
Представление изображений в ис
| Вид материала | Документы |
- Белорусский государственный университет применение информационных технологий при анализе, 187.23kb.
- Некоторые методы распознавания изображений, 261.7kb.
- Представление предметной области «Анализ изображений» в виде специализированного тезауруса, 329.52kb.
- Обработка и передача изображений, 213.76kb.
- Секция 6 А. В. Ковальчук, А. Е. Иванов, В. Г. Яхно, 89.91kb.
- Особенности ранних антропоморфных изображений на археологических памятниках V-II тысячелетия, 187.57kb.
- Обработка и передача изображений, 243.48kb.
- Примерная рабочая программа по дисциплине «Компьютерная обработка изображений» Факультет:, 75.51kb.
- Процедуры графики в языке Turbo Pascal, 62.62kb.
- Суворова Ирина Викторовна план-конспект, 55.68kb.
ИХ – импульсная двухмерная характеристика; КИХ-фильтры, которые имеют конечное число элементов (т.е. область S конечна); БИХ-фильтры, которые имеют бесконечное число элементов.
Линейный фильтр — динамическая система, применяющая некий линейный оператор ко входному сигналу для выделения или подавления определённых частот сигнала и других функций по обработке входного сигнала.
Фильтр центрируется на одном пикселе (i,j). Последний модифицируется при помощи: 1) Умножения каждого окружающего пикселя, включая и центральный, на его соответствующий вес из фильтра и суммирования всех результатов 2) Деления суммы, полученной в шаге 1, на сумму весов из фильтра. В результате получим новое значение для пикселя (i,j).
Медианная фильтрация. Обнаружение границ. Градиент изображения, оператор Робертса, оператор Собела.
Рассмотрим задачу выделения и локализации краев (границ). Края — это такие кривые на изображении, вдоль которых происходит резкое изменение яркости или ее производных по пространственным переменным. Наиболее интересны такие изменения яркости, которые отражают важные особенности изображаемой поверхности. К ним относятся места, где ориентация поверхности меняется скачкообразно, либо один объект загораживает другой, либо ложится граница отброшенной тени, либо отсутствует непрерывность в отражательных свойствах поверхности и т.п. В любом случае нужно локализовать места разрывов яркости или ее производных, чтобы узнать нечто о вызвавших их свойствах изображенного объекта. Рассмотрим также применение дифференциальных операторов для выделения тех особенностей изображения, которые помогают локализовать участки, где можно обнаружить фрагмент края. Вполне естественно, что зашумленность измерений яркости ограничивает возможность выделить информацию о краях. Мы обнаруживаем противоречие между чувствительностью и точностью, и приходим к выводу, что короткие края должны обладать большей контрастностью, чем длинные, чтобы их можно было распознать. Выделение краев можно рассматривать как дополнение к сегментации изображения, поскольку края можно использовать для разбиения изображений на области, соответствующие различным поверхностям. Интуитивно краем обычно является граница между двумя областями, каждая из которых имеет приблизительно равномерную яркость. Часто края на изображениях возникают как результат наличия силуэтных линий объектов. В этом случае две упомянутые области являются изображениями двух разных поверхностей. Края также возникают из-за отсутствия непрерывности в ориентации поверхности и разрывов в ее отражательных свойствах. Если мы возьмем сечение функции яркости вдоль прямой, расположенной под прямым углом к краю, то, как правило, обнаружим скачок в ее значениях. На практике перепад не будет резким ввиду размывания и ограничений, вносимых зрительным устройством. Кроме того, иногда яркостные перепады вдоль краев лучше моделируются в виде скачков в первых производных яркости, нежели в самой яркости.
- Методы сегментации изображений (зачем, как).
