
Лабораторная работа №2 Тема: Формирование выборки случайных чисел, распределенных по заданному закону распределения
| Вид материала | Лабораторная работа |
- Вопросы к экзамену по дисциплине «теория массового обслуживания», 20.42kb.
- Лабораторная работа 1-08 экспериментальное изучение гауссовского закона распределения, 108.63kb.
- Лабораторная работа №7 Технологии разработки распределенных информационных систем, 168.59kb.
- Основные виды случайных величин, 28.43kb.
- Функция распределения. Плотность распределения. Основные параметры непрерывных случайных, 7.05kb.
- Лабораторная работа №1 «Численное решение нелинейных уравнений», 64.59kb.
- Лабораторная работа №3 кпк лабораторная работа №3 Тема: карманный персональный компьютер, 173.34kb.
- M и в качестве результата взять остаток от деления, 127.46kb.
- Методические указания к лабораторным работам Лабораторная работа, 357.24kb.
- Асимптотически оптимальная плотность распределения случайных узлов в формулах Ньютона−Котеса, 14.58kb.
Лабораторная работа №2
Тема: Формирование выборки случайных чисел, распределенных по заданному закону распределения.
Цель: освоение методов генерации последовательности значений случайных величин и построения графиков функций распределения и плотности непрерывных и дискретных случайных величин.
Задания
1. Изучите методы получения случайных величин с заданным законом распределения.
2. Разработайте программу генерации значений случайной величины, распределенной по закону Пуассона, используя для этого любой язык программирования.
3. Получите значения 100 случайных величин, распределенных по закону Пуассона, с использованием разработанной программы для своего варианта из таблицы 2.
4. Постройте графики распределения плотностей вероятностей (теоретический, используя стандартные функции Excel и практический, используя стандартный встроенный генератор).
5. Оцените соответствие экспериментального и теоретического распределения случайных величин.
6. Получите также значения 100 случайных величин, распределенных по нормальному закону распределения; построить графики распределения плотности вероятностей; оценить соответствие экспериментального и теоретического распределения случайных величин.
7. Получите также значения 100 случайных величин, распределенных по экспоненциальному закону распределения; построить графики распределения плотности вероятностей; оценить соответствие экспериментального и теоретического распределения случайных величин.
8. Сделайте отчет по работе.
Содержание отчета
1. Название и цель лабораторной работы.
2. Задание по варианту.
3. Краткое описание и формула получения случайных величин для каждого закона распределения.
4. Последовательность 100 значений случайных величин (по 10 чисел в одной строке), полученных по всем указанным законам распределения.
5. Графики распределения плотностей вероятностей случайных величин по закону Пуассона (теоретический и экспериментальный).
6. Графики распределения плотностей вероятностей случайных величин по нормальному закону (теоретический и экспериментальный).
7. Графики распределения плотностей вероятностей случайных величин по экспоненциальному закону (теоретический и экспериментальный).
8. Выводы по каждому закону распределения.
Таблица 2.
| Номер варианта | Пуассоновское распределение | Экспоненциальное распределение | Нормальное распределение | |
| | ТНЕТА() | Мх | 2 | |
| 1 | 1,0 | 0,33 | 0,15 | 2,55 |
| 2 | 1,1 | 0,44 | 0,22 | 2,22 |
| 3 | 5,2 | 0,45 | 0,33 | 2,07 |
| 4 | 1,4 | 0,55 | 0,45 | 1,91 |
| 5 | 1,5 | 0,66 | 0,51 | 2,11 |
| 6 | 4,6 | 0,75 | 0,62 | 1,88 |
| 7 | 1,8 | 0,72 | 0,77 | 2,33 |
| 8 | 2,0 | 0,83 | 0,83 | 1,77 |
| 9 | 5,5 | 0,94 | 0,91 | 2,44 |
| 10 | 3,0 | 1,08 | 1,05 | 0,66 |
| 11 | 4,0 | 1,11 | 1,22 | 0,58 |
| 12 | 5,0 | 1,22 | 1,41 | 0,43 |
| 13 | 6,0 | 1,33 | 1,63 | 0,37 |
| 14 | 7,0 | 1,44 | 1,82 | 0,25 |
| 15 | 8,0 | 1,55 | 2,05 | 0,19 |
| 16 | 2,5 | 1,65 | 1,37 | 1,28 |
| 17 | 1,2 | 1,77 | 1,28 | 0,95 |
| 18 | 3,8 | 0,25 | 1,85 | 0,83 |
| 19 | 7,6 | 0,29 | 1,95 | 2,33 |
| 20 | 1,7 | 1,25 | 1,72 | 2,41 |
| 21 | 3,2 | 0,88 | 1,65 | 1,82 |
| 22 | 8,2 | 0,62 | 1,54 | 2,66 |
| 23 | 5,7 | 0,33 | 1,48 | 2,78 |
| 24 | 6,3 | 0,71 | 1,29 | 1,33 |
| 25 | 1,3 | 1,99 | 1,11 | 1,44 |
| 26 | 2,2 | 0,22 | 1,76 | 1,55 |
| 27 | 3,3 | 1,98 | 1,67 | 2,37 |
| 28 | 4,4 | 1,09 | 1,17 | 1,92 |
| 29 | 5,5 | 0,91 | 1,71 | 0,51 |
| 30 | 6,6 | 0,39 | 1,81 | 2,55 |
Теоретические сведения.
