
Конспект лекций по дисциплине «Управление данными» Шахты 2010
| Вид материала | Конспект |
- Конспект лекций 2010 г. Батычко Вл. Т. Муниципальное право. Конспект лекций. 2010, 2365.6kb.
- Конспект лекций 2010 г. Батычко В. Т. Уголовное право. Общая часть. Конспект лекций., 3144.81kb.
- Конспект лекций для студентов специальности 080504 Государственное и муниципальное, 962.37kb.
- Конспект лекций для студентов ссузов Кемерово 2010, 1664.44kb.
- Конспект лекций по дисциплине «Маркетинг», 487.79kb.
- Конспект лекций для студентов специальности 080110 «Экономика и бухгалтерский учет, 1420.65kb.
- Конспект лекций по курсу «управление качеством», 1487.57kb.
- Конспект лекций по курсу «управление качеством», 1507.97kb.
- Конспект лекций по дисциплине «Стратегическое управление», 960.8kb.
- В. Ф. Панин Конспект лекций по учебной дисциплине "Теоретические основы защиты окружающей, 1559.17kb.
1. ПОНЯТИЕ БАНКА ДАННЫХ
Определение банка данных. Банк данных (БнД) является современной формой организации хранения и доступа к информации. Существует множество определений банка данных. В «Общеотраслевых руководящих материалах по созданию банков данных» (М.: ГКНТ, 1982) дано следующее определение: «Банк данных это система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных».
В данном определении подчеркивается, что банк данных является сложной системой, включающей в себя все обеспечивающие подсистемы, необходимые для функционирования любой системы автоматизированной обработки данных.
В этом определении обозначены и основные отличительные особенности банков данных. Прежде всего, это то, что БД создаются обычно не для решения какой-либо одной задачи для одного пользователя, а для многоцелевого использования. БД отражают определенную часть реального мира. Эта информация должна по возможности фиксироваться в базе данных однократно, и все пользователи, которым эта информация нужна, должны иметь возможность работать с ней.
Другой отличительной особенностью банков данных является наличие специальных языковых и программных средств, облегчающих для пользователей выполнение всех операций, связанных с организацией хранения данных, их корректировки и доступа к ним. Такая совокупность языковых и программных средств называется системой управления базой данных (СУБД).
Нельзя сказать, что термин «банк данных» является общепризнанным. В некоторой англоязычной литературе в последнее время используется термин «система баз данных» (database system), который по своему содержанию близок введенному понятию банка данных (система баз данных включает базу данных, систему управления базами данных, соответствующее "оборудование и персонал). Согласно семантике русского языка понятие «система баз данных» воспринимается уже, чем оно обозначает в действительности. Поэтому слово «банк» является в этом смысле лучше, так как «банк» привычно обозначает не только то, что хранится в нем, но и всю инфраструктуру. Однако очевидно, что нельзя отождествлять понятия «база данных» и «банк данных», как это иногда происходит в некоторых литературных источниках
Преимущества БнД. Особенности «банковской» организации данных определяют их основные преимущества перед «небанковской» организацией.
Наличие единого целостного отображения определенной части реального мира позволяет обеспечить непротиворечивость и целостность информации, возможность обращаться к ней не только при решении заранее предопределенных задач, но и с нерегламентированными запросами.
Интегрированное хранение сокращает избыточность хранимых данных, что приводит к сокращению затрат не только на создание и хранение данных, но и на поддержание их в актуальном состоянии. Использование БнД при правильной его организации должно существенно изменить деятельность организации, где он внедряется, привести к сокращению документооборота, форм документов, перераспределению функций между сотрудниками.
Централизованное управление данными также дает целый ряд преимуществ. Освобождение от этих функций всех пользователей, кроме администраторов БД, не только приводит к сокращению трудоемкости создания системы и снижению требований к остальным участникам функционирования БнД, но и повышает качество разработок, так как вопросами организации данных занимается небольшое число профессионалов в этой области.
Преимуществом банков данных является также то, что они обеспечивают возможность более полной реализации принципа независимости прикладных программ от данных, чем это возможно при организации локальных файлов.
Наличие в составе СУБД средств, ориентированных на разные категории пользователей, делает возможной работу с базой данных не только профессионалов в области обработки данных, но и практически любого, причем это использование может быть как для их профессиональных целей, так и для удовлетворения потребности в информации в быту и т. п.
