
Ы, включают методы обработки данных многих ранее существовавших автоматизированных систем (АС), с другой обладают спецификой в организации и обработке данных
| Вид материала | Документы |
- Методы анализа данных, 17.8kb.
- Методика определения актуальных угроз безопасности персональных данных при их обработке, 175.98kb.
- Понятия о базах данных и системах управления ими. Классификация баз данных. Основные, 222.31kb.
- Анализ и оценка дисциплин обслуживания требований (запросов) с учетом их приоритетов, 20.53kb.
- Программа дисциплины «Методы обработки экспериментальных данных», 318.77kb.
- «Прикладная информатика (по областям)», 1362.72kb.
- Методические указания к курсовому проектированию по курсу "Базы данных" Составитель:, 602.97kb.
- Концепция баз данных уже давно стала определяющим фактором при создании эффективных, 293.58kb.
- Доклад Тема: «Информационные технологии», 58.36kb.
- Рабочей программы дисциплины Структуры и алгоритмы обработки данных по направлению, 21.62kb.
3.4. Базовые модели данных, используемые в ГИС
Инфологическая модель
Инфологическая модель занимает особое положение по отношению к другим моделям. Она соответствует четвертому этапу построения сложной системы и дает формализованное описание проблемной области независимо от структур данных. Инфологическая область моделирования данных охватывает естественные для человека концепции отображения реального мира.
Создание этой модели является первым шагом процесса формализации. В отличие от представления на естественном языке она в основном исключает неоднозначность за счет использования средств формальной логики.
Одно из главных понятий инфологической модели - объект. Это понятие связано с событиями: возникновение, исчезновение и изменение. Объекты могут быть атомарными или составными.
Атомарный объект - это объект определенного типа, дальнейшее разложение которого на более мелкие объекты внутри данного типа невозможно.
Составные объекты включают в себя множества объектов, кортежи объектов. Применяя это определение, рекурсивно можно получить произвольную структуру составных объектов.
Обычно объект имеет некоторое свойство или взаимосвязь (связь) с Другими объектами. Свойство может быть не определено формально, а лишь охарактеризовано как некоторое утверждение по поводу множества объектов.
Инфологическая модель позволяет выделить три категории фактов: истинные, значимые и ложные, С одной стороны, это обеспечивает модели дополнительную гибкость, с другой - создает определенные сложности.
Различия между традиционными и инфологическими моделями данных аналогичны различию между мнением и истиной. Во многих моделях большинство сообщений относится к одной из двух категорий: истинные или ложные. Инфологическая модель предполагает возможность представления любого сообщения с какой-то долей вероятности, т.е. в виде аналога мнения. Анализ такого сообщения возможен при учете конкретного контекста. В правильном контексте сообщение истинно. Но и ошибочное утверждение может рассматриваться как мнение.
Цель инфологического моделирования - формализация объектов реального мира предметной области и методов обработки информации в соответствии с поставленными задачами обработки и требованиями представления данных естественными для человека способами сбора и представления информации.
Инфологические модели позволяют получать произвольные представления простых событий. На их основе могут быть сконструированы также типы моделей, подобные поддерживаемым сильно типизированными моделями.
В таких моделях ссылки на объекты и сами объекты разделены, а сообщения интерпретируются с учетом контекста. Это позволяет реализовать множественность ссылок и обеспечить разнообразие интерпретации.
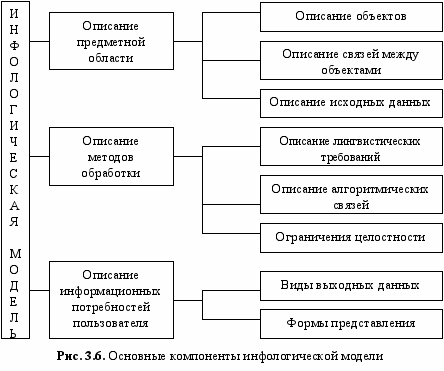
Инфологическая модель может включать в себя ряд компонентов (рис. 3.6). Принципиальной особенностью этой модели является возможность отображения как формализуемых средствами формальной логики процессов и объектов, так и неформализуемых в дальнейшем процессов. Основными компонентами инфологической модели являются:
- описание предметной области;
- описание методов обработки;
- описание информационных потребностей пользователя.
