
Макрос PegGrammar
| Вид материала | Документы |
- План Введение. Начало пути. Редактирование, удаление, переименование и назначение макросов, 283.36kb.
- Программирование действий– Макросы Функция, 304.28kb.
- Русская доктрина андрей Кобяков Виталий Аверьянов Владимир Кучеренко (Максим Калашников), 11986.64kb.
- Тема урока: Создание макросов в Microsoft Excel, 33.61kb.
- Шаг 1 Первый макрос, 909.7kb.
- Этот макрос написан на языке Visual Basic для программы Microsoft Word. Он предназначен, 28.77kb.
PegGrammar – очень молодой продукт, так что немудрено, что не все в нем еще работает как хотелось бы. Вот список известных проблем, которые со временем будут устранены:
- На сегодня PegGrammar не позволяет вмешиваться в процесс работы парсера. Однако в принципе это возможно. Впрочем, имеющиеся механизмы позволяют спокойно обходиться без этого.
- На сегодня не решен вопрос и с модульностью. PEG-нотация обеспечивает великолепный потенциал для поддержки модульности грамматик. Это обеспечивается тем, что нет нужды в отдельном лексическом анализаторе. Любой парсер может иметь необходимые ему «лексические правила» (в кавычках потому, что в PEG нет даже деления на лексические и синтаксические правила). В будущем мы постараемся реализовать возможность подключения готовых грамматик к другим грамматикам и, тем самым, формирования более сложных грамматик из ряда более простых. Например, общие правила разбора выражений можно вынести в отдельную грамматику и подключать там, где они нужны.
- Не позволяет разбирать многие контекстно-зависимые грамматики и неоднозначные грамматики, что делает его непригодным для разбора текстов на естественных языках.
Данные недоработки, кроме последнего пункта, не так сложно устранить. Буквально перед публикацией этой статьи я был вынужден удалить несколько пунктов из этого списка, так как соответствующие недоработки были устранены в PegGrammar.
Оставшиеся недоработки не устранены просто потому, что пока что соответствующие возможности не были востребованы на практике. А без реальных примеров использования очень легко получаются сложные в поддержке и никому не нужные на практике вещи.
Кроме того, к недостаткам PegGrammar можно отнести способ его реализации (в виде макроса Nemerle). Но, во-первых, недостатком это является только для тех, кто по каким-то причинам не приемлет Nemerle, а во-вторых, полученный парсер можно использовать из любого .NET-языка, что делает его применение не страшнее, чем применение любого построителя парсеров кодогенерирующего типа (например, ANTLR).
В заключении данного раздела необходимо упомянуть, что PegGrammar не позволяет разбирать леворекурсивные грамматики. Это особенность технологии рекурсивных парсеров. Существуют алгоритмы, позволяющие разбирать PEG-грамматики, содержащие левую рекурсию, но они используют неэффективные механизмы тотальной мемоизации и сильно усложняют алгоритм разбора. Если мы найдем красивый способ работы с левой рекурсией, то обязательно его реализуем. А пока что придется довольствоваться праворекурсивными грамматиками. Это не всегда удобно, так как многие грамматики описаны в терминах левой рекурсии, но научно доказано, что леворекурсивные и праворекурсивные контекстно-свободные грамматики равны между собой по мощности. Так что данное ограничение не сужает спектр разбираемых языков.
