
В. М. Дубовой Укладач д т. н., проф
| Вид материала | Документы |
- Р. А. Хальфин 08. 12. 2006 г. N 6530-рх методические рекомендации, 1062.91kb.
- Программа студенческой олимпиады мгмсу по стоматологии 30. 10., 33.94kb.
- М. А. Рыбалко (отв редактор), проф, 973.68kb.
- Реферат циклу підручників «Україна в світовій політиці», 148.74kb.
- Колективу авторів у складі: проф. Гаращенко Ф. Г., проф. Закусило О. К., проф. Зайченко, 259.94kb.
- Программа по курсу "Уголовное право" / Сост проф. Б. С. Волков, проф. И. Д. Козочкин,, 638.15kb.
- Квалификационные тесты по дерматовенерологии Москва, 2267.11kb.
- Інформаційні технології в журналістиці: вітчизняний І світовий досвід Київ 2002, 8272.38kb.
- И научные учреждения второе переработанное и дополненное издание, 8298.18kb.
- Программа учебного курса «Международное право» для студентов, 747.97kb.
Таблиця 8 Типи дані дати і часу
| Назва | LPS | Опис |
| Date time | ooo | Тип даних, що дозволяє зберігати комбінації дати і часу, що займає в пам'яті 8 байт. Діапазон: від 01.01.1753 до 31.12.9999. |
| Small-date time | ooo | Аналогічний типу даних Datetime, що займає в пам'яті 4 байти Діапазон: від 01.01.1900 до 06.06.2079. |
Таблиця 9 Типи даних спеціального призначення
| Назва | LPS | Опис |
| Bit | ooo | Тип даних, що дозволяє зберігати інформацію, що приймає тільки два значення: 0 чи 1; займає в пам'яті 1 біт. Діапазон: 0 чи 1. |
| Binary | oo | Тип даних, використовуваний для збереження бітових ланцюжків. Розмірність: до 8000 байт. |
| Varbinary | oo | Тип даних, використовуваний для збереження бітових ланцюжків варьируемой довжини, аналогічно типу даних Binary. Розмірність: до 8000 байт. |
| Timestamp | ooo | Тип даних, що автоматично розміщає значення лічильника щораз при вставці нового запису. |
| Uniqueidentifier | ooo | Розміщення унікального 16-розрядного ідентифікатора QUID (Globally unique identifier), використовуваного для підтримки цілісності даних. Генерація нового ідентифікатора здійснюється з використанням команди SQL NEWID() |
Створення індексів і ключів у системі SQL-сервер
Індекси являють собою наборы унікальних значень для деякої таблиці з відповідними посиланнями на дані, розташовані в самій таблиці. Індекси є зручним внутрішнім механізмом системи SQL-сервера, за допомогою якого здійснюється доступ до даних найбільш оптимальним способом.
Для створення індексів визначеної таблиці бази даних SQL-сервера можна скористатися одним з наступних способів:
• створити індекс за допомогою SQL-команди CREATE INDEX;
• скористатися можливостями утиліти SQL Server Enterprise Manager.
Розглянемо подробней другий спосіб створення індексів. Початковим етапом створення індексу є вибір необхідної бази даних і таблиці, для якої він буде визначатися. Виконання команди. All Tasks / Manage Indexes меню Action відобразить на екрані діалогове вікно керування індексами баз даних. Варто звернути увагу на списки даного діалогового, що випадають, вікна Databases і Table, що дозволяють переміщатися між базами даних і їхня таблиця. При тім у списку Existing indexes відображаються наявні індекси для обраних таблиць баз даних.
