
Т. А. Гаврилова В. Ф. Хорошевский
| Вид материала | Реферат |
- Исследование в 11 классе учителей 1 категории моу «Янгличская сош имени Героя, 80.18kb.
- О. Я. Чекановой заместителя директора Департамента образования атмр, 2067.1kb.
- Н. В. Гаврилова, А. Л. Гусев*, В. И. Кудряш**,, 438.44kb.
- О. Т. Гаврилова, 132.3kb.
- Автор: Гаврилова Ольга Викторовна, 14.56kb.
- Возможные альтернативы, 3457.5kb.
- Семенова Марія Іванівна диплом, 75.73kb.
- Интеграция wiki-технологии и онтологического моделирования в задаче управления знаниями, 110.21kb.
- Липецка Игнатова Елена Юрьевна. Тема реферат, 27.71kb.
- К. В. Самсонова, ст гр. Фк-08-1, Н. В. Гаврилова, викл, 156.11kb.
4.6. Примеры методов и систем приобретения знаний
147
В базе знаний MOLE первоначально существуют знания о том, какие типы когни-
тивных структур необходимы для осуществления вывода и как распознать зна-
ния того или иного типа в информации, сообщаемой экспертом. MOLE запраши-
вает у эксперта список объектов, играющих роли гипотез и наблюдений. Эксперт,
кроме того, должен указать, какие пары «наблюдение — гипотеза» и «гипотеза —
гипотеза» ассоциативно связаны.
Результатом этого этапа извлечения знаний является сеть объектов. Затем MO-
LE пытается получить дополнительную информацию: о типе объекта (является
объект наблюдаемым или выводимым); о природе ассоциативной связи (какой
тип знаний лежит в основе ассоциации — объясняющие, предсказывающие или
иные); о направлении ассоциативной связи, о численной оценке «силы» ассоциа-
тивной связи. Однако MOLE понимает, что эксперт не всегда может предоста-
вить такую информации}. Поэтому на этом этапе MOLE использует стратегию
ожидании: она пытается вывести необходимую информацию из сообщений экс-
перта на основе своих ожиданий.
На :ггапе начального формирования базы знаний MOLE назначает численные
веса ассоциативных связей по умолчанию на основе следующих посылок:
• каждое наблюдение должно быть объяснено некоторой гипотезой;
» только одна из гипотез, объясняющих данное наблюдение, является в каждом
конкретном случае наиболее вероятной;
• сумма оценок для связей данного наблюдения с объясняющими его гипотеза-
ми равна единице.
Тогда по умолчанию MOLE назначает для каждой связи данного наблюдения
оценку, полученную как частное отделения единицы на число гипотез, объясня-
ющих данное наблюдение. MOLE предполагает, что если эксперт сообщил не-
сколько объяснений для одного и того же объекта, то, вероятно, он может сооб-
щить и знания, позволяющие различать эти объяснения.
Система приобретения знании 5Л1Г|Маг1ш8, 1987] создана в университете Car-
negie Mellon. Система SALT — система приобретения знаний для задач конструи-
рования. Система SALT разрабатывалась в предположении, что решение этой за-
дачи осуществляется методом пошагового распространения ограничений.
Для решения задач конструирования методом пошагового распространения огра-
ничений необходимы знания следующих типов:
- процедуры установления значений параметров;
- процедуры проверки ограничений;
- процедуры коррекции значений параметров с указанием «цены» каждого кор-
ректирующего действия.
Важно, чтобы все эти знания составляли целостную и непротиворечивую БЗ.
Наибольшую трудность для эксперта представляет необходимость последова-
тельно, шаг за шагом описать все свои действия при разработке проекта. Работая
с системой SALT, эксперт избавлен от этой необходимости.
.Исходя из того, как именно экспертные знания будут использоваться в ЭС при
составлении конкретных проектов, SALT анализирует текущее состояние БЗ и
-Предлагает эксперту-пользователю ввести или пересмотреть тот'мли иной фраг-
мент знаний. Диалог с пользователем в SALT ведется либо посредством вопро-
сов-подсказок, либо посредством меню. Инициатива в диалоге принадлежит си-
стеме.
