
Лекция Соболевой
| Вид материала | Лекция |
- Лекция Соболевой, 999.06kb.
- Элективный курс по правоведению для 9 класса «Символика Российского государства», 86.61kb.
- «Социальная стратификация и социальная мобильность», 46.19kb.
- Программа по русскому языку по системе Л. В. Занкова. Урок обучения грамоте. Знакомство, 19.7kb.
- Первая лекция. Введение 6 Вторая лекция, 30.95kb.
- Лекция Сионизм в оценке Торы Лекция Государство Израиль испытание на прочность, 2876.59kb.
- Текст лекций н. О. Воскресенская Оглавление Лекция 1: Введение в дисциплину. Предмет, 1185.25kb.
- Собрание 8-511 13. 20 Лекция 2ч режимы работы эл оборудования Пушков ап 8-511 (ррэо), 73.36kb.
- Концепция тренажера уровня установки. Требования к тренажеру (лекция 3, стр. 2-5), 34.9kb.
- Лекция по физической культуре (15. 02.; 22. 02; 01. 03), Лекция по современным технологиям, 31.38kb.
Локальные и глобальные переменные
Использование процедур и функций в Паскале тесно связано с некоторыми особенностями работы с идентификаторами (именами) в программе. В часности, не все имена всегда доступны для использования. Доступ к идентификатору в конкретный момент времени определяется тем, в каком блоке он описан.
Имена, описанные в заголовке или разделе описаний процедуры или функции называют локальными для этого блока. Имена, описанные в блоке, соответствующем всей программе, называют глобальными. Следует помнить, что формальные параметры прцедур и функций всегда являются локальными переменными для соответствующих блоков.
Основные правила работы с глобальными и локальными именами можно сформулировать так:
- Локальные имена доступны (считаются известными, "видимыми") только внутри того блока, где они описаны. Сам этот блок, и все другие, вложенные в него, называют областью видимости для этих локальных имен.
- Имена, описанные в одном блоке, могут совпадать с именами из других, как содержащих данный блок, так и вложенных в него. Это объясняется тем, что переменные, описанные в разных блоках (даже если они имеют одинаковые имена), хранятся в разных областях оперативной памяти.
Глобальные имена хранятся в области памяти, называемой сегментом данных (статическим сегментом) программы. Они создаются на этапе компиляции и действительны на все время работы программы.
В отличие от них, локальные переменные хранятся в специальной области памяти, которая называется стек. Они являются временными, так как создаются в момент входа в подпрограмму и уничтожаются при выходе из нее.
Имя, описанное в блоке, "закрывает" совпадающие с ним имена из блоков, содержащие данный. Это означает, что если в двух блоках, один из которых содержится внутри другого, есть переменные с одинаковыми именами, то после входа во вложенный блок работа будет идти с локальной для данного блока переменной. Пременная с тем же имнем, описанная в объемлющем блоке, становится временно недоступной и это продолжается до момента выхода из вложенного блока.
Рекомендуется все имена, которые имеют в подпрограммах чисто внутреннее, вспомогательное назначение, делать локальными. Это предохраняет от изменений глобальные объекты с такими же именами.
Передача параметров по значению и по ссылке
Параметры в процедуры и функции можно передавать 2 способами - по значению и по ссылке. Отличия между этими двумя способами следующие - при передаче параметра по значению в процедуру (функцию) передается копия переменной, а при передаче по ссылке - оригинал (сама переменная). Рассмотрим эти 2 способа более подробно.
При передаче параметра по значению изменение этого параметра внутри вызываемой процедуры (функции) никак не отразится на ней. Вот поясняющий пример:
...
//Объявление процедуры.
procedure proc(x: integer);
begin
//Изменяем x.
x:=1;
end;
var
r: integer;
begin
r:=25;
//Вызов процедуры.
proc(r);
//Выведется 25
writeln(r);
readln;
end.
Как вы видите, переменная r свое значение не изменила.
При передаче же по ссылке изменение параметра внутри процедуры (функции) влечет за собой изменение и самой передваемой переменной. Вот пример:
...
