
Ния сложного антропоцентрического объекта создаются и используются ряд текстовых технических документов, в том числе текстовый документ "Логика работы системы…"
| Вид материала | Документы |
- Текстовые редакторы это программы для создания и редактирования текстовых документов, 263.8kb.
- 2. Создание текстовых документов с помощью процессора Microsoft Word, 262.73kb.
- Тема курсовой работы выбирается произвольно и согласовывается с преподавателем во время, 84.79kb.
- Ие и его эффективное использование: системы управления базами данных, персональные, 2781.47kb.
- Определенная форма представления сложного объекта мышления. Является организованностью, 40.36kb.
- Лабораторная работа, 552.43kb.
- Сферы использования текстовых документов, 52.06kb.
- Российской интеллигенции, 1500.84kb.
- Текстовый редактор (назначение и основные функции), 28.71kb.
- Н. Э. Баумана Кафедра Компьютерные системы и сети Г. С. Иванова, Т. Н. Ничушкина Оформление, 109.65kb.
УДК 519.711.2
ПОДХОД К РАЗРАБОТКЕ МЕТОДОВ АВТОМАТИЗИРОВАННОГО КОНТРОЛЯ ИНФОРМАЦИОННОЙ ЦЕЛОСТНОСТИ ТЕХНИЧЕСКИХ ТЕКСТОВ *
О.А.Невзорова1
При системном проектировании бортового алгоритмического и индикационного обеспечения функционирования сложного антропоцентрического объекта создаются и используются ряд текстовых технических документов, в том числе текстовый документ "Логика работы системы…". В статье рассматривается актуальная задача контроля информационной целостности документов типа "Логика…" и методы решения поставленной задачи в системе подготовки и анализа технических текстов "ЛоТА".
Введение
Важной проблемой разработки сложных технических систем является контроль информационной целостности создаваемой проектной документации. Автоматизированное проектирование текстовой технической документации является сложной задачей, удовлетворительного решения которой следует ожидать при наличии естественных (или заданных) ограничений на тип анализируемых текстов и тщательно разработанной модели предметной области. Предметом исследований является класс технических документов, обычно называемых "Логика работы системы" (далее “Логика...”), создаваемых на этапах разработки сложных антропоцентрических систем. Назначение этих документов – в текстовом виде описать, как должна работать проектируемая система во всевозможных (расчетных) условиях ее применения. Документ “Логика...” является основой для разработки спецификаций бортовых алгоритмов и алгоритмов деятельности членов экипажа проектируемого антропоцентрического объекта, т. е. основой для разработки бортового алгоритмического и индикационного обеспечения сложной технической системы.
Разработанные форматы текстовых документов (обязательная рубрикация, общие требования к содержанию рубрик) в практической работе не позволяют создавать "идеальных" документов. Реальный документ по целому комплексу причин (календарных, профессионально-психологических) содержит значительное количество пропусков (“белых пятен”) и противоречий, выявляемых на последующих стадиях разработки. Одной из важнейших проблем является нарушение информационной целостности документа. В идеале, создаваемый документ должен обеспечивать эксплицитное структурированное представление необходимых спецификаций информационных объектов со всеми требуемыми связями. Задача контроля информационной целостности документов типа "Логика…" является главной задачей специализированной компьютерной системы подготовки и анализа технических текстов "ЛоТА" [Невзорова и др., 2001]. В настоящей статье обсуждаются основные подходы и методы решения поставленной задачи.
Структура текстового документа "Логика…"
Разработка сложного технического объекта начинается с создания Заказчиком общего технического задания (ТЗ) на разработку объекта и ТЗ на разработку основных бортовых систем. Данные тексты содержат описания назначения объекта, условий его применения и требуемой эффективности функционирования, описания состава и основных функций экипажа и бортовых систем. Эффективность и множество требуемых функциональных свойств задаются как количественно, так и качественно. Одним из текстов, порождаемых на этом этапе, является текст "Логика…", описывающий логику работы системы "оператор (экипаж) – бортовая аппаратура". Назначение "Логики...":
- разработать функциональные спецификации последовательностей бортовых алгоритмов и алгоритмов деятельности экипажа (АДЭ);
- определить состав информации (протоколы информационного обмена), передаваемой между бортовыми компьютерами, а также между бортовыми компьютерами и бортовыми измерительными и исполнительными устройствами.
