
Курс, 524 группа Адаптация комплекса программ M2dgd для работы на мвс с использованием среды параллельного программирования ost павлухин Павел
| Вид материала | Документы |
Содержание6.Результаты счета, сравнение с MPI Рис 12. Результат после 5000 шагов для параллельного(вверху) и последовательного(внизу) счета |
- Рабочая программа учебной дисциплины (модуля) Технологии параллельного программирования, 79.5kb.
- Лекция Языки и системы программирования. Структура данных, 436.98kb.
- Программа по курсу: современные технологии параллельного программирования (по выбору), 69.72kb.
- 1. Теоретические сведения, 771.46kb.
- Рабочая учебная программа по дисциплине «Технология программирования» Направление №230100, 109.02kb.
- Методические указания по выполнению контрольной работы с использованием компьютерных, 1010.76kb.
- Учебной дисциплины «Технология программирования и работ на эвм» для направления 010100., 38.85kb.
- Адаптация персонала, 260.18kb.
- Лекция 3 Инструментальное по. Классификация языков программирования, 90.16kb.
- Эволюция языков программирования, 493.92kb.
5.Постановка тестовой задачи
Для проверки корректности алгоритма и оценки его эффективности использовалась задача о коническом теле, мгновенно помещенном в однородный сверхзвуковой поток газа. Тело представляет собой конус с углом полураствора 20 градусов, сопряженный с цилиндром. Оно мгновенно помещается в трубу круглого сечения со сверхзвуковым однородным потоком газа (M=1.6). Отношение площади выходного отверстия к входному составляет 0.8 (рис.10
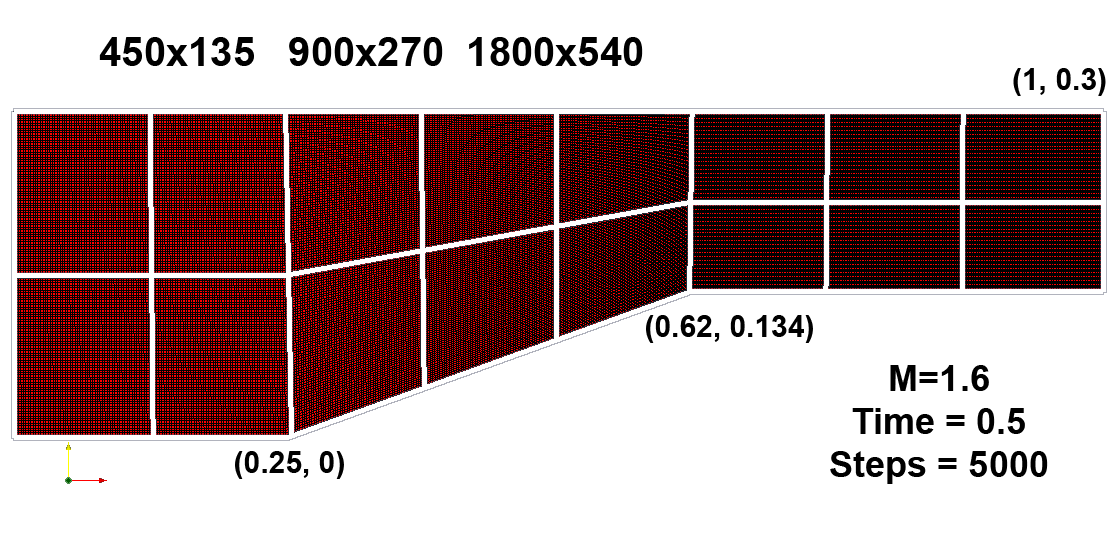 ).
).Рис 10. Задача о коническом теле.
Рассматривалась эволюция потока на интервале времени от 0 до 0.5 (обезразмеренное) с dt=0.0001 и количеством шагов по времени 5000, на каждом шаге выполнялось по 2 итерации. Сетка на области строилась с тремя разрешениями: 450х135, 900х270, 1800х540. На рис.10 изображено разбиение области на 16 блоков, обсчитывающихся параллельно.
6.Результаты счета, сравнение с MPI
Для проверки корректности было произведено сравнение результатов работы последовательного и параллельного алгоритмов на сетке 450х135 с числом шагов 500 и 5000, расчет параллельной версии проводился на 16 ядрах на МВС RSC-4 в ИПМ им.М.В.Келдыша РАН (128 ядер).

Рис 11. Результат после 500 шагов для параллельного(вверху) и последовательного(внизу) счета.

