
Конспект лекций по курсу основы алгоритмизации и программирования для студентов всех специальностей и всех форм обучения Минск 2004
| Вид материала | Конспект |
Содержание2.7. Пример простейшего линейного алгоритма 2.8. Немного истории 3. Синтаксис языка Cи 3.1. Алфавит языка 3.3. Идентификаторы и ключевые слова |
- Методические указания к курсу лекций и задания для контрольных работ по Хозяйственному, 413.98kb.
- Конспект лекций по курсу Начертательная геометрия (для студентов заочной формы обучения, 1032.28kb.
- Конспект лекций для студентов специальности 080110 «Экономика и бухгалтерский учет, 1420.65kb.
- Программа, методические указания и контрольные задания для студентов всех специальностей, 564.84kb.
- Конспект лекций и задания к самостоятельной работе для студентов всех форм обучения, 13.39kb.
- Учебно-практическое пособие для студентов всех специальностей и всех форм обучения, 1395.3kb.
- Методические указания по курсу «Философия» для студентов всех форм обучения всех специальностей, 352.96kb.
- Курс лекций для студентов специальностей 060800, 060500 всех форм обучения Бийск, 1144.22kb.
- Конспект лекций для студентов всех специальностей дневной и заочной формы обучения, 1439.07kb.
- Конспект лекций для студентов, магистров и аспирантов всех специальностей, 373.35kb.
2.7. Пример простейшего линейного алгоритма
 Наиболее часто в практике программирования требуется организовать расчет некоторого арифметического выражения при различных исходных данных. Например, такого:
Наиболее часто в практике программирования требуется организовать расчет некоторого арифметического выражения при различных исходных данных. Например, такого: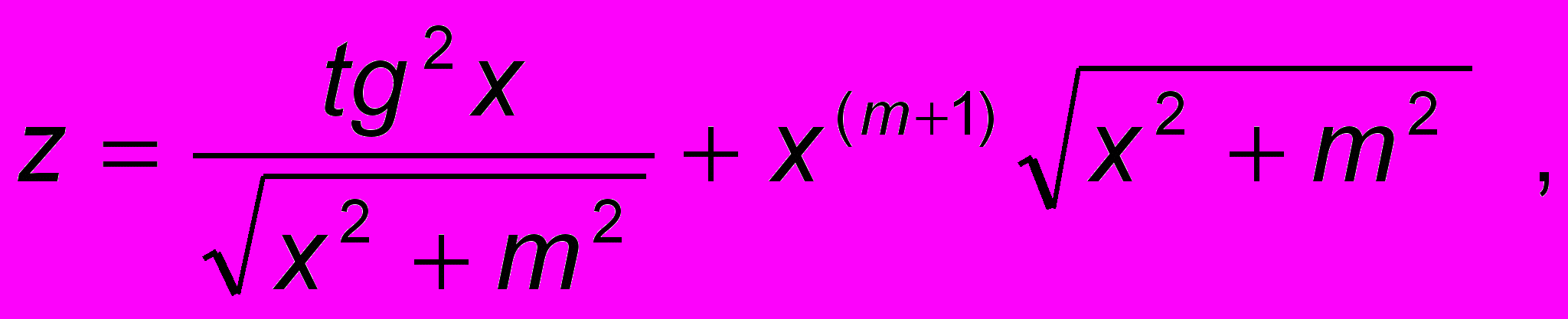
при x>0 - вещественное, m - целое.
Разработка алгоритма обычно начинается с составления схемы. Продумывается оптимальная последовательность вычислений, при которой, например, отсутствуют повторения. При написании алгоритма рекомендуется переменным присваивать те же имена, которые фигурируют в заданном арифметическом выражении, либо иллюстрируют их смысл.
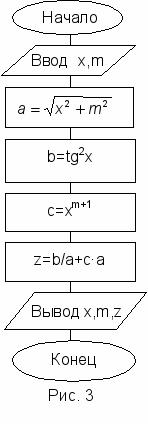
Для того чтобы не было "длинных" операторов, исходное выражение полезно разбить на ряд более простых. В нашей задаче предлагается схема вычислений, представленная на рис. 3.