Этап проектирования спецификаций алгоритмов системообразующего ядра антропоцентрической системы завершается разработкой схемы бортовых алгоритмов, которая представляет собой последовательность алгоритмов, упорядоченную причинно-следственными связями (рис. 1).

Рис. 1. Схема бортовых алгоритмов
Следует отметить, что спецификации БЦВМ - алгоритмов и АДЭ представляют собой завершенные связанные цепочки, и текст "Логика…" является полным и информационно целостным, если для каждого алгоритма можно проследить состав всей цепочки.
Информационная модель алгоритма включает:
- описание входного информационного потока (типы информационных сигналов или семантическое описание информационного потока с указанием источника информации - конкретный алгоритм, конкретное измерительное устройство);
- описание процессов преобразования входных данных в выходные (допустимый способ разрешения проблемы);
- описание выходного информационного потока (типы информационных сигналов или семантическое описание информационного потока с указанием точки приема информации).
Как правило, в силу различных причин в "Логике…" не удается полностью эксплицировать всю необходимую информацию. В реальной практике в тексте "Логика…" решаются две задачи:
- структурирование процесса функционирования сложного объекта через сеть типовых ситуаций и проблемных субситуаций (ПрС/С) в каждой из них;
- представление описаний каждой ПрС/С через полное множество обобщенных алгоритмов и бортовых алгоритмов.
Методы автоматизированного контроля информационной целостности текста "Логика…" по внешним критериям
Основной задачей системы "ЛоТА" является извлечение из технического текста "Логика…" информационной модели схемы бортовых алгоритмов, решающих определенную задачу в определенной проблемной ситуации, и контроль структурной и информационной целостности выделенной схемы. Решение основной задачи обеспечивается комплексом технологий обработки текстов:
- технологии морфосинтаксического анализа;
- технологии семантико-синтаксического анализа;
- технологии взаимодействия с прикладной онтологией.
Указанная сумма технологий формируется на основе центрального ядра – прикладной онтологии (Авиаонтология), обеспечивающей согласованное взаимодействие различных программных модулей. Авиаонтология концептуально отражает предметную область информационного (алгоритмического) обеспечения различных полетных режимов антропоцентрических систем [Добров и др., 2004]. Авиантология представляет собой иерархическую сеть понятий предметной области, текущий размер онтологии - свыше 1600 понятий (около 5000 текстовых входов понятий). Авиаонтология относится к классу лингвистических (лексических) онтологий и предназначена для встраивания в различные лингвистические приложения.
Архитектура программного комплекса системы "ЛоТА" приведена на рис. 2.
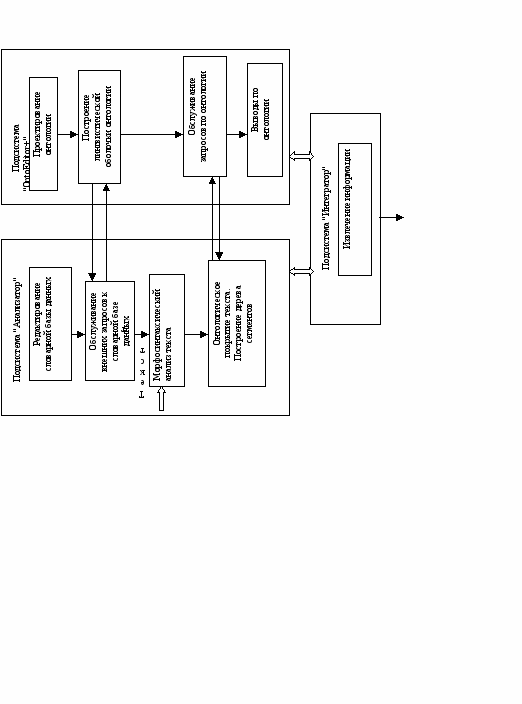
Рис.2. Архитектура программного комплекса "ЛоТА"
Программный комплекс состоит из трех взаимодействующих подсистем: подсистемы лингвистического анализа технических текстов "Анализатор", подсистемы ведения онтологии "OntoEditor+" и подсистемы "Интегратор". Взаимодействие подсистем реализовано на базе технологии "клиент-сервер", причем в различных подзадачах подсистемы выступают в различных режимах (режим сервера или режим клиента).