Выводы
Рис 12. Результат после 5000 шагов для параллельного(вверху) и последовательного(внизу) счета
На рис. 11 и 12 показано распределение плотности после 500 и 5000 шагов (цветовые различия из-за разных цветовых шкал, используемых для отображения). Как видно, результат работы двух версий программ совпадает.
В следующей таблице дается сравнение подходов OST и MPI с точки зрения прикладного программиста:
| OST | MPI |
| объектно-ориентированный подход для построения параллельной модели; обращение к удаленным объектам так же, как к локальным с непосредственным вызовом методов | модель параллельно выполняющихся процессов, взаимодействие между ними – через рассылку сообщений |
| автоматический алгоритм синхронизации, предоставляемый средой | синхронизация полностью организуется самим прикладным программистом |
| автоматическое назначение связей между объектами по заданной топологии | определение связей между процессами организуется самим прикладным программистом |
OST «берет на себя» организацию всей низкоуровневой (системной) части программирования, предоставляя прикладному программисту высокоуровневые средства для написания параллельных программ.
Для оценки эффективности двух реализаций был проведен счет тестовой задачи на трех различных разрешениях сеточного разбиения c 10 шагами по времени (запуск выполнялся на RSC-4).
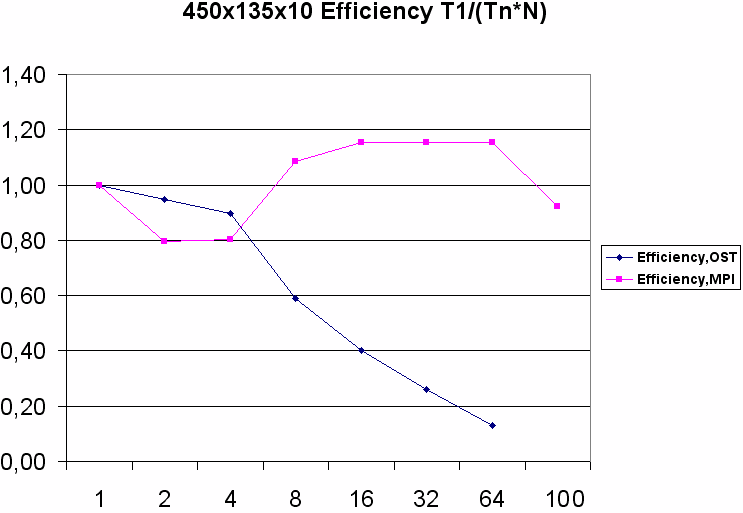
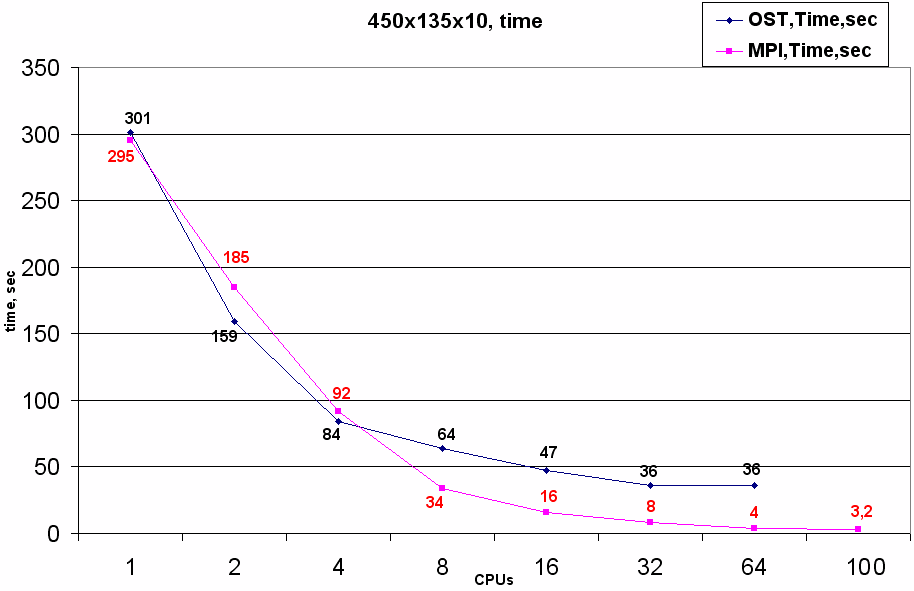
При счете области 450х135 на 2 и 4 ядрах обе реализации показывают высокую эффективность, с дальнейшим увеличением числа ядер эффективность MPI кода остается столь же высокой; для OST эффективность, начиная с 8 ядер, начинает падать и уже на 32 ядрах возникает насыщение, когда увеличение доступных ядер в 2 раза не дает никакого уменьшения времени счета. Это связано с неэффективной работой потоков (threads) в Python, когда вычисления в каждом блоке на одной итерации по времени становятся сравнимы с временем, затрачиваемым на обслуживание потоков синхронизации времени и передачи ячеек.
