
Конспект лекций для специальностей 23020165 Информационные системы и технологии, 08080165 Прикладная информатика в экономике Шахты 2011г
| Вид материала | Конспект |
- Учебно-методический комплекс для студентов специальностей 080801 «Прикладная информатика, 455.9kb.
- Рабочая программа по дисциплине "алгоритмизация и программирование" для специальности, 136.39kb.
- Конспект лекций по дисциплине «Информационные системы в экономике», 1286.5kb.
- Конспект лекций по дисциплине «информационные технологии» для студентов направления, 912.74kb.
- Рабочая программа дисциплины: интеллектуальные информационные системы для специальностей:, 369.71kb.
- Методические рекомендации по выполнению курсовых работ по дисциплинам «Моделирование, 276.48kb.
- Методические рекомендации по изучению дисциплины для студентов специальностей 080801, 180.47kb.
- Учебно-методический комплекс по дисциплине "информационные технологии финансового анализа, 108.22kb.
- Рабочая программа по курсу «Мировые информационные ресурсы» 351400 «Прикладная информатика, 315.91kb.
- Магистерская программа «Информационные технологии и информационные системы» по направлению, 34.28kb.
Схема доступа к сегменту через шлюз вызова.
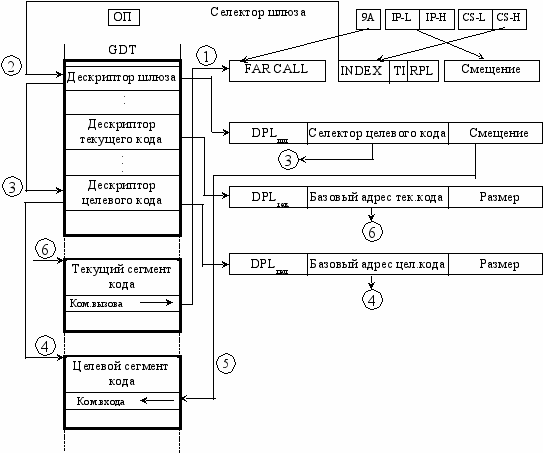
Вызов через шлюз доступен, если
DPLцел.кода (RPL, CPL)max DPLшлюза
Например, если МП выполняет программу с PL2 (CPL=2) и ей нужно вызвать PL0 процедуру (DPLцк=0), то нужно использовать шлюз вызова с DPL=2 или DPL=3. Если DPLцк=CPL, то использовать команду FAR CALL с привлечением шлюза не целесообразно и можно воспользоваться командой FAR JMP, т.к. выполнение команды CALL требует большего числа тактов.
Процесс вызова процедуры через шлюз показан на схеме. Предположим, что в дескрипторной таблице уже сформированы все три дескриптора и в памяти уже находятся кодовые сегменты основной (текущей, вызывающей) и вызываемой программы. Допустим, при выполнении текущей программы встретилась команда с кодом операции 9А, то есть команда дальнего вызова какой-то процедуры (FAR CALL). На схеме это показано стрелкой 1. В соответствии со структурой такой команды следующие два байта (сначала младший байт!) образуют смещение, а последующие два байта - селектор (причем, сначала младший байт!). Пока процессору не ясно, будет ли это прямой дальний вызов или через шлюз (стрелка 2).
Допустим, что анализ вызванного через селектор дескриптора показал, что это системный дескриптор типа шлюза вызова и правила допуска соблюдены. Следовательно, в дескрипторе шлюза находится селектор вызываемого кода (процедуры). Процессор с помощью этого селектора находит в таблице дескриптор сегмента вызываемого (целевого) кода (стрелка 3).
Анализируя дескриптор, процессор определяет базовый адрес сегмента вызываемой процедуры и находит в памяти сам сегмент (стрелка 4). Однако, первая выполняемая команда не обязана находиться в начале сегмента. Ее смещение указано в дескрипторе шлюза вызова. В соответствии с этим значением процессор находит первую команду и запускает процедуру (стрелка 5).
ЛЕКЦИЯ 9
Обработка прерываний
Механизм обработки прерываний в защищенном режиме сильно отличается от механизма реального режима.
В защищенном режиме все прерывания разделяются на два типа - обычные и особые (exeption - исключение). Обычное прерывание инициируется, в основном, внешним событием (аппаратное прерывание). Перед передачей управления процедуре обработки обычного прерывания флаг разрешения прерывания IF сбрасывается и прерывания запрещаются.
Особое прерывание происходит в результате ошибки, возникающей при выполнении какой-либо команды, например, если команда пытается выполнить запись данных за пределами сегмента данных или использует для адресации селектор, не определенный в таблице дескрипторов. Когда процедура обработки исключения получает управление, флаг IF н е и з м е н я е т с я. Поэтому в мультизадачной среде особые случаи, возникающие в отдельных задачах, не оказывают влияние на выполнение остальных задач. По этой же причине обработчики исключений не препятствуют аппаратным прерываниям.
Что касается прерываний, инициируемых командой INT n (программное прерывание), то их обработчики могут запускаться как обычные или особые в зависимости от нужной реакции на флаг IF.
В защищенном режиме прерывания могут приводить к переключению задач. Однако этот процесс требует специального рассмотрения.
Таблица прерываний защишенного режима является дескрипторной таблицей прерываний IDT. Как и таблицы GDT и LDT, таблица IDT содержит 8-байтовые дескрипторы. Дескрипторы IDT - это системные дескрипторы, рассмотренные ранее: шлюзы (вентили) прерываний, исключений и задач. В дальнейшем следует иметь в виду, что в ряде литературных источников вентили называются шлюзами, а байты атрибутов в дескрипторах называются полем доступа. Поле TYPE в дескрипторе шлюза прерывания содержит значение 6, шлюза исключения - значение 7, шлюза задачи - 5.
Расположение IDT в оперативной памяти определяется содержимым внутреннего регистра процессора IDTR. Формат регистра IDTR полностью аналогичен формату регистра GDTR. Загрузка IDTR осуществляется командой LIDT. Регистр IDTR обычно загружают перед переходом в защищенный режим.
Исключения в защищенном режиме. Причины, по которым возникают особые прерывания, подразделяют на три группы. Это необходимо учитывать при разработке обработчиков прерывания.
НАРУШЕНИЕ (fault) - это такой особый случай, который процессор может обнаружить до возникновения фактической ошибки (например, нарушение правил привилегий или предела сегмента). Это - устранимая ошибка. Поэтому после работы обработчика прерывания программа может быть продолжена (рестарт) с "виноватой" команды.
ЛОВУШКА (trap) - это такой особый случай, который обнаруживается после выполнения виноватой команды. После его обработки процессор возобновляет действия с той команды, которая находится после "захваченной" команды. Типичным примером ловушки является команда прерывания при переполнении и команда INT n. Кроме того, большинство отладочных контрольных точек также интерпретируются как ловушки. По этой причине часто дескриптор обработчика исключительного случая называют "дескриптором ловушки".
