
Лекция 3 Текстовая информация
| Вид материала | Лекция |
- Защита информации и информационная безопасность лекция 2 Конфиденциальная информация, 30.97kb.
- Методические рекомендации по обучению базовому курсу информатики в 8 классe (умк, 747.62kb.
- Московский новый юридический институт информационные системы в экономике, 411.38kb.
- Лекция 1 Информация, свойства информации. Информация, 136.63kb.
- План: Введение. Постановка задачи. Концепция индивидуального решения. Исходные материалы., 9.65kb.
- Название проекта, 22.32kb.
- Лекция №1. Тема: «Введение», 40.76kb.
- Все программы и данные хранятся в долговременной (внешней) памяти компьютера в виде, 91.55kb.
- Тема Лекция, 34.13kb.
- Лекция Экономическая информация как часть информационного ресурса общества, 214.25kb.
Лекция 3
Текстовая информация
История создания и развития
Попытки создания славянской письменности до IX веке н. э. носили локальный характер. Есть свидетельства использования рунического и руноподобного письма, выдвигаются версии об узелковом письме. Около 863 г. н. э. братья Конcтантин (Кирилл) Философ и Мефодий из Солуни (Салоники) провели работу по стандартизации славянской письменности по приказу византийского императора Михаила III. Предположительно, это был алфавит из 43 букв. Долгое время дискуссионным оставался вопрос, была ли это кириллица (и в таком случае глаголицу считают тайнописью, появившейся после запрещения кириллицы) или глаголица (а кириллицу в таком случае часто приписывают болгарскому просветителю, ученику солунских братьев Клименту Охридскому) — азбуки, различающиеся исключительно начертанием. В настоящее время в науке преобладает точка зрения, согласно которой глаголица первична, а кириллица вторична. Неизвестно также, являлась ли азбука, которой пользовались Кирилл и Мефодий, модификацией существовавшей ранее славянской азбуки или братья-просветители создали её сами (используя, в частности, греческий алфавит и еврейское письмо).
Благодаря деятельности братьев-просветителей азбука получила очень широкое распространение, что привело в 885 году к запрещению её римским папой, боровшимся с результатами миссии Константина-Кирилла и Мефодия.
Первоначально кириллицей пользовались восточные славяне и часть южных, а также румыны; со временем их алфавиты несколько разошлись друг от друга, хотя начертание букв и принципы орфографии оставались (за исключением западносербского варианта, так называемой босанчицы) в целом едиными.
Брятья и ортодоксальные Славянские монахи Кирилл и Мефодий изобрели письмо называемое глаголицей в Македонии в году 863 как измененный греческий алфавит с расширениями для специальных Славянских звуков. Их ученый Клемент Охрид позже изобрел "Кириллическое" письмо, преобразовав глаголицу в более читаемый алфавит. В течение столетий Кириллическое письмо активно распространялось и преобразовывалось. Серьезную реформу Кириллица претерпела при Царе Петре Великом, который преобразовал ее в т.н. Романовскую форму (Гражданский шрифт).
В настоящее время Кириллический шрифт используется больше чем 70 языками от Славянского русского до языков Восточной Европы, Украины, Белоруссии, Болгарии, Сербии и Македонии.
Русская кириллица. Гражданский шрифт
В 1708 - 1711 гг. Пётр I предпринял реформу русской письменности, устранив надстрочные знаки, упразднив несколько букв и узаконив другое (приближенное к латинским шрифтам того времени) начертание оставшихся – так называемый гражданский шрифт. Вскоре на гражданский шрифт (с соответствующими изменениями) перешли сербы, позже - болгары; румыны же в 1860-е годы отказались от кириллицы в пользу латинской письменности (что интересно, у них одно время использовался «переходный» алфавит, представлявший из себя смесь латинских и кириллических букв). Гражданским шрифтом с минимальными изменениями начертаний (самое крупное — замена m-образной буквы «т» на нынешнюю ее форму) мы пользуемся и поныне.
За три века русский алфавит претерпел ряд реформ. Количество букв в основном уменьшалось, исключение составляет буквы «э» и «й» (употреблявшиеся и ранее, но узаконенные в XVIII веке) и единственная «авторская» буква - «ё», предложенная княгиней Екатериной Романовной Дашковой. Последняя крупная реформа русской письменности была проведена в 1917 - 1918 г.; в ее результате появился современный русский алфавит, состоящий из 33 букв. Этот алфавит также стал основой многих неславянских языков бывшего СССР и Монголии (письменность для которых ранее XX века отсутствовала или была основана на других видах письменности: арабской, китайской, старомонгольской и т. п.).
