
Конспект лекций по дисциплине «Управление данными» Шахты 2010
| Вид материала | Конспект |
- Конспект лекций 2010 г. Батычко Вл. Т. Муниципальное право. Конспект лекций. 2010, 2365.6kb.
- Конспект лекций 2010 г. Батычко В. Т. Уголовное право. Общая часть. Конспект лекций., 3144.81kb.
- Конспект лекций для студентов специальности 080504 Государственное и муниципальное, 962.37kb.
- Конспект лекций для студентов ссузов Кемерово 2010, 1664.44kb.
- Конспект лекций по дисциплине «Маркетинг», 487.79kb.
- Конспект лекций для студентов специальности 080110 «Экономика и бухгалтерский учет, 1420.65kb.
- Конспект лекций по курсу «управление качеством», 1487.57kb.
- Конспект лекций по курсу «управление качеством», 1507.97kb.
- Конспект лекций по дисциплине «Стратегическое управление», 960.8kb.
- В. Ф. Панин Конспект лекций по учебной дисциплине "Теоретические основы защиты окружающей, 1559.17kb.
6. ОСНОВЫ ЯЗЫКА SQL
6.1 Команды SQL-DML
1. Команда выборки данных SELECT.
SELECT [Диапазон] СписокСтолбцов FROM СписокТаблицСУсловиямиОбъединения
[WHERE Условие]
[GROUP BY УсловиеГруппировки [[HAVING УсловиеНаГруппу]]
[ORDER BY УсловиеСортировки]
[COMPUTE ИтоговоеВыражение]
[UNION SELECT …]
Здесь:
Диапазон – задает диапазон строк, возвращаемый после выполнения запроса. Синтаксис:
{ALL | DISTINCT} {TOP n [PERСENT] [WITH TIES]}
где ALL | DISTINCT – включать или нет в результат выборки повторяющиеся строки. По умолчанию действует установка ALL;
TOP n [PERСENT] [WITH TIES] – прямое указание количества первых строк, которое должно быть возвращено запросом. Если указано ключевое слово PERCENT, то количество определяется не абсолютным значением, а в процентах от общего количества (естественно, в этом случае n <= 100). Если дополнительно указано предложение WITH TIES, то будут возвращены и строки, дублирующие последние во множестве, ограниченном значением n.
СписокСтолбцов – задает список столбцов в результирующем множестве. Список может быть задан символом * - выборка всех столбцов из всех таблиц участвующих в предложении FROM, или перечислением имен колонок и/или выражениями. Если в запросе участвую несколько таблиц, то имена колонок следует задавать в формате:
ИмяТаблицы.* - для выборки всех столбцов таблицы,
ИмяТаблицы.ИмяКолонки | АлиасТаблицы.ИмяКолонки – для включения конкретного столбца,
Выражение – для построения вычисляемых столбцов.
В двух последних случаях можно переопределить имя любого столбца с помощью предложения AS НовоеИмя. В качестве выражений могут выступать любые, в соответствии с типом данных столбцов операции, функции сервера или пользователя, агрегатные функции (Count(), Count(*), Sum(), Max(), Min(), Avg(), …).