Сегментация:
- Выявление областей (представляющих интерес в каком-то отношении) в изображениях
- Сегмент – связная область, удовлетворяющая предикату однородности
- Основа для последующего поиска
- Одна из самых трудных задач обработки изображений
- Несколько возможных (эвристических) методов
Сегментацией изображения называется разбиение изображения на непохожие по некоторому признаку области. Предполагается, что области соответствуют реальным объектам, или их частям, а границы областей соответствуют границам объектов. Сегментация играет важную роль в задачах обработки изображений и компьютерного зрения
Задачи автоматической сегментации делятся на два класса:
выделение областей изображения с известными свойствами
разбиение изображения на однородные области
Между этими двумя постановками задачи есть принципиальная разница. В первом случае задача сегментации состоит в поиске определенных областей, о которых имеется априорная информация (например, мы знаем цвет, форму областей, или интересующие нас области представляют собой изображения известного объекта). Методы этой группы узко специализированы для каждой конкретной задачи. Сегментация в такой постановке используется в основном в задачах машинного зрения (анализ сцен, поиск объектов на изображении).
Во втором случае никакая априорная информация о свойствах областей не используется, зато на само разбиение изображения накладываются некоторые условия (например, все области должны быть однородны по цвету и текстуре). Так как при такой постановке задачи сегментации не используется априорная информация об изображенных объектах, то методы этой группы универсальны и применимы к любым изображениям. В основном сегментация в этой постановке применяется на начальном этапе решения задачи, для того чтобы получить представление изображения в более удобном виде для дальнейшей работы. Для грубой оценки качества метода в конкретной задаче обычно фиксируют несколько свойств, которыми должна обладать хорошая сегментация. Качество работы метода оценивается в зависимости от того, насколько полученная сегментация обладает этими свойствами. Наиболее часто используются следующие свойства [1]:
- однородность регионов (однородность цвета или текстуры)
- непохожесть соседних регионов
- гладкость границы региона
- маленькое количество мелких «дырок» внутри региона и т. д.
Кластеризация цветового пространства. В постановке задачи сегментации прослеживается аналогия с задачей кластеризации (или обучения без учителя). Для того чтобы свести задачу сегментации к задаче кластеризации, достаточно задать отображение точек изображения в некоторое пространство признаков и ввести метрику (меру близости) на этом пространстве признаков. В качестве признаков точки изображения можно использовать представление ее цвета в некотором цветовом пространстве, примером метрики (меры близости) может быть евклидово расстояние между векторами в пространстве признаков. Тогда результатом кластеризации будет квантование цвета для изображения. Задав отображение в пространство признаков, можно воспользоваться любыми методами кластерного анализа. Наиболее популярные методы кластеризации, используемые для сегментации изображений – к-средних [35] (обобщенный метод Ллойда), EM алгоритм[5]. Основная проблема методов кластеризации, состоит в том, что пространственное расположение точек либо не учитывается совсем, либо учитывается косвенно (например, используя координаты точки как один из признаков). Поэтому обычно после кластеризации точек изображения проводят процедуру выделения связных компонент. Методы кластеризации плохо работают на зашумленных изображениях: часто теряют отдельные точек регионов, образуется много мелких регионов, и. т. п.
Выращивание регионов, дробление-слияние. Методы этой группы учитывают пространственное расположение точек напрямую.
Методы выращивания регионов основаны на следующей идее. Сначала по некоторому правилу выбираются центры регионов (seeds), к которым поэтапно присоединяются соседние точки, удовлетворяющих некоторому критерию. Процесс выращивания регионов (region growing) останавливается, когда ни одна точка изображения не может быть присоединена ни к одному региону. Применяются разные критерии, на основании которых точка присоединяется или не присоединяется к региону: близость (в некотором смысле) точки к центру региона; близость к соседней точке, присоединенной к региону на предыдущем шаге; близость по некоторой статистике региона; стоимость кратчайшего пути от точки до центра региона, и т. п. В основном процедура выращивания региона используется для получения отдельных регионов, однако, применяя эту процедуру последовательно или одновременно для нескольких регионов, можно получить разбиение всего изображения. Существуют различные стратегии выбора зерен (seeds) и выращивания регионов [14, 15, 16, 17].
Методы дробления-слияния состоят из двух основных этапов: дробления и слияния.[4, 6] Дробление начинается с некоторого разбиения изображения, не обязательно на однородные области. Процесс дробления областей происходит до тех пор, пока не будет получено разбиение изображения (пересегментация), удовлетворяющее свойству однородности сегментов. Затем происходит объединение схожих соседних сегментов до тех пор, пока не будет получено разбиение изображения на однородные области максимального размера. Конкретные методы различаются алгоритмами, используемыми на этапах дробления и слияния. Для получения пересегментации изображения используются алгоритмы k-средних [10], watershed [9, 12], fuzzy expert systems [13], на втором этапе используются алгоритмы k-средних [10], самоорганизующиеся карты Кохонена [11,6], fuzzy expert systems [16], и т. д. На этапе слияния регионов используются relaxation process[3], k-средних [10], SIDE-уравнения [14], самоорганизующиеся карты Кохонена [9],и т. д.