АВАРИЯ (abort) - представляет столь серьезную ошибку, что продолжение программы невозможно. К авариям относятся аппаратные ошибки, а также несовместимые или недопустимые значения в системных таблицах.
Перед тем, как передать управление обработчику исключения, для многих зарезервированных прерываний процессор последним помещает в стек программы обработчика 16-битовый код ошибки. Этот код может быть использован в обрабатывающей программе.
Формат кода ошибки
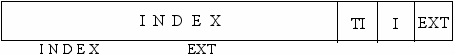
15 3 2 1 0
Поле INDEX содержит индекс дескриптора того сегмента, при обращении к которому произошла ошибка. Поле I, равное 1, означает, что индекс относится к таблице IDT. В этом случае произошла ошибка при обработке прерывания или исключения. Если бит I равен нулю, то поле TI выбирает таблицу дескрипторов (GDT или LDT) по аналогии с соответствующим полем селектора.
Бит EXT устанавливается в 1 в том случае, когда ошибка произошла не в результате выполнения текущей команды, а по внешним относительно выполняемой программы причинам. Например, при обработке аппаратного прерывания от устройства ввода/вывода произошло обращение к отсутствующему в памяти сегменту ( у которого в дескрипторе сброшен бит присутствия Р).
Обработка аппаратных прерываний
Как было указано, для обработки прерываний IRQ0 - IRQ7 в реальном режиме используются номера прерываний от 08h до 0Fh, а для IRQ8 - IRQ15 - от 70h до 77h.Но в защищенном режиме номера от 08h до 0Fh зарезервированы для обработки исключений. Поэтому перед переключением процессора в защищенный режим необходимо перепрограммировать контроллер прерываний. Например, аппаратные прерывания можно расположить сразу за исключениями.
После возврата процессора в реальный режим необходимо восстановить состояние контроллера прерываний. Если при подготовке к возврату в реальный режим в CMOS-память был записан байт состояния отключения со значением 5, то после сброса BIOS сам перепрограммирует контроллер прерывания для работы в реальном режиме.
- Особенности обработки прерываний
Как было отмечено выше, обработка прерывания ведется через шлюзы. В дескрипторах шлюзов всех трех типов, содержащихся в таблице IDT, имеется поле уровня привилегий DPL. Оно определяет минимальный уровень привилегий, который необходим для использования шлюза. Рекомендуется задавать значение DPL шлюза, равное 3, чтобы обработка особых случаев не зависела от уровня привилегий текущей задачи.
Для шлюзов ловушек и прерываний процессор непосредственно перед началом выполнения обработчика производит еще один контроль привилегий. Обработчику не разрешается работать на уровне привилегий, который ниже уровня привилегий прерываемой задачи (если, конечно, он не является отдельной задачей). Из-за непредсказуемости прерываний и особых случаев требуется гарантировать невозможность нарушения правил защиты по привилегиям. Этого можно достичь, в частности, если обработчики размещать в сегментах кода с уровнем привилегий 0; такие обработчики будут действовать всегда, не зависимо от значения CPL программы;
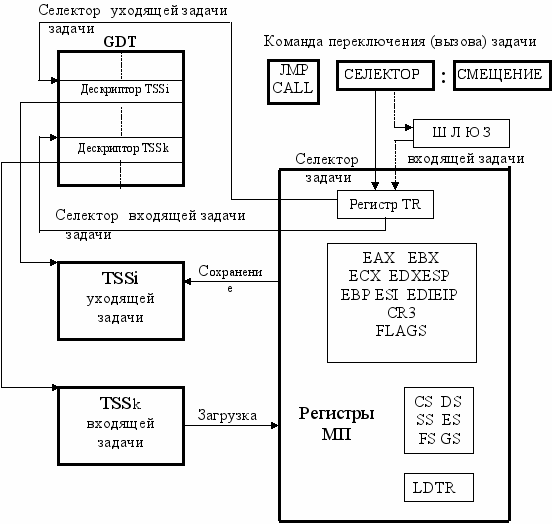
Процесс вызова обработчика прерывания показан на схеме ниже. Предположим, что в дескрипторных таблицах IGT и GDT уже сформированы все три дескриптора и в памяти уже находятся кодовые сегменты основной (текущей, вызывающей прерывание) и вызываемой программы (обработчика прерывания). Допустим, при выполнении текущей программы встретилась команда с кодом CD0D, то есть команда вызова прерывания (JMP 0Dh). На схеме это показано стрелкой 1.
Команды запуска обработчика прерывания используют дескрипторы, расположенные в дескрипторной таблице прерываний IDT. В соответствии с номером прерывания в команде процессор отыскивает нужный дескриптор (стрелка 2). В нем указывается селектор для поиска сегмента с обработчиком и смещение адреса пусковой команды обработчика 0Dh в этом сегменте. Процессор анализирует селектор и определяет, что его дескриптор находится в глобальной дескрипторной таблице GDT (стрелка 3). С помощью этого селектора процессор находит дескриптор кодового сегмента, где размещается обработчик. В этом дескрипторе указывается базовый адрес сегмента (стрелка 4). Однако, первая выполняемая команда не обязана находиться в начале сегмента. Это особенно важно в связи с тем, что в
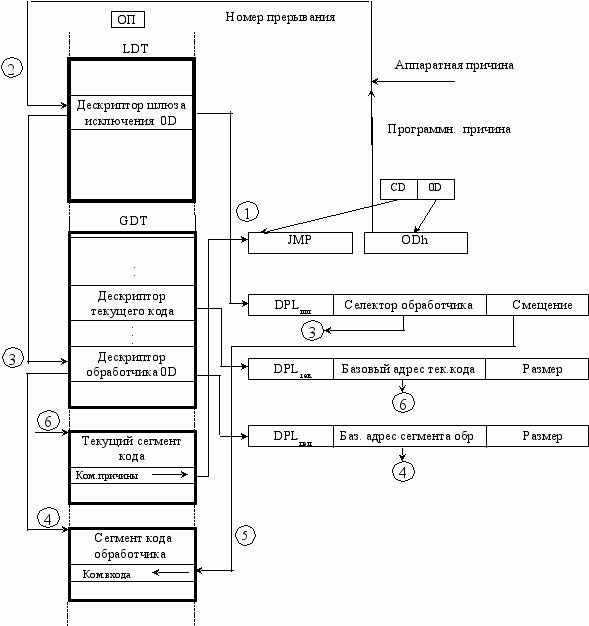
сегменте может быть размещено несколько обработчиков и даже в конкретном обработчике может быть несколько точек входа. Ее смещение указано в IDT в дескрипторе шлюза вызова обработчика. В соответствии с этим значением процессор находит первую команду и запускает обработчик прерывания 0Dh (стрелка 5).
