
Г. М. Сергиевский национальный исследовательский ядерный университет «мифи» latemmephi@yandex ru Об одном варианте использования процедурного подхода для моделирования адаптивного поведения рассматривается задача
| Вид материала | Задача |
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи, 117.71kb.
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи на 2-ой, 78.89kb.
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи на 2-ой, 142.79kb.
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи на 2-ой, 42.54kb.
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи на 2-ой, 104.65kb.
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи на 2-ой, 91.39kb.
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи на 2-ой, 150.35kb.
- Программа аттестационного собеседования для поступающих в иатэ нияу мифи на 2-ой, 183.32kb.
- Одиннадцатый конкурс молодежных инновационных проектов технопарка мифи, 45.49kb.
- А. А. Фатьянов национальный исследовательский ядерный университет «мифи» проблемы совершенствования, 22.17kb.
Г. М. СЕРГИЕВСКИЙ
Национальный исследовательский ядерный университет «МИФИ»
latemmephi@yandex.ru
ОБ ОДНОМ ВАРИАНТЕ ИСПОЛЬЗОВАНИЯ ПРОЦЕДУРНОГО ПОДХОДА ДЛЯ МОДЕЛИРОВАНИЯ АДАПТИВНОГО ПОВЕДЕНИЯ
Рассматривается задача моделирования адаптивного поведения, обсуждаются требования к моделям, реализующим такое поведение, делается вывод об обоснованности применения процедурного подхода для моделирования адаптивного поведения. Процедурный подход понимается как использование соответствующего сложности задачи «процессора адаптивного поведения», реализующего синтезированную в ходе обучения «программу поведения». Обсуждается концепция построения класса «процессоров адаптивного поведения» для задач разного уровня сложности и принципы синтеза «программ поведения» посредством обучения. Приводится пример построения программы, моделирующей поведение животного в лабиринте.
Введение
Моделирование адаптивного поведения (АП) представляет собой одну из центральных задач в области когнитивных исследований. Создание таких моделей даст лучшее понимание механизмов когнитивных процессов, что, в свою очередь, будет стимулировать биологические исследования по отысканию соответствующих носителей. Это обеспечит значительное продвижение в исследованиях по созданию аниматов и других нейроподобных систем технического назначения, а также продвижение в решении обратных задач (определение параметров моделей поведения лабораторных объектов (ЛО), идентифицированных по результатам наблюдения за ними) и многое другое. К сожалению, в настоящий момент не существует общепризнанной адекватной модели АП, нет даже единого представления об используемых парадигмах для ее представления [1]. Как отмечает В.А. Непомнящих [2], «создание действительно автономных агентов остается только перспективой. Зато можно сделать вполне определенный вывод о том, что в настоящее время отсутствует теоретическая основа для создания аниматов. Другими словами, отсутствует теория адаптивного поведения».
Сложность решения подобной задачи, по мнению автора, во многом связана с тем, что механизмы «процедурной памяти» (без обращения к которым врядли возможно адекватное моделирование данных процессов) недостаточно исследованы. Назовем некоторые характерные черты адаптивного поведения, которые трудно обеспечить вне процедурного подхода:
- способность обеспечивать реакцию на внешние стимулы, которая зависит не только от текущих стимулов, но и от ранее поступивших стимулов и выполненных действий,
- способность выполнять вполне определенную и часто достаточно длинную последовательность действий,
- способность обеспечивать алгоритмическую мощность уровня машины Тьюринга (при реализации наиболее сложного адаптивного поведения).
Классический подход к моделированию движения, развитый в современной теории управления, оказывается неадекватным поставленной задаче. В рамках теории управления отсутствуют понятия "обучаемость", "опыт", "процедурная память" и пр., которые характеризуют биологическую систему управления. Понимание ограниченных возможностей классической теории управления, а также компьютерных методов на основе чисто нейросетевых моделей привело к развитию различных «процедурных» расширений последних (рекуррентные, рекурсичные и др. нейросетевые модели). Однако, это не привело пока к созданию вполне адекватных формализаций когнитивных процессов. По-видимому, одной из главных причин этого является то, что для более «программных» расширений до недавнего времени не были разработаны механизмы их синтеза посредством обучения. Именно наличие моделей обучения в нейросетевой парадигме сделало ее столь популярной в задаче описания когнитивных процессов. Однако к настоящему времени появились определенные предпосылки для использования более «процедурных моделей». Наиболее последовательно задачи синтеза программ по примерам исследуются в направлении, называемом «индуктивное программирование» (Inductive Programming), представляющим собой одно из направлений Computer Science. Состояние исследований в этой области можно оценить, например, по материалам, размещенным на сайте [3], типичная постановка задачи приведена в [4].
