
На прошлой лекции мы с вами узнали, что в настоящее время используется трехуровневая архитектура бд
| Вид материала | Лекции |
- Р. С. Гиляревский Знания информация данные На прошлой лекции, 138.38kb.
- На прошлой лекции мы начали изучать такую тему, как влияние структуры молекулы на механизмы, 74.01kb.
- Неймана Термин «архитектура», 53.96kb.
- Г. П. Щедровицкий на прошлой лекции, 310kb.
- Русской Православной Церкви. А мы с Вами вернемся к нашему предмету. Итак, на прошлой, 878.3kb.
- С. С. Хоружий лекции по введению в синергийную антропологию, 299.78kb.
- Ть единицу, простейшую единицу деятельности, то что мы дальше будем с вами называть, 252.85kb.
- Сетевой маркетинг в страховании, 55.33kb.
- Контрольная работа по дисциплине: концепции современного естествознания, 628.84kb.
- План лекции: Что такое «сердечные катастрофы»? Фибрилляция желудочков сердца, 178.21kb.
ЛЕКЦИЯ №2
На прошлой лекции мы с вами узнали, что в настоящее время используется трехуровневая архитектура БД. Кроме этого, пользователи подразделяются на прикладных программистов и пользователей непрофессионалов. Для каждого пользователя используется свой язык общения с базой данных.
Для прикладного программиста это обычный язык программирования, например: Паскаль, Си. Для пользователя-непрофессионала – это специальный язык, разработанный с учетом его потребностей, т.е. это может быть специальное меню, реализованное с помощью языка типа SQL (Structured Query Language – структурированный язык запросов) или QBE (Query-By-Exemple – запросы на основе примеров) и т.п.
Но для взаимодействия с СУБД важно понимать, что связь с базой осуществляется с помощью специального языка - языка манипулирования данными. Пользователь-программист использует язык манипулирования данными как обычные подпрограммы, а пользователь-непрофессионал - как некоторую совокупность правил взаимодействия с базой.
Передача информации между базой данных (БД) и пользователями осуществляется через рабочую область. Для пользователей программистов такой рабочей областью является область ввода-вывода, для непрофессионала эта область состоит из рабочей памяти выделенной терминалу. Т.к. отдельного пользователя, как правило, интересует только некоторая часть всей базы данных, то он взаимодействует с банком данных на уровне внешней модели (которая может не являться точной копией физической (хранимой) базы). Таким образом, внешняя модель является информационным содержанием базы данных в том виде, в каком его представляет конкретный пользователь (т.е. для этого пользователя внешняя модель есть собственно база данных, например: база данных отдела кадров).
Основная функция СУБД – организация обмена информацией между пользователями и базами данных с соответствующими процедурами контроля полномочий и процедур проверки. Среди пользователей СУБД выделяется лицо (или группа лиц), на которого обычно возлагаются следующие функции:
- определение информационного содержания базы данных (идентификация объектов и связей, представляющих интерес для данного предприятия, создание на этой основе концептуальной схемы (с помощью специального языка);
- определение структуры хранения и стратегии доступа;
- взаимодействие с пользователем (подготовка и написание внешних схем);
- определение стратегии дублирования и восстановления;
- управление эффективностью ответа на запросы пользователей;
- создание словаря данных.
Такое лицо получает статус администратора базы данных (АБД).
Для обычного пользователя перечисленные выше функции либо недоступны, либо они ему не нужны. В этом проявляется еще один аспект независимости данных, а именно:
СУБД должна предоставлять доступ к данным, не требуя от пользователя знаний о таких тонкостях как:
- физическое размещение в памяти данных и их описаний;
- управление данными во внешней памяти и управление буферами оперативной памяти;
- механизмы поиска запрашиваемых данных;
- проблемы, возникающие при одновременном запросе одних и тех же данных многими пользователями (как для прикладных, так и системных программ);
- способы обеспечения защиты данных от некорректных обновлений и (или) несанкционированного доступа и множестве других функций СУБД, таких, например, как управление транзакциями или журнализации и восстановления баз данных после всевозможных сбоев.