Достоинства PegGrammar
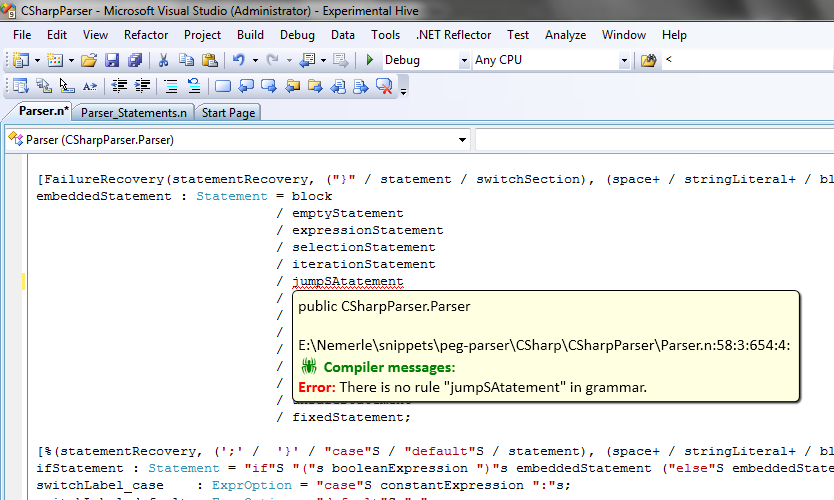
Рисунок 1. Отображение ошибок в граматике по мере редактирования (в реальном времени).
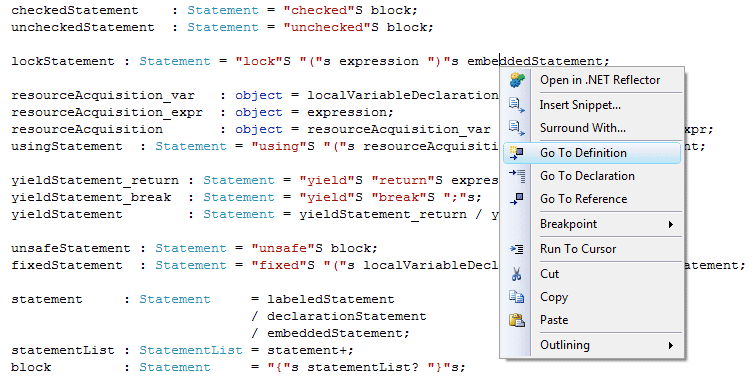
Рисунок 2. Переход к определению правила или к методу-обработчику.
К главным достоинствам PegGrammar можно отнести:
- «Шаговая доступность». Подключить PegGrammar к проекту не сложнее, чем использовать библиотеку регулярных выражений.
- Высокая скорость работы (при компиляции в Release). По имеющимся данным PegGrammar обгоняет не только многие парсеры полученные с помощью других генераторов парсеров, но и некоторые рукописные парсеры авторы которых выставляют скорость как одно из главных достоинств своих продуктов. Так реализация парсера JSON созданная с помощью PegGrammar оказалась примерно на треть быстрее аналогичного парсера из ссылка скрыта.
- Относительно легкая отладка полученного парсера (по сравнению с парсерами, использующими конечные автоматы).
- Отсутствие разделения на парсер и лексический анализатор. Вся грамматика (или ее часть) задается в одном месте и использует один и тот же формализм – PEG.
- Использование PEG-нотации. PEG очень выразителен, и легче понимается людьми (особенно работавшими с регулярными выражениями), так как описывает парсер языка, а не грамматику.
- PegGrammar обеспечивает удобные, быстрые и качественные средства обеспечения восстановления после обнаружения ошибок.
- Благодаря тому, что PegGrammar предоставляет концепцию областей видимости (Scopes), он позволяет разбирать ряд контекстно-зависимых грамматик вроде грамматик языков C, C++ или Nemerle.
- Высокая декларативность, обеспечиваемая отделением грамматики от семантических действий, упрощает разработку и сопровождение грамматик.
- Поддержка IDE. На сегодня в VS доступен (через контекстное меню) переход к определению правила, переход с правил к методам-обработчикам и обратно. Кроме того, доступны обычные для любого кода Nemerle свертка (folding) регионов и разнесение методов-обработчиков по разным файлам (за счет использования partial-классов). Это позволяет удобно структурировать правила и методы-обработчики и легко находить их. Также в IDE доступны сообщения об ошибках в грамматике, сообщения о несоответствии сигнатур обработчиков правил самим правилам. Все сообщения об ошибках выводятся как в консоль при компиляции, так и доступны в виде всплывающих подсказок в соответствующих местах грамматики. Кроме того, все генерируемые публичные методы классов, реализующих парсер, становятся доступны через ссылка скрыта