
Б. Ф. Мельников (Тольяттинский государственный университет, B. Melnikov@tltsu ru, bormel@mail ru) Аннотация Внастоящей статье рассматриваются эвристические методы принятия решений в различных задача
| Вид материала | Задача |
Содержание6. О некоторых других применяемых эвристиках H(x) заранее ничего не известно. Про функцию G(x,y) |
- Программа профилирующей дисциплины "теория игр и исследование операций" Содержание, 69.55kb.
- Аннотация рабочей программы дисциплины методы принятия управленческих решений По направлению, 115.63kb.
- Аннотация программы дисциплины «Методы принятия управленческих решений» Цели и задачи, 22.87kb.
- Анализ принятия управленческих решений, 54.28kb.
- Программа «Методы принятия решений». Гу-вшэ, 2010 г. Министерство экономического развития, 750.51kb.
- Аннотация рабочей программы дисциплины методы принятия управленческих решений для направления, 31.71kb.
- Автор повинен правильно оформити літературу. Удк 338., 87.87kb.
- Исследование по вопросу о коренных народах и праве на участие в процессе принятия решений, 537.75kb.
- Аннотация рабочей программы учебной дисциплины методология и методы исследований, 173.52kb.
- Электронное научное издание «Труды мгта: электронный журнал», 106.8kb.
6. О некоторых других применяемых эвристиках
Материал этого раздела мало связан с главным вопросом – про функции риска в дискретной оптимизации, но связан с общей темой статьи. Выше мы практически не касались вопроса о выборе нескольких конкретных эвристик для организации очередного шага МВГ, а также – в упрощённом случае – для проведения турнирного самообучения.
Как уже было сказано выше, практически все эвристические методы дискретной оптимизации, описываемые в настоящей статье, связаны с методами, применявшимися автором при программировании интеллектуальных компьютерных игр, прежде всего – бэкгеммона.36 Аналоги с программированием игр проявляются не только в организации турнирного самообучения и в применении функций риска37. Ещё более важные аналоги проявляются в следующем. Во-первых, несколько критериев статической оценки позиции игры аналогичны нескольким эвристикам, необходимым для выбора очередного шага МВГ. Во-вторых, разные классы игровых позиций абсолютно аналогичны разным классам конкретных подзадач некоторой задачи дискретной оптимизации. В-третьих, методами ГА удобно одновременно самообучать совершенно разные критерии:
- в программировании игр таковыми являются параметры оценки позиции и конкретные значения коэффициентов функций риска;38
- а в создании anytime-алгоритмов к этим двум группам критериев39 добавляются, среди прочего, коэффициенты зависимости между границей и размерностью – см. об этом далее.
Заметим, что всё сказанное в данном абзаце показывает, среди прочего, и очень высокую роль методов игрового программирования среди всех методов искусственного интеллекта. Более того, по мнению автора настоящей статьи, все приёмы и методы искусственного интеллекта (к которым относится и описание любых эвристик) необходимо предварительно проверять на игровых программах. Автор надеется, что данная статья отвечает на возможный вопрос, как именно это делать.40
Теперь опишем некоторые вспомогательные эвристики. Сначала – те из них, которые являются общими:
- для турнирного самообучения и для выбора очередного шага в МВГ;
- для всех возможных ЗДО.
Поскольку мы конструируем вспомогательные эвристики, в первую очередь, для незавершённого МВГ, мы в процессе решения некоторой конкретной подзадачи кроме главной характеристики обычного (завершённого) МВГ – т.е. границы – имеем ещё одну, не менее важную характеристику – размерность задачи.41 Выбор этой эвристики как вспомогательной объясняется тем простейшим фактом, что задача, имеющая меньшую размерность, с несколько большей вероятностью даст новое псевдо-оптимальное решение – текущее на данный момент для выполняющегося anytime-алгоритма. Однако совсем игнорировать границу, конечно же, нельзя – поэтому для выбора очередной задачи из списка автор применяет упорядочение задач согласно значениям некоторой линейной функции двух переменных – границы и размерности; коэффициенты при переменных этой функции, как было отмечено ранее, добавляются к коэффициентам самообучения методами ГА.42
В разделе 3 уже было отмечено, что часто на практике алгоритмы, использующие ДФР, удачно работают и в том случае, когда не существует никакой эвристики для выбора аналога оценки текущей позиции в играх. Т.е., когда отсутствует информация об отрезке для возможных оценок (наименьшей и наибольшей), возвращаемых предикторами.43 Однако и в этом случае нам всё равно удаётся применять ДФР.44 При этом для старта процесса построения этих функций на практике обычно используется следующая весьма простая вспомогательная эвристика. В ней в начале применения алгоритма построения ДФР минимальная и максимальная из текущих оценок предикторов выступают в роли минимальной и максимальной из возможных; производится обычная нормализация, простое усреднение в качестве первой (статической) оценки, и т.д. А на каждом из последующих шагов данного алгоритма мы используем в качестве минимальной и максимальной из возможных оценок соответствующие значения, взятые по всем предыдущим шагам.
Отметим, что подробное объяснение последней эвристики (т.е. тот факт, что она действительно может дать хорошие практические результаты) выходит за рамки вопросов, рассматриваемых в данной статье – поскольку это объяснение желательно приводить отдельно для каждой конкретной решаемой ЗДО. Краткое же её объяснение можно привести, если посмотреть с иной точки зрения на априорное наличие информация об отрезке возможных оценок предикторов (отмеченное в одной из предыдущих сносок). А именно, поскольку эта информация всегда является следствием рассматриваемой ЗДО, мы можем условно считать, что такой отрезок не задан заранее, а итерационно получается именно в результате многократного применения алгоритма, описанного в предыдущем абзаце.
