
Berkrley Internet Name Domain. Иногда для этой цели выделяют специальную машину задача
| Вид материала | Задача |
- Поурочне планування курсу "Основи Інтернет – технологій", 88.8kb.
- Работа nat введение, 150.17kb.
- 1. Сервіси Internet, 731.38kb.
- 1. Сервіси Internet, 347.99kb.
- Internet Information Services (iis). Понимание организации сетей, tcp/ip и Domain Name, 17.07kb.
- Что такое Internet? Ресурсы Internet*, 347.7kb.
- Лабораторна робота №19 ”Internet”, 103.46kb.
- Е. Е. Израилевич Практическая грамматика английского языка с упражнениями и ключами, 14711.83kb.
- Математическая логика сквозь школьные предметы, 133.29kb.
- Мифы и реальности Internet известные и скрытые возможности сети Что такое Internet, 306.75kb.
3. Каноническая модель кодирования
Процесс формирования объекта MIME можно смоделировать в виде цепочки последовательных шагов. Заметим, что эти шаги сходны с используемыми в PEM [RFC-1421] и реализуются для каждого "внутреннего" уровня тела сообщения.
| (1) | Создание локальной формы. |
Тело, которое подлежит пересылке, формируется в локальном системном формате. При этом используется местный символьный набор и, где возможно, локальное кодирование завершения строки. Тело сообщения может быть текстовым файлом системы UNIX, или растровым изображением, или индексным файлом VMS, или аудио данными в системно зависимом формате, хранящимися в оперативной памяти, или что-то еще, что соответствует локальной модели представления информации.
| (2) | Преобразование в каноническую форму. |
Все тело, включая вспомогательную информацию, такую как длины записи или атрибуты файлов, преобразуется в универсальную каноническую форму. Специфический тип среды тела также как и его атрибуты определяют природу используемой канонической формы. Преобразование в соответствующую каноническую форму может включать в себя преобразование символьного набора, трансформацию аудио данных, компрессию или различные прочие операции, специфические для данного типа среды. Если реализуется преобразование символьного набора, следует побеспокоиться об адаптации к семантике типа среды, что может оказать существенное влияние на преобразование очень многих символьных наборов.
Например, в случае чистого текста, данные должны преобразовываться с использованием поддерживаемого символьного набора, а строки должны завершаться CRLF, как этого требует RFC-822. Заметьте, что ограничения на длины строк, налагаемые RFC-822, игнорируются, если на следующем шаге выполняется кодирование с использованием base64 или закавыченных строк печатных символов.
| (3) | Применение транспортного кодирования. |
Применяется подходящее для данного тела транспортное кодирование. Заметим, что не существует жесткой связи между типом среды и транспортным кодированием. В частности, может оказаться вполне приемлемым выбор base64 или закавыченных строк печатных символов.
| (4) | Вставление в объект. |
Закодированное тело вкладывается в объект MIME, снабженный соответствующими заголовками. Объект затем вкладывается в объект более высокого уровня, если это требуется.
Преобразование из формата объекта в локальную форму представления производится в обратном порядке. Заметим, что реверсирование этих шагов может вызвать различный результат, так как не существует гарантии, что исходная и оконечная формы окажутся идентичными. Очень важно учесть, что эти шаги являются лишь моделью, а не руководством к тому, как на самом деле следует строить систему. В частности, модель не срабатывает в двух достаточно общих случаях.
| (1) | Во многих вариантах преобразование к канонической форме предваряется некоторой трансляцией в самой кодирующей программе, которая непосредственно работает с локальным форматом. Например, локальное соглашение о разрывах строк для текста тел может реализоваться с помощью самого кодировщика, который владеет информацией о характере локального формата. |
| (2) | Выходные данные кодировщика могут проходить через один или более дополнительных ступеней прежде чем будут переданы в виде сообщения. Выход кодировщика как таковой может не согласовываться с форматами, специфицированными в RFC-822. В частности, если это окажется удобно преобразователю, разрыв линии может обозначаться каким то иным способом, а не CRLF, как этого требует стандарт RFC-822. |
Важным аспектом данного обсуждения является то, что несмотря на любые оптимизации или введение дополнительной обработки, результирующее сообщение должно быть совместимым с моделью, описанной здесь. Например, сообщение с полями заголовка:
Content-type: text/foo; charset=bar
Content-Transfer-Encoding: base64
должно быть сначала представлено в форме text/foo, затем, если необходимо, представлено в символьном наборе и, наконец, трансформировано с использованием алгоритма base64 в формат, безопасный для пересылки через любые шлюзы.
Некоторые проблемы вызывают почтовые системы, которые для обозначения перехода на новую строку используют нечто отличное от CRLF, принятого в стандарте RFC-822. Важно отметить, что эти форматы не являются каноническими RFC-822/MIME. Заметим также, что форматы, где вместо последовательности CRLF заносится, например, LF не способны представлять сообщения MIME, содержащие двоичные данные с октетами LF, которые не являются частью последовательности CRLF.
Приложение A. Сложный пример составного сообщения
Данное сообщение содержит пять частей, которые должны быть отображены последовательно: - два вводных объекта чистого текста, встроенное составное сообщение, объект типа text/enriched и завершающее инкапсулированное текстовое сообщение с символьным набором не ASCII типа. Встроенное составное сообщение в свою очередь содержит два объекта, которые должны отображаться в параллель, изображение и звуковой фрагмент.
MIME-Version: 1.0
From: Nathaniel Borenstein
To: Ned Freed
Date: Fri, 07 Oct 1994 16:15:05 -0700 (PDT)
Subject: A multipart example(составной пример)
Content-Type: multipart/mixed;boundary=unique-boundary-1
Это область преамбулы составного сообщения. Программы чтения почты, приспособленные для чтения составных сообщений, должны игнорировать эту преамбулу.
--unique-boundary-1
... Здесь размещается некоторый текст ...
[Заметим, что пробел между границей и началом текста в этой части означает, что не было никаких заголовков и данный текст представлен в символьном наборе US-ASCII.]
--unique-boundary-1
Content-type: text/plain; charset=US-ASCII
Это может быть частью предыдущей секции, но иллюстрирует различие непосредственного и неявного ввода текста частей тела.
