
Базы данных
| Вид материала | Документы |
- 1 научиться создавать таблицу базы данных в режиме таблицы, 54.71kb.
- Ms access Создание базы данных, 34.31kb.
- Лекция 2 10. Полнотекстовые базы данных, 133.46kb.
- Практическая работа № «Создание базы данных», 21.96kb.
- Информационные системы, использующие базы данных: оборудование, программное обеспечение,, 102.98kb.
- Конспект лекций по курсу "базы данных" (Ч., 861.92kb.
- Реферат на тему: Access. Базы данных, 274.77kb.
- Лекция №3 нормализация данных, 107.45kb.
- Курсовая работа по дисциплине «Базы данных» на тему: «Разработка базы данных для учета, 154.05kb.
- Создание базы данных “Классный, 73.09kb.
Вопрос № 9 Методы физической организации баз данных
Любое упорядочение данных на диске называется структурой хранения. К сожалению, до сих пор не создана такая идеальная структура хранения, которую можно было бы использовать как оптимальную для любых задач. Но зато можно организовать самые разные структуры хранения, обладающие различной производительностью, область применения которых определяется тем, насколько они эффективны в том или ином случае.
Организация обработки данных посредством реляционных СУБД имеет свою специфику. Файловая структура и система управления файлами подчиняются законам операционной системы. По отношению к базам данных эти принципы могут быть далеки от оптимальности, а потому СУБД подчиняется несколько иным принципам и стратегиям управления внешней памятью.
Обозначим наиболее важные особенности, влияющие на организацию внешней памяти.
- Наличие двух уровней системы: уровня непосредственного управления данными во внешней памяти и языкового уровня. При такой организации подсистема нижнего уровня должна поддерживать во внешней памяти набор базовых структур, конкретная интерпретация которых входит в число функций подсистемы верхнего уровня.
- Необходимость организации отношений-каталогов с метаданными, поддерживаемых подсистемой языкового уровня. С точки зрения структур внешней памяти отношение-каталог ничем не отличается от обычного отношения базы данных.
- Регулярность структур данных обеспечивается тем, что основным объектом реляционной модели данных является плоская таблица.
- Необходимость обеспечить возможность эффективного выполнения операторов языкового уровня как над одним отношением, так и над несколькими отношениями. Для этого во внешней памяти должны поддерживаться дополнительные "управляющие" структуры — индексы.
- Для выполнения требования надежного хранения баз данных необходимо поддерживать избыточность хранения данных, что обычно реализуется в виде журнала изменений базы данных.
Для функционирования СУБД во внешней памяти базы данных возникает необходимость хранить следующие разновидности объектов:
- строки отношений — основная часть базы данных, большей частью непосредственно видимая пользователям;
- управляющие структуры — индексы, создаваемые по инициативе пользователя (администратора) или верхнего уровня системы из соображений повышения эффективности выполнения запросов и обычно автоматически поддерживаемые нижним уровнем системы;
- журнальную информацию, поддерживаемую для удовлетворения потребности в надежном хранении данных;
- служебную информацию, поддерживаемую для удовлетворения внутренних потребностей нижнего уровня системы.
Поскольку СУБД в силу отмеченной выше специфики не может использовать общесистемные механизмы буферизации и управления файловыми структурами, то она вынуждена сама брать на себя полномочия по управлению размещением данных и размещать их на своих внешних носителях, где пространство внешней памяти управляется непосредственно самой СУБД. Такие системы организации данных во внешней памяти опираются на некоторые механизмы, использующие страничный принцип организации.
- Доступ к базе данных
Поиск и предоставление данных пользователю осуществляются с помощью нескольких программ доступа данных и включают в себя три основных этапа (рис. 1).
- Определяется искомая запись, для извлечения которой запрашивается диспетчер файлов.
- Диспетчер файлов определяет страницу, на которой находится искомая запись, и для извлечения этой страницы запрашивает диспетчер дисков.
- Диспетчер дисков определяет физическое положение искомой страницы на диске и посылает соответствующий вопрос на ввод-вывод данных.

Рис. 1. Схема доступа к базе данных
- Страничная организация данных в СУБД
При распределении дискового пространства рассматриваются две схемы структуризации: физическая, которая определяет хранимые данные (рис. 2), и логическая, которая определяет некоторые логические структуры, связанные с концептуальной моделью данных.
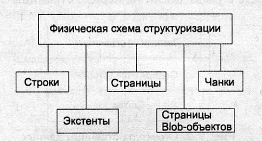
Рис. 2. Классификация объектов физической модели данных
В данной классификации используется ряд понятий.
Страница данных — основная единица осуществления операций обмена (ввода-вывода).
