
Вестник Брянского государственного технического университета. 2007. №2(14) Математическое моделирование и информационные технологии
| Вид материала | Документы |
- Вестник Брянского государственного технического университета. 2007. №4(16) математическое, 61.09kb.
- Вестник Брянского государственного технического университета. 2011. №2(30) вычислительная, 96.24kb.
- Вестник Брянского государственного технического университета. 2007. №3(15), 98.56kb.
- Вестник Брянского государственного технического университета. 2007. №3(15) Естественные, 126.78kb.
- Вестник Брянского государственного технического университета. 2007. №1(13), 159.17kb.
- Математическое моделирование течения высоковязких жидкостей с маловязким пристенным, 225.73kb.
- Вестник Брянского государственного технического университета. 2007. №4(16), 62.05kb.
- Вестник Брянского государственного технического университета. 2006. №1 (9) Социально-философские, 117.78kb.
- Вестник Брянского государственного технического университета. 2007. №3(15), 153.72kb.
- Вестник Брянского государственного технического университета. 2011. №4(32), 114.16kb.
Вестник Брянского государственного технического университета. 2007. № 2(14)
Математическое моделирование
и информационные технологии
УДК 681.3.016
К.В. Гулаков, В.К. Гулаков
Пути повышения производительности OLTP-системы
на базе Microsoft SQL Server 2000
Рассмотрены факторы, влияющие на производительность OLTP-систем на базе Microsoft SQL Server 2000. Показаны методики и приемы повышения производительности оперативной базы данных.
С развитием информационных технологий расширяется сфера применения систем автоматизации предприятий. Большая часть таких систем – это системы учета, основой которых является база данных (БД). Наряду с различными масштабами предприятий, где существует автоматизация (от небольших фирм до крупных производств и холдингов), информационные системы также различаются по классу используемой базы данных, являющейся ядром системы. К наиболее высокому классу относятся клиент-серверные базы данных, работающие в реальном времени с большим количеством пользователей. Такая база данных должна обеспечивать быстрое добавление и обновление данных, а также получение оперативных отчетов. При этом разработчику необходимо минимизировать время ответа для каждого запроса и максимизировать производительность сервера базы данных путем сокращения сетевого трафика, операций ввода/вывода и загрузки процессора. Эта цель достигается, когда разработчик учитывает потребности приложения, логическую и физическую структуру данных, понимает, как добиться компромисса между конкурирующими запросами различных пользователей.
Оценка факторов, влияющих на производительность оперативной базы данных, необходима при построении следующего уровня баз данных – корпоративных хранилищ данных (ХД). Ввиду большого объема ХД важное значение имеет задача обеспечения необходимой производительности системы. Структура ХД и аппаратное обеспечение определяют жизнеспособность системы.
Перед разработчиками часто встает проблема повышения производительности реальных приложений, работающих с серверами баз данных. Имеются в виду случаи, когда пользователю приходится ждать от приложения результатов своего действия. Иногда такое ожидание может быть весьма нежелательным и приводящим даже к уменьшению производительности труда сотрудника. Часто таким проблемам не уделяется должного внимания на этапе проектирования базы данных. Это является следствием того, что для выявления проблем производительности необходимо провести полномасштабное тестирование системы, максимально приближенное к реальности, причем на базе данных, хранящей максимально возможный (расчетный) объем информации. Это значит, что необходимо спрогнозировать возможный прирост данных в базе, а также прирост количества клиентов сервера. Подобное тестирование обычно проводится как опытная эксплуатация системы на каком-либо реальном предприятии. Такие испытания дают возможность выявить просчеты в архитектуре БД, влияющие на производительность системы. Имея определенный опыт эксплуатации и разработки больших баз данных, разработчик способен предвосхитить многие из проблем производительности и решить их уже на начальном этапе проектирования системы. Данная статья представляет некий обобщенный опыт, полученный при эксплуатации и разработке интерактивной OLTP-системы1 на базе MS SQL Server 2000.
Будем считать, что приложение, установленное на компьютере пользователя, является «тонким» клиентом и не влияет на рассматриваемые проблемы. В большинстве случаев задержка реакции системы связана с длительным выполнением SQL-кода, инициированного пользователем.