В приведенной схеме информационных потоков показан случай, когда причиной запуска обработчика прерывания стала специальная команда типа INT. В реальности основной причиной прерывания являются сигналы аппаратной части процессора. В частности, если при выполнении “обычных” команд произойдет нарушение границы сегмента, то процессор аппаратно сформирует вектор 0Dh и запустит процесс прерывания. Если процессор или периферийная аппаратура сформировали вектор прерывания 0Dh, то будет запущен тот же обработчик прерывания, что и командой Int 0Dh. Команды Int Nh применяются при отладке и других необходимых действиях.
Многозадачность.
1. Варианты переключения задач.
Задача - это самостоятельная программа, которая обладает своим виртуальным пространством и состоянием и которой назначен сегмент TSS. На практике используются термины : программа пользователя, задание, окно программы на экране дисплея.
Для управления многозадачностью в МП нет специальных команд. Вместо этого он иначе интерпретирует обычные команды межсегментной передачи управления - переходы и вызовы. Задача также может активизироваться прерыванием и особым случаем. Управление передается через дескрипторные таблицы.
Используются два типа дескрипторов: дескриптор сегмента состояния задачи TSS и дескриптор шлюза задачи. Для большей защиты новой задачи она может использовать свою LDT.
Переключение задач похоже на вызов процедуры, но сохраняется о предыдущей среде значительно больше информации -TSS. Для переключения задач используются их следующие структуры: TSS, дескрипторы TSS, TR и дескрипторы шлюза задачи. Время переключения задач значительно больше времени переключения процедур, поэтому оформление программ в виде задач не всегда оправдано. Однако, если программа одиночна, но использует переключение уровней, то для нее нужно сформировать TSS.
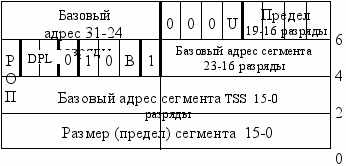
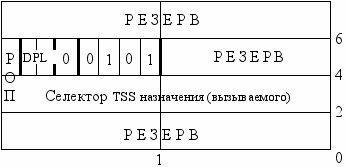
Сопоставим форматы дескрипторов TSS и шлюза задачи.
Формат дескриптора сегмента TSS
1
Здесь В - признак занятости (активности) задачи.
Дескриптор TSS может находиться только в GDT. Поле DPL дескриптора не означает уровень привилегий самого сегмента TSS, т.к. к нему не могут обращаться никакие задачи, а только аппаратно сам МП. DPL показывает, какие программы могут обращаться к задаче, определяемой данным дескриптором TSS. Изменять или читать дескриптор TSS можно только применяя дескриптор данных, отображенный на ту же область памяти, что и дескриптор TSS. Так как обращение к дескриптору TSS может вызвать переключение задачи, то часто полагают DPL равным 0. Поэтому переключение задачи могут вызвать только привилегированные программы ( с PL0 ).
Дескриптор шлюза задачи МП 2(3,4)86
Принципиальной разницы между переключением задач через шлюз задачи и дескриптор TSS нет. Функция шлюза задачи аналогична функции шлюза вызова - косвенный доступ к задаче. Для данного дескриптора TSS можно определить несколько шлюзов, разместить их в GDT, LDT и назначить более низкие привилегии. При этом сохраняется доступ к дескриптору TSS для PL0-программ, которые могут прямо обращаться к нему в GDT. Дескрипторы шлюзов задач могут находиться также в IDT. Обращение к TSS возможно только через его дескриптор. Процедура с доступом к шлюзу задачи может вызвать переключение задачи также, как и процедура с доступом к TSS.
Отсюда следует, что переключение задачи может вызвать:
- выходящая задача, если она выполняет команду FAR CALL или FAR JMP и ее селектор выбирает шлюз задачи, а в нем указан селектор TSS ( косвенное переключение задачи);
- выходящая задача, если она выполняет команду FAR CALL или FAR JMP и ее селектор выбирает дескриптор TSS (прямое переключение задачи );
- выходящая задача, если она выполняет команду IRET для возврата в предыдущую задачу и в регистре флагов бит NT ( вложенной задачи ) равен 1;
- аппаратное или программное прерывание, если соответствующий элемент таблицы IDT содержит шлюз задачи.
Таким образом, МП различает обычное использование указанных команд от команд переключения задач в зависимости от типа дескриптора в байте атрибутов AR и флага NT. Кроме того, переключение задач через FAR
CALL обеспечивает их вложение и возврат по типу процедур, а вызов через FAR JMP не приведет к вложению задач.
2. Этапы переключения задачи.
Переключение задач проходит следующие этапы.
1. Проверка у JMP и CALL права доступа к задаче:
DPL => max( CPL, RPL )
Здесь DPL - уровень привилегий программ, которые могут обращаться к задаче, и указываемый в дескрипторе шлюза задачи (или в дескрипторе TSS);
CPL - текущий уровень привилегий сегмента CS;
RPL - уровень привилегий в селекторе команд JMP (CALL), то есть уровень прав претендента на задачу.
2. Проверка у обоих дескрипторов бита присутствия (Р=1).
3. Сохранение состояния текущей задачи в ее TSS (базовый адрес текущего TSS находится в теневой части TR ).
4. Загрузка в TR селектора новой задачи, установка бита занятости Р в дескрипторе TSS и бита переключения задачи TS в регистре CR0 ( MSW у МП286 ). Селектор TSS является либо операндом команды JMP или CALL, либо берется из шлюза задачи (операндом команд тогда является селектор шлюза). Если TI селектора = 0, то его дескриптор находится в GDT, иначе в LDT. У первого прочитанного дескриптора анализируется поле "Тип" и по его значению определяется, является ли он дескриптором TSS или дескриптором шлюза. В первом случае происходит прямой доступ к TSS, во втором - дескриптор TSS отыскивается как сегмент с процедурой через шлюз вызова.
5. Загрузка состояния новой задачи из ее TSS и выполнение.
Необходимо помнить, что изменять содержимое дескрипторных таблиц прямой пересылкой операнда в поле таблиц нельзя - сработает защита памяти. Для этого надо создать псевдоним ( алиас ) таблиц, т.е. такой сегмент данных, который по базовому адресу и пределу совпадает с сегментом таблицы. Изменение в псевдониме автоматически отражается в таблице.
При использовании команды JMP для переключения задач она же используется и для возврата, указав в качестве операнда логический адрес TSS первой задачи.
Команда CALL позволяет организовать вызов вложенных задач. Для возврата в предыдущую задачу используют команду IRET. Адрес TSS для возврата команда IRET берет из поля обратной связи в TSS, куда он был записан командой CALL при первом переключении задач. Кроме того, следует учитывать, что вызов задачи через CALL приводит к установке в 1 бита NT - вложенной задачи, а использование JMP - к его сбросу.
Возможность переключения задач по прерыванию появляется, если шлюз задачи поместить в дескрипторную таблицу прерываний IDT. Например, можно сделать отдельные задачи для обработки исключений или аппаратных прерываний. В последнем случае обработчикам аппаратных прерываний не нужно использовать стек прикладных задач, так как они будут иметь свой собственный стек.
В заключение для наглядности приведем схему переключения задач.