Языковые средства взаимодействия с СУБД
На взаимодействие с СУБД существенное влияние оказывают языковые факторы как самой СУБД, так и ОС (операционной системы) в среде которой она работает.
Кроме языка описания данных (ЯОД) для описания концептуальной схемы необходимы языки определения данных внешних схем, включающие язык управления внешней памятью, язык манипулирования данными, язык управления заданиями (или другой язык ОС).
Разработчик прикладной программы описывает процесс обработки данных на каком-либо из процедурных языков программирования, выбор которого определяется наличием соответствующего транслятора или интерпретатора, удобством описания обработки и т.д.
Если СУБД располагает средством связи программы, написанной на каком-либо языке, с БД, то такой язык называется включающим языком (Кобол, С, Паскаль, Clipper и т.п.). Языковыми средствами связи с БД являются языки описания внешних схем и языки манипулирования данными.
Язык управления заданиями является средством связи пользователя с ОС. На этом языке пользователь излагает сведения, которые необходимы ОС для принятия его задания к выполнению, организации процесса выполнения, выдачи результатов и т.д. Язык управления заданием является составной частью ОС.
Задача пользователя является объектом обслуживания как для ОС, так и для СУБД. OC выделяет для задачи область памяти, которая в свою очередь разбивается на рабочие области. СУБД осуществляет передачу данных из рабочей области в БД и наоборот.
Язык управления внешней памятью (ЯУП обычно включается как составная часть языка описания данных) предназначен для определения взаимно-однозначного соответствия между страницами концептуальной схемы и физическими элементами хранения страниц.
Чтобы упростить процесс взаимодействия пользователя с хранимой информацией, все указанные языки сгруппированы в оболочке СУБД (где они носят название языков описания схем и манипулирования данными), которая через свои визуальные средства позволяет делать их практически не видимыми для пользователя.
Укрупнено процесс взаимодействия СУБД и прикладной программы состоит из следующих шагов:
- Прикладная программа обращается к СУБД с запросом на чтение описания внешней модели данных (ВМД);
- СУБД определяет, из каких записей состоит внешняя модель данных и на основе концептуальной модели данных выбирает в рабочую область необходимые записи из хранимой базы;
- ОС с помощью своих методов доступа считывает информацию в буферы СУБД.
- На основе описания внешней модели данных и описания соответствующих отображений формируется запись для данной программы пользователя.
- Сформированная запись из буфера СУБД пересылается в рабочую область прикладной программы и обрабатывается прикладной программой.
Таким образом, мы с вами рассмотрели основные виды Баз Данных и СУБД. В настоящее время наиболее распространенными являются реляционные Базы Данных. Рассмотрим их более подробнее.
Основные понятия реляционных баз данных
Для правильного построения и описания схем баз данных используется специальная теория, называемая теорией нормализации.
Как любая более или менее строгая научная дисциплина, теория нормализации (и в более широком смысле теория баз данных) опирается на математический аппарат. Основу этого аппарата составляют теория множеств и элементы алгебры. Однако, необходимость существенного смещения акцентов на прикладную сторону теории нормализации приводит к тому, что некоторые классические понятия математики приходится трактовать в ней несколько иначе. В первую очередь это касается центрального для реляционных баз данных понятия - отношения.
Поскольку специалисты по базам данных, в первую очередь, занимаются вопросами интерпретации реального мира, строят его модели, причем не только для себя, но и для лиц, далеких от чистой математики, постольку им приходится уделять большое внимание связи вводимых ими формализмов с этим реальным миром, возможности объяснить и использовать их в диалоге с неспециалистом, обычным человеком, для которого, собственно, и строятся все эти модели.
А это значит, что, оперируя математическими понятиями, все время приходится не забывать о той смысловой нагрузке, которая увязана с этими понятиями и о необходимости выразить их на обычном, не математическом языке.