Предпосылки широкого использования БнД. Очевидные преимущества БнД и объективные предпосылки их создания привели к широкому их использованию. К числу предпосылок применения относятся следующие:
• объекты реального мира находятся в сложной взаимосвязи между собой. Это приводит к необходимости, чтобы их информационное отражение также представляло единое взаимоувязанное целое;
• информационные потребности различных пользователей существенно пересекаются, что делает целесообразным использование единых баз данных и обеспечение доступа к ним разных пользователей;
• функции создания и ведения информационного фонда и предоставления нужных данных являются универсальными, общими при решении разнообразных задач. Создание специализированных программных средств для управления данными приводит к повышению уровня выполнения этих функций и сокращению трудоемкости создания информационных систем;
• современный уровень развития технического и программного обеспечения, а также теории и практики построения информационных систем позволяют создавать эффективные БнД.
Требования к БнД. Особенности «банковской» организации данных позволяют сформулировать основные требования, предъявляемые к БнД:
• адекватность отображения предметной области (полнота, целостность и непротиворечивость данных, актуальность информации, т. е. ее соответствие состоянию объекта на данный момент времени);
• возможность взаимодействия пользователей разных категорий и в разных режимах, обеспечение высокой эффективности доступа для разных приложений;
• дружелюбность интерфейсов и малое время на освоение системы, особенно для конечных пользователей;
• обеспечение секретности и конфиденциальности для некоторой части данных; определение групп пользователей и их полномочий;
• обеспечение взаимной независимости программ и данных;
• обеспечение надежности функционирования БнД; защита данных от случайного и преднамеренного разрушения; возможность быстрого и полного восстановления данных в случае их разрушения; технологичность обработки данных, приемлемые характеристики функционирования БнД (стоимость обработки, время реакции системы на запросы, требуемые машинные ресурсы и др.).
2. АРХИТЕКТУРА БАНКА ДАННЫХ
B настоящее время принята четырехуровневая архитектура СУБД, использующая четыре уровня восприятия и отображения информации предметной области в моделях баз данных: внутренний, концептуальный уровень, логический и внешний.
На каждом уровне присутствует модель данных информации, которая специфицируется с помощью языка описания данного уровня. Модель каждого уровня, представленную на языке описания, принято называть СХЕМОЙ.
B зависимости от вида представления информации различают следующие типы схем:
- концептуальная схема, дающая общее информационно-логическое представление об информации предметной области;
- логическая (инфологическая) схема, описывающая информацию о предметной области в терминах конкретной СУБД;
- внешняя схема, дающая представление информации о предметной области для прикладных программ и пользователей системы. С помощью концептуальной и внешней схемы СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по описанию внутренней схемы;
- внутренняя схема, характеризующая физический уровень представления информации в конкретной СУБД. Ей соответствует своя модель, которая должна быть описана на языке описания данных этой СУБД.
Стандарт ANSI/SPARC
Используемые в промышленности СУБД имеют много различий, но практически все они опираются на концепцию архитектуры ANSI/SPARC американского института стандартов по проектированию баз данных. Согласно предложениям ANSI/SPARC, к исследованию разнотипных БД можно подходить с единых позиций, если придерживаться следующей архитектуры банка данных (рис. 1). Архитектура представлена тремя уровнями: внутренним, концептуальным и внешним.
Внутренний уровень наиболее близок к физическим структурам хранимой информации. Именно внутренний уровень учитывает методы доступа операционной системы для манипулирования данными на физическом уровне, что в некоторой степени снижает независимость операций обработки данных от технических средств, однако, в идеале СУБД может располагать внутренним уровнем, который бы не опирался на средства ОС.
Внешний уровень является уровнем пользователей СУБД, т.к. он является уровнем восприятия каждого пользователя. В принципе для каждого пользователя создается свой внешний уровень (схема - модель с соответствующим языком описания данных). Типичным воплощением внешнего уровня является использование представлений (VIEW) в языке SQL.
Концептуальный уровень является обобщением локальных представлений пользователей, т.е. является общим глобальным описанием предметной области в терминах (концептах) конкретной СУБД. Важно отметить, что концептуальный уровень исполняет роль некоторого стандарта пользователей, согласуя их представление о предметной области в единое целое.