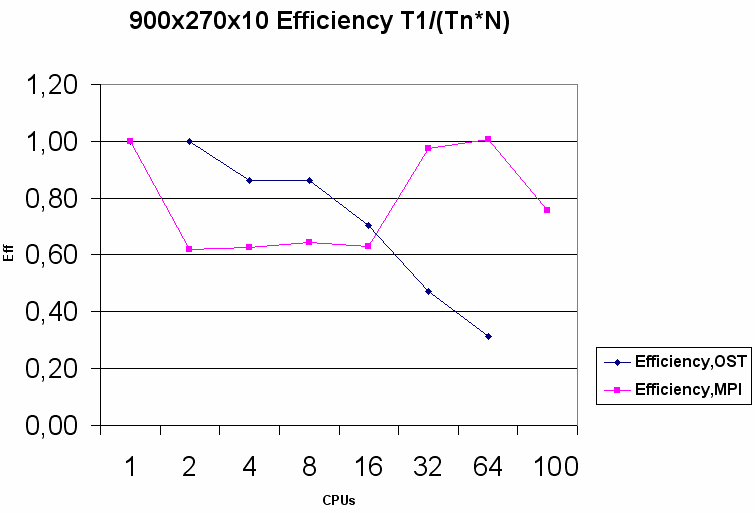
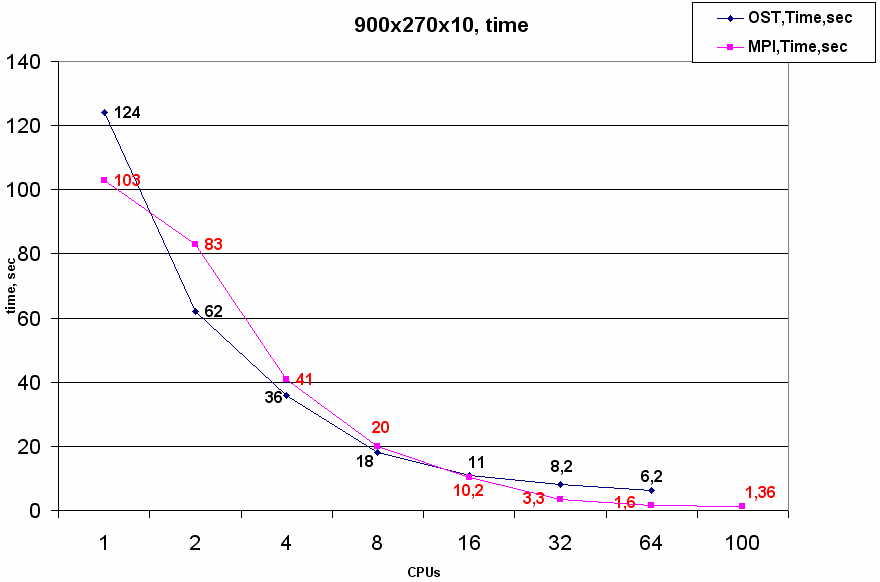
На области 900х270 наблюдается похожая картина, высокая эффективность OST версии сохраняется уже вплоть до 16 ядер, при дальнейшем увеличении числа ядер она значительно падает. Улучшение эффективности в сравнении с областью 450х135 связано с тем, что отношение времени счета в объекте к издержкам, связанным с обслуживанием потоков, увеличилось (каждый объект содержит в 4 раза больше ячеек).