Азбука кириллицы
Состав первоначальной кириллической азбуки нам неизвестен; «классическая» старославянская кириллица из 43 букв, вероятно, частью содержит более поздние буквы (ы, оу, йотированные). Кириллица целиком включает греческий алфавит, но некоторые сугубо греческие буквы (кси, пси, фита, ижица) стоят не на своем исходном месте, а вынесены в конец. Буквы кириллицы используются для записи чисел в точности по греческой системе (только вместо пары совсем архаических знаков, которые даже в классический 24-буквенный греческий алфавит не входят, приспособлены другие славянские буквы). Буквы кириллицы поименованы; начальная часть алфавита названа осмысленными словами, которые даже выстраиваются в понятные словосочетания; конец же азбуки темен, в нем смешаны греческие названия, какие-то искусственно выглядящие рычащие слова (ферт, хер, червь, ер), названия вроде бессмысленных нынешних (цы, ша, ща) и прочие загадки.
Кириллический шрифт
Н
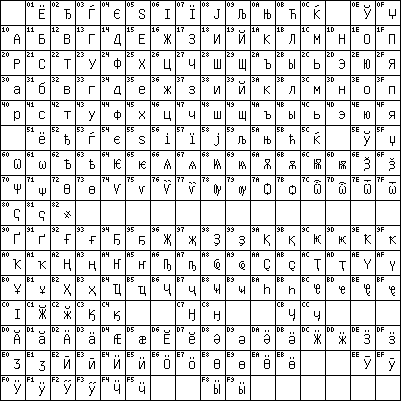
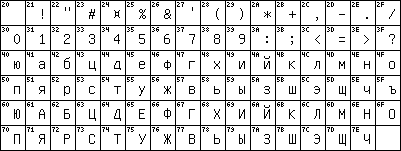 е смотря на то, что ISO 8859 содержит стандартный Кириллический шрифт, существует большое количество других Кириллических кодирований, используемых на компьютерах во всем мире. Каждый шрифт иллюстрирован растровым форматом обмена графическими данными наряду с основным Уникодом, отображающим таблицу и средство разработки бизнес-модели (X/Unix) шрифт
е смотря на то, что ISO 8859 содержит стандартный Кириллический шрифт, существует большое количество других Кириллических кодирований, используемых на компьютерах во всем мире. Каждый шрифт иллюстрирован растровым форматом обмена графическими данными наряду с основным Уникодом, отображающим таблицу и средство разработки бизнес-модели (X/Unix) шрифт GOST-13052 – KOI-0 (Кодировка для обмена и обработки информации)
Первым стандартизированным Кириллическим компьютерным шрифтом является шрифт стандарта GOST 13052. 7bit шрифт кодировал символы российского алфавита (который так же удовлетворяет все болгарские потребности в шрифте) и соответствовал в кодировке ASCII (ISO-646) символам противоположного регистра. Чтобы уменьшить алфавит до 32 символов, пожертвовали буквой ё в позиции =7F, она представляет конец файла =-1
GOST-19768-74: KOI-7 и KOI-8
В
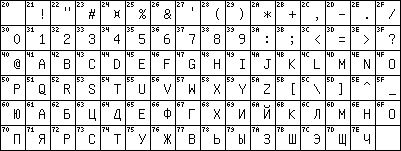 1974 появился стандарт GOST 19768-74, в котором смешивались два шрифта латинский и кириллический в одном наборе. 7bit таблица названная KOI-7 представляла только заглавные буквы:
1974 появился стандарт GOST 19768-74, в котором смешивались два шрифта латинский и кириллический в одном наборе. 7bit таблица названная KOI-7 представляла только заглавные буквы:Оригинал KOI-8
В
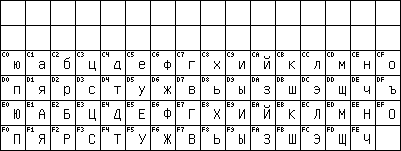 торой, определенной в GOST 19768-74 была 8-bit кодировка (KOI-8), которая давала разборчивый текст в стандарте ASCII. Ее можно назвать первым Кириллическим стандартом ASCII.
