
Общая характеристика работы
| Вид материала | Автореферат |
- Содержание лекций Модели местного самоуправления в России Местное самоуправление:, 786.51kb.
- Общая характеристика работы актуальность работы, 336.09kb.
- Общая характеристика работы актуальность работы, 236.99kb.
- Общая характеристика работы актуальность работы, 227.87kb.
- Общая характеристика работы актуальность работы, 227.87kb.
- Задачи физического воспитания детей дошкольного возраста. Общая характеристика средств, 34.6kb.
- Реферат по курсу: экология на тему: Общая характеристика экосистем, как, 726.64kb.
- Научная работа студентов, 2153.55kb.
- Научная работа студентов, 2114.42kb.
- Общая характеристика работы актуальность работы, 487.01kb.
Санкт-Петербургский институт информатики и автоматизации Российской академии наук
На правах рукописи
ЛИ
Изольда Валерьевна
Разработка методов представления и обработки естественного языка для проблемно-ориентированных систем автоматического понимания речи
Специальность 05.13.11 – Математическое и программное обеспечение вычислительных машин, комплексов и компьютерных сетей
АВТОРЕФЕРАТ
диссертации на соискание ученой степени
кандидата технических наук
Санкт-Петербург
2004
Р
абота выполнена в Федеральном государственном бюджетном учреждении науки Санкт-Петербургском институте информатики и автоматизации Российской академии наук (СПИИРАН).
Научный руководитель:
доктор технических наук,
профессор Косарев Юрий Александрович
Официальные оппоненты:
доктор технических наук,
профессор Тимофеев Адиль Васильевич
кандидат технических наук,
доцент Станкевич Лев Александрович
Ведущая организация:
Санкт-Петербургский Государственный Электротехнический Университет
Защита состоится «____» ______________2004 г. в ____ часов на заседании диссертационного совета Д.002.199.01 при Санкт-Петербургском институте информатики и автоматизации РАН по адресу: 199178, Санкт-Петербург, В.О., 14 линия, 39.
С диссертацией можно ознакомиться в библиотеке Санкт-Петербургского института информатики и автоматизации РАН
Автореферат разослан «____» ______________2004 г.
Ученый секретарь
диссертационного совета Д.002.199.01
Нестерук Филипп Геннадьевич
общая характеристика работы
Актуальность темы диссертации. Обеспечение взаимодействия с ЭВМ на естественном языке является важнейшей задачей исследований по искусственному интеллекту. Сейчас речевые технологии активно включаются в различные сферы нашей жизни, способствуя ускорению процессов информационного обмена в различных предметных областях, что привело к развитию проблемно-ориентированных систем понимания речи. При этом наиболее остро проявилась проблема разрешения языковой неоднозначности, а также проблема учета информации об иерархии понятий и терминов определенной предметной области. Первая проблема обусловлена многозначностью слов естественного языка, ошибками распознавания отдельных слов и синтаксическими неточностями в речи диктора. Вторая - ведет к терминологической путанице, возникающей из-за разницы в толковании терминов у системы и пользователя. Решение этих проблем связано с адекватным отображением естественного языка во внутреннее машинное представление. Для этого следует эффективно использовать всю доступную априорную информацию, включая синтаксис, семантику и прагматику.
Как правило, подходы к представлению и обработке естественного языка используют только два вида информации: синтаксическую и семантическую. Причем основной упор делается на синтаксис, т.е. методы грамматического разбора. Синтаксический анализ становится самоцелью и приводит к построению грамматически правильных предложений, которые, однако, могут содержать смысловую неоднозначность. В результате многолетних исследований в области обработки естественного языка и речи было установлено, что для решения проблемы неоднозначности необходимо использовать информацию о соотнесении знаков естественного языка, объектов и событий реальной действительности, к которым относятся семантическая и прагматическая информация, и которые представляют собой по существу информацию о предметной области. Стало очевидным, что сложность понимания и методы обработки естественного языка определяются не только структурой и особенностями входного текста, но и представлением о предметной области, в рамках которой осуществляется человеко-машинное взаимодействие.
Существует достаточно обширный набор средств представления знаний о предметной области, наиболее эффективным на сегодняшний день считается онтология. Применение этих средств для представления семантической и прагматической информации в области речевых технологий является актуальной темой исследования, поскольку ведет к разрешению проблем языковой неоднозначности и учета иерархии понятий предметной области при автоматическом понимании речи.
Цель работы и задачи исследования. Основной целью диссертационной работы является разработка методов разрешения неоднозначности естественного языка и учета иерархии понятий при представлении и обработке естественного языка в системах автоматического понимания речи. Для достижения поставленной цели в диссертационной работе поставлены и решены следующие задачи:
- Анализ основных подходов к представлению и обработке естественного языка;
- Построение эффективной модели представления и обработки естественного языка;
- Разработка методов эффективного семантико-прагматического анализа.
Методы исследования. Для решения поставленных задач в работе используются методы теории информации, теории множеств, экспертного, статистического и эвристического анализа, а также методы итерационного поиска. Компьютерная реализация разработанных алгоритмов производилась на основе объектно-ориентированного подхода.
Положения, выносимые на защиту:
- Модификация базовой модели представления естественного языка за счет внесения онтологии предметной области.
- Метод верификации онтологического подмножества гипотезы входной фразы, позволяющий отсечь гипотезы входной фразы, содержащие семантически несвязные словосочетания.