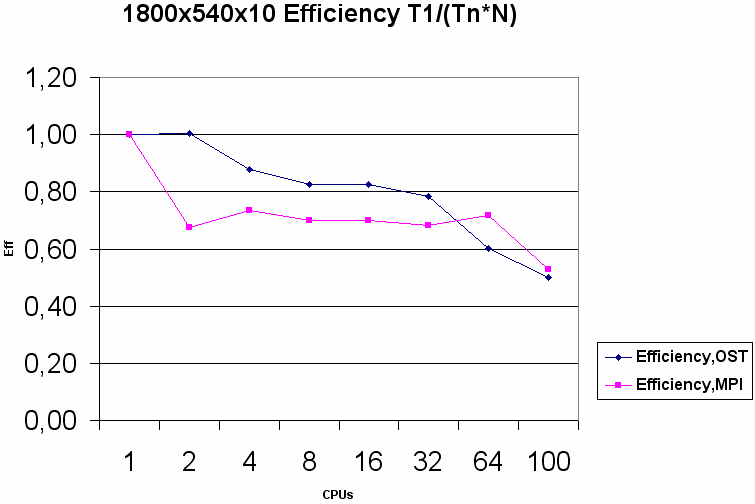
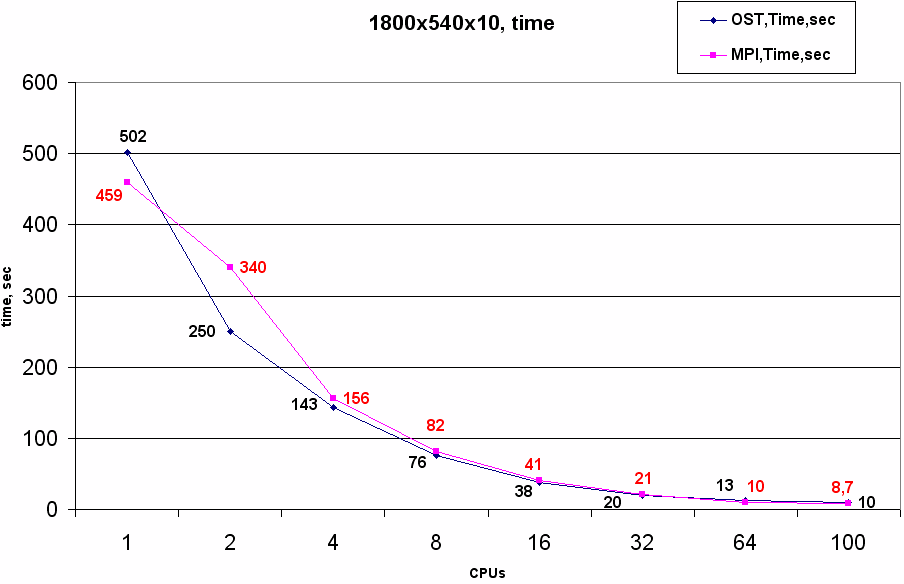
На области 1800х540 особенности работы потоков в Python практически не сказываются на эффективности во всех протестированных конфигурациях, и результаты OST оказываются близкими к MPI даже на 64 и 100 ядрах.
Выводы.
В работе был построен параллельный алгоритм для имеющегося программного комплекса M2DGD, доказана его корректность и эквивалентность существующей последовательной версии. Основным достоинством алгоритма, помимо его эффективности, является точное соблюдение его последовательной версии во всей расчетной области, а не приближенное (как в большинстве публикаций на эту тему), когда последовательный алгоритм реализуется только в определенных подобластях исходной расчетной области. Так же этот алгоритм реализован в OST с использованием средств, предлагаемых средой и облегчающих написание параллельных программ. На тестовой задаче были проведены верификационные расчеты, подтвердившие правильность работы параллельной версии. В сравнении с MPI версией алгоритма для прикладного программиста использование среды OST дает несколько важных преимуществ: более естественное представление расчетной модели в виде множества объектов с удаленным обращением между ними как при обычном локальном доступе; наличие простого в использовании алгоритма синхронизации, предоставляемого средой, и задание топологии объектов для автоматического назначения связей между объектами. По эффективности OST-версия проигрывает MPI на грубых сетках (с малым разрешением) на большом числе процессоров (что является следствием отсутствия контроля со стороны прикладного программиста за низкоуровневой частью системы). Падение эффективности – своего рода плата за высокоуровневые средства, доступные для программиста в OST. Но на сетках с высоким разрешением (1800х540), эффективность OST версии не уступает (а порой даже выше) эффективности MPI кода. Поскольку в реальных прикладных задачах особое внимание уделяется образованию мелкомасштабных структур в расчетной области, которые проявляются только на сетках с очень высоким разрешением, для расчета на которых требуется помимо значительного объема оперативной памяти (возможно, даже не доступного в пределах одного вычислительного узла) еще и значительное время (недели и месяцы), то использование OST в этом случае выглядит вполне оправданным, так как эффективность близка к MPI, но при этом доступны более удобные и естественные средства для высокоуровневого параллельного программирования.
Список использованных источников:
- ru
- I. Menshov, Y. Nakamura, Hybrid Explicit-Implicit, Unconditionally Stable Scheme for Unsteady Compressible Flows, AIAA Journal, Vol. 42, No. 3, pp. 551-559, 2004.
- Документация по языку Python - on.org