
Математические основы информатики
| Вид материала | Документы |
- Пояснительная записка 3 Содержание разделов и тем 5 Элективный курс «Математические, 106.07kb.
- Программа № «Математические основы информатики» (элективный курс) образовательная,, 124.66kb.
- Программа вступительных испытаний по дисциплине информатика, 14.43kb.
- Элективный курс Математические основы информатики, 18.01kb.
- Урок на тему «Решение логических задач с помощью электронных таблиц ms excel\ Раздел, 149.53kb.
- Примерная программа по олимпиадной информатике представляет собой следующее. Математические, 157.49kb.
- А. В. Тищенко Спецкурс «Математические основы информатики» Настоящий спецкурс предлагается, 6.69kb.
- Рабочая программа элективного курса для 10 класса по информатике и икт «Математические, 45.88kb.
- Пантелеев Владимир Иннокентьевич, к ф. м н., доцент кафедры математической информатики, 87.48kb.
- Основы информатики и программирования, 1887.69kb.
Математические основы информатики:
4. Формы представления и преобразования информации
При работе с информацией возникает необходимость преобразования исходного представления информации, удобного для восприятия человеком, к представлению, удобному для хранения, передачи и обработки и наоборот. Такие преобразования называются кодированием и декодированием соответственно. Перечислим несколько известных систем кодирования:
- Человеческий язык – система кодирования мыслей человека посредством речи;
- Азбуки – системы кодирования компонент человеческого языка с помощью графических символов;
- Код Морзе (телеграфная азбука): .--. ---- -- -.-. . - ..- ;
- Код Брайля (азбука для слепых):
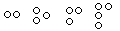 ;
;
- Код морской сигнализации (морская флажковая азбука);
- Двоичное кодирование: данные кодируются последовательностью 0 и 1.
История кодирования
Коды появились в глубокой древности в виде криптограмм (по-гречески - тайнописи), когда ими пользовались для засекречивания важного сообщения от тех, кому оно не было предназначено. Уже знаменитый греческий историк Геродот (V век до н. э.) приводил примеры писем, понятных лишь для одного адресата. Спартанцы имели специальный механический прибор, при помощи которого важные сообщения можно было писать особым способом, обеспечивающим сохранение тайны. Собственная секретная азбука была у Юлия Цезаря. В средние века и эпоху Возрождения над изобретением тайных шифров трудились многие выдающиеся люди, в их числе философ Фрэнсис Бэкон, крупные математики Франсуа Виет, Джероламо Кардано.
С течением времени начали появляться по-настоящему сложные шифры. Один из них, употребляемый и поныне, связан с именем ученого аббата из Вюрцбурга Тритемиуса.
Клод Шеннон, ученый, заложивший основы теории информации, показал, как можно построить криптограмму, которая не поддается никакой расшифровке, если, конечно, не известен способ ее составления.
Исторически первый код, предназначенный для передачи сообщений, связан с именем изобретателя телеграфного аппарата Сэмюэля Морзе и известен всем как азбука Морзе. В этом коде каждой букве или цифре сопоставляется своя последовательность из кратковременных (называемых точками) и длительных (тире) импульсов тока, разделяем паузами. Другой код, столь же широко распространенный в телеграфии (код Бодо), использует для кодирования два элементарных сигнала — импульс и паузу, при этом сопоставляемые буквам кодовые слова состоят из пяти таких сигналов.
Коды, использующие два различных элементарных сигнала, называются двоичными. Удобно бывает, отвлекаясь от их физической природы, обозначать эти два сигнала символами 0 и 1. Тогда кодовые слова можно представлять как последовательности из нулей и единиц.
Отметим, что наряду с двоичными кодами применяются коды, использующие не два, а большее количество кодовых символов. Число этих символов называют основанием кода, а множество кодовых символов — кодовым алфавитом.