Инфологическая модель носит описательный характер. В силу некоторой произвольности форм описания в настоящее время не существует общепринятых способов ее построения. Используют аналитические методы, методы графического описания, системный подход.
Иерархическая модель
К наиболее простым структурно определенным относится иерархическая модель. В этой модели данных связи между ее частями являются жесткими, а ее структурная диаграмма должна быть упорядоченным деревом.
Одно из важных понятий для этой модели - уровень. Для описания разных уровней применяют понятия: корень, ствол, ветви, листья и лес, что подчеркивает сходство структуры модели со структурой дерева.
Граф иерархической модели (ее схемное представление) включает AM типа элементов: дуги и узлы (или записи).
Дуги соединяют разные узлы между собой. Дуги, соответствующие функциональным связям, должны быть всегда направлены от корня в листья дерева, т.е. они являются ориентированным графом. Такая структурная схема называется иерархическим деревом определения или деревом определения [17].
Дуга дерева определения, соответствующая функциональному типу связи, называется связью исходный - порожденный. Между двумя типами записей в иерархической модели может быть не более одной такой связи. Дуга исходит из типа родительской (порождающей) записи и заходит в тип дочерней (порожденной ) записи.
В простейшем случае иерархическая модель представляет собой описание процесса или системы, состоящей из совокупности уровней, связанных одной дугой (рис. 3.7).

Рассматривая последовательность связей "исходный - порожденный", можно естественным образом идентифицировать типы родительской и порожденной записей.
Первую порождающую запись называют корневой (реже стволом), промежуточные записи - ветвями, записи самого нижнего уровня иерархической модели - листьями.
Понятия корневой, ствол, ветви, листья определяют тип записи в иерархической модели.
Иерархический путь, или маршрутизация, - это последовательность типов записей, начинающаяся с типа корневой записи, в которой типы записей выступают переменно в ролях исходного и порожденного.
Известная программистам последовательность "диск- корневой каталог - подкаталог - программа" - характерный пример иерархической модели.
Уровень типа записи относительно типа корневой записи определяется как длина пути от корневой записи, выраженная в числе дуг. Так, тип корневой записи "диск" находится на нулевом уровне, ”корневой каталог” - на первом, ”подкаталог” - на втором, имя файла - на третьем и т.д.
Расширение дерева определения иерархической модели может быть отражено в виде таблиц для записей, а расширение каждой связи "исходный - порожденный" - множеством соединений между таблицами.
Альтернативным способом представления расширения дерева определения является "лес", или совокупность отдельных деревьев, состоящих из одной корневой записи и всех ее зависимых записей. Такое дерево называется деревом базы данных. Оно конструируется в соответствии с деревом определения. Иногда структуру иерархической модели называют Е-деревом (см. рис. (3.2,3.6).
Иерархическим моделям данных присущи два внутренних ограничения. Первое ограничение - все типы связей должны быть функциональными, второе - структура связей должна быть древовидной. Следствием этих ограничений является необходимость соответствующей С1рук1уризации данных. В силу функциональности связей запись может иметь не более одной исходной записи любого типа, т.е. связь должна иметь жесткий вид -1 : п (один ко многим). Очевидный недостаток иерархических моделей - снижение времени доступа при большом числе уровней, поэтому в ГИС не используют модели при большом числе уровней (более 10). В то же время иерархические модели довольно устойчиво применяются для составления различного рода классификаторов.
Квадратомическое дерево
Иерархическая структура данных, известная как квадратомическое дерево, используется для накопления и хранения географической информации. В этой структуре двухмерная геометрическая область рекурсивно подразделяется на квадраты, что определило название данной модели.
На рис. 3.8 показан фрагмент двухмерной области QT, состоящей из 16 пикселей. Каждый пиксель обозначен цифрой. Вся область разбивается на четыре квадранта: А, В, С, D. Каждый из четырех квадрантов является узлом квадратомического дерева. Большой квадрант QT становится узлом более высокого иерархического уровня квадратомического дерева, а меньшие квадранты появляются на более низких уровнях.