Случайной величиной называется величина, принимающая случайные значения, зависящие от ряда факторов, действия которых на исследуемую величину нельзя предусмотреть.
Полный набор значений, которые принимает случайная величина, называется генеральной совокупностью. Набор случайно отобранных из генеральной совокупности объектов называют выборочной совокупностью или выборкой. Объёмом совокупности называют число объектов в ней. При больших объёмах генеральной совокупности для обеспечения теоретических построений объём генеральной совокупности принимается равным бесконечности.
При исследовании систем массового обслуживания (СМО) широкое применение находят различные непрерывные и дискретные распределения. Первые из них описывают непрерывные случайные величины, возможные значения которых непрерывно заполняют некоторый промежуток. Дискретные распределения соответствуют дискретным случайным величинам, возможными значениями которых являются отдельные изолированные числа, которые эта величина принимает с определенными вероятностями.
Примерами случайных непрерывных величин, с которыми приходится иметь дело в процессе исследования СМО, могут служить интервалы между моментами поступления требований в систему, время обслуживания требования и т д. Примерами дискретных случайных величин могут быть число требований, прибывающих в систему за некоторый фиксированный промежуток времени, длина очереди, число отказов в системе и т д.
Случайная величина характеризуется полностью, если указаны вероятности, с которыми она принимает то или иное значение генеральной совокупности. Вероятности могут быть описаны с помощью интегральной функции распределения F(x) или дифференциальной функции плотности распределения f(x).
Функция распределения (закон распределения) определяет вероятность (Р(x)) того, что случайная величина X принимает значение не больше заданного, т.е. F(x)=P(X
Плотность распределения вероятности случайной величины X – это функция f(x) – первая производная от функции распределения F(x)
f(x)=F'(x)
Теорема. Вероятность того, что непрерывная случайная величина X примет значение, принадлежащее интервалу (a,b), равна определенному интегралу от плотности распределения, взятому в пределах от a до b:
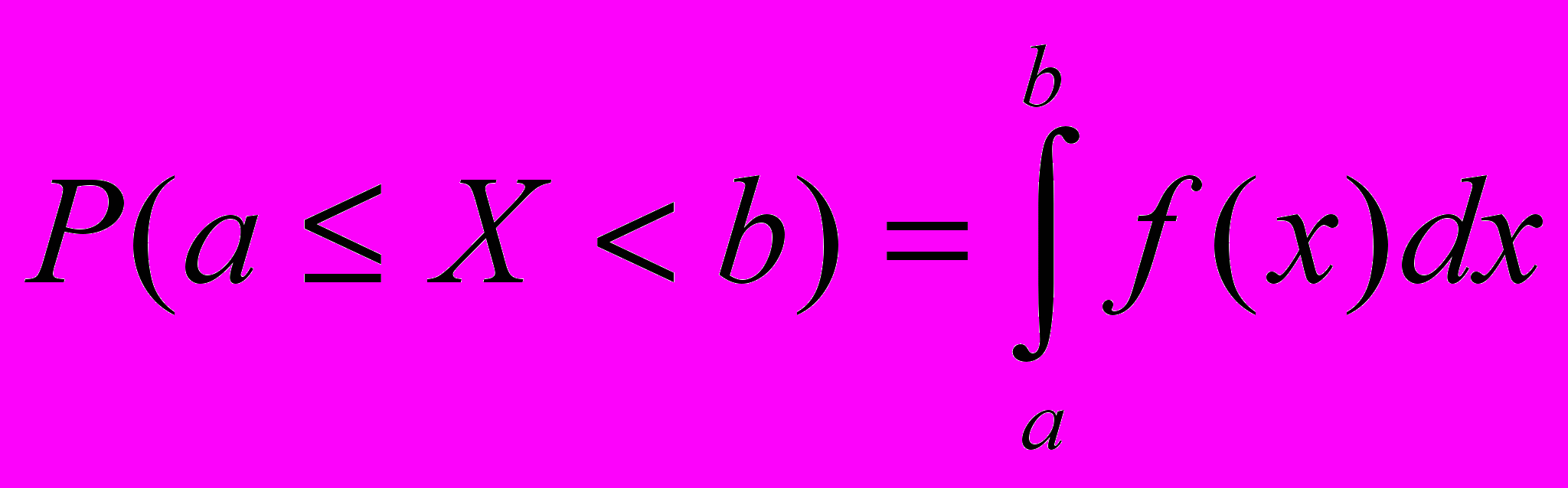
Среднее значение случайной величины называется математическим ожиданием.