Моделирование изображения Марковским полем. Хорошей моделью изображения служит Марковское случайное поле [7, 8]. Данная модель основана на предположении, что цвет каждой точки изображения зависит от цветов некоторого множества соседних точек. Предложено также обобщение модели изображения также можно обобщить на текстурную сегментацию [7]. Данный подход является достаточно сложным в реализации, однако может являться наиболее адекватным в случае важности учёта текстуры при сегментации. Подробнее о Марковских полях можно прочитать в [7, 8].
Методы, основанные на операторах выделения краев. При данном подходе задача сегментации формулируется как задача поиска границ регионов. Методы поиска границ хорошо разработаны для полутоновых изображений. Полутоновое изображение рассматривается как функция двух переменных (x и y), и предполагается, что границы регионов соответствуют максимумам градиента этой функции. Для их поиска применяется аппарат дифференциальной геометрии (в простейшем случае это фильтры Roberts, Kirsch, Prewitt, Sobel).
Для повышения устойчивости к шуму, перед применением фильтрации изображение обычно размывают. Благодаря коммутативности оператора Лапласа и Гауссова фильтра, можно одновременно осуществлять размытие и поиск границ. В методе Canny комбинируются результаты поиска границ при разной степени размытия.
- Машинный анализ и распознавание объектов.
Сравнение с эталоном. Проблема — большое количество эталонов, которые надо хранить, и медленная процедура поиска. Кроме того, невозможно учесть различие в положении, ориентации, размерах или расстояния до объекта, а также модификации формы объекта (человек стоит, сидит, бежит, и т.д.). Признаки. Основные методы в машинном зрении основаны на использовании признаков для обнаружения и опознания объектов. Для описания объектов используется набор признаков (x1, x2, …, xN). N — размерность пространства признаков. Признаком может служить, например: цвет, яркость, положение в пространстве, ориентация.
Кластер-анализ. Кластер-анализ — автоматическое распределение множества объектов (-образцов) на классы. Классы определяются как компактные множества («облака») в пространстве признаков: два объекта относятся к одному и тому же классу, если представляющие их точки в пространстве признаков находятся рядом (в одном облаке). Кластер-анализ применяется не только в ИИ и не только для машинного зрения. Это универсальные алгоритмы, широко используемые для статистической обработки данных. В том числе и в ситуациях, когда «правильная» классификация объектов неизвестна. Цель — классификация образов (отнести образ к определенному классу).
Основные подходы в кластер-анализе:
- Статические алгоритмы.
- Обучение (с учителем или без учителя).
Типы алгоритмов: Разделяющие гиперплоскости: для каждого класса в пространстве признаков строится гиперплоскость, отделяющая точки этого класса от остальных точек. Своеобразной реализацией этого алгоритма является персептрон.
Метод комитетов: для разделения двух классов в пространстве признако строится совокупность гиперплоскостей. Для данной точки принадлежность ее к тому или иному классу определяется «большинством голосов» гиперплоскостей, входящих в комитет.
Вычисление оценок (расстояние от заданной точки до кластеров в пространстве признаков).
Основная проблема кластер-анализа: трудно выделить информативные признаки. Не по любому набору признаков можно правильно классифицировать объекты. Модели. Строится модель (=схема) объекта, описывающая основные составные части и соотношения признаков — вне зависимости от размеров, ориентации и конфигурации объекта.
Пример: нет «треугольника вообще» (каждый треугольник либо прямоугольный, либо остроугольный, либо тупоугольный), «человека вообще» (мужчина/женщина, старик/ребенок и т.п.)
Стратегия распознавания: строится гипотеза («Это дом»), которая затем проверяется на соответствие модели («крыша, стена, дверь, окна»).
- Выделение признаков. Типы признаков. Инвариантность признаков.