- Метод оценки лексической близости ситуативных переходов гипотезе входной фразы, позволяющий отсечь заведомо бесперспективные ситуативные переходы при ситуативном анализе.
- Модификация базовой модели обработки естественно-языкового высказывания.
Научная новизна работы состоит в следующем:
- Разработана эффективная модель представления естественного языка за счет использования онтологии предметной области в виде иерархии понятий предметной области, которая учитывает семантическую информацию и позволяет легко расширять предметную область.
- Разработан алгоритм верификации онтологического подмножества гипотезы входной фразы, позволяющий оценить его семантическую связность и существенно ускорить процесс обработки речи за счет предварительного отсечения гипотез, содержащих семантически несвязные понятия.
- Разработан метод оценки лексической близости ситуативных переходов гипотезе входной фразы, позволяющий избежать последовательного перебора всех возможных канонических перефразировок при определении квантитативной оценки расстояния между входной гипотезой и каноническими перефразировками.
Обоснованность и достоверность научных положений, основных выводов и результатов диссертации обеспечивается за счет тщательного анализа состояния исследований в данной области, подтверждается корректностью предложенных моделей, алгоритмов и согласованностью результатов, полученных при компьютерной реализации, а также апробацией основных теоретических положений диссертации в печатных трудах и докладах на международных научных конференциях.
Практическая ценность работы. Разработанные модели и алгоритмы направлены на разрешение проблемы адекватного отображения естественно-языкового представления во внутреннюю информационную модель, которая представлена ситуативной базой данных, матрицы межсловных ассоциаций и онтологией предметной области.
Разработанный метод верификации онтологического подмножества входной гипотезы позволяет оценить семантическую связность гипотезы входной фразы и обеспечивает систему понимания механизмом обобщения терминов предметной области. В результате пользователь может использовать широкий спектр понятий и терминов предметной области при взаимодействии с прикладной системой автоматического понимания речи.
Разработанный в рамках настоящего диссертационного исследования алгоритм оценки лексической близости ситуативных переходов гипотезе входной фразы позволяет уйти от последовательного перебора всех канонических перефразировок за счет предварительного анализа ситуативных переходов и отсечения заведомо бесперспективных, что позволило существенно повысить скорость ситуативной обработки.
За счет внесения онтологии, использования алгоритмов верификации онтологического подмножества и метода оценки лексической близости ситуативных переходов достигается сокращение избыточности модели представления естественного языка и повышение скорости обработки гипотез входной фразы.
Реализация результатов работы. Исследования, отраженные в диссертации, проведены в рамках научно-исследовательских работ: СПб НЦ РАН: «Разработка методов автоматического перевода устной речи» (№ 01.2.00309944) и «Перевод устной речи на основе интегрального подхода: исследование и применение ситуативной информации» (№01.2.00309949) (2002-2003гг.); ФЦП «Интеграция»: Образовательно-исследовательский центр языка и речи, № 326.81; проект МНТЦ № 1993P (задача 4) «Модель голосового управления подвижным объектом». Кроме того, результаты диссертационной работы использованы при разработке средств голосового доступа к информационной системе «Автомаркет» для компании «BridgeQuest».
Апробация результатов работы. Основные положения и результаты диссертационной работы представлялись на Международных конференциях «Речь и Компьютер» SPECOM (Санкт-Петербург 2000, Москва 2001, Санкт-Петербург 2002, Москва 2003, Санкт-Петербург 2004), IX международной конференции «Региональная информатика РИ-2004» (Санкт-Петербург 2004).
Публикации. Основные результаты по материалам диссертационной работы опубликованы в 9 печатных работах.
Структура и объем работы. Диссертация объемом 132 машинописные страницы, содержит введение, четыре главы и заключение, список литературы (106 наименований), 15 таблиц, 42 рисунок.
содержание работы
Во введении обоснована важность и актуальность темы диссертации, сформулированы цели диссертационной работы и решаемые задачи, определяется научная новизна работы и ее практическая значимость, кратко описаны разработанные методы и алгоритмы, а также представлены основные результаты их реализации в экспериментально-исследовательских моделях речевого диалога.
В первой главе диссертации рассмотрен анализ состояния дел в области автоматического понимания речи. Качественному пониманию речи препятствуют факторы, связанные с соотнесением естественно-языкового высказывания с ожидаемыми действиями системы. К ним относятся неоднозначности, обусловленные синтаксическими неточностями, оговорками диктора и многозначностью слов, а также наличие различных уровней обобщения тех или иных специфических терминов предметной области, которое ведет к терминологической путанице. Поэтому основными проблемами понимания речи являются семантико-синтаксическая неоднозначность речевого высказывания, а также учет иерархии понятий предметной области. Эти проблемы возникают в условиях недостаточности априорной информации о естественном языке, поэтому решение этих проблем в первую очередь связано с адекватным отображением априорной информации о естественном языке во внутреннее машинное представление.