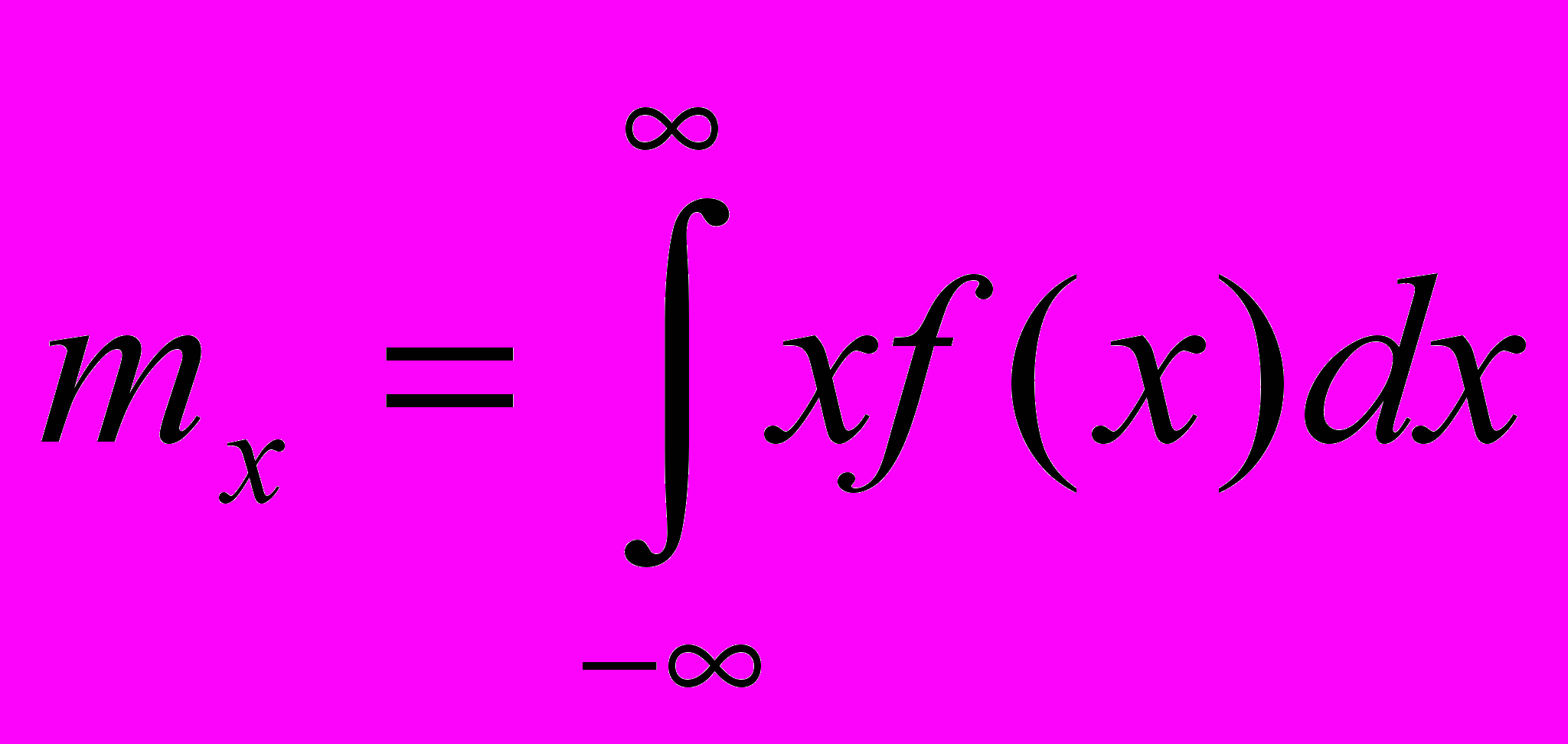
Дисперсия - это математическое ожидание квадрата отклонения величины x от центра её распределения mx:
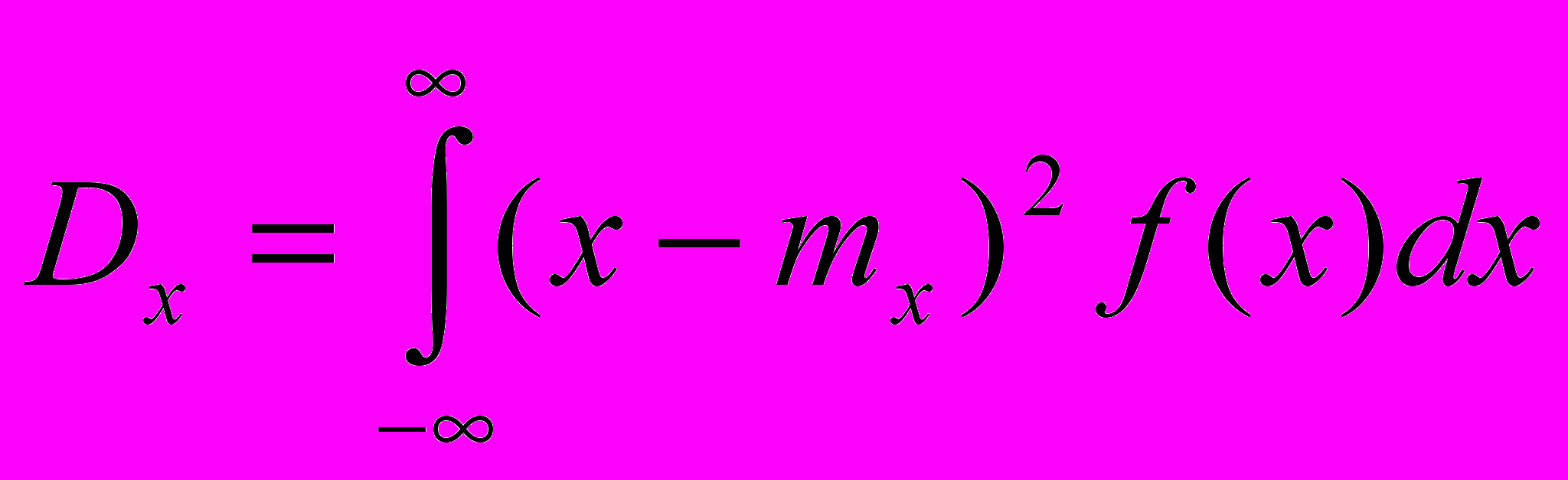