Технология построения квадратомического дерева основана на рекурсивном разделении квадрата на квадранты и подквадранты до тех пор, пока все подквадранты не станут однородными по отношению к значению изображения (цвета) или пока не будет достигнут предопределенный заранее наименьший уровень разрешения.
Если регион состоит из 2n х 2n пикселей, то он полностью представлен на уровне n, а единичные пиксели находятся на нулевом уровне. Квадрант уровня 1 (0<1
На рис. 3.9 показано квадратомическое дерево, построенное по данным рис. 3.8. Как видно, эта структура являет собой классический пример Е-дерева. Преимущество такой структуры состоит в том, что регулярное разделение обеспечивает накопление, восстановление иобработку данных простым и эффективным способом. Простота проистекает из геометрической регулярности разбиения, а эффективность достигается за счет хранения только узлов с данными, которые представляют интерес.
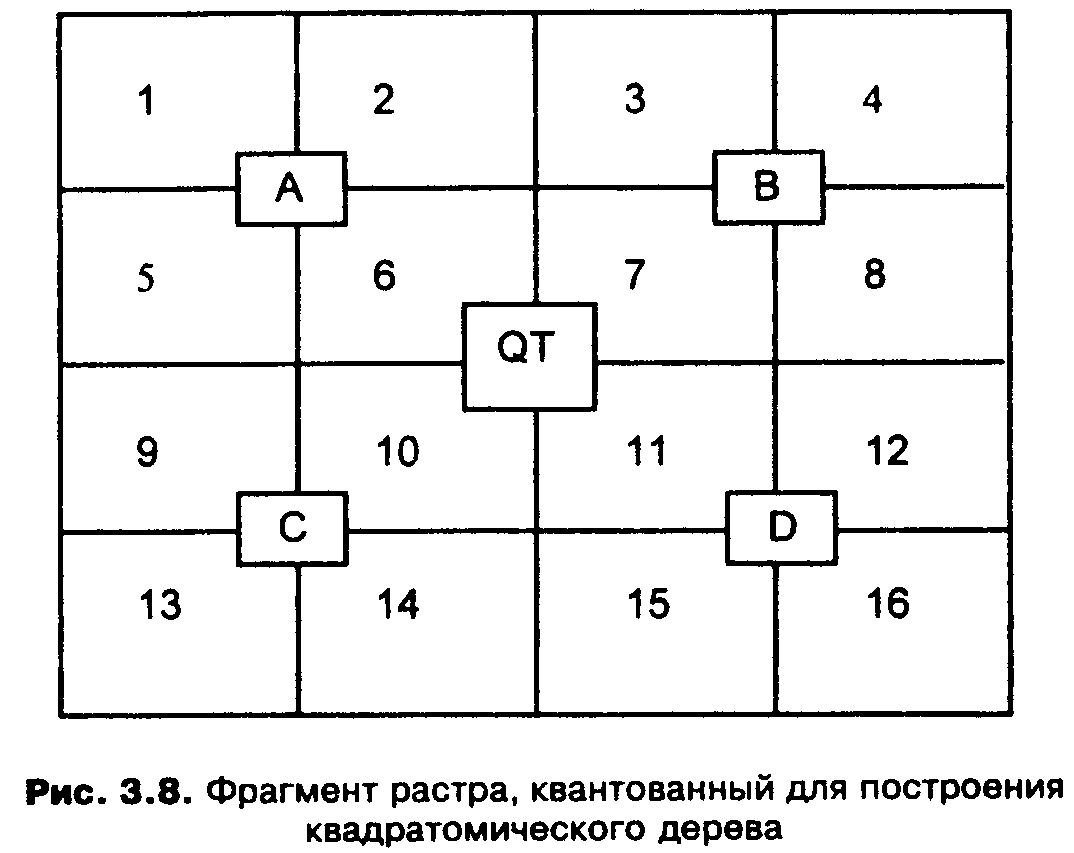
Рис. 3.8. Фрагмент растра, квантованный для построения квадратомического дерева
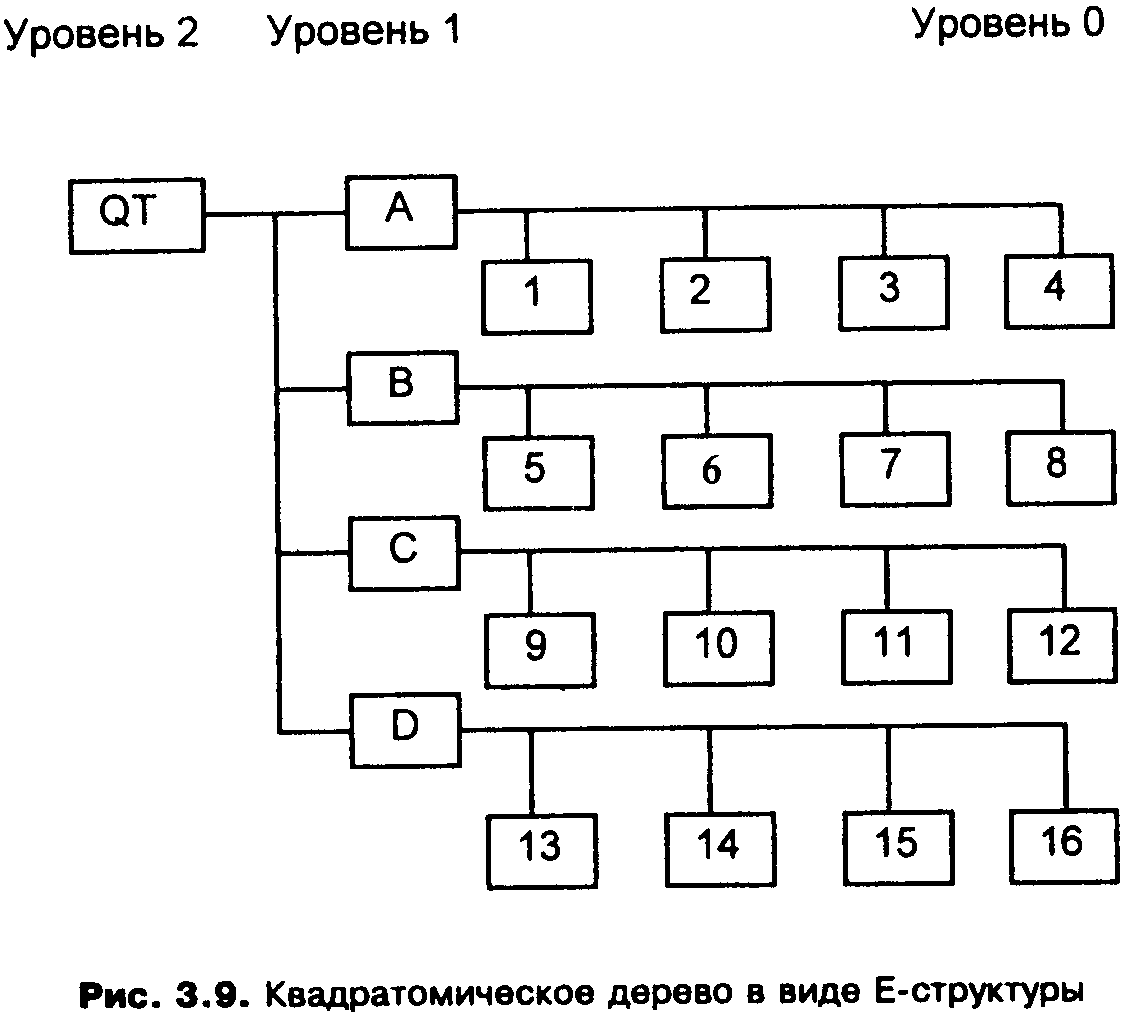
Рис. 3.9. Квадратомическое дерево в виде Е-структуры
Поскольку квадратомическое дерево известно как пространственно-рациональный способ представления сгруппированных однородных ми сопряженных изображений, их преимущество над векторной репрезентацией многих (но не всех) пространственных алгоритмов относительно затрат машинного времени весьма существенно.