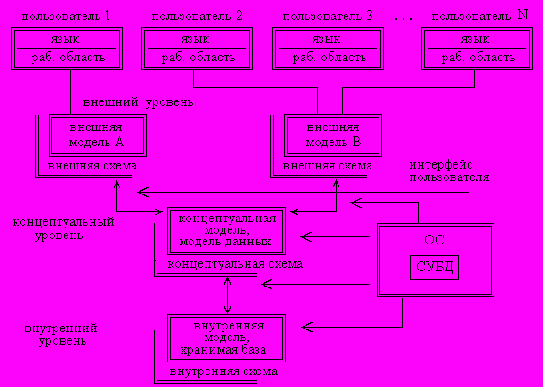
Рис. 1. Архитектура банка данных
Банк данных создается для удовлетворения информационных потребностей пользователя. Пользователи подразделяются на прикладных программистов и пользователей непрофессионалов. Для каждого пользователя используется свой язык общения с базой данных.
Для прикладного программиста это обычный язык программирования, например: Паскаль, Си, PL/1. Для пользователя-непрофессионала – это специальный язык, разработанный с учетом его потребностей, т.е. это может быть специальное меню, реализованное с помощью языка типа SQL (Structured Query Language – структурированный язык запросов) или QBE (Query-By-Exemple – запросы на основе примеров) и т.п.
Передача информации между базой данных (БД) и пользователями осуществляется через рабочую область. Для пользователей программистов такой рабочей областью является область ввода-вывода, для непрофессионала эта область состоит из рабочей памяти выделенной терминалу. Т.к. отдельного пользователя, как правило, интересует только некоторая часть всей базы данных, то он взаимодействует с банком данных на уровне внешней модели (которая может не являться точной копией физической (хранимой) базы). Таким образом, внешняя модель является информационным содержанием БД в том виде, в каком его представляет конкретный пользователь (т.е. для этого пользователя внешняя модель есть собственно база данных, например: БД отдела кадров).
Внешняя модель состоит из различных экземпляров различных типов внешних записей (логических), причем такие записи могут не совпадать с хранимыми записями. Пользователь через рабочую область оперирует с базой данных на уровне внешних записей, например, по оператору SELECT языка манипулирования данными будет происходить выборка внешней записи, а не экземпляра хранимой записи. Каждая внешняя модель задается (описывается) посредством внешней схемы, которая в основном состоит из описаний всех типов внешних записей этой внешней модели, например: запись о студенте. Помимо этого описания, должно быть определено отображение, связывающее внешнюю схему с концептуальной схемой.
Концептуальная запись может не соответствовать внешней или хранимой записи. Концептуальная модель определяется посредством концептуальной схемы, которая включает определения каждого типа концептуальных записей. Для достижения независимости данных эти определения не должны учитывать структуру хранения или стратегию доступа, они должны быть определениями только информационного содержания, т.е. они не должны содержать какие-либо особенности физического отображения (хеш-адресацию, индексирование, и т.д.).
Проектирование концептуальной модели БД включает анализ информационных потребностей пользователей и определение нужных им элементов данных. Результатом такого проектирования является концептуальная схема, единое логическое описание всех элементов данных и отношений между ними. Именно в этой схеме указываются необходимые ограничения, присущие как каждому элементу данных, так и отношениям (таблицам), имеющимся в схеме.
Низшим уровнем архитектуры банка данных является внутренний уровень или уровень хранимых записей. Внутренняя модель описывается посредством внутренней схемы, которая не только определяет различные типы хранимых записей, но и определяет, каким образом эти хранимые записи организованы (последовательно, с использованием хеш-функций, B-деревьев и т.п.), какие добавочные индексы используются, какие используются методы кодирования и т.п.
Основная функция СУБД – организация обмена информацией между пользователями и базами данных с соответствующими процедурами контроля полномочий и процедур проверки. Среди пользователей СУБД выделяется лицо (или группа лиц), на которого обычно возлагаются следующие функции:
- определение информационного содержания БД (идентификация объектов и связей, представляющих интерес для данного предприятия, создание на этой основе концептуальной схемы (с помощью специального языка);
- определение структуры хранения и стратегии доступа;
- взаимодействие с пользователем (подготовка и написание внешних схем);
- определение стратегии дублирования и восстановления;
- управление эффективностью ответа на запросы пользователей;
- создание словаря данных.
Такое лицо получает статус администратора БД (АБД). Для обычного пользователя перечисленные выше функции либо недоступны, либо они ему не нужны. В этом проявляется еще один аспект независимости данных – СУБД должна предоставлять доступ к данным, не требуя от пользователя знаний о таких тонкостях как:
- физическое размещение в памяти данных и их описаний;
- управление данными во внешней памяти и управление буферами оперативной памяти;
- механизмы поиска запрашиваемых данных;
- проблемы, возникающие при одновременном запросе одних и тех же данных многими пользователями;
- способы обеспечения защиты данных от некорректных обновлений и (или) несанкционированного доступа и множестве других функций СУБД, таких, например, как управление транзакциями или журнализации и восстановления баз данных после всевозможных сбоев.
