
Клинико-генетическое прогнозирование риска развития ишемической болезни сердца 14. 00. 05 внутренние болезни
| Вид материала | Автореферат |
- Задачи : Формирование 2-х клинических групп обоего пола: 30 пожилого возраста (65-86, 127.2kb.
- Задачи : Формирование 2-х клинических групп обоего пола: 30 пожилого возраста (65-86, 118.29kb.
- Стратегия диагностики и лечения ишемической болезни сердца в торако-абдоминальной онкохирургии, 788.25kb.
- Клинико-диагностические критерии супрапищеводных синдромов гастроэзофагеальной рефлюксной, 329.02kb.
- «Ставропольская государственная медицинская академия Федерального агентства по здравоохранению, 889.07kb.
- Клинико-функциональные и метаболические характеристики ишемической болезни сердца, 748.58kb.
- Клинико-неврологические и нейропсихологические особенности ишемической болезни мозга, 367.52kb.
- Лечение и профилактика наиболее распространенных заболеваний кровообращения: гипертонической, 5.54kb.
- Постпрандиальная гиперлипемия и ремоделирование артерий у больных с ишемической болезнью, 420.23kb.
- Расписание лекций по дисциплине «внутренние болезни», 62.03kb.
Рисунок 10
На оставшейся группе из 16 признаков были проведены эксперименты по распознаванию на всей исходной выборке в 290 объектов. Результаты показывают, что для данной системы из 16 признаков можно построить алгоритм не уступающий по своей прогностической значимости, представленным выше. Точность метода «линейная машина» составила 90%, голосования - 87.2%.
Обращает внимание, что в систему информативных признаков вошли как традиционные факторы риска, так и дополнительные биомаркеры (лабораторные, инструментальные, генетические). Вес ГИ (0,69) больше по сравнению с весом отдельных генетических маркеров: АроЕ4 (0,45) и TNFα238 (0,29). Удаление генетических признаков из данной системы, приводит к снижению точности распознавания. Такого рода математический анализ позволяет выбрать наиболее информативные биомаркеры, оптимизировать их количество, а также создать наиболее информативную совокупность признаков для решения задач прогноза.
Затем мы сравнили прогностическую значимость традиционных алгоритмов с точностью прогноза, полученного с применением системы «Распознавание». При сравнении AUC ROC для риска Framingham, PROCAM, SCORE индекс Z <1,96, что свидетельствует об отсутствии значимых различий между этими алгоритмами, несмотря на введение поправки для изучаемой популяции в алгоритмах PROCAM и SCORE. AUC ROC, полученная при анализе результатов прогнозирования в программе «Распознавание» составляет 92%, в то время как для шкалы SCORE этот показатель не превышает 72%, что значительно улучшило качество прогноза по сравнению со стандартными алгоритмами (рис.11) (индекс Z составляет 3,26>1,96, p<0,05).
| SCORE | РАСПОЗНАВАНИЕ |
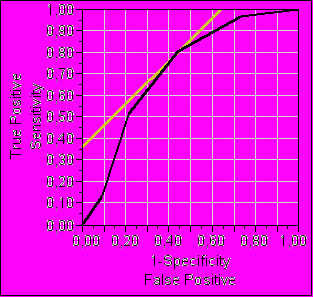 AUC ROC=72% | 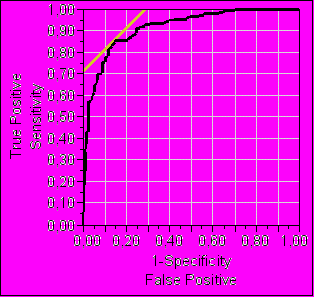 AUC ROC=92% |