FROM СписокТаблицСУсловиямиОбъединения – раздел, задающий имя таблицы или список таблиц, из которых выбираются данные в запросе и условия их объединения, если таблиц несколько. Синтаксис списка:
ИмяТаблицы1 [AS Алиас1]
INNER | { LEFT | RIGHT | FULL } [OUTER] JOIN
ИмяТаблицы2 [AS Алиас2]
ON ИмяТаблицы1.ИмяСтолбца1 = ИмяТаблицы2.ИмяСтолбца2
| ON Алиас1.ИмяСтолбца1 = Алиас2.ИмяСтолбца2
WHERE Условие – задает логическое выражение, ограничивающее отбор строк в результирующее множество. В качестве такого выражения может служить простое логическое условие, несколько логических условий объединенных логическими операторами. В качестве операндов – логических условий – константы, имена столбцов, выражения, результаты выполнения подзапроса. В качестве операторов – простое (= ; > ; < и т.д.) или множественное (IN ; ALL ; ANY ; EXIST) логическое условие. Примеры:
Select Код, Улица From Улицы Where Код > 5
Select Код, Улица From Улицы Where Код > 5 AND Код < 100
Select Сотрудники.ТабНом, Сотрудники.Фамилия, Начисления.Начислено
From Сотрудники Inner Join Начисления
On Сотрудники.ТабНом = Начисления. ТабНом
Where Начисления.Начислено >= (Select Avg(Начислено) From Начисления)
Select Клиенты.ЛицевойНомер, Клиенты.Фамилия
From Клиенты Inner Join Льготы
On Клиенты. ЛицевойНомер = Льготы. ЛицевойНомер
Where Клиенты.ЛицевойНомер Not In
(Select Distinc Льготы.ЛицевойНомер From Льготы
Where Льготы.Код = ‘01’)
С помощью оператора IN могут формироваться многостолбцовые подзапросы, которые содержат более одного атрибута в списке подзапроса. Такое же количество атрибутов должно быть указано в предложении WHERE главного запроса. Обязательным условие является попарное совпадение типа и размера данных атрибутов подзапроса и главного запроса. Такие запросы имеют следующий синтаксис:
SELECT <Атрибут1>, < Атрибут2> [, …] FROM <Таблица1>
WHERE (<Атрибут1>, < Атрибут2> [,…]) [NOT] IN
(SELECT < Атрибут1>, < Атрибут2> [, …] FROM <Таблица2>
WHERE <Условие>)
Предложение WHERE при использовании операторов ANY и ALL представляется следующим образом:
WHERE <Выражение> ANY | ALL (SELECT <Атрибут> FROM …)
где - опрератор сравнения (<, >, >= и т.д.). Например:
WHERE x > ANY (SELECT y FROM …)
условие считается истинным, если x больше хотя бы одного значения y в результирующем множестве выполнения подзапроса. Очевидно, что в предложении
WHERE x <> ANY (SELECT y FROM …)
условие будет выполнено, если x не совпадает ни с одним из значений результата выполнения подзапроса. Оператор = ANY эквивалентен оператору IN.
В предложении
WHERE x > ALL (SELECT y FROM …)
условие будет истинным, если x больше всех значений y множества, формируемого подзапросом. Можно отметить, что оператор > ALL означает «больше, чем максимум», а < ALL – «меньше, чем минимум».
Многостолбцовые подзапросы выполняются один раз и возвращают в предложение WHERE главного запроса одну или несколько строк, со значениями атрибутов которых производится сравнение атрибутов главного запроса. Коррелированные подзапросы, в отличие от многостолбцовых, выполняются для каждого кортежа главного запроса. В коррелированных подзапросах применяется оператор существования. Синтаксис такого запроса в общем виде:
SELECT <Атрибут1>, < Атрибут2> [, …] FROM <Таблица1>
WHERE EXISTS
(SELECT * FROM <Таблица2>
WHERE <Таблица1>.< АтрибутN> <Таблица2>.< АтрибутM>
AND <Условие>)
Пример. Выбрать кафедры, на которых работают сотрудники в возрасте до 23 лет:
SELECT Кафедры.Наименование FROM Кафедры WHERE EXISTS
(SELECT * FROM Сотрудники WHERE Кафедры. Наименование = Сотрудники.Кафедра
AND Сотрудники.Возраст < 23)
GROUP BY – раздел, выполняющий группировку строк в соответствии с некоторым условием. В качестве условия чаще всего выступает список столбцов, по значениям которых следует сгруппировать данные. Как правило, группировка имеет смысл, если для каждой группы производятся некоторые вычисления. Примеры:
1. Выборка всех начислений для всех сотрудников за указанный период
Select Сотрудники.ТабНом, Сотрудники.Фамилия, Начисления.Начислено
From Сотрудники Inner Join Начисления
On Сотрудники.ТабНом = Начисления. ТабНом
Where Начисления.Период Between ’01.01.07’ And ’31.12.07’
2. Определение суммы начислений и среднего заработка для каждого сотрудника
Select Сотрудники.ТабНом, Сотрудники.Фамилия,
Sum(Начисления.Начислено), Avg(Начисления.Начислено)
From Сотрудники Inner Join Начисления
On Сотрудники.ТабНом = Начисления.ТабНом
Where Начисления.Период Between ’01.01.01’ And ’31.12.01’
Group By Сотрудники.ТабНом
HAVING УсловиеНаГруппу – раздел, описывающий условие включения группы в результирующее множество.