Она содержит ввод и вывод исходных данных, линейный вычислительный процесс, вывод полученного результата. Заметим, что выражение
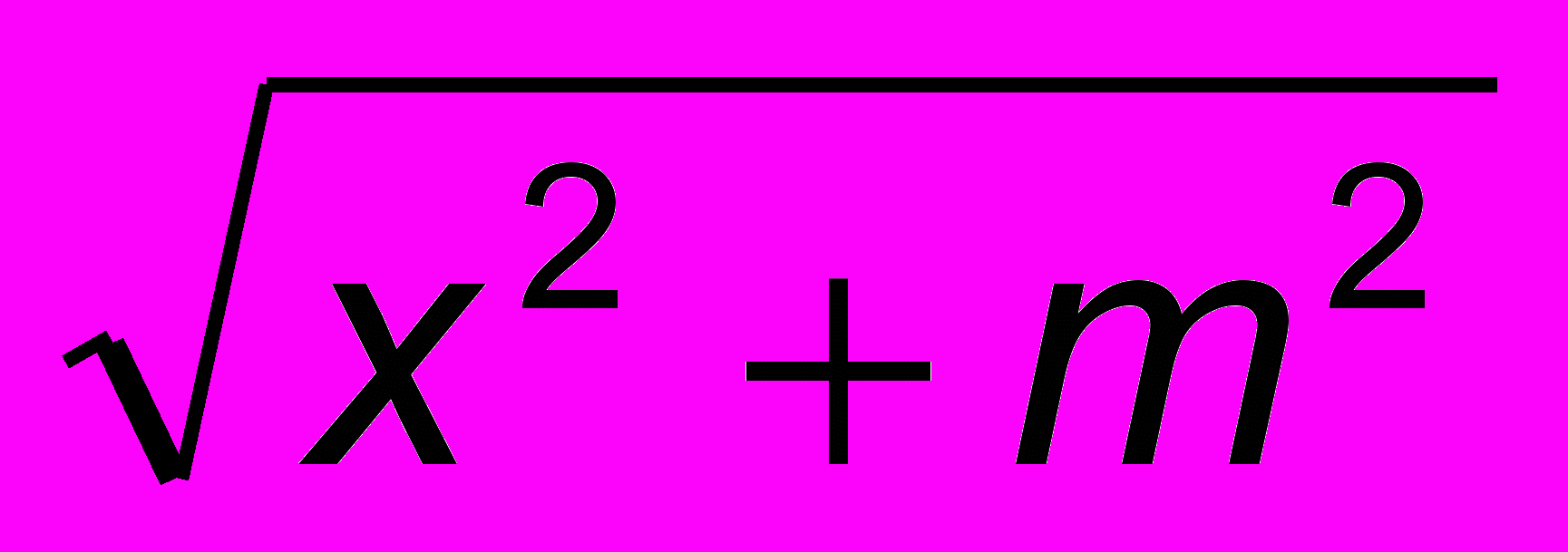 вычисляется только один раз. Введя дополнительные переменные a,b,c, мы разбили сложное выражение на ряд более простых выражений.
вычисляется только один раз. Введя дополнительные переменные a,b,c, мы разбили сложное выражение на ряд более простых выражений.2.8. Немного истории
Алгоритмический язык С был разработан в 1972 г. сотрудником фирмы AT&T Bell Laboratory Денисом Ритчи на базе языка В (автор К.Томпсон), который в свою очередь основывался на языке системного программирования BCPL. Первая версия языка была опубликована в книге авторов Д.Ритчи и Б.Кернигана и получила название стандарт K&R. Минимальная стандартная реализация, поддерживаемая любым компилятором, содержала всего 27 ключевых слов. Началось успешное развитие языка и чтобы избежать путаницы Американский институт стандартизации (American National Standart Institute) ввел в 1983 г. общий стандарт языка – ANSI стандарт.
Язык продолжает развиваться и в 1985 г. появляется язык С++, который в основном сохраняет все черты обычного С, но дополнен новыми существенными возможностями, которые позволили реализовать объектно-ориентированный стиль программирования.
Язык С отражает возможности современных компьютеров. Программы на С отличаются компактностью и быстротой исполнения. Структура С побуждает программиста использовать в своей работе нисходящее программирование, структурное программирование, пошаговую разработку модулей.