В соответствии с этой постановкой [4] задача ставится следующим образом. Задана обучающая выборка в виде множества пар (вход, выход), в которых вход и выход представляют собой значения некоторого алгебраического типа данных (обычно это списочные структуры). Задача состоит в том, чтобы найти процедуру-функцию, в некотором смысле имеющую наиболее короткое описание, которая на каждый вход из выборки вырабатывает соответствующий ей выход, но, также оказывается способной вычислять выход на входах, не принадлежащих обучающей выборке. Процесс синтеза состоит из двух этапов [4]. На первом этапе по обучающей выборке строится нерекурсивная и ациклическая программа, которая определена только на входах из выборки, для которых она возвращает соответствующие им выходы (отметим, что этот этап является наименее обоснованным в данном подходе, так как существует бесчисленное множество способов построения такой программы, но от вида ее существенно зависит конечный результат). На втором этапе построенная программа (представленная своим текстом) подвергается процедуре «генерализации». Эта процедура в общем случае пытается за счет поиска циклов (в [4] этот способ не используется) и определения новых рекурсивных процедур-функций найти более короткую запись текста полученной на первом этапе программы. При этом автоматически достигается эффект обобщения.
Для поставленной задачи моделирования наибольший интерес имеет этап генерализации, так как он может послужить моделью некоторых процессов формирования «процедурных знаний» у ЛО. В этом случае в качестве синтезируемой процедуры выступает та самая процедура, которая моделирует поведение ЛО (управляет действиями ЛО), а примерами для обучения выступают примеры действий ЛО, направленные на достижение целевого состояния. В случае, если рассматривается задача идентификации модели поведения ЛО на основании наблюдений за его поведением, эти наблюдения необходимо представить в терминах «внутренней модели» ЛО [1]. В случае работы анимата данное поведение генерируется аниматом на основе встроенной в него программы поиска решений в проблемной ситуации (образованной внешней средой и целевыми установками, определяющими условия, выполнение которых принимается за нахождение решения). Данный подход также можно применять и для постановки «обучения по примерам». В этом случае необходимо предположить наличие «встроенной» программы у ЛО, наблюдающего за поведением другого ЛО, которая выполняет перевод этих наблюдений во внутреннюю форму. В следующем разделе приводится более подробное обсуждение данного подхода.
Используемая терминология
Для изложения концепции предварительно определим терминологию:
- Лабораторный объект (ЛО) - лабораторное животное (в том числе человек) или анимат,.
- Пространство состояний (ПС) - конечное или бесконечное множество состояний, которые характеризуются набором свойств (их анализ доступен решателю) и для каждого из которых определено множество возможных действий решателя (может быть пустое). Каждое действие приводит к переходу из текущего состояния в другое, соответствующее этому действию, состояние. Некоторые состояния являются «желательными», попадание в которых рассматривается как успех, другие состояния могут быть нейтральными или «нежелательными».
- Проблемная ситуация - поставленная перед решателем задача поиска последовательности действий, которые позволяют перейти из заданного начального состояния (оно может меняться в разных запусках решений) в какое-либо желательное (будем их называть целевыми), минуя нежелательные состояния. Множество возможных проблемных ситуаций образует проблемную область. Если нет никакой априорной информации о пространстве состояний, то единственным способом перейти в целевое состояние является тот или иной вариант перебора всех возможных действий в каждом состоянии [6]. Найденная последовательность действий, обеспечивающая переход в желательное состояние, называется решающей последовательностью. Если свойства пространства состояний не меняются, то найденная решающая последовательность (или последовательности) может быть запомнена, что позволит в следующий раз выполнять переход в целевые вершины без перебора. ПС обычно представляется графом, в котором состояниям соответствуют вершины, а действиям – дуги, помеченные именем действия. Требования к решателю зависят от свойств пространства состояний, среди которых для данной задачи важны следующие:
- помеченность состояний, т.е. может решатель обнаружить, что он попал в конкретное уже посещенное состояние (вариант с1) или не может (вариант с2),
- помеченность дуг, т.е. имеется ли в каждом состоянии конечный набор дуг имена которых известны решателю (вариант д1) или формирование действия может быть сделано через свойства текущей вершины (вариант д2),
- наличие (или отсутствие) параметров у состояний, которые должны обрабатываться в ходе решения проблемной ситуации.