Среди большого количества эвристик для конкретных ЗДО, в связи с естественными ограничениями на объём настоящей статьи, рассмотрим только одну из вышеупомянутых задач – а именно, задачу вершинной минимизации НКА.45 Как уже было сказано выше, описываемые эвристики являются общими для турнирного самообучения и для выбора очередного шага в МВГ.
Описание вспомогательных жадных эвристик для задачи вершинной минимизации НКА предполагает знакомство с материалом статей [28–33]; при этом обозначения, добавленные ниже к использовавшимся в этих работах, представляются очевидными. Итак, из всего множества блоков таблицы соответствий некоторого регулярного языка нам необходимо выбрать некоторое подмножество, включающее в себя все имеющиеся (т.е. построенные в процессе канонизации прямого и зеркального автоматов) элементы #.46 Для такого выбора необходимо ответить на вопрос о включении некоторого конкретного блока в оптимальное подмножество (важно отметить, что это необходимо как для турнирного самообучения, так и для описания очередного шага МВГ), и для ответа на этот вопрос мы будем использовать следующий эвристический алгоритм, формулируемый для матрицы элементов #.
Пусть рассматривается клетка матрицы таблицы соответствий состояний с координатами (i,j), пусть также R(i) – количество знаков # в строке i, а C(j) – количество знаков # в столбце j. Тогда:
- Для каждой пары (i,j), содержащей #, посчитаем значение
F(i,j) = G(H(R(i)),H(C(j))), (1)
где G(x,y) и H(x) – некоторые функции. При выборе этих функций методами ГА относительно вида функции H(x) заранее ничего не известно. Про функцию G(x,y) известно лишь то, что она является возрастающей (т.к. чем больше соседей у ячейки, тем с большей вероятностью она должна войти в искомый блок), но не известно ничего о её выпуклости.47 G, вообще говоря, не обязана удовлетворять условию симметричности G(x,y)=G(y,x) – поскольку общее число строк и столбцов в рассматриваемой таблице соответствий может различаться. Отметим ещё, что если у ячейки нет соседей ни в строке, ни в столбце (т.е. R(i)=0 либо C(j)=0), то соответствующий ей блок обязательно должен войти в искомое множество покрывающих блоков. Итак, подбор параметров, необходимых для описания поведения этих функций, и есть объект самообучения.
- При самообучении обычно использовался следующий конкретный вид функции H(x):
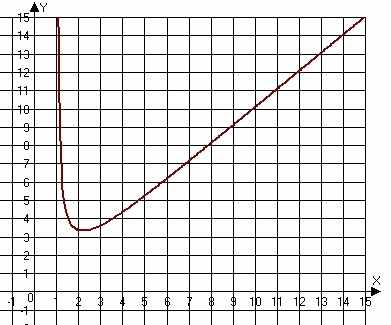
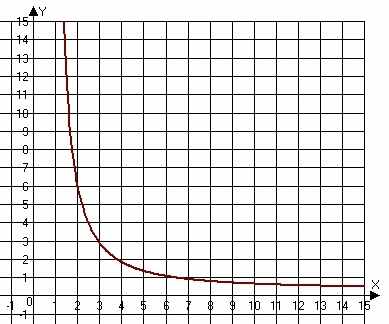
H(x)= e–(P1X) + P2N(x–1)–1 + P3 x + 1, (2)
где N – соответствующая размерность таблицы соответствий состояний. Отметим, что здесь возникает ещё одна аналогия с результатами, полученными в статье [7] при самообучении игровых программ: при начале самообучения с функциями произвольного вида, т.е. функциями, не имеющими вид (2), результат работы ГА даёт функции вида, близкого к указанному. Однако вид (2) всё же был априори подобран эвристически.
Возможные графики функции (2) для двух различных вариантов значений параметров (а именно, для P1=2/N, P2=1, P3=1 и P1=4/N, P2=5/N, P3=0.01) изображены ниже:
- Среди всех блоков выбираем такой (R,C), для которого т.н. итоговая рейтинговая сумма ∑F(Ri,Cj), где RiR и CjC, будет наибольшей. Ещё раз отметим, что функция F выбирается согласно (1), а функции G и H при этом получаются в результате самообучения методами ГА. Поместим выбранный блок в итоговое множество.
- Специальным образом пометим ячейки, принадлежащие выбранному на шаге 3 блоку, чтобы они не учитывались при вычислении F(Ri,Cj), но могли входить в любой вновь выбираемый блок. Итак, в будущем, т.е. при повторном выполнении шагов 1–3, эти ячейки уже не считается помеченными символом #.
- Если остались еще ячейки, не вошедшие ни в один блок из итогового множества, то возвращаемся на этап 1. Заметим, что блоки, которым принадлежит хотя бы одна ячейка, не имеющая соседей по вертикали либо по горизонтали, будут обязательно включены в искомое множество, т.к., согласно виду функции F, их рейтинговая сумма равна бесконечности.
Полученное множество блоков считается искомым – и используется либо для проведения очередного шага турнирного самообучения (в простом случае), либо (после применения к результатам работы нескольких программ-предикторов аппарата ДФР) для проведения очередного шага МВГ.