
Т. А. Гаврилова В. Ф. Хорошевский
| Вид материала | Реферат |
- Исследование в 11 классе учителей 1 категории моу «Янгличская сош имени Героя, 80.18kb.
- О. Я. Чекановой заместителя директора Департамента образования атмр, 2067.1kb.
- Н. В. Гаврилова, А. Л. Гусев*, В. И. Кудряш**,, 438.44kb.
- О. Т. Гаврилова, 132.3kb.
- Автор: Гаврилова Ольга Викторовна, 14.56kb.
- Возможные альтернативы, 3457.5kb.
- Семенова Марія Іванівна диплом, 75.73kb.
- Интеграция wiki-технологии и онтологического моделирования в задаче управления знаниями, 110.21kb.
- Липецка Игнатова Елена Юрьевна. Тема реферат, 27.71kb.
- К. В. Самсонова, ст гр. Фк-08-1, Н. В. Гаврилова, викл, 156.11kb.
44. Простейшие методы структурирования
135
Все методы выявления понятий мы разделили на:
- традиционные, основанные на математическом аппарате распознавания обра-
зов и классификации;
- нетрадиционные, основанные на методологии инженерии знаний.
Если первые достаточно хорошо освещены в литературе, то вторые пока менее из-
вестны.
Пример 4.8
Интересный эксперимент по выявлению понятий описан в работе [Кук, Макдопальд,
1986J.
Тридцати студентам, имеющим права на вождение автомобиля, предложили составить
словарь терминов предметной области с помощью четырех методов:
- Формирование перечня понятий (17 %).
- Интервьюирование специалистов (35 %).
- Составление списка элементарных действий (18 %).
- Составление оглавления учебника (30 %).
Цифры в скобках характеризуют продуктивность соответствующего метода,
то есть показывают, какой процент понятий из общего выявленного списка (702 тер-
мина) был получен соответствующим методом. Для классификации понятий были
привлечены еще два участника эксперимента, которые разделили 702 выявленных по-
нятия на семь категорий (методом сортировки карточек). Таблица 4.5 отражает чис-
ленные данные концептуализации.
Таблица 4.5. Данные концептуализации
Категории Процент Процент от общего числа терминов, полученный
от общего соответствующим
числа терминов методом
| | | Перечень понятий | Интервью- ирование | Список операций | Составление оглавления |
| Объяснение | 6 | 5,5 | 7,2 | 7,0 | 4,9 |
| Общие правила | 22,0 | 43,6 | 18,9 | 36,8 | 4,9 |
| Режимные | 9,0 | 9,8 | 8,4 | 11,6 | 6,6 |
| правила | | | | | |
| Понятия | 42,0 | 18,4 | 38,9 | 8,5 | 77,7 |
| Процедуры | 9,0 | 5,1 | 9,5 | 25,6 | 1,2 |
| Факты | 9,0 | 15,0 | 12,5 | 8,9 | 1,2 |
| Прочие | 3,0 | 2,6 | 4,6 | 1,6 | 3,5 |
| понятия | | | | | |
В целом результаты показали, что для выявления непосредственно концептов
наиболее результативными оказались методы интервьюирования и составления
оглавления учебника. Однако наибольшее число общих правил было порождено
в методе списка действий. Таким образом, еще раз подтвердилось утверждение о
том, что нет «лучшего» метода, есть методы, подходящие для тех или иных ситуа-
ций и типов знаний.
Интересно, что число правил — продукций «если — то» — составило небольшой
процент во всех четырех методах. Это говорит о том, что популярная продукци-
онная модель вряд ли является естественной для человеческих моделей репрезен-
тации знаний.
Методы выявления связей между понятиями
Концепты не существуют независимо, они включены в общувиэ понятийную
структуру с помощью отношений. Выявление связей между понятгиями при раз-
работке баз знаний доставляет инженеру по знаниям немало проблем. То, что зна-
ния в памяти — это некоторые'связные структуры, а не отдельнмле фрагменты,
общеизвестно и очевидно. Тем не менее основной упор в существу=ющих моделях
представления знаний делается на понятия, а связи вводят весьма- примитивные
(в основном причинно-следственные).