В результате обзора существующих методов представления и обработки ЕЯ были выделены три основных подхода: лингвистический, семантический и прагматический. Лингвистические теории построения модели естественного языка, основанные на извлечении правильных синтаксических конструкций ЕЯ. Одной из наиболее известных является теория трансформационных грамматик И. Хомского, которая предлагает формально-логическую модель, в виде синтаксического дерева разбора на основе правил. Статистический подход к представлению естественно-языкового текста был предложен в начале 80-х Ф. Джелинеком. Статистическая модель n-грамм строится на основе показательных текстов предметной области. Её цель состоит в оценке вероятности появления некоторой цепочки слов w1,w2,…,wq. Однако, такие модели позволяют только оценить синтаксическую корректность фразы, но не учитывают семантических связей и, следовательно, не решают проблему семантической неоднозначности естественно-языкового высказывания.
Таким образом, избыточность синтаксического анализа не позволяет решить проблему установления семантических связей. Попытки построения семантически связных текстов привели к появлению теории семантических падежей Филлмора, в которой смысл предложения рассматривается как форма сообщения, выражающая определенный смысл. Одна из наиболее популярных идей, используемых в семантическом анализе, основана на предположение о возможности прямого отображения между предикатно-аргументной структурой и поверхностным языковым представлением. Она была предложена Й. Уилксом в виде теории семантики предпочтений. Одним из первых эту концепцию реализовал Б. Богураев в 1979г. Реализация представляла собой систему для описания семантических предпочтений и применялась для системы обработки запросов к базе данных. Семантический подход позволил рассматривать слово в зависимости от его предметной прикрепленности. В результате возникла необходимость учета прагматической информации, помимо модели языка стала учитываться модель предметной области. В области искусственного интеллекта разработан ряд средств представления знаний о предметной области, одним из наиболее эффективных на сегодняшний день среди них является онтология.
В результате многолетних исследований в области проблем автоматического понимания речи и естественно-языковой неоднозначности была осознана необходимость комплексного подхода к построению семантико-синтаксической модели языка и прагматической модели ПО. При таком подходе синтаксическая информация используется как вспомогательная и позволяет оценить грамматическую корректность естественно-языковых конструкций, семантическая информация накладывает связи между знаками естественного языка, а прагматическая информация соотносит знаки естественного языка с реальными объектами и ситуациями.
Таким образом, анализ существующих подходов к представлению и обработке естественного языка показал, что существует ряд средств эффективного представления и обработки естественного языка, применение которых в системах автоматического понимания речи позволит решить проблему неоднозначности и учесть иерархию понятий ПО.
Во второй главе приводится описание интегральной модели понимания речи (разработанной ранее в группе речевой информатики СПИИРАН). Модель содержит модули акустического и естественно-языкового анализа. В данной работе более полно рассматривается уровень естественно-языкового анализа, поскольку он претерпел изменения за счет модификации представления и обработки естественного языка, учитывающих иерархию терминов ПО.
Б
 азовая модель интегрального понимания речи использует ассоциативный и ситуативный виды естественно-языкового анализа. Ситуативная модель описывает модель восприятия мира, ограниченную конкретной предметной областью, и может быть представлена ориентированным графом, где узлами являются ситуации, возможные в данной предметной области, а дуги - переходы между ситуациями, которые могут быть отражены наборами возможных перефразировок:
азовая модель интегрального понимания речи использует ассоциативный и ситуативный виды естественно-языкового анализа. Ситуативная модель описывает модель восприятия мира, ограниченную конкретной предметной областью, и может быть представлена ориентированным графом, где узлами являются ситуации, возможные в данной предметной области, а дуги - переходы между ситуациями, которые могут быть отражены наборами возможных перефразировок: 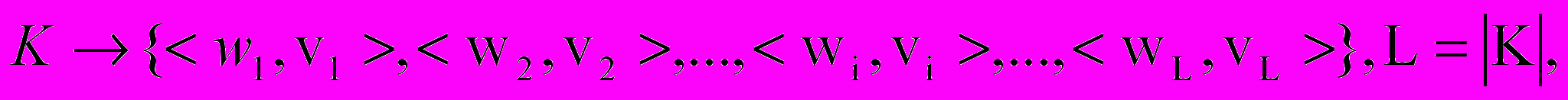
K- каноническая фраза в наборе возможных перефразировок, которая представлена множеством пар
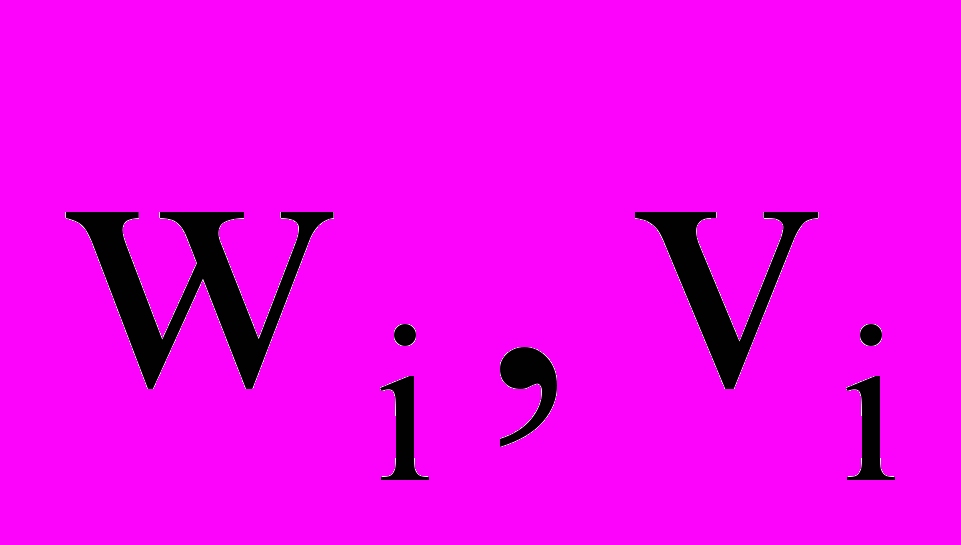 , где wi – слово из фразы, vi - вес слова во фразе, при этом сумма весов по фразе постоянна и одинакова для всех фраз ситуативной модели, L – длина канонической перефразировки.