Инструментальная система визуального проектирования "OntoEditor+" [Невзорова и др., 2004] является специализированной СУБД. Система предназначена для ручного редактирования онтологий, хранящихся в реляционной базе данных в формате TPS, а также обслуживания запросов пользователей и внешних программ. Новые возможности системы обеспечиваются функциональным набором "Лингвистический инструментарий", посредством которого реализуется встраивание прикладной онтологии в лингвистические приложения. Наиболее типичными задачами, решаемыми с помощью инструментария системы "OntoEditor+", являются: изучение структурных свойств прикладной онтологии с помощью исследовательского инструментария системы "OntoEditor+"; построение лингвистической оболочки прикладной онтологии; задача покрытия текста онтологическими входами; построение выводов по прикладной онтологии и др.
Основные функциональные блоки системы "OntoEditor+" (блок настройки, блок проектирования онтологий, блок визуализации, лингвистический инструментарий, интерпретатор команд) имеют соответствующие специализированные наборы функций. Блок проектирования онтологий поддерживает основные табличные функции работы с онтологией (добавление, изменение, удаление записей; автоматическая коррекция записей; ведение нескольких онтологий, в том числе смешанных, т.е. с общими списками типов отношений, классов, синонимов и др.; импорт онтологий различных форматов данных; фильтрация онтологии; ведение автоматической статистики по объектам онтологии; поиск цепочек отношений и др.). Блок визуализации обеспечивает графический режим проектирования онтологии. Система использует развитые механизмы фильтрации при работе в графическом режиме. Блок настройки позволяет задавать различные цветовые и графические образы, используемые для формирования графического образа онтологии, а также другие функциональные настройки. Лингвистический инструментарий реализует функции загрузки корпуса текстов; автоматическое ведение статистики по различным объектам корпуса; функции предсинтаксической обработки текста (сегментация предложений, распознавание аббревиатур, разрешение омонимии на основе специальных протоколов взаимодействия с внешними словарными ресурсами); построение лингвистической оболочки онтологии; распознавание терминов прикладной онтологии во входном тексте (задача покрытия). Интерпретатор команд поддерживает различные типы запросов к онтологии, используя развитые механизмы фильтрации запроса. Система имеет многооконный интерфейс и снабжена развитой системой подсказок, а также механизмами поиска конкретной записи.
Подсистема "Анализатор" реализует основные этапы лингвистической обработки текста (графематический, морфосинтаксический). В подсистеме реализован частичный синтаксический анализ. Результат синтаксического анализа - дерево сегментов определенных типов, причем в основе сегментации лежит процедура распознавания в тексте онтологических входов концептов прикладной онтологии. Задача покрытия текста онтологическими входами решается на основе взаимодействия с подсистемой "OntoEditor+". Лингвистический инструментарий системы "OntoEditor+" позволяет эффективно распознавать в тексте различные лексические формы линейных онтологических входов. Усложненные синтаксические конструкции, в частности, конструкции с однородными членами, распознаются механизмами синтаксического анализа подсистемы "Анализатор" и информация о структуре однородной группы передается на вход подсистемы "OntoEditor+".
В модуле "Извлечение информации" подсистемы "Интегратор" формируется ответ на внешний запрос, в структуре которого выделяется набор взаимосвязанных компонентов. Текущая версия системы связана с анализом и исполнением внешнего запроса, в структуре которого задаются компоненты информационной модели алгоритма. Внешняя форма запроса интерпретируется при взаимодействии с подсистемой "OntoEditor+" как структура, привязанная к прикладной онтологии. Выделение компонент информационной модели происходит на основе механизмов отождествления элементов дерева сегментов входного текста (взаимодействие с подсистемой "Анализатор") и элементов структуры запроса (взаимодействин с подсистемой "OntoEditor+"). Этот процесс поддерживается различными видами онтологического поиска по запросам определенного типа (поиск концепта верхнего уровня, поиск цепочки определенного вида между двумя концептами и др.). Контроль информационной целостности текста по внешним критериям, в роли которых выступает внешний запрос, заключается в идентификации элементов текста, соответствующих элементам внешнего запроса.