Первоначально большинство приложений моделей квадратомических деревьев было сделано для обработки изображений. Из этой области данная модель была перенесена в ГИС.
Модели, основанные на квадратомических деревьях, обеспечивают расчеты площадей, центроидные определения, распознавание образов, выявление связанных компонентов, определение соседства, преобразование расстояний, разделение изображений, сглаживание данных и усиление краевых эффектов. Вследствие этого появилась возможность использовать квадратомические деревья для хранения географических данных. Однако при этом требуется развитие процедур для превращения растровых данных в формат квадратомического дерева и усовершенствование техники линейного кодирования.
В первых работах по квадратомическим деревьям связи между квадрантом и подквадрантом давались в виде дерева со степенью ветвления, равной четырем. В такой структуре связи между родительским и дочерним уровнем определяются системой внешних указателей.
Все узловые точки дерева, за исключением корневой, имеют одного родителя. В то же время все они, за исключением листьев, связаны с четырьмя дочерними узловыми точками.
Преимущество представления, основанного на указателях, заключается в том, что оно выражает только значимую часть полного квадратомического дерева.
Последние исследования показали, что для больших квадратомических деревьев наиболее подходящей структурой является линейное квадродерево. В нем каждый листовой узел представлен линейным числовым кодом, который базируется на упорядоченном списке узловых точек прародителей. Последующее преобразование дерева в код достигается использованием битового уровня или модулярной арифметики. Система линейных кодов обеспечивает эффективную связь между структурами пространственных данных и алгоритмами, применяемыми в вычислительной геометрии для решения проблем восстановления прямоугольников и определения ближайшего "соседа".
Рядом исследователей была рассмотрена возможность использования искусственного интеллекта для совершенствования очень больших географических информационных систем, основанных на квадратоми-ческих деревьях.
Иерархические модели, как и прочие, могут описывать системы, данные и схемы процессов обработки данных. Следует, однако, подчеркнуть, что правильно составленная иерархическая схема должна содержать в качестве записей ( вершин) атрибуты или агрегаты атрибутов либо типы сущностей. Атрибуты или агрегаты атрибутов соответствуют множествам или расширенным множествам. Дуги могут использоваться для представления агрегации двух атрибутов в тип сущности или двух типов сущности в тип связи. На практике часто в запись вставляют не только сущности базы данных, но и связи. Такая схема описывается моделью "сущность-связь" и будет рассмотрена ниже.
Анализ иерархических моделей (связей между их частями) с "неправильным" описанием необходимо проводить, выделяя типы сущностей.
Реляционная модель
В современных информационных системах и базах данных наиболее широко представлены реляционные модели (РМ).
Реляционная модель данных, разработанная Коддом еще в 1969-1970 гг. на основе математической теории отношений, опирается на систему понятий, важнейшие из которых - таблица, отношение, строка, столбец, первичный ключ, внешний ключ, домен (domain). Доменом называется совокупность значений, не повторяющихся в одном столбце. Такая модель положена в основу так называемых электронных таблиц -специализированных баз данных.
Сущности, атрибуты и связи хранятся в таблицах как данные определенной структуры. Структура данных обусловливается используемыми моделями данных.
Таблица состоит из строк и столбцов и имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка - конкретный объект.
Основным средством структурирования данных в реляционной модели является отношение (relation). Понятия отношения в реляционной модели и математике близки, хотя и не совпадают. Можно определить отношение как декартово произведение доменов. Поясним связь перечисленных выше понятий между собой. Таблица имеет столбцы и записи (строки). Каждая запись имеет набор атрибутов. Записи каждого типа образуют таблицу или отношение. Каждая строка - это запись или кортеж. Каждый столбец - это атрибут. Диапазон допустимых значений (домен) определяется для каждого атрибута. Степень отношения - число атрибутов в таблице: один атрибут - унарное отношение, два атрибута - бинарное отношение, n атрибутов — n-арное отношение.
Ключ отношения - это подмножество атрибутов, имеющее следующие свойства:
- уникальную идентификацию;
- неизбыточность;
- ни один из атрибутов ключа нельзя удалить, не нарушив его уникальности.