, где wi – слово из фразы, vi - вес слова во фразе, при этом сумма весов по фразе постоянна и одинакова для всех фраз ситуативной модели, L – длина канонической перефразировки. На основе всех канонических перефразировок, заданных в ситуативной модели строится ассоциативная модель, которая представляет собой матрицу межсловных ассоциаций. В результате ассоциативного анализа получают количественную меру соответствия гипотезы одновременно синтаксису и семантике, заданным в данной ПО.
Ситуативный анализ позволяет разрешить семантико-прагматическую неоднозначность входной фразы и оценить степень соответствия анализируемой гипотезы фразы F и возможных ситуативных переходов. При этом вычисляется насколько гипотеза входной фразы коррелируется с каждой канонической перефразировкой:

где A1=F/K, A2=K/F, M=|F|, L=|K|, а p1, p2 – весовые коэффициенты, которые позволяют минимизировать влияние случайных или незначащих слов на оценку D(F,K), которая вычисляется для всех канонических перефразировок, что приводит к избыточности ситуативного анализа.
Кроме того, существенный недостаток базовой модели интегрального понимания проявляется при учете иерархии понятий ПО. При этом возникает избыточность представления перефразировок для каждого перехода, содержащего синонимичные понятия или понятия, различного уровня обобщения. Пример устранения такой избыточности представлен на рисунке 1. Как видно из примера, перефразировки тиражируются как в рамках одного набора перефразировок, так и для каждого ситуативного перехода. Наличие обобщающего понятия позволяет представить ситуативные переходы более компактно.
Для решения проблемы учета иерархии понятий предлагается использовать простейший вид онтологии: классификацию терминов ПО в формате XML, который удовлетворяет критериям расширяемости онтологии, и, в то же время, позволяет ввести набор понятий, достаточный для моделирования необходимой модели мира в задаче речевого взаимодействия. Построение онтологии начинается от корневого, наиболее обобщенного понятия, и далее по пути классификации объектов предметной области по общим признакам выстраивается иерархия понятий предметной области.

Рис. 1. Пример устранения избыточности ситуативной модели
Онтология в интегральной модели представляет собой простую иерархическую систему понятий (терминов предметной области), связанных между собой отношением is_a («быть элементом класса»). Отношение is_a имеет фиксированную заранее семантику и позволяет организовывать структуру понятий онтологии в виде дерева.
В результате внесения онтологии ПО в рамках ситуативной модели было модифицировано представление канонической перефразировки K (рис. 2), которая теперь состоит из двух подмножеств: подмножество слов, однозначно интерпретируемых
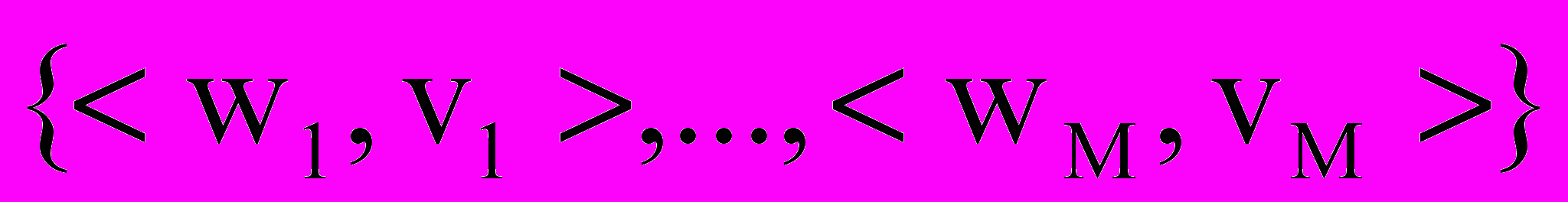 , и подмножество слов из онтологии ПО
, и подмножество слов из онтологии ПО . Соответственно при обработке речевого сигнала гипотеза фразы должна быть сформирована в том же формате. Теперь она содержит два подмножества: подмножество слов, однозначно интерпретируемых в рамках определенного перехода
. Соответственно при обработке речевого сигнала гипотеза фразы должна быть сформирована в том же формате. Теперь она содержит два подмножества: подмножество слов, однозначно интерпретируемых в рамках определенного перехода  , и онтологическое подмножество
, и онтологическое подмножество  , элементы которого принадлежат онтологии и должны быть проверены на правомерность их совместного использования в анализируемой гипотезе входной фразы
, элементы которого принадлежат онтологии и должны быть проверены на правомерность их совместного использования в анализируемой гипотезе входной фразы  :
:
Кроме того, наличие обобщающих понятий обеспечивает уменьшение неоднозначности на ассоциативном уровне и значительное сокращение соответствующей базы данных за счет объединения нескольких элементов одного уровня и их оценок семантической связности с остальными словами в одну группу.
