
Конспект лекций для студентов, магистров и аспирантов всех специальностей
| Вид материала | Конспект |
- Конспект лекций бурлачков в. К., д э. н., проф. Москва, 1213.67kb.
- Конспект лекций для студентов всех специальностей дневной и заочной формы обучения, 1439.07kb.
- Курс лекций (для магистров всех специальностей Академии) харьков − 2006, 1136.42kb.
- Конспект лекций по курсу основы алгоритмизации и программирования для студентов всех, 3059.86kb.
- Конспект лекций по курсу Начертательная геометрия (для студентов заочной формы обучения, 1032.28kb.
- Конспект лекций для студентов по специальности i-25 01 08 «Бухгалтерский учет, анализ, 2183.7kb.
- Конспект лекций по курсу "Начертательная геометрия и инженерная графика" Кемерово 2002, 786.75kb.
- Конспект лекций по дисциплине «Маркетинг», 487.79kb.
- Конспект лекций для студентов специальности 080110 «Экономика и бухгалтерский учет, 1420.65kb.
- Конспект лекций по культурологии Для студентов всех специальностей, 4611.53kb.
Федеральное агентство по образованию
Государственное образовательное учреждение
высшего профессионального образования
Санкт-Петербургский государственный университет
низкотемпературных и пищевых технологий
Кафедра информатики и прикладной математики
ЗАЩИТА ИНФОРМАЦИИ
Конспект лекций для студентов,
магистров и аспирантов всех специальностей
Санкт-Петербург
2008
УДК 681.3.06
А.М. Радин. Защита информации: Конспект лекций для студентов магистров и аспирантов всех специальностей. – СПб.: СПбГУНиПТ, 2008, 42 с.
Автор: А.М. Радин
Конспект лекций содержат в сжатом виде материал, необходимый для изучения курса “Защита информации”, а также курсов “Информатика”, “Компьютерные технологии в науке и производстве” студентами, магистрами и аспирантами Санкт-Петербургского государственного университета низкотемпературных и пищевых технологий.
Рецензент
Проф. Л.А.Акулов
Рекомендовано к изданию редакционно-издательским советом университета.
© Санкт-Петербургский государственный
университет низкотемпературных
и пищевых технологий, 2008
Лекция 1.
Введение.
Разработкой методов преобразования (шифрования, зашифрования) информации с целью защиты её от незаконных пользователей занимается криптография. Дешифрование (расшифрование) - процесс, обратный шифрованию, с помощью определённых правил, содержащихся в шифре.
Криптография – прикладная наука, она использует самые
последние достижения фундаментальных наук, и в первую
очередь, математики.
Какие решаются при этом задачи?
Это в основном задачи, решаемые удалёнными абонентами в формате различных протоколов.
Примеры:
- Протокол подписания контракта.
Нельзя допустить ситуацию, когда один абонент получил подпись другого, а сам не подписался.
- Протокол подбрасывания монеты (принятие решения).
Нужно сделать так, чтобы абонент, подбрасывающий монету, не мог изменить результат после получения догадки от абонента, угадывающего этот результат.
- Протокол идентификации абонента. Взаимодействуют два абонента (А - клиент, В - банк). Абонент А хочет доказать В, что он именно А, а не противник.
- Взаимодействуют абоненты, получающие приказ из одного центра. Часть абонентов, включая центр, могут быть противниками. Необходимо выработать единую стратегию действий, выигрышную для абонентов. Эту задачу называют задачей о византийских генералах, а протокол её решения – протоколом византийского соглашения.
Основу решения указанных и других задач составляет интерактивная система доказательств. Это математическая наука, базирующаяся на новейших достижениях математики.
^ P, V, S протоколы.
Под интерактивной системой доказательства (P,V,S) (Prove , Verify, Statement) понимают протокол взаимодействия двух абонентов: P (доказывающий) и V (проверяющий). Абонент P хочет доказать V, что утверждение S истинно. При этом абонент V самостоятельно, без помощи P , не может проверить утверждение S (поэтому V и называется проверяющим). Абонент P может быть и противником, который хочет доказать V, что утверждение S истинно, хотя в действительности оно ложно. Протокол может состоять из многих раундов обмена и должен удовлетворять двум условиям:
- Полнота – если S действительно истинно, то абонент P убедит абонента V признать это.