--unique-boundary-1
Content-Type: multipart/parallel; boundary=unique-boundary-2
--unique-boundary-2
Content-Type: audio/basic
Content-Transfer-Encoding: base64
... здесь размещаются одноканальные аудио данные, полученные при частоте стробирования 8 кГц, представленные с использованием -преобразования, и закодированные с привлечением base64 ...
--unique-boundary-2
Content-Type: image/jpeg
Content-Transfer-Encoding: base64
... здесь размещается изображение, закодированное с привлечением base64 ...
--unique-boundary-2--
--unique-boundary-1
Content-type: text/enriched
This is enriched.
как определено в RFC-1896
Isn't it
cool?
-unique-boundary-1
Content-Type: message/RFC-822
From: (mailbox in US-ASCII)
To: (address in US-ASCII)
Subject: (subject in US-ASCII)
Content-Type: Text/plain; charset=ISO-8859-1
Content-Transfer-Encoding: Quoted-printable
Additional text in ISO-8859-1 goes here ...
--unique-boundary-1--
Ссылки
| [ATK] | Borenstein, Nathaniel S., Multimedia Applications Development with the Andrew Toolkit, PrenticeHall, 1990. |
| [ISO-2022] | International Standard -- Information Processing -- Character Code Structure and Extension Techniques, ISO/IEC 2022:1994, 4th ed. |
| [ISO-8859] | International Standard -- Information Processing -- 8-bit Single-Byte Coded Graphic Character Sets - Part 1: Latin Alphabet No. 1, ISO 8859-1:1987, 1st ed. - Part 2: Latin Alphabet No. 2, ISO 8859-2:1987, 1st ed. - Part 3: Latin Alphabet No. 3, ISO 8859-3:1988, 1st ed. - Part 4: Latin Alphabet No. 4, ISO 8859-4:1988, 1st ed. - Part 5: Latin/Cyrillic Alphabet, ISO 8859-5:1988, 1st ed. - Part 6: Latin/Arabic Alphabet, ISO 8859-6:1987, 1st ed. - Part 7: Latin/Greek Alphabet, ISO 8859-7:1987, 1st ed. - Part 8: Latin/Hebrew Alphabet, ISO 8859-8:1988, 1st ed. - Part 9: Latin Alphabet No. 5, ISO/IEC 8859-9:1989, 1st ed. International Standard -- Information Technology -- 8-bit Single-Byte Coded Graphic Character Sets >- Part 10: Latin Alphabet No. 6, ISO/IEC 8859-10:1992, 1st ed. |
| [ISO-646] | International Standard -- Information Technology - ISO 7-bit Coded Character Set for Information Interchange, ISO 646:1991, 3rd ed.. |
| [JPEG] | JPEG Draft Standard ISO 10918-1 CD. |
| [MPEG] | Video Coding Draft Standard ISO 11172 CD, ISO IEC/JTC1/SC2/WG11 (Motion Picture Experts Group), May, 1991. |
| [PCM] | CCITT, Fascicle III.4 - Recommendation G.711, "Pulse Code Modulation (PCM) of Voice Frequencies", Geneva, 1972. |
| [POSTSCRIPT] | Adobe Systems, Inc., PostScript Language Reference Manual, Addison-Wesley, 1985. |
| [POSTSCRIPT2] | Adobe Systems, Inc., PostScript Language Reference Manual, Addison-Wesley, Second Ed., 1990. |
| [RFC-783] | Sollins, K.R., "TFTP Protocol (revision 2)", RFC-783, MIT, June 1981. |
| [RFC-821] | Postel, J.B., "Simple Mail Transfer Protocol", STD-10, RFC-821, USC/Information Sciences Institute, August 1982. |
| [RFC-822] | Crocker, D., "Standard for the Format of ARPA Internet Text Messages", STD 11, RFC-822, UDEL, August 1982. |
| [RFC-934] | Rose, M. and E. Stefferud, "Proposed Standard for Message Encapsulation", RFC-934, Delaware and NMA, January 1985. |
| [RFC-959] | Postel, J. and J. Reynolds, "File Transfer Protocol", STD 9, RFC-959, USC/Information Sciences Institute, October 1985. |
| [RFC-1049] | Sirbu, M., "Content-Type Header Field for Internet Messages", RFC-1049, CMU, March 1988. |
| [RFC-1154] | Robinson, D., and R. Ullmann, "Encoding Header Field for Internet Messages", RFC-1154, Prime Computer, Inc., April 1990. |
| [RFC-1341] | Borenstein, N., and N. Freed, "MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying and Describing the Format of Internet Message Bodies", RFC-1341, Bellcore, Innosoft, June 1992. |
| [RFC-1342] | Moore, K., "Representation of Non-Ascii Text in Internet Message Headers", RFC-1342, University of Tennessee, June 1992. |
| [RFC-1344] | Borenstein, N., "Implications of MIME for Internet Mail Gateways", RFC-1344, Bellcore, June 1992. |
| [RFC-1345] | Simonsen, K., "Character Mnemonics & Character Sets", RFC-1345, Rationel Almen Planlaegning, June 1992. |
| [RFC-1421] | Linn, J., "Privacy Enhancement for Internet Electronic Mail: Part I -- Message Encryption and Authentication Procedures", RFC-1421, IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1422] | Kent, S., "Privacy Enhancement for Internet Electronic Mail: Part II -- Certificate-Based Key Management", RFC-1422, IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1423] | Balenson, D., "Privacy Enhancement for Internet Electronic Mail: Part III -- Algorithms, Modes, and Identifiers", IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1424] | Kaliski, B., "Privacy Enhancement for Internet Electronic Mail: Part IV -- Key Certification and Related Services", IAB IRTF PSRG, IETF PEM WG, February 1993. |
| [RFC-1521] | Borenstein, N., and Freed, N., "MIME (Multipurpose Internet Mail Extensions): Mechanisms for Specifying and Describing the Format of Internet Message Bodies", RFC-1521, Bellcore, Innosoft, September, 1993. |
| [RFC-1522] | Moore, K., "Representation of Non-ASCII Text in Internet Message Headers", RFC-1522, University of Tennessee, September 1993. |
| [RFC-1524] | Borenstein, N., "A User Agent Configuration Mechanism for Multimedia Mail Format Information", RFC-1524, Bellcore, September 1993. |
| [RFC-1543] | Postel, J., "Instructions to RFC Authors", RFC-1543, USC/Information Sciences Institute, October 1993. |
| [RFC-1556] | Nussbacher, H., "Handling of Bi-directional Texts in MIME", RFC-1556, Israeli Inter-University Computer Center, December 1993. |