Чанк — представляет собой часть диска, физическое пространство на диске, которое ассоциировано одному процессу.
Экстент — это непрерывная область дисковой памяти.
Страницы Blob предназначены для хранения слабоструктурированной информации, содержащей тексты большого объема, графическую информацию, двоичные коды.
Страницы данных
Основными единицами осуществления операций обмена являются страницы данных, управляемые диспетчером дисков. Все данные хранятся постранично. Таким образом, с точки зрения СУБД база данных выглядит как набор записей, которые просматриваются с помощью диспетчера файлов. С точки зрения диспетчера файлов база данных выглядит как набор страниц, которые могут просматриваться с помощью диспетчера дисков.
На одной странице хранятся однородные данные, например, только данные или только индексы. Все страницы данных имеют одинаковую структуру, представленную на рис. 3.
Заголовок страницы используется для задания посредством указателей логической последовательности страниц в данном наборе. Он также содержит информацию о физическом дисковом адресе страницы, которая логически следует за данной страницей (рис. 4 — правый верхний угол).
Заголовки страниц и указатели на следующие страницы обрабатываются только диспетчером дисков и скрыты от диспетчера файлов. Для выполнения своих функций в распоряжении диспетчера дисков имеется каталог (страница 0), содержащий информацию обо всех имеющихся на данном диске борах страниц вместе с указателями на первые страницы этих наборов

Рис. 3. Определение логической последовательности страниц
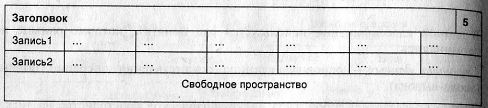
Рис. 4. Определение логической последовательности страниц
Слоты характеризуют размещение строк данных на странице. На одной, странице хранится не более 255 строк.
Таблицы данных
Как правило, на одной странице данных хранятся записи только одной таблицы. Существуют, однако, варианты с возможностью хранения на одной странице записей нескольких таблиц, что иногда позволяет резко сократить число обменов с внешней памятью при выполнении соединений.
Таблица моделируется совокупностью экстентов. Для моделирования каждой таблицы используется два типа экстентов: первый и последующие. Первый экстент задается при создании нового объекта типа таблица, его размер задается при создании. Минимальный размер экстента в каждой системе свой, но в большинстве случаев он равен 4 страницам, максимальный 2 Гбайтам. Новый экстент создается после заполнения предыдущего и связывается с ним специальной ссылкой, которая располагается на последней странице экстента. Внутри экстента идет учет свободных станиц.
Экстенты состоят из четырех типов страниц: страницы данных, страницы индексов, битовые страницы и страницы Blob-объектов (Binary Large Object), которые соответствуют неструктурированным данным. В современных СУБД к этому типу относятся неструктурированные текстовые данные, картинки, просто наборы машинных кодов.
Изменение схемы хранимого отношения с добавлением нового столбца не вызывает потребности в физической реорганизации отношения. Достаточно лишь изменить информацию в описателе отношения и расширять записи только при занесении информации в новый столбец.
Таким образом, подводя итоги рассмотрения общего подхода организации хранения данных и доступа к ним на физическом уровне, следует отметить, что эта организация направлена на то, чтобы обеспечить поддержку функциональности СУБД с максимально возможной эффективностью, причем так, чтобы пользователь не замечал всей сложности и многоступенчатости данной проблемы. Диспетчер дисков скрывает все подробности физической организации ввода-вывода от диспетчера файлов, который ведет работу только на логическом уровне. На своем уровне СУБД уже имеет дело только с хранимыми записями и файлами. С точки зрения СУБД хранимая запись обладает определенной структурой, а с точки зрения диспетчера файлов — это просто битовая строка.
- Файловые структуры баз данных
Файлы и файловые структуры, широко применяемые практически во всех СУБД для хранения информации во внешней памяти, можно классифицировать следующим образом (рис. 6).
Так как файл — это линейная последовательность записей, то всегда в файл можно определить текущую запись, предшествующую ей и следующую за ней
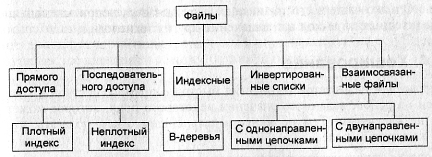
Рис. 6. Классификация файлов, используемых в системах баз данных
Для каждого файла в системе хранится следующая информация:
- имя файла;
- тип файла (например, расширение или другие характеристики);
- размер записи;
- количество занятых физических блоков;
- базовый начальный адрес;
- ссылка на сегмент расширения;
- способ доступа.
