
Базы данных
| Вид материала | Документы |
- 1 научиться создавать таблицу базы данных в режиме таблицы, 54.71kb.
- Ms access Создание базы данных, 34.31kb.
- Лекция 2 10. Полнотекстовые базы данных, 133.46kb.
- Практическая работа № «Создание базы данных», 21.96kb.
- Информационные системы, использующие базы данных: оборудование, программное обеспечение,, 102.98kb.
- Конспект лекций по курсу "базы данных" (Ч., 861.92kb.
- Реферат на тему: Access. Базы данных, 274.77kb.
- Лекция №3 нормализация данных, 107.45kb.
- Курсовая работа по дисциплине «Базы данных» на тему: «Разработка базы данных для учета, 154.05kb.
- Создание базы данных “Классный, 73.09kb.
Вопрос №2. Классификация СУБД
В основу любой классификации закладывается признак классификации.
СУБД можно классифицировать по ряду признаков:
1. По модели данных
2. По типу используемого транслятора
3. По способности настраиваться на предметную область
4. По сфере применения
5. По количеству одновременно открытых файлов и наличию языка программирования
1
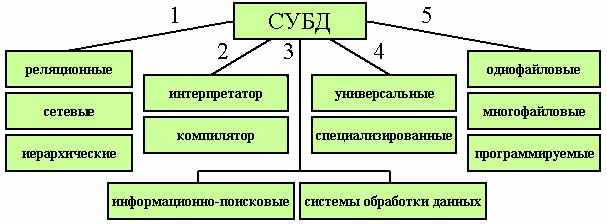 . По модели данных
. По модели данныхРеляционная модель является простейшей и наиболее привычной формой представления данных в виде таблицы со множеством строк (записей) и столбцов (полей). Каждая строка таблицы (запись) содержит сведения об описываемом объекте. Все записи базы данных имеют идентичную, заданную пользователем структуру и размеры. В теории множеств таблице соответствует термин отношение (relation) который и дал название модели. Для нее имеется развитый математический аппарат - реляционное исчисление и реляционная алгебра, где для баз данных (отношений) определены известные теоретико-множественные операции (объединение, вычитание, пересечение, соединение и другие). Достоинством реляционной модели является сравнительная простота инструментальных средств ее поддержки. В настоящее время реляционные системы лучше соответствуют техническим возможностям персональных компьютеров и вполне удовлетворяют большинство пользователей. Недостаток реляционной модели - жесткость структуры данных (ограничения на поля) и зависимость скорости ее работы от размера базы данных. Обработка ведется сразу над множеством записей, для многих операций, определенных в такой модели, может оказаться необходимым просмотр всей базы. Результат выполнения каждой процедуры - создание нового отношения.
Иерархическая модель предполагает наличие множества типов структурных связей между данными, имеющими какой либо общий признак. В иерархической модели такие связи могут быть отражены в виде дерева-графа, где возможны только односторонние связи от старших вершин к младшим. Одна вершина является корневой. В каждую вершину графа может заходить только одна дуга. Обработка начинается обычно с корневой вершины. Движение всегда вниз. Это облегчает доступ к необходимой информации, но только если всевозможные запросы отражены в структуре дерева. Никакие иные запросы удовлетворены быть не могут.
Использование иерархических и сетевых моделей ускоряет доступ к информации в базах данных. Но, поскольку каждый элемент данных должен содержать ссылку на некоторые другие элементы, требуются значительные ресурсы как дисковой, так и основной памяти ЭВМ. Недостаток основной памяти, конечно, снижает скорость обработки данных. Кроме того, для таких моделей характерна сложность реализации СУБД.
2. По типу используемого транслятора
Важной характеристикой любой СУБД является используемый в ней тип транслятора (интерпретатор или компилятор). Программы написанные для системы-интерпретатора, используются лишь в присутствии самой системы. В настоящее время скорость работы таких программ не уступает скорости работы программ, сгенерированных компилятором. Есть много пакетов, которые имеют только один этот компонент. Собственно, СУБД - это, конечно, оболочка пользователя. В виду того, что такая среда ориентирована на немедленное удовлетворение его запросов, это всегда система-интерпретатор. Наличие в СУБД языка программирования позволяет создавать сложные системы обработки данных, ориентированные под конкретные задачи и даже под конкретного пользователя. Компилятор используется для придания завершенной программе вида готового коммерческого продукта в форме независимого EXE-файла.
3. По способности настраиваться на предметную область
По сфере применения можно выделить справочные системы и системы обработки данных. Справочные системы предполагают, что большинство пользователей обращаются к ним для выборки подмножества хранимых данных. (Возможные обработки редки и выполняются в пакетном режиме.) СУБД, ориентированные на справочные функции имеют развитые средства поиска, однако обновление данных в БД идет очень медленно (Справочная служба города). Системы обработки данных характеризуются тем,что большинство пользователей не опрашивает систему, а обрабатывает данные в реальном режиме. Причем обращения к операционной системе, даже если они предполагают вывод, часто представляют собой не подмножество хранимых данных, а результат обработки этих данных. В таких системах усилен аппарат обработки данных.
4. По сфере применения
Различают универсальные и специализированные СУБД. Универсальные СУБД легко настраиваются на любую предметную область. Они предоставляют неограниченные возможности для развития и применения, но при этом требуют существенно больших усилий для проектирования БД. Набор сервисных программ намного меньше. Специализированные СУБД ориентированы на определенный класс приложения. Структура БД уже определена. Имеется развитый набор сервисных программ и, следовательно, внедряется быстро. Недостатком являются ограниченные возможности для ее развития.
5. По количеству одновременно открытых файлов и наличию языка программирования
Некоторые СУБД позволяют в одном сеансе работать только с одним файлом данных и обеспечивают только последовательный доступ к данным. Такие СУБД являются однофайловыми (картотечного типа). Они предназначены для автоматизированного выполнения простых функций, например, хранение списка оборудования на складе небольшого предприятия. Другие позволяют одновременно искать и обрабатывать информацию, находящуюся в нескольких файлах БД - многофайловые СУБД. Распределение информации на несколько взаимосвязанных файлов позволяет избежать дублирования данных, индексирование обеспечивает быструю выборку информации. Такие СУБД реализуют одну из моделей организации базы данных, в основном реляционную. Программируемые СУБД предоставляют пользователю не только стандартные средства манипулирования данными, но ипроблемно-ориентированный язык для создания приложений с нестандартными функциями в соответствии с конкретной задачей.