В ЭВМ используется двоичное кодирование. Одним битом можно закодировать только два понятия 1(да) и 0(нет). Двумя битами можно закодировать четыре понятия 00, 01, 10, 11. Тремя битами можно закодировать уже восемь понятий: 000, 001, 010, 011, 100, 101, 110, 111 и т.д. Т.е. увеличивая каждый раз количество разрядов в двоичном кодировании на единицу, количество возможных кодируемых значений будет удваиваться, в общем виде можно записать:
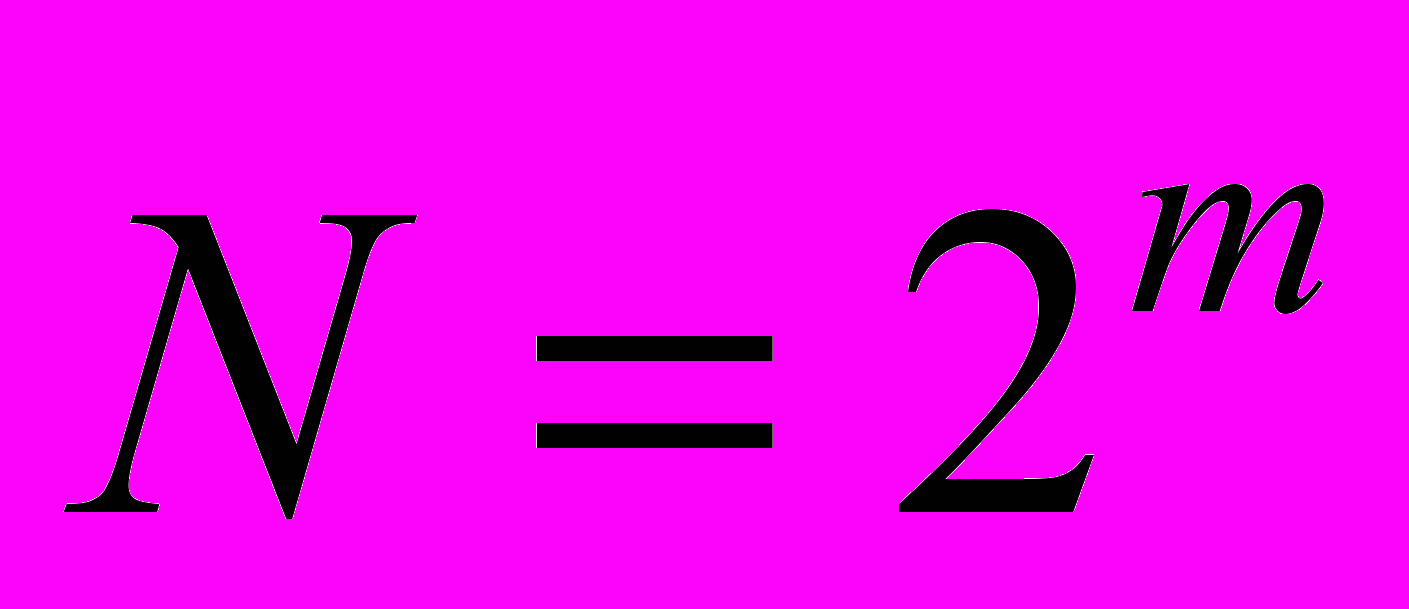 , где N – количество возможных кодируемых состояний (значений, понятий);
, где N – количество возможных кодируемых состояний (значений, понятий);m – разрядность двоичного кодирования.
Для записи, хранения и выдачи по запросу информации в ЭВМ имеется Запоминающее устройство (память), организованная на электронных носителях. Один элемент памяти (бит) никакой смысловой нагрузки не несет (т.к. с помощью одного бита можно закодировать только два понятия). Однако, если соединить несколько таких элементов в ячейку, то тогда в ЗУ можно хранить столько информации, сколько потребуется. Один байт (8 бит) – элементарная ячейка памяти ЭВМ. Каждая ячейка имеет адрес и содержимое. Когда процессор обрабатывает информацию, он находит нужную ячейку памяти по ее адресу. Объем адресуемой памяти зависит от разрядности процессора ( 8-ми разрядный имеет 28 = 256 ячеек памяти, 16-ти разрядный – 216 = 65536 ячеек, 32-х разрядный – 232 = 4294967296 ячеек 4 Гбайта ).