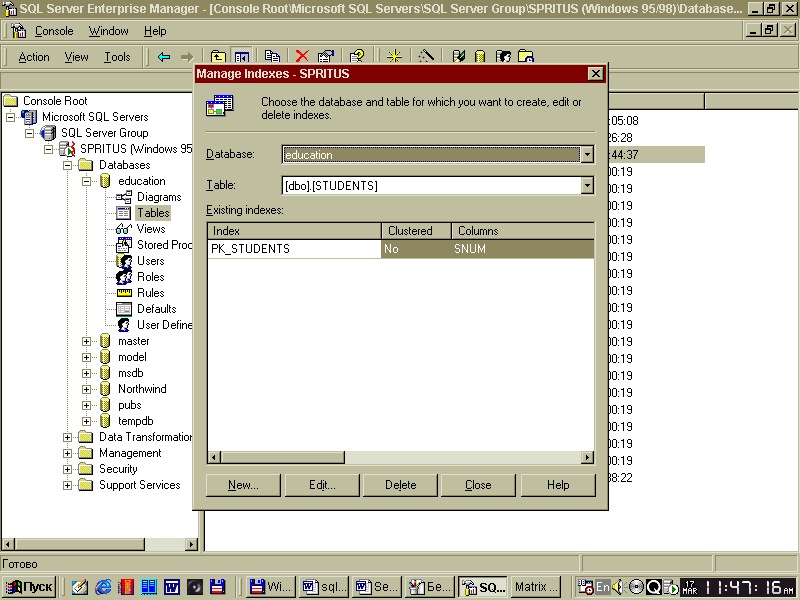
Рисунок 8 - Діалогове вікно керування індексами таблиці
У нижній частині даного діалогового вікна располоя керуючі кнопки, що виконують наступні дії:
New - створення нового індексу для обраної таблиці даних;
Edit - редагування параметрів існуючого індексу;
Delete - видалення попереднє обраного індексу;
Close - закриття діалогового вікна;
Help - одержання довідкової інформації з даного питання.
Отже, для створення нового індексу варто скористатися кнопкою New даного діалогового вікна. Ця дія приведе до відкриття іншого діалогового вікна Create New Index, за допомогою якого і встановлюються параметри індексу (див. мал. 3.30).
У поле Index name даного діалогового вікна необхідно ввести ім'я створюваного індексу, після чого визначити перелік полів, що беруть участь в індексі, у представленому списку. Для додавання визначеного полючи в індекс варто установити прапорець ліворуч від його імені. Тут також можна переглянути наступну інформацію про поле: Column - ім'я полючи, Data type - тип даних, Length - розмір, Nullable - можливість використання NULL-значень, Precision - точність і Scale - порядок значень, що вводяться.
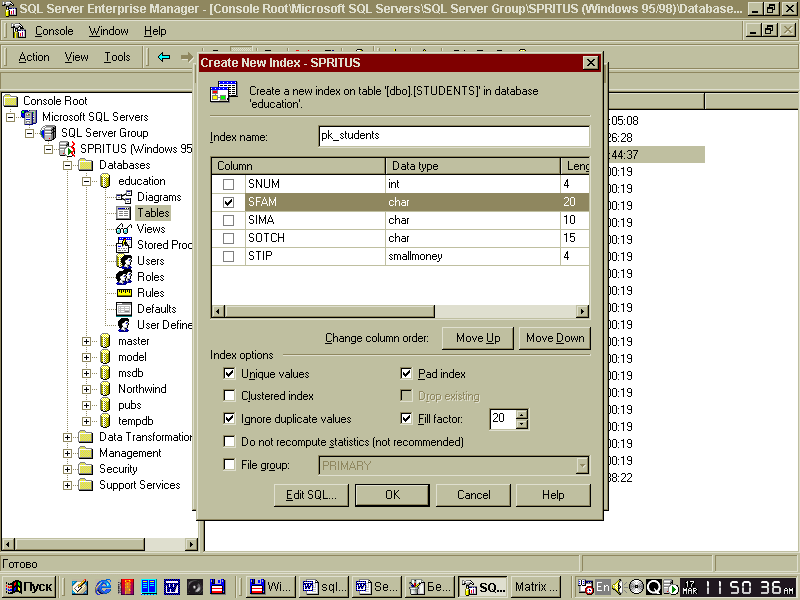
Рис3.30. Діалогове вікно створення індексу
Група опцій Index options дозволяє настроїти додаткові параметри створюваного індексу:
Unique values - при необхідності введення у визначене поле тільки унікальних значень, варто установити дану опцію. Це дозволить здійснювати автоматичну перевірку унікальності при кожнім додаванні нового запису. Якщо буде почата спроба уведення вже наявного значення в записі даного полючи, то системою буде видане повідомлення про помилку. При цьому варто звернути увагу на заборону присутності NULL-значень у цьому полі. При використанні NULL-значень і установці даної опції можуть виникнути помилки. Тому рекомендується установити обов'язкове введення значень у поле, для якого планується створення унікального індексу;
Clustered index - у системі SQL-сервер є можливість фізичного індексування даних. Іншими словами, використання індексів приводить до створення окремої структури, що зв'язується з фізичним розташуванням даних у таблиці. Використання цієї опції дозволяє зробити так називане кластерное індексування, у результаті чого будуть відсортовані дані в самій таблиці відповідно до порядку цього індексу, і вся інформація, що додається, буде приводити до зміни фізичного порядку даних. При цьому потрібно враховувати, що в таблиці може бути визначений тільки один кластерный індекс;
Ignore duplicate values — вибір даної опції приводить до ігнорування введення повторюваних значень у проіндексованих полях. Використання даної опції разом з Unique values дозволяє ігнорувати унікальність значень для полючи. Варто звертатися з цією опцією особливо акуратно роботі з многотабличными структурами і зв'язками між ними. Звичайне використання даної опції має значення при орієнтації на розподіл даних у розроблювальних структурах;
Do not recompute statistics (not recommended) - установка опції визначає функцію автоматичного відновлення статистики для таблиці. Не рекомендується установка даної опції;