Метрические признаки, принимающие определенные значения на некотором числовом отрезке (площадь, средняя яркость и т. д.);
логические признаки, принимающие значения 1 или 0 (истинно или ложно данное утверждение об изображении); примерами таких утверждений служат: изображение имеет «дыры», контур изображения неодносвязен, форма изображения – прямоугольник, площадь области изображения не больше 10;
топологические признаки, как и логические, относятся к качественному характеру изображения, но могут принимать не два, а несколько значений; примерами являются число компонент связности контура изображения, число дыр в связной области объекта;
структурно-лингвистические признаки связаны с двумя близкими подходами к проблеме распознавания – структурным и лингвистическим. При структурном подходе изображение считается состоящим из частей. Частями изображения являются непроизводные элементы, которые в совокупности с правилами их соединения образуют специальный язык (грамматику). Анализ такой грамматики составляет суть лингвистического подхода к распознаванию. Грубо говоря, структурно-лингвистические методы, которые называют также синтаксическими, направлены на синтаксическую формализацию классов изображений: каждому классу соответствует грамматика с определенными правилами, каждому входному изображению – фраза. Изображение считается соответствующим данному классу, если отвечающая ему фраза удовлетворяет правилам грамматики для этого класса изображений.
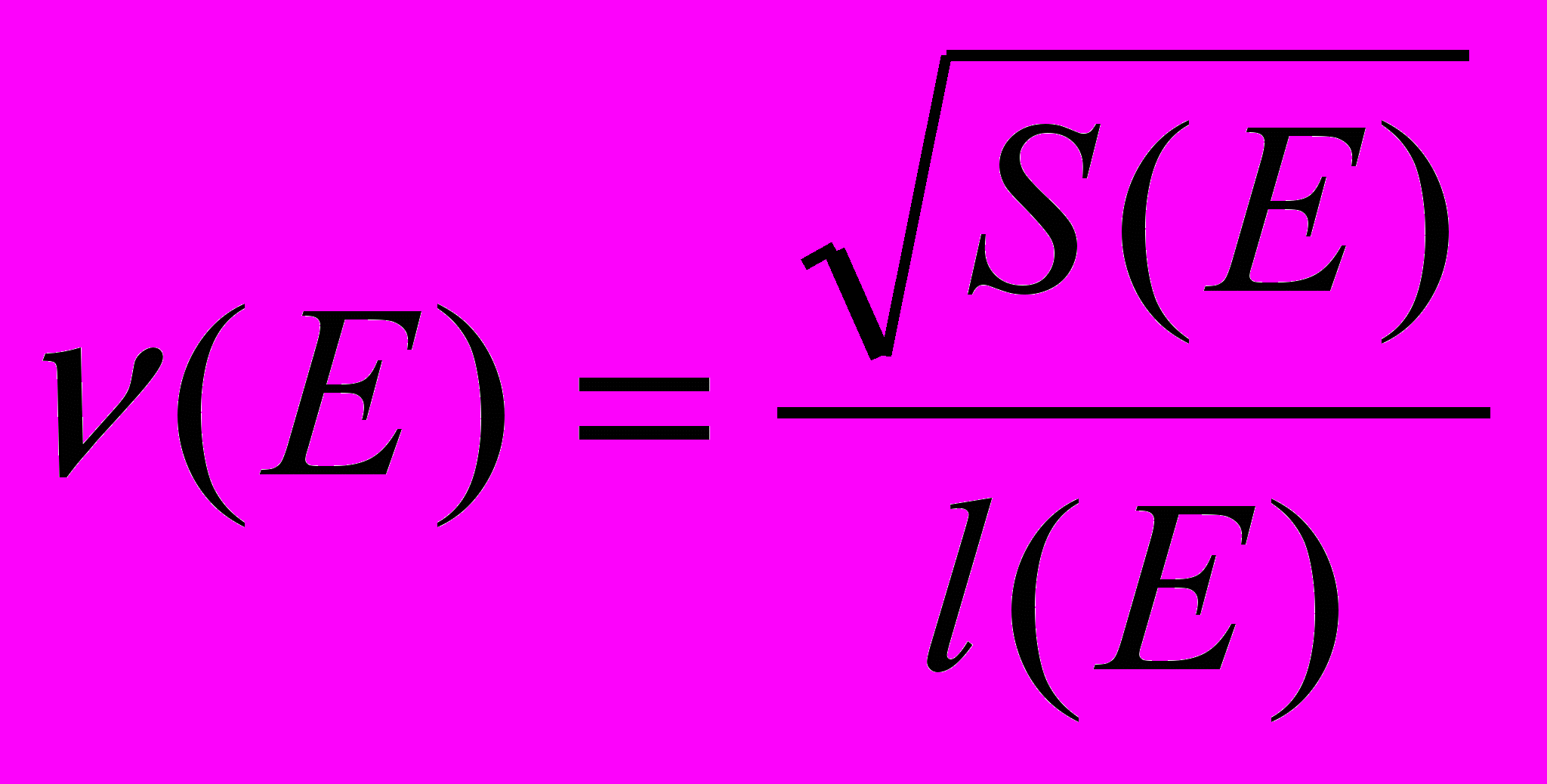 ,
,где Е – область рассматриваемого изображения; S(Е) – ее площадь; l(Е) – длина контура. Очевидно, признак (E) инвариантен к смещениям, к поворотам и к изменениям масштаба. Метрические признаки формы инвариантны к изменениям яркости. В случае отсутствия преобразований яркости или при известном законе яркостных преобразований можно использовать в качестве признаков яркостные характеристики полутоновых изображений. Основными яркостными признаками являются:
- средняя яркость в области изображения Вср;
- максимальная и минимальная яркость Bmах, Bmin;
- модальное значение яркости Bmod;
- разброс (дисперсия) значений яркости
- Распознавание изображений.
При создании систем технического зрения (СТЗ) возникает ряд трудностей и проблем:
- Изображения предъявляются на сложном фоне.
- Изображения эталона и входные изображения отличаются положением в поле зрения.
- Входные изображения не совпадают с эталонами за счет случайных помех.
- Отличия входных и эталонных изображений возникает за счет изменения освещенности, подсветки, локальных помех.