В последних работах по теории ИИ все больше внимания уделяется взаимосвя-
занности структур знаний. Так, в работе [Шенк, Бирнбаум, Мей, 1989] введено
понятие сценария (script) как некоторой структуры представлен!—\я знаний. Ос-
нову сценария составляет КОП (концептуальная организация памяти) и мета-
КОПы — некоторые обобщающие структуры.
Сценарии, в свою очередь, делятся на фрагменты ~ или сцены (chunks). Связи
между фрагментами — временные или пространственные, внутри фрагмента —
самые различные: ситуативные, ассоциативные, функциональные и т. д.
Все методы выявления таких связей можно разделить на две групглы;
* Формальные.
• Неформальные (основаны на дополнительной работе с экспержом).
Неформальные методы выявления связей придумывает инженер гмо знаниям для
того, чтобы вынудить эксперта указать явные и неявные связи между понятиями.
Наиболее распространенным является метод «сортировка карточек» в группы
[Волков, Ломнев, 1989; Rabbits, Wright, 1987], широко применяемый и для фор-
мирования понятий. Другим неформальным методом является no-строение замк-
нутых кривых. В этом случае эксперта просят обвести замкнутой кривой свя-
занные друг с другом понятия [Olson, Reuter, 1987]. Этот метшэд может быть
реализован как на бумаге, так и на экране дисплея. В этом случае можно говорить
о привлечении элементов когнитивной графики [Зенкин, 1991].
После того как определены связи между понятиями, все понятия как бы распада-
ются на группы. Такого рода группы представляют собой метапонвятия, присвое-
ние имен которым происходит на следующей стадии процесса структурирования.
Методы выделения метапонятий и детализация понятий
(пирамида знаний)
Процесс образования метапонятий, то есть интерпретации групп понятий, полу-
ченных на предыдущей стадии, как и обратная процедура — детализация (разук-
Рупнение) понятий, — видимо, принципиально не поддающиеся формализации
операции. Они требуют высокой квалификации экспертов, а такжге наличия спо-
собностей к «наклеиванию» лингвистических ярлыков. Если на рмс. 4.11 показа-
136
Глава 4 • Технологии инженерии знаний
4.5. Состояние и перспективы автоматизированного приобретения наний 137
ны схемы обобщения и детализации на тривиальных примерах, то в реальных
предметных областях эта задача оказывается весьма трудоемкой. При этом неза-
висимо от того, формальными или неформальными методами были выявлены
понятия или детали понятий, присвоение имен которым или интерпретация их —
всегда неформальный процесс, в котором инженер по знаниям просит эксперта
дать название некоторой группе понятий или отдельных признаков.
I
ID
О
U3
О

Рис. 4.11. Обобщение и детализация понятий
Это не всегда удается. Так, в системе АВТАНТЕСТ [Гаврилова, Червинская,
1992] при образовании метапонятий, полученных методами кластерного анализа,
интерпретация заняла несколько месяцев и не может считаться удовлетворитель-
ной. Это связано с тем, что формальные методы иногда выделяют «искусствен-
ные» концепты, в то время как неформальные обычно — практически исполь-
зуемые и потому легко узнаваемые понятия.
М

Рис. 4,12. Пирамиды знаний
етоды построения пирамиды знаний обязательно включают использование на-
глядного материала — рисунков, схем, кубиков. Уровни пирамиды чаще возника-
ют в сознании инженера по знаниям именно как некоторые образы.
Построение пирамиды знаний может быть основано и на естественной иерархии
предметной области, например связанной с организационной структурой пред-
приятия или с уровнем компетентности специалистов (рис. 4.12).

Методы определения отношений
если на стадии 4 (см. рис. 4.10) мы выявили связи между понятияпми и использо-
вали их на стадиях 5 и 6 для получения пирамиды знаний, то на стадии 7 мы даем
имена связям, то есть превращаем их в отношения.
