
Автоматическое реферирование и аннотирование
| Вид материала | Лекция |
- Автоматическое реферирование и аннотирование, 125.41kb.
- Автоматическое реферирование и аннотирование текста, 71.7kb.
- Аннотирование и реферирование как основные аспекты формирования письменной компетенции, 100.27kb.
- Учебное пособие рпк «Политехник» Волгоград, 917.7kb.
- У информации, у потребителей информации возникает естественная необходимость в силу, 61.83kb.
- Учебное реферирование и аннотирование в процессе обучения иностранному языку, 97.1kb.
- Общие методические указания по выполнению контрольной работы практика выполнения контрольной, 496.46kb.
- Вид управления ٱ автоматическое ٱ- ручное, 39.33kb.
- Дополнительное задание: обменяться результатами работы (что в качестве "сути" выделил, 39.8kb.
- 3. Высокоуровневая архитектура, 7.97kb.
Лекция №7 Автоматическое реферирование и аннотирование
Рефератом называют:
- доклад на определенную тему, включающий обзор соответствующих литературных и других источников;
- изложение содержания научной работы, книги и т.д.
Под аннотацией понимается краткая характеристика произведения печати или рукописи. Обычно аннотация приводится после библиографического описания источника.
Аннотацию от реферата отличают:
- существенно меньший объем;
- обязательная констатация назначения аннотируемого произведения (для каких категорий читателей оно предназначено).
Автоматические реферирование и аннотирование получили значительную актуальность в связи с развитием Internet и каталогов информационных ресурсов. Для экономии времени поиска пользователям предлагаются каталоги аннотаций и рефератов источников.
Формирование рефератов и аннотаций вручную требует колоссальных человеческих ресурсов, поэтому и возникла задача создания методов автоматического реферирования и аннотирования.
Автоматическое реферирование и аннотирование — одно из направлений компьютерной обработки естественно-языковых текстов. И в этом качестве оно относится к фундаментальным технологиям ИИ.
Основные тенденции для данной области:
- аннотированные каталоги перерастают в гипертекстовые (с их минусами и плюсами);
- на всех крупных сайтах Internet предусматривают оглавления (карта сайта — sitemap) и функции поиска по сайту;
- использование онтологических словарей-тезаурусов общего и специализированного назначения, а также методов ИИ.
Потребности в средствах автоматического реферирования и аннотирования испытывают: корпоративные системы документооборота; поисковые машины и каталоги ресурсов Internet; автоматизированные информационно-библиотечные системы; каналы вещания; службы рассылки новостей и др.
Методы автоматического реферирования и аннотирования подразделяются на поверхностные и глубинные.
Поверхностные методы базируются на «экстрагировании» текста, т.е. извлечении из него фрагментов, оцениваемых системой как важнейшие, и объединении их в реферат или аннотацию. Важность фрагментов определяется:
- по маркерам важности (оборотам типа «идея ... состоит в...», «главным результатом ... является...», «в заключении нужно сказать, что...» и т.д.);
- по количеству заданных в запросе ключевых слов, входящих во фрагмент, и др.
При объединении выделенных предложений в реферат или аннотацию учитываются их зависимости друг от друга (удаленность выделяемых мыслей). «Стыки» между предложениями (фрагментами) «сглаживаются».
Глубинные методы, развиваемые в настоящее время, базируются на применении тезаурусов и развитых механизмов синтаксического разбора текста.
К традиционным системам автоматического реферирования и аннотирования, реализующим поверхностные методы, можно отнести:
- Microsoft Word (функция автоматического реферирования);
- ОРФО 5.0 (разработчик — компания «Информатик»), включающую функцию автоматического аннотирования русских текстов;
- «Либретто» (разработчик — компания «МедиаЛингва»), обеспечивающую автоматическое реферирование и аннотирование русских и английских текстов (система встраивается в Word);
- пакет «МедиаЛингва Аннотатор SDK 1.0», служащий инструментарием для реализации функций автоматического реферирования и аннотирования в прикладных ИАС;
- поисковую систему «Следопыт», включающую средства автоматического реферирования и аннотирования документов;
- поисковую машину «Золотой Ключик» компании Textar, обеспечивающую составление рефератов и аннотаций;
- Intelligent Text Miner (IBM);
- Oracle Context;
- программные компоненты для разработки систем управления знаниями Inxight Summarizer фирмы Inxight Software, Inc.