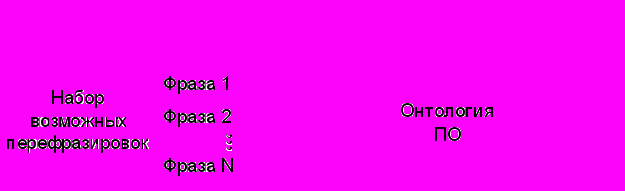
Рис. 2. Модификация представления канонической перефразировки в ситуативной модели
Таким образом, внесение онтологии позволило учесть иерархию понятий в ходе семантико-прагматического анализа и устранить избыточность в представлении ситуативной и ассоциативной информации.
Третья глава описывает разработанные автором метод верификации онтологического подмножества на основе онтологии ПО и метод оценки лексической близости ситуативных переходов гипотезе входной фразы. Оба метода направлены на предварительную оценку поступающих на ситуативный анализ гипотез фраз. Первый метод позволяет отсечь семантически неверные гипотезы, опираясь на онтологическую модель, а второй – осуществляет анализ множества канонических перефразировок с целью отсечения маловероятных, за счет предварительного лексического анализа. В результате повышается точность понимания, а скорость ситуативного анализа увеличивается в несколько раз.
В методе верификации онтологического подмножества выполняется поиск элементов подмножества
 в онтологии ПО, выявляется наличие или отсутствие прямых родственных связей между этими элементами, а также определяются обобщающие понятия для каждого из элементов.
в онтологии ПО, выявляется наличие или отсутствие прямых родственных связей между этими элементами, а также определяются обобщающие понятия для каждого из элементов.Упрощенная схема алгоритма представлена на рисунке 3. Здесь выполняется циклическая обработка онтологических подмножеств