Б работе [Поспелов, 1986] указывается на наличие более 200 базо вых видов раз-
личных отношений, существующих между понятиями. Предложены различные
классификации отношений [Келасьев, 1984; Поспелов, 1986]. Следует только
подчеркнуть, что помимо универсальных отношений (простран ственных, вре-
менных, причинно-следственных) существуют еще и специфические отноше-
ния, присущие той или иной предметной области [Гавриловаа, Червинская,
Яшин, 1988].
Интересные возможности к структурированию знаний добавляювт системы ког-
нитивной графики. Так, в системе OPAL [Olton., Muser, Combs e=t al., 1987] экс-
перт может манипулировать на экране дисплея изображениями пзростейших по-
нятий и строить схемы лечения заболеваний, обозначая отногппения явными
линиями, которые затем именуются.
Предлагаемая в данном учебнике методология структурированшя опирается на
современные представления о структуре человеческой памяти и формах репре-
зентации информации в ней [Величковский, 1982].
Скудность методов структурирования объясняется тем, что методологическая
база инженерии знаний только закладывается, а большинство инженеров по зна-
ниям проводит концептуализацию, руководствуясь наиболее дорогими и неэф-
фективными способами — «проб и ошибок» и «по наитию», то ес~гь исходя из со-
ображений здравого смысла.
4.5. Состояние и перспективы
автоматизированного
приобретения знаний
В данном параграфе мы рассмотрим автоматизированный подход к проблеме из-
влечения и структурирования знаний, традиционно называемый* приобретением
знаний (knowledge acquisition).
Поскольку основную трудность в создании интеллектуальных с=истем представ-
ляет домашинный этап проектирования, выполняемый инженером по знаниям
(или аналитиком), — анализ предметной области, получение знаний и их струк-
турирование, — эти процедуры традиционно считаются «узким местом» (bottle-
neck) проектирования экспертных систем [Gaines, 1987; Boose, I 990]. Последние
5-6 лет усилия разработчиков направлены на создание инструментальной про-
граммной поддержки деятельности инженера по знаниям и эксшерта именно на
этих этапах.
Г
138
лава 4 • Технологии инженерии знаний
4.5.1. Эволюция систем приобретения знаний
Первое поколение таких систем появилось в середине 80-х — это так называемые
системы приобретения знаний (СПЗ) (TEIRESIAS [Davis, 1982], SIMER+
MIR [Осипов, 1988], АРИАДНА [Моргоев, 1988]). Это средства наполнения так
называемых «пустых» ЭС, то есть систем, из БЗ которых изъяты знания (напри-
мер, EMYCIN — EMPTY MYCIN, опустошенная медицинская ЭС MYCIN со спе-
циальной диалоговой системой заполнения базы знаний TEIRESIAS). Их авто-
ры считали, что прямой диалог эксперта с компьютером через СПЗ поможет
сократить жизненный цикл разработки. Однако опыт создания и внедрения СПЗ
продемонстрировал несовершенство такого подхода.
Основные недостатки СПЗ I поколения:
- Слабая проработка методов извлечения и структурирования знаний.
- Жесткость модели представления знаний, встроенной в СПЗ и связанной с
привязкой к программной реализации.
- Ограничения на предметную область.
Таким образом, традиционная схема разработки СПЗ I поколения:
создание конкретной ЭС —> опустошение БЗ —> разработка СПЗ для новых
наполнений БЗ —» формирование новой БЗ для другой ЭС
оказалась несостоятельной для промышленного применения.
Второе поколение СПЗ появилось в конце 80-х и было ориентировано на более
широкий модельный подход [Games, 1989; Борисов, Федоров, Архипов, 1991] с
акцентом на предварительном детальном анализе предметной области. Так, в Ев-
ропе широкое применение получила методология KADS (Knowledge Acquisition
and Documentation Structuring) [Wielinga et al., 1989], в основе которой лежит
понятие интерпретационной модели, позволяющей процессы извлечения, струк-
турирования и формализации знаний рассматривать как «интерпретацию» линг-
вистических знаний в другие представления и структуры.