Система приобретения знаний OPAL [Musen, Fagan, et al., 1987] была создана в
начале 80-х годов в Стэнфордском университете. Эта система обеспечивает
формирование и наращивание базы знаний для ЭС ONCOCIN, «ающей советы
по лечению онкологических больных. Система приобретения знаний OPAL ос-
нована на детально проработанной модели медицинских знаний используемых
врачами-онкологами для рекомендации лечения.
Системой используется девять типов знаний:
• схема лечения (порядок и длительность режимов лечения);
,"•» критерий выбора протокола;
- химиотерапия (описание комбинаций лекарств, назначаемых в том или ином
режиме, их дозировка);
- радиотерапия (локализация и дозировка радиотерапии);
- изменения в составе крови, требующие модификации дозировки;
- негативные реакции на лечение, выявленные путем лабораторных исследова-
ний;
- другие отрицательные последствия проводимого лечения, требующие моди-
фикации дозировки лекарств;
- перерыв или прекращение лечения;
- лабораторные исследования, необходимые для обнаружения токсичности ле-
чения и для сохранения истории течения болезни.
Эти типы медицинских знаний связаны в иерархическую структуру.
Для ввода каждого типа знаний разработан специальный графический интер-
фейс, учитывающий то, как принято фиксировать соответствующийе знания. Так,
например, для записи схемы лечения онкологи используют диа граммы перехо-
дов с условиями на дугах. В системе OPAL ввод таких знаний осуществляется с
помощью графического языка программирования. Схема лечения создается как
программа на этом языке.
Схемы протоколов и заполненные формы транслируются системой OPAL во
внутреннее представление БЗ ЭС ONCOCIN. Этот процесс осуществляется без
участия пользователя. По схемам протоколов порождаются диаграммы перехо-
дов, называемые генераторами; по формам-бланкам порождают-ся правила про-
дукций, присоединяемые к соответствующим состояниям в диажрамме.
Система KNA СК создана в 1989 г. в университете Carnegie Mellozi. Она представ-
ляет собой ориентированный на экспертов предметной области инструмент для
создания ЭС, помогающих оценивать и улучшать различные виды проектов.
148
Глава 4 • Технологии инженерии знаний
4.6, Примеры методов и систе_м_приобретения знаний
149
Единственными знаниями, изначально встроенными в систему KNACK, явля-
ются знания о процессе оценки проектов вообще, то есть независимо от конкрет-
ного содержания проектов. Все остальные знания приобретаются системой
KNACK на основе диалога и анализа документов, называемых отчетами. Отчет
описывает процесс оценки какого-либо конкретного проекта.
Приобретение знаний, необходимых для оценки проектов определенного класса,
система KNACK осуществляет в два этапа. Первый этап — это настройка на класс
проектов. На этом этапе система KNACK с помощью эксперта создает предвари-
тельную модель. Расширенная с помощью специальных процедур модель пред-
метной области автоматически транслируется в программу на языке OPS-5.
К методам структурированного интервью примыкают и использованные при по-
строении системы МЕДИКС [Ларичев, Мечитов и др., 1989] процедуры эксперт-
ной классификации. Задача экспертной классификации формулируется в работе
[Ларичев, Мечитов и др., 1989] для:
- множества независимых свойств Р;
- множества признаков Q;
- множества Q,, возможных значений m-го признака;
- множества А всех возможных состояний.
Эксперту (или группе экспертов) предлагается идентифицировать наличие свойств
из множества Р и тем самым построить классификацию множества А = UKJ5 та-
кую, что состояние а О А относится к некоторому классу К, если, по мнению экс-
перта, это состояние обладает свойством POP. Повысить эффективность экспер-
тной классификации в этом случае удается благодаря использованию априорно
заданного отношения линейного порядка на множестве состояний.
4.6.2. Имитация консультаций
Этот метод реализован в системе АРИАДНА [Моргоев, 1988]. В основе этого ме-
тода — многократное решение экспертом проблемы классификации в режиме
последовательной вопросно-ответной консультации «клиент — эксперт». При
этом роль клиента моделируется всеми участниками работы, а эксперт выполня-
ет функции, близкие к его профессиональной консультативной деятельности.