Последовательность битов, рассматриваемых аппаратной частью ЭВМ как единое целое, называется машинным словом.
Числовая система ЭВМ. Целые числа без знака и со знаком.
Введем основные понятия на примере 4-х битовых машинных слов. Сразу оговоримся, что такой размер слов практического интереса не представляет, однако основные закономерности сохраняют силу для машинных слов любого размера.
 Предположим, что процессор ЭВМ способен увеличивать (на 1) и дополнять (т.е. инвертировать) 4-х битовые слова. Например, слово: 0010 + 0001 = 0011 - увеличение на 1
Предположим, что процессор ЭВМ способен увеличивать (на 1) и дополнять (т.е. инвертировать) 4-х битовые слова. Например, слово: 0010 + 0001 = 0011 - увеличение на 11101 - дополнение (инвертирование)
При последовательном увеличении 4-х битового слова 0000 на 0001 наступает ситуация, когда слово станет равным 1111 (1510). Если теперь к этому слову будет прибавлена 0001, то получим 0000, т.е. неверный результат (15+1=0) и исходное состояние. Это произошло потому, что слово памяти может состоять только из конечного числа битов. Таким образом, числовая система ЭВМ является конечной и цикличной.
0
Числовая система без знака
Диапазон чисел:
0 15

 000+0001 = 0001 (+1)
000+0001 = 0001 (+1) 0001+0001 = 0010 (+2)
0
 010+0001 = 0011 (+3)
010+0001 = 0011 (+3)0011+0001 = 0100 (+4)
………………………..
1
110+0001 = 1111 (+15)Этого неверного результата можно избежать, если битовое слово 1111 принять за код для «-1», тогда получим другую числовую систему со знаком, содержащую как положительные числа (07), так и отрицательные (-1-8). Все слова, которые начинаются с «0» - положительные и нуль, а слова с «1» - отрицательные. При этом старший бит называют знаковым битом. Числовая система со знаком также конечна и циклична.
(

Числовая система со знаком.
Диапазон чисел:
0 7; -1 -8 или
– 8 до +7 (- 23 до 23 - 1)
 0) 0000 (+8) 1000 (-8)
0) 0000 (+8) 1000 (-8) (+1) 0001 (+9) 1001 (-7)
(
-1
+1
+2) 0010 (+10) 1010 (-6)
(+3) 0011 (+11) 1011 (-5)
(
 +4) 0100 (+12) 1100 (-4)
+4) 0100 (+12) 1100 (-4)(+5) 0101 (+13) 1101 (-3)
(+6) 0110 (+14) 1110 (-2)
(
+7) 0111 (+15) 1111 (-1)Если знаковый бит = 0, то значение числа легко вычисляется (3 бита младших разрядов интерпретируются как двоичный код десятичного числа). Если знаковый бит = 1, то для оценки отрицательного числа нужно:
- выполнить операцию инвертирования;
- к полученному результату прибавить единицу.
Эти правила вытекают из следующих соображений. Рассмотрим число (- k) в системе со знаком, представив его как: - k = (-1- k)+1, т.е. для получения числа (- k) надо из - 1 (1111) вычесть число k и прибавить 1. При этом операция вычитания: а) всегда возможна и не требует заема; б) равнозначна операции инвертирования битов вычитаемого числа k.
Примеры. 1. Пусть k = 0011 (3). Тогда: – k = (1111 - 0011) + 0001 = 1100 + 0001 = 1101 (-3), где величина 1100 представляет собой инвертирование числа 0011 (3) или дополнение до единицы, а число 1101 называют дополнением до двух. Таким образом, инвертирование называется дополнением до единицы, а инвертирование с добавлением единицы к младшему биту называется дополнением до двух.
2. Пусть есть слово 1010. Какое отрицательное число в нем закодировано? Согласно вышеприведенным правилам это число надо инвертировать и добавить 0001. Инвертируя, получим 0101. Добавив 0001, получим 0110. А это есть двоичный код числа 6, следовательно, число 1010 есть код числа -6.
3. Определите, какие отрицательные числа закодированы в словах 1011; 1100; 1001?
Индикаторы переноса и переполнения.