торой, определенной в GOST 19768-74 была 8-bit кодировка (KOI-8), которая давала разборчивый текст в стандарте ASCII. Ее можно назвать первым Кириллическим стандартом ASCII. KOI-8 with ë
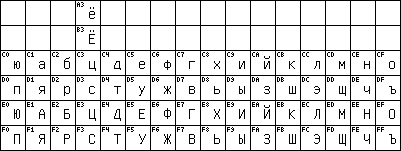
KOI-8 входит в Европу: ISO-IR-111 (ECMA-Cyrillic) Кириллица Европейской Ассоциации производителей ЭВМ
В
 середине 1980-ых, комитет европейской ассоциации производителей ЭВМ, разрабатывающий ISO-8859 в кодировке ISO-8859-5 пожелал сохранить совместимость с установленной базовой системой десятилетнего стандарта KOI-8, были добавлены отсутствующие Украинские, Белорусские, Сербские и Македонские символы в неиспользованные коды. Их проект был издан как ECMA-113 в 1986 и черновой международный эталон DIS-8859-5 в 1987 и был зарегистрирован под номером 111 в международном регистре наборов символов ISO-2022-управляющие последовательности. Было присвоено название ISO-IR-111 (ECMA-Cyrillic)
середине 1980-ых, комитет европейской ассоциации производителей ЭВМ, разрабатывающий ISO-8859 в кодировке ISO-8859-5 пожелал сохранить совместимость с установленной базовой системой десятилетнего стандарта KOI-8, были добавлены отсутствующие Украинские, Белорусские, Сербские и Македонские символы в неиспользованные коды. Их проект был издан как ECMA-113 в 1986 и черновой международный эталон DIS-8859-5 в 1987 и был зарегистрирован под номером 111 в международном регистре наборов символов ISO-2022-управляющие последовательности. Было присвоено название ISO-IR-111 (ECMA-Cyrillic)GOST-19768-87 изменяет все
I
 SO-IR-111 никогда не принимался как заключительный стандарт ISO-8859-5. Во времена перестройки GOST пересмотрел стандарт 19768 в 1987 и создал несовместимый с ASCII новый GOST 19768-87, который перемещал русские символы одна строку выше и упорядочил их в родном русском порядке словаря (ABVGD) вместо KOI порядка (ABCDE)
SO-IR-111 никогда не принимался как заключительный стандарт ISO-8859-5. Во времена перестройки GOST пересмотрел стандарт 19768 в 1987 и создал несовместимый с ASCII новый GOST 19768-87, который перемещал русские символы одна строку выше и упорядочил их в родном русском порядке словаря (ABVGD) вместо KOI порядка (ABCDE)ISO-8859-5 Cyrillic

Европейская ассоциация производителей ЭВМ немедленно отреагировала на пожелания GOST и переставила символы ISO-IR-111 на позиции нового кода GOST 19768-87. Пересмотренное предложение было издано как 2-ое издание ECMA-113:1988 заменяющее первоначальную версию ECMA -113:1986. Новый стандарт создавал препятствия нормальному переводу символов и по настоящее время мы имеем международный эталон ISO-8859-5, который является настолько ненормативным, что почти никто им не пользуется
KOI8-R
С
 появлением Российского Internet использование Кириллицы стандарта ISO-8859-5 в почтовой связи и телеконференциях было затруднено. Андреем Черновым был предложен Кириллический Набор символов "KOI8-R", который был представлен как фактический стандарт на Internet. KOI8-R был позже также переименован в CP878, который содержит пунктир KOI8 плюс блок символов, позволяющих отображать примитивные рисунки
появлением Российского Internet использование Кириллицы стандарта ISO-8859-5 в почтовой связи и телеконференциях было затруднено. Андреем Черновым был предложен Кириллический Набор символов "KOI8-R", который был представлен как фактический стандарт на Internet. KOI8-R был позже также переименован в CP878, который содержит пунктир KOI8 плюс блок символов, позволяющих отображать примитивные рисункиMicrosoft's CP1251
К
 омпания Microsoft предложила свою кодировку символов русского языка – т.н. WinCyrillic кодовая страница Windows Microsoft CP1251, для которого Microsoft зарегистрировал бренд "Windows 1251". В нашей стране стандарт этой кодировки не принят, не принят он и международными организациями по стандартизации. Но с декабря 1997 веб-сервер GOST приветствует нас с charset=WINDOWS-1251 - GOST! CP1251 имеет богатый набор символов, несовместимый ни с ISO-IR-111 (KOI8), ни с ISO-8859-5
