
А. В. Яровой , О. Л. Зорин фиан, ифвэ аннотация Вдоклад
| Вид материала | Доклад |
- Механизм воздействия инфразвука на вариации магнитного поля земли, 48.07kb.
- А. В. Жилкин, Д. А. Филиппов, С. Ю. Круглов, И. В. Шевченко фгуп «Горно-химический, 69.77kb.
- II. Название сорта (гибрида), 416.94kb.
- Алехина Марина Владимировна. Ведущий архитектор. Тел.: +7 (486) 242 03 87, e-mail:, 69.44kb.
- В. И. Мелдов Аннотация Вдоклад, 347.44kb.
- Мотылева Мария Владимировна ( mariyadeg@mail ru ) Государственное образовательное учреждение, 97.65kb.
- Сахалинска Клинов Алексей Александрович, Министерство образования Сахалинской области, 151.03kb.
- Новикова Галина Георгиевна (novikova galina@mail ru) Муниципальное Общеобразовательное, 154.61kb.
- Заводская Елена Сергеевна (e-mail в электронной версии статьи удалён) Закрытое акционерное, 205.37kb.
- Чугунова Наталья Петровна (koshki olimp@mail ru) Муниципальное образовательное учреждение, 184.41kb.
Ассоциативный поиск текстовой информации
С.А.Шумский, А.В. Яровой, О.Л.Зорин
ФИАН, ИФВЭ
Аннотация
В докладе сравниваются различные методы ассоциативного поиска и фильтрации информации, используемые в Интернет. На примере около 8000 абстрактов общества SPIE иллюстрируется оригинальная технология категоризации текстов, выделения ключевых и семантически связанных слов.
Введение
Традиционные методы поиска и фильтрации информации были разработаны для библиотечных баз данных, то есть для информационных ресурсов ограниченного объема и заранее известной структуры. Создание глобальной сети и выход Web за рамки интересов научного сообщества привели к тому, что число поставщиков информации стало стремительно расти, при том, что публикуемая ими информация не имела однородной структуры. Последовавший информационный взрыв стал вызовом стандартным информационным технологиям. Новые масштабы с одной стороны сделали аутсайдерами некоторые ранее конкурентоспособные интеллектуальные технологии, а с другой - стимулировали интенсивные исследования в области лингвистических и вероятностных методов обработки текстовой информации и новых методов навигации в неоднородном информационном море. В данном докладе будет рассказано о современных поисковых технологиях Интернет, а также приведены результаты работы демонстрационной ассоциативной поисковой системы.
Индексация текстовых документов
Реальные поисковые системы на Web не хранят оригинальные тексты документов, используя вместо них индексы – специальное представление документов, удобное для быстрого поиска. Способ построения индексов – индексирование – существенно варьируется от одной поисковой системы к другой и в конечном счете определяет отличия известных поисковых серверов друг от друга [1].
Однако, несмотря на их многообразие, все существующие способы индексирования можно разбить на два класса – лексическое индексирование и векторное индексирование. Лексическое индексирование предназначено для оптимизации булевых запросов, в то время как векторное индексирование позволяет делать запросы по подобию. По существу, это две совершенно разных парадигмы индексирования. Единственное, что объединяет их – это предварительный этап построения “инвертированного индекса” - матрицы вхождения слов в документы. Последующая обработка этой матрицы и является спецификой метода индексирования.
Наиболее старым и уже традиционным является лексическое индексирование. За время своего существования оно почти достигло совершенства в области поиска по ключевым словам и целым фразам. Развитые поисковые лексические системы используют стоп-листы, грамматические словоформы и расширенный язык запросов. Используются возможности задавать близость данных слов в тексте (проксимити) и близость слова к началу текста. Многим системам добавляют интеллектуальность за счет вручную построенных тезаурусов. Можно определенно сказать, что нынешние возможности систем лексического поиска вполне удовлетворяют запросам экспертов, интересующихся информацией в какой-нибудь узкой области.
Однако, для большинства пользователей поисковых систем на Web эффективность лексического поиска выглядит крайне неудовлетворительной. Причин здесь две. Первая состоит в том, что для рядового пользователя Internet булева алгебра воспринимается как высшая математика и ему не запутаться в логике отрицаний и конъюнкций довольно трудно. Вторая причина кроется в том, что обычному пользователю, в отличие от “эксперта”, трудно сформулировать свой запрос на языке ключевых слов предметной области, особенно если в этой предметной области нет устоявшейся или регламентированной терминологии. Кроме того, при попытке выйти за рамки узкой предметной области сразу остро встают проблемы синонимии и полисемии (одинаковые слова с разным смыслом).
В связи с проблемами синонимии и полисемии была осознана важность контекста. Вопросы представления контекста исследовались в разных подходах -статистических, лингвистических, концептуальных, – но ощутимые практические результаты были получены с использованием статистических методов.