Рассмотрим неверный арифметический результат, который возникает из-за конечной числовой системы ЭВМ.
В числовой системе без знака это будет: 1111+0001 = 0000 (15+1 = 0) возникает перенос единицы из знакового бита.
В числовой системе со знаком: 1111+0001 = 0000 (-1+1 = 0 – это верно), но
0111+0001 = 1000 (7+1 = - 8 – это неверно) возникает перенос в знаковый бит.
Для регистрации переноса из знакового бита процессор имеет индикатор переноса (он содержит один бит информации: 1 – индикатор установлен, 0 – индикатор сброшен). Для регистрации переноса в знаковый бит процессор имеет индикатор переполнения (также 1 - установлен, 0 - сброшен). Если индикатор переноса установлен, то произошла неверная арифметическая операция в системе без знака, если сброшен, то произошла верная операция. Если индикатор переполнения установлен, то произошла неверная арифметическая в системе со знаком. Кроме того, установление или сброс индикаторов зависит еще и от выполняемой операции (например, сложение двух чисел с одинаковым знаком или сложение двух чисел с разными знаками). При конструировании ЭВМ эти условия учитываются и аппаратура разрабатывается таким образом, чтобы индикаторы переноса и переполнения давали информацию о правильности выполнения операций в целом ряде обстоятельств.
Итак, обработка числовой информации в процессоре зависит от длины машинного слова, при этом старший бит машинного слова является знаковым. Представление целых чисел в памяти ЭВМ зависит от того, сколько байт памяти отводится под целое число. Если целое число занимает 2 байта, тогда схему хранения целых чисел можно представить следующим образом:

Диапазон изменения таких чисел равен: - 215 до (215 – 1) ( - 32768 до +32767)
Диапазон изменения целых чисел, которые занимают:
1 байт (8 бит) : - 27 до (27 – 1) (- 128 до +127)
4 байта (32 бита): - 231 до (231 – 1 ) (-2147483648 до + 2147483647)
Отрицательные целые числа представляются в дополнительном коде (посредством операции дополнения до 2-х). Например, для 16-ти битового слова число «- 5» будет иметь код:
1111111111111011 (0000000000000101(+5) 1111111111111010 +00000000000000001 1111111111111011)
Представление вещественных чисел.
Любое вещественное число Х, представленное в системе счисления с основанием N, можно записать в виде: X = mNp, где m – мантисса, P – характеристика (или порядок) числа. И это число будет нормализованным, если после запятой в мантиссе стоит не нуль.
Примеры. а) 372,95 = 0,37295103
0,000000343 = 0,34310-5
б) 11010,1101 = 0,11010110125
0,011011 = 0,110112-1
Порядок определяет, насколько разрядов необходимо осуществить сдвиг относительно запятой. Это так называемые числа с плавающей запятой.
В памяти ЭВМ вещественные числа, приведенные к нормализованной форме, хранятся следующим образом. Для 32-х битового слова:

Диапазон порядка: -27 до (27 – 1) (-128 до +127) ( при этом один бит из восьми отводится под знак порядка).
Диапазон мантиссы: -223 до (223 – 1) (-8388608 до 8388607)
Диапазон вещественного числа: 1.1754944E-38 до 3.4028235E+38, где 1.1754944E-38 - машинный нуль, а 3.4028235E+38 – мах вещественное число, после которого будет переполнение. Мах вещ. число равно
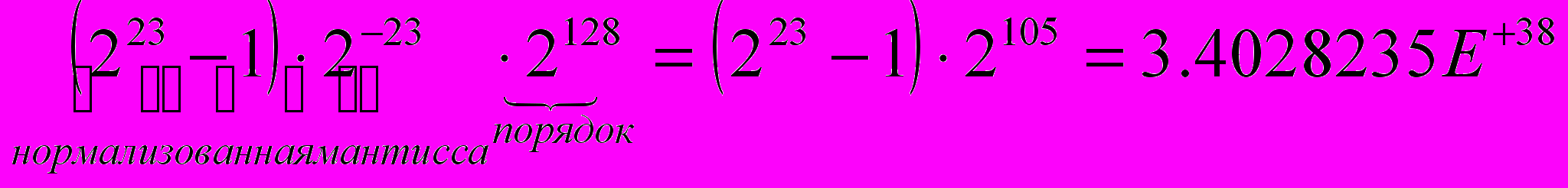 .
