
Ввода-вывода
| Вид материала | Лекция |
- 1scsi (Small Computer System Interface), 197.4kb.
- 2. Порты ввода/вывода, 253.14kb.
- Лекция Мультиплексирование ввода/вывода и асинхронный ввод/вывод, 220.73kb.
- Контрольная работа (приложение работает правильно) 20 баллов. Опрос на лекциях 1 балл,, 34.71kb.
- 1. Технологии работы с графической информацией. Растровая и векторная графика. Аппаратные, 388.94kb.
- Примеры фрагментов программ ввода вывода с текстовыми файлами на языках Qbasic, TurboPascal, 97.23kb.
- Устройства ввода информации Устройствами ввода, 26.92kb.
- Type znak=(minus, plus, del, mult), 96.24kb.
- Карта базовой икт компетенции учителя-предметника, 50.08kb.
- Лекция: Система управления вводом-выводом, 614.83kb.
Лекция №2
Архитектура однопроцессорной системы: процессор, память, подсистема ввода-вывода
Содержание лекции:
- Процессор
- Общая структура процессора
- Регистры процессора
- Дешифратор команд и система команд
- Конвейер и блок предсказания команд
- Кэш первого и второго уровня
- Подсистема прерываний
- Архитектурные расширения
- MMX/3DNow/SSE/SSE2/SSE3
- Векторно-конвейерный процессор
- Технология Hyper Threading (Intel)
- Технология Hyper Transport (AMD)
- Двуядерные и многоядерные процессоры
- MMX/3DNow/SSE/SSE2/SSE3
- Общая структура процессора
- Память
- Динамическая память (DRAM)
- Общие принципы работы памяти
- SDRAM
- DDR
- DDR-II
- DRDRAM
- Общие принципы работы памяти
- Статическая память (SRAM)
- Ассоциативная память
- Другие технологии памяти
- Динамическая память (DRAM)
- Устройства ввода-вывода
- Принципы подсистемы прямого доступа к памяти
- Дисковые накопители
- Общие принципы организации дисковой памяти
- Технологии IDE, SATA
- Технология SCSI
- RAID
- Общие принципы организации дисковой памяти
- Сетевая среда
- Принципы подсистемы прямого доступа к памяти
1. Процессор
Рассмотрим общую архитектуру процессора. Схематично ее можно изобразить на следующем рисунке.