Первичный атрибут отношения - это атрибут, присутствующий по крайней мере в одном ключе, все другие атрибуты непервичные.
В реляционной модели данных схема отношения может быть использована для представления типа сущности.
Реляционная модель является табличной моделью, некоторые типы связей между отношениями могут представляться в схеме неявно. В этих моделях не предусматривается поддержание логической упорядоченности, однако кортежи помещаются в физическую память в соответствии с некоторым порядком. Физическая упорядоченность используется для выборки.
Рассмотренная выше иерархическая модель данных может быть сведена к реляционной с помощью "нормализации" - пошагового процесса приведения к табличной форме с полным сохранением информации. Рассмотрим пример реляционной модели. Таблица "Сотрудник" (рис. 3.10, а) содержит сведения о сотрудниках, работающих в организации, а ее строки являются наборами значений атрибутов. Каждый столбец таблицы - это совокупность значений конкретного атрибута объекта. Например, столбец "Специальность" содержит множество значений специальностей, столбец "Стаж" - целые неотрицательные числа.
| Код | Ф.И.О | Специальность | Стаж | Название отдела |
| 137 | Иванов И. И. | Физик | 10 | Экспериментальный |
| 139 | Иванов А.П. | Экономист- | 9 | Технологический |
| 143 | Петров А. Г. | Математик | 12 | Теоретический |
| 147 | Рыбкин И.И. | Математик | 11 | Экспериментальный |
| 149 | Слонов К. И. | Физик | 5 | Экспериментальный |
| 151 | Семин П.П. | Экономист | 10 | Теоретический |
| 155 | Трунов К.А. | Физик | 11 | Технологический |
| 156 | Теркин П.И. | Физик | 14 | Экспериментальный |
а
| Название отдела | Код отдела | Численность |
| Технологический Теоретический Экспериментальный | 007 Oil 008 | 8 12 20 |
б
Рис. 3.10. Реляционная модель: а - "Сотрудник" ; б - "Отдел"
Значения в столбце "Специальность" выбираются из множества имен всех возможных специальностей данной организации. В нем принципиально невозможно появление значения, которого нет в соответствующем домене, например "15" или "с.н.с".
Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы. Оно должно быть уникальным в таблице, однако различные таблицы могут иметь столбцы с одинаковыми именами. Любая таблица должна иметь по крайней мере один столбец. Столбцы расположены в таблице в соответствии с порядком следования их имен при се создании. В отличие от столбцов строки не имеют имен, порядок их следования в таблице не определен, а количество логически не ограничено.
Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции - среди них не существует "первой", "второй", "последней". Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключам (primary key).
В таблице "Сотрудник" первичный ключ - это столбец "код". В нашем примере каждый сотрудник имеет единственный номер (код), по которому из таблицы извлекается необходимая информация. Следовательно, в этой таблице первичный ключ - это столбец "код". В нем значения не могут дублироваться - в таблице "Сотрудник" не должно быть строк, имеющих одно и то же значение в столбце "код".
Взаимосвязь таблиц - важнейший элемент реляционной модели данных. Она поддерживается внешними ключами (foreign key).
Рассмотрим пример, в котором база данных хранит информацию о сотрудниках (таблица "Сотрудник") и отделах (таблица "Отдел") в некоторой организации. Первичный ключ таблицы "Отдел" (рис. 3.10,6)-столбец "Название отдела". Столбец "Численность" не может выполнять роль первичного ключа, так как в одной организации могут существовать несколько отделов с одинаковой численностью.
Любой сотрудник работает в одном отделе, что должно быть отражено в базе данных. Таблица "Сотрудник" содержит столбец "Название отдела" и значения в этом столбце выбираются из столбца "Название отдела" таблицы "Отдел". Столбец "Название отдела" является внешним ключом в таблице "Сотрудник".
Для обработки данных, размещенных в таблицах, нужны дополнительные данные о данных, например описатели таблиц, столбцов и т.д. Их называют обычно метаданными. Метаданные также представлены в табличной форме и хранятся в словаре данных (data dictionary).
