
Институт
| Вид материала | Конспект |
- Социология семьи и брака, 265.87kb.
- Доклад на Всероссийской научной конференции «От СССР к рф: 20 лет итоги и уроки», 140.15kb.
- Положение о региональном молодёжном конкурсе проектов развития «приграничное сотрудничество:, 101.04kb.
- Рао «еэс россии» безопасность гидротехнических сооружений. Основные понятия. Термины, 272.39kb.
- Гостиная, 170.34kb.
- Ю. С. Пивоваров Прошу подтвердить получение, 33.67kb.
- Институт экономики и бизнеса Институт экономики и бизнеса, 567.55kb.
- Программа фестиваля: 24 февраля, пятница 11. 00- 16. 00 Институт искусств нгпу, ул., 61.01kb.
- Институт дополнительного профессионального образования, 133.98kb.
- Учебник для вузов, 7388.21kb.
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
ВСЕРОССИЙСКИЙ ЗАОЧНЫЙ ФИНАНСОВО-ЭКОНОМИЧЕСКИЙ
ИНСТИТУТ
Кафедра экономико-метематических моделей
ЭКОНОМЕТРИКА
Конспект лекции 4
(часть 2)
КОНЦЕВАЯ Н.В.
2007
Тема 6. Многомерный статистический анализ
Вопросы
- Многомерный статистический анализ. Задачи классификации объектов: кластерный анализ. Дискриминантный анализ.
- Многомерный статистический анализ. Задачи снижения размерности: факторный анализ, компонентный анализ
Данная тема знакомит студентов с некоторыми методами многомерного статистического анализа (МСА), которые получили наибольшее распространение. При изучении данной темы необходимо уделить особое внимание типам задач, для решения которых используются методы МСА. Технология решения задач подробно рассмотрена в [1]. Практическое применение методов МСА требует обязательного использования вычислительной техники и специального программного обеспечения.
Факторный и компонентный анализ в большинстве случаев проводятся совместно.
Компонентный анализ является методом определения структурной зависимости между случайными переменными. В результате его использования получается сжатое описание малого объема, несущее почти всю информацию, содержащуюся в исходных данных. Главные компоненты получаются из исходных переменных путем целенаправленного вращения, т.е. как линейные комбинации исходных переменных. Вращение производится таким образом, чтобы главные компоненты были ортогональны и имели максимальную дисперсию среди возможных линейных комбинаций исходных переменных X. При этом переменные не коррелированы между собой и упорядочены по убыванию дисперсии (первая компонента имеет наибольшую дисперсию). Кроме того, общая дисперсия после преобразования остается без изменений.
Факторный анализ является более общим методом преобразования исходных переменных по сравнению с компонентным анализом.
Кластерный анализ
Кластерный анализ — это совокупность методов, позволяющих классифицировать многомерные наблюдения, каждое из которых описывается набором признаков (параметров) Х1, Х2, ..., Хk. Целью кластерного анализа является образование групп схожих между собой объектов, которые принято называть кластерами (класс, таксон, сгущение).
Кластерный анализ — одно из направлений статистического исследования. Особо важное место он занимает в тех отраслях науки, которые связаны с изучением массовых явлений и процессов. Необходимость развития методов кластерного анализа и их использования продиктована тем, что они помогают построить научно обоснованные классификации, выявить внутренние связи между единицами наблюдаемой совокупности. Кроме того, методы кластерного анализа могут использоваться с целью сжатия информации, что является важным фактором в условиях постоянного увеличения и усложнения потоков статистических данных.
Методы кластерного анализа позволяют решать следующие задачи [2]:
• проведение классификации объектов с учетом признаков, отражающих сущность, природу объектов. Решение такой задачи, как правило, приводит к углублению знаний о совокупности классифицируемых объектов;
• проверка выдвигаемых предположений о наличии некоторой структуры в изучаемой совокупности объектов, т.е. поиск существующей структуры;
• построение новых классификаций для слабоизученных явлений, когда необходимо установить наличие связей внутри совокупности и попытаться привнести в нее структуру.
Дискриминантный анализ
Дискриминантный анализ является разделом многомерного статистического анализа, который включает в себя методы классификации многомерных наблюдений по принципу максимального сходства при наличии обучающих признаков.
Напомним, что в кластерном анализе рассматриваются методы многомерной классификации без обучения. В дискриминантном анализе новые кластеры не образуются, а формулируется правило, по которому объекты подмножества подлежащего классификации относятся к одному из уже существующих (обучающих) подмножеств (классов), на основе сравнения величины дискриминантной функции классифицируемого объекта, рассчитанной по дискриминантным переменным, с некоторой константой дискриминации.
Предположим, что существуют две или более совокупности (группы) и что мы располагаем множеством выборочных наблюдений над ними. Основная задача дискриминантного анализа состоит в построении с помощью этих выборочных наблюдений правила, позволяющего отнести новое наблюдение к одной из совокупностей.
Рассмотрим более подробно факторный анализ
Факторный анализ - это совокупность методов, которые на основе реально существующих связей объектов (признаков) позволяют выявить латентные (неявные) обобщающие характеристики организационной структуры. При этом предполагается, что наблюдаемые переменные являются линейной комбинацией факторов. Под фактором понимается гипотетическая непосредственно не измеряемая, скрытая (латентная) переменная в той или иной мере связанная с исходными наблюдаемыми переменными. К факторному анализу относятся: метод главных компонент, методы многомерного шкалирования, применяемые для формирования факторного пространства по информации о близости объектов, методы кластерного анализа, применяемые для описания неколичественных факторов.
Основные цели факторного анализа:
- сокращение числа переменных (редукция данных);
- определение структуры взаимосвязей между переменными (классификация переменных);
- косвенные оценки признаков, неподдающихся непосредственному измерению;
- преобразование исходных переменных к более удобному для интерпретации виду.
Если кратко охарактеризовать факторный анализ, то наиболее важными являются следующие моменты:
- факторный анализ, в противоположность контролируемому эксперименту, опирается в основном на наблюдения над естественным варьированием переменных;
- При использовании факторного анализа совокупность переменных, изучаемых с точки зрения связей между ними, не выбирается произвольно: сам метод позволит выявить основные факторы, оказывающие существенное влияние в данной области;
- факторный анализ не требует предварительных гипотез, наоборот, он сам может служить методом выдвижения гипотез, а также выступать критерием гипотез, опирающихся на данные, полученные другими методами;
- факторный анализ не требует априорных предположений относительно того, какие переменные независимы, а какие зависимы, метод не преувеличивает причинно-следственные связи и решает вопрос об их мере в процессе дальнейших исследований.
Метод факторного анализа первоначально был разработан в психологии с целью выделения отдельных компонентов человеческого интеллекта из многомерных данных по измерению различных проявлений умственных способностей. Однако очень быстро этот метод завоевал и такие области применения, как социология, экономика, география и многие другие.
Переменные, значения которых можно измерить, имеют для исследуемого объекта нередко достаточно условный характер, лишь опосредованно отражая его внутреннюю структуру, движущие механизмы или факторы. Например, исследователь ставит цель: провести сравнительный анализ темпов экономического роста отдельных регионов (соответствующий пример будет в дальнейшем рассмотрен). Закономерен вопрос: чем измерить экономическое развитие, и какие показатели следует включить в исследование?
Когда неизвестный фактор проявляется в изменении нескольких переменных, в процессе анализа можно наблюдать существенную корреляцию между переменными. Тем самым, факторов может быть существенно меньше, чем измеряемых переменных, число которых выбирается исследователем достаточно субъективно.
Степень влияния фактора на некоторый показатель (переменную) статистически характеризуется величиной дисперсии этого показателя при изменении значений фактора. Если расположить оси исходных переменных ортогонально друг к другу, то можно обнаружить, что в этом многомерном пространстве объекты группируются в виде эллипса рассеяния, более вытянутого в одних направлениях и почти плоского в других. Если теперь провести новые оси соответственно осям эллипса рассеяния, то можно говорить о выделении скрытых факторов и оценивать сравнительную значимость этих факторов в терминах дисперсии. При этом оказывается, что толщина такого эллипса по некоторым осям настолько не велика, что можно исключить их из исследования.
Как правило, применение методов факторного анализа включает три этапа:
- выделение первоначальных факторов;
- вращение выделенных факторов с целью облегчения их интерпретации в терминах исходных переменных (в частности, для исключения отрицательных значений);
- содержательная интерпретация новых факторов в предметных терминах, что является творческой задачей исследователя, выходящей за рамки предлагаемого формального метода.
Наиболее часто факторный анализ используется для выявления в наблюдаемых признаках
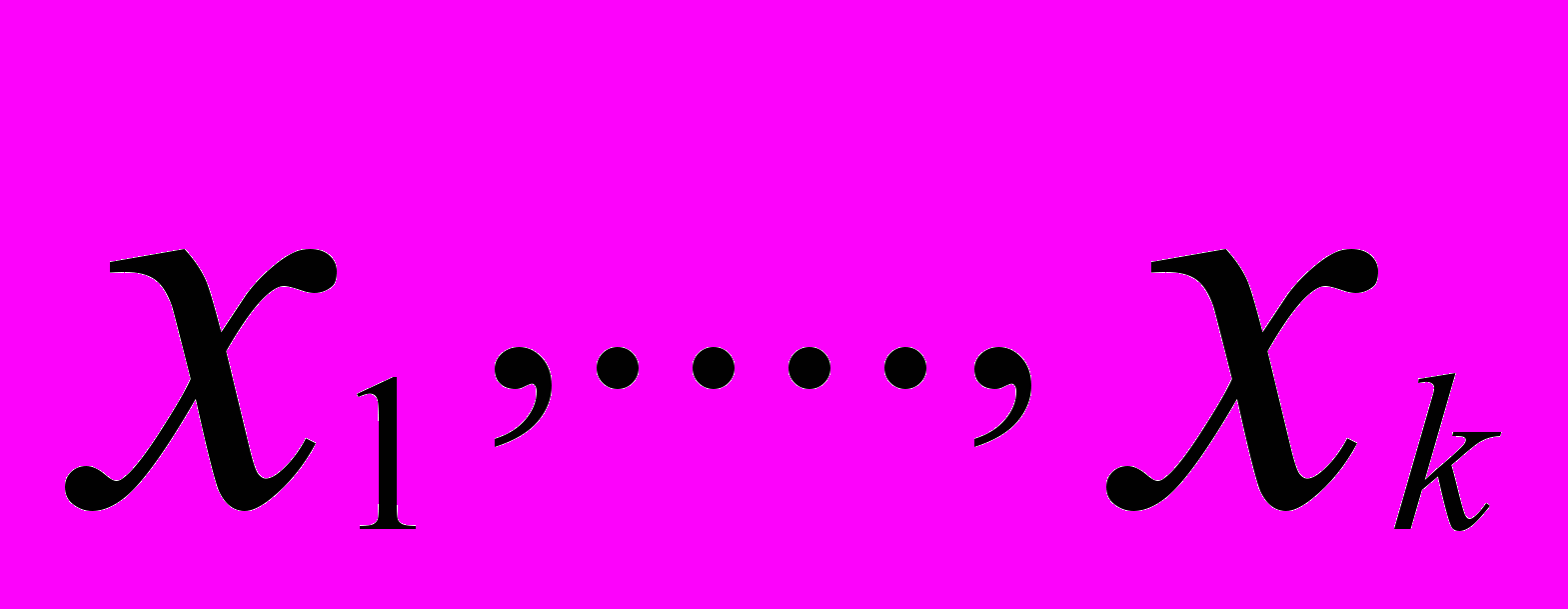 некоторых латентных (скрытых) переменных fm, называемых факторами. Гипотеза о наличии этих факторов основана на предположении о существовании чего-то общего в наблюдаемых признаках. Выводимые гипотетические факторы обладают следующими свойствами:
некоторых латентных (скрытых) переменных fm, называемых факторами. Гипотеза о наличии этих факторов основана на предположении о существовании чего-то общего в наблюдаемых признаках. Выводимые гипотетические факторы обладают следующими свойствами:1. Они образуют линейно независимый набор переменных, т.е. ни один из факторов (компонент) не выводится как линейная комбинация остальных.
2. Переменные, являющиеся гипотетическими факторами, можно разделить на два основных вида – общие и характерные факторы. Они отличаются структурой весов в линейном уравнении, которое выводит значение наблюдаемой переменной из гипотетических факторов. Общий фактор имеет несколько переменных с ненулевым весом или факторной нагрузкой, соответствующей этому фактору. При этом фактор называется общим, если хотя бы две его нагрузки значительно отличаются от нуля. Характерный фактор имеет только одну переменную с ненулевым весом (т.е. только одна переменная от него зависит).
3. Всегда предполагается, что общие факторы не коррелируют с характерным фактором, также характерные факторы не коррелированы между собой.
4. Обычно предполагается, что число общих факторов меньше, чем число наблюдаемых переменных, однако число характерных факторов принимают равным числу наблюдаемых переменных.