множества гипотез фраз F. В первом блоке осуществляется извлечение цепочек предков каждого элемента методом итерационного перехода по ссылкам вплоть до корневого понятия. Затем производится сортировка полученных цепочек предков по их длине. В результате на выходе блока получается упорядоченное множество цепочек предков R:
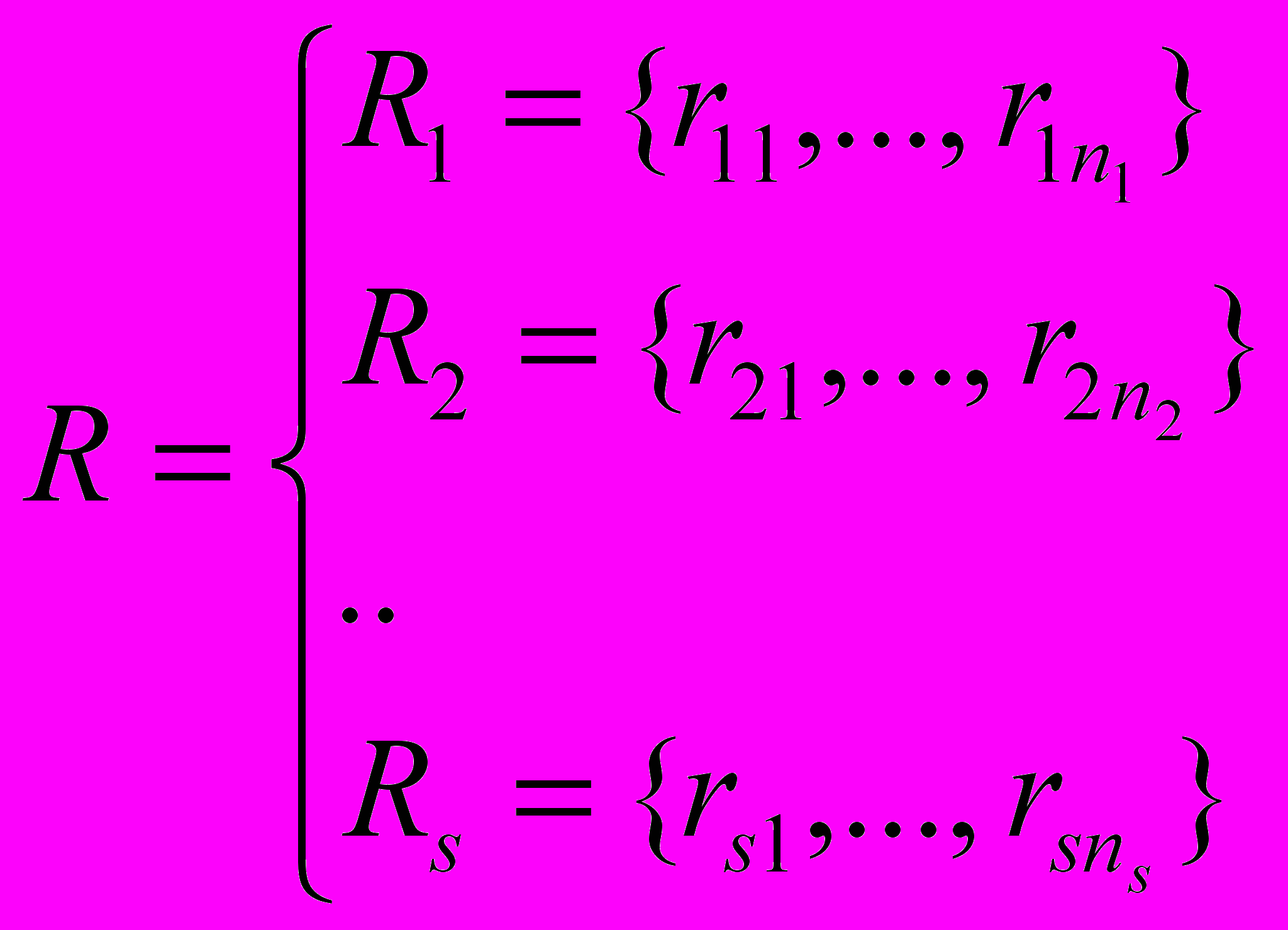
где n1

Рис. 3. Алгоритм верификации подмножества font
После чего проверяется, что все элементы множества R находятся на одной ветви онтологии ПО, т.е. цепочка предков самого младшего потомка должна включать все остальные цепочки. Для этого используется оценка семантической связности GR, которая вычисляется по следующей формуле:
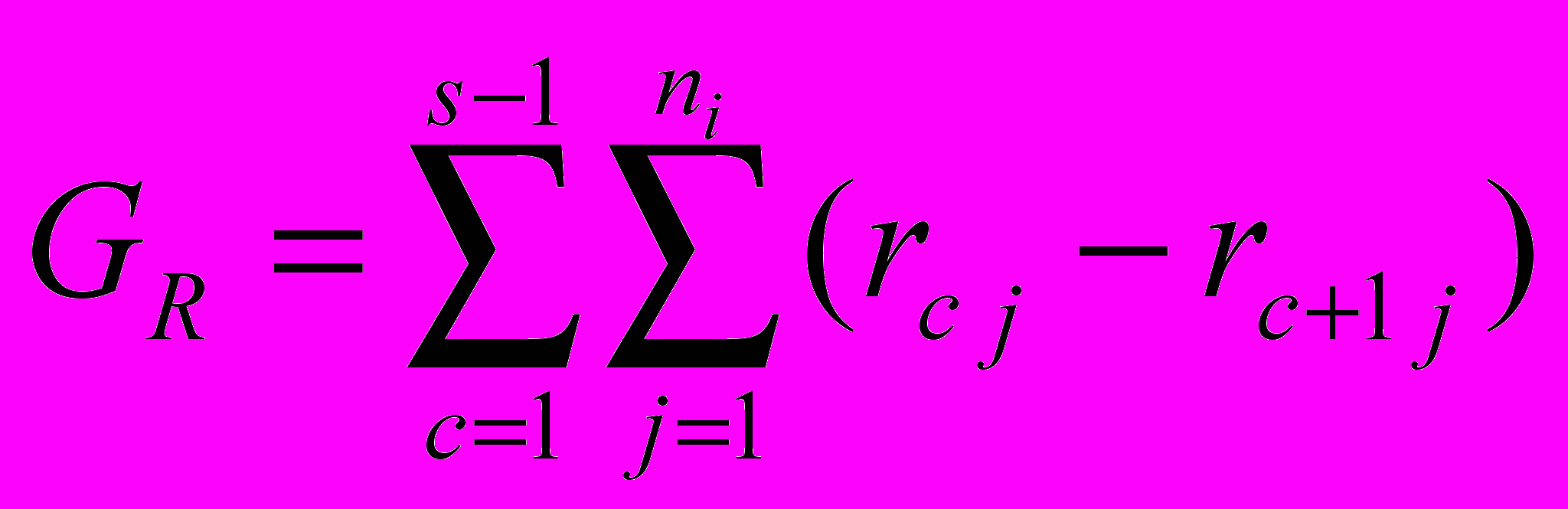
GR равна нулю только в том случае, когда совпали все элементы сравниваемых цепочек предков, и, следовательно, множество
является семантически правильным. Тогда в гипотезу входной фразы вместо элементов подставляются обобщающие понятия из онтологии. В случае хотя бы одного несовпадения, все множество рассматривается как некорректное и следует без изменений на дальнейшую обработку. Однако, если гипотеза фразы состоит только из множества , т.е. 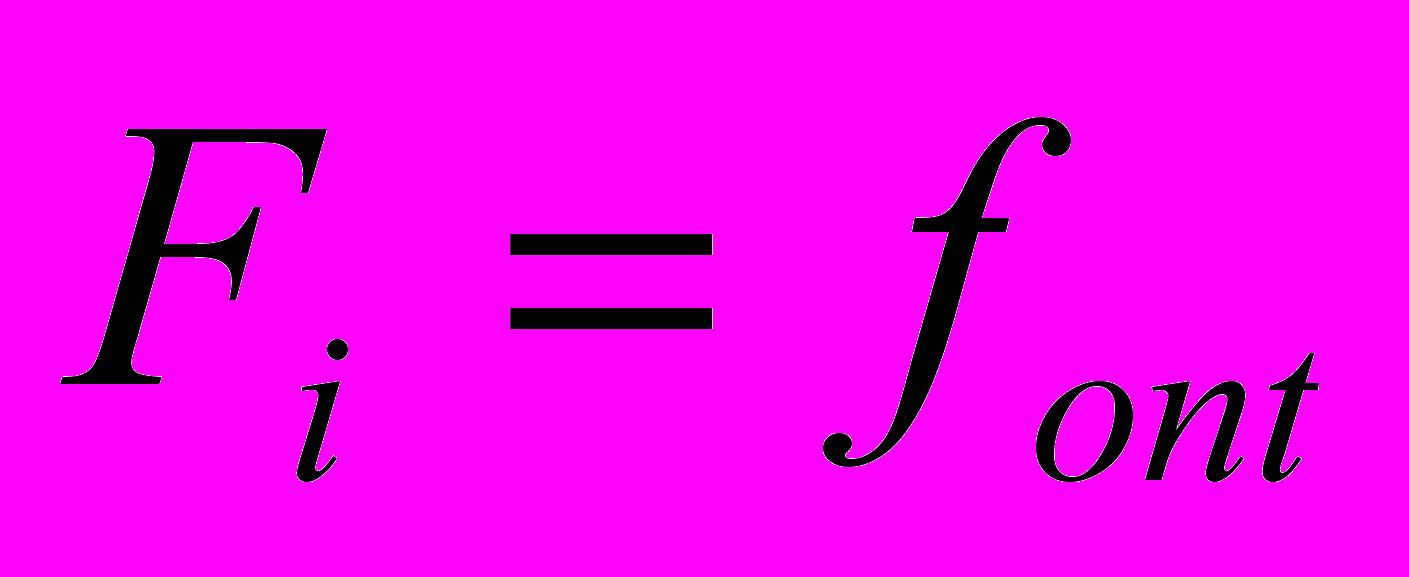 и при этом оно является некорректным, то эта гипотеза исключается из дальнейшего рассмотрения. Таким образом, внесение онтологии ПО в модель представления естественного языка и использование метода верификации онтологического подмножества позволило учесть иерархические связи между терминами предметной области и получить оценку их семантической связности GR.