В конце 80-х годов в работах Салтона [2] была предложена векторная модель как альтернатива лексическому бесконтекстному индексированию. В простейшей векторной модели каждому документу сопоставляется частотный спектр слов и соответственно вектор в лексическом пространстве. В процессе поиска частотный портрет запроса рассматривался как вектор в том же пространстве и по степени близости (расстоянию или углу между векторами) определялись наиболее релевантные документы.
В более продвинутых векторных моделях размерность пространства обычно сокращают отбрасыванием очень распространенных и очень редких слов, увеличивая тем самым процент значимых слов. Кроме того, при построении вектора документа частоты слов модифицируются специальными весовыми коэффициентами, учитывающими долю в общей коллекции документов, содержащих данное слово.
Наиболее привлекательной стороной векторной модели является возможность поиска и ранжирования документов по подобию – их близости в векторном пространстве. Однако, результаты не всегда впечатляют при оценке близости запроса к документу, особенно когда запрос содержит мало слов. С целью подавить словесный шум и добиться лучшей релевантности отклика в 1990 году была предложена модель скрытого семантического индексирования [4] - Latent Semantic Indexing (LSI). Модель использовала singular value decomposition (SVD) для перехода от разреженной матрицы слов к компактной матрице главных собственных значений [5].
LSI показала значительное превосходство в результатах поиска [6] по сравнению с лексическим методом, однако сложность модели часто приводила к существенному проигрышу в скорости на больших коллекциях по сравнению с традиционной булевой техникой. Возможно, наиболее работоспособная система на основе LSI была создана в Беркли в 1995 году Майклом Берри и Тодом Летче [7].
Контекстная категоризация
Описываемая ниже система контекстной категоризации использует схожий круг идей. А именно, предлагается ввести ограниченный набор базовых смысловых категорий, определяемых через контекст. Контекст каждой категории определяется через ее корреляцию с другими категориями, что и формирует ее смысл. Разложение каждого слова по этим смысловым категориям отражает разнообразие смыслов этого слова, причем это разложение будет примерно одинаковым у различных словоформ одного и того же слова и у синонимов, если они употребляются в одних и тех же контекстах.
Смысловой портрет текста определяется совокупным смыслом входящих в него слов. При этом, слова часто употребляемые в одном контексте (и, следовательно, принадлежащие к одной категории) дадут смысловой пик именно на этой категории.
Для формирования смысловых категорий требуется определить контекст в котором употребляется каждое слово. Трудность задачи, которую, однако удается преодолеть, состоит в том, что контекст определяется через категории, определяемые, в свою очередь, через контекст.
После того, как категории сформируются, между словами (и текстами) можно измерять расстояние в пространстве категорий, и следовательно, находить ближайших соседей, что и применяется в системах ассоциативного поиска и фильтрации документов.
Результаты экспериментов
Данный алгоритм был опробован на абстрактах научных статей, опубликованных научным обществом SPIE (org). В экспериментах было задействовано более 8000 абстрактов, содержащихся в 250 томах, которые, в свою очередь, принадлежали одному из 10 тематических разделов.
Категоризация текстов разделяет все множество документов по заданному числу категорий - в примере, приведенном ниже, использовалось 40 категорий. Кроме того, алгоритм позволяет определять какие слова являются наиболее значимыми для каждой из выделенных категории. В Таб. 1 представлены главные слова из 3-х таких категорий. Легко убедиться, что по этим словам четко определяется «тема» категории. Так в первом случае категория объединяет абстракты по голографии, во втором - по вейвлетам и нейросетям, а в третьем - по медицине.
Таб. 1 Наиболее значимые слова в трех (из 40) категориях с указанием степени принадлежности к данной категории
| RAINBOW | 0.898 | WAVELETS | 0.952 | ANIMAL | 0.942 |
| HOE | 0.751 | TIME-FREQUENCY | 0.947 | IX | 0.930 |
| HOLOGRAM | 0.685 | RANK | 0.919 | MUCOSA | 0.922 |
| DICHROMATED | 0.650 | SUBSPACE | 0.911 | PORPHYRINS | 0.909 |
| SHEARING | 0.565 | LEAST-SQUARES | 0.840 | SENSITIZERS | 0.850 |
| HOLOGRAMS | 0.547 | CORTEX | 0.812 | MICE | 0.838 |
| HOLOGRAPHY | 0.462 | CUMULANTS | 0.802 | MALIGNANT | 0.817 |
| HALIDE | 0.435 | SINGULAR | 0.797 | PHOTOSENSITIZERS | 0.805 |
| PHOTOPOLYMER | 0.416 | BANKS | 0.785 | CAM | 0.802 |
| HOLOGRAPHIC | 0.395 | NEURONS | 0.782 | INCUBATION | 0.799 |
| EMULSION | 0.384 | WAVELET | 0.753 | UPTAKE | 0.795 |
| RECORDINGS | 0.364 | PIECEWISE | 0.744 | PHOTOSENSITIZER | 0.787 |
| TRACES | 0.324 | KERNELS | 0.729 | ORAL | 0.772 |
| CREATIVE | 0.320 | IMPULSIVE | 0.726 | MOUSE | 0.707 |
| SUNLIGHT | 0.302 | DILATION | 0.697 | TUMOR | 0.698 |
| RECONSTRUCTIONS | 0.298 | SVD | 0.696 | TOPICAL | 0.661 |
| FABRICATING | 0.291 | ALIASING | 0.695 | SENSITIZER | 0.621 |
| FRINGES | 0.282 | CONVERGENCE | 0.691 | EPITHELIAL | 0.596 |
| RECONSTRUCTED | 0.278 | BACKPROPAGATION | 0.682 | THERAPY | 0.585 |
| QUASI | 0.253 | MULTIRESOLUTION | 0.674 | CANCER | 0.571 |
Сравнивать по степени близости друг к другу можно как и документы так и слова. Ниже приведены примеры близости в пространстве словоформ: выписаны слова, ближайшие к THE, NEURAL, CANCER.