Основные этапы применения факторного анализа в случае одного объясняющего фактора
В случае существования только одного фактора суть ФА состоит в объяснении корреляции между наблюдаемыми признаками с помощью корреляции этих признаков с фактором
 В общем случае может быть несколько факторов
В общем случае может быть несколько факторов 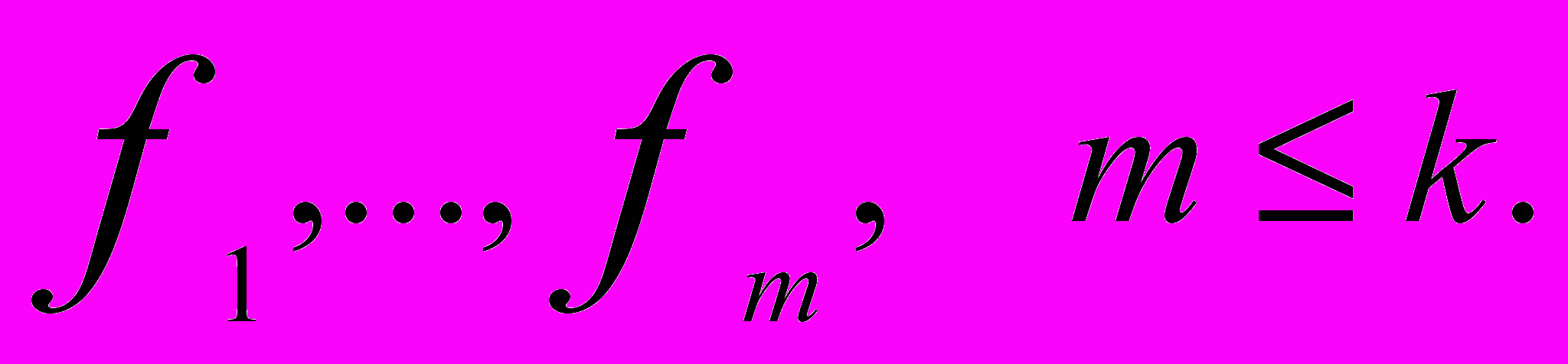 Корреляцию между наблюдаемыми признаками и факторами обозначают
Корреляцию между наблюдаемыми признаками и факторами обозначают 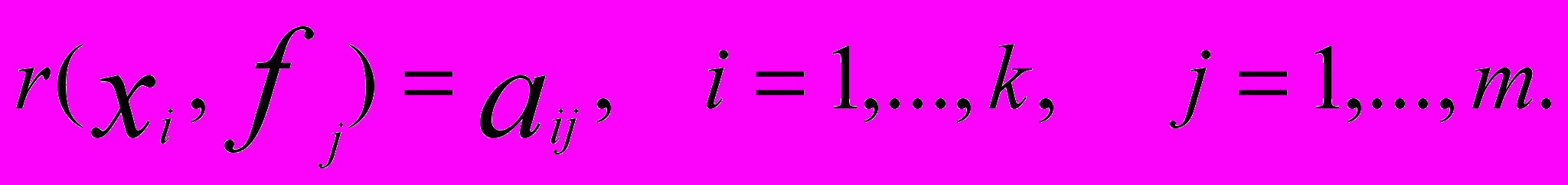 Величины
Величины  называются факторными нагрузками и они образуют матрицу факторных нагрузок
называются факторными нагрузками и они образуют матрицу факторных нагрузок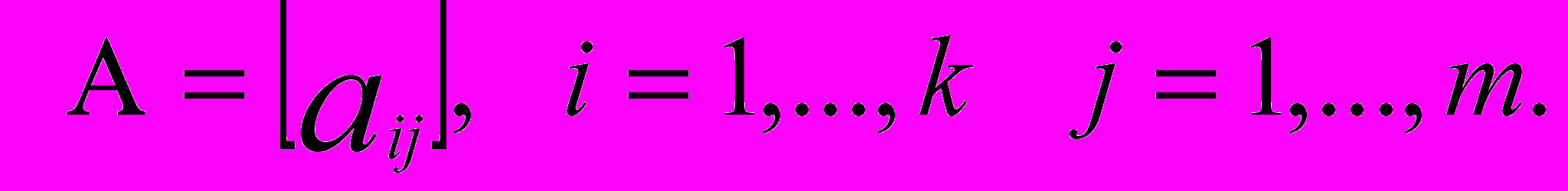
Как правило, основная цель ФА состоит в объяснении корреляционной матрицы признаков R ее матрицей факторных нагрузок
 . Матрицу находят численными методами, определяя собственные числа и векторы матрицы R при условии выполнения
. Матрицу находят численными методами, определяя собственные числа и векторы матрицы R при условии выполнения 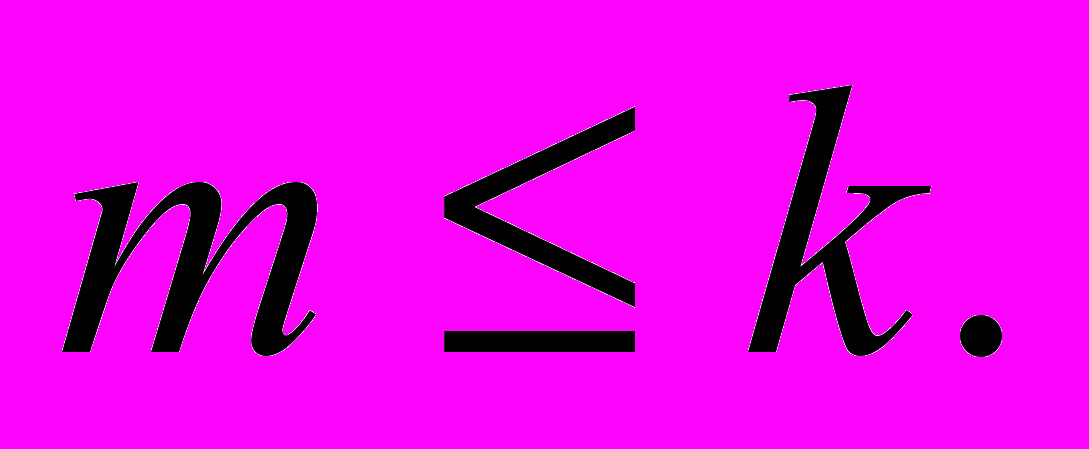
Предположим, существует один объясняющий фактор. На первом этапе формируют матрицу наблюдений (исходных данных),
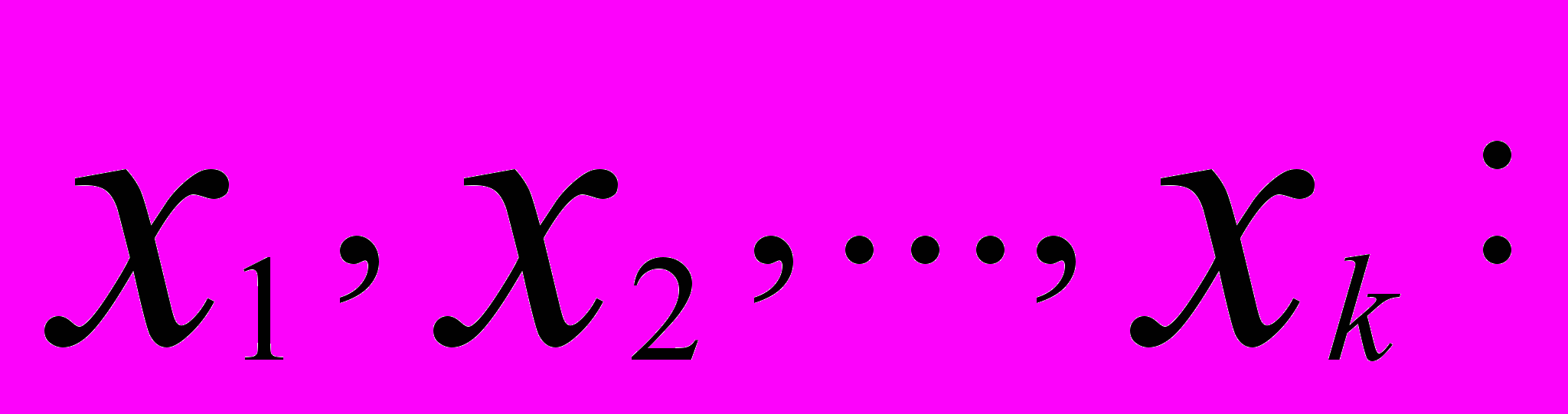
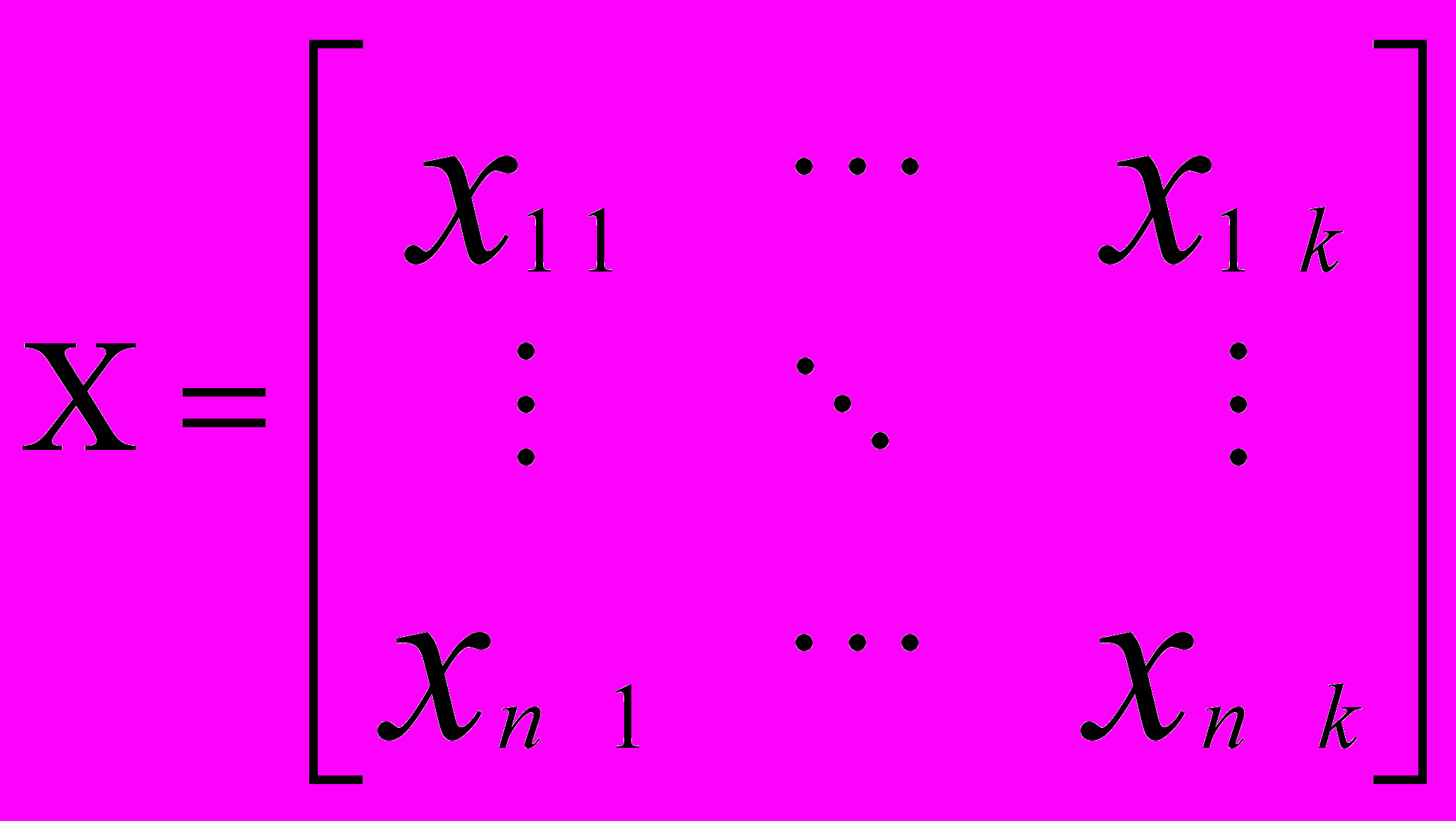
Вычисленная корреляционная матрица матрицы наблюдений X равна:

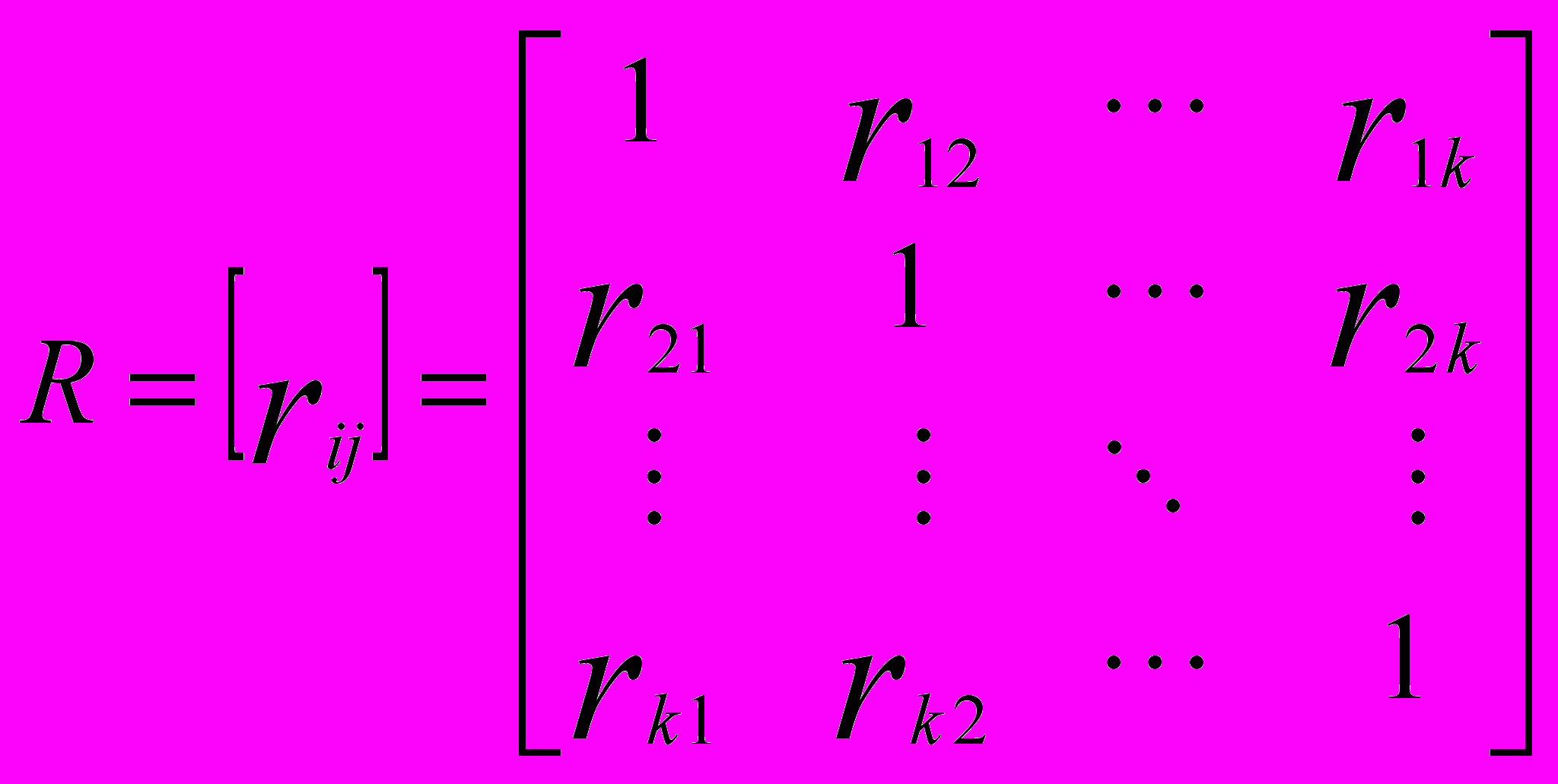
Целью факторного анализа является нахождение латентной переменной, так называемого фактора, который бы позволил воспроизвести наблюдаемую корреляционную матрицу с использованием соответствующей процедуры вычислений. Редуцированную (преобразованную) корреляционную матрицу
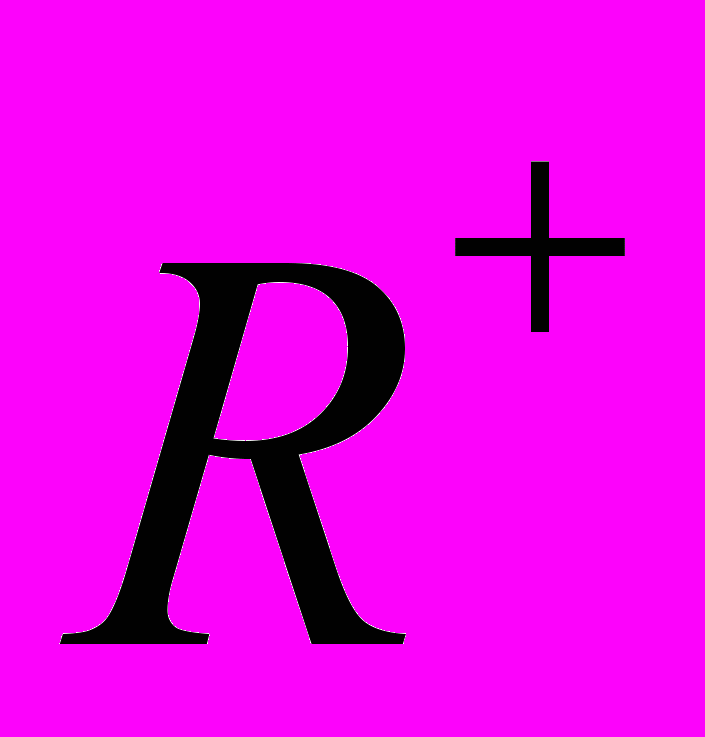 можно воспроизвести с помощью вектора
можно воспроизвести с помощью вектора  факторной нагрузки по уравнению
факторной нагрузки по уравнению 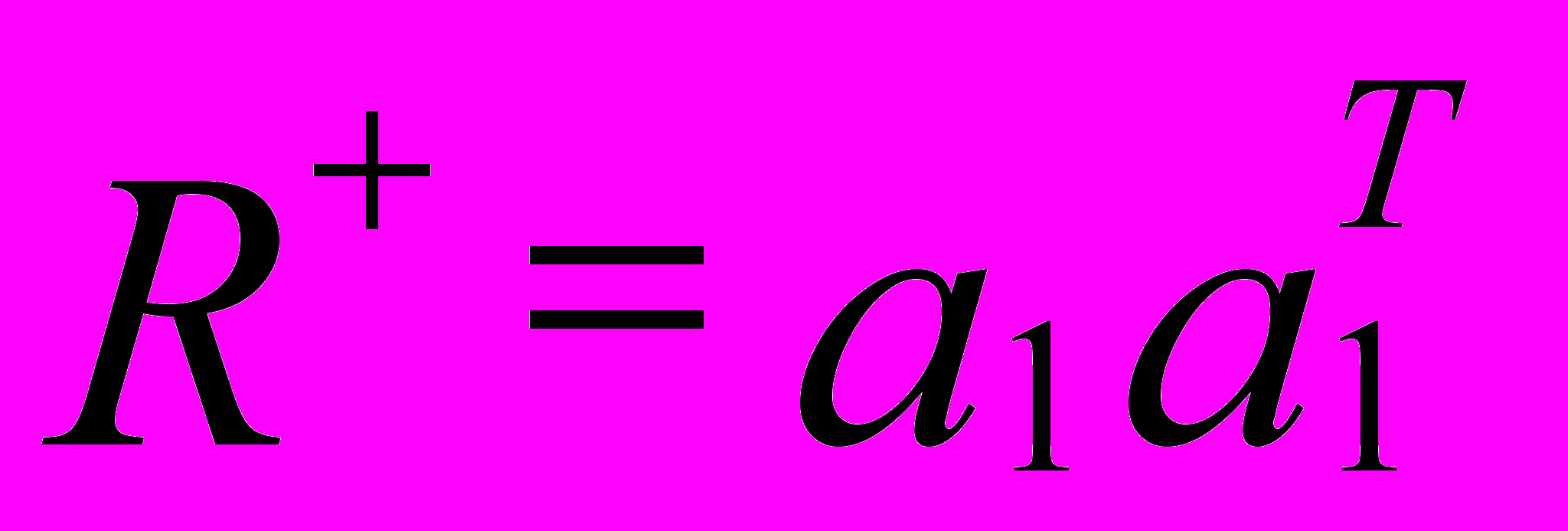 (1)