File group - за допомогою даної опції можна здійснити вибір файлової групи, у якій буде знаходитися створюваний індекс. Використання індексу з іншої файлової групи підвищує продуктивність некластерных індексів у зв'язку з паралельністю виконання процесів уведення/висновку і роботи із самим індексом. При виборі даної опції активізується список файлових груп, що дозволяє визначити необхідну групу для розміщення індексу;
Fill factor - дана можливість використовується вкрай рідко. За допомогою цієї опції здійснюється настроювання розбивки індексу на сторінки. Однак використання даної можливості може помітно оптимизировать роботу SQL-сервера. Коефіцієнт FILLFACTOR визначає у відсотком співвідношенні розмір створюваних індексних сторінок. При цьому є зворотна пропорційна залежність частоти роботи з таблицею і коефіцієнта FILLFACTOR. Іншими словами, якщо планується часта зміна, видалення і додавання інформації в таблиці бази даних, то коефіцієнт FILLFACTOR варто установити якнайменше, наприклад, 20. З іншого боку, установка коефіцієнту значення 100 рекомендується при використанні великих таблиць, звертання до яких звичайно відбувається тільки для читання;
Pad index - опція визначає заповнення внутрішнього простору індексу і використовується разом з опцією Fill factor,
Drop existing - при використанні кластерного індексу, вибір даної опції визначає його повторне створення, що дозволяє запобігти небажане відновлення кластерных індексів.
Звичайному користувачу вкрай рідко приходиться створювати БД чи таблиці усередині її. Традиційно він працює з уже готовою структурою, що вже розроблена і реалізована адміністратором БД. Проте, для повного розуміння особливостей роботи SQL на операторах DDL (мова визначення даних) варто зупинитися досить докладно. За допомогою цих операторів можна:
- створити нову БД;
- визначити структуру нової таблиці і створити цю таблицю;
- видалити існуючу таблицю;
- змінити визначення існуючої таблиці;
- визначити представлення даних;
- забезпечити умови безпеки БД;
- створити індекси для доступу до таблиць;
- керувати розміщенням даних на пристроях збереження.
Оператори DDL дозволяють користувачу не вникати в деталі, збереження інформації в БД на фізичному рівні, тому що оперують, наприклад, такими поняттями, як чи таблиці полючи. У той же час, оператори DDL мають можливість маніпуляції з фізичною пам'яттю.
Власне DDL базується на трьох командах SQL:
- CREATE - створити, що дозволяє визначити й об'єкт БД;
- DROP - видалити, застосовуваний для видалення існуючого об'єкта даних;
- ALTER - змінити, за допомогою якого можна змінити визначення об'єкта БД.
Використання команд DDL під час роботи дозволяє зробити структуру реляционной БД динамічної. Іншими словами, у СУБД можна створювати, чи видаляти змінювати таблиці, одночасно з цим забезпечуючи доступ користувачам до даних. У свою чергу, це означає, що з часом БД може рости і змінюватися, а її експлуатація може продовжуватися в той час, коли в БД додаються всі нові таблиці і додатки.