- Эталоны и изображения могут отличать геометрические преобразования, включая такие сложные как аффинные и проективные.
Для решения задачи в целом и на отдельных ее этапах применяются различные методы.
Классификацию основных методов обработки и распознавания СТЗ изображений приведены на схеме, где указаны основные процедуры и методы обработки от начального этапа восприятия поля зрения посредством датчиков, например, телекамеры до конечного, которым является распознавание.
Основные процедуры и методы распознавания изображений

Операция предобработки применяется практически всегда после снятия информации с видеодатчика и преследует цель снижения помех на изображении, возникших в результате дискретизации и квантования, а также подавления внешних шумов. Как правило, это операции усреднения и выравнивания гистограмм.
Сегментация обычно понимается как процесс поиска однородных областей на изображении. Этот этап весьма трудный и в общем виде не алгоритмизированный до конца для произвольных изображений. Наиболее распространены методы сегментации, основанные на определении однородных яркостей (цветов) или однородностей типа текстур.
После сегментации возникают помехи в виде как разрозненных изменений изолированных элементов изображения, так и в виде искажений некоторых связных областей. На практике при борьбе с подобными помехами наибольшее распространение получили цифровые фильтры-маски и нелинейные фильтры типа медианных. При этом в случае сегментации путем выделения границ использование усредняющих фильтров-масок невозможно, так как границы при этом не подчеркиваются, а размываются. Для подчеркивания контуров применяются специальные операторы интегрального типа.
Распознавание - чаще всего конечный этап обработки, лежащий в основе процессов интерпретации и понимания. Входными для распознавания являются изображения, выделенные в результате сегментации и, частично, отреставрированные. Они отличаются от эталонных геометрическими и яркостными искажениями, а также сохранившимися шумами.
Для реальных задач распознавания применяются, в основном, четыре подхода, использующие методы: корреляционные, основанные на принятии решений по критерию близости с эталонами; признаковые и синтаксические - наименее трудоемкие и нормализации, занимающие промежуточное положение по объему вычислений.
Каждый из подходов в распознавании имеет право на существование. Более того, в рамках каждого подхода есть свои конкретные алгоритмы, имеющие определенную область применения, которая зависит от характера различий входных и эталонных изображений, от помеховой обстановки в поле зрения, требований к объемам вычислений и скорости принятия решений.