KADS-методология
Рисунок 4.13 демонстрирует преобразование знаний согласно методологии KADS
[Breaker, Wielinga, 1989] через спецификацию пяти шагов анализа «идентифика-
ция — концептуализация — гносеологический уровень — логический уровень —уро-
вень анализа выполнения* и стадии или пространства проектирования.
Результатом анализа является концептуальная модель экспертизы, состоящая из
четырех уровней (уровня области — уровня вывода — уровня задачи — стратеги-
ческого у ровня), которая затем вводится в пространство проектирования и преоб-
разуется в трехуровневую модель проектирования (рис. 4.14).
При решении реальных задач KADS использует библиотеку интерпретацион-
ных моделей, описывающих общие экспертные задачи, такие как диагностика,
мониторинг (см. классификацию 1 из п. 2.2) и пр., без конкретного наполнения
объектами предметной области. Интерпретационная модель представляет собой
4.5. Состояние и перспективы автоматизированного приобретения знаний 139
концептуальную модель без уровня области. На основании извлеченных лингви-
стических данных происходит отбор, комбинация и вложение верхних уровней
модели, то есть уровней вывода и задачи, которые наполняются конкретными
объектами и атрибутами из уровня области и представляют в результате концеп-
туальную модель рассматриваемой задачи. На рис. 4.15 представлена модель
жизненного цикла KADS.
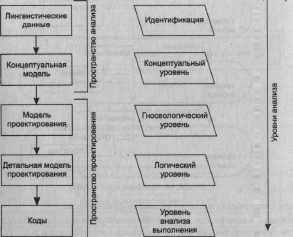
Рис. 4.13. Методология KADS
Первые системы программной поддержки KADS-методологии представлены на-
бором инструментальных средств KADS Power Tools [Schreiber G., Breuker J. et al.,
1988]. В этот набор входят следующие системы: редактор протоко»лов FED (Pro-
tocol Editor); Редактор системы понятий (Concept Editor); Реда=ктор концепту-
альных моделей СМЕ (Conceptual Model Editor) и ИМ-библиотекарь IML (Inter-
pretation Model Librarian).
Редактор протоколов — программное средство, помогающее инже=неру по знани-
ям в проведении анализа знаний о предметной области на лингвис—гическом уров-
не. При работе со знаниями на этом уровне исходным материале!» являются тек-
сты (протоколы) — записи интервью с экспертом, протоколы «мелслсй вслух» и
любые другие тексты, полезные с точки зрения инженера знаний— Редактор про-
токолов реализован как гипертекстовая система, обеспечиваются выделение
фрагментов в анализируемом тексте, установление связей межд фрагментами,
группирование фрагментов, аннотирование фрагментов. Фрагмен—ты могут иметь
любую длину — от отдельного слова до протокола в целом. Фрагменты могут пе-
рекрывать друг друга.
140
Глава 4 • Технологии инженерии знаний
5. Состояние перспективы автоматизированного приобретение знаний 141
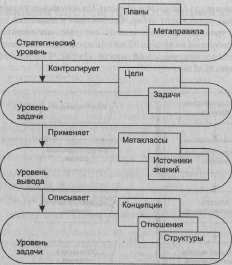
Рис. 4.14. Основные модели KADS
Возможны следующие типы связей между фрагментами:
- аннотация (связь между фрагментом протокола и некоторым текстом, введен-
ным инженером знаний для спецификации этого фрагмента);
- член группы (связь между фрагментом и названием — именем группы фраг-
ментов; объединение фрагментов в группу позволяет инженеру знаний струк-
турировать протоколы, при этом группа фрагментов получает уникальное
имя);
- поименованная связь (связь между двумя фрагментами, имя связи выбирает-
ся инженером знаний);
- понятийная связь (поименованная связь между фрагментом и понятием; обыч-
но используется, если фрагмент содержит определение понятий).