3. АРХИТЕКТУРА СУБД
Условная обобщенная структура СУБД изображена на рис. 1. Здесь показано, что СУБД должна управлять внешней памятью, в которой расположены файлы с данными, файлы журналов и файлы системного каталога. С другой стороны, СУБД управляет и оперативной памятью, в которой располагаются буфера с данными, буфера журналов, данные системного каталога, которые необходимы для поддержки целостности и проверки привилегии пользователей. Кроме того, и оперативной памяти во время работы СУБД располагается информация, которая соответствует текущему состоянию обработки запросов, там хранятся планы выполнения скомпилированных запросов и т. д.
Модуль управления внешней памятью обеспечивает создание необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например для ускорения доступа к данным в некоторых случаях (обычно для этого используются индексы). Как мы рассматривали ранее, в некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
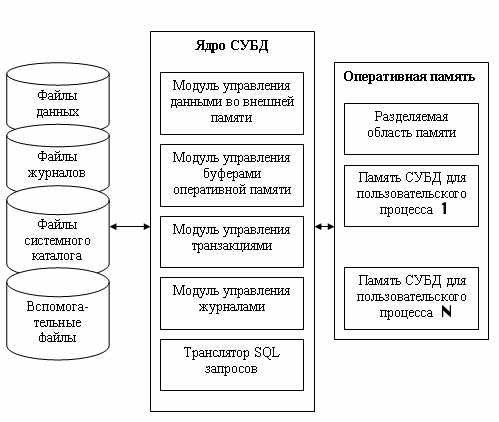
Рис. 1. Обобщенная структура СУБД
Модуль управления буферами оперативной памяти предназначен для решения задач эффективной буферизации, которая используется практически для выполнения всех остальных функций СУБД.
Условно оперативную память, которой управляет СУБД, можно представить как совокупность буферов, хранящих страницы данных, буферов, хранящих страницы журналов транзакций и область совместно используемого пула (см. рис. 2). Последняя область содержит фрагменты системного каталога, которые необходимо постоянно держать в оперативной памяти, чтобы ускорить обработку запросов пользователей, и область операторов SQL с курсорами. Фрагменты системного каталога в некоторых реализациях называются словарем данных. В стандарте SQL2 определены общие требования к системному каталогу.
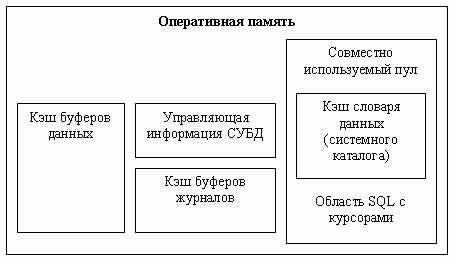
Рис. 2. Оперативная память, управляемая СУБД
Системный каталог в реляционных СУБД представляет собой совокупность специальных таблиц, которыми владеет сама СУБД. Таблицы системного каталога создаются автоматически при установке программного обеспечения сервера БД. При обработке SQL-запросов СУБД постоянно обращается к этим таблицам. В некоторых СУБД разрешен ограниченный доступ пользователей к ряду системных таблиц, однако только в режиме чтения. Только системный администратор имеет некоторые права на модификацию данных в некоторых системных таблицах.