(1)или
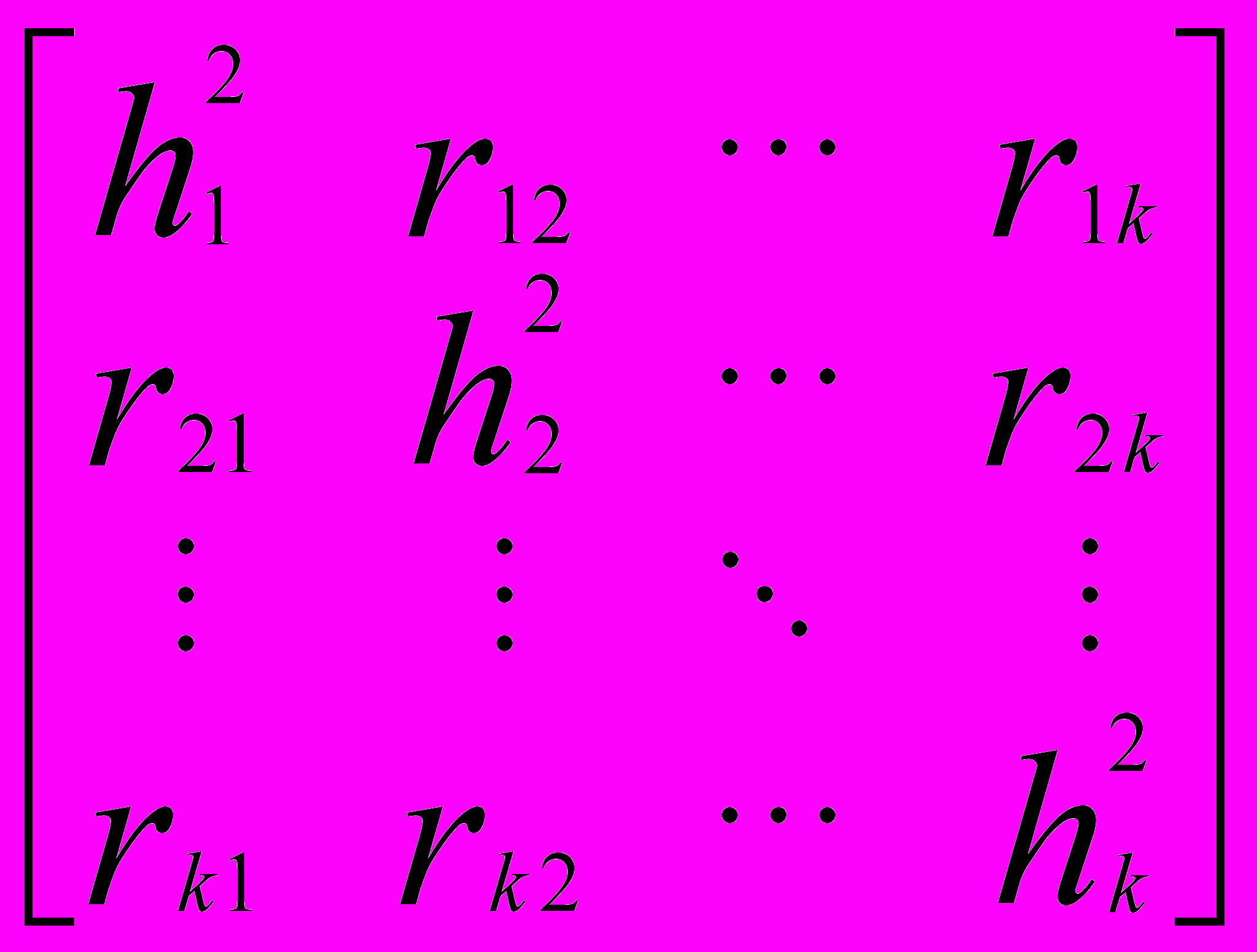 =
= 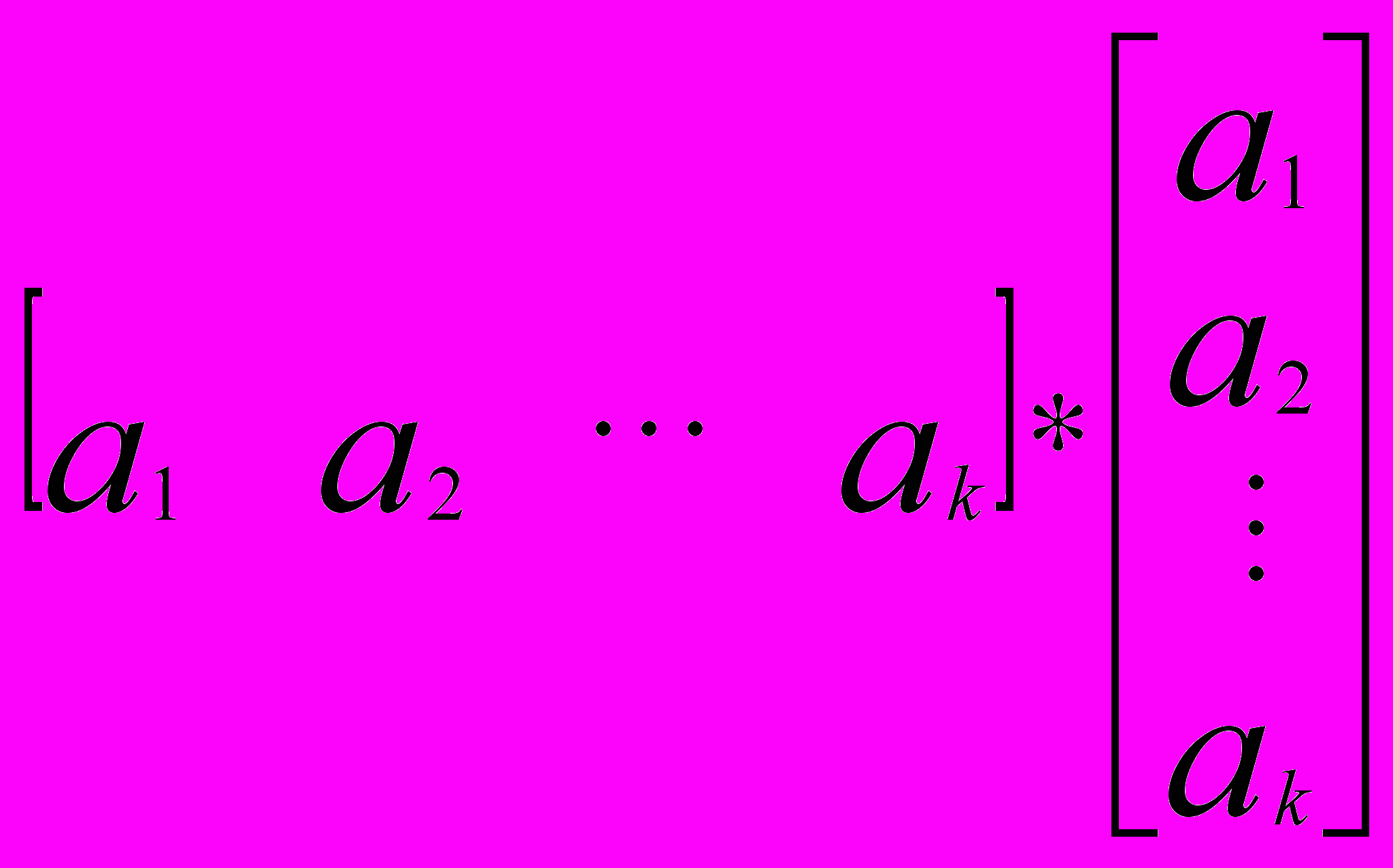 (2)
(2)Вектор
 представляет собой факторную нагрузку ненаблюдаемого фактора. В результате умножения
представляет собой факторную нагрузку ненаблюдаемого фактора. В результате умножения 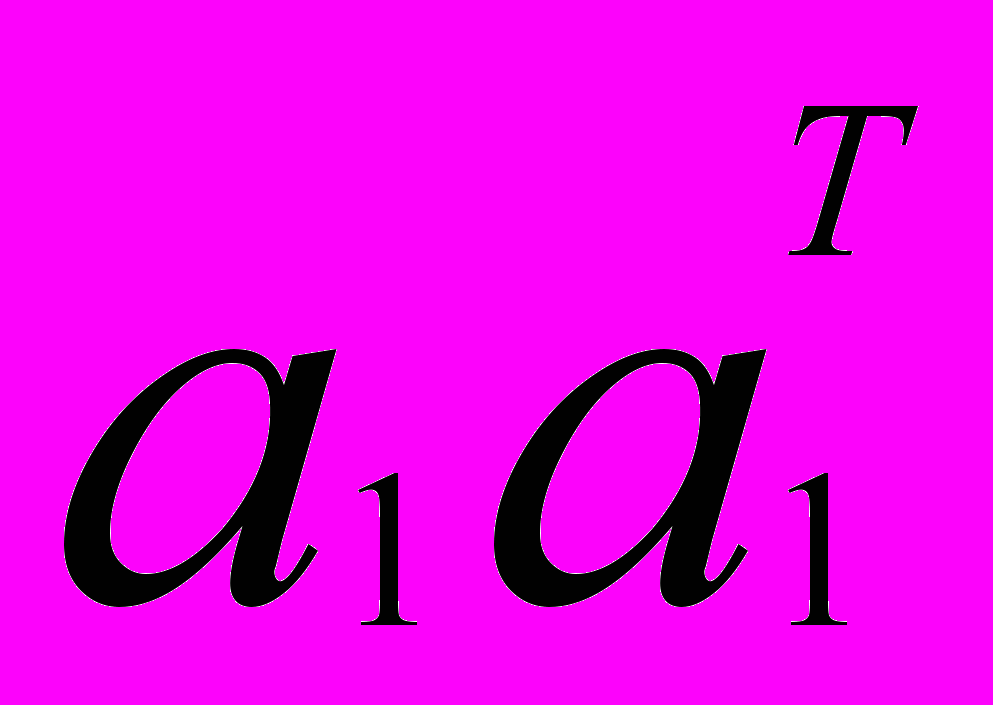 получим матрицу , принципиально отличающуюся от
получим матрицу , принципиально отличающуюся от  диагональными элементами. Диагональные элементы матрицы называются общностями. Общность i-того элемента будем обозначать через
диагональными элементами. Диагональные элементы матрицы называются общностями. Общность i-того элемента будем обозначать через 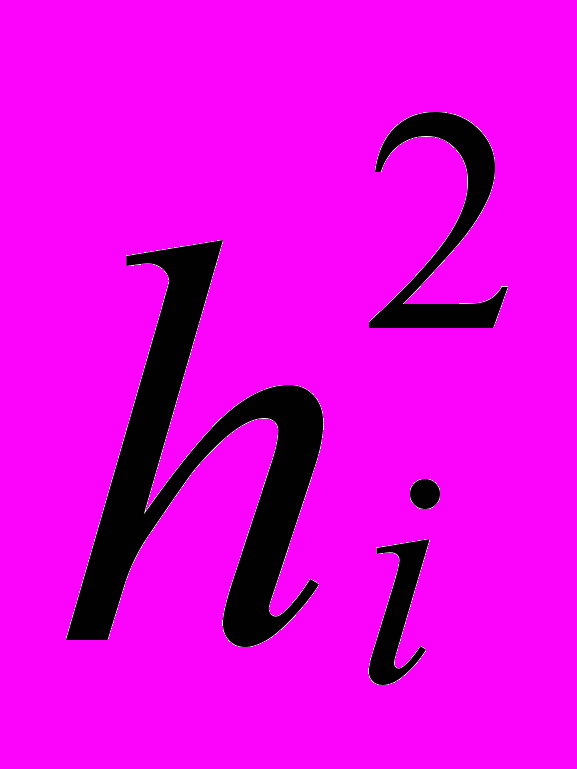 . Величина
. Величина 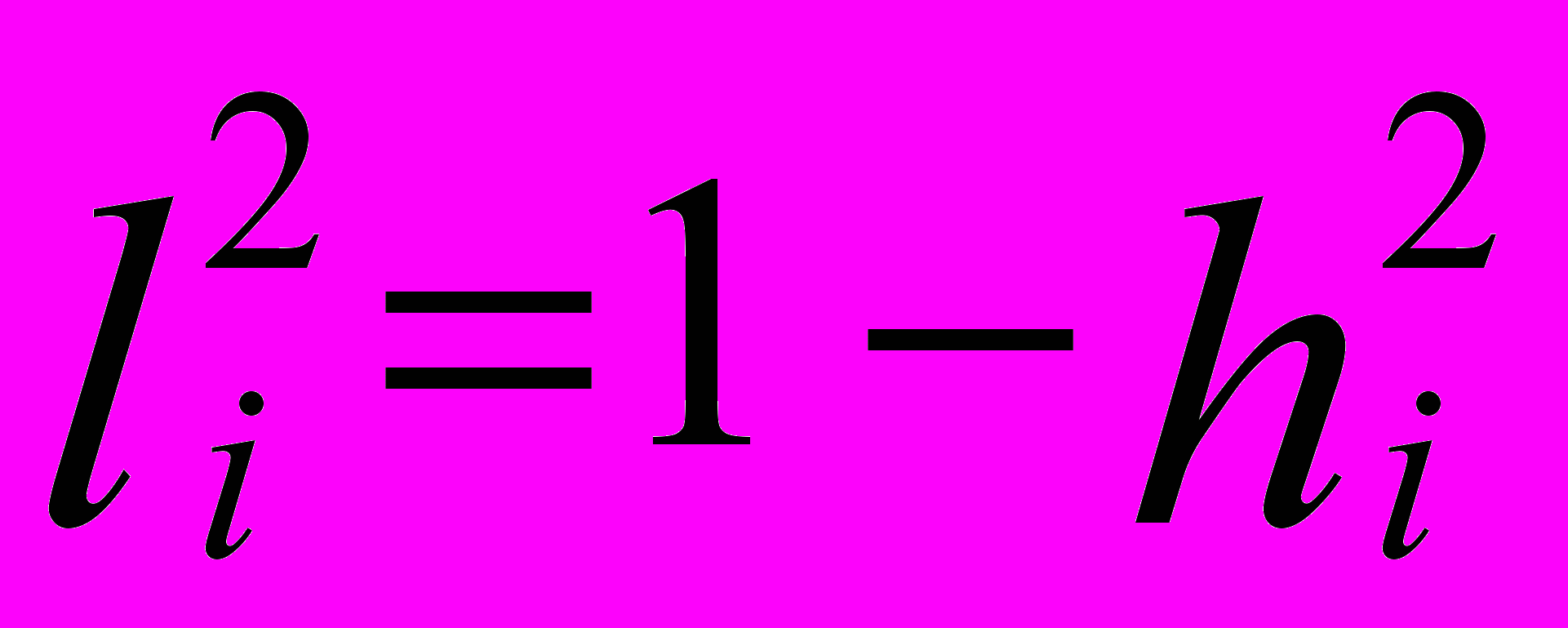 называется характерностью. Диагональные элементы исходной и редуцированной корреляционных матриц связаны соотношением
называется характерностью. Диагональные элементы исходной и редуцированной корреляционных матриц связаны соотношением 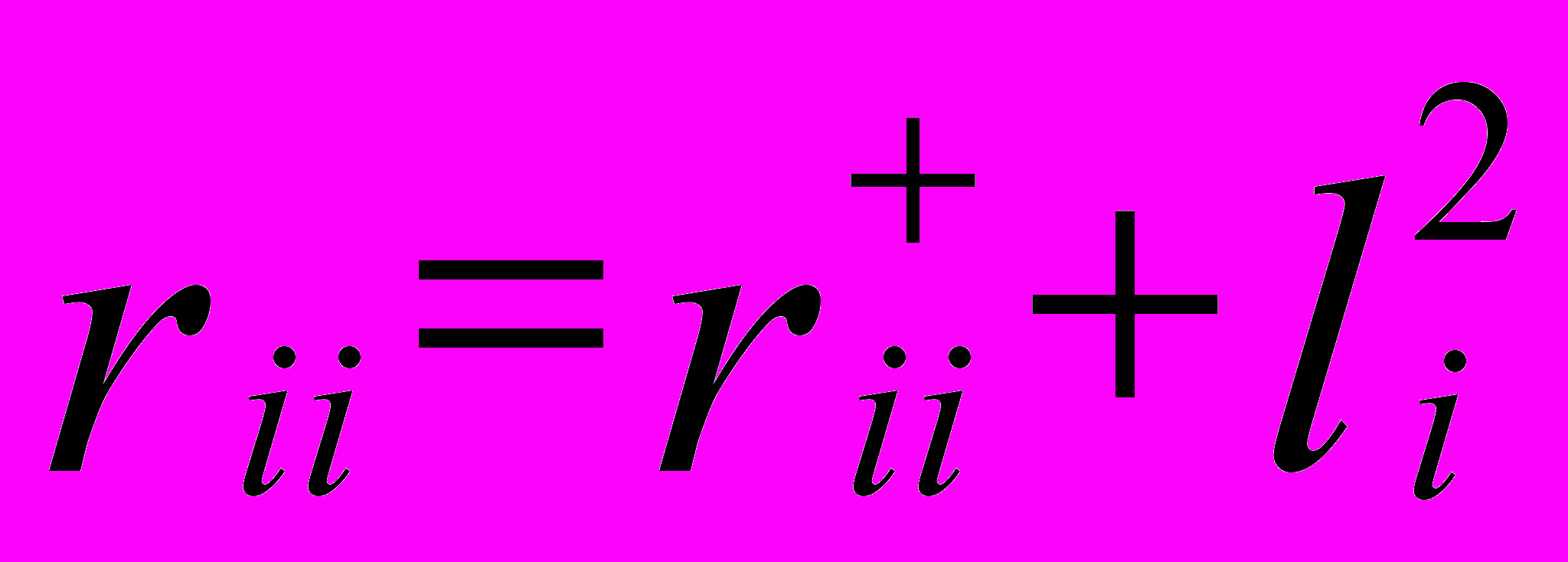 (3)
(3)Таким образом, значения компонент вектора
, называемых факторными нагрузками, воспроизводят все коэффициенты корреляции для всех переменных. Фактор f непосредственно для измерения недоступен - он гипотетичен. Факторный анализ призван для установления таких гипотетичных факторов. Из приведенного алгоритма ясно, что, прежде чем определить фактор, нужно построить редуцированную корреляционную матрицу
по значениям общностей. Оценка общностей составляют первую проблему факторного анализа, проблему общности. Второй проблемой является определение фактора. Это так называемая проблема факторов. Методика факторного анализа в случае нескольких объясняющих факторов
В общем случае для объяснения корреляционной матрицы потребуется не один, а несколько факторов. Каждый фактор характеризуется столбцом, каждая переменная - строкой матрицы