THE: OF IN FROM THAT ARE ON TO WHICH FOR AND AS TWO IS BOTH A BY IT WITH BETWEEN ALSO AN RESULTS HAS WITHIN INTO BE TIME USED OR
NEURAL: LEARNING CLASSIFIERS UNSUPERVISED TRAINED BACK-PROPAGATION SUPERVISED NEURONS WEIGHTS TRAINING HIDDEN HOPFIELD BACKPROPAGATION NETWORK IMPULSIVE NETS FEEDFORWARD PREDICTOR NETWORKS TEXTURAL SPEAKER TELEPHONE PERCEPTRON LEARN AMBIGUITIES DIGITS MULTIDIMENSIONAL BP MLP CLASSIFIER
CANCER: ORGANS LESIONS THERAPY TUMOR VIVO CAM PHOTOSENSITIZERS TUMORS RAT MOUSE PATIENTS AUTOFLUORESCENCE ADMINISTRATION NECROSIS SENSITIZERS VASCULAR RESECTION ADMINISTERED VITRO CLEARANCE INCUBATION PP ACUTE DRUG BALLOON PROSTATE SKIN DISORDERS EPITHELIAL
Как видно из этих примеров, к артиклю THE ближайшими оказываются служебные слова: артикли, союзы и т.д. К словам же NEURAL и CANCER ближайшими являются слова из той же предметной области. Причем, как это видно из Рис. 1, незначимые слова равномерно распределены по категориям, тогда как семантически нагруженные имеют четко выраженные пики в категориях, где они являются ключевыми.
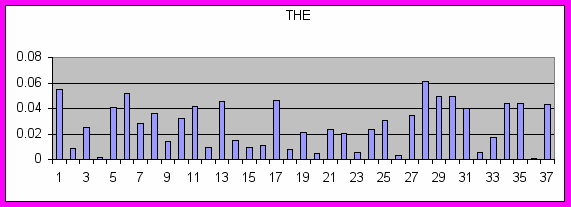
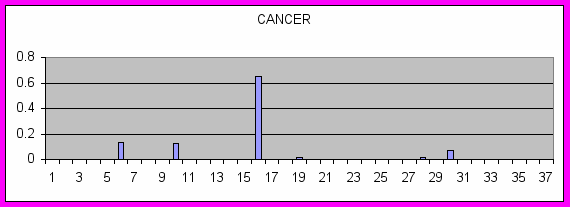
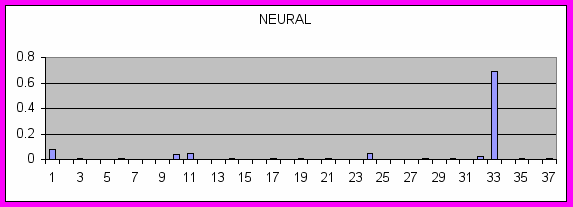
Рис. 1 Распределение некоторых слов по категориям
Заключение
Представленный в докладе алгоритм категоризации текстов способен выявлять в больших текстовых массивах “осмысленные” категории, сопоставлять им значимые слова, автоматически отсекая семантически ненагруженные артикли, глаголы и другие словоформы, обычно заносимые в специально составленные стоп-листы. Он может быть использован в системах фильтрации и рубрикации текстовой информации.
Литература
[1] How To Use Web Search Engines. URL: ll.k12.ia.us/ccsdpages/searchhelp.php
h.com/spidap3.php
[2] G. Salton. Automatic Text Processing. Addison-Wesley Publishing Company, Inc., Reading, MA, 1989.
[3] G. Salton, J. Allan, and C. Buckley. Automatic structuring and retrieval of large text files. Communications of the ACM, 37(2):97-108, February 1994.
[4] S. Deerwester, S. Dumais, G. Furnas, T. Landauer, and R. Harshman. Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41(6):391--407, 1990.
[5] G. Golub and C. Van Loan. Matrix Computations. Johns-Hopkins, Baltimore, Maryland, second edition, 1989
[6] S. Dumais. Improving the retrieval of information from external sources. Behavior Research Methods, Instruments, & Computers, 23(2):229--236, 1991.
[7] Todd A. Letsche and Michael W. Berry. Large-Scale Information Retrieval with Latent Semantic Indexing. URL: k.edu/ ~berry/sc95/sc95.php