Рассмотрим проблему производительности в целом. На рисунке показаны некоторые факторы, влияющие на производительность сервера базы данных. Среди них можно выделить базовые факторы, немаловажные в любой БД, и факторы, существенно влияющие на производительность в случае больших промышленных баз данных. Так, при проектировании таблиц БД важно уделять большое внимание не только нормализации, но и денормализации. Целесообразно по возможности разделять таблицы, предназначенные для OLTP- и OLAP-операций2. Продуманная с целью уменьшения объемов данных, представляемых на экране, логика приложения позволяет эффективно использовать индексный доступ (см. «Повышение селективности выборок» ниже). Важно при написании запросов продумывать также и структуры индексов. Не следует полагаться на помощь таких утилит, как Index Tuning Wizard. После того как таблицы построены, начинается важный этап, к которому следует отнестись с большой тщательностью, - написание и оптимизация SQL-запросов. Так, если структура таблиц вынуждает использовать курсоры, то значит, имеются просчеты в архитектуре таблиц БД, которые ведут к значительной потере производительности. Наличие длинных транзакций часто приводит к большому количеству блокировок и их эскалации. Конечно, не следует забывать и об аппаратной платформе. Большое значение здесь имеет объем оперативной памяти, так как SQL Server 2000 помещает наиболее часто используемые данные в память, что позволяет избегать значительно более медленное чтение диска. Объем кэш-памяти второго уровня в значительной степени определяет производительность потоковых вычислений. Скорость системы ввода-вывода становится особенно важной в случае большой промышленной БД. Обычно в этих случаях систему строят на базе RAID-массивов дисков. Таблицы разделяют на группы файлов и помещают их на различные диски массива, что дает возможность аппаратного параллельного доступа к ним. Отделяют также на независимые диски системные базы SQL Server и журналы транзакций.
Начинать работы по увеличению производительности следует с оптимизации SQL-запросов. Необходимо рассмотреть планы выполнения запросов и попытаться прийти к наиболее оптимальному плану. Результатом этой работы может быть как создание недостающего индекса, так и необходимость переписать запрос более оптимально. Методики оптимизации запросов здесь не рассматриваются, так как это отдельная сложная тема [1]. Предполагается, что этап оптимизации запросов пройден, найдены оптимальные планы выполнения, все необходимые индексы существуют.
Если запросы вполне оптимальны, а время реакции велико (при соответствующих аппаратных ресурсах), можно предположить, что имеются некоторые просчеты в архитектуре самой базы данных. Изменение структуры таблиц либо логики БД в уже работающей системе — очень сложная и трудоемкая задача. Необходимо стремиться избегать этого на этапе проектирования и создания приложения. Следует оценить объемы хранимых данных, заполнить базу тестовыми данными, создать стресс-тесты системы и сделать выводы о жизнеспособности системы при прогнозируемом приросте объемов информации в БД [2]. Если результаты такого исследования выявляют плохую производительность системы либо если проектируется большая база данных, необходимо рассмотреть следующие вопросы [3]:
- денормализация таблиц БД;
- повышение селективности выборок;
- уменьшение количества данных, находящихся в блокировке;
- затраты на контроль целостности;
- применение распределенных секционированных представлений.
Рассмотрим эти вопросы подробнее.