| [RFC-1590] | Postel, J., "Media Type Registration Procedure", RFC-1590, USC/Information Sciences Institute, March 1994. |
| [RFC-1602] | Internet Architecture Board, Internet Engineering Steering Group, Huitema, C., Gross, P., "The Internet Standards Process -- Revision 2", March 1994. |
| [RFC-1652] | Klensin, J., (WG Chair), Freed, N., (Editor), Rose, M., Stefferud, E., and Crocker, D., "SMTP Service Extension for 8bit-MIME transport", RFC-1652, United Nations University, Innosoft, Dover Beach Consulting, Inc., Network Management Associates, Inc., The Branch Office, March 1994. |
| [RFC-1700] | Reynolds, J. and J. Postel, "Assigned Numbers", STD-2, RFC-1700, USC/Information Sciences Institute, October 1994. |
| [RFC-1741] | Faltstrom, P., Crocker, D., and Fair, E., "MIME Content Type for BinHex Encoded Files", December 1994. |
| [RFC-1896] | Resnick, P., and A. Walker, "The text/enriched MIME Content-type", RFC-1896, February, 1996. |
| [RFC-2045] | Freed, N., and and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", RFC-2045, Innosoft, First Virtual Holdings, November 1996. |
| [RFC-2046] | Freed, N., and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", RFC-2046, Innosoft, First Virtual Holdings, November 1996. |
| [RFC-2047] | Moore, K., "Multipurpose Internet Mail Extensions (MIME) Part Three: Representation of Non-ASCII Text in Internet Message Headers", RFC-2047, University of Tennessee, November 1996. |
| [RFC-2048] | Freed, N., Klensin, J., and J. Postel, "Multipurpose Internet Mail Extensions (MIME) Part Four: MIME Registration Procedures", RFC-2048, Innosoft, MCI, ISI, November 1996. |
| [RFC-2049] | Freed, N. and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part Five: Conformance Criteria and Examples", RFC-2049 (this document), Innosoft, First Virtual Holdings, November 1996. |
| [US-ASCII] | Coded Character Set -- 7-Bit American Standard Code for Information Interchange, ANSI X3.4-1986. |
| [X400] | Schicker, Pietro, "Message Handling Systems, X.400", Message Handling Systems and Distributed Applications, E. Stefferud, O-j. Jacobsen, and P. Schicker, eds., North-Holland, 1989, pp. 3-41. |
4.4.14.5. Программа Sendmail
Семёнов Ю.А. (ГНЦ ИТЭФ), ссылка скрыта
Одной из досадных особенностей программы Sendmail является огромное количество опций. К счастью большинство из них обычно не используются. Иной раз может показаться, что назначение некоторых опций знает только их автор. Часть этих опций служит для тестирования конфигурационного файла и файла псевдонимов. Такие опции как -bt и -bv используются при изменении конфигурационного файла, чтобы гарантировать, что новые наборы правил работают безошибочно. Наиболее важные опции служат администратору для установления отладочного уровня (-d#), или для установки программы в фоновый режим или режим демона (-bd), или для установки самого отладочного режима (-v).
Почтовая программа sendmail должна запускаться в фоновом режиме с помощью строки в стартовом скрипте. Например:
/usr/lib/sendmail -bd -q30m
Эта командная строка предлагает обрабатывать занесенные в очередь сообщения каждые 30 минут. Время после опции -q может быть задана как произвольная комбинация дней, часов, минут и секунд. В этом случае за числами должны следовать соответственно символы d, h, m или s. Так, например, запись: -q1d2h30m15s указывает, что очередь будет обрабатываться с периодичностью 1 день, 2 часа, 30 минут и 15 секунд.
Конфигурационный файл sendmail является читаемым текстовым. Этот файл начинается с перечня опций и макросов, далее следует набор правил. Эти правила определяют метод дешифровки адресов почтовых сообщений. Обычно настройке подвергаются опции и макросы.
Макросы начинаются с символа D, за которым следует одна буква, определяющая имя макро, и текст расширения. Буква-имя чувствительна к регистру в котором она напечатана. Макросы используются для определения имен (имя ЭВМ, имя домена и т.д.). Практически все опции, доступные при запуске программы sendmail, могут быть описаны и в конфигурационном файле (буквенные имена совпадают).
Описание опции начинается с символа О. В остальном справедливы замечания, представленные в предыдущем абзаце о макро.
Прежде чем изменять конфигурационный файл рекомендуется сделать его копию. Усовершенствования не всегда работают так, как ожидает их автор.
Опция OL# определяет уровень работы журнала операций. Эта опция управляет объемом информации, которая записывается в log-файл при работе программы sendmail. Чем больше число, проставленное вместо символа #, тем больше информации будет записано. Наибольшему уровню соответствует цифра 9.
Опция Om служит для расширения псевдонимов. Если пользователь посылает сообщение адресату, обозначенному псевдонимом, и имя отправителя присутствует в списке псевдонимов, действием по умолчанию будет блокировка посылки самому себе. Опция Om переписывает значение по умолчанию и отправитель также получит свое сообщение. Некоторые пользователи используют такую возможность для контроля того, что сообщение было действительно послано.
Опции Or<время> и OT<время> являются опциями таймаута. Опция ОТ производит запись проблемного сообщения в очередь и осуществляет повторную попытку через специфицированный промежуток времени, прежде чем отправитель будет проинформирован о неудаче. Опция Or специфицирует значение таймаута для операций чтения. Если при получении почты от удаленной ЭВМ возникает пауза, в течение которой не приходит ничего, sendmail по истечение заданного времени прерывает процесс и закрывает соединение. Так как эта опция, вообще говоря, нарушает стандарт RFC-821, значение таймаута должно быть достаточно велико.