и при этом оно является некорректным, то эта гипотеза исключается из дальнейшего рассмотрения. Таким образом, внесение онтологии ПО в модель представления естественного языка и использование метода верификации онтологического подмножества позволило учесть иерархические связи между терминами предметной области и получить оценку их семантической связности GR.Во второй части третьей главы рассматривается метод оценки лексической близости возможных ситуативных переходов гипотезе входной фразы. На рисунке 4 представлена схема модифицированного ситуативного анализа с использованием разработанного метода.

Рис. 4. Схема модифицированного ситуативного анализа
Суть метода состоит в оценке пересечения множества слов входной гипотезы
и словарей ситуативных переходов T, полученных из наборов равноценных перефразировок, заданных в ситуативном графе:T = {T1, .. Tg},
где g – число возможных переходов из текущей ситуации.
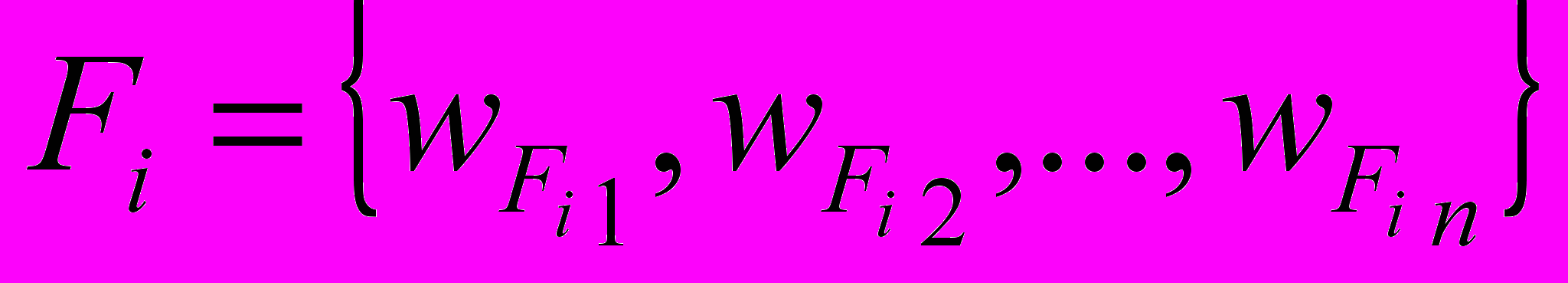 ,
, 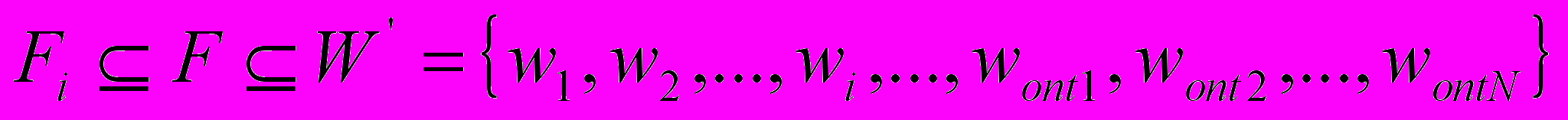
где n – количество слов в
.Пусть
 – словарь некоторого перехода
– словарь некоторого перехода  из множества T,
из множества T, 
Для проверки некоторого перехода
, ( ) введена оценка лексической близости
) введена оценка лексической близости , которая вычисляется по формуле:
, которая вычисляется по формуле: ,
, где h-количество слов в
, n – количество слов в. Оценка получается путем пословного сравнения двух множеств и , и равна нулю в случае нахождения хотя бы одного общего слова у анализируемого словаря и гипотезы входной фразы, в противном случае оценка равна единице. Тогда множество бесперспективных переходов равно: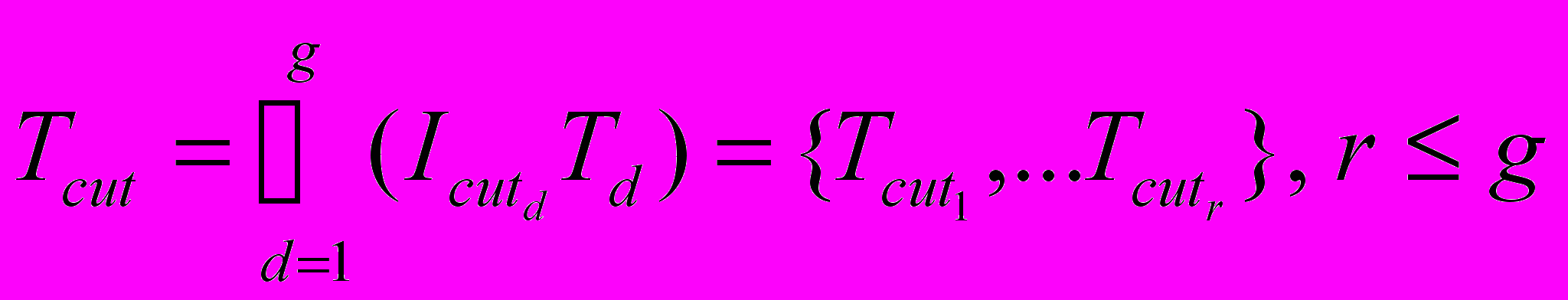 ,
,где r – число бесперспективных переходов.