//Объявление процедуры.
procedure proc(var x: integer);
begin
//Изменяем x.
x:=1;
end;
var
r: integer;
begin
r:=25;
//Вызов процедуры.
proc(r);
//Выведется 1
writeln(r);
readln;
end.
Как вы видите, тут переменная k изменила свое значение. Обратите внимание, что для передачи переменной по ссылке мы пишем ключевое слово var:
...
procedure proc(var x: integer);
...
- Регулярный тип (массивы). Описание массивов. Ввод и вывод элементов массива. Нахождение максимального (минимального) элемента массива.
Массивом называется ограниченная упорядоченная совокупность однотипных величин. Каждая отдельная величина называется компонентой массива. Тип компонент может быть любым, принятым в языке Pascal, кроме файлового типа. Тип компонент называется базовым типом. Вся совокупность компонент определяется одним идентификатором, посредством которого к нему осуществляется обращение, указывается тип и количество элементов массива. Для обозначения отдельных компонент используется конструкция, называемая переменной с индексом или с индексами:
A[5] S[k+1] B[3,5].
Пример описания массивов.
Type
Massiv = array [1..20] of Real;
Var
A, B:Massiv;
C: array [10..30] of Integer;
В данном примере описаны одномерные массивы с именами A, B, C, причём массивы A и B имеют элементы типа Real, порядковые индексы элементов изменяются от 1 до 20, а массив С - с элементами типа Integer, и индексами от 10 до 30. В квадратных скобках указывается тип индекса (в приведённых примерах - это тип диапазон).
В качестве индекса может быть использовано выражение. В индексных типах, по одному для каждой размерности массива, указывается число элементов. Допустимыми индексными типами являются все порядковые типы, за исключением длинного целого и поддиапазонов длинного целого. Индексы интервального типа, для которого базовым является целый тип, могут принимать отрицательные, нулевое и положительные значения.
Массив может быть проиндексирован по каждой размерности всеми значениями соответствующего индексного типа; число элементов, поэтому равно числу значений в каждом индексном типе. Число размерностей не ограничено.
Массивы бывают одномерные и многомерные. Из многомерных наиболее часто приходится иметь дело с двумерными. Двумерные массивы хранятся в памяти ЭВМ по строкам. Двумерный массив можно представить как матрицу элементов. Описание такого массива выглядит так:
Type
Matrix = array [1..20, 1..10] of Real;
Var
X, Y: Matrix;
Z: array [1..10, 1..10] of Integer;
Массивы X и Y имеют двадцать строк и десять столбцов. Массив Z представляет собой квадратную матрицу размером 10X10.
Для доступа к элементам массива необходимо указать идентификатор массива с одним или несколькими индексами в скобках (в зависимости от размерности массива). Конкретный элемент массива обозначается с помощью имени переменной массива, за которой указывается индекс, определяющий данный элемент.
Индексные выражения обозначают компоненты в соответствующей размерности массива. Число выражений не должно превышать числа индексных типов в описании массива. Более того, тип каждого выражения должен быть совместимым по присваиванию с соответствующим индексным типом. В случае многомерного массива можно использовать несколько индексов или несколько выражений в индексе.
Например:
X[I][J] тождественно записи: X[I,J].
Для одномерного массива обращение к элементу будет выглядеть так: Z[I]. В этом и предыдущем случае переменные I и J должна иметь значения, не превышающие диапазона индексов соответствующего массива.
Если тип элемента в типе массив также является массивом, то результат можно рассматривать как массив массивов или как один многомерный массив.
Например, array[boolean] of array[1..100] of array[Size] of Real интерпретируется компилятором точно так же, как массив: array[boolean,1..10,Size] of Real.
Массив вида: array[0..X] of Char, где X - положительное целое число, называется массивом с нулевой базой. Массивы с нулевой базой используются для хранения строк с завершающим нулем, и, когда разрешен расширенный синтаксис (с помощью директивы компилятора {$X+}), символьный массив с нулевой базой совместим со значением типа PChar.
Pascal допускает единственно возможное действие над массивом в целом: использование его в операторе присваивания.