Оператори DDL у СУБД можна використовувати як в інтерактивному, так і в програмному SQL. Наприклад, якщо чи програмі користувачу потрібно таблиця для тимчасового збереження результатів, то допускається створити цю таблицю, заповнити її інформацією, виконати необхідні маніпуляції з даними і потім видалити її. У серйозних СУБД за створення нових БД відповідає тільки адміністратор, хоча не виключена можливість того, що й окремим користувачам це може бути дозволено.
Методи створення БД, застосовувані у ведучих реляционных СУБД, мають ряд розходжень. Наприклад, у Microsoft SQL Server існує оператор CREATE DATABASE, що є частиною мови визначення даних і служить для створення БД. Відповідно, оператор DROP DATABASE видаляє існуючі БД. Ці оператори можна використовувати як в інтерактивному, так і в програмному SQL.
Більшість многопользовательских БД мають досить нескладну організацію фізичної пам'яті, що забезпечує підвищення її продуктивності. Наприклад, у Microsoft SQL Server адміністратор БД може за допомогою оператора CREATE DATABASE задати один чи кілька іменованих файлів:
CREATE DATABASE
Підхід, використовуваний у SQL Server, дозволяє розподіляти вміст БД по декількох дискових томах, про що вже говорилося вище. Наступним кроком, слідом за створенням порожній БД, є заповнення її таблицями.
Створення таблиць
Отже, після створення: БД необхідно здійснити створення, зміна, а якщо потрібно - те й успение таблиць. Ці дії відносяться до самих таблиць, а не до даних, що у них містяться.
Таблиці створюються командою CREATE TABLE. Ця команда створює порожню таблицю, тобто не утримуючих записів. Очевидно, що значення в неї можна ввести, наприклад, за допомогою команди INSERT. Головне в команді CREATE TABLE - це визначення імені таблиці й описи набору імен полів, що вказуються у відповідному порядку. Крім того, цією командою також обмовляються типи даних і розміри полів таблиці.
Очевидно, що в кожній таблиці повинне бути, принаймні одне поле.
Синтаксис команди CREATE TABLE наступний:
CREATE TABLE
| Казанко | Віталій | Володимирович |
| Костыркин | Оле | Володимирович |
| Познякова | Любов | Олексійович |
| Котенко | Анатолій | Миколайович |
| Нагорний | Євгеній | Васильович |
| Поляків | Анатолій | Олексіївна |
Звідси можна зробити висновок, що запису, обрані двома командами, виведені так, ніби вона була одна. Природно, що заголовки стовпців виключені, тому що жоден зі стовпців, виведених об'єднанням, не був витягнутий безпосередньо з тільки однієї таблиці, отже, Всі ці стовпці висновку не мають ніяких імен. Зверніть увагу на те, що тільки останній запит закінчується крапкою з коми - відсутність крапки з коми дає зрозуміти SQL, що мається ще один чи більш запитів.
Коли два чи більш запити піддаються об'єднанню, їхні стовпці висновку повинні бути сумісні для об'єднання, що нами вже розглядалося вище. Нагадаємо, що це означає для кожного запиту необхідність включення однакового числа стовпців у тім же порядку, що і перший, другий, третій, і т.д., і при цьому повинна бути присутнім сумісність типів. Інше обмеження на сумісність - це коли порожні значення NULL заборонені в будь-якому стовпці об'єднання, тоді ці значення необхідно заборонити і для Всіх відповідних стовпців в інших запитах об'єднання. Нарешті, не можна використовувати агрегатні функції в пропозиції SELECT запиту в об'єднанні.
UNION буде автоматично виключати дублікати рядків з висновку. Якщо, наприклад, у таблиці STUDENTS з'явиться ще один студент із прізвищем Поляків, то запит
SELECT SFAM FROM STUDENTS
дасть наступний висновок:
-
SFAM
Поляків
Старова
Гриценко
Котенко
Нагорний
Поляків
Тут мається дублювання значень SFAM = Поляків, тому що не зазначено, щоб SQL усунув дублікати. Однак, при використанні UNION у комбінації цього запиту з йому подібним у таблиці викладачів, надлишкова інформація буде усунута.
SELECT SFAM FROM STUDENTS UNION SELECT TFAM FROM TEACHERS;
дає наступні результати без дублювання прізвища Поляків:
| Поляків |
| Старова |
| Гриценко |
| Котенко |
| Нагорний |
| Викулина |
| Костыркин |
| Казанко |
| Позднякова |
| Загарийчук |