Редактор понятий помогает инженеру знаний организовывать предметные зна-
ния в виде набора понятий и связывающих их отношений. Каждое понятие име-
ет имя и может иметь атрибуты; каждый атрибут может иметь значение. Какие
именно атрибуты используются — это определяет инженер знаний с учетом спе-
цифики предметной области. С помощью Редактора понятий инженер знаний
может вводить произвольные отношения между понятиями и создавать иерар-
хические структуры по тому или иному отношению. Существует единственное
отношение (ISA), семантика которого «встроена» в Редактор. Если инженер зна-
ний устанавливает это отношение между двумя понятиями, то имеет место на-
следование атрибутов.
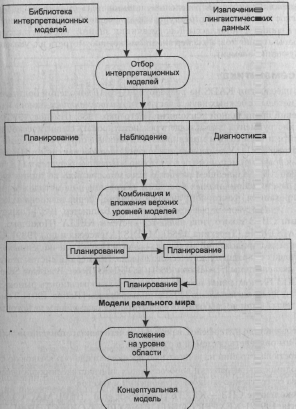
Рис. 4.15. Жизненный цикл KADS
ИМ-библиотекарь помогает инженеру знаний проводить анализ= предметных зна
ний на эпистемологическом уровне. Основное назначение Библ иотекаря состой-
в том, чтобы помочь инженеру знаний выбрать одну или более ИМ, подходящи:
Для исследуемой проблемной области (ПО). Помощь Библиотекаря проявляете;
в чисто информационном аспекте. Вначале Библиотекарь демонстрирует пользо
вателю иерархию типов задач, для которых в библиотеке име ются ИМ. Поел'
того как пользователь выбрал интересующую его ИМ, ему демонстрируется е
краткое описание и список атрибутов, включающий в себя след_ующие атрибуть
«краткое описание», «определение», «структура задачи», «стра_тегии», «ПО-зна
142
Глава 4 • Технологии инженерии знаний
4.5. Состояние и перспективы автоматизированного приобретение знаний 143
ния». Выбрав атрибут «определение», пользователь сможет увидеть на экране
графическое изображение структуры вывода, элементами которой являются ис-
точники знаний и метаклассы. Как источники знаний, так и метаклассы имеют
свои наборы атрибутов; инженер знаний может просмотреть их, указывая на со-
ответствующий элемент.
Психосемантика
Помимо идеологии KADS на разработку СПЗ II поколения большое влияние
оказали методы смежных наук, в частности психосемантики, одного из молодых
направлений прикладной психологии [Петренко, 1988; Шмелев, 1983], перспек-
тивного инструмента, позволяющего реконструировать семантическое простран-
ство памяти и тем самым моделировать глубинные структуры знаний эксперта
(см. параграф 5.1). Уже первые приложения психосемантики в ИИ в середине
80-х годов позволили получить достаточно наглядные результаты [Кук, Макдо-
нальд, 1986]. В дальнейшем развитие этих методов шло по линии разработки
удобных пакетов прикладных программ, основанных на методах многомерно-
го шкалирования, факторного анализа, а также специализированных методов
обработки репертуарных решеток [Франселла, Баннистер, 1987] (параграф 5.2).
Примерами СПЗ такого типа являются системы KELLY [Похилько, Страхов,
1990], MADONNA [Терехина, 1988], MEDIS [Алексеева и др., 1989]. Специфи-
ка конкретных приложений требовала развития также «нечисленных» методов,
использующих парадигму логического вывода. Примерами систем этого направ-
ления служат системы ETS [Boose, 1986] и AQUINAS [Boose, Bradshaw, Schema,1988].
Успехи СПЗ II поколения позволили значительно расширить рынок ЭС, кото-
рый к концу 80-х оценивался в 300 млн долларов в год [Попов, 1991]. Тем не менее
и эти системы были не свободны от недостатков, к важнейшим из которых можно
отнести:
- несовершенство интерфейса, в результате чего неподготовленные эксперты не
способны овладеть системой и отторгают ее;
- сложность настройки на конкретную профессиональную языковую среду;
- необходимость разработки дорогостоящих лингвистических процессоров для
анализа естественно-языковых сообщений и текстов.