Можно выделить наиболее важные блоки. Блок регистров и флагов состояния процессора. Блоки целочисленной и вещественной арифметики. Кэши первого и второго уровня. Блоки графического и векторного расширения. Конвейеры, блоки дешифрации команд и предсказания. Блок управления прерываниями и интерфейс доступа к системной шине.
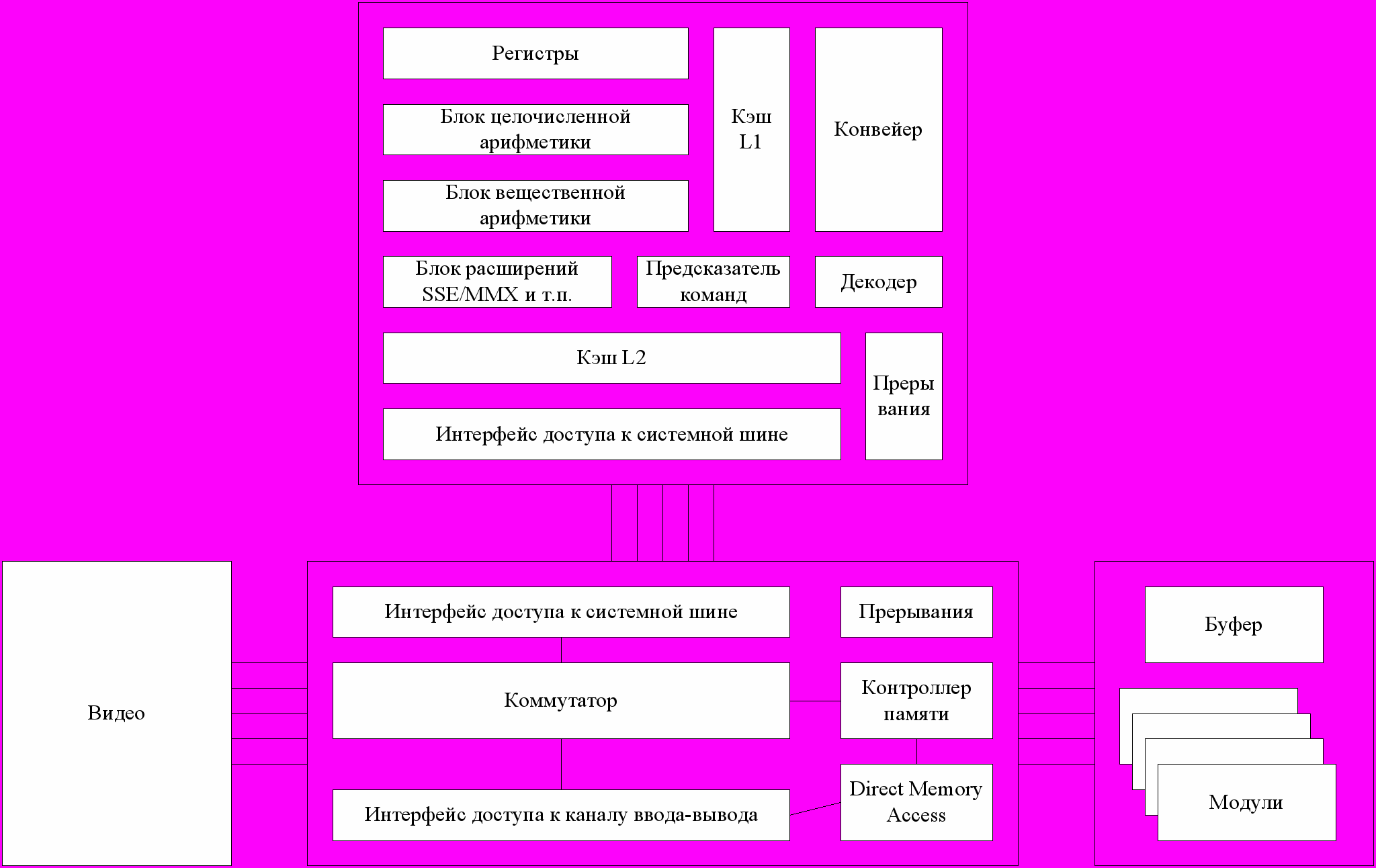
Рис. 2.1. Архитектура процессора
1.а. Регистры процессора
Регистр процессора — сверхбыстрая память внутри процессора, предназначенная прежде всего для хранения промежуточных результатов вычисления (регистр общего назначения/регистр данных) или содержащая данные, необходимые для работы процессора — смещения базовых таблиц, уровни доступа и т. д. (специальные регистры).
Доступ к значениям, хранящимся в регистрах как правило в несколько раз быстрее чем доступ к ячейкам оперативной памяти (даже если кеш-память содержит нужные данные), но объём оперативной памяти намного превосходит суммарный объём регистров (объём среднего модуля оперативной памяти сегодня составляет 1 Гб — 4 Гб[1], суммарная «ёмкость» регистров общего назначения/данных для процессора Intel 80x86 16 битов * 4 = 64 бита (8 байт)).
Регистры подразделяют на:
- Регистры общего назначения (для арифметических и логических операций):
- Арифметические регистры
- Индексные регистры
- Сегментные регистры
- Арифметические регистры
- Регистры управления (для управления порядком исполнения программы)
- Регистры состояния (отображение состояния процессора)
- Регистры специального назначения (векторные регистры, регистры MMX/SSE)
Например
EAX, EBX – название регистров общего назначения на платформе x86
IP, SP – (instruction pointer, stack pointer) – регистры счетчика команд и указатель стека
Flags (ZF, CF) – флаг нуля, флаг переноса и т.п.
MM0, MM1 – регистры MMX
1.b. Дешифратор команд и система команд
Команда – минимальное действие, которое может совершить процессор над данными в адресуемой памяти.