. Фактор называется генеральным, если все его нагрузки значительно отличаются от нуля и он имеет нагрузки от всех переменных. Генеральный фактор имеет нагрузки от всех переменных и схематически такой фактор изображен на рис.1. столбцом 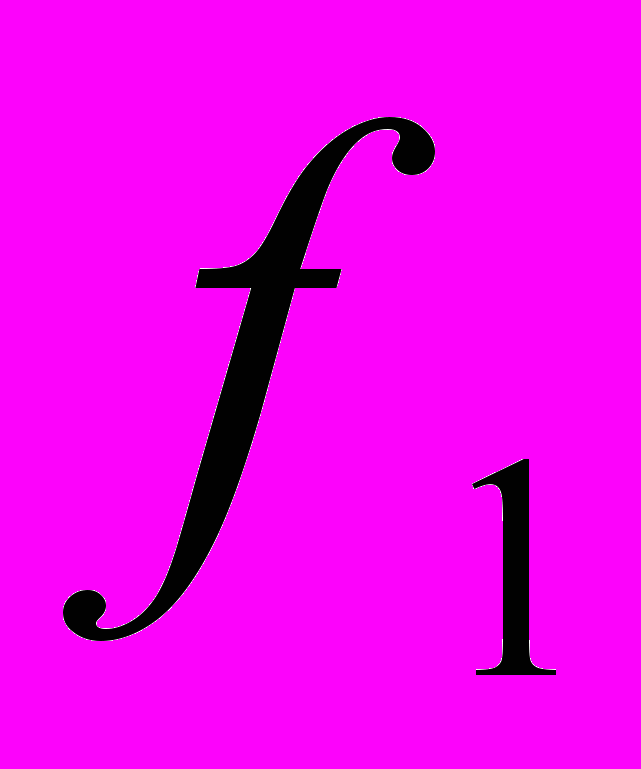 .Фактор называется общим, если хотя бы две его нагрузки значительно отличаются от нуля. Столбцы
.Фактор называется общим, если хотя бы две его нагрузки значительно отличаются от нуля. Столбцы 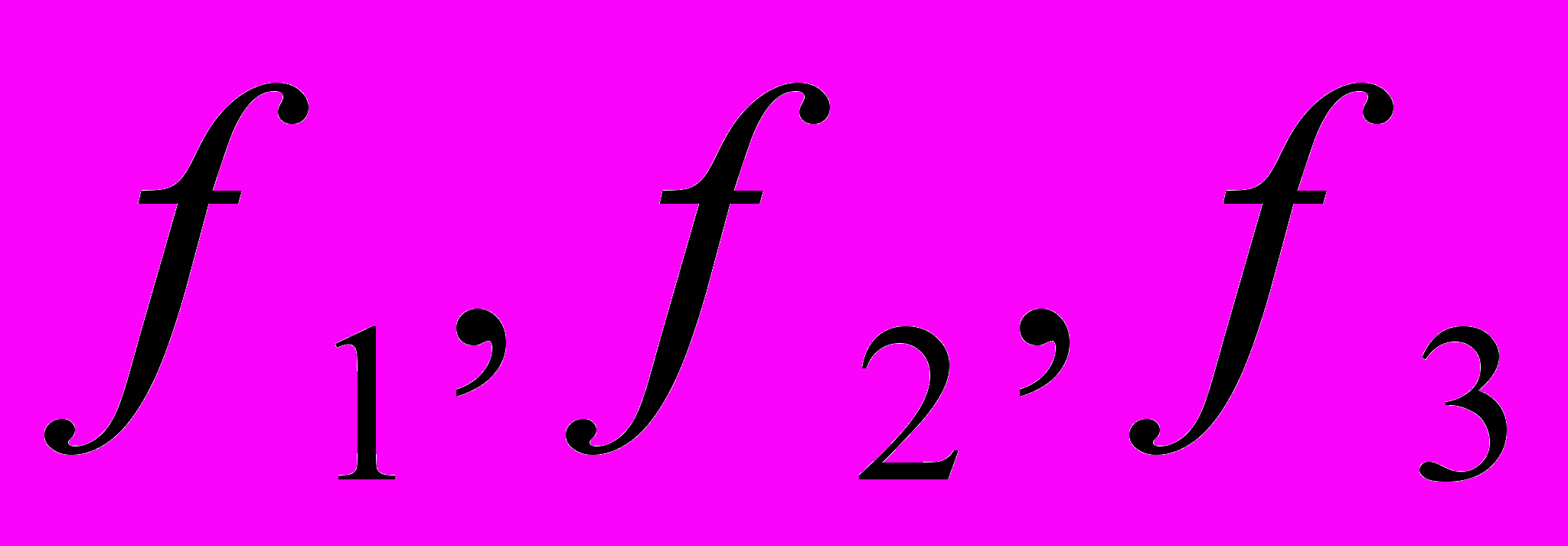 , на рис. 1. представляют такие общие факторы. Они имеют нагрузки от более чем двух переменных. Если у фактора только одна нагрузка, значительно отличающаяся от нуля, то он называется характерным фактором (см. столбцы
, на рис. 1. представляют такие общие факторы. Они имеют нагрузки от более чем двух переменных. Если у фактора только одна нагрузка, значительно отличающаяся от нуля, то он называется характерным фактором (см. столбцы 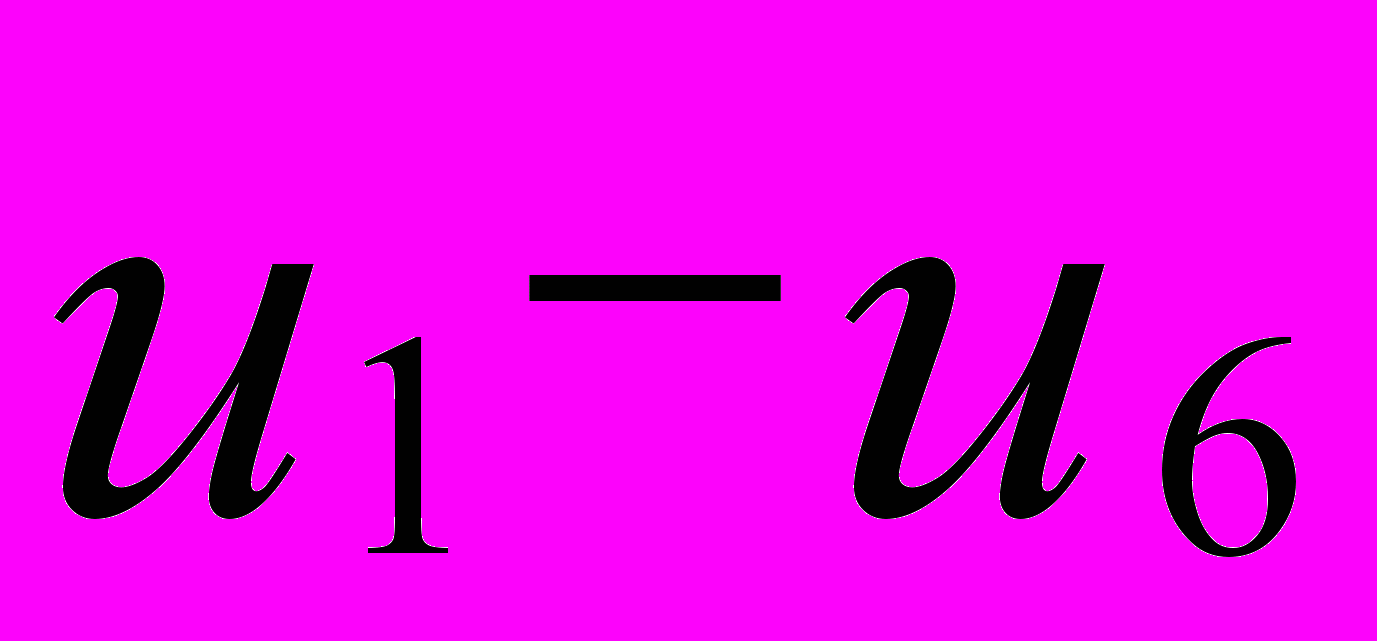 на рис. 1.) Каждый такой фактор представляет только одну переменную. Решающее значение в факторном анализе имеют общие факторы. Если общие факторы установлены, то характерные факторы получаются автоматически. Число высоких нагрузок переменной на общие факторы называется сложностью. Например, переменная
на рис. 1.) Каждый такой фактор представляет только одну переменную. Решающее значение в факторном анализе имеют общие факторы. Если общие факторы установлены, то характерные факторы получаются автоматически. Число высоких нагрузок переменной на общие факторы называется сложностью. Например, переменная 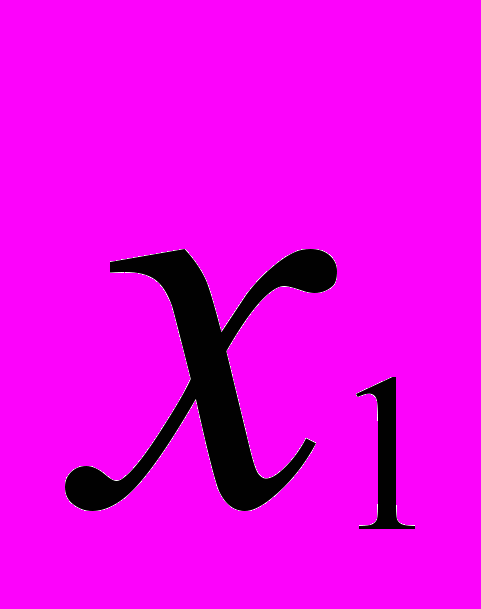 на рис.1. имеет сложность 2, а переменная
на рис.1. имеет сложность 2, а переменная 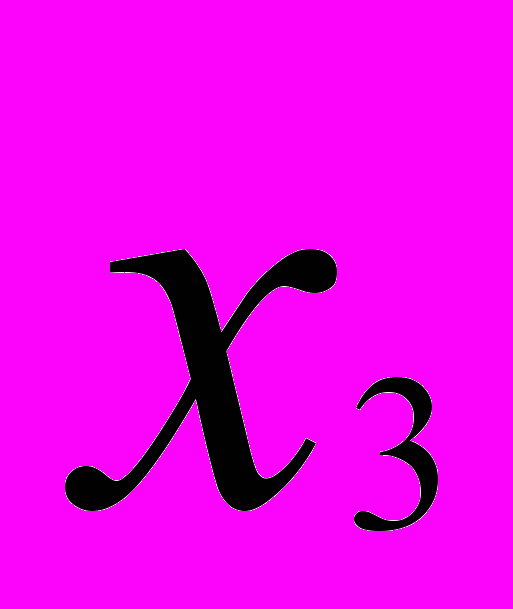 - три.
- три. 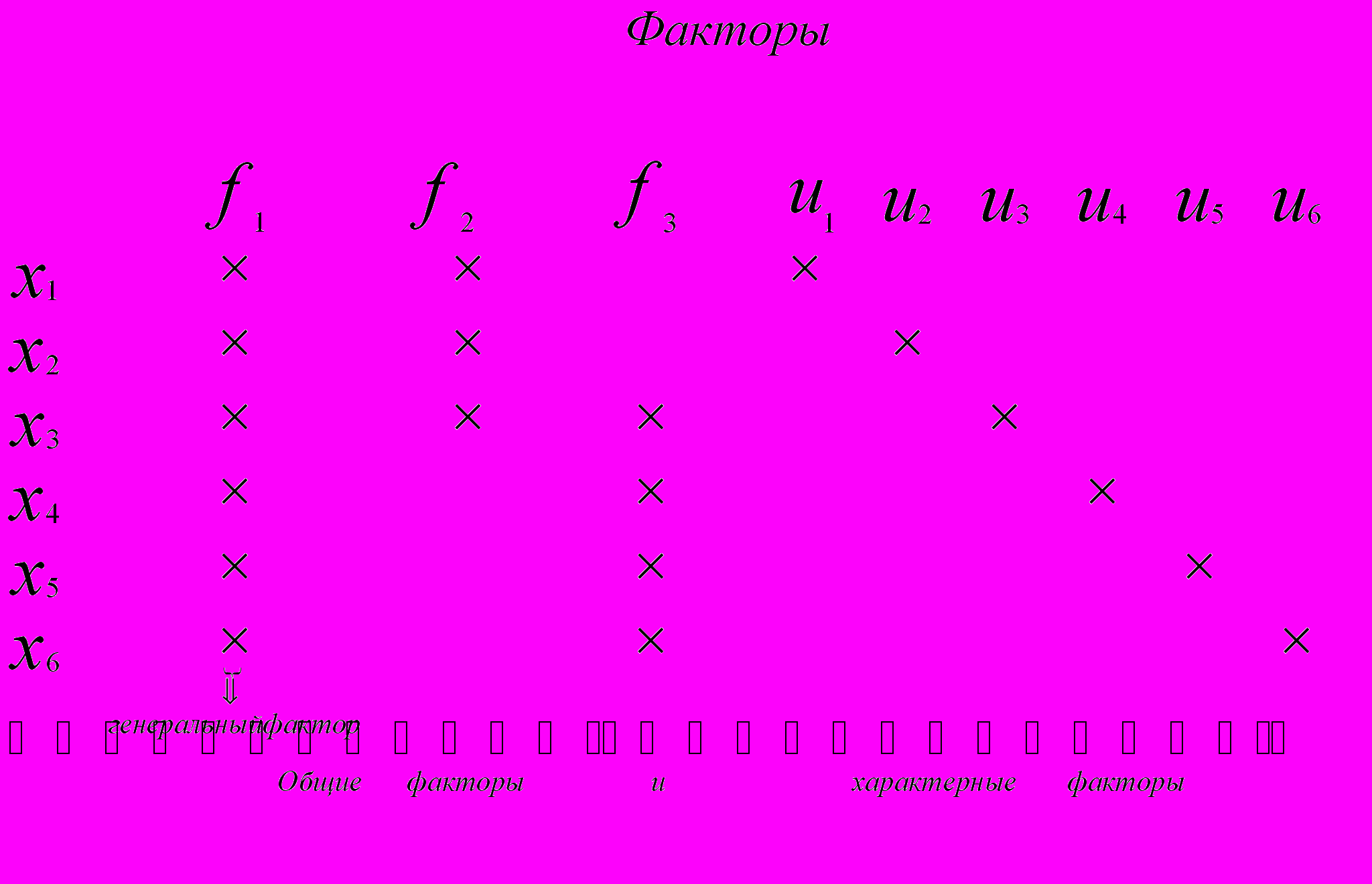
Рис. 1. Схематическое изображение факторного отображения. Крестик
 означает высокую факторную нагрузку.