ЛЕКЦИЯ 10
Иерархия памяти ЭВМ
Внутренняя память расположена на основной плате ЭВМ, там, где располагается ее процессор. Сюда входит переменная память, содержимое которой может изменяться в процессе работы ЭВМ. Она состоит из следующих видов:
ОП – основная память,
СОП – сверхоперативная (регистровая) память,
СТЕК - небольшая память для временного хранения данных,
КЭШ – очень быстрая память небольшого объема, в которой автоматически (аппаратно) накапливаются последние использованные данные.

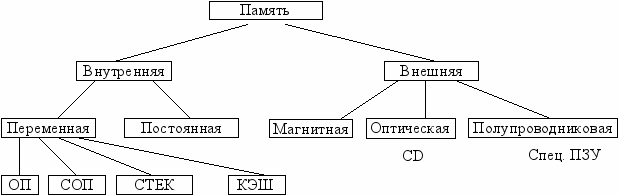
Постоянная внутренняя память - это обычно небольшого объема память, содержимое которой не изменяется в процессе работы ЭВМ (постоянное запоминающее устройство - ПЗУ). Ее содержимое записывается на заводе-изготовителе и определяет функции ЭВМ в момент включения. Она управляет многими операциями ввода-вывода, поэтому называется Базовой Системой Ввода Вывода (BIOS).
Внешняя память реализуется на различных физических принципах. Наиболее распространены магнитные и оптические носители информации - диски. На них могут размещаться большие объемы информации, измеряемые гигабайтами. Они могут работать как в режиме чтения ранее записанной информации, так и в режиме записи новой информации. Перспективной является полупроводниковая сменная память – флеш память.
Рассмотрим особенности стековой и кэш памяти. Стековая память работает по типу монетника: прочитать можно только ту информацию, которая была записана последней. Этот принцип называют LIFO : последним вошел - первым вышел. У стековой памяти имеется один общий вход-выход. При чтении данных из стека занятая ими ячейка освобождается. Для обмена со стеком в программе используются специальные команды. Стековая память применяется при работе с подпрограммами. При последовательном запуске подпрограмм возврат будет из той, которая была запущена последней. В стеке сохраняются адреса возврата и другие необходимые данные.
 Число ячеек в этой памяти ограничено, поэтому возможно ее переполнение, если последовательно выполнять запись большее число раз. Для стековой памяти обычно "арендуется" участок основной (оперативной) памяти, хотя, в принципе, возможна ее реализация на физически отдельной памяти. На рисунке справа показана структурная схема стековой памяти.
Число ячеек в этой памяти ограничено, поэтому возможно ее переполнение, если последовательно выполнять запись большее число раз. Для стековой памяти обычно "арендуется" участок основной (оперативной) памяти, хотя, в принципе, возможна ее реализация на физически отдельной памяти. На рисунке справа показана структурная схема стековой памяти.КЭШ-память является кошельком основной памяти, которым удается удобно и быстро пользоваться при текущих расчетах. КЭШ выполняют на микросхемах памяти статического типа с высоким быстродействием по сравнению с основной памятью, которая выполняется на элементах динамического типа с регенерацией. Это память магазинного типа, у которой имеется отдельный вход и отдельный выход. Объем памяти ограничен. Однако переполнения не наступает, так как память покидает та запись, которая была сделана первой. Такой принцип обмена называется FIFO - первым вошел, первым покидаешь. Это позволяет сохранять в КЭШ-памяти самые свежие данные. На рисунке справа показана структурная схема КЭШ-памяти и ее взаимодействие с основной памятью. ИШП - обозначает информационная шина процессора, к которой подключается ОП.
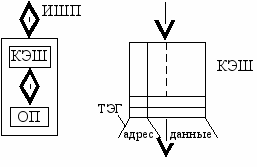 КЭШ является прозрачной (невидимой) для программы памятью. Операции с ней выполняются автоматически, поэтому не существует команд обмена с ней. Таким образом, в КЭШ-памяти дублируется часть ячеек ОП. Ячейка КЭШ-памяти имеет две составляющие: данное и адрес ячейки ОП, в которой хранится это данное. Адресная часть ячейки КЭШ-памяти называется ТЭГом.
КЭШ является прозрачной (невидимой) для программы памятью. Операции с ней выполняются автоматически, поэтому не существует команд обмена с ней. Таким образом, в КЭШ-памяти дублируется часть ячеек ОП. Ячейка КЭШ-памяти имеет две составляющие: данное и адрес ячейки ОП, в которой хранится это данное. Адресная часть ячейки КЭШ-памяти называется ТЭГом. Машина будет работать, если КЭШ вытащить из разъема, но медленнее.
Кэш-память
Кэш-память представляет собой быстродействующее ЗУ, размещенное на одном кристалле с ЦП или внешнее по отношению к ЦП. Кэш служит высокоскоростным буфером между ЦП и относительно медленной основной памятью. Идея кэш-памяти основана на прогнозировании наиболее вероятных обращений ЦП к оперативной памяти. В основу такого подхода положен принцип временной и пространственной локальности программы.
Если ЦП обратился к какому-либо объекту оперативной памяти, с высокой долей вероятности ЦП вскоре снова обратится к этому объекту. Примером этой ситуации может быть код или данные в циклах. Эта концепция описывается принципом временной локальности, в соответствии с которым часто используемые объекты оперативной памяти должны быть "ближе" к ЦП (в кэше).
Для согласования содержимого кэш-памяти и оперативной памяти используют три метода записи:
- Сквозная запись (write through) - одновременно с кэш-памятью обновляется оперативная память.
- Буферизованная сквозная запись (buffered write through) - информация задерживается в кэш-буфере перед записью в оперативную память и переписывается в оперативную память в те циклы, когда ЦП к ней не обращается.
- Обратная запись (write back) - используется бит изменения в поле тега, и строка переписывается в оперативную память только в том случае, если бит изменения равен 1.
Как правило, все методы записи, кроме сквозной, позволяют для увеличения производительности откладывать и группировать операции записи в оперативную память.
В структуре кэш-памяти выделяют два типа блоков данных:
- память отображения данных (собственно сами данные, дублированные из оперативной памяти);
- память тегов (признаки, указывающие на расположение кэшированных данных в оперативной памяти).
Пространство памяти отображения данных в кэше разбивается на строки - блоки фиксированной длины (например, 32, 64 или 128 байт). Каждая строка кэша может содержать непрерывный выровненный блок байт из оперативной памяти. Какой именно блок оперативной памяти отображен на данную строку кэша, определяется тегом строки и алгоритмом отображения. По алгоритмам отображения оперативной памяти в кэш выделяют три типа кэш-памяти:
- полностью ассоциативный кэш;
- кэш прямого отображения;
- множественный ассоциативный кэш.
Для полностью ассоциативного кэша характерно, что кэш-контроллер может поместить любой блок оперативной памяти в любую строку кэш-памяти (рис. 9.1). В этом случае физический адрес разбивается на две части: смещение в блоке (строке кэша) и номер блока. При помещении блока в кэш номер блока сохраняется в теге соответствующей строки. Когда ЦП обращается к кэшу за необходимым блоком, кэш-промах будет обнаружен только после сравнения тегов всех строк с номером блока.