Различают:
- Команды передачи данных (например, MOV)
- Арифметические операции (ADD, SUB)
- Логические операции (OR, AND)
- Операции сдвига (SHL, SHR)
- Операции ввода-вывода (IN, OUT)
- Команды управления (JMP, CALL)
- Команды ветвления и цикла (JC, JZ, REP)
- Специальные команды (EMMS, MOVQ, управление кэшем и т.п.)
Команда состоит из кода операции и набора операндов. Различают одноадресные команды (один операнд), двух адресные команды и трехадресные команды.
Существует два подхода к конструированию процессоров. Первый состоит в том, чтобы придумать как можно больше разных команд и предусмотреть как можно больше разных режимов адресации. Процессоры такого типа называются CISC-процессорами, от слов Сomplex Instruction Set Computers. Это, в частности, Intel 80x86 и Motorola 68000. Противоположный подход состоит в том, чтобы реализовать лишь минимальное множество команд и режимов адресации, процессоры такого типа называются RISC-процессорами, от слов Reduced Instruction Set Computers. Примеры RISC-процессоров: DEC Alpha, Power PC, Intel Itanium.
Казалось бы, CISC-процессоры должны иметь преимущество перед RISC-процессорами, но на самом деле все обстоит строго наоборот. Дело в том, что простота набора команд процессора облегчает его конструирование, в результате чего удается достичь следующих целей:
- все команды выполняются исключительно быстро, причем за одинаковое время, т.е. за фиксированное число тактов работы процессора;
- значительно поднимается тактовая частота процессора;
- намного увеличивается количество регистров процессора и объем кэш-памяти;
- удается добиться ортогональности режимов адресации, набора команд и набора регистров. Это означает, что нет каких-либо выделенных регистров или режимов адресации: в любых (или почти любых) командах можно использовать произвольные регистры и режимы адресации независимо друг от друга. Следует отметить, что к памяти могут обращаться лишь команды загрузки слова из памяти в регистр и записи из регистра в память, а все арифметические команды работают только с регистрами;
- простота команд позволяет эффективно организовать их выполнение в конвейере (pipeline), что значительно ускоряет работу программы.
Пункты 3 и 4 по достоинству оценят те, кому пришлось программировать на Ассемблере Intel 80x86, имеющем ряд ограничений на использование регистров и режимы адресации, к тому же и регистров в нем очень мало.
RISC-архитектуры обладают неоспоримыми преимуществами по сравнению с CISC-архитектурами — быстродействием, низкой стоимостью, удобством программирования и т.д. — и практически не имеют недостатков. Существование CISC-процессоров в большинстве случаев объясняется лишь традицией и требованием совместимости со старым программным обеспечением. Впрочем, существует и третий вариант — процессоры, которые, по сути, являются RISC-процессорами, но эмулируют внешнюю систему команд устаревших процессоров, например, современные процессоры Intel Pentium.
1.d. Конвейер и блок предсказания команд
Конвейер – очередь команд, которая позволяет выбирать и выполнять следующие инструкции вместе с текущей. Конвейер характеризуется своей глубиной или количеством ступеней конвейера. Каждая ступень конвейера выполняет одну микрооперацию.
Максимальный эффект применение конвейер дает прирост производительности выраженный формулой (n * d) / (n + d), где n – количество операндов, загружаемых в конвейер, d – глубина конвейера. В этом случае ускорение составит (200*5)/(200+5)=4.88. Разумеется, это идеальная ситуация, недостижимая в реальной жизни, в частности, считается, что нет "пузырей".
Важным условием нормальной работы конвейера является отсутствие конфликтов, то есть данные, подаваемые в конвейер, должны быть независимыми. В том случае, когда очередной операнд зависит от результата предыдущей операции, возникают такие периоды работы конвейера ("пузыри"), когда он пуст.
Блок предсказания команд основывается на результатах операций сравнения и условного перехода для выборки в кэш возможных команд, которые потребуются для дальнейшего исполнения.
1.e. Кэш первого и второго уровня
При выполнении каждого цикла команды процессор, по крайней мере, один раз обращается к памяти, чтобы произвести выборку команды. Соответственно, частота (а значит и производительность), с которой процессор исполняет команды, ограничена временем обращения к памяти. Кэш предназначен для того, чтобы приблизить скорость доступа к памяти к максимально возможной, и в то же время обеспечить большой объем памяти.