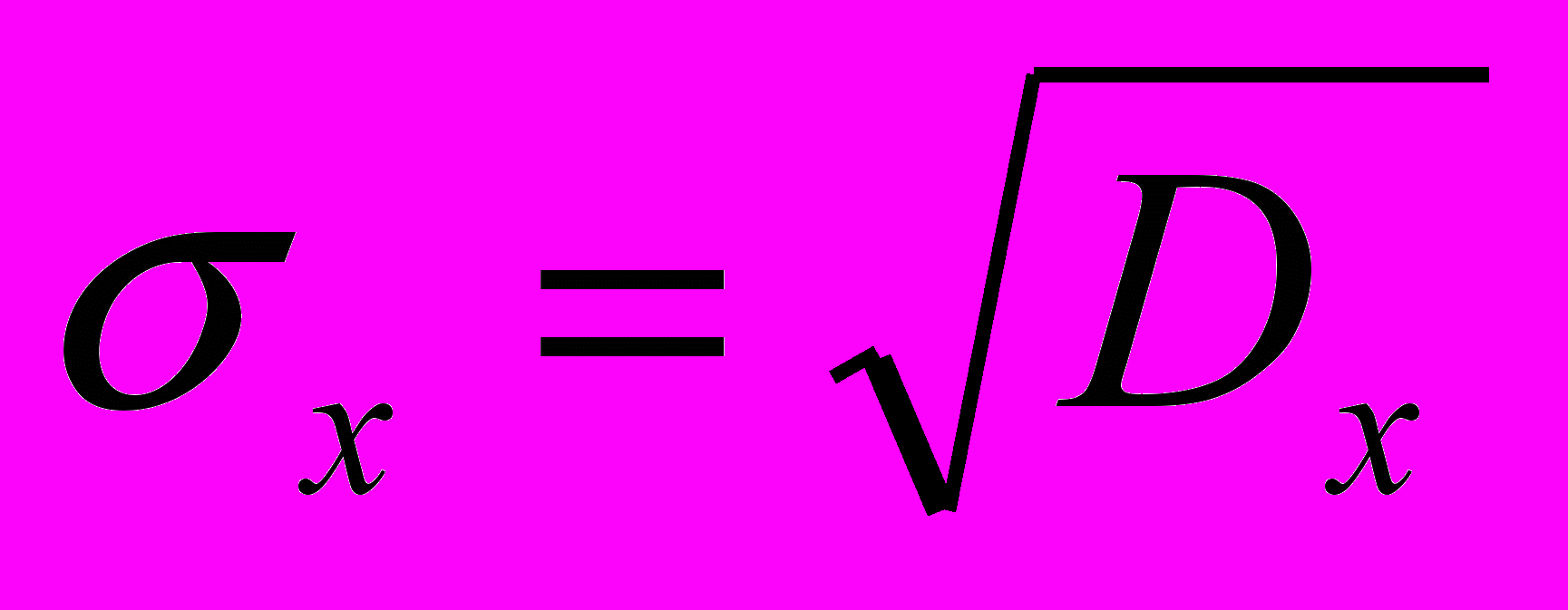 - среднее квадратическое отклонение (стандартное отклонение).
- среднее квадратическое отклонение (стандартное отклонение).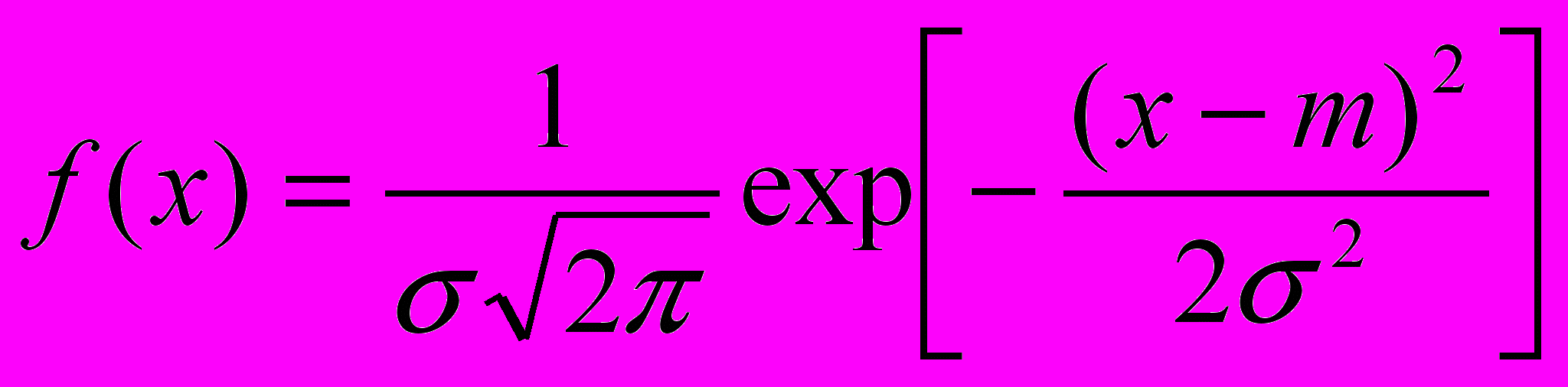 - плотность нормального распределения.
- плотность нормального распределения.Рассмотрим основные способы моделирования непрерывных и дискретных случайных величин с заданными законами распределения.