Одно из основных достоинств данного способа отображения - хорошая утилизация оперативной памяти, т.к. нет ограничений на то, какой блок может быть отображен на ту или иную строку кэш-памяти. К недостаткам следует отнести сложную аппаратную реализацию этого способа, требующую большого количества схемотехники (в основном компараторов), что приводит к увеличению времени доступа к такому кэшу и увеличению его стоимости.
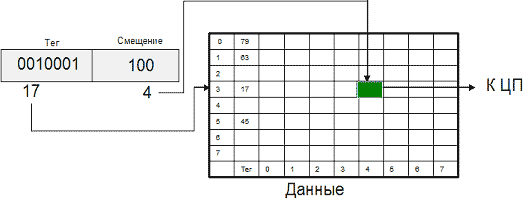 Рис. 9.1. Полностью ассоциативный кэш 8х8 для 10-битного адреса
Рис. 9.1. Полностью ассоциативный кэш 8х8 для 10-битного адресаАльтернативный способ отображения оперативной памяти в кэш - это кэш прямого отображения (или одновходовый ассоциативный кэш). В этом случае адрес памяти (номер блока) однозначно определяет строку кэша, в которую будет помещен данный блок. Физический адрес разбивается на три части: смещение в блоке (строке кэша), номер строки кэша и тег. Тот или иной блок будет всегда помещаться в строго определенную строку кэша, при необходимости заменяя собой хранящийся там другой блок. Когда ЦП обращается к кэшу за необходимым блоком, для определения удачного обращения или кэш-промаха достаточно проверить тег лишь одной строки.
Очевидными преимуществами данного алгоритма являются простота и дешевизна реализации. К недостаткам следует отнести низкую эффективность такого кэша из-за вероятных частых перезагрузок строк. Например, при обращении к каждой 64-й ячейке памяти в системе на рис. 9.2 кэш-контроллер будет вынужден постоянно перегружать одну и ту же строку кэш-памяти, совершенно не задействовав остальные.
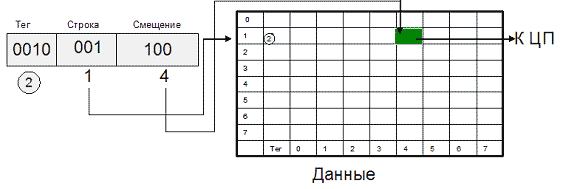 Рис. 9.2. Кэш прямого отображения 8х8 для 10-битного адреса
Рис. 9.2. Кэш прямого отображения 8х8 для 10-битного адресаНесмотря на очевидные недостатки, данная технология нашла успешное применение, например, в МП Motorola MC68020, для организации кэша инструкций первого уровня (рис. 9.3). В данном микропроцессоре реализован кэш прямого отображения из 64 строк по 4 байт. Тег строки, кроме 24 бит, задающих адрес кэшированного блока, содержит бит значимости, определяющий действительность строки (если бит значимости 0, данная строка считается недействительной и не вызовет кэш-попадания). Обращения к данным не кэшируются.
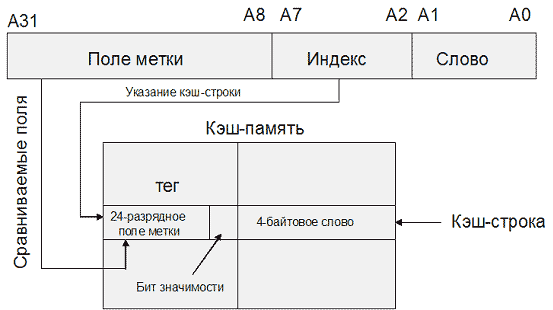 Рис. 9.3. Схема организации кэш-памяти в МП Motorola MC68020
Рис. 9.3. Схема организации кэш-памяти в МП Motorola MC68020Компромиссным вариантом между первыми двумя алгоритмами является множественный ассоциативный кэш или частично-ассоциативный кэш (рис. 9.4). При этом способе организации кэш-памяти строки объединяются в группы, в которые могут входить 2, 4, : строк. В соответствии с количеством строк в таких группах различают 2-входовый, 4-входовый и т.п. ассоциативный кэш. При обращении к памяти физический адрес разбивается на три части: смещение в блоке (строке кэша), номер группы (набора) и тег. Блок памяти, адрес которого соответствует определенной группе, может быть размещен в любой строке этой группы, и в теге строки размещается соответствующее значение. Очевидно, что в рамках выбранной группы соблюдается принцип ассоциативности. С другой стороны, тот или иной блок может попасть только в строго определенную группу, что перекликается с принципом организации кэша прямого отображения. Для того чтобы процессор смог идентифицировать кэш-промах, ему надо будет проверить теги лишь одной группы (2/4/8/: строк).
 Рис. 9.4. Двухвходовый ассоциативный кэш 8х8 для 10-битного адреса
Рис. 9.4. Двухвходовый ассоциативный кэш 8х8 для 10-битного адресаДанный алгоритм отображения сочетает достоинства как полностью ассоциативного кэша (хорошая утилизация памяти, высокая скорость), так и кэша прямого доступа (простота и дешевизна), лишь незначительно уступая по этим характеристикам исходным алгоритмам. Именно поэтому множественный ассоциативный кэш наиболее широко распространен
ЛЕКЦИЯ 11
Оперативная память
1) Общие сведения об оперативной памяти.
2) Теоретические основы устройства современной оперативной памяти:
а) SDRAM: определение.
б) Физическая организация и принцип работы.
в) Логическая организация.
г) Организация модуля.
д) Тайминги памяти
3) Отличия SDR от DDR и DDR2.
4) Способы повышения производительности
Общие сведения об оперативной памяти.
Назначение, основные характеристики.
Оперативная память является одним из важнейших элементов компьютера. Именно из нее процессор берет программы и исходные данные для обработки, в нее он записывает полученные результаты. Название “оперативная” эта память получила потому, что она работает очень быстро, так что процессору практически не приходится ждать при чтении данных из памяти или записи в память. Однако содержащиеся в ней данные сохраняются только пока компьютер включен. При выключении компьютера содержимое оперативной памяти стирается. Часто для оперативной памяти используют обозначение RAM (Random Access Memory, то есть память с произвольным доступом) .
Основными выходными характеристиками оперативной памяти(теми, на которые мы обращаем внимание при ее покупке) являются:
Объем – максимально возможное количество данных, которое один модуль способен хранить в себе в данный момент времени.
Пропускная способность – максимальная скорость передачи данных между памятью и шиной. Измеряется в битах на секунду.
Теоретические основы современной оперативной памяти
SDRAM: Определение
Аббревиатура SDRAM расшифровывается как Synchronous Dynamic Random Access Memory — синхронная динамическая память с произвольным доступом. Остановимся подробнее на каждом из этих определений. Под «синхронностью» обычно понимается строгая привязка управляющих сигналов и временных диаграмм функционирования памяти к частоте системной шины в асинхронной DRAM.