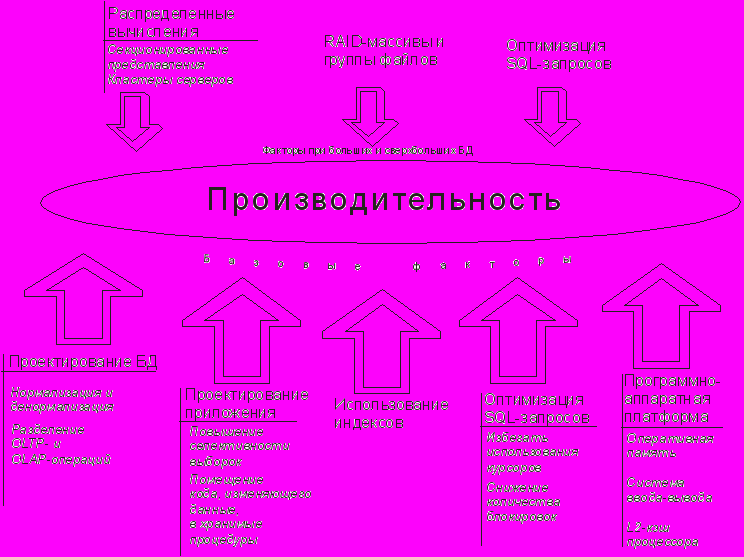
Рис. Факторы, влияющие на производительность сервера базы данных
Денормализация таблиц БД [4]. В запросах к полностью нормализованной базе нередко приходится объединять более десятка таблиц. А каждое объединение - операция весьма ресурсоемкая. Как следствие на такие запросы тратятся значительные ресурсы сервера, и выполнение их замедлено. Эта проблема особенно актуальна при построении оперативных отчетов.
В такой ситуации оправданно применение денормализации путем сокращения количества таблиц. Следует объединять в одну несколько таблиц небольшого размера, содержащих редко изменяемую (как часто говорят, условно-постоянную, или нормативно-справочную) информацию, по смыслу тесно связанную между собой.
Зачастую медленно выполняются и требуют много ресурсов запросы, в которых осуществляются какие-либо сложные вычисления, особенно при использовании группировок и агрегатных функций (Sum(), Max() и т.п.). Иногда имеет смысл добавить в таблицу 1-2 дополнительных столбца, содержащих часто используемые (и сложно вычисляемые) расчетные данные.
Если в базе данных есть большие таблицы, содержащие длинные поля (Image, Binary, Text и т.п.), то значительно ускорить выполнение запросов к ним можно путем вынесения длинных полей в отдельную таблицу. Например, требуется создать в базе каталог фотографий, при этом сохранить в BLOB-полях и сами фотографии (профессионального качества, с высоким разрешением и соответствующего размера). С точки зрения нормализации абсолютно правильной будет такая структура таблицы:
ID фотографии
ID автора
ID модели фотоаппарата
Сама фотография (BLOB-поле)
Естественно, есть еще отдельные таблицы, содержащие сведения об авторах (ключевое поле - ID автора) и о моделях фотоаппаратов (ключевое поле - ID модели). При такой структуре данных запрос, подсчитывающий число фотографий, сделанных каким-либо автором, потребует большого количества операций чтения диска и в результате будет выполняться неприемлемо медленно.
Правильным решением (хотя и нарушающим принципы нормализации) в такой ситуации будет создание еще одной таблицы, состоящей всего из двух полей: ID фотографии и BLOB-поле с самой фотографией. Тогда выборки из основной таблицы (в которой огромного BLOB-поля уже нет) будут выполняться значительно быстрее. Если возникнет необходимость получить саму фотографию, то придется потратить немного вычислительных ресурсов и объединить таблицы. К тому же, вероятно, селективность такой выборки будет весьма высокой (вряд ли понадобятся сразу все изображения), а значит, операция объединения не займет много времени и вычислительных ресурсов.
При проведении денормализации в базе данных неизбежно создаются избыточные, дублирующиеся данные. Поэтому перед разработчиками сразу возникает задача обеспечения непротиворечивости (а чаще - идентичности) дублирующихся данных. Как это реализовать?
Рассмотрим два варианта. Первый - через механизм триггеров. Так, при добавлении вычисляемого поля для каждого из столбцов, от которых оно зависит, создается триггер, вызывающий единую (это важно!) хранимую процедуру, которая и записывает нужные данные в вычисляемое поле. Надо только не пропустить ни один из столбцов, от которых зависит это поле. Второй вариант: не использовать триггеры, а собрать всю логику работы с данными в хранимые процедуры. Например, можно реализовать процедуру, которая будет «закрывать» документ: вставлять запись в таблицу, содержащую агрегированные данные, и заодно подсчитывать их значения. Это позволит избежать лишних вызовов подсчетов агрегатов (как в случае с триггерами), которые могут быть весьма ресурсоемкими процедурами. Первый способ надежнее с точки зрения целостности данных, второй – экономит вычислительные ресурсы и делает более прозрачной логику программного кода.