Помимо таблиц в ГИС могут храниться и другие объекты, такие, как экранные формы, отчеты (reports), представления (views) и даже прикладные программы, работающие с информацией, размещенной в реляционной модели.
Данные информационной системы должны быть однозначными и непротиворечивыми. В таком случае говорят, что реляционная модель удовлетворяет условию целостности (integrity). При этом на реляционную модель накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints).
Существует несколько типов ограничений целостности. Например, требуется, чтобы значения в столбце таблицы выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, в частности, целостность по ссылкам (reference integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице.
Модель "сущность-связь"
Модель данных "сущность-связь" или ER-модель (Entity Relationship Model) дает представление о предметной области в виде объектов, называемых сущностями, между которыми фиксируются связи.
Для каждой связи определено число связываемых ею объектов. На схеме сущности изображаются прямоугольниками, связи - ромбами. Число связываемых объектов указывается цифрой на линии соединения объекта и связи.
Появление моделей данных типа "сущность-связь" было обусловлено практическими потребностями проектирования баз данных для коммерческих СУБД. Такие модели имеют много общего с иерархическими и сетевыми моделями данных.
Теоретической основой этого подхода является известная модель, введенная М. Ченом в 1976 г. и получившая широкое распространение в качестве средств концептуального проектирования баз данных.
В основе модели Чена лежит представление о том, что предметная область состоит из отдельных объектов, находящихся друг с другом в определенных связях. Объекты описываются различными параметрами или атрибутами; однотипные объекты описываются одним и тем же набором параметров и объединяются во множества или классы (сущности). Конкретные объекты, составляющие класс, называют экземплярами соответствующей сущности. Между сущностями идентифицируются взаимосвязи различного вида: один к одному, один ко многим и др.
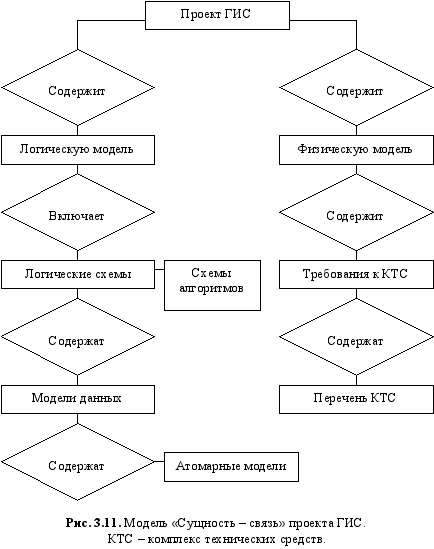
На рис. 3.11 приведена схема проектирования геоинформационной системы, построенная на основе модели "сущность-связь". В силу своей ориентации на процесс проектирования ER-модели могут рассматриваться как обобщение и развитие иерархических и сетевых моделей.
Это, в частности, означает, что допускаются явная спецификация ограничений целостности и непосредственное представление связей типа "один к одному" (1:1), "один ко многим" (1: М) , "многие к одному" (М : 1) "многие ко многим" (М : N).
При построении ER-моделей важно учитывать разновидность объектов. Прежде всего это простые и сложные объекты. Объект модели рассматривается как простой, если он имеет свойства атомарного объекта или модели.
Сложными называют объекты, которые могут быть представлены в виде совокупности более простых объектов. На схеме это соответствует тому, что блок, отображающий такой объект, может быть заменен несколькими взаимосвязанными подблоками, определяющими другие объекты или наборы данных.
Такое разделение условно, так как в одних случаях объект может считаться простым, в других - сложным.
Сложные объекты подразделяют на составные, обобщенные и агрегированные.
Составной объект структурирован на основе связей "целое-часть". Он строится аналогично классификации.
Обобщенный объект построен на основе обобщения, т.е. на основе связей "тип-тип", "род-вид" и т.д. Выделение родовых-видовых связей позволяет осуществлять классификацию, т.е. выделение классов и подклассов, с использованием признаков и свойств объектов.