Понятие «динамической» памяти, DRAM, относится ко всем типам оперативной памяти, начиная с самой древней, «обычной» асинхронной динамической памяти и заканчивая современной DDR2. Этот термин вводится в противоположность понятия «статической» памяти (SRAM) и означает, что содержимое каждой ячейки памяти периодически необходимо обновлять (ввиду особенности ее конструкции, продиктованной экономическими соображениями).
Наконец, стоит также упомянуть о «памяти с произвольным доступом» — Random Access Memory, RAM. Данная аббревиатура подразумевает, что операции чтения и записи могут осуществляться в произвольном порядке(в противовес более ранним системам, где операции «чтение» и «память» были строго очередны).
Микросхемы SDRAM:
Физическая организация и принцип работы
SDRAM производится на основе стандартной DRAM и работает также, как стандартная DRAM - осуществляя доступ с строкам и колонкам ячеек данных. Только SDRAM объединяет свои специфичные свойства синхронного функционирования банков ячеек, и пакетной работы, для эффективного устранения состояний задержек-ожидания. Когда процессору необходимо получить данные из оперативной памяти, он может получить их в требуемый момент. Таким образом, фактическое время обработки данных непосредственно не изменилось, в отличии от увеличения эффективности выборки и передачи данных. Для того, чтобы понять как SDRAM ускоряет процесс выборки и поиска данных в памяти, представьте себе, что центральный процессор имеет посыльного, который возит тележку по зданию оперативной памяти, и каждый раз ему нужно бросать или подбирать информацию. В здании оперативной памяти клерк, отвечающий за пересылку/получение информации, обычно тратит около 60ns, чтобы обработать запрос. Посыльный знает только, сколько требуется времени, чтобы обработать запрос, после того, как он получен. Но он не знает будет ли готов клерк, когда он приедет к нему, так что обычно он отводит немного времени на случай ошибки. Он ждет, пока клерк не будет готов получить запрос. Затем он ожидает обычное время, требующееся для обработки запроса. А затем, он задерживается, чтобы проверить, что запрошенные данные загружены в его тележку, прежде, чем отвезти тележку с данными обратно центральному процессору. Предположим, с другой стороны, что каждые 10 наносекунд пресылающий клерк в здании оперативной памяти должны быть снаружи и готовым получить другой запрос или ответить на запрос, который был получен ранее. Это делает процесс более эффективным, поскольку посыльный может прибыть именно в нужное время. Обработка запроса начинается в момент его получени. Информация посылается в CPU, когда она готова.
Схема обращения к ячейке памяти в самом общем случае может быть представлена следующим образом:
1. На адресные линии микросхемы памяти подается адрес строки. Наряду с этим подается сигнал RAS#, который помещает адрес в буфер (защелку) адреса строки.
2. После стабилизации сигнала RAS#, декодер адреса строки выбирает нужную строку, и ее содержимое перемещается в усилитель уровня (при этом логическое состояние строки массива инвертируется).
3. На адресные линии микросхемы памяти подается адрес столбца вместе с подачей сигнала CAS#, помещающего адрес в буфер (защелку) адреса столбца.
4. Поскольку сигнал CAS# также служит сигналом вывода данных, по мере его стабилизации усилитель уровня отправляет выбранные (соответствующие адресу столбца) данные в буфер вывода.
5. Сигналы CAS# и RAS# последовательно дезактивируются, что позволяет возобновить цикл доступа (по прошествии промежутка времени, в течение которого данные из усилителя уровня возвращаются обратно в массив ячеек строки, восстанавливая его прежнее логическое состояние).
Тайминги памяти
Немаловажной категорией характеристик микросхем/модулей памяти являются «тайминги памяти» — понятие, наверняка так или иначе знакомое каждому пользователю ПК. Понятие «таймингов» тесно связано с задержками, возникающими при любых операциях с содержимым ячеек памяти в связи со вполне конечной скоростью функционирования устройств SDRAM, как и любых других интегральных схем. Задержки, возникающие при доступе в память, также принято называть «латентностью» памяти (этот термин не совсем корректен, и пришел в обиход с буквальным переводом термина latency, означающего «задержка»).
tCL Задержка между подачей команды READ и подачей на шину первой порции данных.
(данные, считанные из усилителя уровня, синхронизируются и передаются на внешние выводы микросхемы)
tRCD Задержка между подачей адреса строки и столбца (активация строки требует определенного времени, вследствие чего столбец не может быть активирован на следующем такте).
tRP Минимальный промежуток между подзарядкой строки и следующей активацией. Связан с тем, что подзарядка сама по себе требует некоторого времени.
tRAS минимальный период активности строки.
ЛЕКЦИЯ 12
Интерфейсы периферийных устройств
В данной лекции рассматриваются универсальные периферийные интерфейсы для подключения внешних устройств к персональному компьютеру.
Цель: познакомить учащихся с примерами организации взаимодействия ПК и периферийных устройств, а также обозначить основные тенденции развития интерфейсов вычислительных систем.
Интерфейс RS-232C
Стандарт на последовательный интерфейс RS-232C был опубликован в 1969 г. Ассоциацией электронной промышленности (EIA). Первоначально этот интерфейс использовался для подключения ЭВМ и терминалов к системе связи через модемы, а также для непосредственного подключения терминалов к машинам. До недавнего времени последовательный интерфейс использовался для широкого спектра периферийных устройств (плоттеры, принтеры, мыши, модемы и др.), но сейчас активно вытесняется интерфейсом USB.
Стандарт RS-232C определяет:
- механические характеристики интерфейса (разд.1) - разъемы и соединители;
- электрические характеристики сигналов (разд.2) - логические уровни;
- функциональные описания интерфейсных схем (разд.4) - протоколы передачи;
- стандартные интерфейсы для выбранных конфигураций систем связи (разд. 5).
В 1975 г. были приняты стандарты RS-422 (электрические характеристики симметричных цепей цифрового интерфейса) и RS-423 (электрические характеристики несимметричных цепей цифрового интерфейса), позволяющие увеличить скорость передачи данных по последовательному интерфейсу.
Обычно ПК имеют в своем составе два интерфейса RS-232C, которые обозначаются COM1 и COM2. Возможна установка дополнительного оборудования, которое обеспечивает функционирование в составе PC четырех, восьми и шестнадцати интерфейсов RS-232C. Для подключения устройств используется 9-контактный (DB9) или 25-контактный (DB25) разъем.
Основные принципы обмена информацией по интерфейсу RS-232C заключаются в следующем:
- Обмен данными обеспечивается по двум цепям, каждая из которых является для одной из сторон передающей, а для другой - приемной.
- В исходном состоянии по каждой из этих цепей передается двоичная единица, т.е. стоповая посылка. Передача стоповой посылки может выполняться сколь угодно долго.