Известно, что в соответствии с методами управления доступом различают устройства внешней памяти произвольного и последовательного доступа.
На устройствах последовательного доступа могут быть организованы файлы только последовательного доступа.
Вообще файлы могут иметь постоянную или переменную длину записи. Файлы с переменной длиной записи всегда являются файлами последовательного доступа. Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа, являются файлами прямого доступа.
Наиболее перспективным в системах баз данных считается использование файлов прямого доступа, поскольку посредством их обеспечивается наиболее быстрый доступ к произвольным записям. Для файлов с постоянной длиной записи физический адрес расположения нужной записи может быть вычислен по номеру записи. Но доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в базах данных необходим поиск по ключу, для которого необходимо определить соответствующий ему номер записи, а следовательно, предпочтительнее связывать между собой не номер записи и физический адрес, а значение ключа записи и номер записи файла.
При организации файлов прямого доступа в некоторых очень редких случаях возможно построение линейной обеспечивающей однозначное соответствие функции, которая по значению ключа однозначно вычисляет номер записи файла. Однако чаще всего такой подход оказывается неприемлемым и тогда приходится искать выход в привлечении других технологий.
- Хеширование
Хешированием называется технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля, которое может быть даже не ключевым.
Технология хеширования предполагает следующие моменты:
- Каждая запись БД размещается по адресу, вычисляемому путем применения к значению ключа некоторой функции свертки (хеш-функции), вырабатывающей значение меньшего размера. Свертка значения ключа применяется для того, чтобы избежать неэффективного использования дискового пространства. Достигается подобный эффект подбором специальной функции. Указанная неэффективность обязательно возникнет, если вместо свертки использовать значения непосредственно ключевого поля, которые разбросаны по домену, а если диапазон значений ключевого поля значительно шире диапазона имеющихся адресов, такой подход вообще оказывается неприемлемым. Например, ключевое поле содержит 7 значений в диапазоне 0-1000. В результате использования подходящей хеш-функции получим 7 ее значений в диапазоне 0-9.
- Свертка значения ключа используется и для доступа к записи. Ее полученное значение берется в качестве адреса начала поиска, тем самым ограничивается время поиска (количество дополнительных шагов) для окончательного получения адреса. В самом простом, классическом случае, свертка ключа используется как адрес в таблице, содержащей ключи и записи.
Основным требованием к хеш-функции является равномерное распределение значения свертки, где одному значению хеш-функции может соответствовать одно значение ключа. Однако часто приходится допускать обратное. Если для нескольких значений ключа получается одна и та же свертка, то образуются цепочки переполнения. Подобные ситуации называются коллизиями. Значения ключей, которые имеют одно и то же значение хеш-функции, называются синонимами.
Главным ограничением этого метода является фиксированный размер таблицы. Если таблица заполнена слишком сильно или переполнена, то возни слишком много цепочек переполнения и утрачивается главное преимущество хеширования: доступ к записи почти всегда за одно обращение к таблице. Расширение таблицы требует ее полной переделки на основе новой (со значением свертки большего размера).
Следовательно, при использовании хеширования как метода доступа необходимо принять два независимых решения:
- выбрать хеш-функцию;
- выбрать метод разрешения коллизий.
Стратегии разрешения коллизий:
- Метод последовательного перебора
- Стратегия разрешения коллизий с областью переполнения
- Организация стратегии свободного замещения
- Индексирование
Хотя технология хеширования и может дать высокую эффективность, но для ее реализации не всегда удается найти соответствующую функцию, поэтому при организации доступа к данным широко используются индексные файлы.
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к записи таблицы по ключу. Различают индексированный файл и индексный файл (рис. 7). Индексированный файл — это основной файл, содержащий данные отношения, для которого создан индексный файл.

Рис. 7. Индексированный и индексный файлы
Индексный файл — это файл особого типа, в котором каждая запись состоит из двух значений: данных и указателя. Данные представляют поле, по которому производится индексирование, а указатель осуществляет связывание с соответствующим кортежем индексированного файла. Если индексирование осуществляется по ключевому полю, то индекс называется первичным. Такой индекс к тому же обладает свойством уникальности, т. е. не содержит дубликатов ключа.
Обычно индекс определяется для одного отношения, и ключом является значение простого или составного атрибута.
Основное преимущество использования индексов заключается в значительном ускорении процесса выборки данных, а основной недостаток — в замедлении процесса обновления данных. Действительно, при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс (а это дополнительное время) в индексный файл. Поэтому при выборе поля индексирования всегда важно уточнить, который из двух показателей важнее: скорость выборки или скорость обновления.