Повышение селективности выборок. Во многих случаях после выполнения пользователем транзакции, регистрирующей некоторые изменения в БД, приложение выполняет запрос, который отображает на экране изменившиеся данные. Если проектируется база данных с большой нагрузкой, то, возможно, следует попытаться «договориться» с разработчиками приложения не делать этот запрос после каждой транзакции либо сделать его как можно более редким. Следует реализовать механизм, который будет изменять данные на экране пользователя в соответствии с выполненной транзакцией без очередного выполнения запроса. Такой подход позволит значительно уменьшить нагрузку на сервер, однако он неприменим, когда пользователю необходимо видеть на экране результаты работы другого сотрудника в реальном времени.
Если решено обновлять данные на экране пользователя с помощью запроса, то следует построить логику приложения таким образом, чтобы уменьшить количество отображаемых строк до минимума. Это могут быть, к примеру, документы только сегодняшнего дня, только данного сотрудника, только новые, неподтвержденные и т.п. Обычно это количество сравнимо с числом строк, способным поместиться на одном экране. Условия диктуются решаемой задачей и логикой приложения. Конечно, пользователь может захотеть увидеть и остальные документы, для этого ему придется настроить соответствующим образом свой список. Но на практике, если пользователь видит все, что ему необходимо, он не станет пытаться что-то изменить. Большая селективность выборки позволит уменьшить накладные расходы на объединение таблиц (если оно имеется в выборке) и эффективнее использовать индекс по условию выбора отображаемых строк. Чем больше селективность условия отбора, тем больше эффективность индекса, который при этом применяется [1]. Если запрос возвращает большой процент всех строк таблицы, то оптимизатор может решить совсем не использовать индекс, а применить вместо этого полное сканирование таблицы, что приведет к значительной трате вычислительных ресурсов и времени.
Таким образом, тщательное планирование объемов данных, представляемых на экране пользователя позволит значительно увеличить скорость выполнения запросов благодаря эффективному использованию индексного доступа.
Уменьшение количества данных, находящихся в блокировке. Как правило, в СУБД организация данных представляет собой некоторую иерархию, например «файл-база данных- таблица- страница данных- запись- поле в записи». Некоторые уровни этой иерархии могут быть переставлены местами, быть чисто виртуальными либо полностью отсутствовать. Всё это зависит от особенностей конкретной реализации и даже используемой терминологии. В СУБД, реализующих механизм иерархических блокировок (Multigranularity Locking) для обеспечения параллельной обработки транзакций, можно наложить блокировку на объект, находящийся на любом уровне этой иерархии. При этом автоматически блокируются соответствующие объекты на нижележащих уровнях. Так, в SQL Server существует понятие «эскалация блокировок» (Lock Escalation) - это процесс, при котором множество блокировок с малой гранулярностью конвертируются в одну блокировку с большей гранулярностью на более высоком уровне иерархии.
Интуитивный ход мыслей примерно таков: блокировка на более высоком уровне иерархии вызывает блокирование объектов на более низком уровне, в том числе и тех, которые блокировать не надо. А это ведет к уменьшению степени параллелизма транзакций и в конечном итоге к падению производительности. Но на самом деле эффект обратный. При более детальном рассмотрении выясняется, что с точки зрения производительности в некоторых случаях выгоднее блокировать объекты с большей гранулярностью (когда число блокировок велико и в системе выполняются довольно длинные транзакции). В результате уменьшается общее число блокировок, снижается время выполнения длинных и как следствие коротких транзакций, вынужденных ожидать окончания выполнения длинных. Расходуется меньше системных ресурсов.
В SQL Server существуют следующие уровни иерархии блокировок:
ROWLOCK – блокировка на уровне записи.
PGLOCK - блокировка на уровне страницы данных.
TABLOCK – блокировка на уровне таблицы.