Основная память состоит из 2n адресуемых слов, каждое из которых характеризуется своим уникальным n-битовым адресом. Предполагается, что вся память состоит из определенного количества блоков фиксированной длины, в каждый из которых входит K слов. Таким образом, всего имеется M=2n/K блоков. Кэш состоит из C слотов, по K слов в каждом. При этом количество слотов много меньше количества блоков (C<
Ключевые параметры кэш-памяти:
- Размер блока (слота) – до 4 кб (обычно страница памяти)
- Время попадания (hit time) – 1-4 такта
- Потери при промахе (miss penalty) – 8 – 32 тактов
- Доля промахов (miss rate) – 1% - 20%
- Размеры кэш-памяти – 128Кб – 16Мб

Рис. 2.2. Структура кэша и основной памяти
Размещение блоков в кэш
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
- Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapped). Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Таким образом, все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е. (адрес блока кэш-памяти) =(адрес блока основной памяти) mod (число блоков в кэш-памяти)
- Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-way set associative). Для размещения блока, прежде всего, необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом): (адрес множества кэш-памяти) =(адрес блока основной памяти) mod (число множеств в кэш-памяти)
- Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fully associative).
Для поиска соответствующего блока используется сравнение требуемого адреса с дескриптором блока. Если искомый блок найден, то данное слово выбирается из кэша, если нет то происходит процедура замещения блока кэше блоком из памяти с запрошенным адресом.
Как правило для замещения блоков применяются две основных стратегии: случайная и LRU:
- В первом случае, чтобы иметь равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
- Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-Recently Used).
Запись в кэш
При выполнении операции записи ситуация коренным образом меняется. В общем случае это подразумевает выполнение над блоком последовательности операций чтение-модификация-запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тегов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэш-память имеются две базовые возможности:
- сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
- запись с обратным копированием (write back, copy back, store in) - информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
1.f. Подсистема прерываний
Во всех компьютерах предусмотрен механизм, с помощью которого различные устройства (ввода-вывода, памяти) могут прервать нормальную работу процессора.
Различают классы прерываний:
- Программные прерывания (деление на 0, выполнение некорректной команды)
- Прерывания по таймеру
- Прерывания ввода-вывода
- Аппаратное прерывание
1.g. Архитектурные расширения
i. SSE (Streaming SIMD Extension) – в состав команд процессора включены дополнительные регистры и команды для повышения производительности потоковых вычислений, что часто применяется в графических вычислениях.
ii. Векторно-конвейерный процессор – внесена функциональность исполнения векторных команд. Таких команд, для которых операнд считается вектор значений.
iii. Технология Hyper Threading
Проблема неполного использования исполнительных устройств связана с несколькими причинами. Вообще говоря, если процессор не может получать данные с желаемой скоростью (это происходит в результате недостаточной пропускной способности системной шины и шины памяти), то исполнительные устройства будут использоваться не так эффективно. Кроме того, существует ещё одна причина – недостаток параллелизма на уровне инструкций в большинстве потоков выполняемых команд.
В настоящее время большинство производителей улучшают скорость работы процессоров путем увеличения тактовой частоты и размеров кэша. Конечно, таким способом можно увеличить производительность, но все же потенциал процессора не будет полностью задействован. Если бы мы могли одновременно выполнять несколько потоков, то мы смогли бы использовать процессор куда более эффективно. Именно в этом и заключается суть технологии Hyper-Threading.
Hyper-Threading – это название технологии, существовавшей и ранее вне x86 мира, технологии одновременной многопоточности (Simultaneous Multi-Threading, SMT). Идея этой технологии проста. Один физический процессор представляется операционной системе как два логических процессора, и операционная система не видит разницы между одним SMT процессором или двумя обычными процессорами. В обоих случаях операционная система направляет потоки как на двухпроцессорную систему. Далее все вопросы решаются на аппаратном уровне.
В процессоре с Hyper-Threading каждый логический процессор имеет свой собственный набор регистров (включая и отдельный счетчик команд), а чтобы не усложнять технологию, в ней не реализуется одновременное выполнение инструкций выборки/декодирования в двух потоках. То есть такие инструкции выполняются поочередно. Параллельно же выполняются лишь обычные команды.