Опция OW специфицирует пароль для операций процессора. По существу это лазейка для выполнения пользователем некоторых операций, которые непосредственно для почтовой программы не нужны. Эта опция используется программистами для выявления проблем в работе основной программы, реализующей почтовый протокол.
Сразу после инсталляции следует поменять значение этого пароля (заменить значение, установленное по умолчанию). Удаление строки соответствующей данной опции, автоматически приведет к установлению пароля по умолчанию.
Опция -о или Оо означает, что имена получателей могут разделяться пробелами (стандарт требует применения запятых).
Опция OD служит, для того чтобы автоматически осуществлять актуализацию базы данных при изменении файла псевдонимов (alias).
Привилегированные пользователи могут изменить имя поля From, которое используется при посылке сообщений об ошибках. Это имя может быть изменено с помощью команды –f<пользователь>.
Файл alias обычно размещается в каталоге /usr/lib/aliases и служит для создания почтовых ящиков, которым не соответствует никакой аккоунт пользователя. В этом файле определяется, в какой почтовый ящик следует направлять сообщение, адресованное субъекту с указанным псевдонимом. Допускается направление сообщений вместо какого-либо почтового ящика на stdin. Стандартная строка переадресации в этом файле выглядит как.
alias: имя_пользователя или
alias: имя_пользователя_1, имя_пользователя_2, имя_пользователя_3, …
Первая строка перенаправляет все сообщения, адресованные alias пользователю с указанным именем. Второй пример соответствует случаю, когда все сообщения, адресованные alias переадресовываются всем пользователям из предлагаемого списка. Этот список может быть продолжен на следующей строке, если пред CR ввести символ \. В качестве имен пользователей могут быть записаны полные почтовые адреса типа vanja.ivanov@somewhere.ru или локальное имя. Для особо длинных списков имен можно указать файл, где этот список содержится. Для этого в файл /usr/lib/aliases нужно занести стоку типа.
Participants: “:include:/usr/local/lib/participants.list”
Обычно желательно включать псевдоним “почтмейстера” и администратора. Когда пользователь на удаленной ЭВМ не может найти имя аккоунта или ЭВМ, он может послать запрос по одному из этих псевдонимов.
Одной из наиболее эффективных (и опасных в то же самое время) особенностей файла alias является возможность перенаправлять приходящую почту программе, базирующейся на псевдониме. Когда первый символ имени аккоунта в псевдониме является вертикальной чертой (|), имя воспринимается как наименование программы, которой следует передать управление. Приходящее сообщение будет передано этой программе, как если бы этот текст был введен с консоли. В файле псевдонимов вертикальная черта работает также как в ядре UNIX. Таким образом, строка:
listserv: “|/usr/local/bin/listserv –l”
пошлет почтовый файл программе listserv, как если бы вы выполнили команду cat mailfile|listserv –l. В действительности так работают серверы подписных листов (LISTSERV). Администратор устанавливает псевдоним, а программа listserv транслирует строку поля Subject или тела сообщения в качестве команды, управляющей работой почтового сервера рассылки. Следует иметь в виду, что эта техника представляет достаточно серьезную угрозу безопасности. По этой причине ее использование должно быть обставлено соответствующими мерами (например, аутентификацией с использованием шифрованных паролей).
4.4.14.6. SPAM
Семёнов Ю.А. (ГНЦ ИТЭФ), ссылка скрыта
Cлово "спам" - это компьютерный жаргон. На самом деле, спам -- это такие консервы, вроде китайского колбасного фарша, популярного в годы застоя. Расшифровывается это слово, как SPiced hAM, перченая ветчина. Слово это придумано (и зарезервировано) корпорацией Hormel.
В начале 1970-х, английские анархисты Monty Python сочинили сюрреальный скетч о спаме. Действие происходит в кафе, в котором меню состоит из спама, яичницы с беконом из спама, спама с яичницей, и беконом из спама, яичницы со спамом и сосиской из спама, сосиски из спама, спама и помидоров со спамом... (тут официантку прерывает компания викингов, сидящих за соседним столиком. Викинги поют: спам, спам, спам! вкусный спа-а-ам!)
До 1994 года, Интернет был сетью сугубо не коммерческой, а пользователями Интернета были студенты и профессора университетов. С 1994-1995 доступ к Интернет был открыт человеку с улицы, то есть торговцу. Каналы информации UseNet, прежде заполненные научными дискуссиями, порнографией или пустым трепом, были украшены сотней сообщений под заголовком типа "make money fast". Такие сообщения стали называть спамом.
Начав с конференций UseNet, спаммеры переключились на е-майл (электронную почту). Составив списки из миллионов адресов, спаммеры рассылают коммерческую рекламу сомнительных продуктов, сайтов и полулегальных услуг. В последнее время, впрочем, распространённым продуктом рекламы являются программы для рассылки спама. Купив такую программу, желающие могут разослать по 90 миллионам адресов предложение купить у них какой-нибудь товар. Спам практически ничего не стоит для отправителя - временем и деньгами за него расплачивается сплошь и рядом жертва рассылки.
Согласно исследованиям ссылка скрыта, только 9,2% пользователей читают спам сообщения. При этом данная цифра сформирована благодаря пользователям-новичкам, из тех кто провел в сети более 3 лет спам читают лишь 5,4 %.12% пользователей сети пишут возмущенные письма по обратному адресу, а 1,5 % пользователей производят вендетту (это могут быть "почтовые бомбы" в адрес злоумышленника, жалоба провайдеру и т.д.).