- Корректность – если S ложно, то абонент P вряд ли убедит абонента V, что S истинно.
Подчеркнём, что в определении системы (P,V,S) не допускалось, что V может быть противником. А если V оказался противником, который хочет выведать у P какую-нибудь новую полезную для себя информацию об утверждении S? В этом случае P, естественно, может не хотеть, чтобы это случилось в результате работы протокола (P,V,S). Протокол (P,V,S), решающий такую задачу, называется протоколом с нулевым разглашением и должен удовлетворять, кроме условий 1) и 2), ещё и следующему условию:
- Нулевое разглашение – в результате работы протокола (P,V,S) абонент V не увеличит свои знания об утверждении S или, другими словами, не сможет извлечь никакой информации о том, почему S истинно.
^ Уровни защищаемой информации.

1

2

3

4
Рис.1 Уровни защищаемой информации компьютера
Информацию защищают как локально (на отдельных компьютерах ) так и глобально (в сети Internet). Уровни защищаемой информации компьютера схематически изображены на рис.1.
Уровень 1 – это аппаратное обеспечение компьютера – система BIOS (Basic Input Output System). Система BIOS обеспечивает возможность защиты компьютера паролем включения CMOS (Complementary Metal-Oxide Semiconductor). Пароль включения снимается путём отключения аккумулятора, поддерживающего автономное электропитание CMOS.
Уровень 2 – это операционная система компьютера (например, Windows XP, Unix, Linux). Операционные системы защищают паролями доступа, имеющимися в каждой из них, и которые контролируются, как правило, системными администраторами.
Уровень 3 – это приложения – комплекс программ, при помощи которых создаётся деловая документация (Ofice, графические редакторы и другие программы). Приложения также защищают паролями доступа, имеющимися в каждом из них.
Уровень 4 – деловая документация (файлы и папки), доступ к которым также может быть защищён паролями. Однако самый надёжный способ защиты деловой документации – это её шифрование.
В процессе обмена между деловыми структурами конфиденциальная информация циркулирует в открытой сети (например, Internet) в зашифрованном виде, потому что создание и обслуживание для этой цели секретных каналов связи экономически не оправдано.
^ Технические аспекты защиты информации.
Из технических аспектов, касающихся защиты информации, следует отметить возможность дистанционного перехвата информации путём регистрации электромагнитного излучения от компьютеров комплексами специальной высокочувствительной измерительной аппаратуры типа TEMPEST (Transient Electromagnetic Pulse Emanations Standard). Это аппаратура двойного назначения. Она предназначена также и для защиты компьютеров от внешнего электромагнитного зондирования. Производитель комплексов TEMPEST - США , потребитель, в основном, Китай.
Разрабатывается также аппаратура для дистанционного считывания информации через сети электропитания компьютеров.
Для эффективной защиты конфиденциальной информации от дистанционного перехвата необходимо экранировать помещения, в которых находятся компьютеры, а также иметь их автономное электропитание. И ещё, при изготовлении, например, плат памяти компьютеров всегда существуют некоторые неконтролируемые аппаратно количества бит в платах (например, в пределах погрешности измерительной аппаратуры). Учитывая современные высоко компактные технологии изготовления плат, этого неконтролируемого количества бит вполне достаточно для размещения на платах в процессе их изготовления коротких программ, например, несанкционированного считывания паролей и пересылки их заказчику по сети.
^ Схема обмена конфиденциальной информацией в открытой сети.
Взаимодействуют два абонента A и B. Абонент A кодирует документ, затем, как правило, архивирует его (сжимает), затем шифрует и передаёт абоненту B по каналу связи. Абонент B действует в обратном порядке: дешифрует, деархивирует, декодирует документ. В этой схеме защита конфиденциальности информации обеспечивается только надёжностью шифрования, поскольку исключить возможность перехвата информации в открытой сети практически невозможно.
^ Кодирование информации.