Но, вернемся к отношению. В общем случае, математики редко определяют это понятие, в связи с его первичным характером. Хотя у отдельных авторов и имеется формальное определение отношения, как подмножества декартова произведения множеств, на которых задано отношение. Это рабочее определение, когда речь идет о конечных или хотя бы счетных множествах. Но пользы от него для случая непрерывных множеств немного. Однако, для баз данных характерны дискретные конечные множества, поэтому для них вполне подходит названное определение.
Если теперь формально встать на позиции этого определения, то любое новое подмножество, даже отличающееся от первого одним элементом, будет новым отношением. Этот факт, с практической точки зрения, не очень удобен.
Ни один пользователь, да и обычный программист тоже, для которого отношение - это, попросту, некоторый список (таблица), не поймет теоретика баз данных, если тот будет утверждать, что, добавив, изменив или удалив какой-либо элемент этого отношения, мы получим новое отношение.
И действительно, с точки зрения пользователя или программиста занесение в таблицу новой строки либо изменение или удаление существующей строки саму эту таблицу, как таковую, не меняют. И это разумно, хотя, строго говоря, не меняется только форма таблицы, содержание же ее становится другим. Но, с точки зрения здравого смысла (а, как впоследствии будет показано, и при правильном построении базы данных), это все-таки не есть изменение таблицы.
Чтобы избежать подобных проблем, в теории баз данных приходится, с одной стороны, придерживаться свойств математического понятия отношение, чтобы можно было использовать аппарат (очень нужные операции) теории множеств и алгебраические понятия, а с другой стороны, “выкручиваться”, пытаясь сказать, что различные подмножества одного и того же декартова произведения, суть одно и то же отношение, что напрямую противоречит исходному определению.
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации:
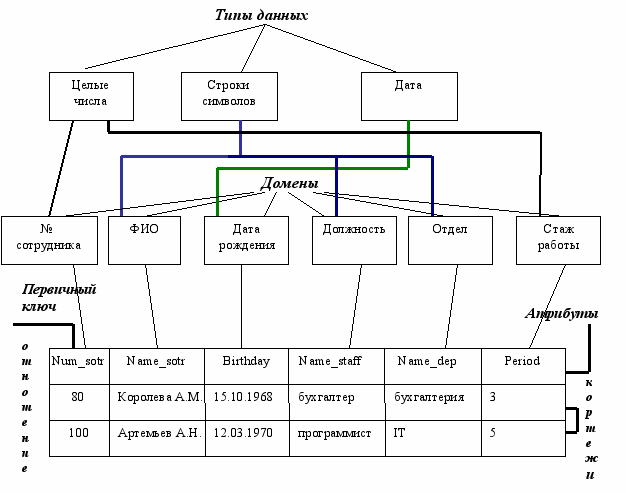
Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных данных таких как: дата, время, временной интервал. В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и дата.
Домен
Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных является элементом домена.
Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен "ФИО" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака).
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов "Номер сотрудника" и "Стаж работы" относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Oracle V.7 оно уже поддерживается.
Схема отношения, схема базы данных
Схема отношения - это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Степень или "арность" схемы отношения определяется количеством атрибутов. Степень отношения СОТРУДНИКИ равна шести, то есть оно является 6-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута).
Схема БД (в структурном смысле) - это набор именованных схем отношений.
Кортеж, отношение
Кортеж, соответствующий данной схеме отношения, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или "арность" кортежа, т.е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Попросту говоря, кортеж - это набор именованных значений заданного типа.
Отношение - это множество кортежей, соответствующих одной схеме отношения.
Реляционная база данных - это набор отношений, имена которых совпадают с именами схем отношений в схеме БД.
Альтернативные варианты терминов в реляционной модели.
| Официальная терминология | Альтернативный вариант 1 | Альтернативный вариант 2 |
| Отношение | Таблица | Файл |
| Кортеж | Строка | Запись |
| Атрибут | Столбец | Поле |
Остановимся теперь на некоторых важных свойствах отношений, которые следуют из приведенных определений:
Отсутствие кортежей-дубликатов
То свойство, что отношения не содержат кортежей-дубликатов, следует из определения отношения как множества кортежей. В классической теории множеств по определению каждое множество состоит из различных элементов.
Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения по крайней мере полный набор его атрибутов обладает этим свойством. Однако при формальном определении первичного ключа требуется обеспечение его "минимальности", т.е. в набор атрибутов первичного ключа не должны входить такие атрибуты, которые можно отбросить без ущерба для основного свойства - однозначно определять кортеж. Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных.
Отсутствие упорядоченности кортежей
Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат, вообще говоря, не отношение, а некоторый упорядоченный список кортежей.
Отсутствие упорядоченности атрибутов
Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {имя атрибута, имя домена}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов.
Атомарность значений атрибутов
Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т.е. среди значений домена не могут содержаться множества значений (отношения).
Исходя из всех определений, данных выше, отметим следующее. При представлении отношения с помощью таблицы ее строки соответствуют кортежам, а столбцы – атрибутам. Причем такая таблица должна обладать следующими свойствами:
- В таблице нет одинаковых строк.
- Каждый столбец таблицы содержит значения только одного атрибута.
- Порядок строк и столбцов в таблице не существенен.
Реляционная модель, как и любая другая модель данных учитывает ограничения, накладываемые семантикой предметной области на используемые данные. Одним из способов учета ограничений предметной области является понятие функциональной зависимости, которое поддается строгой формализации и позволяет упростить процесс проектирования схемы баз данных, удовлетворяющих определенным требованиям.
Функциональная зависимость атрибута B от атрибута A состоит в том, что каждому значению свойства, описываемого атрибутом A, может быть поставлено в соответствие только одно значение свойства, описываемого атрибутом B.
Поясним на примере. Пусть, имеется отношение СПИСОК_ПОЛЕТОВ с атрибутами, имена которых Пилот, Номер рейса, Дата, Время вылета.
| Пилот | Номер рейса | Дата | Время вылета |
| Иванов | 641 | 3 июня | 1.10 |
| Иванов | 643 | 5 июня | 0.20 |
| Петров | 641 | 4 июня | 1.10 |
| Серов | 43 | 1 июня | 7.10 |
СПИСОК_ПОЛЕТОВ
Представленное отношение описывает реальную ситуацию, когда за пилотом закреплены рейсы, а за каждым рейсом – дата и время вылета.
Анализ этого отношения со схемой:
СПИСОК_ПОЛЕТОВ = {{Пилот, Номер рейса, Дата, Время вылета}},
или, используя более простую запись:
СПИСОК_ПОЛЕТОВ(Пилот, Номер рейса, Дата, Время вылета),
показывает, что:
- Для каждого рейса определено только одно время вылета;
- Для любого пилота, даты, время вылета, определен только один рейс;
- Для рейса и даты определен только один пилот.
Данные предложения описывают ограничения на атрибутах отношения и носят названия функциональных зависимостей, которые обычно обозначаются: “
 ”.
”.Например, для рассмотренного отношения набор ФЗ будет иметь вид:
- Время вылета Номер рейса,
- Пилот, Дата, Время вылета Номер рейса,
- Номер рейса, Дата Пилот.
Заметим, что выделенные зависимости должны быть устойчивыми во времени, т.е. не зависеть от состояния Ri отношения R. Функциональная зависимость есть свойство реляционной схемы, которое определяется во время ее построения и выполняется для любого состояния отношений.
Понятие ФЗ играет фундаментальную роль в теории реляционных баз данных и требует формального определения.
Определение ФЗ. Пусть R – отношение со схемой R(X, Y, Z), где X, Y и Z – атрибуты R. Отношение R удовлетворяет функциональной зависимости X
Y, если мощность отношений (результатов) следующих двух предложений языка SQLSELECT X, Y
FROM R;
и
SELECT DISTINCT X, Y
FROM R;
будет одинакова.
Первое предложение определяет срез на отношении R, а второе предложение является аналогом операции проекции реляционной алгебры.