.Порядок числа равен 128, а не 127, т.к. следует иметь в виду, что хотя для мантиссы отведены 23 разряда для одинарной точности и 55 разрядов для чисел двойной точности, в операциях участвуют 24 и 56 разрядов, т.е. имеет место скрытый разряд, который при аппаратном выполнении операций автоматически восстанавливается. Порядок числа учитывает скрытый старший разряд мантиссы.
Т.к. мантисса вещественного числа не может содержать более 7 десятичных цифр (ее мах = 8388607), компьютер при вычислениях отбрасывает лишние цифры в мантиссе, поэтому все вычисления с вещественными числами ЭВМ всегда выполняет приближенно, или с ошибкой. При более точных расчетах используются вычисления с двойной точностью. Нормализованные числа двойной точности занимают в два раза больше памяти (64 бита), под мантиссу при этом отводится 64-9 = 55 бит. В результате мантисса содержит 15 десятичных цифр. Точность расчетов возрастает в два раза.
Арифметические операции с вещественными числами сложнее арифметических операций с целыми числами. При выполнении арифметических операций над числами, представленными в формате с плавающей запятой, надо отдельно выполнять их для порядков и мантисс. При сложении – надо сначала порядки слагаемых уровнять; при умножении - порядки складываются, мантиссы перемножаются; при делении – порядки вычитаются, мантиссы делятся. После выполнения операции надо провести нормализацию результата, если это необходимо, т.е. изменить порядок. Таким образом, запятая в изображении числа все время плавает, что и определило термин: числа с «плавающей запятой».
Представление текстовой информации в ЭВМ.
Для представления текстовых символов в ЭВМ также используется двоичное кодирование. Главное, чтобы при этом соблюдалась взаимная однозначность: каждому символу свой собственный двоичный код. Но сколько же бит при этом необходимо, чтобы эта однозначность соблюдалась? Сначала посчитаем, сколько символов надо закодировать (см.табл.).
| Символы | Число кодов |
| Цифры 09 | 10 |
| Знаки препинания, математические символы, специальные символы ($, # и т.д.) | 34 |
| Прописные и строчные латинские буквы | 26+26=52 |
| Управляющие символы | 32 |
| Итого: | 128 |
Отечественной версией кода ASCII является код КОИ – 7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования (коды 128 255). Отсутствие единого стандарта в этой области (128 255) привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта, кодировки: Windows – 1251 (кодировка введена фирмой Microsoft для символов русского языка); КОИ -8 (код обмена информацией, восьмизначный); ISO (International Standard Organization – международный институт стандартизации) – международный стандарт, в котором предусмотрена кодировка символов русского алфавита.
В связи с изобилием систем кодирования возникает задача перекодировки символов. Это неудобно. Как быть? Надо увеличить число разрядов для кодирования символов, например, в два раза. Это позволит увеличить число кодируемых символов до 216 = 65536 – этого вполне достаточно для размещения в одной таблице символов большинства языков планеты. Такая система, основанная на 16-ти разрядном кодировании, получила название универсальной – UNICODE. Но в системе UNICODE все текстовые документы автоматически становятся вдвое длиннее. Однако, начиная с 90-х, вычислительные средства располагают достаточными ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования UNICODE.
Кодирование графических данных.
Графическая информация представляется в ЭВМ двумя способами: растровым и векторным. Они различаются тем, что при растровом способе изображение представляют в виде совокупности точек, а при векторном более крупными объектами - линиями и фигурами, созданными из линий.
Стандартных приемов кодирования векторных изображений, в общем, не существует, поскольку каждая программа делает это по-своему, применяя для этого свои внутренние форматы. С кодированием растровых изображений, состоящих из точек, дело обстоит несколько проще, хотя и здесь есть немало различных форматов, например BMP, TIFF, PCX, GIF, JPG и т. д. Наиболее простым является формат BMP, поскольку в нем не используются методы сжатия информации и точечная структура изображения, в общем, соответствует битовой структуре данных, хотя вид этого соответствия меняется в зависимости от того, сколько цветов имеет изображение.