По умолчанию, если не вмешиваться в логику работы сервера, он старается наложить блокировку на запись, т.е. блокировку, обладающую наименьшей гранулярностью. Но если сервер посчитает, что блокировка на уровне отдельной записи - не самое оптимальное решение, то он заблокирует больший объем данных. К сожалению, не всегда можно определить стратегию наложения блокировок на этапе компиляции, поэтому иногда приходится увеличивать гранулярность динамически, прямо в ходе выполнения запроса.
SQL Server определяет необходимость эскалации исходя из следующего. Если число блокировок, наложенных одной транзакцией, превышает 1250 или их число на один индекс или таблицу больше 765 и если при этом больше сорока процентов памяти, доступной серверу, используется под блокировки, то тогда сервер выбирает наиболее подходящую таблицу и пытается эскалировать блокировки до табличного уровня. В случае неудачи, если на некоторые записи таблицы наложены несовместимые блокировки других транзакций, сервер не ждет, а продолжает работать на прежнем уровне гранулярности до следующей попытки. Таким образом, исключается возможность взаимоблокировки непосредственно по причине эскалации.
Как правило, эскалация блокировки – это признак того, что в приложении есть узкое место и его следует оптимизировать. Можно также попытаться разбить длинную транзакцию на множество мелких, что всегда полезно, даже если не принимать во внимание эскалацию. В целом чем оптимальнее написаны транзакции и запросы, тем меньше риск эскалации блокировок. Но никогда нельзя быть уверенным, что эскалация не произойдет.
Контроль целостности (Сonstraints). Не следует создавать слишком много проверок целостности (Сheck Constraints), особенно ссылочной целостности между таблицами, где это не так нужно. Все Constraints являются вычисляемыми. Чем больше контроля ссылок, тем больше выполняется чтений с диска и тем больше их вычисление влияет на производительность системы. Необходимо хорошо продумывать структуру таблиц и связей между ними. А проверки корректности полученных от пользователя данных рекомендуется поместить в хранимые процедуры, осуществляющие регистрацию данных (если, конечно, это допустимо логикой приложения). Так можно добиться большей оптимальности проверок и прозрачности логики базы данных.
Распределенные секционированные представления (Distributed Partitioned Views). В случае, когда необходимо получить дополнительную производительность на сверхбольших базах данных, а хранимые процедуры уже оптимизированы, программное обеспечение является многоуровневым и аппаратные средства модернизированы, настает время для распределения базы данных по нескольким серверам. Для SQL Server это делается путем горизонтального секционирования больших таблиц по множеству серверов. Если разделение таблицы с множеством столбцов на несколько таблиц с меньшим количеством столбцов является вертикальным секционированием, то горизонтальным секционированием считается разделение таблицы с множеством записей на множество таблиц с меньшим количеством записей. Если новые таблицы меньшего размера размещаются на разных серверах, то это называется объединенной базой данных. Здесь используется слово «объединенный», потому что все задействованные серверы могут работать совместно для балансировки нагрузки. Они действуют как некое объединение. Как только данные распределяются по нескольким серверам, для выборки записей становится необходимым новый тип выражений. Эти новые выражения называются распределенными секционированными представлениями.
При использовании в запросе условия секционирования производительность существенно возрастает. Главное, чтобы оптимизатор правильно определил, что нужно сканировать только некоторые таблицы. Для этого, правда, придется использовать динамические запросы - чтобы в запросе фигурировала константа вместо переменной. Но – с учетом с выигрыша во времени — это приемлемая цена [5].
Оптимизатор при построении плана выполнения запроса не вычисляет значений переменных и как следствие не может определить, какой запрос выполнять нет необходимости. Принимаются во внимание лишь константные выражения. Поясним на примере. Пусть есть две таблицы, Table1 и Table2, содержащие поле SomeField, а также существуют ограничения целостности (Сheck Constraints): для Table1 – SomeField<10, а для Table2– SomeField>10. Тогда при выполнении запроса
Select SomeField
From Table1
Where SomeField=5
UNION
Select SomeField
From Table2
Where SomeField=5
будет просканирована только одна таблица, так как во второй не может находиться значение 5. Однако запрос, содержащий переменную
declare @Var int
Set @Var=5
Select SomeField
From Table1
Where SomeField=@Var
UNION
Select SomeField
From Table2
Where SomeField=@Var,
будет сканировать обе таблицы, несмотря на то, что выборка из Table2 не даст результатов. Решение этой проблемы заключается в формировании текстовой строки, содержащей текст запроса со значениями переменных в директиве Where и последующее выполнение этого текста с помощью команды sp_executeSQL (или EXEC() ).