Спамерным атакам подвергаются не только корпоративные пользователи сети, но и владельцы домашних PC, имеющих выход в Internet. Этот факт существенно осложняет борьбу со спамом и вовлекает в неё не только самих пользователей, но и широкую общественность. В частности, 1 марта 1999 года Открытым Форумом Интернет-Сервис-Провайдеров был одобрен документ “Нормы пользования сетью” www.ofisp.org (Acceptable Use Policy), который регламентирует нормы работы в сети (в том числе накладывает ограничения на информационный шум (спам)) и обязателен для всех пользователей, а в июле минувшего года Палата Представителей США одобрила меры по борьбе со спамом. Согласно законопроекту, электронное послание должно иметь реальный обратный адрес для того, чтобы получатели спама могли заблокировать его отправителя, нарушение этого закона грозит злоумышленнику штрафом в размере до $150.000. Почему СПАМ это действительно плохо? С практической точки зрения эта проблема раскладывается на несколько компонент (RFC 2505):
- Объём, т.е. пользователи получают огромное количество спам-сообщений в свои почтовые ящики.
- В 99% процентах случаев содержание таких писем не коррелирует с интересами адресатов.
- Для получателей СПАМ стоит реальных денег. Например, те, кто имеют выход в сеть через модем и платят за время, проведенное в Интернет, вынуждены тратить центы на фильтрацию полезных писем.
- СПАМ также стоит денег и для тех, кто поддерживает и отвечает за корректную работу почтовых серверов.Предположим, что злоумышленник послал письмо объёмом 10 килобайт 10 000 пользователям на одну ЭВМ. Несложно подсчитать, сколько места займут его все его сообщения, а именно 100 мегабайт. А что произойдёт, если спамер не один и отправляет не по одному письму?
- Большинство спамеров идут на всевозможные уловки, чтоб адресат взглянул хоть краем глаза на их сообщение. Например, пишут письмо таким образом, чтоб получатель подумал, что его с кем-то перепутали, или же помечают письмо так, что якобы внутри него содержится информация запрашиваемая адресатом. Разумеется, о морали и этике здесь не может идти и речи.
Признаки спам
- Заголовки
образуют последовательную цепочку, начиная от верхней части сообщения и заканчивая нижней частью.
- Любые заголовки
, расположенные ниже заголовка , - поддельные.
- Следует обращать внимание на любой заголовок
, в котором имена двух узлов не совпадают. Вероятно, почтовое сообщение было ретранслировано через первый узел (узел, имя которого заключено в круглые скобки, является действительным источником сообщения).
- Заголовок
, имеющий старую дату, вероятнее всего, подделан.
- Сетевая часть заголовка
должна согласоваться с последним заголовком .
- Домен заголовка
должен совпадать с доменом заголовка .
- Следует проверить, нет ли в заголовках
признаков того, что сообщение ретранслировано через посторонний узел.
- Убедитесь, что все перечисленные узлы действительно существуют в базе данных DNS
- Поле
не должно быть пустым.
- Обилие в тексте опечаток и прочих искажений может также указывать на нелегальную природу сообщения, так как программа рассылки может работать без контроля подтверждений, чтобы скрыть истинный адрес рассылки.
- Любые заголовки
В последнее время появилось достаточное число коммерческих и общедоступных программ фильтрации SPAM.
4.4.15. Сетевой протокол времени NTP
Семёнов Ю.А. (ГНЦ ИТЭФ), ссылка скрыта
Время – самый важный и невосполнимый ресурс любого человека. Проблема эта занимала людей всегда, и уже более 4 тысяч лет люди пытаются как-то упорядочить учет расходования этого ресурса, создавая различные календарные системы и устройства измерения времени. Календарные системы древнего мира отражали сельскохозяйственные, политические и ритуальные нужды, характерные для того времени. Астрономические наблюдения для установления зимнего и летнего солнцестояния производились еще 4000 лет тому назад. Проблема создания календаря возникала только в обществах, где государственная стабильность поддерживалась в течение достаточно долгого времени (Китай, Египет, государство Майя). В 14-ом столетии до Рождества Христова в Китае была определена длительность солнечного года - 365.25 дней, а лунный месяц - 29.5 дней. Солнечно-лунный календарь действовал на ближнем востоке (за исключением Египта) и в Греции, начиная с 3-го тысячелетия до нашей эры. Ранние календари использовали либо 13 лунных месяцев по 28 дней или 12 месяцев с чередующейся протяженностью 29 и 30 дней.
Древнеегипетский календарь имел 12 30-дневных лунных месяцев, но был привязан к сезонному появлению звезды Сириус (sirius – sothis). Для того чтобы примирить этот календарь с солнечным годом, был изобретен гражданский календарь, в котором добавлено 5 дней, доводящих длительность года до 365 дней. Однако со временем было замечено, что гражданский год примерно на одну четверть дня короче, чем солнечный год. Выбранная длительность года обеспечивала полное совпадение с солнечным годом раз за 1460 лет. Этот период называется циклом Сотиса (sothic-цикл). Так же как и shang chinese, древние египтяне установили длительность солнечного года равной 365,25 дней, что с точностью 11 минут совпадает с результатами современных вычислений. В 432 году до рождества Христа, около столетия после китайцев греческий астроном Метон вычислил, что 110 лунных месяцев по 29 дней и 125 лунных месяцев по 30 дней соответствуют 6940 солнечным дням, что лишь немного превышает 19 лет. 19-летний цикл, названный циклом Метона, установил длительность лунного месяца равной 29,532 солнечных дней, что с точностью 2 минут совпадает результатами современных измерений.
В древнем Риме использовался лунный календарь. Юлий Цезарь пригласилалександрийского астронома Сосигенса, который разработал календарь (который по понятным причинам стал называться юлианским), принятый в 46 году до Рождества Христова. Календарь содержал 365 дней в году с добавлением одного дня каждые 4 года. Однако первые 36 лет по ошибке дополнительный день добавлялся каждые три года. В результате набежало лишних три дня, которые пришлось компенсировать вплоть до 8 года нашей эры.
Семидневная неделя была введена лишь в четвертом столетии нашей эры императором Константином I.
Во время романской эры 15-летний цикл переписи использовался при исчислении налогов. Последовательность имен дней недели воспроизводится через 28 лет, этот период называется солнечным циклом. Таким образом, учитывая 28-летний солнечный цикл, 19-летний цикл Метона и 15-летний переписи, получаем суперцикл протяженностью 7980-лет, называемый юлианской эрой, которая начинается в 4713 году до рождества христова.