Равномерное распределение. При моделировании случайных величин особое место занимает непрерывное распределение, называющееся равномерным. Функция плотности вероятности случайной величины, имеющей равномерное распределение на интервале (a, b), имеет вид:
 (2.1)
(2.1)Большинство способов моделирования случайных величин основано на использовании псевдослучайных р
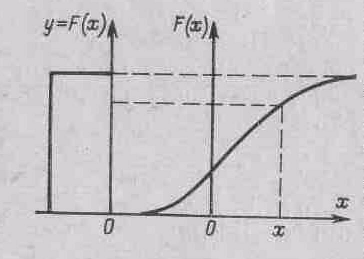
Рис.1. Принцип преобразования равномерного распределения в заданное
авномерно распределенных в интервале (0,1) последовательностей чисел. При этом в основу положена следующая известная в математической статистике теорема: если случайная величина X имеет плотность распределения f(x), то распределение случайной величины Y=F(x) является равномерным в интервале (0, 1)
Таким образом, задаваясь функцией распределения F(x), можно выбирать случайное значение Y из равномерного распределения в интервале (0,1) и определять значение аргумента, для которого F(x)=Y (рис.2.1). Полученная таким образом случайная величина X будет иметь заданную функцию распределения F(x). Эта операция может быть представлена аналитически следующим выражением:
 (2.2)
(2.2)согласно которому определяется значение хi, соответствующее значению функции распределения, равному yi. Для некоторых частных законов распределения уравнение (2.2) удается решить непосредственно, в других случаях прибегают к приближенным способам решения, в частности к аппроксимации подынтегральной функции полиномами, интегрируемыми в квадратурах.
Моделирование дискретных случайных величин с известным распределением вероятностей в общем случае производится следующим образом. Предположим, что заданы численные значения вероятностей p1, p2, ..., pп для независимых событий А1, А2, ..., Ап, составляющих полную группу. В соответствии с этим интервал (0,1) разбивается на п отрезков так, чтобы длина i-го отрезка равнялась вероятности pi. Производя выборку случайных чисел ξi из равномерного распределения в интервале (0,1), будем определять, на какой отрезок попадает число ξi. Попадание числа на i-й отрезок фиксируется как факт свершения события Аi .
Другой способ моделирования дискретных величин состоит в формировании интервалов между моментами наступления соседних событий. При этом задача сводится к уже описанному выше случаю моделирования непрерывной случайной величины.
Экспоненциальное распределение. Непрерывная случайная функция, распределенная по экспоненциальному закону, имеет функцию распределения F(x) и плотность распределения f(x) вида:
 (2.3)
(2.3) (2.4)
(2.4)Значения математического ожидания и дисперсии для экспоненциального закона распределения равны соответственно 1/λ и 1/λ2.
Экспоненциальное распределение занимает в теории массового обслуживания особое место. Это связано с тем, что распределение многих величин, таких, например, как интервалы между наступлениями соседних событий, времена обслуживания и др., во многих задачах массового обслуживания принимаются имеющими экспоненциальное распределение. Хотя реальные распределения (в частности распределение времени обслуживания) часто существенно отличаются от экспоненциального, использование последнего позволяет намного упростить решение задач. Кроме того, использование экспоненциального распределения позволяет получить во многих случаях оценку для более напряженного режима обслуживания.
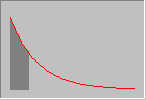
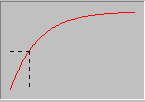
Рис. 2 Функция плотности и распределения для экспоненциального закона распределения
Для моделирования случайных величин xi ,имеющих экспоненциальное распределение, можно воспользоваться непосредственным решением уравнения (2.2). Действительно, с учетом (2.4) получаем:
 (2.5)
(2.5)После интегрирования имеем:
 (2.6)
(2.6)Поскольку случайная величина (1-i) имеет также равномерное распределение в интервале (0,1) окончательно получаем:
xi = -(1 / ) ln i = - ln i (2.7)
где альтернативной параметризацией является параметр масштаба θ=1/λ).
Алгоритм формирования значений случайной величины, распределенной по экспоненциальному закону:
- Вводятся исходные значения: количество генерируемых величин N (не менее 100) и математическое ожидание экспоненциального закона распределения (THETA);
- Обнуляется переменная К для подсчета количества генерируемых случайных величин;
- Генератор псевдослучайных чисел формирует число;
- Вычисляется случайная величина по формуле 2.7;
- Значение величины выводится на печать;
- Значение счётчика случайных величин увеличивается на единицу;
- Процедура формирования случайных величин повторяется до тех пор, пока не будет получено заданное количество.
Нормальное распределение. Большое число стохастических процессов описываются нормальным распределением (законом Гаусса). Этот закон, согласно теореме Ляпунова, справедлив в случаях, когда результат (исход) процесса зависит от большого числа независимых случайных факторов, каждый из которых в отдельности влияет на результат незначительно.