С появлением персональных компьютеров связано появление игр эксперта с
компьютером [Андриенко Г., Андриенко Н., 1992]. В системе ЭСКИЗ реализо-
ван набор игр для приобретения знаний, являющихся той или иной модифика-
цией принципа репертуарных решеток. Например, в игре «Регата» объектами,
для которых эксперт должен указать различающие признаки, являются яхты.
В ходе гонок яхты должны проходить в пролеты мостов; в один и тот же пролет
проходят яхты, соответствующие сходным по какому-либо атрибуту объектам.
Рассмотренные выше системы поддержки процессов приобретения знаний, как
правило, ориентированы на отдельные фазы всего технологического цикла.
В связи с вышесказанным интересно хотя бы кратко рассмотреть интегрирован-
ные средства поддержки определенных методологий.
4.6.3. Интегрированные среды
приобретения знаний
Интегрированная среда приобретения знаний AQUINAS [Boose=, Bradshaw, Sche-
ma, 1988] представляет собой набор программных средств дл*з извлечения экс-
пертных знаний различных типов различными методами. В состав AQUINAS
входят:
- система Dialog Manager для помощи новичкам в работе с AQUINAS;
- система ETS для извлечения и анализа репертуарных решетомк с последующим
преобразованием их в базу продукционных правил;
- средства конструирования различных иерархических структур знаний;
- средства извлечения, представления и использования неточеных знаний;
- средства тестирования и коррекции БЗ;
- средства, позволяющие эксперту оценивать конструкторы псэ наиболее подхо-
дящим шкалам;
- средства работы с несколькими экспертами;
- средства автоматического пополнения и коррекции БЗ.
Dialog Manager представляет собой ЭС, специально созданную для того, чтобы
консультировать эксперта о возможностях, представляемых A—QUINAS, и руко-
водить экспертом при работе с AQUINAS. Возможны три режима взаимодей-
ствия с Dialog Manager:
- автоматический, при котором Dialog Manager полностью берет на себя руко-
водство процессом извлечения знаний;
- ассистирующий, при котором хотя эксперту и даются рекомендации относи-
тельно его дальнейших действий, но он может им не следовать;
- режим наблюдения за действиями эксперта и сохранения истории.
Выбрав автоматический или ассистирующий режим, экспре—г должен выбрать
степень подробности подсказок и объяснений, даваемых систеи—юй («полностью»,
«на среднем уровне», «кратко»).
В БЗ Dialog Manager имеются эвристики, которые позволяют этой системе при
накоплении экспертом достаточного опыта перейти от автома—гического режима
к ассистирующему. Dialog Manager информирует эксперта о переключении ре-
жимов. Работая в ассистирующем режиме, Dialog Manager оставляет за экспер-
том выбор деятельности, но на основе своих эвристик рекошендует наиболее
подходящую. В частности, если Dialog Manager считает, что эксперту следует
заняться анализом БЗ, то в рекомендации обычно указываемся, какой именно
аспект нуждается в анализе. Так, эксперту может быть рекомежадовано обратить-
ся либо к процедурам анализа сходства элементов (конструкт оров), либо к про-
цедурам кластеризации элементов (конструкторов), либо к разбиению исходной
решетки на несколько иерархически связанных.
150
Глава 4 • Технологии инженерии знаний
4.6. Примеры методов и систем приобретения знаний
151
Интегрированная среда приобретения знаний KITTEN (Knowledge Initiation &
transfer Tools for Experts and Novices) [Show, Woodward, 1988], подобно AQUI-
NAS, основана на построении и анализе репертуарных решеток. Отличие KIT-
TEN от AQUINAS заключается в том, что в KITTEN обеспечивается извлечение
элементов и конструкторов из текстов, а кроме того, имеются процедуры, анали-
зирующие примеры решедия задач экспертом и генерирующие по ним продук-
ционные правила. Продукционные правила, порождаемые из примеров и реше-
ток, могут быть загружены в БЗ оболочки NEXPERT, с помощью которой про-
водится тестирование БЗ.
Завершая обзор прямых методов приобретения знаний, суммируем проблемы,
которые этими методами не решаются:
- эти методы не устраняют посредника между системой и экспертом;
- автономное использование описанных методов не решает таких проблем ин-
женерии знаний, как устранение «пробелов» в знаниях, выявление «глубин-
ных», невербальных знаний; сохраняется большая «время-емкость» и субъек-
тивность интервью;
- фаза приобретения знаний идеологически и теоретически не связывается со
следующими фазами инженерии знаний.