ORDER BY УсловиеСортировки – определение сортировки результатов. Здесь
УсловиеСортировки - список столбцов в формате:
ИмяКолонки1 [ASC | DESC], …
где ASC | DESC - указание порядка (по возрастанию или по убыванию) сортировки результата запроса по значениям столбца. По умолчанию используется ASC.
COMPUTE ИтоговоеВыражение – задает выражение, вычисляемое в качестве итогового для всего результата запроса или каждой группы, если в запросе используется группировка данных. В качестве выражения должны использоваться агрегатные функции SQL. Например:
Select Сотрудники.ТабНом, Сотрудники.Фамилия, Начисления.Начислено
From Сотрудники Inner Join Начисления
On Сотрудники.ТабНом = Начисления.ТабНом
Where Начисления.Период Between ’01.01.01’ And ’31.12.01’
Order By Сотрудники.ТабНом Asc, Начисления.Период Asc
Compute Sum(Начисления.Начислено), Avg(Начисления.Начислено)
Результатом будет таблица со всеми начислениями всех сотрудников плюс две дополнительные строки с суммой всех начислений и средним значением.
Select Сотрудники.ТабНом, Сотрудники.Фамилия, Начисления.Начислено
From Сотрудники Inner Join Начисления On Сотрудники.ТабНом = Начисления.ТабНом
Where Начисления.Период Between ’01.01.01’ And ’31.12.01’
Group By Сотрудники.ТабНом
Compute Sum(Начисления.Начислено), Avg(Начисления.Начислено)
Результатом будет таблица с данными для каждого сотрудника по всем его начислениям и, дополнительно, после данных каждого сотрудника будут добавлены две строки с суммой его начислений и средним заработком.
UNION – предложение, содержащее еще один оператор SELECT. В одном запросе допускается использование нескольких предложений UNION. Результаты выполнения всех операторов SELECT будут объединены в одно множество. Условием возможности такого объединения является совпадение имен колонок во всех запросах (при необходимости следует использовать алиасы) и типов данных (при необходимости следует использовать функции преобразования). При объединении результатов сортировка каждого запроса не имеет смысла, но допускается применение одного «общего» предложения ORDER BY. Пример:
Select ТабНомер As Код, Фамилия, ‘Преподаватели’ As Статус From Преподаватели
Union Select ТабНомер As Код, Фамилия, ‘Сотрудники’ As Статус From СотрудникиАХЧ
Union Select НомерЗачетки As Код, Фамилия, ‘Студенты’ As Статус From Студенты
Order By Статус
2. Команда добавления данных в существующие таблицы и представления INSERT.
INSERT INTO {ИмяТаблицы WITH УровеньБлокировки} | ИмяПредставления
|{СписокКолонок)
| VALUES {(DEFAULT | NULL | Выражение1, … )}
| SQL_Select
| SQL_Execute }
|DEFAULT VALUES
Здесь:
ИмяТаблицы и ИмяПредставления – имя таблицы или представления, в которую производится вставка строк.
УровеньБлокировки – определяет уровень блокировки (хинт) таблицы. Если уровень блокировки для таблицы не указан, то он определяется сервером автоматически. Для представлений уровень блокировки не указывается и всегда определяется автоматически.
СписокКолонок – определяет список столбцов, в который будет производится вставка данных. Аргумент необязательный, и, если он опущен, то вставка данных производится последовательно, в порядке определения столбцов при создании таблицы.
VALUES – ключевое слово, задающее значения данных. Список значений определяется одним из следующих вариантов:
1) указанием значения для каждого столбца в виде: DEFAULT – значения по-умолчанию; NULL – значения NULL; Выражение – выражения с использованием констант, переменных и функций.
2) SQL_Select – подзапросом с помощью оператора SELECT
3) SQL_Execute – результатом выполнения хранимой процедуры, т.е. выполнения команды:
EXEC ИмяХранимойПроцедуры Параметры.
DEFAULT VALUES – указание вставки для всех столбцов новой строки значений, определенных по-умолчанию. Данный аргумент является альтернативой конструкции VALUES
3. Команда создания таблиц и одновременного добавления в них данных SELECT INTO.
SELECT ИмяКолонки1 AS Алиас1, …
INTO ИмяНовойТаблицы
FROM SQL_Select
Здесь:
ИмяКолонки – задает имя колонки таблицы, которая будет включена в результат,
AS Алиас – переопределение имени колонки в создаваемой таблице. Аргумент необходим в случае, если данные выбираются из нескольких таблиц, имеющих столбцы с одинаковыми именами.