Компьютеры кодируют информацию стандартным кодом ASCII (American Standart Code for Information Interchange). Код ASCII содержит 256 символов. Первые 128 символов кода (128=27 ) по семь бит (bit, Binary Digit) каждый (позиции 0 – 127) предназначены для кодирования английского алфавита (строчных и прописных букв) и специальных символов клавиатуры компьютера. Вторая часть кода – оставшиеся 128 символов (позиции 128-257) по одному байту
(byte=8 bit) каждый предназначены для кодирования национальных клавиатур. Коды ASCII хранятся в микросхемах, расположенных на тыльной стороне клавиатуры компьютера. Таким образом, после кодирования информация приобретает числовую форму – это последовательность нулей и единиц (двоичный код). В дальнейшем, перед шифрованием, информацию в зависимости от размера документа, как правило, архивируют (сжимают).
Лекция 2.
Принципы архивирования (сжатия) информации.
| - 0 000000 а 1 000001 б 2 000010 в 3 000011 г 4 000100 д 5 000101 е 6 000110 ё 7 000111 ж 8 001000 з 9 001001 и 10 001010 й 11 001011 к 12 001100 л 13 001101 м 14 001110 н 15 001111 о 16 010000 п 17 010001 р 18 010010 с 19 010011 т 20 010100 у 21 010101 ф 22 010110 х 23 010111 ц 24 011000 ч 25 011001 ш 26 011010 щ 27 011011 ъ 28 011100 ы 29 011101 ь 30 011110 э 31 011111 ю 32 100000 я 33 100001 | - 0 00000 а 1 00001 б 2 00010 в 3 00011 г 4 00100 д 5 00101 е 6 00110 ё 7 00111 ж 8 01000 з 9 01001 и 10 01010 й 11 01011 к 12 01100 л 13 01101 м 14 01110 н 15 01111 о 16 10000 п 17 10001 р 18 10010 с 19 10011 т 20 10100 у 21 10101 ф 22 10110 х 23 10111 ц 24 11000 ч 25 11001 ш 26 11010 щ 27 11011 ъ 28 11100 ы 29 11101 ь 30 11110 э 31 11111 ю 32 я 33 | - 0 00000 а 1 00001 б 2 00010 в 3 00011 г 4 00100 д 5 00101 е 6 00110 ж 7 00111 з 8 01000 и 9 01001 й 10 01010 к 11 01011 л 12 01100 м 13 01101 н 14 01110 о 15 01111 п 16 10000 р 17 10001 с 18 10010 т 19 10011 у 20 10100 ф 21 10101 х 22 10110 ц 23 10111 ч 24 11000 ш 25 11001 щ 26 11010 ъ 27 11 011 ы 28 11100 э 29 11101 ю 30 11110 я 31 11111 |
Таблица 1. Примеры равномерного кодирования алфавита.
Рассмотрим русский алфавит из 34 символов: 33 литеры плюс пробел и попытаемся экономно его закодировать. Если на каждый символ выделить 6 бит, то как следует из первого столбца табл.1 – это много.
Если закодировать таким способом какой-либо текст, то в нём будут в качестве балласта циркулировать лишние биты. А если на каждый символ выделить 5 бит, то как следует из второго столбца табл.1, этого будет недостаточно. Исключим из алфавита две буквы: ё и ъ.
Тексты в таком алфавите будут читаться без проблем, а на кодирование алфавита достаточно пяти бит на символ (третья строка табл.1) . Таким образом, для оптимального кодирования необходимо,
чтобы кодируемый текст из n символов имел представление
n=2 m , где m – число бит на один символ. Такое кодирование называют равномерным. Примером кода с равномерным кодированием может служить рассмотренный выше код ASCII.
Закодированный равномерным кодом текст занимает на носителе информации определённое число бит. Возникает вопрос: нельзя ли это число бит уменьшить без ущерба для прочтения текста, т.е. сжать текст? Оказалось, что можно и эту проблему решил ещё до создания компьютеров американский математик Р. Фано (R.Fano), предложив новую схему кодирования текстов.
^ Схема двоичного кодирования по Р. Фано (R.Fano)
Идея Р. Фано заключается в применении к алфавиту языка неравномерной схемы кодирования. На те символы (буквы) языка, которые встречаются в текстах чаще, нужно отводить меньше бит, а на те, которые встречаются реже – больше. При этом используется статистика, т.е. частоты (вероятности), с которыми символы встречаются в текстах, написанных на данном языке.