Рис. 2.3. Hyper-Threading
iv. Технология Hyper Transport
Это первый представитель нового, восьмого поколения процессоров AMD, знаменующего собой эру перехода с 32-разрядных вычислений на 64-разрядные. Процессор Opteron первым в мире обеспечил возможность работы с 64-разрядными ОС и приложениями, одновременно сохраняя высокую производительность при работе с 32-разрядными x86-программами.
Отметим основные особенности Opteron. В архитектуре нового процессора имеются 12-ступенчатый конвейер для целочисленных вычислений и 17-ступенчатый для операций с плавающей точкой. Полностью виртуальное 64-разрядное адресное пространство (52 разряда физической памяти) теоретически позволяет получить доступ к 4,5 Тбайт памяти. Регистры общего назначения имеют разрядность 64 бит. Для кэш-памяти инструкций и данных 1-го уровня (L1) отведено по 64 Кбайт, объем кэш-памяти 2-го уровня (L2) - 1 Мбайт. Встроенный двухканальный контроллер памяти DDR (PC2700), позволяющий обойтись без "северного моста" набора микросхем, работает на частоте процессора и снимает ограничения по пропускной способности, связанные с фронтальной шиной FSB. Три встроенных канала шины HyperTransport обеспечивают совокупную пропускную способность до 19,2 Гбайт/с.
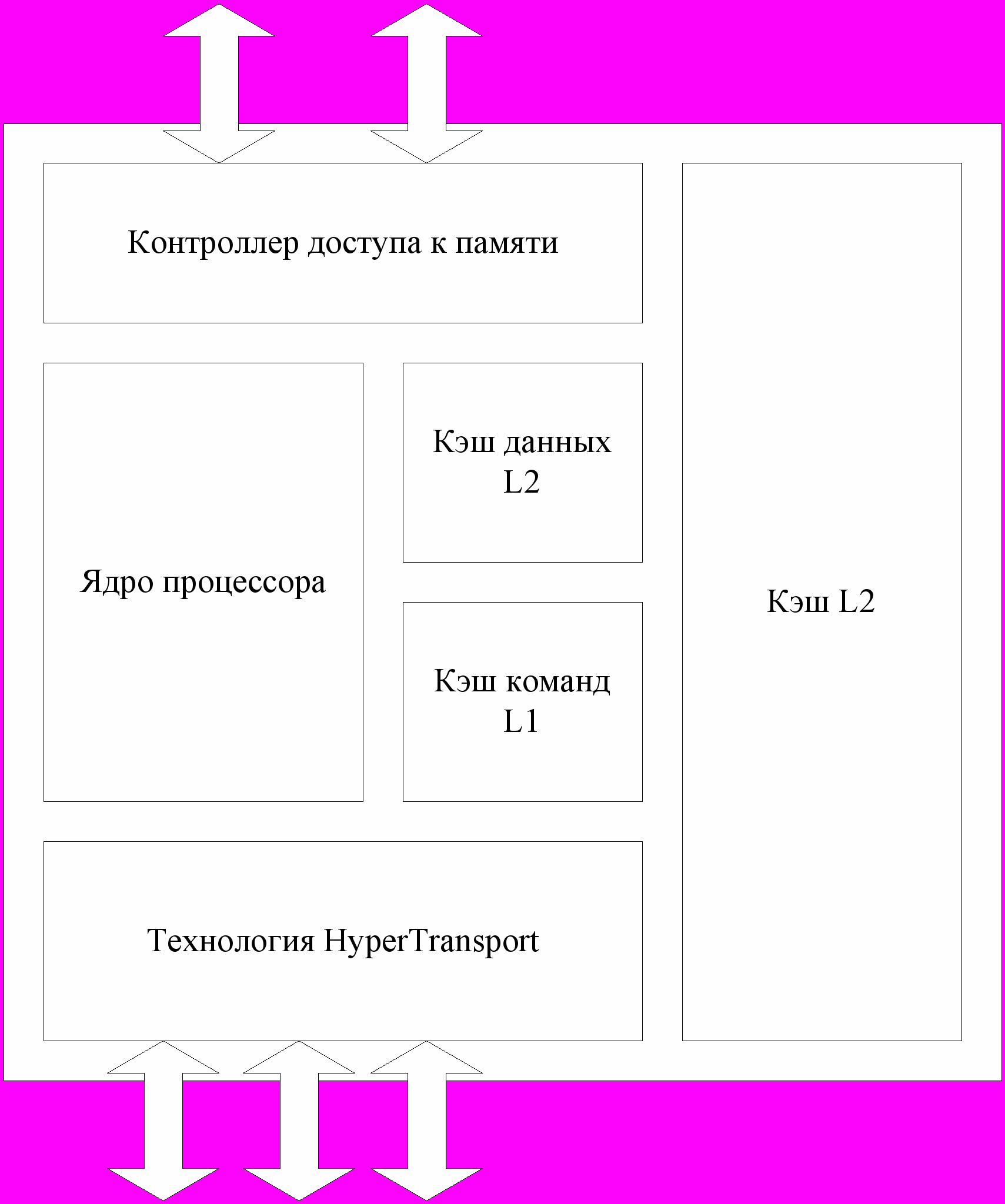
Рис. 2.4. Процессор Opteron
Hyper Transport – отраслевой стандарт связи микросхем (в частности микросхем на материнской плате). Обеспечивает скорость 6.4Гб/с (по сравнению с текущими скоростями 3,2Гб/c).
2. Память
Для достижения высшей производительности память должна иметь возможность быстро обмениваться данными с процессором. Общую память компьютера принято представлять в виде некоторой иерархии запоминающих устройств разной архитектуры (пирамиды);

Рис. 2.5. Иерархия запоминающих устройств
Автономная память – внешние носители
Внешняя память – HDD
Оперативная память – DRAM (Dynamic RAM) => SDRAM => DDR => DDR2
Кэш, регистры – внутренняя память процессора
В этом разделе рассмотрим оперативную память. Различия в современных модулях памяти