означает высокую факторную нагрузку.Итак, построим модель
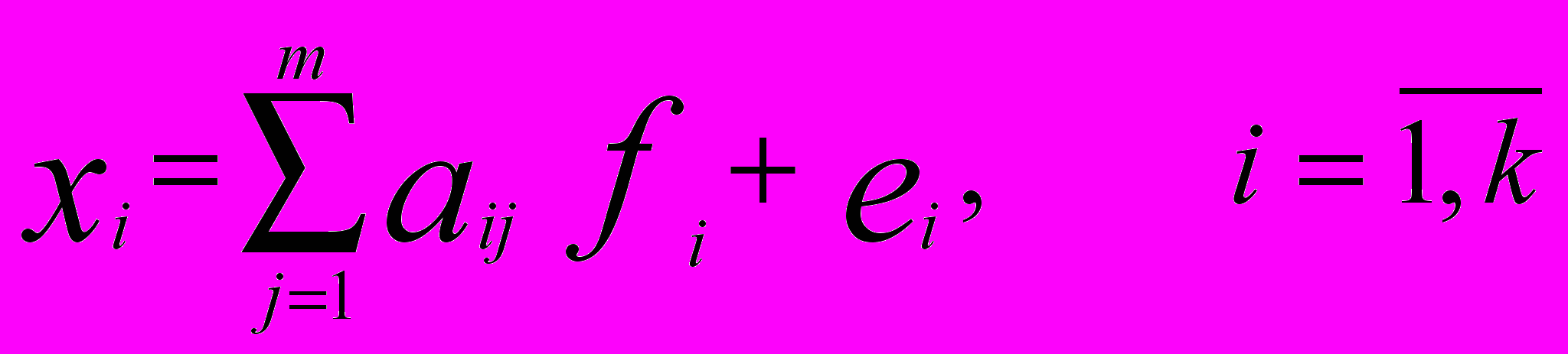 , (4)
, (4)где
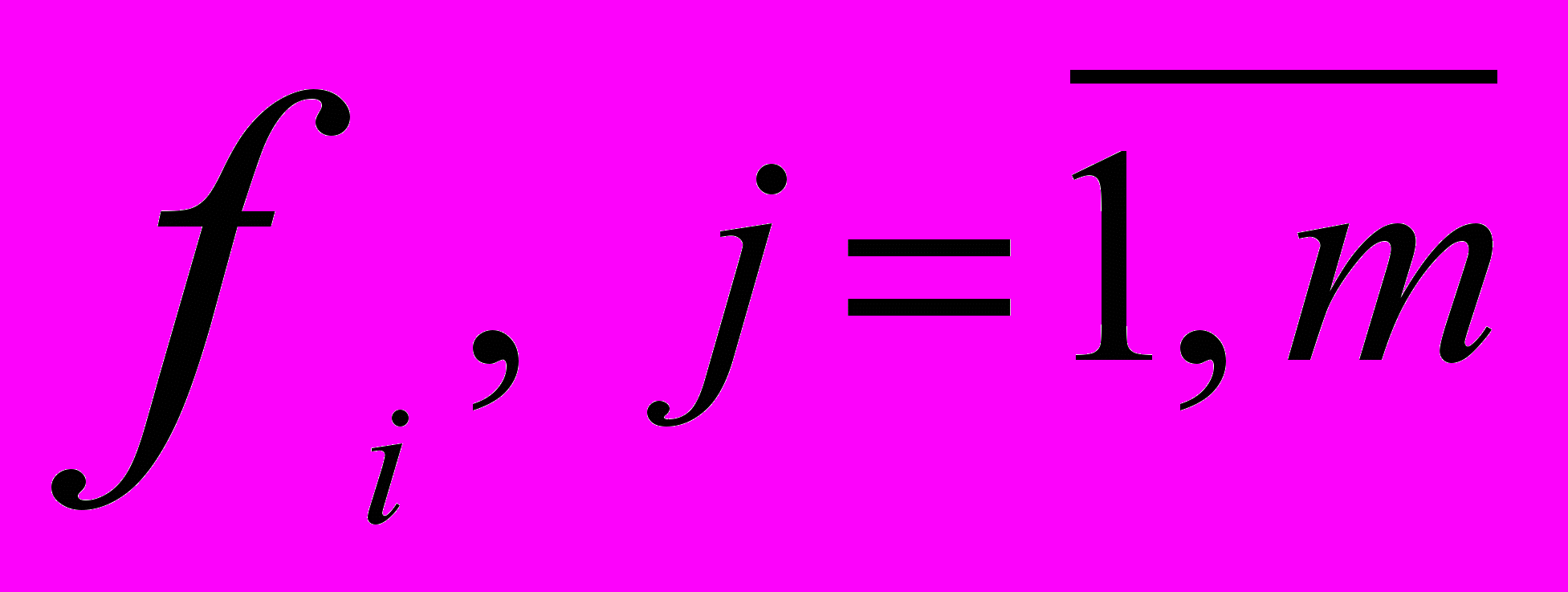 - ненаблюдаемые факторы m < k,
- ненаблюдаемые факторы m < k, 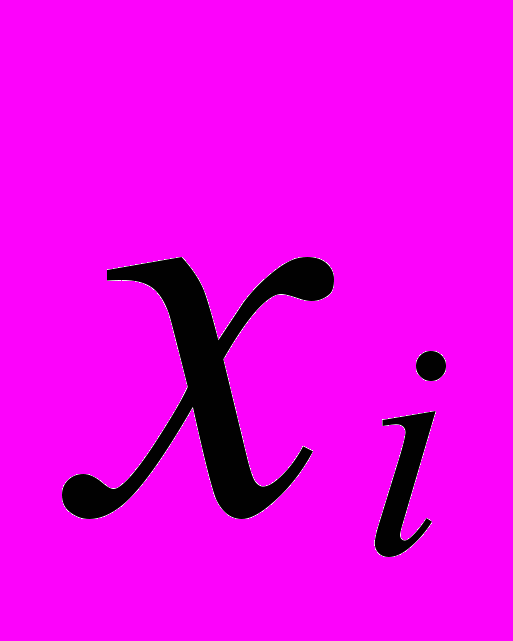 - наблюдаемые переменные (исходные признаки),
- наблюдаемые переменные (исходные признаки), 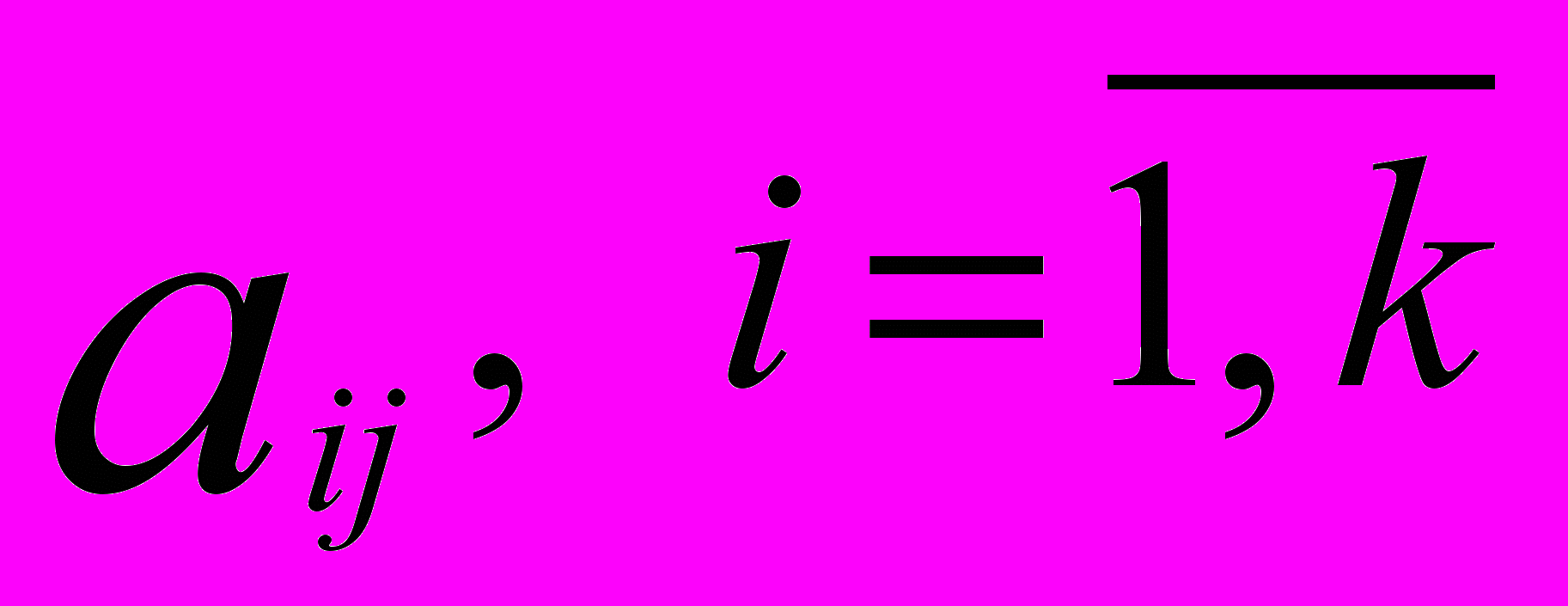 - факторные нагрузки,
- факторные нагрузки,  - случайная ошибка связанная только с с нулевым средним и дисперсией
- случайная ошибка связанная только с с нулевым средним и дисперсией  :
: 

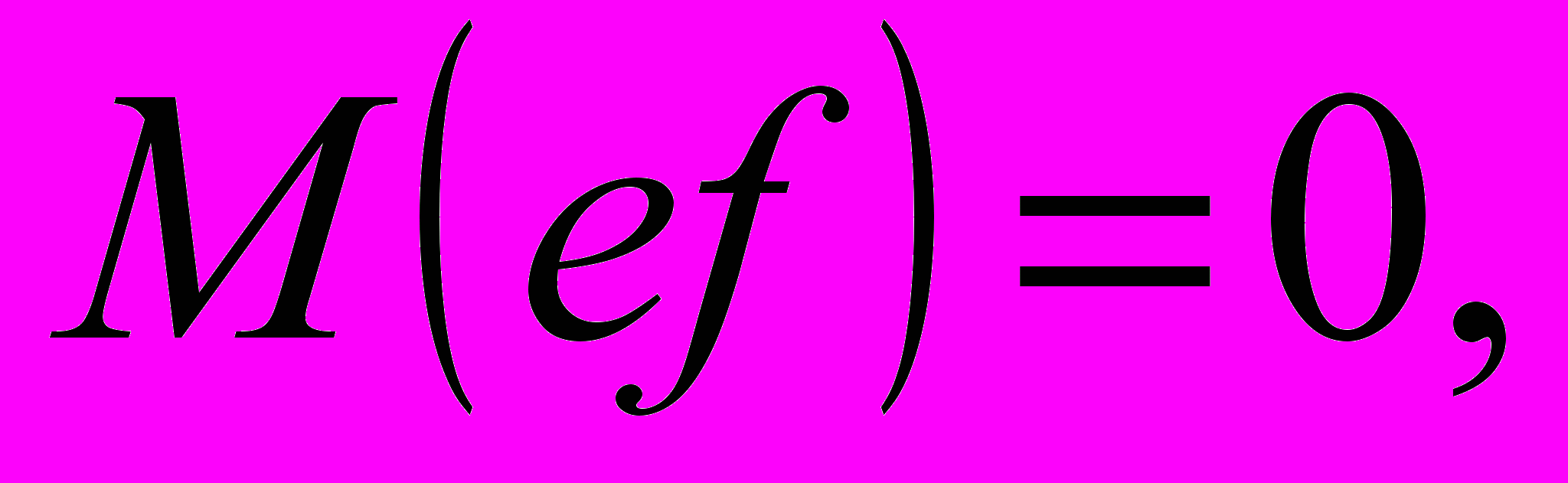
 и - некорpелированы, - некоррелированные случайные величины с нулевым средним и единичной дисперсией
и - некорpелированы, - некоррелированные случайные величины с нулевым средним и единичной дисперсией 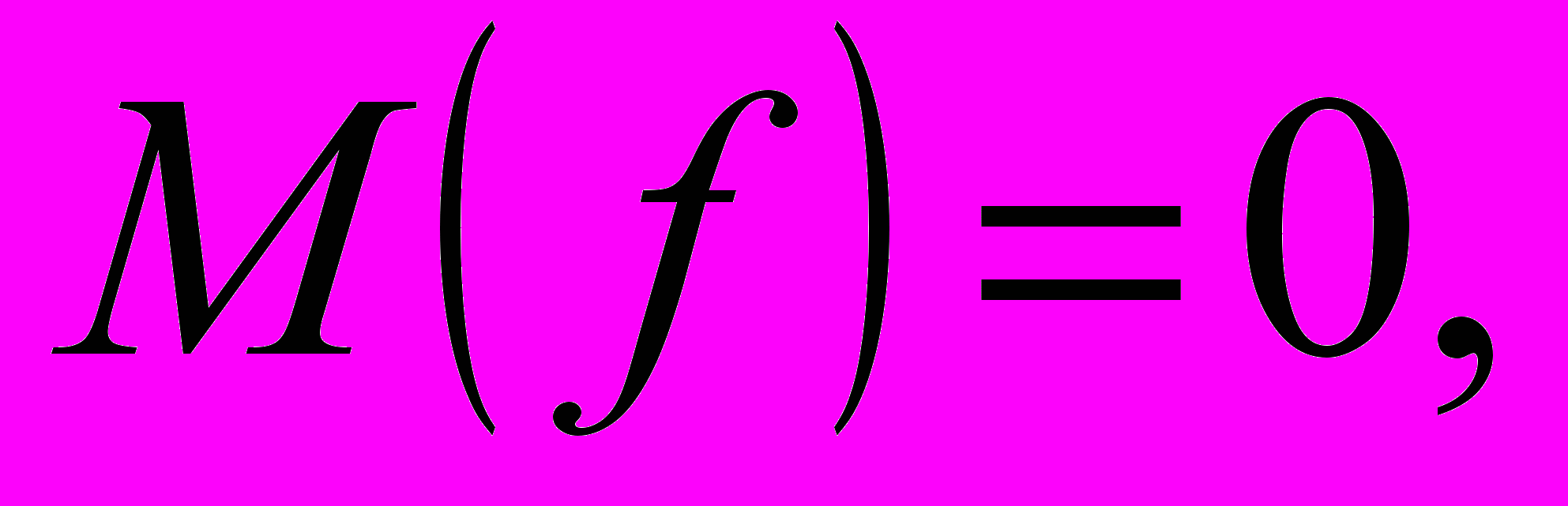
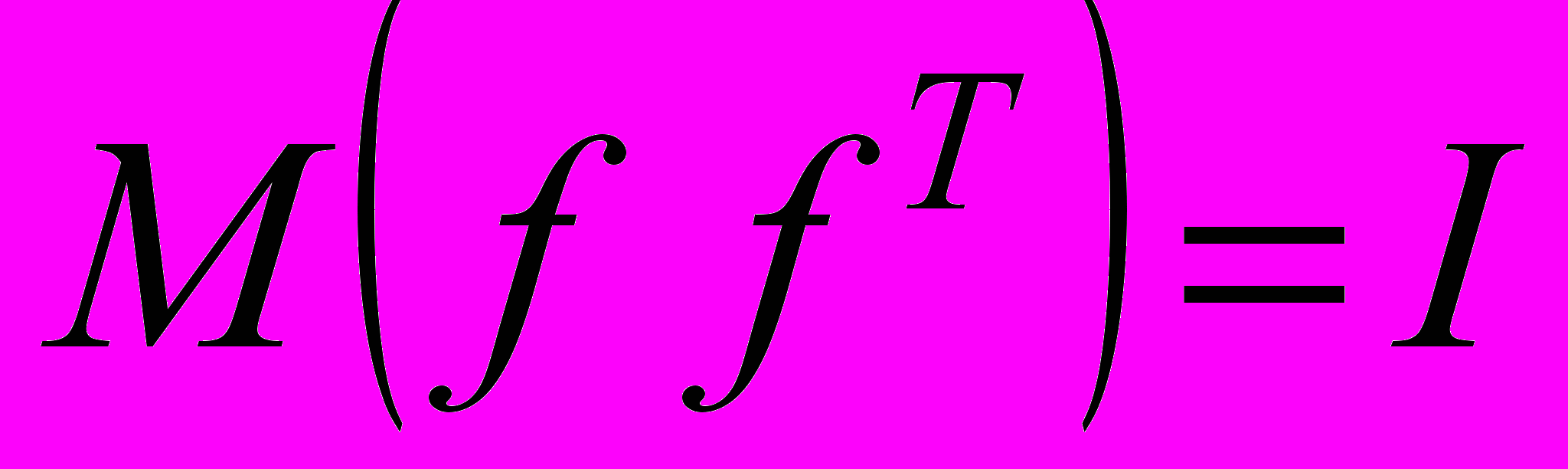 .