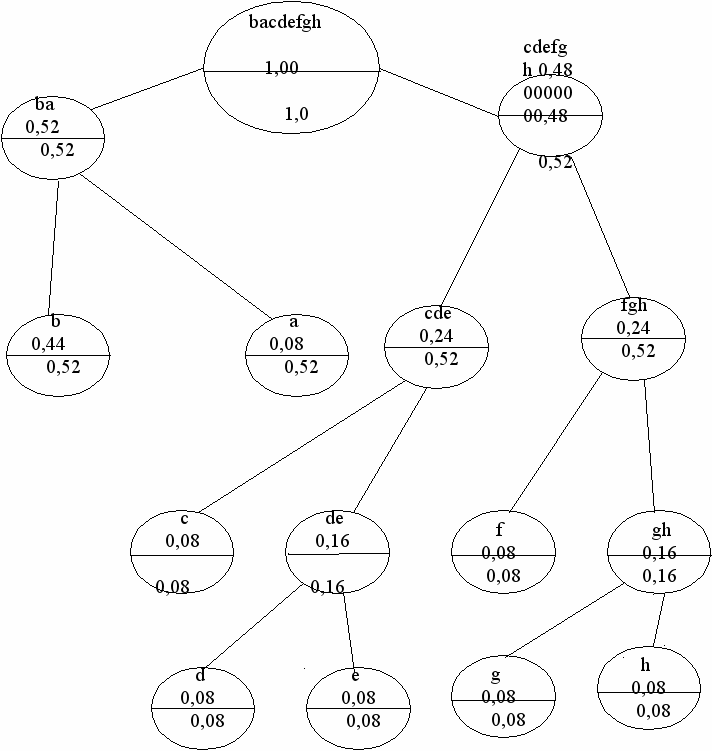
Рассмотрим пример. Пусть для определённости алфавит состоит из 8-ми букв: a, b, c, d, e, f, g, h. При равномерном кодировании достаточно трёх битов на букву, так как 8=23 .
a 000, b 001, c 010, d 011, e 100, f 101, g 110,
h 111
0 1
0 1 0 1
0 1 0 1
0 1 0 1
Рис.2 Пример схемы составления кодовых наборов по Р. Фано.
Если учесть частоты (вероятности) встречаемости букв в текстах, то число бит на букву в среднем можно уменьшить, т.е. сделать его меньше трёх. Пусть, например, частоты для определённости будут:
p(a)= 0,08; p(b)= 0,44; p(c) =0,08; p(d)= 0,08; p(e)= 0,08; p(f) =0,08; p(g) =0,08; p(h) =0,08
Заметим, что сумма частот всегда должна быть равна единице (полная система событий).
Схема кода Р. Фано изображена на рис.2. Она основана на следующем алгоритме:
- составить список букв алфавита в порядке убывания соответствующих им вероятностей.
- разбить этот список на два подсписка таким образом, чтобы значения вероятностей того, что наугад взятая буква окажется в первом или во втором списке, были бы по возможности равны.
- приписать одному из списков символ 0, а другому 1.
- Рассматривая каждый из подсписков как исходный, применить к ним операции 2) и 3).
- Этот процесс продолжать до тех пор, пока в каждом из очередных подмножеств не окажется по одной букве.
- Каждой букве приписать двоичный код, состоящий из последовательности нулей и единиц, встречающихся на пути из исходного множества букв, к множеству, состоящему из одной буквы.
В результате получаем двоичные кодовые наборы Фано для символов данного алфавита.
a 01, b 00, c 100, d 1010, e 1011, f 110, g 1110,
h 1111
Среднее число бит на символ алфавита (подсчитывается по правилу вычисления среднего значения случайной величины) получается равным:
0,082+0,442+0,083+0,084+0,084+0,083+0,084+0,084=
24 0,08+0,442=2,8
Это приводит к сжатию текстов в данном примере (по сравнению с равномерным кодированием) на (1-2,8/3)100 %= ~ 7 % .
Таким образом, Р. Фано открыл качественно новую точку зрения на преобразование информации, что послужило основой для поиска других схем кодирования, которые позволяли бы сжимать тексты в ещё большей степени. Такие схемы были предложены американским математиком Д. А. Хаффмэном (1952). Рассмотрим простейшую из них.