Срезом называют совокупность кортежей отношения, получаемую после удаления из него невыбранных столбцов.
Результатом первого предложения всегда будут все строки присутствующие в отношении R, а результатом второго предложения будет "чистое" отношение, т.е. повторяющиеся строки в ответе будут отсутствовать.
Можно считать функциональную зависимость одним из способов описания ограничений целостности базы данных.
Количество функциональных зависимостей для отношения R конечно и их полное множество, которое можно определить, применив специальные правила, называемые аксиомами вывода, которые утверждают, что если отношение удовлетворяет определенным ФЗ, то оно должно удовлетворять и другим функциональным зависимостям. Рассмотрим их.
АКСИОМА РЕФЛЕКСИВНОСТИ
Любая функциональная зависимость рефлексивна по определению, т.е. Х
X.Следствие. Если Y
 X, то имеет место функциональная зависимость Х Y.
X, то имеет место функциональная зависимость Х Y.Действительно, каждый кортеж проекции отношения на X, в силу того, что Y
X, содержит в себе и соответствующий кортеж проекции на Y, что и требовалось доказать.Пусть, например, имеется отношение R(A, B, C, D), на котором определено и некоторое множество функциональных зависимостей F.
Пусть, далее, Х={B, C, D}, а Y={B, D}, очевидно, что Y
X. Если состояние Ri отношения R имеет вид:| Ri(A, B, C, D) | тогда | R[B, C, D] | | R[B, D] |
| a1 b1 c1 d1 | | b1 c1 d1 | | b1 d1 |
| a2 b1 c2 d2 | | b1 c2 d2 | | b1 d2 |
| a3 b2 c1 d1 | | b2 c1 d1 | | b2 d1 |
| a4 b1 c1 d1 | | | | |
т.е. одной и той же совокупности значений атрибутов, входящих в Х, всегда соответствует одна и та же совокупность значений атрибутов, входящих в Y.
Правило дает так называемые тривиальные зависимости Х
X, XY X и т.д., которые характеризуются тем, что атрибуты, входящие в правую часть ФЗ, полностью содержатся среди атрибутов левой ее части.АКСИОМА ПОПОЛНЕНИЯ
Функциональная зависимость XYZ
Y принадлежит полному множеству функциональных зависимостей, если на отношении R выполняется X Y и Z AR, X AR, Y AR.Данное правило показывает, что если в R существует Х
Y, то к левой части функциональной зависимости можно прибавить любые атрибуты, принадлежащие AR, что определит зависимости, принадлежащие полному множеству функциональных зависимостей.Пример. Пусть задано отношение R(A, B, C, D), на котором определено множество функциональных зависимостей F = {A
B}, и пусть состояние Ri отношения R следующее:| Ri(A, B, C, D) |
| a1 b1 c1 d1 |
| a1 b1 c1 d2 |
| a2 b2 c2 d2 |
| a3 b1 c3 d3. |
Тогда, согласно аксиоме пополнения, отношение R будет удовлетворять и следующим зависимостям: {AB
B, AC B, AD B, ABC B, ACD B, ABD B, ABCD B}.Еще аксиому пополнения можно сформулировать следующим образом. Если Z
AR, X AR, Y AR и задана зависимость Х Y, которая либо принадлежит множеству функциональных зависимостей, либо получена из нее с использованием правил вывода, то X U Z Y U Z (для краткости запись X U Z Y U Z будет в дальнейшем записываться в виде: XZ YZ).Для аксиомы пополнения не существенно, перекрываются множества X, Y, Z или нет. Согласно этой аксиоме, любые атрибуты из множества AR можно подставить (но одновременно) и в правую и в левую части выражения функциональной зависимости, при этом функциональная зависимость сохраняется.
АКСИОМА ПСЕВДОТРАНЗИТИВНОСТИ
Если X, Y, Z и W - подмножества атрибутов отношения R, для которого выполняются зависимости X
Y и YZ W, то для него справедлива и зависимость XZ W.