. Тогда
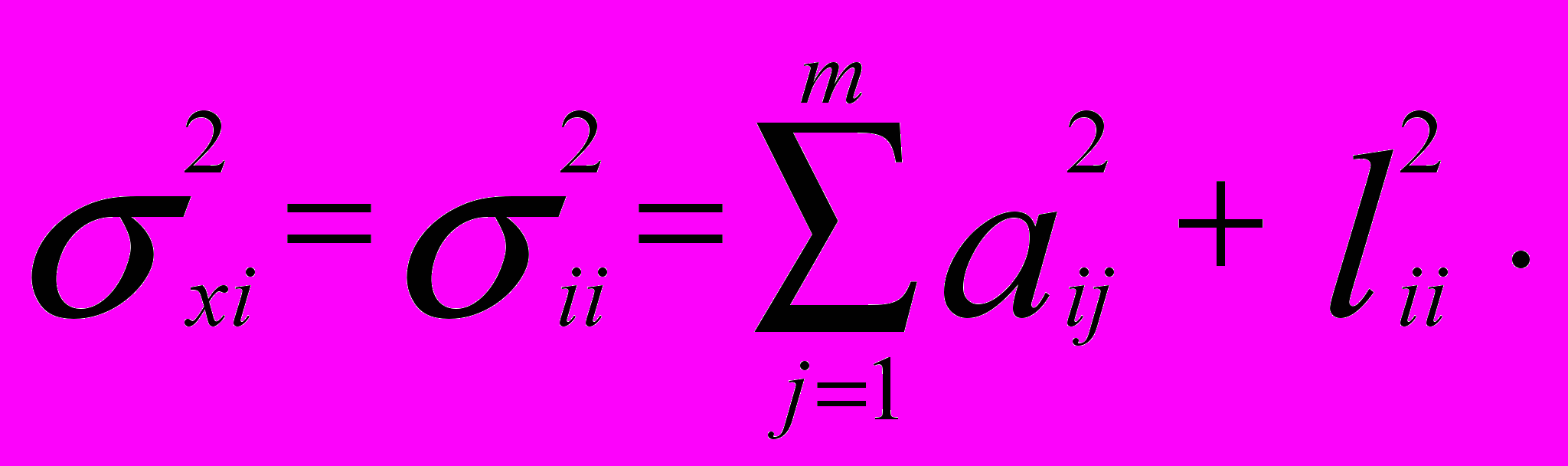 ( 5)
( 5)Здесь
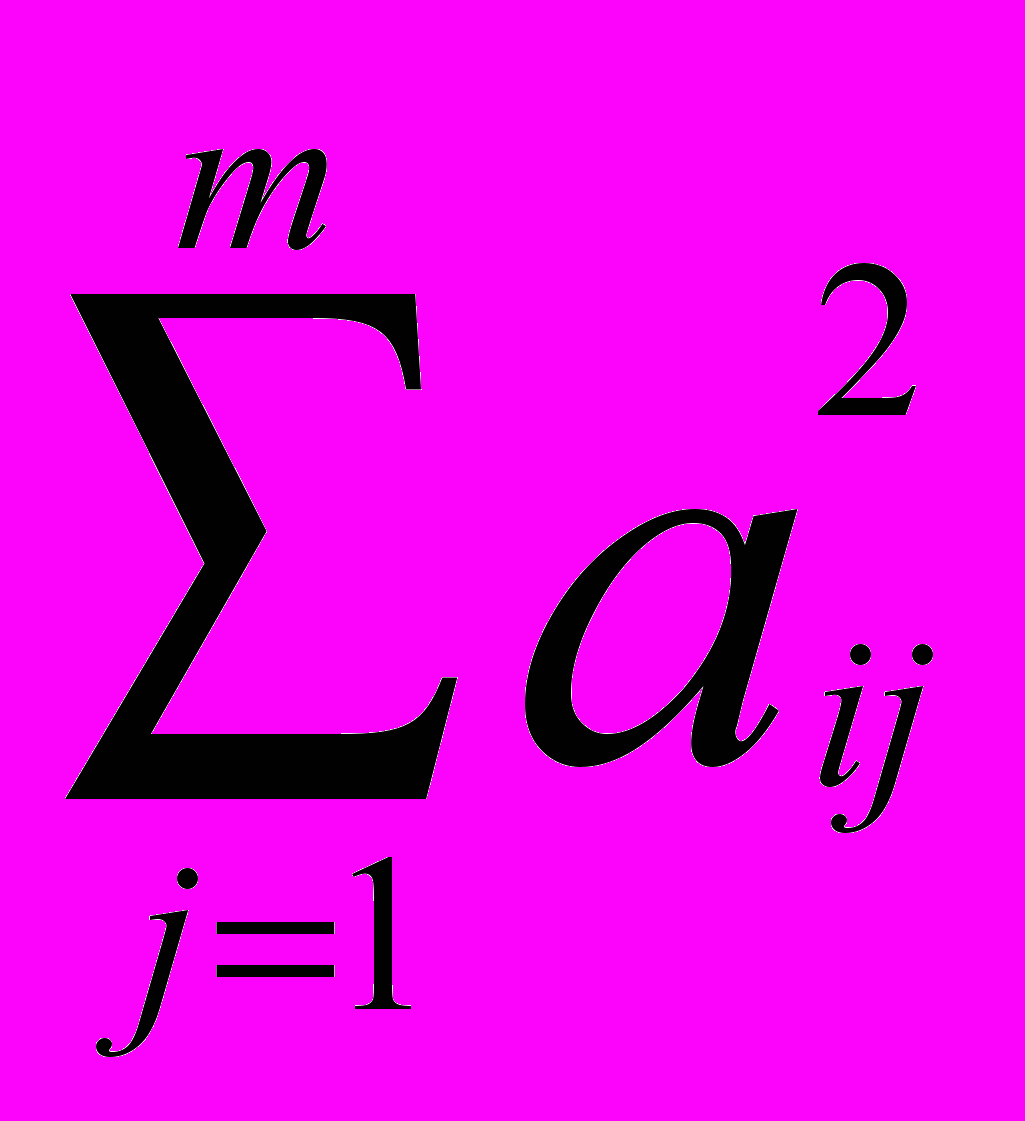 - i-ая общность представляющая собой часть дисперсии , обусловленная факторами, - часть дисперсии , обусловленная ошибкой. В матричной записи факторная модель примет вид:
- i-ая общность представляющая собой часть дисперсии , обусловленная факторами, - часть дисперсии , обусловленная ошибкой. В матричной записи факторная модель примет вид: 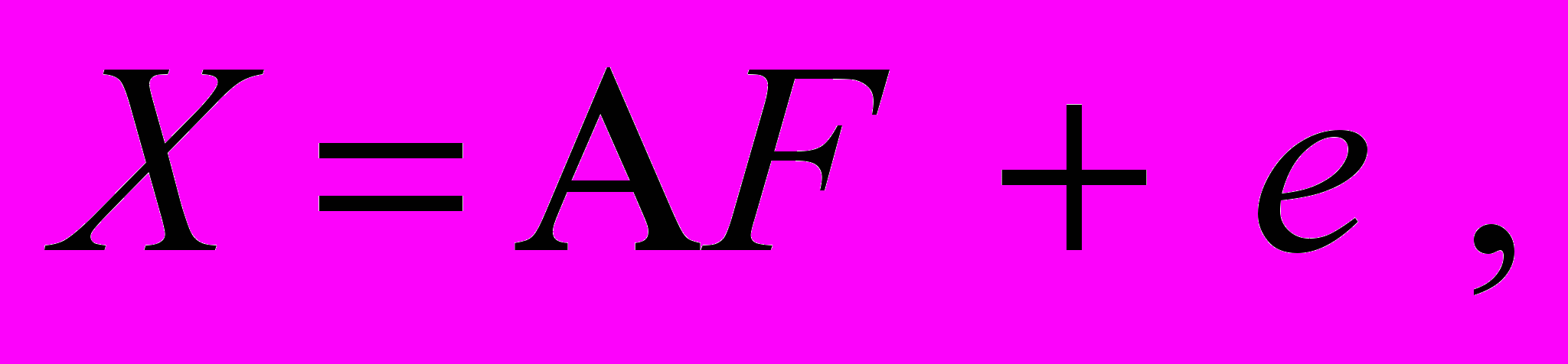 (6)
(6)где
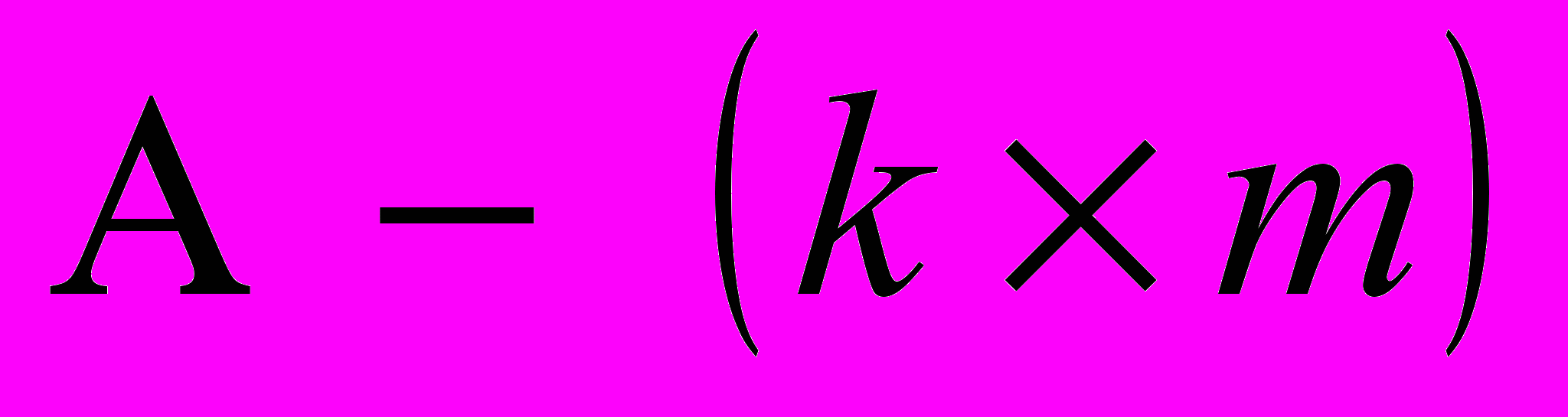 - матрица нагрузок,
- матрица нагрузок, 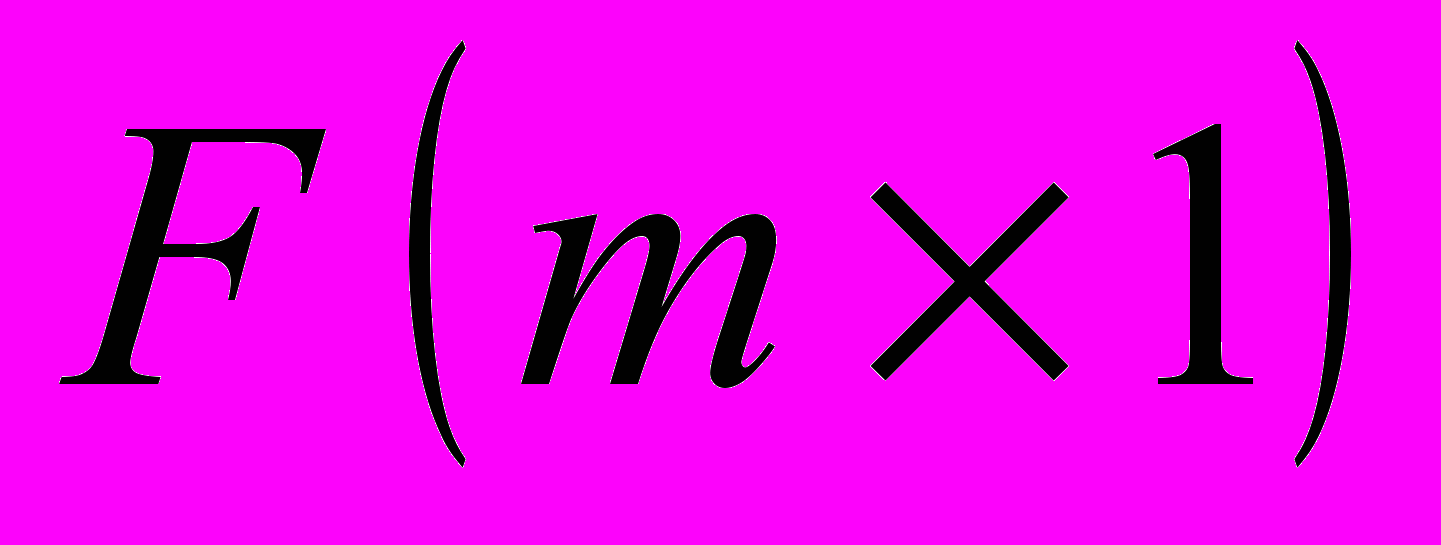 - вектор факторов,
- вектор факторов,  - вектор ошибок.