- Передаче каждого пакета данных предшествует передача стартовой посылки, т.е. передача двоичного нуля в течение времени, равного времени передачи одного бита данных.
- После передачи стартовой посылки обеспечивается последовательная передача всех разрядов данных, начиная с младшего разряда. Количество битов может быть 5, 6, 7 или 8.
- После передачи последнего бита данных возможна передача контрольного разряда, который дополняет сумму по модулю 2 переданных разрядов до четности или нечетности. В некоторых системах передача контрольного бита не выполняется.
- После передачи контрольного разряда или последнего бита, если формирование контрольного разряда не предусмотрено, обеспечивается передача стоповой посылки. Минимальная длительность посылки может быть равной длительности передачи одного, полутора или двух бит данных.
Обмен данными по описанным выше принципам требует предварительного согласования приемника и передатчика по скорости (длительности бита) (300-115200 бит/с), количеству используемых разрядов в символе (5, 6, 7 или 8), правилам формирования контрольного разряда (контроль по четности, по нечетности или отсутствие контрольного разряда), длительности передачи стоповой посылки (1 бит, 1,5 бит или 2 бит).
Спецификация RS-232C для электрических характеристик сигналов определяет, что высокий уровень напряжения от +3В до +12В (при передаче - до +15В) считается логическим "0", а низкий уровень напряжения от 3В до 12В (при передаче - до 15В) считается логическим "1". Диапазон сигналов 3В:+3В обеспечивает защиту от помех и стабильность передаваемых данных.
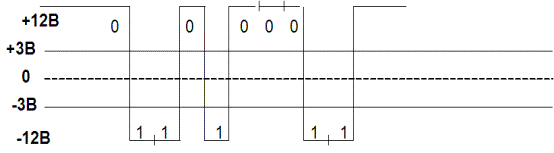 Рис. Логические уровни интерфейса RS-232C
Рис. Логические уровни интерфейса RS-232CИнтерфейс IEEE 1284
Стандартный интерфейс параллельного порта получил свое первоначальное название по имени американской фирмы Centronics - производителя принтеров. Первые версии этого стандарта были ориентированы исключительно на принтеры, подразумевали передачу данных лишь в одну сторону (от компьютера к принтеру) и имели невысокую скорость передачи (150-300 Кбайт/с). Такие скорости неприемлемы для современных печатающих устройств. Кроме того, для работы с некоторыми устройствами необходима двусторонняя передача данных. Поэтому некоторые фирмы (Xircom, Intel, Hewlett Packard, Microsoft) предложили несколько модификаций скоростных параллельных интерфейсов: EPP (Enhanced Parallel Port) - до 2 Мбайт/с, ECP (Extended Capabilities Port) - до 4 Мбайт/с и др. На основе этих разработок в 1994 году Институтом инженеров по электронике и электротехнике был принят стандарт IEEE 1284-1994, ныне повсеместно используемый в персональных компьютерах в качестве стандартного параллельного интерфейса.
Стандарт IEEE 1284 определяет работу параллельного интерфейса в трех режимах: Standard Parallel Port ( SPP), Enhanced Parallel Port (EPP) и Extended Capabilities Port (ECP). Каждый из этих режимов предусматривает двустороннюю передачу данных между компьютером и периферийным устройством.
Режим SPP (Стандартный параллельный порт) используется для совместимости со старыми принтерами, не поддерживающими IEEE 1284.
В режиме EPP (Улучшенный параллельный порт) используется аппаратная реализация сигналов квитирования, благодаря чему возможно увеличение скорости передачи до 2 Мбайт/с. Этот режим поддерживает адресацию устройств, благодаря чему возможно подключение нескольких (до 64) устройств к одному порту.
Режим ECP (Порт расширенных возможностей) также использует аппаратное квитирование и адресацию устройств (до 128). Дополнительно ECP поддерживает распознавание ошибок, согласование скорости и режима передачи, буферизацию данных в очереди FIFO (с использованием DMA) и их компрессию по алгоритму RLE (Run Length Encoding), что позволяет достигать скорость до 4 Мбайт/с.
Инфракрасный интерфейс
В 1994 году Ассоциацией инфракрасной передачи данных (Infra-Red Data Assotiation) была принята первая версия стандарта IrDA. Интерфейс IrDA позволяет соединяться с периферийным оборудованием без кабеля при помощи ИК-излучения с длиной волны 850-900 нм (номинально - 880 нм). Порт IrDA дает возможность устанавливать связь на коротком расстоянии до 1 метра в режиме "точка-точка". Ассоциация намеренно не пыталась создавать локальную сеть на основе ИК-излучения, поскольку сетевые интерфейсы очень сложны и требуют большой мощности, а в цели интерфейса входили низкое ресурсопотребление и экономичность.
Порт IrDA основан на архитектуре коммуникационного порта и использует универсальный асинхронный приемо-передатчик UART (Universal Asynchronous Receiver Transmitter), позволяющий работать со скоростью передачи данных 2400-115200 бит/с. Данные передаются 10-битными символами: 8 бит данных, один стартовый бит в начале и один стоповый бит в конце посылки. Связь в IrDA полудуплексная, т.к. передаваемый ИК-луч неизбежно засвечивает приемный фотодиод. Воздушный промежуток между устройствами позволяет принять ИК-энергию только от одного источника в данный момент. На физическом уровне стандарт IrDA определяет следующий способ кодирования: логический "0" передается одиночным ИК-импульсом длиной от 1,6 мкс до 3/16 периода передачи битовой ячейки, а логическая "1" передается как отсутствие ИК-импульса. Минимальная мощность потребления гарантируется при фиксированной длине импульса 1,6 мкс
 Рис. Формат пакета IrDA
Рис. Формат пакета IrDAОписанный способ кодирования (асинхронный) используется на скоростях до 115200 бит/с. В стандарте IrDA 1.1 этот режим определяется как SIR (Standard Infra-Red). Кроме того, стандарт IrDA 1.1 допускает реализацию высокоскоростного ИК-интерфейса до 4 Мбит/с - FIR (Fast Infra-Red). В этом случае ИК-интерфейс реализуется на основе синхронных протоколов HDLC/SDLC (High-level Data Link Control / Synchronous Data Link Control) с использованием на скоростях выше 1 Мбит/с фазоимпульсной модуляции. В настоящее время существует дополнение к стандарту IrDA - VFIR (Very Fast IR), описывающее обмен данными на скоростях до 16 Мбит/с.
Интерфейс USB
Спецификация периферийной шины USB была разработана лидерами компьютерной и телекоммуникационной промышленности (Compaq, DEC, IBM, Intel, Microsoft, NEC и Northern Telecom) для подключения компьютерной периферии вне корпуса ПК с автоматическим автоконфигурированием (Plug&Play). Первая версия стандарта появилась в 1996 г. Агрессивная политика Intel по внедрению этого интерфейса стимулирует постепенное исчезновение таких низкоскоростных интерфейсов, как RS 232C, Access.bus и т.п. Однако для высокоскоростных устройств с более строгими требованиями к производительности (например, доступ к удаленному накопителю или передача оцифрованного видео) конкурентом USB является интерфейс IEEE 1394.