Например:
Vect1:=Vect2
причем типы обоих массивов в данном случае должны быть эквивалентны.
Для работы со всем массивом используется идентификатор массива без указания индекса. К массивам приемлемы только операции отношения "=", "<>". Массивы, являющиеся операндами, должны соответствовать друг другу по структуре, т.е. быть одного типа (одинаковые количество и типы элементов). Таким образом, для двух однотипных массивов X, Y:array [1..30] of Integer; приемлемы следующие выражения:
- X=Y (равно TRUE, если значения каждого элемента массива X равны соответствующим элементам массива Y);
- X<>Y (TRUE, если хотя бы одно значение элемента массива X неравно значению соответствующего элемента массива Y).
Задача:заполнить массив случайными числами от -100 до 100. Найти максимальный и минимальный элемент и их номера.
uses crt;
var m:array[1..100]of integer;
i,n,min,max:integer;
begin
clrscr;
write('N-> ');
readln(n);
for i:=1 to n do
begin
m[i]:=-100+random(201);
write(m[i],' ');
end;
writeln;
min:=1;
max:=2;
for i:=1 to n do if m[i]>m[max] then max:=i else if m[i]
writeln('MAX - M[',max,']=',m[max]);
writeln('MIN - M[',min,']=',m[min]);
readln;
end.
uses
Crt;
- Обработка матриц. Поиск заданного элемента в матрице.
Матрица – это одномерные и многомерные массивы, вощем смотри предыдущий вопрос про массивы
Задана матрица А(n,m). Для выполнения действий над элементами матрицы в соответствии с данными, приведенными в таблице написать программу на языке Pascal.
Количество строк n=20
Количество столбцов m=10
Результат – одномерный массив
Найти минимальный элемент в каждом столбце матрицы отдельно.
Решение
const n=20;m=10;
var A:array [1..n,1..m] of integer;
MinA:array[1..m] of integer;
i,j,min:integer;
begin
writeln;
writeln('Vvedite elementy massiva:');
for i:=1 to n do
for j:=1 to m do
read(A[i,j]);
for j:=1 to m do begin
min:=a[1,j];
for i:=2 to n do
if a[i,j]
end;
writeln('Minimal elementy stolbtsov:');
for j:=1 to m do
write(minA[j],' ');
readln;
end.
- Работа с динамическими переменными. Динамические массивы.
Статической переменной (статически размещенной) называется описанная явным образом в программе переменная, обращение к которой осуществляется по имени. Место в памяти для размещения статических переменных определяется при компиляции программы.
В отличие от таких статических переменных в программах, написанных на языке Паскаль, могут быть созданы динамические переменные. Основное свойство динамических переменных заключается в том, что они создаются и память для них выделяется во время выполнения программы. Размещаются динамические переменные в динамической области памяти (heap – области).
Динамическая переменная не указывается явно в описаниях переменных и к ней нельзя обратиться по имени. Доступ к таким переменным осуществляется с помощью указателей и ссылок.
Работа с динамической областью памяти в Турбо Паскале реализуется с помощью процедур и функций New, Dispose, GetMem, FreeMem, Mark, Release, MaxAvail, MemAvail, SizeOf.
Процедура New (var p: Pointer) выделяет место в динамической области памяти для размещения динамической переменной p и ее адрес присваивает указателю p.
Процедура Dispose (var p: Pointer) освобождает участок памяти, выделенный для размещения динамической переменной процедурой New, и значение указателя p становится неопределенным.
Процедура GetMem (var p: Pointer; size: Word) выделяет участок памяти в heap-области, присваивает адрес его начала указателю p, размер участка в байтах задается параметром size.
Процедура FreeMem (var p: Pointer; size: Word) освобождает участок памяти, адрес начала которого определен указателем p, а размер параметром size. Значение указателя p становится неопределенным.
Процедура Mark (var p: Pointer) записывает в указатель p адрес начала участка свободной динамической памяти на момент ее вызова.
Процедура Release (var p: Pointer) освобождает участок динамической памяти, начиная с адреса, записанного в указатель p процедурой Mark, то есть, очищает ту динамическую память, которая была занята после вызова процедуры Mark.