Предлагаемая концепция моделирования АП
Содержание концепции изложим в виде следующих тезисов:
- Поведение лабораторного объекта рассматривается как поиск решающей последовательности в пространстве состояний, а сам объект – как решатель.
- Функционирование решателя осуществляется за счет (искусственного или «биологического») процессора адаптивного поведения (ПАП), устройство которого для успеха жизнедеятельности ЛО должно быть адекватно свойствам проблемной области.
- Функционирование процессора определяется действующей на нем программой поведения (ПП).
- Программа поведения синтезируется в режиме обучения либо в ходе поиска решающей последовательности с помощью собственной активности (обучение с подкреплением) либо на основе обучения по примерам.
- Программа поведения, которая в данный момент является активной, определяет действия ЛО в каждый момент времени в зависимости от полученных к этому моменту данных от рецепторов, ранее выполненных действий, а также текущих целевых установок (мотивационного состояния) ЛО.. Предполагается, что действия ЛО происходят в дискретные моменты времени, которые можно пронумеровать (длительность действия и другие его параметры при необходимости могут быть представлены в качестве атрибутов действия). Если внешняя среда остается стабильной, программа поведения изменяется в результате обучения в сторону более рациональных действий.
- Каждое действие ЛО происходит в некотором (текущем) состоянии пространства состояний. Действия можно разделить на внешние и внутренние.
- Внешние действия представляются в упрощенном схематезированном виде и делятся на исследовательские действия (ИД), физические действия (ФД).
- ИД не меняют положение ЛО в пространстве состояний и, либо заканчиваются успехом или неуспехом (например, возможно ли движение направо, налево, прямо, есть ли пища и т.п.), образуя предикатные исследовательские действия, либо состоят в записи в память ПАП информации, сопоставленной состоянию с последующим распознаванием.
- ФД означают переход в новое состояние (т.е. они изменяют положение ЛО в пространстве состояний), а возможность их выполнения определяется результатами соответствующих им ИД.
- Внутренние действия могут означать вызов новой программы поведения или выполнение вспомогательных «вычислений» с помощью ПАП.
- Простейшая детерминированная версия ПАП поддерживает программы поведения, которые могут быть представлены диаграммой в виде ориентированного графа. Вершины графа (называемые состояниями вычислений) соответствуют реальным или потенциальным точкам разветвления (операторам типа CASE), а дуги помечены условиями (идентификаторами предикатных исследовательских действий) и действиями (физическими или внутренними, выполняемыми при истинности условий).
- Более адекватной для рассматриваемого применения является стохастический вариант ПАП, в котором вычислительным состояниям (вершинам диаграммы) сопоставляются стохастические CASE-операторы, работающие в наиболее сложном случае (c2, d2) под управлением нейронных сетей. По мере обучения вероятности переходов будут максимизироваться на дугах, обеспечивающих решающую последовательность.
- Механизм обучения (понимаемый как система автоматического синтеза программ), в совокупности с набором встроенных ПП (ориентировочная деятельность, варианты случайного поиска и т.п.) и, возможно. с некоторыми сформированными ПП, образует ядро ПАП каждого экземпляра ЛО (от способности ядра находить хорошие решения в проблемных ситуациях и запоминать эти решения зависит биологическая выживаемость ЛО).
- Исходным объектом для синтеза ПП являются протоколы вычислений (ПВ), представляющие собой запись выполненных действий – исследовательских вместе с их результатами и физических, имевших место в некоторый период времени в форме, которую ПАП может интерпретировать как программу поведения.
- При попадании ЛО в незнакомую проблемную область (например, сцену) вначале задействуются встроенные программы (ориентировочной деятельности, случайного поиска и др., так как сформированные программы для других сред и/или мотивационных состояний скорее всего окажутся бесполезными), которые и обеспечивают генерацию начальных протоколов вычислений.