- Методы сжатия изображений: классификация, метод RLE, LZV.
Алгоритмы сжатия можно разделить на две категории: симметричные и асимметричные. При симметричном сжатии время, затрачиваемое на кодирование и декодирование данных, примерно одинаково, а алгоритмы, применяемые при этом, достаточно близки. При асимметричном сжатии в одном направлении (обычно при кодировании) расходуется значительно больший объем машинного времени, чем в другом.
Сжатие без потерь (lossless) подразумевает, что восстановленные после сжатия данные будут полностью (с точностью до бита) идентичны исходным. Сжатие с потерями (lossy) применяется только для сжатия мультимедийной информации (в основном, изображений и звуковых файлов) и означает, что восстановленные после сжатия данные не будут соответствовать исходным.
LZW - метод сжатия (графических изображений), основанный на алгоритме поиска одинаковых последовательностей во всем файле.
Сжатие в RLE происходит за счет замены цепочек одинаковых байт на пары "счетчик, значение".
- Методы сжатия изображений: классификация метод Хаффмана.
Метод кодирования Хаффмана - метод сжатия данных, основанный на использовании относительной частоты встречаемости индивидуальных элементов. Часто встречающиеся элементы кодируются более короткой последовательностью битов.
Кодирование Хаффмана имеет высокую эффективность при относительно равномерном распределении уровней пикселей.
- Представление и сжатие изображений: пирамидальное представление, метод квадрантов, цепное кодирование.
Пирамидальная техника: Итерационная субдискретизация (блок пикселей заменяется одним пикселем с усредненным значением, получившееся изображение опять разбивается на блоки, заменяемые одним пикселом, и т.д.); в итоге, получаем одно значение (усредненный уровень серого). Получаемые (и хранимые) «разностные» изображения, в которых значение каждого пиксела равны разнице между реальным и усредненным по блоку значениями, позволяют восстановить оригинальное изображение. Своего рода обобщение иерархического блочного кодирования
Естественный подход для постепенного (progressive) отображения (передачи) графики: сначала отображение в плохом разрешении, затем последовательно все в более лучшем.
- Мультимедийные базы данных.
- Методы построения и принципы поиска информации в мультимедийных базах данных.
- С помощью иерархической классификации изображений
При поиске пользователь использует иерархию, например:
- Художественные произведения
- Живопись
- Россия
- 19-ый век
- 19-ый век
- Россия
- Живопись
- С помощью индекса признаков:
Изображения рассматриваются как документы с индексом терминов
- Поиск по содержимому
Поиск по шаблону, возвращающий изображения похожие на заданное изображение, фигуру и т.д.
а) Реляционное представление:
- Представление изображения: идентификатор изображения и его основные свойства (атрибуты)
- Представление объекта: объекты (сегменты, прямоугольники) внутри изображений; извлекаются вручную или автоматически
Атрибуты включают: id изображения, id объекта, координаты минимального ограничивающего прямоугольника, признаки
- Обобщение: вероятностные отношения - объект x находится в изображении i с вероятностью p
- Запросы: применять стандартную технику запросов, используя значения признаков в условиях запроса
б) Пространственное представление:
- Например, с помощью R- или R*-деревьев
- Построить одно R-дерево для всех изображений в базе данных
- Страница, соответствующая листу, содержит близко-расположенные объекты (их MBR’ы) со списком указателей на исходные изображения
- Также сохранены дополнительные свойства (признаки) объекта
- Для не пространственных свойств объектов может быть построен отдельный индекс
- Аппаратные средства мультимедиа технологий.
Звуковые и видео карты, сидиромы, ТВ-тюнеры, мпег-плееры (на это фантазии должно хватить ;) )
- Кино и видео форматы изображения: форматы, принципы реализации.
частота 24 кадра в секунду - для показа в кинотеатрах.
частота 25 кадров в секунду -киноплёнка, предназначенная для показа на ТВ в PAL/SECAM
частота 16 кадров в секунду (старые немые фильмы, любительские фильмы на плёнке 16мм)
Большинство государств на Земле использует модификации трех телевизионных стандартов: NTSC, PAL и SECAM. Эти стандарты несовместимы друг с другом.