К 1545 году расхождение между юлианским календарем и солнечным годом достигло 10 дней. В 1582, астрономы Кристофер Клавиус и Луиджи Лилио предложили новую схему календаря. Папа Грегорий XIII выпусти указ, где среди прочего указывалось, что в году содержится 365.2422 дней. Для того чтобы более точно аппроксимировать эту новую величину, только столетние годы, которые делятся без остатка на 400, объявляются високосными, что предполагает длительность года 365,2425 дней. В настоящее время григорианский календарь принят большинством стран мира.
Для того чтобы мерить расширение вселенной или распад протона необходимо стандартную схему нумерации дней. По решению Международного астрономического Союза был принят стандарт на секунду и юлианская система нумерации дней (jdn). Стандартный день содержит 86,400 стандартных секунд, а стандартный год состоит из 365,25 стандартных дней.
В схеме (JDN), предложенной в 1583 французским ученым Джозефом Юлиусом Скалигером, JDN 0.0 соответствует 12 часам (полдень) первого дня юлианской эры - 1 января 4713 до нашей эры. Годы до нашей эры подсчитываются согласно юлианскому календарю, в то время как годы нашей эры нумеруются по григорианскому календарю. 1 января 1 года после рождества христова в григорианском календаре соответствует 3 января 1 года юлианского календаря [DER90], в JDN 1.721.426,0 день соответствует 12 часам первого дня нашей эры.
Эталоном времени может стать любой циклический процесс с достаточно стабильным периодом. Для измерения времни сначала использовали солнечные часы (Вавилон, 3,5 тысячи лет назад), которые были пригодны только днем при безоблачном небе. Им на смену пришли водяные часы, способные работать круглые сутки (если позволял объем сосуда). Позднее были изобретены песочные часы (появились примерно тысячу лет назад), которые могли обеспечить точность около 15-20 минут за сутки. Именно от этого типа часов пошла морская единица измерения времени - "склянки". Революцию в сфере измерения времени вызвало изобретение механических часов (Вестмистерские куранты 1288 год). Первые часы с маятником были изготовлены Х. Гюйгенсом в 1657 году, через 13 лет был изобретен анкерный механизм. Механическим хронометрам человечество обязано великим географическим открытиям 18 века (Дж.Кук). Первые часы с использованием электричества был разработаны А. Бейном в 1840 году, а первые кварцевые часы увидели свет в 1918 году. В 1937 году кварцевые часы Л.Эссена были установлены в Гринвичской лаборатории (GMT), они имели точность 2мсек в сутки. В 1944 году радиостанция BBC стала передавать сигналы точного времени с погрешностью около 0,1 мсек.сутки. Сейчас кварцевые часы можно увидеть на запястьях людей и в любом комьютере. Первые атомные часы были изготовлены в 1949 году. Без этих технологических свершений технический прогресс 20-го века был бы невозможен. Кварцевые часы побывали в космосе и на Луне.
В 1967 году был принят цезиевый (Cs133) стандарт времени, где одна секунда соответствует 9192631770 периодам перихода между уровнями в атоме цезия UTC (Universal Time Coordinated). UTC почти в миллион раз точнее астрономического среднего времени по Гринвичу. Ошибка UTC составляет менее 0,3 нсек/сутки .
Не исключено, что со врменем эталоном времени станет излучение миллисекундного пульсара (открыт в 1982 году), имеющего период 1,55780645169838 миллисекунды. Этот пульсар предположительно имеет массу Солнца, радиус 10 км и вращается со скоростью 642 оборота в секунду.
С 1 января 2001 года английским правительством было официально объявлено о новом стандарте времени Grinwich e-time (GET), который будет использоваться для обеспечения глобальных электронных платежей через Интернет.
Для оценки времени природа снабдила человека, как и некоторых других живых существ, так называемыми биологическими часами. Эти часы отсчитывают циклы длительностью около 24 часов. У нас, правда, есть природный генератор - это сердце, с периодом около 1 секунды. За отсчет времени ответственен теменной участок коры больших полушарий мозга. Механизмы оценки коротких временных интервалов и упорядочение наших жизненных событий происходит разными способами. Но эти механизмы хороши, пожалуй, лишь для определния времени обеда.
Калиброванный эталон времени, например атомные часы, довольно сложное и дорогостоящее устройство, требующее квалифицированного обслуживания. По этой причине многие пользователи не могут позволить себе такие издержки и вынуждены обращаться к услугам удаленных эталонов. Это может быть первичный эталон, размещенный где-то в локальной сети, или радио-часы. Условия доступа к сети уже предполагают наличие определенной дисперсии для времени доставки калибровочной информации. Если же эталон размещен далеко в Интернет, значения задержки и дисперсии могут возрасти многократно. Для обеспечения большей надежности калибровки обычно используют несколько эталонов, а для снижения влияния временных разбросов привлекают довольно сложные алгоритмы усреднения.
Сетевой протокол задания времени NTP (network time protocol; Network Time Protocol Version 3 Specification, Implementation and Analysis, David L. Mills, RFC-1305, March 1992) служит для осуществления синхронизации работы различных процессов в серверах и программах клиента. Он определяет архитектуру, алгоритмы, объекты и протоколы, используемые для указанных целей. NTP был впервые определен в документе RFC-958 [MIL85c], но с тех пор несколько раз переделан и усовершенствован (RFC-1119 [MIL89]). Протокол использует для транспортных целей UDP [POS80]. Целью протокола является обеспечение максимально возможной точности и надежности, несмотря на значительный разброс задержек при прохождении через большое число промежуточных маршрутизаторов.
Протокол NTP обеспечивает механизмы синхронизации с точностью до наносекунд. Протокол предлагает средства для определения характеристик и оценки ошибок локальных часов и временного сервера, который осуществляет синхронизацию. Предусмотрены возможности работы с иерархически распределенными первичными эталонами, такими как синхронизуемые радио-часы.
Точность, достижимая с помощью NTP, сильно зависит от точности локальных часов и характерных скрытых задержек. Алгоритм коррекции временной шкалы включает внесение задержек, коррекцию частоты часов и ряд механизмов, позволяющих достичь точности порядка нескольких миллисекунд, даже после длительных периодов, когда потеряна связь с синхронизирующими источниками.