Перечисленные средства обеспечивают выбор оригинальных фрагментов из исходных документов и соединение их в короткий текст.
Сделаем два замечания. Во-первых, источниками информации для рефератов и аннотаций могут служить не только тексты, но и видеозаписи, разнообразные табличные документы и т.д. Во-вторых, краткое изложение предполагает передачу основной мысли не обязательно теми же словами.
Основные требования к реферату:
- сжатие (объем реферата должен составлять от 5 до 30 % от объема исходного документа);
- возможность использования нескольких источников;
- выражение всех основных мыслей оригинала.
Выделяют три вида рефератов:
- повествовательные, формирующие общее представление об источнике;
- информационные, заменяющие источник (содержат основную или новую фактическую информацию);
- критические (обзоры), отражающие не только суть источника, но и мнение о нем (т.е. содержащие дополнительные выводы, которых нет в оригинале).
Построение реферата человеком включает следующие этапы:
- анализ источника;
- выделение в источнике наиболее важных и информативных фрагментов;
- формирование выводов.
В теории автоматического реферирования различают три основных подхода. Первый из них не предполагает опору на знания, связанные с текстом на ЕЯ. В системах такого типа применяется универсальная база правил, не зависящая от ПрО и языка текста. Второй подход предусматривает выделение различных уровней понимания текста, что требует использования наряду с универсальными правилами БЗ о ПрО и базы лингвистических правил, зависящих от языка. Третий подход является гибридным. Он сочетает лучшие стороны первых двух.
В системах первого типа (т.е. воплощающих первый подход) применяется метод составления выдержек. Он реализуется в два этапа. На первом проводится сопоставление текста и фразовых шаблонов, в результате чего выделяются блоки наибольшей лексической и статистической релевантности. На втором — путем соединения выделенных фрагментов формируется итоговый документ.
Для реализации первого этапа используют модель линейных весовых коэффициентов. В соответствии с ней каждому блоку U текста оригинала автоматически (на основании определенных правил) приписываются весовые коэффициенты:
- к1, зависящий от расположения блока U в оригинале;
- к2, зависящий от частоты появления блока в оригинале;
- к3, зависящий от частоты использования блока в ключевых предложениях;
- к4, отражающий показатели статистической значимости блока.
Затем по значениям к1, к2, к3 и к4 и коэффициентам настройки программы реферирования 1, 2, 3 и 4 вычисляется коэффициент важности блока B(U) = 1к1 + 2к2 + 3к3 + 4к4. По коэффициентам важности выполняется отбор блоков в реферат.
Для вычисления каждого весового коэффициента используется своя группа правил. Для к1 они учитывают расположение блока:
- во всем тексте или некотором разделе;
- в начале, середине или конце текста;
- во вводной части, заключении и т.д.
Для к2 правила учитывают результаты автоматической индексации документа (например, соотношение между частотой появления термина в документе и в наборе документов).
Для к3 учитывается наличие в блоке таких ключевых фраз и выражений, как «в заключение...», «в данной статье...», «согласно результатам анализа...», «отличный от...», «малозначащий...» и т.п.
Для к4 правила учитывают вхождение термина в заголовки, колонтитулы, первый параграф текста, пользовательский профиль запроса и т. п.
Настройка с помощью коэффициентов 1, 2, 3 и 4 позволяет управлять степенью сжатия.
На рис. 1 изображена обобщенная архитектура системы автоматического реферирования первого типа.

Рис. 1. Обобщенная архитектура системы автоматического реферирования
Главное достоинство описанной модели линейных весовых коэффициентов заключается в простоте ее реализации, а главный недостаток связан с возможностью формирования бессвязных рефератов, не учитывающих контекст. Для его устранения вводится этап ручного редактирования результатов.
Схема автоматического определения критериев адекватного выбора фрагментов оригинала для реферата используется в системе Inxight Summarizer (рис. 2).