ИмяНовойТаблицы – имя создаваемой таблицы. Структура и данные таблицы будут определяться типом данных и данными столбцов, выбираемых оператором SELECT.
SQL_Select – оператор SELECT.
Выполнение команды SELECT INTO по умолчанию запрещено. Для включения или выключения возможности ее выполнения используется хранимая процедура с соответствующим параметром.
EXEC SP_DBOPTION ‘SELECT INTO/BULKCOPY’, ‘ON’ | ‘OFF’
4. Обновление данных UPDATE.
UPDATE {ИмяТаблицы WITH УровеньБлокировки} | ИмяПредставления
SET ИмяКолонки1 = DEFAULT | NULL | Выражение1 , …
WHERE Условие
Здесь:
SET – ключевое слово, определяющее список изменяемых столбцов и соответствующее каждому столбцу новое значение (по-умолчанию, NULL или определяемое выражением).
WHERE – раздел, в котором задается Условие – логическое выражение, определяющее фильтр для строк, в которых будут изменены данные. Если WHERE отсутствует, то обновляются все строки.
5. Команда удаления данных DELETE.
DELETE FROM {ИмяТаблицы WITH УровеньБлокировки} | ИмяПредставления
WHERE Условие
Команда удаляет строки из указанной таблицы или представления в соответствии с выбранным в предложении WHERE условием. Если WHERE отсутствует, то удаляются все строки.
7. ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ
Проект реляционной БД представляет собой набор взаимосвязанных отношений, в которых определены все атрибуты, первичные и внешние ключи отношений, заданы свойства отношений, обеспечивающие поддержку целостности данных. Фактически проект БД это фундамент будущего программного комплекса, который будет использоваться достаточно долго и многими пользователями. И как в любом здании, можно достраивать мансарды, переделывать крышу, можно даже менять окна, но заменить фундамент, не разрушив всего здания, невозможно. Этапы жизненного цикла БД изображены на рис. 1.
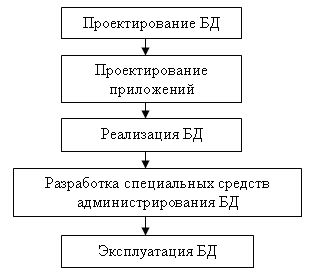 |
| Рис. 1. Этапы жизненного цикла БД |
- Системный анализ и словесное описание информационных объектов предметной области.
- Проектирование концептуальной модели предметной области частично формализованное описание объектов предметной области в терминах некоторой семантической модели, например, в терминах ЕR-модели.
- Логическое проектирование, то есть описание БД в терминах принятой логической модели данных.
- Физическое проектирование БД, то есть выбор эффективного размещения БД на внешних носителях для обеспечения наиболее эффективной работы приложения.
Рассмотрим более подробно этапы проектирования БД.
Анализ предметной области
При проектировании БД на первом этапе необходимо произвести анализ объектов предметной области, связей, которые присутствуют между этими объектами, и дать их подробное словесное описание. Целью такого изучения является выявление и документирование существующих бизнес-процессов, особенностей и недостатков существующих в конкретной предметной области информационных решений. Для этого должен быть проведен сбор существующей в выбранной сфере нормативно-правовой и справочной документации, определены входные и выходные формы (документы, отчеты), изучены должностные инструкции сотрудников. При изучении организационной структуры выбранного предприятия, должны быть определены методы и технологии управления, функции, выполняемые различными подразделениями.
На основании результатов анализа предметной области формируется функциональная схема объекта и схема информационных потоков. Функциональная модель содержит совокупность взаимосвязанных функций, между которыми установлены поименованные управляющие и информационные связи. Модель информационных потоков состоит из следующих элементов: процесс, операция, носитель информации.
Процесс обработки данных – совокупность операций, направленных на преобразование данных.
Операция – действие, выполняемое персоналом по контролю, анализу, сортировке, преобразованию и переносу данных с одного носителя на другой.
Для каждого процесса необходимо составить спецификацию, которая содержит следующие компоненты; имя процесса, списки входных и выходных данных и тело процесса, которое трансформирует входные потоки данных в выходные. Для конструирования тела процесса применяется структурированный естественный язык, обеспечивающий читаемое, достаточно строгое описание спецификаций процессов. Этот язык включает следующие элементы:
- термины, используемые в предметной области;
- глаголы, отражающие действия, применяемые к объектам;
- предлоги и союзы, включаемые в логические отношения;
- общепринятые математические, физические и технические термины;
- алгоритмические выражения, таблицы, диаграммы, графы.