Существует ряд механизмов в Интернет, которые позволяют передавать и записывать время, когда произошло какое-то событие. Это протокол daytime [POS83a], time protocol [POS83b], сообщения ICMP “временная метка” [DAR81b] и опция IP “временная метка” [SU81].
Маршрутный протокол fuzzball [MIL83b], иногда называемый hellospeak, встраивает синхронизацию непосредственно в алгоритм маршрутного протокола. Он не является протоколом из стека IP.
Юниксовский (4.3BSD) времязадающий демон [GUS85a] измеряет временные сдвиги различных клиентских процессов и рассылает им соответствующие поправки.
В этой модели сервер определен с помощью алгоритма выбора [GUS85b], который исключает ситуации, где сервер не выбран или выбрано более одного сервера. Процесс выбора требует возможности рассылки широковещательных сообщений.
Архитектура системы
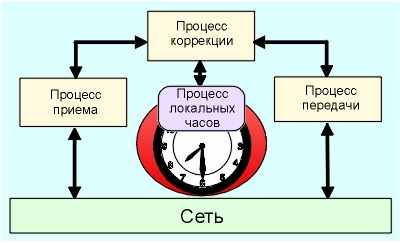
В модели NTP некоторое число первичных эталонов времени, синхронизованных по кабелю или с помощью национальных радио служб времени, подключено к широкодоступным ресурсам, таким как порты опорной сети. Эти устройства функционируют как первичные серверы времени. Целью NTP является передача информации о точном времени от этих серверов к другим серверам через Интернет и коррекция ошибок, связанных с флуктуациями задержек в сети. Некоторое число локальных ЭВМ или внешних шлюзов могут выполнять функции вторичных серверов времени, общающихся с первичными эталонами на основе протокола NTP. Вторичные серверы позволяют минимизировать избыточность протокола, рассылая нужную временную информацию локально. В целях обеспечения надежности выбранные вторичные источники могут быть снабжены менее точными, зато более дешевыми радио-часами, используемыми в ситуациях, когда откажет первичный эталон или выйдет из строя ведущий к нему канал.
Под стабильностью подразумевается степень постоянства задающей частоты часов, а под точностью – соответствие этой частоты национальным стандартам времени. Если не указано обратного, под временным сдвигом между часами подразумевается разница показаний этих часов. В то время как под сбоем (skew) подразумевается различие их рабочих частот (первая производная). Настоящие часы имеют конечную стабильность частоты (вторая производная не равна нулю). Нестабильность частоты называется дрейфом, но в рамках протокола NTP дрейф предполагается равным нулю.
Протокол NTP создан с целью определения трех величин: смещения часов (clock offset), RTT и дисперсии, все они вычисляются по отношению к выбранным эталонным часам. Смещение часов определяет поправку, которую необходимо внести в показания местных часов, чтобы результат совпал показанием эталонных часов. Дисперсия характеризует максимальную ошибку локальных часов по отношению к эталонным.
В протоколе NTP нет средств для нахождения партнера или управления. Целостность данных обеспечивается с помощью IP и UDP контрольных сумм. Система может работать в симметричном режиме, когда сервер и клиент неразличимы, и в режиме клиент-сервер, где сервер выполняет только то, что требует клиент. Используется только один формат сообщений NTP. В рамках модели необходимо определить минимально возможную частоту коррекций часов, обеспечивающую требуемую временную точность.
Реализация модели
Клиент посылает NTP-сообщения одному или нескольким серверам и обрабатывает отклики по мере их получения. Сервер изменяет адреса и номера портов, переписывает содержимое некоторых полей, заново вычисляет контрольную сумму и немедленно посылает отклик. Информация, заключенная в сообщение NTP, позволяет клиенту определить показания часов сервера по отношению к часам клиента и соответствующим образом скорректировать рабочие параметры местных часов. Кроме того, эта информация содержит данные, позволяющие оценить точность и надежность часов сервера и выбрать наилучший эталон времени.
Модель клиент-сервер может быть вполне достаточна для локальных сетей, где один сервер обслуживает некоторое количество клиентов. В общем случае NTP требует одновременной работы большого числа распределенных пар партнеров (клиент-сервер), конфигурация которых изменяется динамически. Нужны достаточно сложные алгоритмы управления такой ассоциацией, для обработки данных и контроля множества локальных часов.
Процесс передачи, управляемый независимыми таймерами для каждого из партнеров, осуществляет накопление информации в базе данных и посылает сообщения NTP. Каждое сообщение содержит локальную временную метку момента отправки сообщения, ранее полученные временные метки, а также необходимую вспомогательную информацию. Частота посылки сообщений определяется требуемой точностью локальных часов, а также предельными точностями часов партнеров.
Процесс приема осуществляет получение сообщений NTP и, возможно, сообщений других протоколов, а также информации от непосредственно подключенных радио-часов. Когда получено сообщение NTP, вычисляется сдвиг между часами партнера и локальными часами, результат заносится в базу данных вместе с другой информацией, необходимой для вычисления ошибок и выбора партнера.
Конфигурации сети
Субсеть синхронизации представляет собой соединение первичных и вторичных серверов времени, клиентов и каналов передачи данных. Первичные серверы времени синхронизованы непосредственно от эталонов времени, обычно от радио-часов. Вторичные серверы могут быть синхронизованы от первичных серверов или других вторичных серверов времени. Система серверов имеет иерархическую структуру, построенную по схеме клиент-сервер. Понятно, что вторичные серверы обеспечивают более низкую временную точность.
Следуя принципам, принятым в телефонной промышленности [BEl86], точность каждого сервера определяется номером слоя (stratum), наивысший уровень (для первичного сервера) имеет номер 1. На современном уровне технологий (радио-часы) точность однократной сверки имеет порядок одной миллисекунды.
Точность однократной сверки падает по мере роста значения RTT и его разброса. Для того чтобы избежать сложных расчетов [BRA80], необходимых для оценки точности в каждом конкретном случае, полезно предположить, что средняя ошибка измерения пропорциональна RTT и ее дисперсии. Предполагая, что первичные серверы синхронизованы стандартами времени с известной точностью, можно получить вполне надежную оценку точности синхронизации субсети.
