
М. Н. Машкин Информационные технологии Учебное пособие
| Вид материала | Учебное пособие |
Содержание23Информационные хранилища. 23.1Особенности построения информационных хранилищ 23.2Определение и типовые архитектуры хранилищ данных |
- О. В. Шатунова информационные технологии учебное пособие, 1418.45kb.
- Информационные технологии управления, 3933.39kb.
- Учебное пособие Санкт-Петербург 2007 удк алексеева С. Ф., Большаков В. И. Информационные, 1372.56kb.
- С помощью программы Autocad учебное пособие Для студентов вузов Вдвух частях, 1127.91kb.
- Учебное пособие Томск 2006 Чайковский Д. В. Информационные технологии управления. Учебное, 1860.35kb.
- Учебное пособие Под общей редакцией доктора технических наук, профессора Н. А. Селезневой, 1419.51kb.
- Учебное пособие для учащихся педагогических специальностей вузов и слушателей курсов, 2543.24kb.
- В. П. Дьяконов, А. Н. Черничин Новые информационные технологии Часть Основы и аппаратное, 2695.36kb.
- Учебный мультимедийный комплекс «Основы физической культуры в вузе» (Электронное учебное, 5127.54kb.
- Название Предмет Направление, 921.62kb.
23Информационные хранилища.
Огромные массивы данных можно хранить на одном или нескольких серверах. Если они расположены в сетях типа Интернет, то их называют информационными хранилищами (базами обобщённых данных). Это могут быть сети хранения данных, которые формируются из множества различных внешних и внутренних источников. В любом случае это базы и банки данных, функционирующие, как правило, под управлением распределённых СУБД.
Для сохранности электронных информационных ресурсов применяют специальные сети хранения данных, получившие название Storage Area Network (SAN), а в корпоративных сетях – специализированные Network Attached Storage (NAS-серверы), которые осуществляют совместимость, интеграцию и администрирование серверов общего назначения, а также хранение огромных массивов данных. В качестве информационных хранилищ в них используют RAID-массивы, CD и DVD библиотеки.
Возможность современных СУБД организовывать накопление и оперативную обработку больших объёмов информации способствовала развитию аналитических систем прогнозирования, идентификации объектов и состояний, оценки и выбора альтернативных решений и др., например, систем поддержки принятия решений.
23.1Особенности построения информационных хранилищ2
В основе концепции хранилища данных лежат две основные идеи: интеграция разъединенных детализированных данных (описывающих некоторые конкретные факты, свойства, события и т.д.) в едином хранилище и разделение наборов данных и приложений, используемых для обработки и анализа.
В начале 80-х годов, в период бурного развития регистрирующих информационных систем, появилось осознание ограниченности их применения для анализа данных и построения систем поддержки и принятия решений. Регистрирующие системы создавались для автоматизации рутинных операций: выписки счетов, оформления договоров, проверки состояния склада и т.д., и предназначались для линейного персонала. Основными требованиями к таким системам были обеспечение транзакционности вносимых изменений и максимизация скорости, что и определило тогда выбор реляционных СУБД и модели представления данных «сущность-связь» в качестве основных технических решений при построении регистрирующих систем.
Для менеджеров и аналитиков в свою очередь требовались системы, которые бы позволяли: анализировать информацию во временном аспекте, формировать произвольные запросы к системе, обрабатывать большие объемы данных, интегрировать данные из различных регистрирующих систем. Очевидно, что регистрирующие системы не удовлетворяли ни одному из этих требований — информация в такой системе актуальна только на момент обращения к базе данных, а в следующий момент времени по тому же запросу можно получить совершенно другой результат. Интерфейс регистрирующих систем рассчитан на проведение жестко определенных операций и возможности получения результатов на нерегламентированный (ad-hoc) запрос сильно ограничены. Возможности обработки больших массивов данных также были невелики из-за настройки СУБД на выполнение коротких транзакций.
Ответом на возникшую потребность стало появление технологии хранилищ данных.
23.2Определение и типовые архитектуры хранилищ данных
Определение понятия «хранилище данных» первым дал Уильям Инмон в своей монографии — это «предметно-ориентированная, интегрированная, содержащая исторические данные, неразрушаемая совокупность данных, предназначенная для поддержки принятия управленческих решений».
Концептуально модель хранилища данных можно представить в виде схемы, см.рис. 28.1. Данные из различных источников помещаются в хранилище, а их описания — в репозиторий метаданных. Конечный пользователь, используя различные инструменты (средства визуализации, построения отчетов, статистической обработки и т.д.) и содержимое репозитория анализирует данные в хранилище. Результатом является информация в виде готовых отчетов, найденных скрытых закономерностей, каких-либо прогнозов. Так как средства работы конечного пользователя с хранилищем данных могут быть самыми разнообразными, то теоретически их выбор не должен влиять на структуру хранилища и функции его поддержания в актуальном состоянии. Физическая реализация данной концептуальной схемы может быть самой разнообразной.