4.6.4. Приобретение знаний из текстов
Как было указано в параграфе 4.3, даже ручные методы выявления знаний из тек-
ста крайне слабо разработаны. В тех же немногих случаях, когда применяются
автоматизированные методики, речь, как правило, идет о методах лексико-семан-
тического анализа, а также о моделях понимания текста.
Наибольшую известность имеют модели понимания на лингвистическом уровне.
Системы, основанные на них, состоят в большинстве случаев из двух частей:
- первая — морфологический и синтаксический анализ;
- вторая — семантический анализ, который использует результаты работы пер-
вой части, а также словарную или справочную информацию для построения
формализованного образа текста.
Говоря о семантическом анализе текста, надо иметь в виду, что всякие отношения
текста с его семантикой начинаются после того, как в нашем распоряжении ока-
зывается некоторая модель действительности. Объектами этой модели, в частно-
сти, могут являться индивиды и отношения. ,
Таким образом, первая проблема, возникающая при попытках автоматического
извлечения знаний из текста, — это выявление свойств элементов текста для со-
отнесения этих элементов с объектами модели. Крайне редко эти свойства при-
сутствуют в тексте эксплицитно, то есть явно.
Вторая особенность существующих систем анализа текста — это, как правило,
необходимость использования словаря предметной области для выполнения
морфологического анализа, выделения имен и словосочетаний и т. д. Однако тре-
бование предварительного создания словаря предметной области одновременно
сильно осложняет задачу и уменьшает степень универсальности получаемой сис-
темы.
Понимание текста на семантическом уровне предполагает выявление не только
лингвистических, но и логических отношений между языкоазыми объектами
[Апресян, 1974]. Среди подходов к пониманию текста на семан тическом уровне
следует выделить модели типа «смысл — текст», в частности, мчодель семантик
Предпочтения [Wilks, 1976], модель концептуальной зависимости [Хейес-Рот и
др., 1987]. В модели «смысл — текст» [Мельчук, 1974] предлага ется семантичес-
кое представление на основе семантического графа и описания коммуникатив-
ной структуры текста.
В системе KRITON [Diderich, Ruchman, May, 1987] анализ тек-ста используется
для выявления хорошо структурированных знаний из книг, до_кументов, описа-
ний, инструкций. Основанный на контент-анализе метод протокольного анализа
используется для выявления процедурных знаний. Он осуществляется в пять
шагов.
\
- Протокол делится на сегменты на основании пауз, которые делает эксперт в
процессе записи.
- Семантический анализ сегментов, формирование высказываний для каждого
сегмента.
- Из текста выделяются операторы и аргументы.
- Делается попытка поиска по образцу в БЗ для обнаружен ия переменных в
высказываниях (переменная вставляется в высказывание, ес_ли соответствую-
щая ссылка в тексте не обнаружена).
- Утверждения упорядочиваются в соответствии с их появлением в протоколе.
В системе ГЛХГ(Тоо1 for Acquisition of Knowledge from Text) [Kaplan, Berry-Rog-
ghe, 1991] предполагается предварительная подготовка (разм-етка посредством
введения явной скобочной структуры) предложений текста до начала работы тек-
стового анализатора. В результате анализа выделяются объект&1, процессы и от-
ношения каузального характера.
4.6.5. Инструментарий прямого приобр етения
знаний SIMER + MIR
Программная система SIMER + MIR, разработанная в ИПС РАН под руководством
Осипова Г. С. [Осипов, 1997], представляет собой совокупность программных
средств для формирования модели и базы знаний предметной -области. Система
ориентирована преимущественно на области с неясной структурой объектов, с
неполно описанным множеством свойств объектов и богаты.1*—i набором' связей
различной «связывающей силы» между объектами.
Г
152
лава 4 • Технологии инженерии знаний
Одна из особенностей системы состоит в том, что ее использование на заключи-
тельном этапе не предполагает участия специалистов-разработчиков экспертных
систем. Это означает, что система SIMER + MIR представляет собой технологию
создания систем, основанных на знаниях о предметной области, причем техноло-
гию, ориентированную на экспертов.