Каждая таблица системного каталога содержит информацию об отдельных структурных элементах БД. В стандарте SQL2 определены следующие системные таблицы:
Таблица 14.1. Содержание системного каталога по стандарту SQL2
| Системная таблица | Содержание |
| USERS | Одна строка для каждого идентификатора пользователя с зашифрованным паролем |
| SCHEMA | Одна строка для каждой информационной схемы |
| DATA_TYPE_DESCRIPTION | Одна строка для каждого домена или столбца, имеющего определенный тип данных |
| DOMAINS | Одна строка для каждого домена |
| DOMAIN_CONSTRA1NS | Одна строка для каждого ограничивающего условия, наложенного на домен |
| TABLES | Одна строка для каждой таблицы с указанием имени, владельца, количества столбцов, размеров данных столбцов, и т. д. |
| VIEWS | Одна строка для каждого представления с указанием имени, имени владельца, запроса, который определяет представление и т. д. |
| COLUMNS | Одна строка для каждого столбца с указанием имени столбца, имени таблицы или представления, к которому он относится, типа данных столбца, его размера, допустимости или недопустимости неопределенных значений (NULL ) и т. д. |
| VIEW_TABLE_USAGE | Одна строка для каждой таблицы, на которую имеется ссылка в каком-либо представлении (если представление многотабличное, то для каждой таблицы заносится одна строка) |
| VIEW_COLUMN_USAGE | Одна строка для каждого столбца, на который имеется ссылка в некотором представлении |
| TABLE_CONSTRAINS | Одна строка для каждого условия ограничения, заданного в каком-либо определении таблицы |
| KEY_COLUMN_USAGE | Одна строка для каждого столбца, на который наложено условие уникальности и который присутствует в определении первичного или внешнего ключа (если первичный или внешний ключ заданы несколькими столбцами, то для каждого из них задается отдельная строка) |
| REFERENTIAL_CONSTRAINTS | Одна строка для каждого внешнего ключа, присутствующего в определении таблицы |
| CHECK_ CONSTRAINTS | Одна строка для каждого условия проверки, заданного в определении таблицы |
| CHECK_TABLE_USAGE | Одна строка для каждой таблицы, на которую имеется ссылка в условиях проверки, ограничительном условии для домена или всей таблицы |
| CHECK_COLUMN_USAGE | Одна строка для каждого столбца, на который имеется ссылка в условии проверки, ограничительном условии для домена или ином ограничительном условии |
| ASSERTIONS | Одна строка для каждого декларативного утверждения целостности |
| TABLE_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какую-либо таблицу |
| COLUMN_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какой-либо столбец |
| USAGE_PRIVILEGES | Одна строка для каждой привилегии, предоставленной на какой-либо домен, набор символов и т. д. |
| CHARACTER_SETS | Одна строка для каждого заданного набора символов |
| COLLATIONS | Одна строка для заданной последовательности |
| TRANSLATIONS | Одна строка для каждого заданного преобразования |
| SQL_LAGUAGES | Одна строка для каждого заданного языка, поддерживаемого СУБД |
Стандарт SQL2 не требует, чтобы СУБД в точности поддерживала требуемый набор системных таблиц. Стандарт ограничивается требованием того, чтобы для рядовых пользователей были доступны некоторые специальные представления системного каталога. Поэтому системные таблицы организованы по-разному в разных СУБД и имеют различные имена, но большинство СУБД предоставляют ряд основных представлений рядовым пользователям.
Кроме того, системный каталог отражает некоторые дополнительные возможности, предоставляемые конкретными СУБД. Так, например, в системном каталоге Oracle присутствуют таблицы синонимов.
Область SQL содержит данные связывания, временные буферы, дерево разбора и план выполнения для каждого оператора SQL, переданного серверу БД. Область разделяемого пула ограничена в размере, поэтому, возможно, в ней не могут поместиться все операторы SQL, которые были выполнены с момента запуска сервера БД. Ядро СУБД удаляет старые, давно не используемые операторы, освобождая память под новые операторы SQL. Если пользователь выполняет запрос, план выполнения которого уже хранится в разделяемом пуле, то СУБД не производит его разбор и построение нового плана, она сразу запускает его на выполнение, возможно, с новыми параметрами.
Модуль управления транзакциями поддерживает механизмы фиксации и отката транзакций, он связан с модулем управления буферами оперативной памяти и обеспечивает сохранение всей информации, которая требуется после мягких или жестких сбоев в системе. Кроме того, модуль управления транзакциями содержит специальный механизм поиска тупиковых ситуаций или взаимоблокировок и реализует одну из принятых стратегий принудительного завершения транзакций для развязывания тупиковых ситуаций.
Перечисленные функции СУБД, в свою очередь, используют следующие основные функции более низкого уровня, которые назовем низкоуровневыми:
 управление данными во внешней памяти;управление буферами оперативной памяти;управление транзакциями;ведение журнала изменений в БД;обеспечение целостности и безопасности БД.
управление данными во внешней памяти;управление буферами оперативной памяти;управление транзакциями;ведение журнала изменений в БД;обеспечение целостности и безопасности БД.Реализация функции управления данными во внешней памяти в разных системах может различаться и на уровне управления ресурсами (используя файловые системы ОС или непосредственное управление устройствами ПЭВМ), и по логике самих алгоритмов управления данными. В основном методы и алгоритмы управления данными являются "внутренним делом" СУБД и прямого отношения к пользователю не имеют. Качество реализации этой функции наиболее сильно влияет на эффективность работы специфических ИС, например, с огромными БД, со сложными запросами, большим объемом обработки данных.