Нормальный закон распределения характеризуется плотностью вероятности:
(2.8)И имеет функцию распределения:
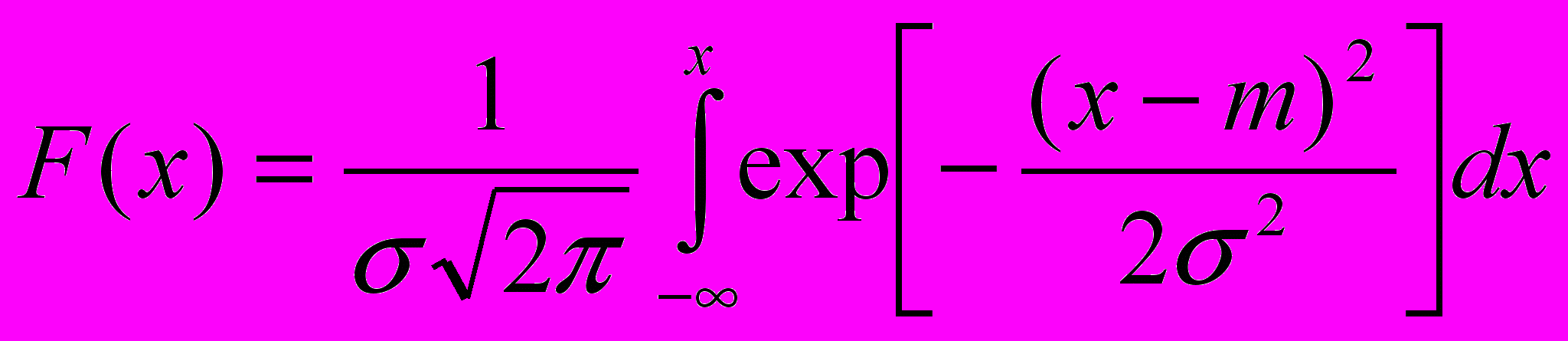 (2.9)
(2.9)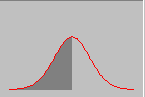
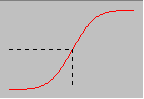
Рис. 3 Функция плотности и функция распределения для нормального закона распределения вероятностей
Распределение Пуассона. Распределение Пуассона нашло очень широкое применение в теории массового обслуживания для моделирования потоков событий, поскольку оно является единственным распределением, позволяющим в большинстве случаев достаточно легко получать результаты.
Потоком событий называется последовательность событий, наступающих одно за другим в случайные моменты времени.
Поток событий называется пуассоновским если он удовлетворяет распределению Пуассона, является ординарным и не имеет последействия.
Дискретная случайная величина X называется распределенной по закону Пуассона, если ее возможными значениями являются 0,1,2, ... m ..., а вероятность того, что Х=т, выражается формулой
 (2.10)
(2.10)где а>0 — параметр закона Пуассона. Для пуассоновского потока число событий, попадающих на любой участок времени (t0 ,t0+τ), распределения в соответствии с выражением (2.10), причем математическое ожидание числа точек, попадающих на этот участок, равно:
 (2.11)
(2.11)В выражении (2.11) λ(t) есть плотность потока. В частности, если λ(t)=const, то пуассоновский поток называется стационарным пуассоновским или простейшим.
Для простейшего потока вероятность появления k событий за время т определяется законом Пуассона с параметром а= λτ, т. е.
 (2.12)
(2.12)Расстояние Т между двумя соседними событиям в простейшем потоке есть непрерывная случайная величина, распределенная по экспоненциальному закон с функцией распределения
 (2.13)
(2.13)Моделирование пуассоновского потока может производиться двумя способами, соответствующими выражениям (2.10) и (2.13). При первом способе в соответствии с заданными численными значениями вероятностей P1 , Р2, ..., Рп независимых событий A1 А2, ..., Ап производится разбиение интервала (0, 1) на п отрезков так,, чтобы длина 1-го отрезка равнялась вероятности Р. Затем, выбирая из равномерного распределения в интервале (0, 1) случайные числа ξi определяют, на какой из отрезков попадает число ξi . Попадание случайного числа на i-й участок фиксируется как факт свершения события Аi.
Справочная информация по технологии работы в среде ППП EXCEL
Проведение имитационных экспериментов в среде ППП EXCEL можно осуществить путем использования инструмента "Генератор случайных чисел" дополнения "Анализ данных" (Analysis ToolPack). Если дополнение не установлено, установить его можно через меню "Сервис". Выбрать пункт "Надстройки" и поставить галочку напротив этого дополнения.