^ Схема двоичного кодирования текстов по Д. А. Хаффмэну (1952)
Идея Д. А. Хаффмэна создания кодовых наборов для символов алфавита основана на учёте не только частот отдельных букв
k=1 k=2 k=3 k=4 k=5
b 0.44 b 0.44 b 0.44 b 0.44 b 0.44
a 0.08 (gh) 0.16 (gh) 0.16 (gh) 0.16 (cda) 0.24
c 0.08 a 0.08 (ef) 0.16 (ef) 0.16 -----------
d 0.08 c 0.08 a 0.08 ------------- 0(gh) 0.16
e 0.08 d 0.08 ------------- 0(cd) 0.16 1(ef) 0.16
f 0.08 ----------- 0c 0.08 1a 0.08
-------- 0e 0.08 1d 0.08
0g 0.08 1f 0.08
1h 0.08
k=6 k=7 k=8
b 0.44 ------------------ (ghefcdab) 1.00
-------------- 0(ghefcda) 0.56
0(ghef) 0.32 1b 0.44
1(cda) 0.24
Таблица 2. Пример схемы для составления двоичного кодового
набора по Д. А. Хаффмэну.
алфавита в текстах, но и частот буквосочетаний.
Алгоритм простейшей схемы кодирования заключается в следующем:
Формируется первый (k=1) столбик, где все буквы алфавита записываются в порядке убывания их вероятностей в тексте, подлежащем кодированию. Напротив каждой буквы пишется соответствующее ей значение частоты (вероятности). Две последние буквы отмечаются двоичными символами 0 и 1.
При известном k – ом столбце строится (k+1) –й столбец по тому же принципу, что и предыдущий, с той лишь разницей, что буквы, отмеченные в предыдущем столбце двоичными символами, в последующем столбце отсутствуют.
В новом столбце их представляет одна составная буква со значением вероятности, равным сумме вероятностей слагаемых букв.
Двоичный кодовый набор каждой буквы строится путём выбора соответствующего ей двоичного символа из последних двух строк каждой таблицы, начиная с конца (в отличие от кода Р. Фано, где двоичные символы считываются при движении из основного множества алфавита к множеству из отдельной буквы).
Рассматривая для сравнения пример из предыдущего параграфа, находим из табл.2, согласно описанному выше алгоритму, кодовые наборы для символов выбранного в качестве примера алфавита.
a 011, b 1, c 0100, d 0101, e 0010, f 0011, g 0000,
h 0001
Среднее число двоичных кодов на один символ алфавита получается равным:
30.08+10.44+40.08+40.08+40.08+40.08+40.08+40.08=270.08+0.44=2.16+0.44=2.6
Это приводит к сжатию текстов на (1-2,6/3)*100 = ~ 13% по сравнению с равномерным кодированием (3 бита на символ в данном примере) и на ~ 6% больше, чем по Р. Фано (2,8 бит на символ, см. предыдущий параграф).
Таким образом, уже из этого простого примера видно, что алгоритм составления кодовых наборов по Д. А. Хаффмэну приводит к большей степени сжатия текстов, чем алгоритм Р. Фано.
Ясно, что далее можно учитывать частоты более сложных буквосочетаний и получать большие степени сжатия текстов. И возникает вопрос: а до какой степени можно сжать и существует ли предел? Этот вопрос был решён американским математиком
К. Шенноном (Shannon C.E., 1945).
Лекция 3.
Сведения из теории информации по К. Шеннону Shannon C.E., 1945).
По количеству полученных результатов и их практической значимости К. Шеннон по праву считается основоположником теории информации. Рассмотрим некоторые из результатов теории Шеннона.
Шеннон впервые ввёл новое понятие – количество информации. Рассмотрим некоторый алфавит, состоящий из n символов с известными частотами для каждого из символов:
i=n
n = 2 m , p i (i=1, 2, … , n) – частоты символов, pi =1.
i=1
Количество информации H в таком алфавите Шеннон определил формулой:
i=n
H= - pi log 2 pi
i=1
Количество информации в алфавите, о котором, кроме частот отдельных его символов, известна дополнительная статистика (например, частоты буквосочетаний) будет выражаться более сложной формулой. Доказательство формулы для H, а также более сложные случаи не рассматриваем. Рассмотрим количество информации в алфавите, в котором частоты символов одинаковы (равновероятны). Тогда
n=2m , p1= p2=… = p n=1/n и H = log 2 n = log 2 2m = m
Но мы уже знаем, что m – это число бит на символ при равномерном кодировании алфавита. Следовательно, количество информации H имеет смысл числа бит на символ при кодировании. Опираясь на свою формулу для H, Шеннон доказал имеющий важное практическое значение результат:
^ В любой схеме архивирования (сжатия) текстов получить число бит на символ меньше, чем это следует из формулы Шеннона для H, невозможно.