Необходимость буферизации данных и как следствие реализации функции управления буферами оперативной памяти обусловлено тем, что объем оперативной памяти меньше объема внешней памяти.
Буферы представляют собой области оперативной памяти, предназначенные для ускорения обмена между внешней и оперативной памятью. В буферах временно хранятся фрагменты БД, данные из которых предполагается использовать при обращении к СУБД или планируется записать в базу после обработки.
Механизм транзакций используется в СУБД для поддержания целостности данных в базе. Транзакцией называется некоторая неделимая последовательность операций над данными БД, которая отслеживается СУБД от начала и до завершения. Если по каким-либо причинам (сбои и отказы оборудования, ошибки в программном обеспечении, включая приложение) транзакция остается незавершенной, то она отменяется.
Говорят, что транзакции присущи три основных свойства:
атомарность (выполняются все входящие в транзакцию операции или ни одна);сериализуемость (отсутствует взаимное влияние выполняемых в одно и то же время транзакций);долговечность (даже крах системы не приводит к утрате результатов зафиксированной транзакции). Примером транзакции является операция перевода денег с одного счета на другой в банковской системе. Здесь необходим, по крайней мере, двухшаговый процесс. Сначала снимают деньги с одного счета, затем добавляют их к другому счету. Если хотя бы одно из действий не выполнится успешно, результат операции окажется неверным и будет нарушен баланс между счетами.
Контроль транзакций важен в однопользовательских и в многопользовательских СУБД, где транзакции могут быть запущены параллельно. В последнем случае говорят о сериализуемости транзакций. Под сериализацией параллельно выполняемых транзакций понимается составление такого плана их выполнения (сериального плана), при котором суммарный эффект реализации транзакций эквивалентен эффекту их последовательного выполнения.
При параллельном выполнении смеси транзакций возможно возникновение конфликтов (блокировок), разрешение которых является функцией СУБД. При обнаружении таких случаев обычно производится "откат" путем отмены изменений, произведенных одной или несколькими транзакциями.
Ведение журнала изменений в БД (журнализация изменений) выполняется СУБД для обеспечения надежности хранения данных в базе при наличии аппаратных сбоев и отказов, а также ошибок в программном обеспечении.
Журнал СУБД - это особая БД или часть основной БД, непосредственно недоступная пользователю к используемая для записи информации обо всех изменениях базы данных. В различных СУБД в журнал могут заноситься записи, соответствующие изменениям в СУБД на разных уровнях: от минимальной внутренней операции модификации страницы внешней памяти до логической операции модификации БД (например, вставки записи, удаления столбца, изменения значения в поле) и даже транзакции.
Для эффективной реализации функции ведения журнала изменений в БД необходимо обеспечить повышенную надежность хранения и поддержания в рабочем состоянии самого журнала. Иногда для этого в системе хранят несколько копий журнала.
Обеспечение целостности БД составляет необходимое условие успешного функционирования БД, особенно для случая использования БД в сетях. Целостность БД, есть свойство базы данных, означающее, что в ней содержится полная, непротиворечивая и адекватно отражающая предметную область информация. Поддержание целостности БД включает проверку целостности и ее восстановление в случае обнаружения противоречий в базе данных. Целостное состояние БД описывается с помощью ограничений целостности в виде условий, которым должны удовлетворять хранимые в базе данные. Примером таких условий может служить ограничение диапазонов возможных значений атрибутов объектов, сведения о которых хранятся в БД, или отсутствие повторяющихся записей в таблицах реляционных БД.
Обеспечение безопасности достигается в СУБД шифрованием прикладных программ, данных, защиты паролем, поддержкой уровней доступа к базе данных и к отдельным ее элементам (таблицам, формам, отчетам и т. д.).
Модуль поддержки SQL – это транслятор с языка SQL и блок оптимизации запросов.
В общем, оптимизация запросов может быть разделена на синтаксическую и семантическую.
Методы синтаксической оптимизации запросов
Методы синтаксической оптимизации запросов связаны с построением некоторой эквивалентной формы, называемой иногда канонической формой, которая требует меньших затрат на выполнение запроса, но дает результат, полностью эквивалентный исходному запросу.
К методам, используемым при синтаксической оптимизации запросов, относятся следующие:
Логические преобразования запросов. Прежде всего, это относится к преобразованию предикатов, входящих в условие выборки. Предикаты, содержащие операции сравнения простых значений. Такой предикат имеет вид:
Выражение1 ОС Выражение2
где ОС – операция сравнения, а арифметические выражения левой и правой частей в общем случае содержат имена полей отношений и константы (в языке SQL среди констант могут встречаться и имена переменных объемлющей программы, значения которых становятся известными только при реальном выполнении запроса).