- Протоколы вычислений, полученные в результате многократных попыток нахождения ЛО решающих правил в неизменной проблемной ситуации, обрабатываются в инкрементном режиме ядром ПАП, работа которого собственно и реализует процесс обучения (генерализацию протоколов).
Пример применения предлагаемого подхода
В задачах с лабораторными животными пространство состояний в большинстве случаев определяется свойствами сцены. Наиболее простое ПС имеет место для лабиринта, оно может быть определено, как (с1,д1). Наиболее сложное ПС имеет место, когда сцена представляет собой свободную поверхность (бассейн, клетка). Этот случай соответствует (с2, д2). В качестве иллюстративного примера рассмотрим известный эксперимент с крысами [7]. Есть Т-образный лабиринт, с двумя камерами, присоединяемыми к плечам лабиринта (рис. 1). Красная камера присоединена к правому плечу лабиринта, зеленая к левому плечу.
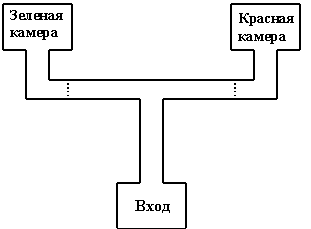
Рис.1. Схема лабиринта.
Представим себе гипотетический эксперимент, который является упрощением эксперимента, описанного в [7]. Будем считать, что крыса входит в лабиринт со стороны «входа», в зеленой камере она получает удар током, а в красной – пищу. Хорошо известно, что после нескольких повторений животное будет преимущественно перемещаются направо. В [7] построена нейросетевая модель, объясняющая поведение животных в описанном эксперименте. Приведем сильно упрощенное описание данного эксперимента и результатов синтеза программы поведения в терминах предлагаемого подхода.
На рис. 2 приведен граф пространства состояний, в котором знаками «+» и «-» отмечены желательные и нежелательные вершины, а также указаны возможные физические действия животного. Вершины, обозначенные цифрами 2. 3. 5 и 7 (их число может колебаться), соответствуют промежуточным исследованиям животного при движении вдоль длинных отрезков лабиринта.
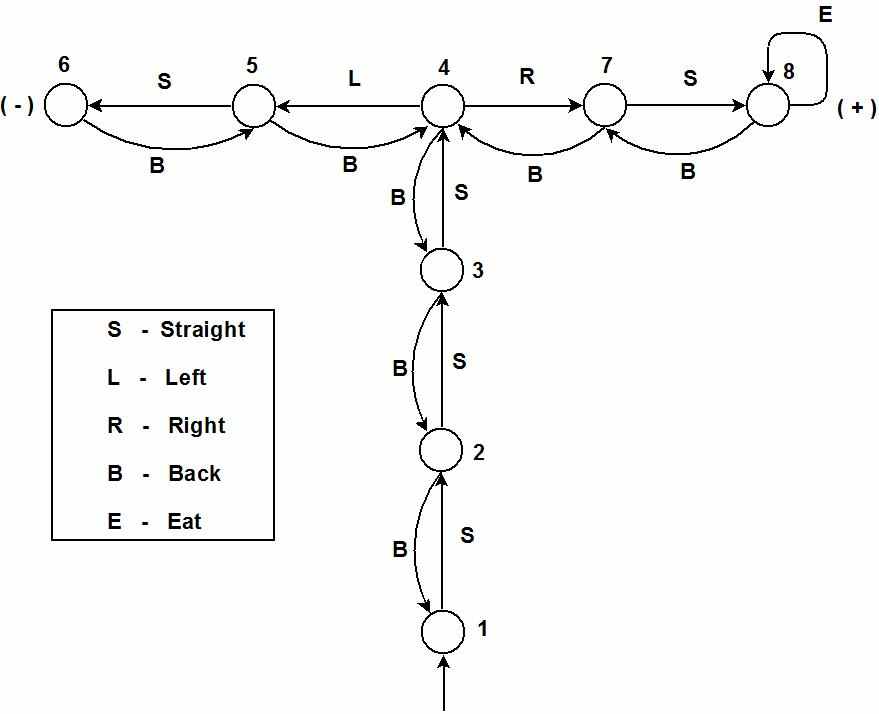
Рис. 2 Граф пространства состояний
Возможный протокол вычислений, соответствующей обходу лабиринта с предварительным заходом в зеленую камеру может иметь вид:
(⌐?r, ⌐?l,?s, ⌐e)/s; (⌐?r, ⌐?l,?s, ⌐e)/s; (⌐?r, ⌐?l,?s, ⌐e)/s; (?r, ?l,?s, ⌐e)/l; (⌐?r, ⌐?l,?s, ⌐e)/s; (⌐?r, ⌐?l,?s, ⌐e)/s; (-)/b; (⌐?r, ⌐?l,?s, ⌐e)/b; (⌐?r, ⌐?l,?s, ⌐e)/b; (?r, ?l, ⌐?s, ⌐e)/r; (⌐?r, ⌐?l,?s, ⌐e)/b; (⌐?r, ⌐?l,?s, ⌐e)/b;(+)/e.