Индексы позволяют:
- осуществлять последовательный доступ к индексированному файлу в соответствии со значениями индексного поля для составления запросов на поиск наборов записей;
- осуществлять прямой доступ к отдельным записям индексированного файла на основе заданного значения индексного поля для составления запросов для заданных значений индекса;
- организовать запросы, не требующие обращения к индексированному файлу, а лишь приводящие к проверке наличия данного значения в индексном файле.
Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений ключа в порядке возрастания или убывания значений ключа.
В зависимости от организации индексной и основной областей различают два типа файлов: индексно-прямые файлы и индексно-последовательные файлы.
Индексно-прямые файлы
В индексно-прямых файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а индексная запись содержит значение первичного ключа и порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в индексно-прямых файлах для каждой записи в основной области существует только одна запись из индексной области. Такой индекс называется плотным. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном пространстве.
Наиболее эффективным алгоритмом поиска на упорядоченном массиве является бинарный поиск. При этом все пространство поиска разбивается пополам, и так как оно строго упорядочено, то сначала определяется, не является ли срединный элемент искомым, а если нет, то дается оценка в какой половине его надо искать. Далее установленная половина также делится пополам и производятся аналогичные действия, и так до тех пор, пока не будет обнаружен искомый элемент.
В данном случае двоичный алгоритм поиска применяется к индексному файлу, а потом путем прямой адресации происходит обращение к основной области уже по конкретному номеру записи.
Операция добавления осуществляет запись в конец основной области. В индексной области при этом производится занесение информации так, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения) (рис. 8).
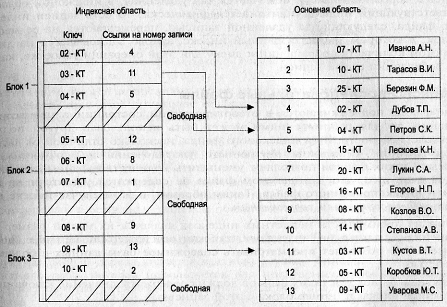
Рис. 8. Организация индексно-прямой адресации
Блок, в который должен быть занесен индекс, копируется в оперативную память, где производится вставка новой записи, и измененный блок записывается обратно на диск.
Естественно, в процессе добавления новых записей процент расширения Постоянно уменьшается. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны два решения: либо перестроить заново индексную область, либо организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записи. Однако первый способ потребует дополнительного времени на перестройку индексной области, а второй увеличит время на доступ к произвольной записи и потребует организации дополнительных ссылок в блоках на область переполнения.
Именно поэтому при проектировании физической базы данных так важно заранее как можно точнее определить объемы хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
Индексно-последовательные файлы
Если файлы поддерживаются в отсортированном состоянии с момента их создания, то для работы с ними может быть использован другой подход с технологией построения индексного файла, несколько отличной от вышерассмотренной. Принципы внутреннего упорядочения и блочности построения таких файлов позволяют уменьшить количество хранимых индексов за счет того, что в индексном файле не содержатся указатели на все записи индексированного файла. Таким образом, в этом случае индекс получается неплотным или разреженным,
Одним из преимуществ неплотных индексов является их малый размер по сравнению с плотными индексами, так как они содержат меньшее число записей. Это позволяет просматривать содержимое базы данных с большей скоростью.
Индексная запись для таких файлов должна содержать: значение ключа первой записи блока и номер блока с этой записью.
Теперь по заданному значению первичного ключа в индексной области требуется отыскать уже нужный блок. Так как все записи упорядочены, то значение первой записи блока позволяет быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области (рис. 9). При переходе к неплотному индексу время доступа уменьшается практически в полтора раза.
При таком подходе новая запись должна заноситься сразу в требуемый блок на требуемое место. Данное занесение осуществляется в оперативной памяти, куда считывается блок основной памяти, который вследствие упорядоченности записей по значению ключа должен принять эту запись. Содержимое считанного блока корректируется, и затем он снова записывается на диск на старое место. Естественно, что для добавления записей уже блок основной области должен иметь свободное место. При внесении новой записи индексная область не корректируется.
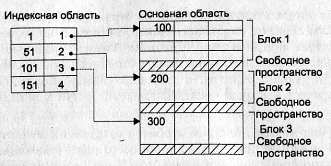
Рис. 9. Организация индексно-последовательной адресации
Уничтожение записи происходит путем ее физического удаления из основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока.
Однако следует отметить:
- с помощью одного неплотного индекса нельзя выполнить проверку наличия некоторого значения;
- в данном хранимом файле может быть, по крайней мере, один неплотный индекс, который организуется по полю, по которому этот файл отсортирован, а остальные индексы обязательно должны быть плотными.