Канонические представления могут быть различными для предикатов разных типов. Если предикат включает только одно имя поля, то его каноническое представление может, например, иметь вид имя поля ОС константное арифметическое выражение (эта форма предиката – простой предикат селекции – очень полезна при выполнении следующего этапа оптимизации). Если начальное представление предиката имеет вид
(n+12)*R.B OC 100
здесь n – переменная языка, R.B – имя столбца В отношения R.
Каноническим представлением такого предиката может быть
R.В ОС 100/(n+12)
В этом случае мы один раз для заданного значения переменной п вычисляем выражение в скобках и правую часть операции сравнения 100/(n +12), а потом каждую строку можем сравнивать с полученным значением.
Если предикат включает в точности два имени поля разных отношений (или двух разных вхождений одного отношения), то его каноническое представление может иметь вид:
Имя_поля ОС Арифметическое_выражение,
Если в начальном представлении предикат имеет вид:
12*(Rl.A)-n*(R2.B) ОС m,
то его каноническое представление:
R1.A ОС (m+n*(R2.B)/12
В общем случае желательно приведение предиката к каноническому представлению вида:
арифметическое выражение ОС константное арифметическое выражение,
где выражения правой и левой частей также приведены к каноническому представлению. В дальнейшем можно произвести поиск общих арифметических выражений в разных предикатах запроса. Это оправдано, поскольку при выполнении запроса вычисление арифметических выражений будет производиться при выборке каждого очередного кортежа, то есть потенциально большое число раз.
При приведении предикатов к каноническому представлению можно вычислять константные выражения и избавляться от логических отрицаний.
Еще один класс логических преобразований связан с приведением к каноническому виду логического выражения, задающего условие выборки запроса. Как правило, используются либо дизъюнктивная, либо конъюнктивная нормальные формы. Выбор канонической формы зависит от общей организации оптимизатора.
При приведении логического условия к каноническому представлению можно производить поиск общих предикатов (они могут существовать изначально, могут появиться после приведения предикатов к каноническому виду или в процессе нормализации логического условия) и упрощать логическое выражение за счет, например, выявления конъюнкции взаимно противоречащих предикатов.
Преобразования запросов с изменением порядка реляционных операций. В традиционных оптимизаторах распространены логические преобразования, связанные с изменением порядка выполнения реляционных операций.
Например, имеем следующий запрос:
Rl NATURAL JOIN R2 WHERE R1.A ОС a AND R2.B С b
Здесь а и b некоторые константы, которые ограничивают значение атрибутов отношений R1 и R2.
Если мы его рассмотрим в терминах реляционной алгебры, то это естественное соединение отношений R1 и R2, в которых заданы внутренние ограничения на кортежи каждого отношения.
Для уменьшения числа соединяемых кортежей резоннее сначала произвести операции выборки на каждом отношении и только после этого перейти в операции естественного соединения.
Поэтому данный запрос будет эквивалентен следующей последовательности операций реляционной алгебры:
R3 =.R1[R1.A ОС а] R4 = R2[R2.B С b] R5 = R3*[ ]*R4
Хотя немногие реляционные системы имеют языки запросов, основанные в чистом виде на реляционной алгебре, правила преобразований алгебраических выражений могут быть полезны и в других случаях. Довольно часто реляционная алгебра используется в качестве основы внутреннего представления запроса. Естественно, что после этого можно выполнять и алгебраические преобразования.
В частности, существуют подходы, связанные с преобразованием запросов на языке SQL к алгебраической форме. Особенно важно то, что реляционная алгебра более проста, чем язык SQL. Преобразование запроса к алгебраической форме упрощает дальнейшие действия оптимизатора по выборке оптимальных планов. Вообще говоря, развитый оптимизатор запросов системы, ориентированной на SQL, должен выявить все возможные планы выполнения любого запроса, но «пространство поиска» этих планов в общем случае очень велико; в каждом конкретном оптимизаторе используются свои эвристики для сокращения пространства поиска. Некоторые, возможно, наиболее оптимальные планы никогда не будут рассматриваться. Разумное преобразование запроса на SQL к алгебраическому представлению сокращает пространство поиска планов выполнения запроса с гарантией того, что оптимальные планы потеряны не будут.