Описание на структурированном языке базируется на следующих правилах:
- бизнес-логика процесса представляется как сочетание последовательных инструкций, операций выбора и итераций;
- глаголы являются активными и ориентированы на целевое действие.
В качестве примера рассмотрим фрагмент спецификации для процесса «Составление сводной ведомости по отгрузке продукции».
ПРОЦЕСС: Составление сводной ведомости.
ВХОД: Данные отчета по продукции. Документ об отгрузке, Себестоимость по цеху готовой продукции.
ВЫХОД: Сводная ведомость по отгрузке для цеха готовой продукции.
АЛГОРИТМ:
Ежедневно и ежемесячно формировать ведомость по отгрузке продукции. Для этого:
- Выбрать из носителя данных Товарно-транспортные накладные документы по отгрузке:
- товарно-транспортные накладные с отметками охраны и цеха готовой продукции об отгрузке, а также со штампом магазина;
- комплект документов, включающий Приемный акт покупателя, Акт о возврате продукции. Товарно-транспортную накладную.
- товарно-транспортные накладные с отметками охраны и цеха готовой продукции об отгрузке, а также со штампом магазина;
- Сформировать ведомость по отгрузке с включением следующих атрибутов:
наименование; фасовка; количество – отгруженной продукции, возвращенной продукции; начислений при отгрузке продукции по стоимости меньшей, чем заявлена покупателем; удержаний при отгрузке продукции по стоимости выше заявленной покупателем,
- Сохранить ведомость по отгрузке на носителе данных Ведомости.
- Выбрать ежемесячно из носителя данных Ведомости по цеху готовой продукции и составить ведомость отгруженной продукции по ассортименту за период с включением следующих атрибутов: цех отгрузки; код; наименование фасовки; количество мест; масса в кг; сумма без НДС; НДС за продукцию; торговая наценка без НДС; НДС торговой наценки. Разбить продукцию по категориям: собственная; покупная; отгруженная тара - наименование, количество, сумма, амортизация.
- Получить из балансового отдела величину себестоимости по каждому виду продукции цеха готовой продукции.
- Осуществить проводку со счета реализованной продукции на счет 68 - по собственной, 19 - по покупной.
- Осуществить проводку со счета реализованной продукции на сумму себестоимости.
- Определить результат реализации по каждому виду продукции на 46 счете (Кредит – прибыль, Дебит – убыток).
На основании выполненного анализа должно быть сформулировано назначение разрабатываемой системы, цели ее создания, а также определены требования к ее функциональным возможностям, т.е. должен быть составлен список автоматизируемых с ее помощью задач.
Разработка концептуальной модели данных
Разработанные структура информационной системы, схема информационных потоков, а также предложенные процедуры обработки информации являются исходными данными для реализации этапа концептуального проектирования базы данных. Результатом концептуального проектирования является концептуальная схема, наиболее известным вариантом представления, которой является модель «сущность-связь» или иначе ER -модель.
Основными элементами концептуальной ER-модели являются сущности, атрибуты и связи.
Сущность – это абстрактный объект, предназначенный для информационного представления относительно самостоятельного предмета реального мира, либо связанных с ними процессов и событий. Экземпляром сущности является конкретный объект описываемой предметной области. Сущности делятся на сильные и слабые. Сильные сущности соответствуют объектам, которые представлены в предметной области вне зависимости от наличия других объектов. Слабые сущности соответствуют объектам, которые существуют в предметной области только в зависимости от других, связанных с ними объектов.
Сущности соответствует набор атрибутов, предназначенных для представления их свойств. Набор значений, которые могут быть присвоены атрибуту, называется доменом. Атрибуты делятся на простые и составные, однозначные и многозначные, исходные и производные. Простой атрибут описывает элементарное свойство сущности и не может быть декомпозирован на составные компоненты. Составной атрибут состоит из независимых простых атрибутов. Однозначный атрибут принимает единственные значения для сущности. Многозначный атрибут содержит произвольное количество значений для одной сущности. Производные атрибуты вычисляются на основе значений других атрибутов, которые могут принадлежать различным сущностям.