Архитектура. Система SIMER + MIR включает модуль прямого приобретения
знаний SIMER, систему моделирования рассуждений типа аргументации MIR,
программу адаптации системы MIR к базе знаний, сформированной с помощью
SIMER + и программной среды поддержки базы знаний, над которой работают
все названные модули. Конструкции базы знаний создаются и просматриваются с
помощью языка инженера знаний FORTE, который включается в технологию в
специальных случаях (рис. 4.17).
Интерфейс пользователя
Программа MIR
П
рограмма
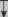
| Интерфейс эксперта Система SIMER пользователя | Программная среда базы знаний пользователя | Интерфейс инженера по знаниям Язык Форте |
Рис. 4.17. Создание конструкции базы знаний с помощью языка FORTE
Представление и база знаний. Одним из наиболее распространенных видов экс-
пертизы являются высказывания (сообщения) эксперта об объектах (событиях)
предметной области. Эти высказывания имеют вид:
< имя объекта > < имя отношения > < имя объекта >.
Для ряда областей — медицины, экологии, политики, социологии — можно выде-
лить формы сообщений, показанные в табл. 4.6:
4
153
6. Примеры методов и систем приобретения знаний
| -~ | |||
| Номер формы | Имя формы | Номер формы | Имя формы |
| Ф,5 | а исключает р | Фго | С а начинается р |
| Ф,6 | а приводит к р | Фг, | 3 развив— ается при а |
| Ф,7 | При а возникает р | Ф22 | 3 может развиваться при а |
| Ф,а | а может привести к р | Фгз | Р может начаться с а |
| 1» | а может развиваться в Р | | |
Этот список не является исчерпывающим, однако дает представление о тех ког-
нитивных структурах, которые необходимо представлять и обрабатывать в базе
знаний.
Каждая из этих форм может иметь различный смысл; уточнен ие смысла можно
получить при рассмотрении «прямого» сообщения с «обращенным». Иными сло-
вами, если для некоторых фиксированных а или р справедлившэ сообщение фор-
мы Ф10, то необходимо попытаться установить, какое из сообщений Ф, — Ф23
справедливо при замене а на р, (3 на ее. Так, для сообщения «FpoNc=i наблюдается при
грозе» справедливо «обращенное» сообщение «Гроза сопровождается гро-
мом», а для сообщения «Воспалительный процесс может наблюдаться при повы-
шенной температуре» справедливо сообщение «Повышенная температура ха-
рактерна для воспалительного процесса». Таким образом, смысл сообщений
уточняется построением «конъюнкций» форм Oj — Ф23 Такие «конъюнкции»
форм сообщений будут называться типами сообщений. Возможные типы сообще-
ний приведены в табл. 4.7.
С каждым типом сообщения из табл. 4.7 связывается формалж>ная конструкция
базы знаний, то есть бинарное отношение на множестве объектов (событий). Эти
конструкции можно проиллюстрировать следующим образ-ом: если каждый
объект (событие) представить в виде «двухмерного» множества, по первому из-
мерению которого можно откладывать атрибуты этого объект а, а по второму -
множества значений соответствующих атрибутов, то каждый объект представ-
ляется в виде фигуры:
Таблица 4.6. Формы сообщений
| Номер формы | Имя формы | Номер формы | Имя формы |
| Ф, | а характерно для р | Фв | При а нередко присутствует р |
| Ф2 | а наблюдается при р | Фэ | а может наблюдаться при р |
| Фз | а отмечается при р | Ф,о | аобычно сопровождается р |
| Ф4 | а есть проявление р | Фп | При а как правило Р |
| Ф5 | а есть признак р | ФЧ | При аобычно р |
| Фб | а сопровождает |3 | *., | а иногда сопровождается р |
| Ф7 | а нередко сопровождается р | Ф,4 | а часто сопровождается р |

Таблица 4.7. Типы сообщений
| Тип т, тг Т3 Т4 Т5 Т6 | Сообщение а есть проявление р, и р может сопровождать а а есть проявление Р, и р сопровождается а а может увеличивать возможность Р, и Рувеличивает возможность а может сопровождаться Р, и р может быть проявлением а а сопровождается р, и р может быть проявлением а а есть проявление р, и р есть проявление а |
154