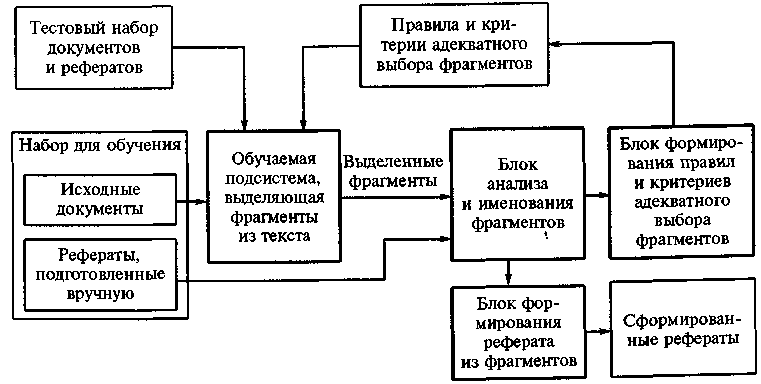
Рис. 2. Схема автоматического определения критериев адекватного выбора фрагментов
Обучение (настройка) системы осуществляется на наборах текстов и рефератов, составленных для них вручную при различных критериях сжатия.
Человеку, уловившему общий смысл информации, легче выделить главное и кратко изложить содержание. Это и обусловливает создание реферирующих систем второго типа. Для таких систем требуются:
- мощные вычислительные ресурсы;
- развитые грамматики и словари;
- развитые средства синтаксического разбора;
- средства генерации естественно-языковых конструкций;
- онтологические справочники.
В этих системах реализуются три подхода:
1) традиционный метод синтаксического разбора;
2) подход с опорой на понимание ЕЯ;
3) комбинированный подход.
В первом случае для построения деревьев разбора используется синтаксическая информация. Процедуры сжатия манипулируют деревьями с целью сокращения скобок, подчиненных предложений и т.д. При этом дерево разбора упрощается до «структурной выжимки».
При втором подходе в результате разбора строится не дерево, а семантическая сеть текста. Другими словами, в ходе разбора выделяются концептуальные репрезентативные структуры исходного текста. Из них удаляется избыточная информация: поверхностные суждения, концептуальные подграфы. Далее выполняется агрегирование и обобщение информации: слияние некоторых концептуальных графов на базе правил. В результате получается «концептуальная выжимка».
Обобщенная схема для этих двух методов представлена на рис. 3.
Стадии синтеза реферата в обоих подходах почти совпадают (используется генератор текста).
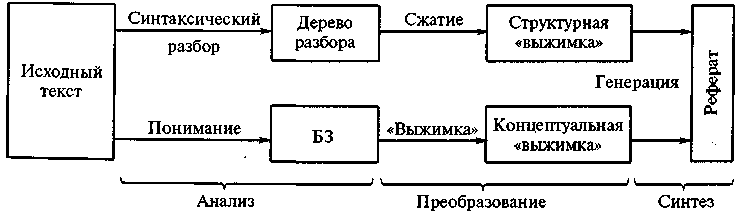
Рис. 4. Два основных подхода к формированию реферата в системах с опорой на знания
Для функционирования подобных систем необходимы:
- исчерпывающие словари (тезаурусы) типа WordNet;
- онтологические справочники типа Сус и Penman Upper Model;
- большие объемы тестовых файлов с текстами (например, The Wall Street Journal или Perm Treebank от Linguistic Data Consortium).
Отметим следующие новые задачи, связанные с компьютерным реферированием.
1. Создание одноязычных рефератов из источников на разных языках.
2. Построение рефератов по гибридным источникам, включающим как текстовые, так и числовые данные в разных формах (таблицы, диаграммы, графики и т. д.).
3. Создание рефератов на основе массивов документов. Например, построение единого реферата по сборнику тезисов докладов научной конференции. Одна из областей применения подобных средств — формирование новостных сообщений по газетным источникам.
4. Растущий объем мультимедийной информации обусловливает актуальность разработки средств ее автоматического реферирования. Методы извлечения семантики из мультимедийной информации находятся на начальных стадиях развития.
Средства автоматического аннотирования в целом аналогичны средствам автоматического реферирования. Однако требования к сжатию текста для них, как правило, на порядок более жесткие.
Системы, обрабатывающие тексты на ЕЯ, в зарубежной литературе называют NLP-системами (natural language processing).