Приведение запросов с вложенными подзапросами к запросам с соединениями. Основным отличием языка SQL от языка реляционной алгебры является возможность использовать в логическом условии выборки предикаты, содержащие вложенные подзапросы. Глубина вложенности не ограничивается языком, то есть, вообще говоря, может быть произвольной. Предикаты с вложенными подзапросами при наличии общего синтаксиса могут обладать различной семантикой. Единственным общим для всех возможных семантик вложенных подзапросов алгоритмом выполнения запроса является вычисление вложенного подзапроса всякий раз при вычислении значения предиката. Поэтому естественно стремиться к такому преобразованию запроса, содержащего предикаты со вложенными подзапросами, которое сделает семантику подзапроса более явной, предоставив тем самым в дальнейшем оптимизатору возможность выбрать способ выполнения запроса, наиболее точно соответствующий семантике подзапроса.
Каноническим представлением запроса на n отношениях называется запрос, содержащий n-1 предикат соединения и не содержащий предикатов с вложенными подзапросами. Фактически каноническая форма это алгебраическое представление запроса.
Например, запрос с вложенным подзапросом:
(SELECT Rl.A FROM Rl
WHERE Rl.B IN (SELECT R2.B FROM R2 WHERE Rl.C = R2.D))
эквивалентен
(SELECT Rl.A FROM Rl. R2 WHERE Rl.A = R2.B AND Rl.C = R2.D)
Второй запрос:
(SELECT Rl.A FROM Rl WHERE Rl.K =
(SELECT AVG (R2.B) FROM R2 WHERE Rl.C = R2.D)
При использовании подобного подхода в оптимизаторе запросов не обязательно производить формальные преобразования запросов. Оптимизатор должен в большей степени использовать семантику обрабатываемого запроса, а каким образом она будет распознаваться — это вопрос техники.
Методы семантической оптимизации запросов
Рассмотренные ранее методы никак не связаны с семантикой конкретной БД, они применимы к любой БД, вне зависимости от ее конкретного содержания. Семантические методы оптимизации основаны как раз на учете семантики конкретной БД. Таких методов в различных реализациях может быть множество, мы с вами коснемся лишь некоторых из них:
Преобразование запросов с учетом семантической информации. Это прежде всего относится к запросам, которые выполняются над представлениями. Само представление представляет собой запрос. В БД представление хранится в виде скомпилированного плана выполнения запроса, то есть в нем в некоторой канонической форме представлены уже все предикаты и сам план выполнения запроса. При преобразовании внешнего запроса производится объединение внешнего запроса с внутренней формой запроса, составляющего основу представления, и строится обобщенная каноническая форма, объединяющая оба запроса. Для этой новой формы проводится анализ и преобразование предикатов. Поэтому при выполнении запроса над представлением будет выполнено не два, а только один запрос, оптимизированный по обобщенным параметрам запроса.
Использование ограничений целостности при анализе запросов. Ограничения целостности связаны с условиями, которые накладываются на значения столбцов таблицы. При выполнении запросов над таблицами условия запросов объединяются специальным образом с условиями ограничений таблицы и полученные обобщенные предикаты уже анализируются. Допустим, что мы ищем в нашей библиотеке читателей с возрастом более 100 лет, но если у нас есть ограничение, заданное для таблицы READERS, которое ограничивает дату рождения читателей, так чтобы читатель имел дату рождения в пределах от 17 до 100 лет включительно. Поэтому оптимизатор запроса, сопоставив два эти предиката, может сразу определить, что результатом запроса будет пустое множество.
После оптимизации запрос имеет непроцедурный вид, то есть в нем не определен жесткий порядок выполнения элементарных операций над исходными объектами. На следующем этане строятся все возможные планы выполнения запросов и для каждого из них производятся стоимостные оценки. Оценка планов выполнения запроса основана на анализе текущих объемов данных, хранящихся в отношениях БД, и на статистическом анализе хранимой информации. В большинстве СУБД ведется учет диапазона значений отдельного столбца с указанием процентного содержания для каждого диапазона. Поэтому при построении плана запроса СУБД может оценить объем промежуточных отношений и построить план таким образом, чтобы на наиболее ранних этапах выполнения запроса минимизировать количество строк, включаемых в промежуточные отношения.
Кроме ядра СУБД каждый поставщик обеспечивает специальные инструментальные средства, облегчающие администрирование БД и разработку новых проектов БД и пользовательских приложений для данного сервера. В последнее время практически все утилиты и инструментальные средства имеют развитый графический интерфейс.