На рис 3 приведена синтезированная по данному протоколу диаграмма программы поведения. В силу простоты проблемной области - фиксированного числа предикатных исследовательских действий (на рис. 3 они обозначены с помощью «?»), фиксированного числа соответствующих им физических действий и отсутствия параметров, в качестве ПАП может выступать автомат с конечным числом состояний. Для данного случая не представляет особого труда реализация механизма синтеза ПП в основе которого должны использоваться методы минимизации неполностью определенного конечного автомата.
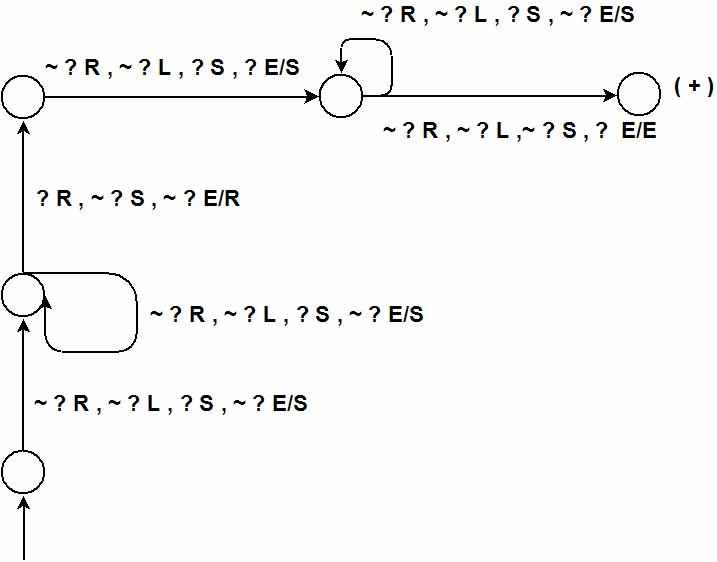
Рис. 3 Диаграмма ПП, реализуемая ПАП в классе конечных автоматов
Выводы
Предлагаемый подход позволяет привлечь к задаче моделирования АП новые парадигмы, основанные на методах индуктивного синтеза программ. Особенно перспективно, на взгляд автора, его применение для создания аниматов. С другой стороны, если считать, что данный способ синтеза программ поведения в определенной степени моделирует когнитивные процессы, реализуемые «биологическим компьютером» животных, то появляется задача экспериментального обнаружения биологических механизмов для его реализации. Из-за недостатка места в данной статье не было возможности подробно описать сами алгоритмы синтеза, тем более для более мощных процессоров адаптивного поведения. На алгоритмическом уровне эти задачи в основном решены и в планах исследования автора предусматривается доведение этих работ до уровня программной реализации.
Список литературы
- В.Г. Редько, Проблемы адаптивного поведения и подходы к моделированию мышления, ссылка скрыта
- В.А. Непомнящих Поведение "аниматов" как модель поведения животных, ссылка скрыта
- Сайт по индуктивному программированию ссылка скрыта
- Ricardo Aler Mur Automatic inductive programming ICML 2006 Tutorial, ссылка скрыта
- Emanuel Kitzelmann. Inductive Synthesis of Functional Programs: An Explanation Based Generalization Approach, ссылка скрыта
- И. Братко Алгоритмы искусственного интеллекта на языке PROLOG, Вильямс, 2004
- Sutton, R.S., & Barto, A.G. (1981). An adaptive network that constructs and uses an internal model of its world, Cognition and Brain Theory 4:217-246.