Агрегированным объектом, строго говоря, следует считать объект, спроектированный (смоделированный ) на основе агрегации. Однако в разных приложениях допускают введение дополнительных условий. В частности, агрегированными обозначают объекты, участвующие в каком-либо процессе. Это соответствует описанию динамических свойств, и такие агрегированные объекты называют "отглагольными существительными", например, поставлять - "поставка", производить - "производство" и т.п.
Большинство ограничений в ER-моделях относится к классу явных. Однако в них существует ограничение для случая, когда сущность может быть идентифицирована по связям, а не по значениям своих атрибутов. Такое ограничение называется зависимостью по идентификации и обозначается как ID-зависимость.
Сетевые модели
Сетевые модели дают представление о проблемной области в виде объектов, связанных бинарными отношениями "многие ко многим". В отличие от иерархических моделей в сетевой модели каждый объект может иметь несколько "подчиненных" и несколько "старших" объектов.
Сетевые модели используют табличные и значительно чаще графовые представления. Вершинам графа сопоставляют некоторые типы сущности, представляемые таблицами, а дугам - типы связей.
Многие типы сетевых моделей данных используют для описания экономических и организационных систем.
Наиболее развитой сетевой моделью данных является модель, разработанная Рабочей группой по базам данных Ассоциации по языкам систем обработки данных КОДАСИЛ. Ее спецификации впоследствии неоднократно пересматривались.
Дискуссия по поводу сравнительных достоинств реляционной и сетевой моделей данных окончательно не закончилась. Пока признано, что нет модели, наилучшей в любых условиях, и что различным задачам адекватны различные модели.
Прочие модели
Бинарная модель. Она дает представление о проблемной области в виде бинарных отношений, характеризуемых триадой: объект, атрибут, значение.
Как известно, в иерархической графовой модели вершины представляют атрибуты или агрегаты атрибутов и соответствуют множествам или Смотренным множествам. Дуги могут использоваться для представления агрегации двух атрибутов в тип сущности или двух типов сущности в тип связи.
Вершина графа бинарной модели соответствует классификационному обобщению данных в типы, называемые категориями.
Дуга бинарной модели соответствует бинарному отношению категорий. Используя исчисление предикатов, бинарное отношение можно определить как двухместный предикат. Алгебра этих множеств определяется двухместными, или бинарными, операциями.
Графовое представление бинарных моделей дает структуру так называемого B-дерева в отличие от Е-дерева - иерархической структуры общего вида.
Семантические сети. Как модели данных они созданы для изучения проблем искусственного интеллекта. Базовые структуры в этих моделях могут быть представлены графом, множество вершин и дуг которого, как для бинарной, так и сетевой модели образует сеть.
Первоначально такую модель предполагали использовать для описания памяти в психологических задачах, но по мере развития она стала одним из основных способов представления знаний.
В отличие от сетевых моделей данных, применяемых в экономической сфере, семантические сети предназначены для представления и систематизации знаний общего характера. Развитие моделей этого класса связано с проблемами понимания естественного языка, а не с проблемами теории типов и категорий данных.
Выбор базовых информационных моделей во многом определяется не только задачами и технологией, но и возможностью программно-технологических средств. Обоснованный выбор моделей данных - залог оптимальной работы ГИС. Этот процесс является обязательным пр" системном анализе и построении ГИС.
Рассматривая базовые модели данных в ГИС для применения их в управлении, следует подчеркнуть, что эти же самые модели используют в информационных системах, решающих экономические задачи и задачи управления.
Следовательно, на уровне базовых моделей ГИС, как и ОАСУ, применимы для решения разнообразых задач управления объектами, территориальными комплексами и т.д.
Выводы
Для эффективной работы ГИС необходимы обоснованный выбор базовых моделей данных и создание интегрированной информационной основы.
Выбор моделей данных осуществляется при анализе области применения ГИС.
Организация моделей данных ГИС для управления позволяет решать задачи, которые прежде входили в сферу деятельности АСУ.
ГИС является системой более широкого применения по сравнению с АСУ. Она используется в областях, в которых АСУ не применялись, - это военное дело, навигация, экологический мониторинг, разведка подземных ископаемых, анализ сетей и др.