Интерфейс USB представляет собой последовательную, полудуплексную, двунаправленную шину со скоростью обмена:
- USB 1.1 - 1,5 Мбит/с или 12 Мбит/с;
- USB 2.0 - 480 Мбит/с.
Шина позволяет подключить к ПК до 127 физических устройств. Каждое физическое устройство может, в свою очередь, состоять из нескольких логических (например, клавиатура со встроенным манипулятором-трекболом).
Кабельная разводка USB начинается с узла (host). Хост обладает интегрированным корневым концентратором (root hub), который предоставляет несколько разъемов USB для подключения внешних устройств. Затем кабели идут к другим устройствам USB, которые также могут быть концентраторами, и функциональным компонентам (например, модем или акустическая система). Концентраторы часто встраиваются в мониторы и клавиатуры (которые являются типичными составными устройствами). Концентраторы могут содержать до семи "исходящих" портов.
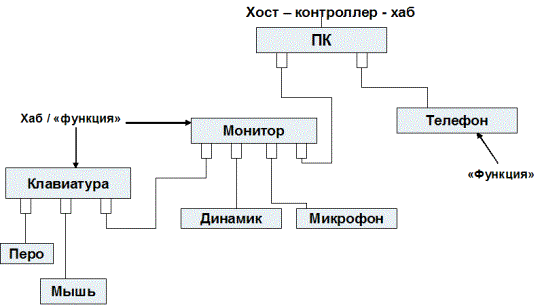 Рис. Топология подключения устройств к USB
Рис. Топология подключения устройств к USBДля передачи сигналов шина USB использует четырехпроводной интерфейс. Одна пара проводников ("+5В" и "общий") предназначена для питания периферийных устройств с нагрузкой до 500 мА. Данные передаются по другой паре ("D+" "D"). Для передачи данных используются дифференциальные напряжения до 3 В (с целью снижения влияния шума) и схема кодирования NRZIссылка скрыта (что избавляет от необходимости выделять дополнительную пару проводников под тактовый сигнал).
Интерфейс USB 1.1 декларирует два режима:
- низкоскоростной подканал (пропускная способность - 1,5 Мбит/с), предназначенный для таких устройств, как мыши и клавиатуры;
- высокопроизводительный канал, обеспечивающий максимальную пропускную способность 12 Мбит/с, что может использоваться для подключения внешних накопителей или устройств обработки и передачи аудио- и видеоинформации.
Все концентраторы должны поддерживать на своих исходящих портах устройства обоих типов, не позволяя высокоскоростному трафику достигать низкоскоростных устройств. Высокопроизводительные устройства подключаются с помощью экранированного кабеля, длина которого не должна превышать 3 м. Если же устройство не формулирует особых требований к полосе пропускания, его можно подключить и неэкранированным кабелем (который может быть более тонким и гибким). Максимальная длина кабеля для низкоскоростных устройств - 5 м. Требования устройства к питанию (диаметр проводников, потребляемая мощность) могут обусловить необходимость использования кабеля меньшей длины. Из-за особенностей распространения сигнала по кабелю число последовательно соединенных концентраторов ограничено шестью (и семью пятиметровыми отрезками кабеля).
Хост узнает о подключении или отключении устройства из сообщения от концентратора (эта процедура называется опросом шины - bus enumeration). Затем хост присваивает устройству уникальный адрес USB (1:127). После отключения устройства от шины USB его адрес становится доступным для других устройств.
Для индивидуального обращения к конкретным функциональным возможностям составного устройства применяется 4-битное поле конечной точки. В низкоскоростных устройствах за каждой функцией закрепляется не более двух адресов конечных точек: нулевая конечная точка используется для конфигурации и определения состояния USB, а также управления функциональным компонентом; а другая точка - в соответствии с функциональными возможностями компонента. Устройства с максимальной производительностью могут поддерживать до 16 конечных точек, резервируя нулевую точку для задач конфигурации и управления USB.
Хост опрашивает все устройства и выдает им разрешения на передачу данных (рассылая для этого пакет-маркер - Token Packet). Таким образом, устройства лишены возможности непосредственного обмена данными - все данные проходят через хост. Это условие сильно мешало внедрению интерфейса USB на рынок портативных устройств. В результате в конце 2001 года было принято дополнение к стандарту USB 2.0 - спецификация USB OTG (On-The-Go), предназначенная для соединения периферийных USB-устройств друг с другом без необходимости подключения к хосту (например, цифровая камера и фотопринтер). Устройство, поддерживающее USB OTG, способно частично выполнять функции хоста и распознавать, когда оно подключено к полноценному хосту (на основе ПК), а когда - к другому периферийному устройству. Спецификация описывает также протокол согласования выбора роли хоста при соединении двух USB OTG-устройств.
Данные на шине передаются транзакциями, интервал между которыми составляет 1 мс. Предусмотрено четыре типа транзакций.
Управляющие передачи используются для конфигурации вновь подключенных устройств (например, присвоения им адреса USB) и их компонентов. Устройства с максимальной производительностью могут быть настроены на работу с конфигурационными сообщениями длиной 8, 16, 32 или 64 байта (по умолчанию - 8 байт). Устройства с низкой производительностью в состоянии распознавать управляющие сообщения длиной не более 8 байт.
Групповая передача (bulk) используется для адресной пересылки данных большого объема (до 1023 байт). В качестве примера можно привести передачу данных на принтер или от сканера. Устройства с низкой производительностью не поддерживают этот режим.
Передача данных прерывания, например, введенных с клавиатуры данных или сведений о перемещении мыши. Эти данные должны быть переданы достаточно быстро для того чтобы пользователь не заметил никакой задержки. В соответствии со спецификациями время задержки USB составляет несколько миллисекунд.
Изохронные передачи (передачи в реальном масштабе времени). Пропускная способность и задержка доставки оговариваются до начала передачи данных. К изохронным данным алгоритмы коррекции ошибок неприменимы (поскольку время на повторную их ретрансляцию превышает допустимый интервал задержки). За один сеанс в таком режиме может быть передано до 1023 байт. Устройства с низкой производительностью не поддерживают этот режим.
Следует также отметить, что разными производителями предлагались спецификации, описывающие интерфейс различных аппаратных реализаций контроллера USB. Фирмой Intel была предложена спецификация UHCI (Universal Host Controller Interface), которая предусматривает чрезвычайно простую аппаратную реализацию контроллера USB. В рамках данной спецификации основные функции контроля и арбитража шины возлагаются на программный драйвер. Альтернативная спецификация была предложена компаниями Compaq, Microsoft и National Semiconductor - OHCI (Open Host Controller Interface). Контроллеры по спецификации OHCI обладают унифицированным абстрактным интерфейсом, предусматривающим аппаратную реализацию большинства управляющих функций, что облегчает их программирование.
ЛЕКЦИЯ 13