- Организация индексов в виде Б-деревьев
Структура типа Б-дерева является частным случаем бинарного индекса древовидного типа, которая используется для построения наиболее важных и распространенных индексов. Бинарные индексы обладают в большинстве случаев сравнительно высокой производительностью и поэтому в настоящее время их использование предусмотрено почти во всех СУБД, а некоторые СУБД работают только на основе такого индекса.
Высокая производительность бинарных индексов обеспечивается тем, что при их использовании удается избежать обязательного просмотра всего содержимого файла согласно его физической последовательности, которое требует больших затрат времени. Дело в том, что если индексированный файл имеет большой размер, то и его индекс также очень велик и последовательный просмотр даже только одного индекса занимает значительное время.
Построение Б-деревьев связано с простой идеей построения индекса над уже построенным индексом. Действительно, если уже построен плотный (но может быть и неплотный, если в индексированном файле проведена кластеризация на основе индекса) индекс для реальных данных, то сама индексная о6ласть может рассматриваться как основной файл, над которым надо снова построить неплотный индекс.
Записи внутри индекса сгруппированы по страницам, а страницы связаны в цепочку таким образом, чтобы логическое упорядочение на основе индекса осуществлялось внутри первой страницы, затем с помощью физической последовательности записей внутри второй страницы этой последовательной цепочки и т. д. Таким образом, с помощью набора последовательностей можно организовать быстрый последовательный доступ к индексированным данным.
Потом снова над новым индексом строится следующий неплотный индекс и так до того момента, пока не останется всего один индексный блок. Эта операция обычно применяется трижды, поскольку создание большого количества иерархических уровней индексирования требуется для очень больших файлов. При этом индекс на каждом из уровней будет неплотным по отношению к нижнему индексируемому уровню. Таким образом, на самом верхнем уровне такого индекса находится только один элемент структуры (страница, содержащая множество записей), который называется корневым.
Набор индексов обеспечивает быстрый непосредственный доступ к набору последовательностей (а значит, и к данным).
В результате такого построения получится некоторое дерево (рис. 10), каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в одном блоке. Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве. Такие деревья называются сбалансированными потому, что путь от корня до любого листа в этом древе одинаков.
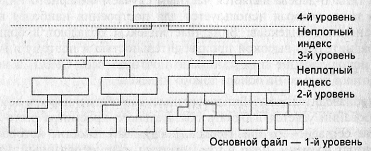
Рис. 10. Б-дерево
Структуры типа Б-дерева относятся к иерархическим системам. Несбалансированность работы иерархических структур является нежелательным их свойством, которое заключается в том, что элементы с реальными данными могут оказаться на разных уровнях и на разных расстояниях от корневого элемента. При работе с такими структурами очень сложно оценить время поиска нужного элемента.
- Инвертированные списки
Базы данных должны предоставлять возможность проводить операции доступа к данным не только по первичным, но и по вторичным ключам. Для обеспечения ускорения доступа по вторичным ключам используются структуры, называемые инвертированными списками.
При организации инвертированного списка можно выделить три уровня (рис. 11).
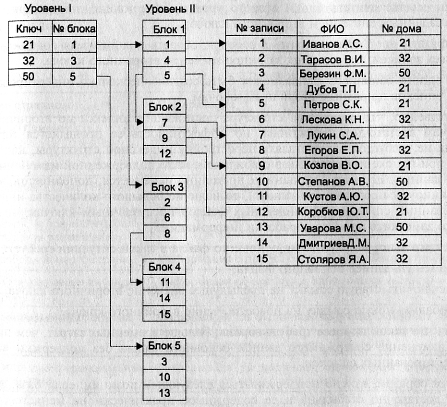
Рис. 11. Уровни инвертированного списка
Самый нижний уровень представлен собственно основным файлом.
Над этим уровнем строится еще два уровня, которые и представляют собой непосредственно инвертированный список.
- На первом уровне этой структуры находится файл, в который помещаются значения вторичных ключей основного файла, причем в упорядоченном состоянии. В этом файле предусмотрено поле, куда помещается ссылка на второй уровень.
- На втором уровне для каждого значения вторичного ключа строится цепочка блоков, содержащих номера записей основного файла с этим значением вторичного ключа. Адрес первого блока такой цепочки и помещается в поле ссылки первого уровня. При этом блоки второго уровня1 также упорядочены по значениям вторичного ключа.
Механизм доступа к записям по вторичному ключу при подобной организации записей состоит в следующем:
- найти в области первого уровня заданное значение вторичного ключа;
- по ссылке считать блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа;
- прямым доступом загрузить в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа.
-