В режиме работы "Генерация случайных чисел" формируется массив случайных чисел. В зависимости от выбранного теоретического распределения меняются параметры диалогового окна Генерация случайных чисел. Общими параметрами для всех подрежимов (распределений) являются:
- число переменных – вводится число столбцов значений, которые необходимо разместить в выходном диапазоне, если число не введено, то все столбцы будут заполнены;
- число случайных чисел – вводится число случайных значений, которое необходимо вывести, если число не введено, то все строки будут заполнены;
- распределение – из раскрывающегося списка выбирается тип распределения;
- случайное рассеивание – вводится стартовое число для генерации определенной последовательности СЧ;
- выходной интервал.
Строить графики дифференциальных и интегральных функций распределения удобно с помощью мастера диаграмм. Для этого необходимо предварительно сформировать интегральные и дифференциальные массивы значений, для этого использовать функцию, соответствующую выбранному распределению, используя в качестве её аргументов сгенерированную последовательность СЧ.
Пример
Для закупки и последующей реализации мужских курток фирмой было проведено выборочное обследование мужского населения города в возрасте от 18 до 65 лет в целях определения его среднего роста. В результате было установлено, что средний рост 176 см, стандартное отклонение 6 см. Необходимо определить, какой процент общего числа закупаемых курток должны составлять куртки пятого роста (182-186 см). Предполагается что рост мужского населения распределен по нормальному закону. Построить графики функции и плотности распределения
Решение
Сначала в MS Excel последовательность случайных чисел. Для этого:
1. вызовем из меню Сервис команду Анализ данных→Генерация случайных чисел.
2. Заполним диалоговое окно как показано на рис.4.
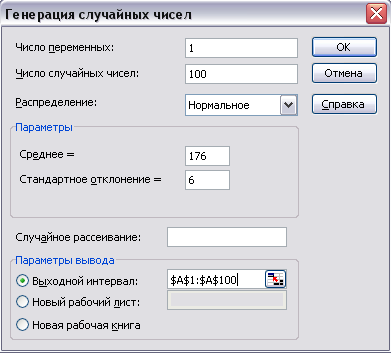
Рис.4.
После нажимаем кнопку OK и в указанном нами диапазоне получаем последовательность псевдослучайных чисел.
3. Упорядочиваем их по возрастанию.
4. Для подсчета значений функции плотности нормального распределения используем функцию НОРМРАСП с аргументом интегральная=0. Таким образом, по формуле представленной на рис. 5 для числа x=154,6192 из ячейки А1 получим значение = 0,000116

Рис.5.
5. Значения функции распределения считаем используя функцию НОРМРАСП с аргументом интегральная=1. Таким образом, по формуле представленной на рис. 6 для числа x=154,6192 из ячейки А1 получим значение = 0,000183

Рис.6.
6. Решаем задачу по формуле:
=НОРМРАСП(186;176;6;1)-НОРМРАСП(182;176;6;1)=0,949675-0,84109=10,858≈11%
Вывод: куртки 5-го роста должны составлять приблизительно 11% от общего числа закупаемых курток.
7. Строим графики полученных функций, используя мастер диаграмм. Выделяем диапазон ячеек А1:С100 и вызываем мастер диаграмм.
8. На первом шаге выбираем тип диаграммы – точечная, вид – со сглаживающими линиями без маркеров.
9. На втором шаге проверяем правильность выбранного диапазона данных.
10. Указываем параметры диаграммы на третьем шаге и расположение на четвертом. Нажимаем кнопку Готово. Получаем результат (рис.7)
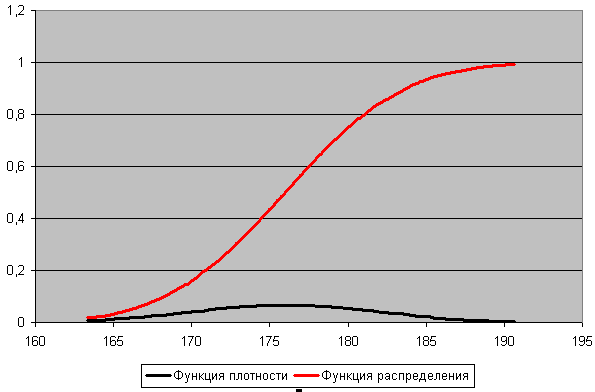
Рис.7.