Функция MaxAvail: Longint возвращает длину в байтах самого длинного свободного участка динамической памяти.
Функция MemAvail: Longint полный объем свободной динамической памяти в байтах.
Вспомогательная функция SizeOf (X): Word возвращает объем в байтах, занимаемый X, причем X может быть либо именем переменной любого типа, либо именем типа.
Рассмотрим некоторые примеры работы с указателями.
var
p1, p2: Integer;
Здесь p1 и p2 – указатели или переменные ссылочного типа.
p1:=NIL; p2:=NIL;
После выполнения этих операторов присваивания указатели p1 и p2 не будут ссылаться ни на какой конкретный объект.
New(p1); New(p2);
Процедура New(p1) выполняет следующие действия:
– в памяти ЭВМ выделяется участок для размещения величины целого типа;
– адрес этого участка присваивается переменной p1:
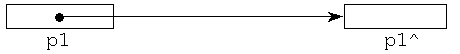
Аналогично, процедура New(p2) обеспечит выделение участка памяти, адрес которого будет записан в p2:

После выполнения операторов присваивания
p1:=2; p2:=4;
в выделенные участки памяти будут записаны значения 2 и 4 соответственно:

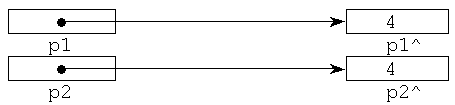
В результате выполнения оператора присваивания
p1:=p2;
в участок памяти, на который ссылается указатель p1, будет записано значение 4:
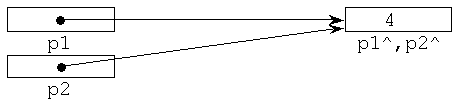
После выполнения оператора присваивания
p2:=p1;
оба указателя будут содержать адрес первого участка памяти:
Переменные p1, p2 являются динамическими, так как память для них выделяется в процессе выполнения программы с помощью процедуры New.
Динамические переменные могут входить в состав выражений, например:
p1:=p1+8; Write('p1=',p1:3);
Пример. В результате выполнения программы:
Program DemoPointer;
Var p1,p2,p3:Integer;
Begin
p1:=NIL; p2:=NIL; p3:=NIL;
New(p1); New(p2); New(p3);
p1:=2; p2:=4;
p3:=p1+Sqr(p2);
writeln('p1=',p1:3,' p2=',p2:3,' p3=',p3:3);
p1:=p2;
writeln('p1=',p1:3,' p2=',p2:3)
End.
на экран дисплея будут выведены результаты:
p1= 2 p2= 4 p3= 18
p1= 4 p2= 4
Динамические массивы
Динамическим называется массив, размер которого может меняться во время исполнения программы. Для изменения размера динамического массива язык программирования, поддерживающий такие массивы, должен предоставлять встроенную функцию или оператор. Динамические массивы дают возможность более гибкой работы с данными, так как позволяют не прогнозировать хранимые объёмы данных, а регулировать размер массива в соответствии с реально необходимыми объёмами. Обычные, не динамические массивы называют ещё статическими.
byteArray : Array of Byte; // Одномерный массив
multiArray : Array of Array of string; // Многомерный массив
1.11. Файловый ввод-вывод. Работа с текстовыми и двоичными файлами.
Язык программирования Си поддерживает множество функций стандартных библиотек для файлового ввода и вывода. Эти функции составляют основу заголовочного файла стандартной библиотеки языка Си <stdio.h>.
Функциональность ввода-вывода языка Си по текущим стандартам реализуется на низком уровне. Язык Си абстрагирует все файловые операции, превращая их в операции с потоками байтов, которые могут быть как "потоками ввода", так и "потоками вывода". В отличие от некоторых ранних языков программирования, язык Си не имеет прямой поддержки произвольного доступа к файлам данных; чтобы считать записанную информацию в середине файла, программисту приходится создавать поток, ищущий в середине файла, а затем последовательно считывать байты из потока.