омпания Microsoft предложила свою кодировку символов русского языка – т.н. WinCyrillic кодовая страница Windows Microsoft CP1251, для которого Microsoft зарегистрировал бренд "Windows 1251". В нашей стране стандарт этой кодировки не принят, не принят он и международными организациями по стандартизации. Но с декабря 1997 веб-сервер GOST приветствует нас с charset=WINDOWS-1251 - GOST! CP1251 имеет богатый набор символов, несовместимый ни с ISO-IR-111 (KOI8), ни с ISO-8859-5Unicode ISO-10646
Unicode – это стандарт кодировки символов, который поддерживает большинство систем записи символов. Первоначально, идея Unicode состояла в том, чтобы каждый из символов кодировался не 8-ю, а 16-ю битами, что дает возможность определить 65536 символов, вместо 256. Наборы символов ASCII и ISO 8859-1 (Latin-1) являются поднаборами Unicode, и сохранили числовые значения своих символов. Например, Символ 'A' имеет значение 0x41 в ASCII, Latin-1 и Unicode.
Класс QString хранит строки как Unicode. Каждый символ в QString является 16-ти битным QChar, а не 8-ми битным char. Ниже приводится два способа записи символа 'A' в строку:
str[0] = 'A';
str[0] = QChar(0x41);
Мы можем записать любой из символов Unicode, по его числовому значению.
UTF-8
Еще одна кодировка, которая поддерживает весь набор символов Unicode - это UTF-8. Ее основное преимущество перед UTF-16 состоит в том, что для хранения символов ASCII (символы в диапазоне 0x00..0x7F) она использует всего один байт. Все остальные символы, включая символы Latin-1, числовые значения которых лежат выше 0x7F, представлены многобайтными последовательностями. Для хранения текста, состоящего преимущественно из ASCII-символов, в формате UTF-8 потребуется практически в два раза меньше пространства, чем в UTF-16.
П
 роблемы Юникода
роблемы ЮникодаКак любая изобретённая человеком система, Юникод не свободен от недостатков (хотя, в основном, они связаны с возможностями обработчиков текста, а не непосредственно с принципом кодирования).
- Некоторые системы письма всё ещё не представлены должным образом в Юникоде. Например, отсутствуют некоторые буквы традиционной письменности церковнославянского языка. Эта письменность содержит много дополнительных графических элементов (такие, как титла и выносные буквы). Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, пока не реализовано.
- Тексты на китайском, корейском и японском языке имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Переключение горизонтального и вертикального написания для этих языков не предусмотрено в Юникоде — это должно осуществляться средствами языков разметки или внутренними механизмами текстовых процессоров.
- Первоначальная версия Юникода предполагала наличие большого количества готовых символов, в последующем было отдано предпочтение сочетанию букв с диакритическими модифицирующими знаками (Combining diacritics). Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде монолитных символов, хотя могут быть представлены и набором базового символа с последующим диакритическим знаком, то есть в составной форме (Decomposed): Е+ ̈ (U+0415 U+0308), И+ ̆ (U+0418 U+0306). В то же время множество символов из языков с алфавитами на основе кириллицы не имеют монолитных форм.
- Юникод предусматривает возможность разных начертаний одного и того же символа в зависимости от языка. Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханджа), но при этом в Юникоде обозначаться одним и тем же символом (так называемая CJK-унификация), хотя упрощённые и полные иероглифы всё же имеют разные коды. Часто возникают накладки, когда, например, японский текст выглядит «по-китайски». Аналогично, русский и сербский языки используют разное начертание курсивных букв п и т (в сербском они выглядят как и и ш). Поэтому нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку.
- Файлы с текстом в Юникоде занимают больше места в памяти, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков, алфавит которых укладывается в ASCII). Однако с увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной.
- Хотя поддержка Юникода реализована в наиболее распространённых операционных системах, не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки BOM и плохо поддерживаются диакритические символы. Проблема является временной и есть следствие сравнительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).