Третье поколение СПЗ - KEATS [Eisenstadt et al., 1990], MACAO [Aussenac-
Gilles, Natta, 1992], NEXPERT-OBJECT [NEXPERT-OBJECT, 1990] - перенес-
ло акцент в проектировании с эксперта на инженера по знаниям [Гаврилова,
1988; Gruber, 1989]. Новые СПЗ — это программные средства для аналитика,
более сложные, гибкие, а главное использующие графические возможности со-
временных рабочих станций и достижения CASE-технологии (Computer-Aided
Software Engineering). Эти системы позволяют не задавать заранее интерпрета-
ционную модель, а формировать структуру БЗ динамически.
Существуют различные классификации СПЗ — по выразительности и мощнос-
ти инструментальных средств [Попов, 1988]; по обобщенным характеристикам
[Boose, 1990]; в рамках структурно-функционального подхода [Волков, Ломнев,
1989]; интегрированная классификация предложена в работе [Гаврилова, Чер-
винская, 1992].
Учитывая новейшие тенденции в инженерии знаний можно предложить следую-
щую схему таксономии СПЗ, представленную на рис. 4.16.
Системы приобретения знаний
rd ZEII ig i I ~ 1
il •== is 1<2 Si |
£ » IS .s tn ч re S с £ t: i о
|1 £i t-0 ft |0 ££| |
°a 2 § I "8 "
с i_ ш a.
с a.
A —Г — —Г~ f— —I—
гТЛЛР-п г-ТЦ Л ЛЛЛ -ХлЛп r-Ц
О •*• « 5 л 5
Я S i s -S32 II It 2 3 i|
|!Н ; Н i
!ШШиишпшЩш| | г i {{И!
illduijuLJjl
pCxp-i а л л л дц ArLAAA
вП
* X
К В ж
х П >1 П S £ т
i i ? i i i i i II i II! ]
I '. & i I I : *
£e So?i 5яёг 3|23,s
C C I S I If
ш 5 ff 1 § I
LJ LJ LJ U U U U Ul IU I I f I i
i § & -
s
Рис. 4.16. Классификация систем приобретения знанийн
Однако и современные СПЗ не полностью лишены серьезных ншедостатков СПЗ
I и II поколений, большая часть которых обусловлена отсутствием теоретической
концепции проектирования БЗ. В результате эта область до нас-гтоящего времени
справедливо считается скорее «искусством», чем наукой и осно вана на «ad hoc»
технологии (то есть применительно к случаю).
4.5.2. Современное состояние
автоматизированных систем
приобретения знаний
Анализ современного состояния программных средств приобр—етения знаний и
поддержки деятельности инженера по знаниям позволяет выя=вить две группы
проблем, характерных для существующих СПЗ:
- Методологические проблемы.
- Технологические проблемы.
144
Глава 4 • Технологии инженерии знаний
4.6. Примеры методов и систем приобретения знаний
145
А. Методологические проблемы
Основная проблема, встающая перед разработчиками, — отсутствие теорети-
ческого базиса процесса извлечения и структурирования знаний — порождает
дочерние более узкие вопросы и казусы на всех этапах создания интеллектуаль-
ных систем. Даже тщательно проработанная методология KADS, описанная в пре-
дыдущем параграфе, страдает громоздкостью и явной избыточностью. Ниже пе-
речислены наиболее общие из возникающих проблем в последовательности,
соответствующей стадиям жизненного цикла (см. рис. 2.4);
- размытость критериев выбора подходящей задачи;
- слабая проработанность теоретических аспектов процессов извлечения зна-
ний (философские, лингвистические, психологические, педагогические, ди-
дактические и другие аспекты), а также отсутствие обоснованной классифи-
кации методов извлечения знаний и разброс терминологии;
- отсутствие единого теоретического базиса процедуры структурирования зна-
ний;
- жесткость моделей представления знаний, заставляющая разработчиков обед-
нять и урезать реальные знания экспертов;
- несовершенство математического базиса моделей представления знаний (дес-
криптивный, а не конструктивный характер большинства имеющихся матема-
тических моделей);
- эмпиричность процедуры выбора программного инструментария и процесса
тестирования (отсутствие критериев, разрозненные классификации, etc.).
