разработка, создание и сопровождение баз данных обычно осуществляется с помощью программных средств разработки и администрирования, входящих в комплект поставки математического обеспечения СУБД, под управлением которой функционирует база данных. Для разработки прикладного математического обеспечения наряду с этими средствами разработки широко использоваться средства разработки математического обеспечения общего назначения, среди которых большое распространение получили средства быстрой разработки приложений фирмы Borland: Delphi и Borland C++ Builder. Их неоспоримое достоинство определяется тем, что они включают в себя чрезвычайно большое количество компонентов, специально предназначенных для разработки сетевых приложений и программных средств работы с базами данных.
Разработка прикладного математического обеспечения для наполнения, поддержки и работы с базой данных, представленной в предыдущем разделе, была выполнена с помощью средства быстрой разработки приложений Borland C++ Builder. Это позволило реализовать все необходимые программные средства в рамках единой интегрированной системы цифровой обработки водяных знаков и средств работы с ней конечных пользователей9. Система реализована на платформе PC и работает под операционной системой Windows 9*/NT/2000/XP или выше. Взаимодействие пользователя с разработанной системой осуществляется через графический интерфейс пользователя, содержащий широкий набор интерфейсных форм, меню, управляющих кнопок и других средств. Графический интерфейс пользователя разработан в Windows-стиле. Многоязыковая поддержка графического интерфейса пользователя не вызывает больших проблем с реализацией поскольку зависящим от используемого языка практически являются только информационные метки, сообщения и диалоги, количество которых ограничено и постоянно. При изменении языка просто осуществляется этих переключение на соответствующую языковую версию.
Главная интерфейсная форма разработанной системы представлена на Рис.1. В качестве примера ее использования показаны только две открытые графические интерфейсные формы: в левой части форма с изображением обрабатываемого водяного знака, а справа форма, используемая для классификации водяных знаков и генерации соответствующих им кодов. Классификация водяных знаков и генерация их кода осуществляется на основе использования иерархической (древовидной) структуры всех основных и дополнительных типов (подтипов) водяных знаков. Пользователь только указывает положение данного конкретного типа водяного знака в некотором узле древовидного классификатора, определяя тем самым его принадлежность к тому или иному типу/подтипу. После этого вся дальнейшая процедура генерации и поддержки кода для данного водяного знака осуществляется системой автоматически.
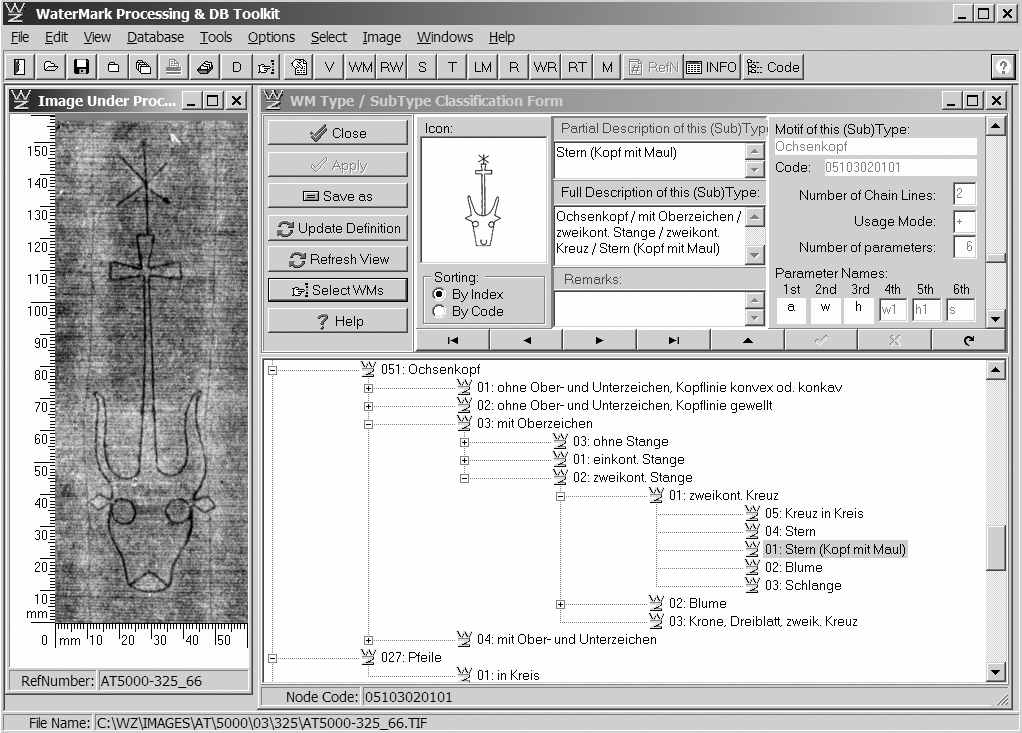 |
| Рис.1 Главная интерфейсная форма разработанной системы. |
Благодарности
Работа частично поддержана ИНТАС в рамках проекта INTAS 00 00081 и Российским фондом фундаментальных исследований в рамках проекта РФФИ 01 07 90354.
Литература
- Briquet Ch. M., Les Filigranes. Dictionnaire historique des marques du papier dés leur apparition vers 1282 jusqu’en 1600. Paris 1907.
- Piccard G., Die Wasserzeichenkartei Piccard im Hauptstaatsarchiv Stuttgart. Findbuch I-XV, W. Kohlhammer, Stuttgart, 1966 1987.
- Rauber C., Tschudin P., Startchik S., Pun T., Archival and retrieval of historical watermarks. ICIP 1996 International conference on image processing, Lausanne. IEEE, 1996.
- Haidinger A., Wenger E., Stieglecker M., Karnaukhov V. Wasserzeichen Klosterneuburger Handschriften. Gazette du livre medieval, No. 32, 1998, pp. 8 13.
- E.Wenger, V.Karnaukhov, A.Haidinger, M.Stieglecker. A Digital Image Processing and Database System for Watermarks in Medieval Manuscripts. In: David Bearman and Franca Garzotto, editors, ICHIM ' 01 Proceedings, Cultural Heritage and Technologies in the Third Millennium, Milano, Italy, 2001, pp. 259 264.
- van Thienen G. A date for the Freeska Landriucht press (1484-7) from paper evidence, with a note on the Codex Roorda, in : Incunabula, Studies in fifteenth-century printed books presented to Lotte Hellinga, ed. by Martin Davies, London, 1999 ,pp. 141 167.
- Incunabula printed in the Low Countries, A Census, ed. by G. van Thienen & J.Goldfinch, Nieuwkoop, 1999. 636pp.
- Карнаухов В.Н., Мерзляков Н.С., Венгер Е., Хайдингер А. и Лакнер Ф., Цифровой анализ водяных знаков средневековых рукописей. Компьютерная оптика, вып. 14 15, 1995, сс. 11 24.
- V.N.Karnaukhov, E.Wenger, A.Haidinger, N.S.Merzlyakov, Y.J. Zhang. An Integrated System for Digital Processing and Identification of Watermark Images. First International Conference on Image and Graphics, August 16-18, Tianjin, China, 2000, p. 119 122.