Память это массив (выбор по строкам и по столбцам). Сперва чип принимает адрес ряда и затем через несколько наносекунд по той же линии передается адрес колонки. Чип считывает данные и передает их на вывод. При цикле записи данные принимаются чипом вместе с адресом колонки. Для управления чипом используется несколько управляющих линий. RAS (Row Address Strobe) сигналы которыми передается адрес ряда и также активируется весь чип. CAS (Column Address Strobe) сигналы которыми передается адрес колонки. WE (Write Enable) указывающий, что произведенный доступ - это доступ записи. OE (Output Enable) открывает буфера используемые для передачи данных с чипа памяти на "хост" (процессор).
DRAM (Dynamic Random Access Memory) — один из видов компьютерной памяти с произвольным доступом (RAM), наиболее широко используемый в качестве ОЗУ современных компьютеров.
Конструктивно память DRAM состоит из «ячеек» размером в 1 или 4 бит, в каждой из которых можно хранить определённый объём данных. Совокупность «ячеек» такой памяти образуют условный «прямоугольник», состоящий из определённого количества строк и столбцов. Один такой «прямоугольник» называется страницей, а совокупность страниц называется банком. Весь набор «ячеек» условно делится на несколько областей.
SDRAM (Synchronous DRAM) – синхронное управление выборкой из памяти.
В отличие от других типов DRAM, использовавших асинхронный обмен данными, ответ на поступивший в устройство управляющий сигнал возвращается не сразу, а лишь при получении следующего тактового сигнала. Тактовые сигналы позволяют организовать работу SDRAM в виде конечного автомата, исполняющего входящие команды. При этом входящие команды могут поступать в виде непрерывного потока, не дожидаясь, пока будет завершено выполнение предыдущих инструкций (конвейерная обработка): сразу после команды записи может поступить следующая команда, не ожидая, когда данные окажутся записаны. Поступление команды чтения приведёт к тому, что на выходе данные появятся спустя некоторое количество тактов — это время называется задержкой (latency) и является одной из важных характеристик данного типа устройств.
Циклы обновления выполняются сразу для целой строки, в отличие от предыдущих типов DRAM, обновлявших данные по внутреннему счётчику, используя способ обновления по команде CAS перед RAS.