При растровом изображении экран дисплея можно представить в виде прямоугольной сетки с шагом по осям x и y равным единице, называемой растровой моделью.
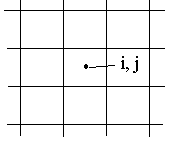
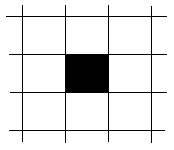
Точка инициализации находится в центре квадратной сетки. Инициализации точки растра (i, j) соответствует закраска квадрата сетки, в центре которого эта точка расположена. Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных.
Черно-белое изображение. Для черно-белого изображения на кодирование одной точки достаточно одного бита. Черная точка обозначается нулем, а белая - единицей.
Общепринятым на сегодня считается представление черно-белых иллюстраций в виде комбинаций точек с 256 градациями серого цвета и, таким образом, для кодирования яркости любой точки обычно достаточно 8-ми разрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие: красный (Red, R), зеленый (Green, G) и синий (Blue, B). Такая система кодирования называется системой RGB: на практике считается, что любой цвет, видимый человеческим глазом, можно получить механическим смешением 3-х цветов.
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (8 двоичных разрядов), то на кодирование одной точки надо затратить 24 разряда. При этом можно получить 224 = 16,5 млн значений для однозначного кодирования различных цветов. Режим представления цветной графики с использованием 24-х двоичных разрядов называется полноцветным (True Color). В этом случае потребность ни в каких вспомогательных таблицах-палитрах не возникает, поскольку количество цветов, выражаемых в режиме True Color, и так достаточно близко к количеству цветов, которые способен различить человеческий глаз.
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, т.е. цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных двух цветов. Соответственно, дополнительными цветами являются голубой (Cyan, C), пурпурный (Magenta, M) и желтый (Yellow, Y). Принцип декомпозиции произвольного цвета на составляющие компоненты можно применить не только для основных цветов, но и для дополнительных, т.е. любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. В полиграфии используется еще и черная краска (Black, K). Поэтому данная система кодирования обозначается четырьмя буквами CMYK и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим также называется полноцветным (True Color).
Если уменьшить количество разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но количество кодируемых цветов заметно сократиться.
Изображение с 16 цветами. Для такого изображения используют 4 бита на кодирование цвета каждой точки. Правда, при этом непонятно, какой же цвет соответствует, например, коду 13. Это не характеристика цвета, а только его номер (индекс) в принятой системе кодирования. При таком кодировании код каждой точки растра выражает не цвет сам по себе, а только номер (индекс) в некоей справочной таблице, называемой палитрой. Эта таблица-палитра должна прикладываться к графическим данным (чтобы небо не получилось зеленым, а листья красными), в ней конкретно указано, какой индекс какому реальному цвету соответствует.
Изображение с 256 цветами. Для такого изображения необходимо затратить 8 битов на кодирование цвета каждой точки. К изображению также прикладывается индексная палитра (таблица, содержащая 256 значений).
Изображение High Color. Такими называют изображения, имеющие 65536 (216) цветов. На кодирование цвета каждой точки в этом режиме необходимо 16 бит. К таким изображениям палитра не прикладывается, тем не менее, она имеется и является стандартной (фиксированной).
Кодирование звуковой информации.
Приемы и методы работы со звуковой информацией пришли в вычислительную технику позже. В отличие от числовой, текстовой и графической информации у звукозаписи не было столь длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты. Но если говорить обобщенно, то можно выделить два основных направления.
Метод FM(Frequency Modulation). Этот метод основан на том, что теоретически любой сложный звук можно разложить на последовательности простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а, следовательно, может быть описан числовым параметром, т.е. кодом. В природе звуковые сигналы имеют непрерывный спектр, т.е. являются аналоговыми сигналами. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналого-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи получается не совсем удовлетворительным.
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. В заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в качестве синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.