- вектор ошибок. Корреляции между переменными, выраженные факторами, можно вывести следующим образом:
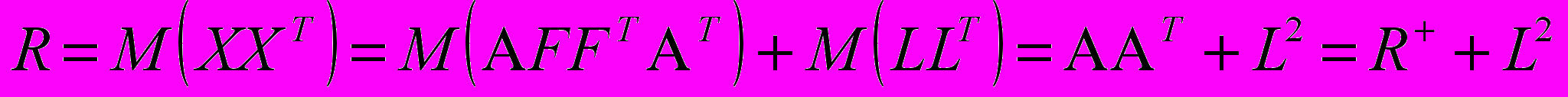 , (7)
, (7)где
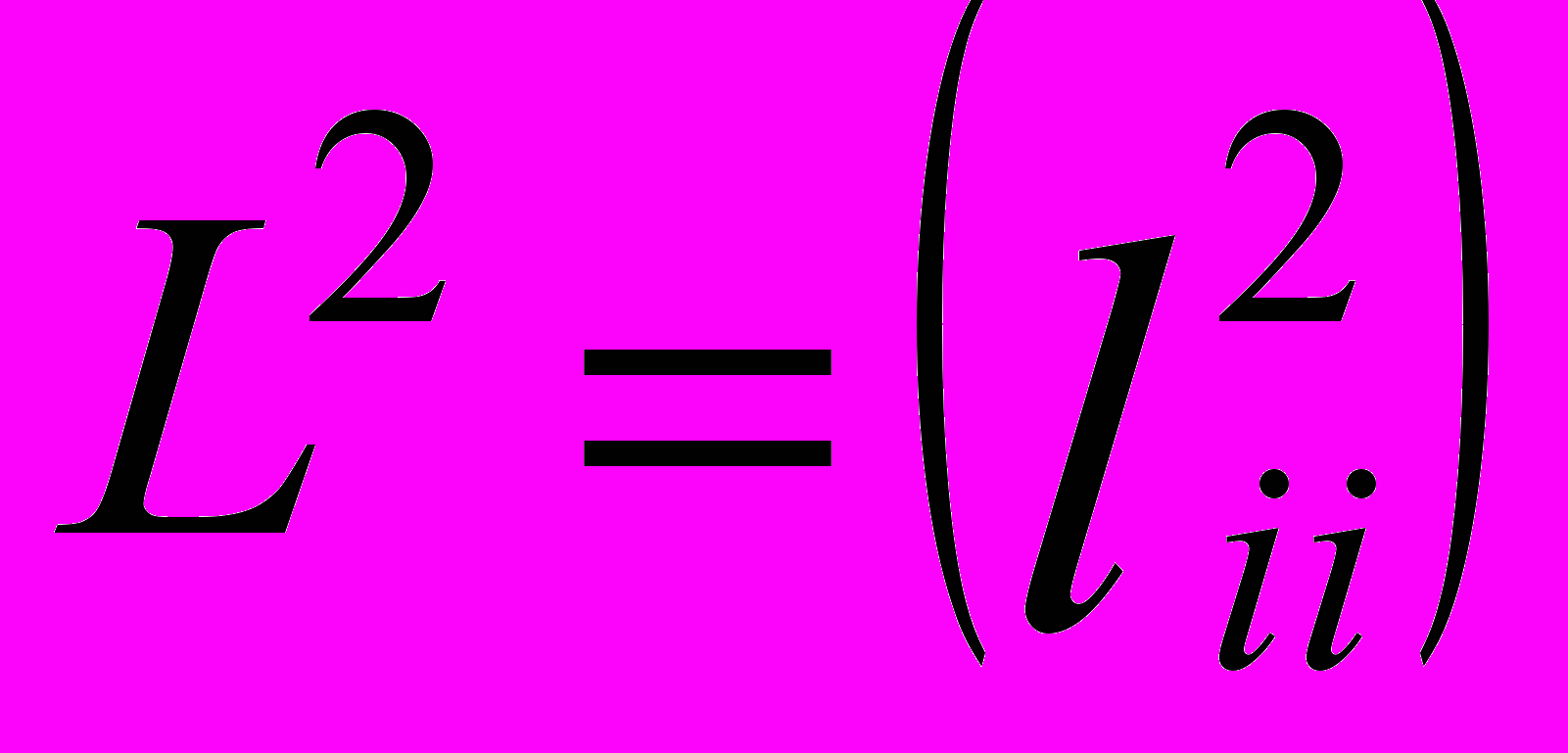 - диагональная матрица порядка
- диагональная матрица порядка 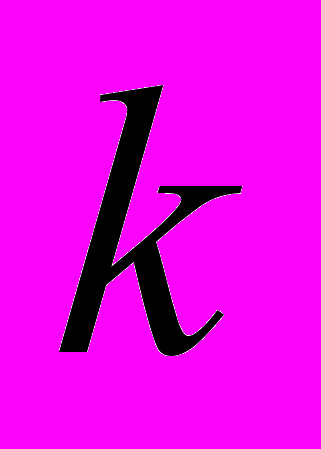 , содержащая дисперсии ошибокi. Основное условие:
, содержащая дисперсии ошибокi. Основное условие: 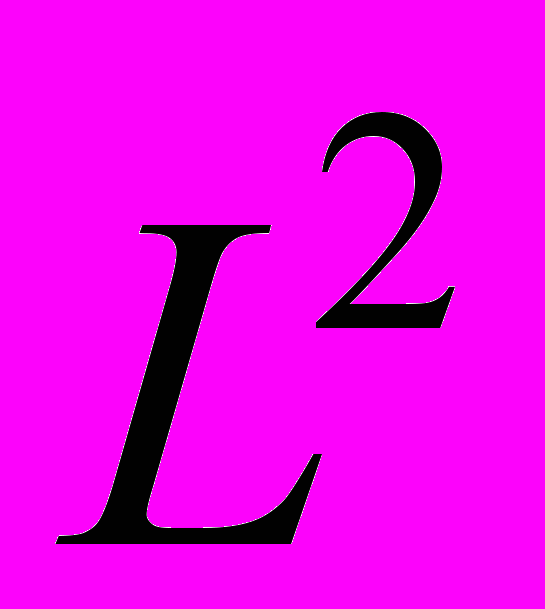 - диагональная,
- диагональная, 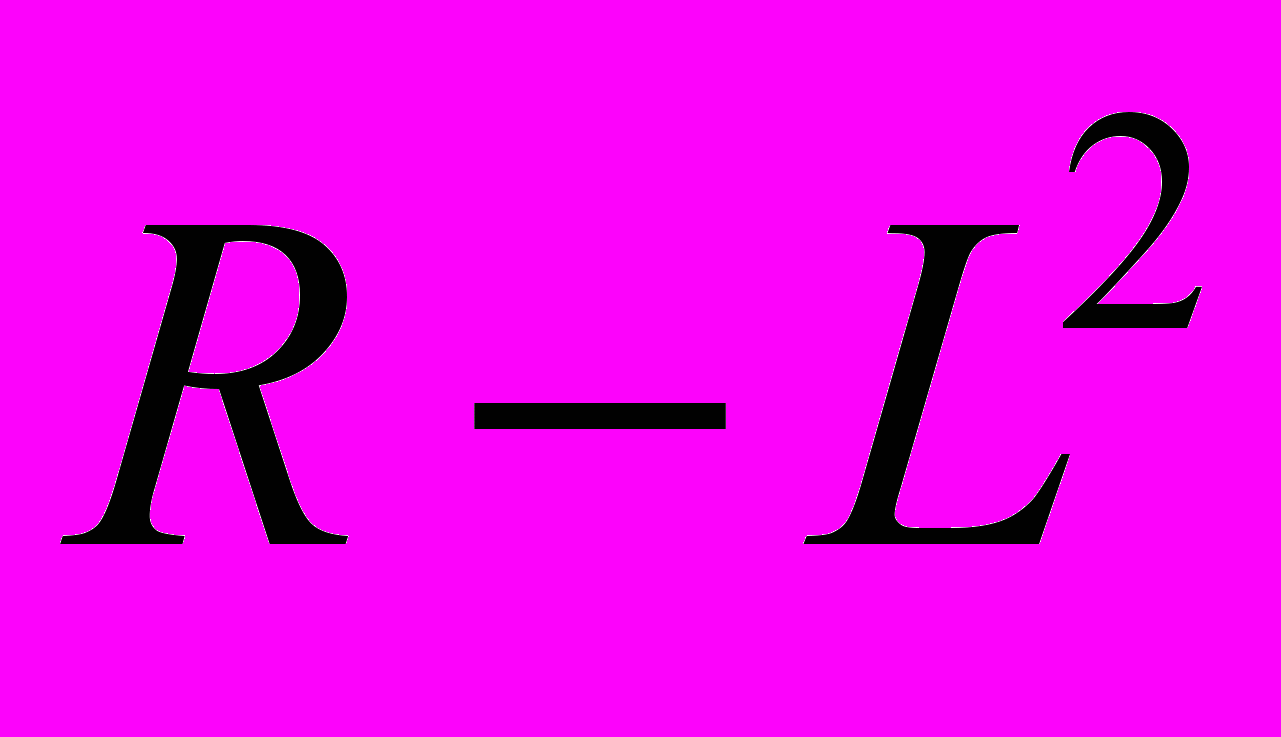 - неотрицательно определенная матрица. Дополнительным условием единственности решения является диагональность матрицы
- неотрицательно определенная матрица. Дополнительным условием единственности решения является диагональность матрицы 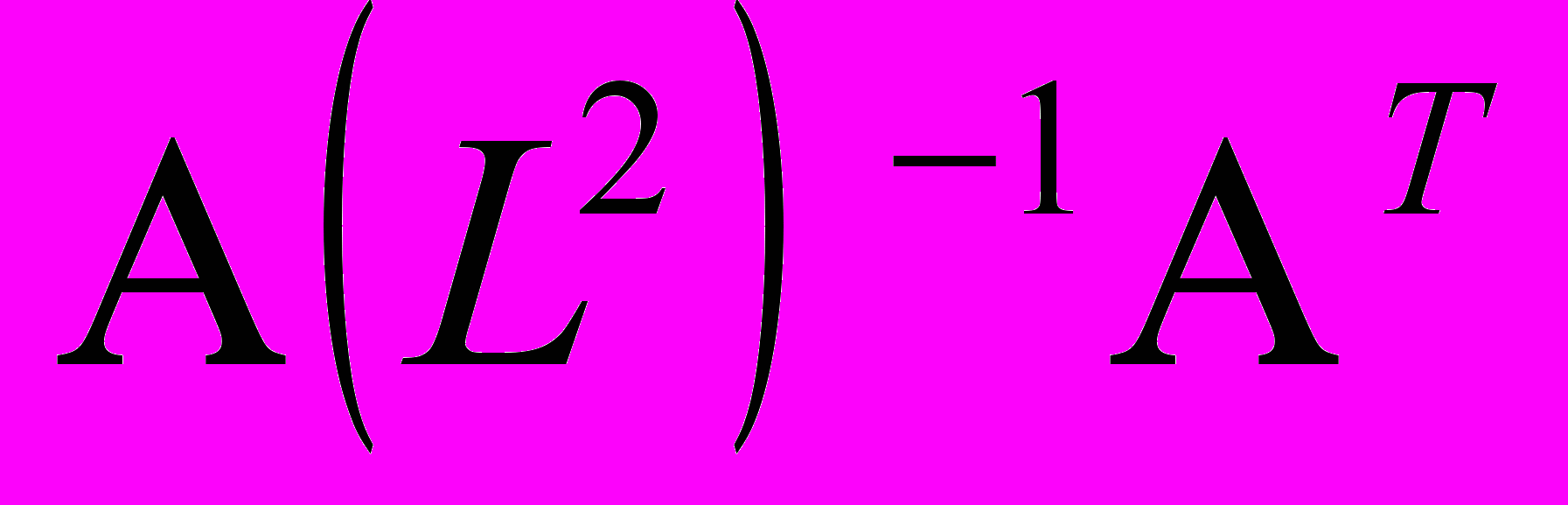 .
. Имеется множество методов решения факторного уравнения. Наиболее ранним методом факторного анализа является метод главных факторов, в котором методика анализа главных компонент используется применительно к редуцированной корреляционной матрице
с общностями на главной диагонали. Для оценки общностей обычно пользуются коэффициентом множественной корреляции между соответствующей переменной и совокупностью остальных переменных. Факторный анализ проводится исходя из характеристического уравнения, как и в анализе главных компонент:
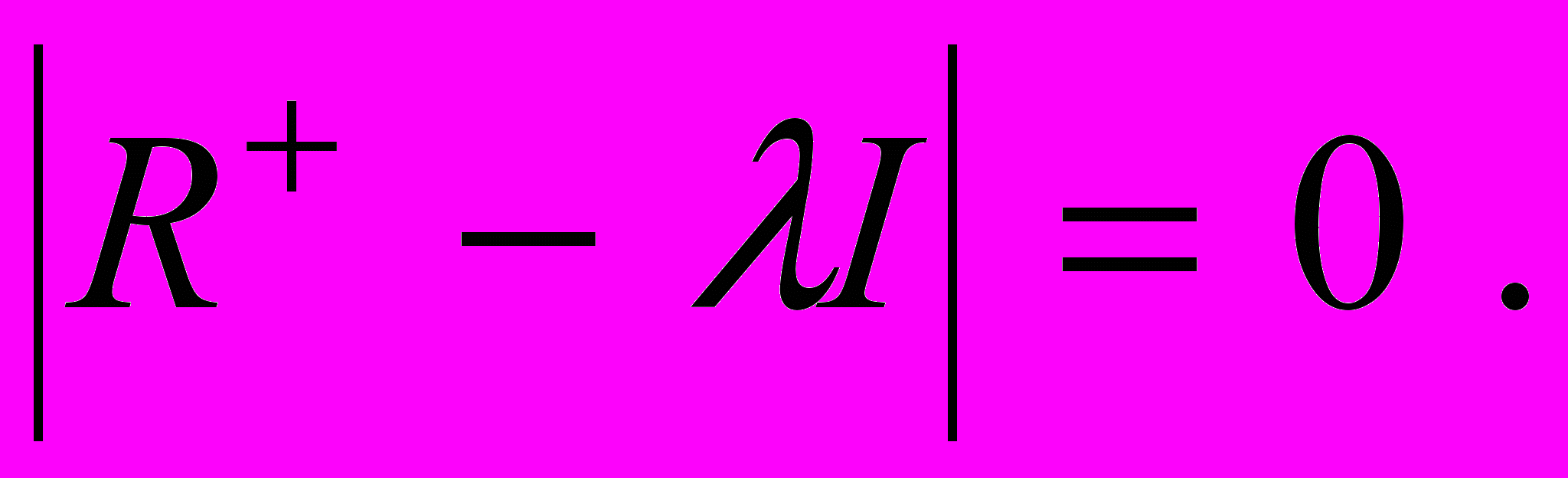 (8)
(8)Решая которое, получают собственные числа λi и матрицу нормированных (характеристических) векторов V, и затем находят матрицу факторного отображения:
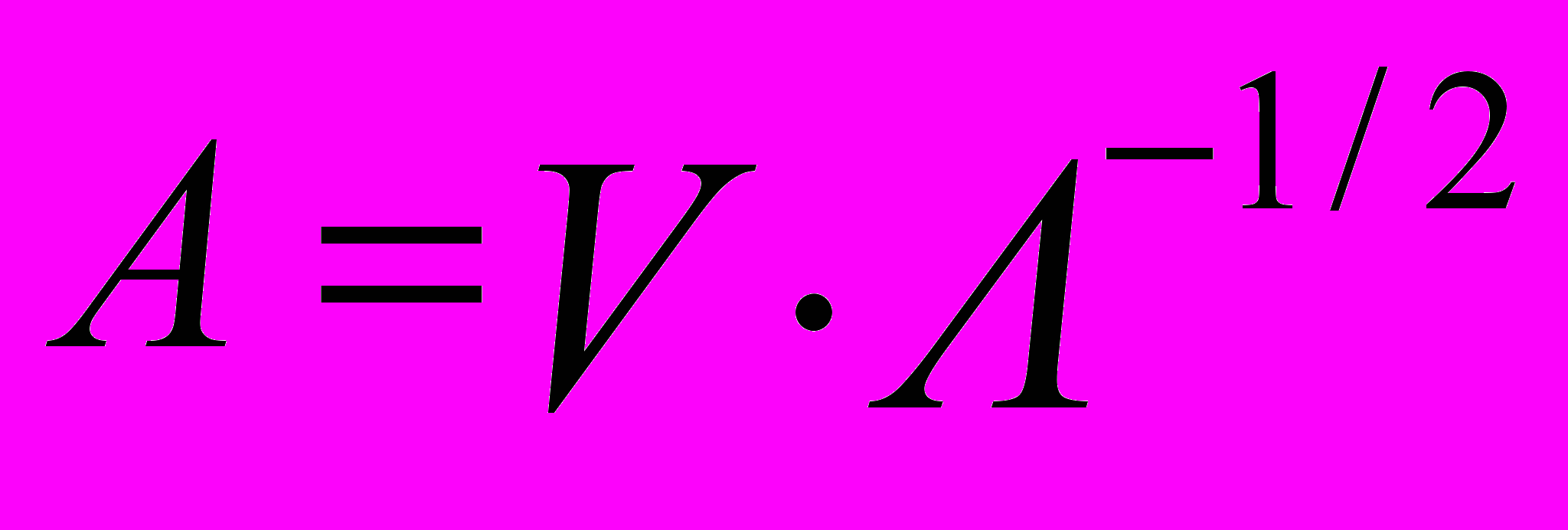
Для получения оценок общностей и факторных нагрузок используется эмпирический итеративный алгоритм, который сходится к истинным оценкам параметров. Сущность алгоритма сводится к следующему: первоначальные оценки факторных нагрузок определяются с помощью метода главных факторов. На основании корреляционной матрицы R формально определяются оценки главных компонент и общих факторов:
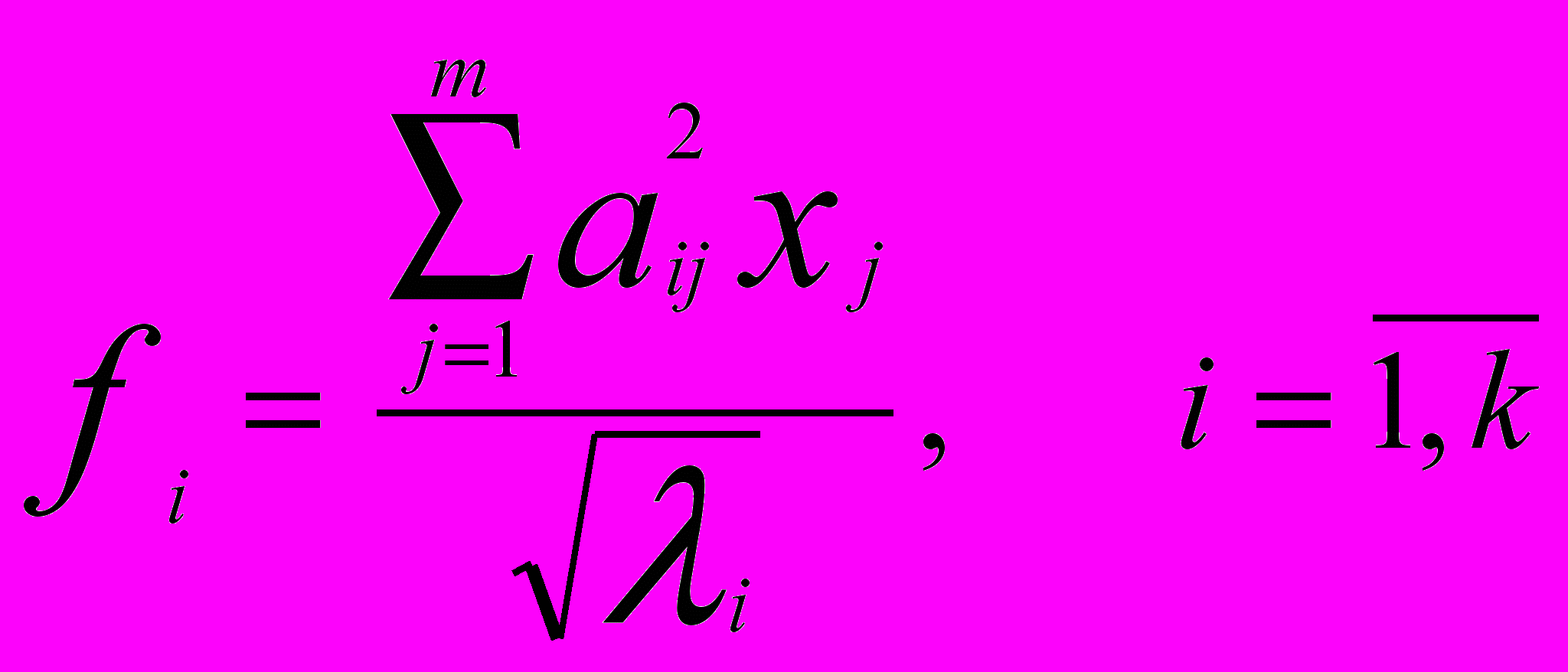 (9)
(9)где
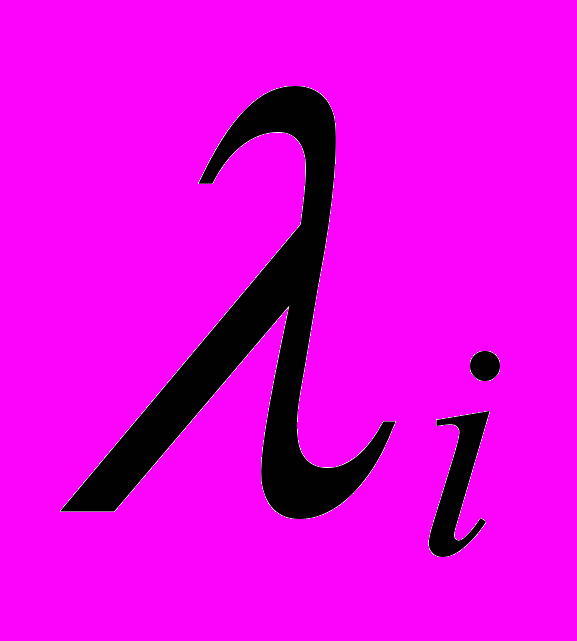 - соответствующее собственное значение матрицы R;
- соответствующее собственное значение матрицы R;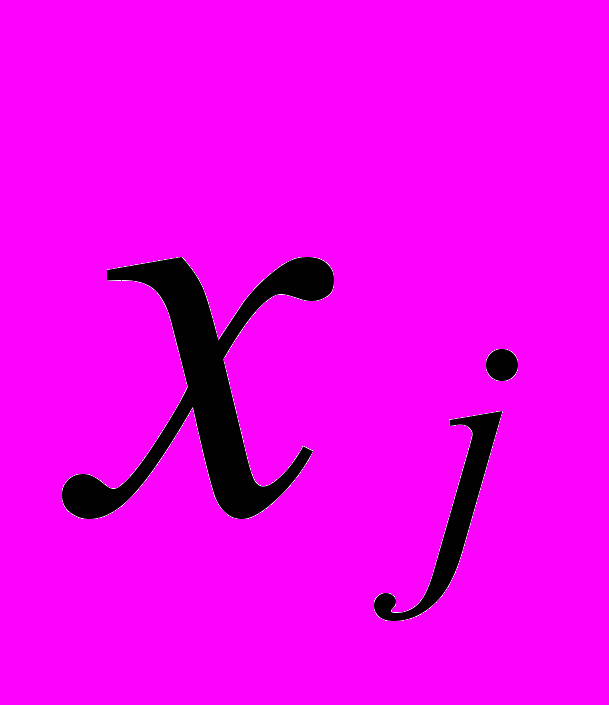 - исходные данные (вектор-столбцы);
- исходные данные (вектор-столбцы); - коэффициенты при общих факторах;
- коэффициенты при общих факторах;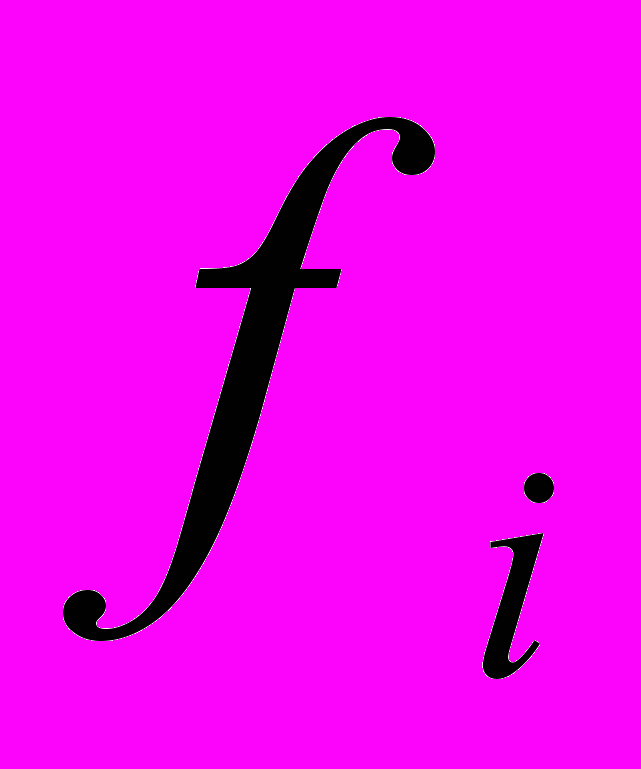 - главные компоненты (вектор-столбцы).