Дополнительным фактором является то, что каждый переход от одного слоя к другому предполагает наличие ненадежного сервера времени, который вносит дополнительные ошибки. Алгоритм выбора серверов времени использует разновидность алгоритма маршрутизации Беллмана-Форда, при этом формируется дерево минимальных весов, основанием которого являются первичные сервера. Метрикой расстояния служит номер слоя плюс расстояние синхронизации, которое характеризуется суммой дисперсии и половины абсолютного значения задержки.
Такая конструкция способствует тому, что субсеть автоматически реконфигурируется и настраивается на максимально достижимую точность даже при выходе из строя первичных или вторичных серверов времени. Если даже все первичные серверы выйдут из строя или станут недоступными, их функции будут выполнять вторичные серверы, если расстояние до них согласно алгоритму Беллмана-Форда не превышает значения метрики, соответствующего бесконечности (разрыву связи). Если все серверы окажутся на больших расстояниях, субсеть продолжит работу при установках, выполненных при последней синхронизации (коррекции внутренних часов). Даже в этом случае достижима точность порядка миллисекунд в сутки.
Если два сервера находятся согласно алгоритму на равных расстояниях, допускается случайный выбор.
Форматы данных
Все арифметические операции в рамках протокола выполняются в формате с фиксированной запятой. По этой причине все переменные в NTP имеют именно этот формат. Биты пронумерованы слева на право (со старшего бита), начиная с нуля. Жестких требований на число разрядов после запятой не установлено. Если не оговорено обратного, все числа не имеют знака и занимают все отведенное для них поле (при необходимости в качестве заполнителей старших разрядов используются нули).
Временные метки NTP представляют собой 64-битные числа с фиксированной запятой без знака, которое указывает число секунд с нуля часов 1-го января 1900 года. Целая часть содержит первые 32 разряда, а дробная часть остальные 32 разряда. Этот формат не совпадает с форматом меток ICMP, где время измеряется в миллисекундах. Точность представления составляет 200 пикосекунд, что должно удовлетворить самым экзотическим требованиям.
Временная метка формируется путем копирования показания местных часов. Это производится в момент времени, заданный каким-то событием, например, приходом сообщения. Для поддержания наивысшей точности, важно, чтобы это делалось как можно ближе к оборудованию или программному обеспечению, инициирующего этот процесс. В случае, когда временная метка недоступна, например, производится перезагрузка машин, поле метки характеризуется 64 нулями.
Заметим, что с 1968 года старший бит (бит 0 целой части) равен единице, а где-то в 2036 году 64-битовое поле переполнится.
Переменные состояния и параметры
Ниже приводится обзор различных переменных и параметров, используемых протоколом. Они распределены по классам системных переменных, которые имеют отношение к операционной среде и механизму реализации местных часов. Сюда входят переменные партнеров, которые характеризуют состояние протокольных машин участников обмена, переменные пакетов, описывающие содержимое пересылаемых NTP-сообщений, а также параметры, задающие конфигурацию текущей версии программного обеспечения. Имена переменных записываются строчными буквами, а имена параметров - прописными.
Общие переменные
Следующие переменные являются общими для двух или более систем, партнеров и классов пакетов. Когда необходимо отличить общие переменные с идентичными именами, вводится идентификатор переменной.
Адрес партнера (peer.peeraddr, pkt.peeraddr), порт партнера (peer.peerport, pkt.peerport). 32-битный ip-адрес и 16-битный номер порта партнера.
Адрес ЭВМ (peer.hostaddr, pkt.hostaddr), порт ЭВМ (peer.hostport, pkt.hostport). 32-битный IP-адрес и 16-битный номер порта ЭВМ. Эти переменные включаются в переменные состояния для поддержки мультиинтерфейсных систем.
Индикатор приращения (sys.leap, peer.leap, pkt.leap) - это двухбитный код предупреждения о включении дополнительных секунд во временную шкалу NTP. Эти биты устанавливаются до 23:59 дня добавления и сбрасываются после 00:00 следующего дня. В результате день, для которого проведена эта процедура, окажется длиннее или короче на одну секунду. Для вторичных серверов эти биты устанавливаются протоколом NTP. Биты 0 и 1 (LI) принимают значения, перечисленные в таблице 4.4.15.1:
Таблица 4.4.15.1 Значения кодов индикатора LI
| LI | Величина | Значение |
| 00 | 0 | предупреждения нет |
| 01 | 1 | последняя минута содержит 61 секунду |
| 10 | 2 | последняя минута содержит 59 секунд |
| 11 | 3 | аварийный сигнал (часы не синхронизованы) |
Во всех случаях за исключением аварийного сигнала (alarm = 112), протокол NTP никак не изменяет эти биты, а только передает их программам преобразования времени, которые не являются частью протокола. Аварийная ситуация возникает, когда по какой-либо причине локальные часы оказываются не синхронизованными. Это может случиться в ходе инициализации системы или в случае, когда первичные часы оказываются недоступны в течение длительного времени.
Режим (peer.mode, pkt.mode) - это целое 3-битовое число, обозначающее код режима ассоциации, который может принимать значения, приведенные в таблице 4.4.15.2:
Таблица 4.4.15.2. Значения кодов Режим
| Режим | Значение |
| 0 | зарезервировано |
| 1 | симметричный активный |
| 2 | симметричный пассивный |
| 3 | клиент |
| 4 | сервер |
| 5 | широковещательный |
| 6 | для управляющих сообщений NTP |
| 7 | зарезервировано для частного использования |
Слой (sys.stratum, peer.stratum, pkt.stratum) - это целое число, указывающее код слоя локальных часов, который может принимать значения приведенные в таблице 4.4.15.3.
Таблица 4.4.15.3. Значения кодов слой
| Слой | Значение |
| 0 | Не специфицирован или недоступен |
| 1 | Первичный эталон (например, радио часы) |
| 2-15 | Вторичный эталон (через NTP или sntp) |
| 16-255 | Зарезервировано на будущее |