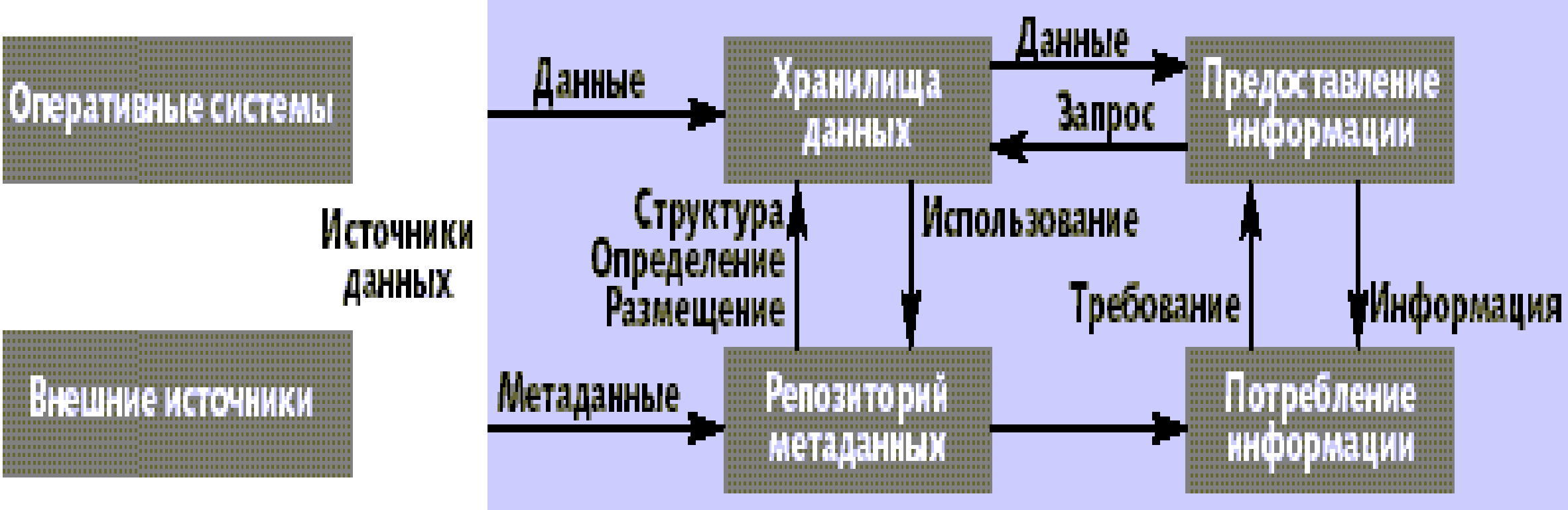
Рис. 28.1. Концептуальная модель хранилища данных
Виртуальное хранилище данных — это система, предоставляющая интерфейсы и методы доступа к регистрирующей системе, которые эмулируют работу с данными в этой системе, как с хранилищем данных. Виртуальное хранилище данных можно организовать, создав ряд «представлений» (view) в базе данных, либо применив специальные средства доступа, например, продукты класса Desktop OLAP, к которым относятся, в частности, Business Objects, Brio Enterprise и другие [12]. Главными достоинствами такого подхода являются простота и малая стоимость реализации, единая платформа с источником информации, отсутствие сетевых соединений между источником информации и хранилищем данных.
Однако недостатков гораздо больше. Создавая виртуальное хранилище данных создается не хранилище как таковое, а иллюзия его существования. Структура хранения и само хранение не претерпевают изменений, и остаются проблемы: производительности, трансформации данных, интеграции данных с другими источниками, отсутствие истории, чистоты данных, зависимость от доступности и структуры основной базы данных.
Двухуровневая архитектура хранилища данных подразумевает построение витрин данных (data mart) без создания центрального хранилища, при этом информация поступает из регистрирующих систем и ограничена конкретной предметной областью. При построении витрин используются основные принципы построения хранилищ данных, поэтому их можно считать хранилищами данных в миниатюре. Плюсы: простота и малая стоимость реализации; высокая производительность за счет физического разделения регистрирующих и аналитических систем, выделения загрузки и трансформации данных в отдельный процесс, оптимизированной под анализ структурой хранения данных; поддержка истории; возможность добавления метаданных.
Построение полноценного корпоративного хранилища данных обычно выполняется в трехуровневой архитектуре. На первом уровне расположены разнообразные источники данных — внутренние регистрирующие системы, справочные системы, внешние источники (данные информационных агентств, макроэкономические показатели). Второй уровень содержит центральное хранилище, куда стекается информация от всех источников с первого уровня, и, возможно, оперативный склад данных, который не содержит исторических данных и выполняет две основные функции. Во-первых, он является источником аналитической информации для оперативного управления и, во-вторых, здесь подготавливаются данные для последующей загрузки в центральное хранилище. Под подготовкой данных понимают их преобразование и проведение определенных проверок. Наличие оперативного склада данных просто необходимо при различном регламенте поступления информации из источников. Третий уровень представляет собой набор предметно-ориентированных витрин данных, источником информации для которых является центральное хранилище данных. Именно с витринами данных и работает большинство конечных пользователей.
Хранилища строятся на основе многомерной модели данных, подразумевающей выделение отдельных измерений (время, география, клиент, счет) и фактов (объем продаж, доход, количество товара) с их анализом по выбранным измерениям. Многомерная модель данных физически может быть реализована как в многомерных, так и в реляционных СУБД. В последнем случае она выполняется по схеме «звезда» или «снежинка». Данные схемы предполагают выделение таблиц фактов и таблиц измерений. Каждая таблица фактов содержит детальные данные и внешние ключи на таблицы измерений.