Это принцип работы оптимизатора. Ведь план любого SQL-кода строится без учета значений переменных, участвующих в запросе.
И еще одно примечание, которое может оказаться полезным. На секционированные представления индекс построить нельзя: оператор UNION документирован как неразрешенный при создании индекса.
Описанные приемы применялись авторами для повышения производительности оперативной системы торгового предприятия на базе MS SQL 2000. Для многострочных документов итоги по колонкам были помещены в денормализованные таблицы. Это позволило уменьшить количество объединений таблиц в запросах и использовать в отчетах, где это возможно, агрегированные данные. Во многих случаях запрос, суммировавший детализированные данные, выполнялся несколько минут, в то время как запрос, оперировавший агрегированными данными, – несколько секунд.
Клиентское приложение на экране пользователя представляет данные, возвращенные исключительно хранимыми процедурами с большой селективностью выборки, т.е. объемы данных на экране минимизированы логикой приложения. Так, существует понятие «операционный день», поскольку большинство сотрудников работают с документами именно сегодняшнего дня. Такую выборку приложение делает по умолчанию, и в большинстве случаев этого достаточно. Сервер кэширует часто запрашиваемые данные, что вместе с индексным доступом значительно увеличивает скорость выполнения таких запросов.
Использование курсоров приводило к возникновению длинных транзакций, которые порождали блокировку большого количества данных, а также приводили к эскалации блокировок. В процессе выполнения таких транзакций работа других пользователей останавливалась, и они были вынуждены ожидать ее окончания. Решение проблемы заключалось в разбиении большой транзакции на более короткие.
Таким образом, недостаточное внимание, уделенное вопросам производительности, при больших объемах данных и большом количестве пользователей системы может привести к значительному падению эффективности работы системы, а возможно, даже к ее полной нежизнеспособности. Просчеты в архитектуре, приводящие к критической потере производительности с ростом объемов информации, являются трудно устранимыми во внедренной работающей системе. Использование упомянутых методов позволило авторам полностью избавиться от задержек при регистрации транзакций и построении отчетов в системе с большой нагрузкой. Так, некоторая денормализация таблиц базы данных увеличила скорость формирования основных оперативных отчетов. Подсчет промежуточных итогов во время регистрации транзакций позволил при построении отчетов обрабатывать вместо таблиц с несколькими миллионами записей таблицы с несколькими сотнями тысяч записей. При этом не используются мультипроцессорные высокопроизводительные и дорогостоящие серверы, что делает потенциально возможным масштабирование системы при росте объемов информации.
Список литературы
- Тоу, Д. Настройка SQL. Для профессионалов / Дэн Тоу. – СПб.: Питер, 2004.
- Берзин, В. Технология нагрузочного тестирования информационных систем с большим объемом данных / В. Берзин // Oracle Magazine. Русское издание. – 2004, декабрь. – С. 94-124 .
- Вьейра, Р. SQL Server 2000. Программирование: в 2 ч. / Роберт Вьейра. – М.: БИНОМ. Лаборатория знаний, 2004. – Ч.2. – С. 1145.
- Пуле, М. Денормализация: как нарушить правила и избежать последствий / Мишель Пуле // SQL Server Magazine. – 24.10.2001.
- Schlichting, Don. MS SQL Server Distributed Partitioned Views / Don Schlichting; пер. В. Степаненко // ссылка скрыта, 2004.
Материал поступил в редколлегию 26.01.07.
1OLTP – On-Line Transaction Processing (оперативная обработка транзакций). Термин применяют к системам, ориентированным на быструю вставку, обновление данных и получение оперативных отчетов.
2 OLAP – On-Line Transaction Processing (оперативная аналитическая обработка). Термин применяют к системам ориентированным на получение обобщенной, агрегированной информации при помощи многомерных моделей данных.