- главные компоненты (вектор-столбцы).Оценками факторных нагрузок служат величины
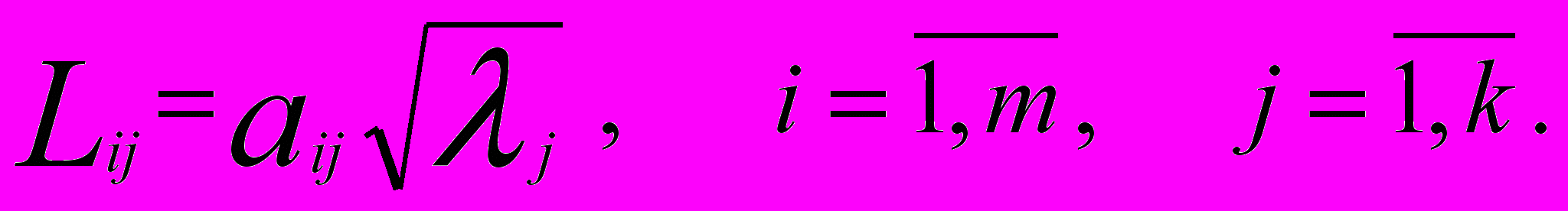 (10)
(10)Оценки общностей получаются как
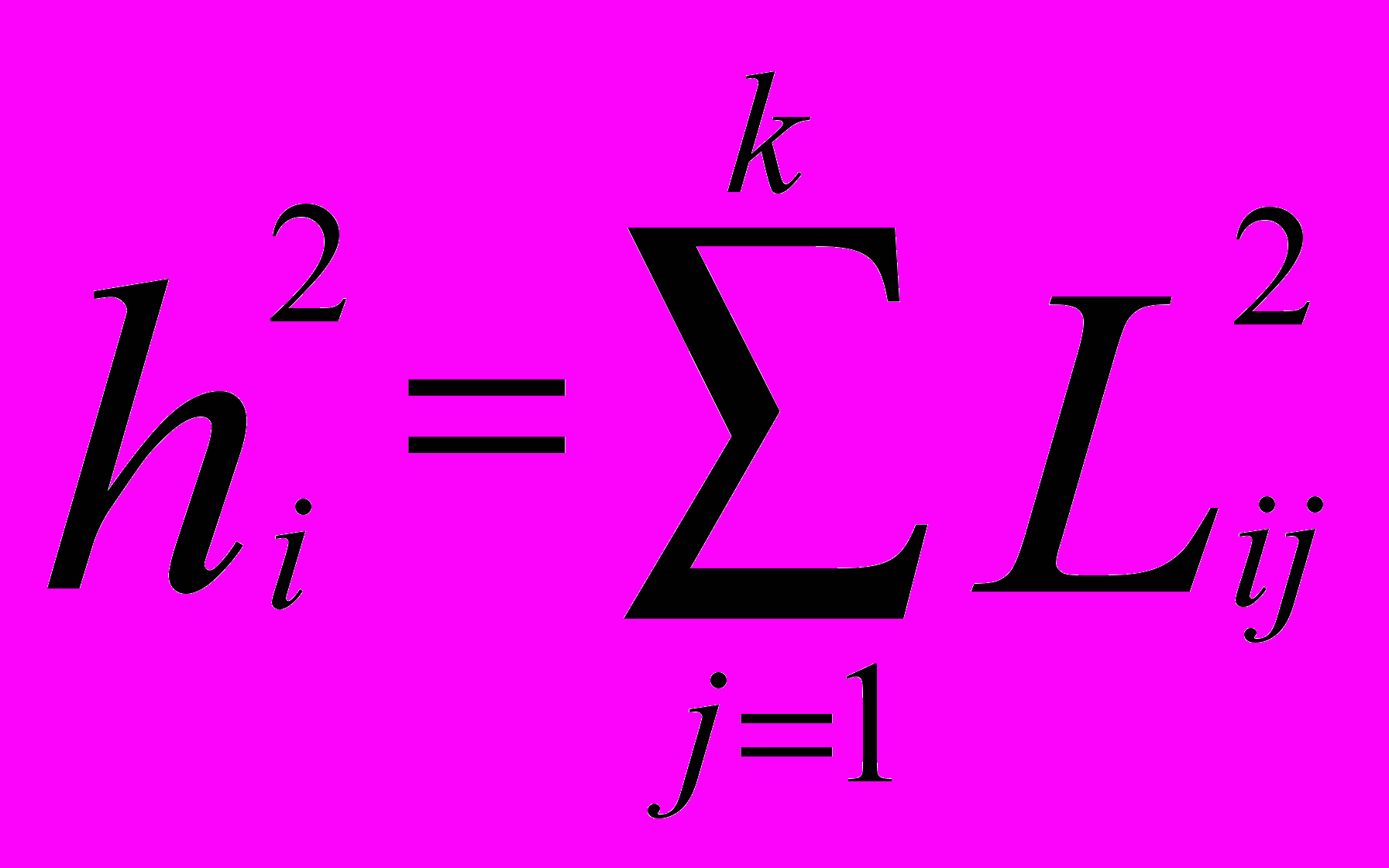 (11)
(11)На следующей итерации модифицируется матрица R - вместо элементов главной диагонали подставляются оценки общностей, полученные на предыдущей итерации; на основании модифицированной матрицы R с помощью вычислительной схемы компонентного анализа повторяется расчет главных компонент (которые не являются таковыми с точки зрения компонентного анализа), ищутся оценки главных факторов, факторных нагрузок, общностей, специфичностей. Факторный анализ можно считать законченным, когда на двух соседних итерациях оценки общностей меняются слабо.
Примечание. Преобразования матрицы R могут нарушать положительную определенность матрицы R+ и, как следствие, некоторые собственные значения R+ могут быть отрицательными.
Для лучшей интерпретации полученных общих факторов к ним применяется процедура вращения. Если факторный анализ ведется в терминах главных компонент, то значения факторов могут быть вычислены непосредственно. В случае вращения главных компонент соотношения, связывающие исходные переменные и значения факторов, несколько усложняются. Ниже в матричном виде приведено соотношение, оптимальное по скорости вычисления, а также независимое от метода вращения факторов:
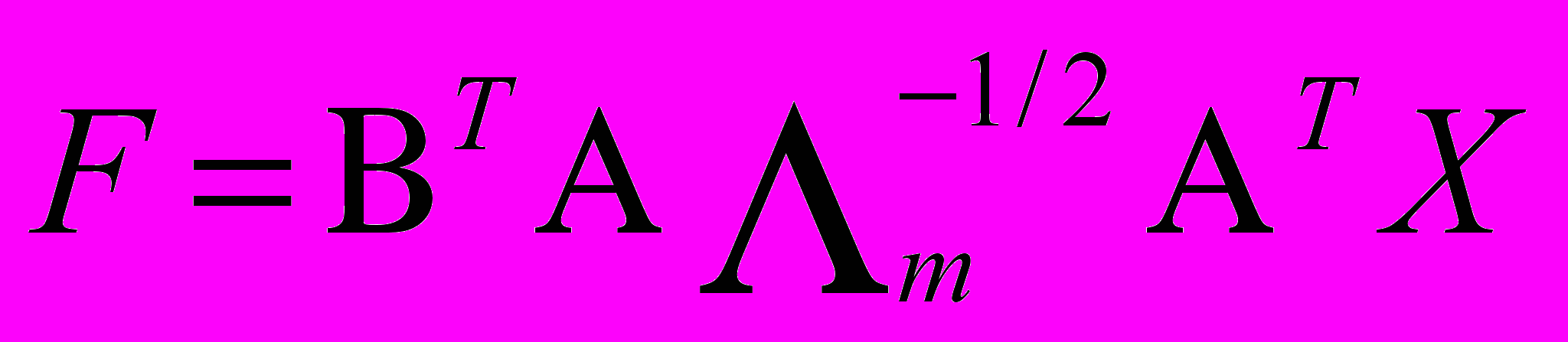 ( 12)
( 12)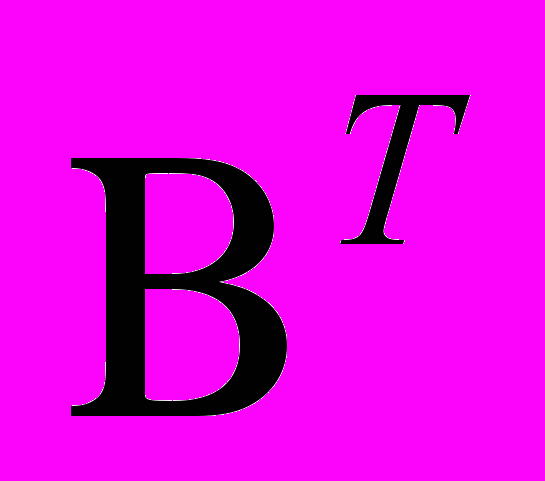 - повернутая матрица A,
- повернутая матрица A,A - матрица коэффициентов при общих факторах,
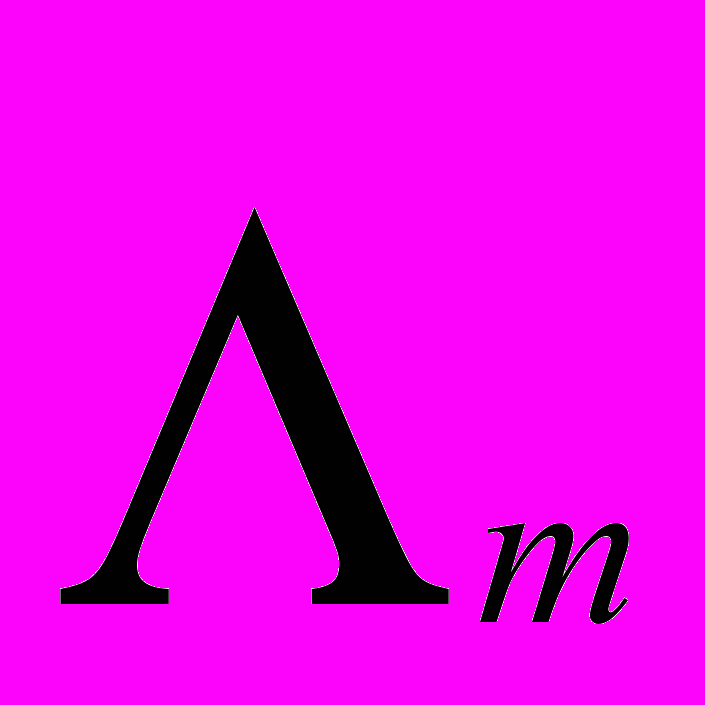 - диагональная матрица m собственных членов,
- диагональная матрица m собственных членов,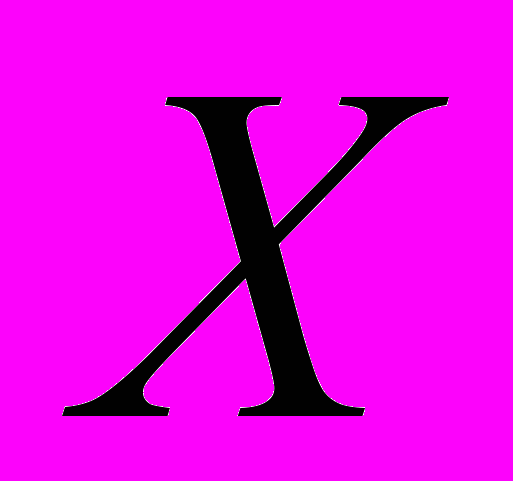 - матрица исходных данных,
- матрица исходных данных, - матрица m повернутых факторов.
- матрица m повернутых факторов.При определении числа общих факторов руководствуются следующими критериями: число существенных факторов можно оценить из содержательных соображений, в качестве числа общих факторов m берется число собственных значений, больших либо равных единице (по умолчанию), выбирается число факторов, объясняющих определенную часть общей дисперсии или суммарной мощности
Литература по теме 6:
- Окунь Я. Факторный анализ/ пер. с польск. – Москва: «Статистика», 1974. - 200 с.
- Дубров А.М., Мхитарян В.С., Трошин Л.И. Многомерные статистические методы/ - Москва, «Финансы и статистика», 2000. - 352
i Дубров А.М., Мхитарян В.С., Трошин Л.И. Многомерные статистические методы/ - Москва, «Финансы и статистика», 2000. - 352 с.