Приведем пример анализа фрагмента технического текста на основе разрабатываемых технологий.
Исходный текст:
Алгоритм анализа структуры налёта. На вход алгоритма поступает информация о взаимном расположении самолетов противника (структура его строя). Происходит сравнение со структурой строев, активизированных в БД. По некоторой метрике выбирается структура строя налета, наиболее близкая к наблюдаемой. В соответствии с отождествляемой структурой строя в наблюдаемом строю расставляются приоритеты атаки целей.
Результат анализа текста, отображенный в структуре информационной модели алгоритма (модель передается как внешний запрос к системе):
Имя алгоритма: алгоритм анализа структуры налёта;
Задача алгоритма: анализ структуры налета;
Входная информация для алгоритма: взаимное расположение самолетов противника (структура его строя);
Точка возникновения входной информации:
Вопрос: Откуда поступает информация?
Ответ: Информация отсутствует.
Действие_1: происходит сравнение (произвести сравнение).
Что сравнивается: входная информация (=построен вывод)
С чем сравнивается: со структурой строев, активизированных в БД.
Действие_2: Выбирается структура строя налета, наиболее близкая к наблюдаемому расположению самолетов противника (=построен вывод). Выбирается по некоторой метрике.
Действие_3: расставляются приоритеты атаки целей в наблюдаемом строю. Расставляются в соответствии с отождествляемой структурой строя.
Выходная информация для алгоритма:
1. Структура строя налета наиболее близкая к наблюдаемому расположению самолетов противника.
2. Приоритеты атаки целей в наблюдаемом строю.
Точка приема выходной информации:
Вопрос: Что является приемником информации?
Ответ: Информация отсутствует.
Формирование структуры информационной модели алгоритма поддерживается всем комплексом функциональных возможностей системы: механизмами подсистемы "OntoEditor+" (прежде всего построение покрытия текста онтологическими входами и поддержка выводов по онтологии), механизмами лингвистической обработки подсистемы "Анализатор" (механизмы сегментации текста и интерпретации сегментов текста), а также механизмами построения и контроля исполнения внешнего запроса на извлечение знаний определенной структуры подсистемы "Интегратор". Так, в рассматриваемом примере были построены выводы, позволившие установить для действия_1 объект сравнения (входная информация), а также отождествить синтаксические конструкции наблюдаемая структура строя и взаимное расположение самолетов противника в структуре выходной информации.
Заключение
Предложенный в статье подход к разработке методов контроля информационной целостности текстов по внешним критериям, заданным в форме внешнего запроса к системе, реализуется на основе технологий лингвистической обработки текстов и технологий использования прикладной онтологии в лингвистических приложениях. Центральным звеном является прикладная онтология, обеспечивающая интерпретацию входного текста и внешнего запроса в онтологических терминах. Можно указать ряд проблем, актуальных для текущего состояния исследования: организация эффективной управляющей структуры, позволяющей принимать решения в критических (по ряду параметров) ситуациях анализа; проектирование онтологии мета-уровня, обеспечивающей эффективную трансляцию внешних запросов и взаимодействие с прикладной онтологией по выполнению внешних запросов.
Список литературы
[Добров и др., 2004] Добров Б.В., Лукашевич Н.В., Невзорова О.А., Федунов Б.Е. Методы и средства автоматизированного проектирования прикладной онтологии // Известия РАН. Теория и системы управления.– М.: 2004. № 2. С. 58-68.
[Невзорова и др., 2004] Невзорова О.А., Невзоров В.Н. Система визуального проектирования онтологий "OntoEditor": функциональные возможности и применение //IX национальная конференция по искусственному интеллекту с международным участием КИИ-2004. – М.: Физматлит, 2004. Том 3. С.937-945.
[Невзорова и др., 2001] Система анализа технических текстов "ЛоТА": основные концепции и проектные решения. // Изв. РАН. Теория и системы управления.– 2001. № 3. С. 138-149.
* Работа выполнена при финансовой подержке РФФИ (проект № 05-07-90257)
1 420008, Казань, ул. Кремлевская 18, НИММ им. Н.Г. Чеботарева, ТГГПУ olga.nevzorova@ksu.ru