Потоковая модель файлового ввода-вывода была популяризирована во многом благодаря операционной системе Unix, написанной на языке Си. Большая функциональность современных операционных систем унаследовала потоки от Unix, а многие языки семейства языков программирования Си унаследовали интерфейс файлового ввода-вывода языка Си с небольшими отличиями (например, PHP). Стандартная библиотека C++ отражает потоковую концепцию в своем синтаксисе.
Файл открывается при помощи fopen, которая возвращает информацию потока ввода-вывода, прикрепленного к указанному файлу или другому устройству, с которого идет чтение (или в который идет запись). В случае неудачи функция возвращает нулевой указатель.
Функция freopen закрывает текущий файл, связанный с потоком fp, и переназначает этот поток в файл, определяемый path-именем. Эта функция обычно применяется для переадресации предоткрытых потоков stdin, stdout, stderr, stdaux, stdprn в файлы, определяемые пользователем. Новый файл, связанный с потоком, открывается в режиме mode.
Они определяются как:
FILE *fopen(const char *path, const char *mode);
FILE *freopen(const char *path, const char *mode, FILE *fp);
Функция fopen по сути представляет собой "обертку" более высокого уровня системного вызова open операционной системы Unix. Аналогично, fclose является оберткой системного вызова Unix close, а сама структура FILE языка Си зачастую обращается к соответствующему файловому дескриптору Unix. В POSIX-окружении[ Portable Operating System Interface for Unix — Переносимый интерфейс операционных систем Unix — набор стандартов, описывающих интерфейсы между операционной системой и прикладной программой.] функция fopen может использоваться для инициализации структуры FILE файловым дескриптором. Тем не менее, файловые дескрипторы как исключительно Unix-концепция не представлены в стандарте языка Си.
Параметр mode (режим) для fopen и freopen должен быть строковый и начинаться с одной из следующих последовательностей:
| режим | описание | начинает с.. | ||
| r | rb | | открывает для чтения | начала |
| w | wb | | открывает для записи (создает файл в случае его отсутствия). Удаляет содержимое и перезаписывает файл. | начала |
| a | ab | | открывает для добавления (создает файл в случае его отсутствия) | конца |
| r+ | rb+ | r+b | открывает для чтения и записи | начала |
| w+ | wb+ | w+b | открывает для чтения и записи. Удаляет содержимое и перезаписывает файл. | начала |
| a+ | ab+ | a+b | открывает для чтения и записи (добавляет в случае существования файла) | конца |
Значение "b" зарезервировано для двоичного режима С. Стандарт языка Си описывает два вида файлов — текстовые и двоичные — хотя операционная система не требует их различать. Текстовый файл - файл, содержащий текст, разбитый на строки при помощи некоторого разделяющего символа окончания строки или последовательности (в Unix - одиночный символ перевода строки; в Microsoft Windows за символом перевода строки следует знак возврата каретки). При считывании байтов из текстового файла, символы конца строки обычно связываются (заменяются) с переводом строки для упрощения обработки. При записи текстового файла одиночный символ перевода строки перед записью связывается (заменяется) с специфичной для ОС последовательностью символов конца строки. Двоичный файл - файл, из которого байты считываются и выводятся в "сыром" виде без какого-либо связывания (подстановки).
При открытом файле в режиме обновления ( '+' в качестве второго или третьего символа аргумента обозначения режима) и ввод и вывод могут выполняться в одном потоке. Тем не менее, запись не может следовать за чтением без промежуточного вызова fflush или функции позиционирования в файле (fseek, fsetpos или rewind), а чтение не может следовать за записью без промежуточного вызова функции позиционирования в файле.
Режимы записи и добавления пытаются создать файл с заданным именем, если такого файла еще не существует. Как указывалось выше, если эта операция оканчивается неудачей, fopen возвращает NULL.
Закрытие файла осуществляется с помощью функции fclose . Функция fclose принимает один аргумент: указатель на структуру FILE потока для закрытия.
int fclose(FILE *fp);
Функция возвращает нуль в случае успеха и EOF в случае неудачи. При нормальном завершении программы функция вызывается автоматически для каждого открытого файла.