Ключ – атрибут или набор атрибутов, уникальным образом определяющие конкретный экземпляр сущности. Два экземпляра сущности не могут обладать одинаковыми комбинациями значений атрибутов, входящих в ключ. Каждая сущность может иметь произвольное количество ключей, которые позиционируются в качестве потенциальных (альтернативных) . Один из потенциальных ключей объявляется в качестве первичного ключа. Дополнительным требованием является отсутствие неопределенных значений тина NULL для атрибутов, входящих в первичный ключ. В состав ключа слабых сущностей обязательно входят ключевые атрибуты связанных с ними сущностей.
Сущности соединяются между собой поименованными связями. Степенью связи называется количество сущностей, которые участвуют в этой связи. Унарная связь имеет степень один, бинарная связь – два. Показатель кардинальности задает количество возможных связей для каждой из связанных сущностей. В зависимости от значения показателя кардинальности выделяют следующие виды связи:
- связь типа «1:1» представляет бинарную связь, в которой каждой сущности первого из связанных классов сущностей соответствует единственная сущность второго класса и наоборот;
- связь типа «1:М» представляет бинарную связь, в которой каждой сущности первого из связанных классов сущностей соответствует подмножество М сущностей второго класса. В общем случае это подмножество может быть пустым;
- связь типа «М:N» представляет бинарную связь, в которой каждой сущности первого из связанных классов сущностей соответствует подмножество сущностей второго класса и наоборот;
- связь тина «М:1» представляет бинарную связь, в которой каждой сущности первого из связанных классов сущностей может соответствовать единственная сущность второго класса, а каждой сущности второю класса соответствует подмножество сущностей первого класса. В общем случае это подмножество может быть пустым.
Важной характеристикой связи является степень участия, которая определяет зависимость существования некоторой сущности от участия в связи другой сущности. Выделяют два варианта участия сущности в связи полное и частичное. Полная степень участия предполагает обязательность участия сущности в связи. Частичная степень участия характеризуется возможным отсутствием зависимых сущностей.
Пример схемы концептуальной модели для предметной области «Прием коммунальных платежей в среде многофункциональной автоматизированной банковской системы»:
Концептуальная модель содержит следующие сильные сущности: «Пользователи», «Получатели», «Группы получателей», «Плательщики», «Тарифы», «Кассовые документы», «Банковские атрибуты», «Проводки», «Отчеты», «Настройки». «Отделения» и слабую сущность «Квитанция».
Сущность «Получатели» предназначена для хранения информации об организациях-получателях, с которыми коммерческий банк заключил договор, а также о тех получателях, с которыми договор не заключен. В этом случае информация представляется плательщиком. Сущность включает следующие атрибуты:
табельный номер,
наименование получателя,
дата первоначальной инициализации получателя,
банковский идентификационный номер,
краткое наименование,
расчетный счет,
адрес.
Сущность «Получатели» соединена с сущностью «Тип платежа» связью с кардинальностью «один-ко- многим», т.к. один получатель может иметь несколько типов платежей. В частности, для ОАО «Водоканал» существует два типа платежей – «За водоснабжение» и «Прочие платежи». Степень участия сущности «Получатели» в рассматриваемой связи является полной, а сущности «Тип платежа» – частичной.
Анализируемая сущность «Получатели» соединена с сущностью «Квитанции» связью с кардинальностью «один-ко-многим». Это определяется тем, что в адрес одной организации поступает произвольное количество квитанций.
Сущность «Группы получателей» предназначена для представления информации об особенностях, присущих подмножеству получателей. К атрибутам этой сущности относятся:
номер группы,
наименование группы,
способ формирования платежных документов (по каждой квитанции, по каждому получателю, по всей группе),
момент взимания комиссии (по требованию кассового работника, непосредственно после регистрации квитанции),
документ, которым зачисляется комиссия на счет доходов банка,
момент формирования документов платежа (по требованию кассового работника, непосредственно после регистрации квитанции),
момент печати документов.
Сущность «Группа получателей» соединена с сущностью «Получатели» связью с кардинальностью «один-ко-многим», так как группа получателей объединяет нескольких получателей.
Степень участия сущности «Группа получателей» в рассматриваемой связи является полной, а сущности «Получатели» - частичная.
Аналогично представляется информация и об остальных сущностях и связях между ними.