Б. Технологические проблемы
Большая часть технологических проблем является естественным следствием ме-
тодологических и порождена ими. Наиболее серьезными из технологических
проблем являются:
- отсутствие концептуальной целостности и согласованности между отдельны-
ми приемами и методами инженерии знаний;
- недостаток или отсутствие квалифицированных специалистов в области ин-
женерии знаний;
- отсутствие технико-экономических показателей оценки эффективности ЭС
(в России);
- несмотря на обилие методов извлечения знаний (фактически более 200 в обзо-
ре [Boose, 1990]), практическая недоступность методических материалов по
практике проведения сеансов извлечения знаний;
- явная неполнота и недостаточность имеющихся методов структурирования
знаний [Кук, Макдональд, 1986; Гаврилова, Червинская, 1992], отсутствие
классификаций и рекомендаций по выбору подходящего метода;
- несмотря на обилие рынка программных средств, недостаток промышленных
систем поддержки разработки и их узкая направленность (зависимость от
платформы, языка реализации, ограничений предметной области), разрыв
между ЯПЗ и языками, встроенными в «оболочки» ЭС;
- жесткость программных средств, их низкая адаптивность, отсутствие индиви-
дуальной настройки на пользователя и предметную область;
- слабые графические возможности программных средств, недос таточный учет
когнитивных и эргономических факторов;
- сложность внедрения ЭС, обусловленная психологическими пр-облемами пер-
сонала и неприятия новой технологии решения задач.
4.6. Примеры методов и систем
приобретения знаний
Данный параграф посвящен обзору некоторых наиболее известные методов и си-
стем приобретения знаний, на основе переработки материалов из работ [Осипов,
1990; Молокова, 1992; Осипов, 1997].
4.6.1. Автоматизированное структурированное
интервью
Впервые структурированное интервью применено при создание системы TEI-
RESIAS [Davis, 1982] для формирования новых правил и иовы>-£ понятий. Для
этих целей в системе использованы следующие соображения: в слпучае неудачи в
режиме консультации (или тестирования) система предлагает эксперту выде-
лить причины неудачи. Контекст, полученный в результате этого, позволяет сис-
теме сформировать некоторые «ожидания», характеризующие содержание ново-
го правила, которое будет вводиться экспертом для устранения меудачи.
Система ROGET [Bennet, 1985] — это первая попытка заменить иыженера знаний
программной системой на начальном этапе приобретения знаншга. Эта система
беседует с экспертом как инженер по знаниям, стремящийся понять, как концеп-
туально могут быть организованы экспертные знания, необходимою для создания
диагностической ЭС.
В системе MOLE [Eshelman, 1987] приобретение знаний осуществляется в два
этапа: на первом этапе используется структурированное интервью и эксперту
(или инженеру по знаниям) предлагается ввести список событий предметной об-
ласти и определить связи между ними; на втором этапе выполняемся контекстное
приобретение знаний, как это сделано в системе TEIRESIAS.
Система состоит из двух частей: интерпретатора базы предметных знаний и
подсистемы приобретения знаний. Последняя поддерживает как процесс перво-
начального заполнения БЗ, так и процесс отладки и уточнения Б 3.
Интерпретатор БЗ ориентирован на класс диагностических задач и осуществляет
вывод решения путем сопоставления заранее определенного множества гипотез
(о причине неисправности, о заболевании и т. д.) с совокупност-ью наблюдений
(симптомов, показаний приборов и т. д.). Иными словами, интер-претатор систе-
мы MOLE реализует некоторый вариант метода эвристической з—слассификации.
146