Области применения языка C - системное программирование и прикладные задачи с жесткими требованиями по скорости и памяти.
3. Синтаксис языка Cи
В языках программирования вместо номеров ячейкам памяти принято давать имена (идентификаторы), а содержимое ячеек называть переменными, или константами, в зависимости от того, изменяется значение в процессе работы или нет.
В языке Си фундаментальным понятием является инструкция (операция, оператор, функция), которая представляет собой описание определенного набора действий. Таким образом, программа, написанная на языке Си, состоит из последовательности инструкций.
3.1. Алфавит языка
Каждому из множества значений, определяемых одним байтом, - от 0 до 255, в таблице знакогенератора вычислительной машины ставится в соответствие символ. По системе кодировки фирмы IBM символы с кодами от 0 до 127, образующие первую половину таблицы знакогенератора, построены по стандарту ASCII и одинаковы на всех IBM-совместимых компьютерах. Вторая половина символов (коды 128 … 255) может отличаться на разных компьютерах. Обычно коды от 128 до 175 и от 224 до 239 используются для размещения символов национального алфавита, коды с 176 по 223 отводятся под символы псевдографики и коды с 240 по 255 – под специальные знаки (Приложение 1).
Алфавит языка Си включает:
- прописные и строчные буквы латинского алфавита, а также знак подчеркивания (код ASCII 95);
- арабские цифры от 0 до 9;
- специальные символы:
+(плюс) –(минус) *(звездочка) /(дробная черта) =(равно) >(больше) <(меньше) ;(точка с запятой) &(амперсант) [ ](квадратные скобки) { }(фигурные скобки) ()(круглые скобки) _(знак подчеркивания) (пробел) .(точка) ,(запятая) :(двоеточие) #(номер) %(процент) ~(поразрядное отрицание) ?(знак вопроса) !(восклицательный знак) \(обратный слеш).
- пробельные (разделительные) символы: пробел, символы табуляции, перевода строки, возврата каретки, новая страница и новая строка.
3.2. Лексемы
Из символов алфавита формируются лексемы языка – минимальные значимые единицы текста в программе:
- идентификаторы;
- ключевые (зарезервированные) слова;
- знаки операций;
- константы;
- разделители (скобки, точка, запятая, пробельные символы).
Границы лексем определяются другими лексемами, такими, как разделители или знаки операций, а также комментариями.
3.3. Идентификаторы и ключевые слова
Идентификатор (в дальнейшем, для краткости - ID) – это имя программного объекта (константы, переменной, метки, типа, функции, модуля, поля в структуре). В идентификаторе могут использоваться латинские буквы, цифры и знак подчеркивания; первым символом ID может быть буква или знак подчеркивания, но не цифра; пробелы внутри ID не допускаются.
Длина идентификатора определяется реализацией (версией) транслятора Cи и редактора связей (компоновщика). Современная тенденция - снятие ограничений длины идентификатора.
При именовании объектов следует придерживаться общепринятых соглашений:
- ID переменной обычно пишется строчными буквами, например index (для сравнения: Index – это ID типа или функции, а INDEX – константа);
- идентификатор должен нести какой-либо смысл, поясняя назначение объекта в программе, например birth_date (день рождения) или sum (сумма);
- если ID состоит из нескольких слов, как, например birth_date, то принято либо разделять слова символом подчеркивания (birth_date), либо писать каждое следующее слово с большой буквы (birthDate).
Разделители идентификаторов объектов:
- пробелы;
- символы табуляции, перевода строки и страницы;
- комментарии (играют роль пробелов).
Наличие разделителей не влияет на работу программы.
В Си прописные и строчные буквы – различные символы. Идентификаторы Name, NAME, name – различные объекты.
Ключевые (зарезервированные) слова не могут быть использованы в качестве идентификаторов.
Ключевые слова Си:
| auto | break | case | char |
| const | continue | default | do |
| double | else | enum | extern |
| float | for | goto | if |
| int | long | register | return |
| short | signed | sizeof | static |
| struct | switch | typedef | union |
| unsigned | void | volatile | while |