Рассмотрим алфавит из 8-символов (8=23):
a, b, c, d, e, f, g, h,
p(b)=0,44; p(a)=p(c)=p(d)=p(e)=p(f)=p(g)=p(h) =0,08.
Для данного алфавита выше было установлено, что при равномерном кодировании достаточно 3-х бит на символ, в схеме Фано в среднем – 2,8 и в схеме Наффмэна – 2,6 бит на символ. Вычислим теперь H по формуле Шеннона для данного алфавита. В результате получается
H= - (0.56ln (0.08)+0.44ln (0.44))/ln(2)=2.5617
Число бит на символ оказалось меньшим, чем в рассмотренных выше схемах. Следовательно, имеется резерв для дополнительного сжатия
 H(p)
H(p)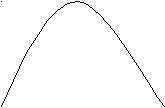
 1
1
0 0.5 1 p
Рис.3. Зависимость H(p) для алфавита из двух бит.
текстов. В программных продуктах для архивирования текстов
(например, Win.zip, Win.rar и др.) разработаны и используются
технически более сложные и более эффективные схемы архивирования, но идейная их основа такая же, как и в
рассмотренных выше примерах.
Рассмотрим алфавит из двух символов (битов): 0 и 1. Частоту одного из битов обозначим через p. Тогда из формулы Шеннона получаем, что H есть функция частоты p:
H(p)= - p log 2 p - (1-p)log 2 (1-p)
Зависимость H(p) изображена на рис.3. Из этого рисунка видно, что
H(p) достигает максимального значения при p=0,5. Отсюда вытекает следующий практически очень важный результат:
^ Для наилучшей информативности двоичный код любого текста должен содержать одинаковое число символов 0 и 1 .
Другими словами, для разгрузки двоичного кода любого текста от балластных битов необходимо, чтобы число битов 0 и 1 в нём было
одинаково. Как следует из формулы К. Шеннона это всегда возможно.
Для дальнейшего нам понадобятся некоторые сведения из арифметики.
^ Необходимые сведения из арифметики.
Приведём без доказательства (для упрощения изложения ) необходимые в дальнейшем факты из арифметики.
Натуральные числа: 1, 2, 3, …, n, … бывают простыми и составными. Простые числа – это числа, которые делятся только на себя и на единицу, например, 1, 2, 3, 5, 7, …. Однако закон распределения простых чисел на числовой оси современной науке не известен. Имеют место теоремы:
^ Основная теорема арифметики: Всякое натуральное число является произведением простых чисел.
Малая теорема Ферма: для любого натурального a и простого p, при условии, что числа a и p не делятся друг на друга
a p-1 1 (mod p).
Примеры: 25 – 2=30 делится на 5, но 29 – 2=510 не делится на 9, почему?
Пусть a, b, p - некоторые целые числа. Если разность чисел a и b делится на p без остатка, то числа a и b называют сравнимыми по модулю p. Эту операцию сравнения чисел обозначают при помощи символа сравнения следующим образом: ab (mod p).
Примеры: 52 (mod 3), 176 (mod 11). Операция сравнения неоднозначна, например, 133 (mod 5) и 138 (mod 5).
^ Числа a и b называются взаимно простыми, если они не имеют общих сомножителей.
Легко проверяется, что a и b не обязательно должны быть простыми.
Функция Эйлера.
Функция Эйлера φ(a) определяется для всех целых положительных a и представляет собою число чисел ряда
0, 1, ..., a-1
взаимно простых с a.
Примеры: φ(1)=1, φ(2)=1, φ(3)=2, φ(4)=2, φ(5)=4, φ(6)=2.
^ Теорема Эйлера.
φ(a)
При m>1 и a взаимно простом с m a 1 (mod m)
Обобщение теоремы Ферма, полученное Эйлером, утверждает:
При взаимно простых p и a
a p-11(mod p).
Лекция 4.