В результате, общее число отсеченных канонических фраз
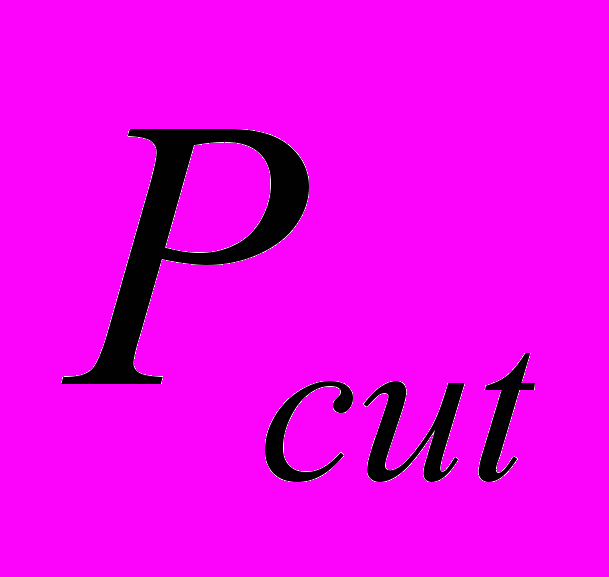 равно сумме всех перефразировок из
равно сумме всех перефразировок из 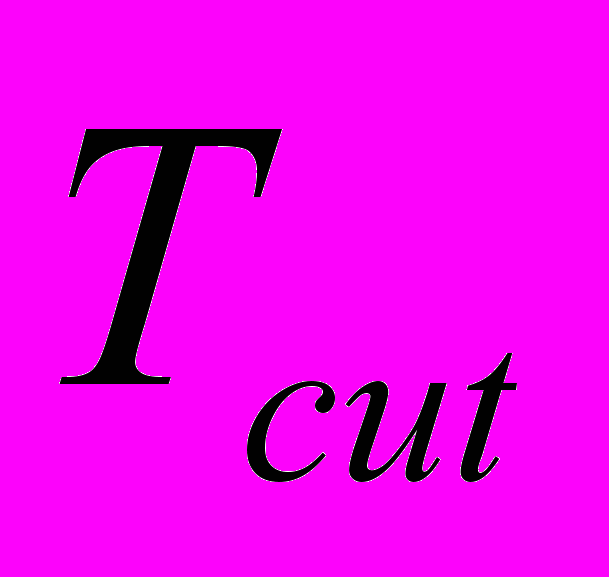 :
: ,
, где
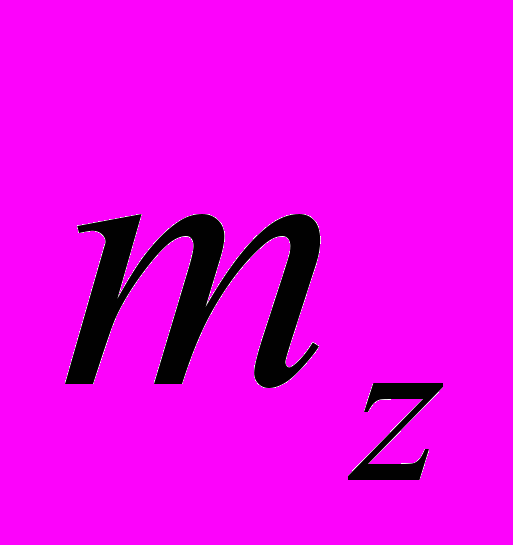 – число перефразировок z-ого перехода из .
– число перефразировок z-ого перехода из . Метод оценки лексической близости ситуативных переходов позволяет заранее отсечь бесперспективные для поступившего набора гипотез ситуативные переходы и таким образом, значительно ускорить процесс ситуативного анализа.
На рисунке 5 показана модификация модуля естественно-языковой обработки. Пунктиром выделены модули, разработанные в результате модификации.
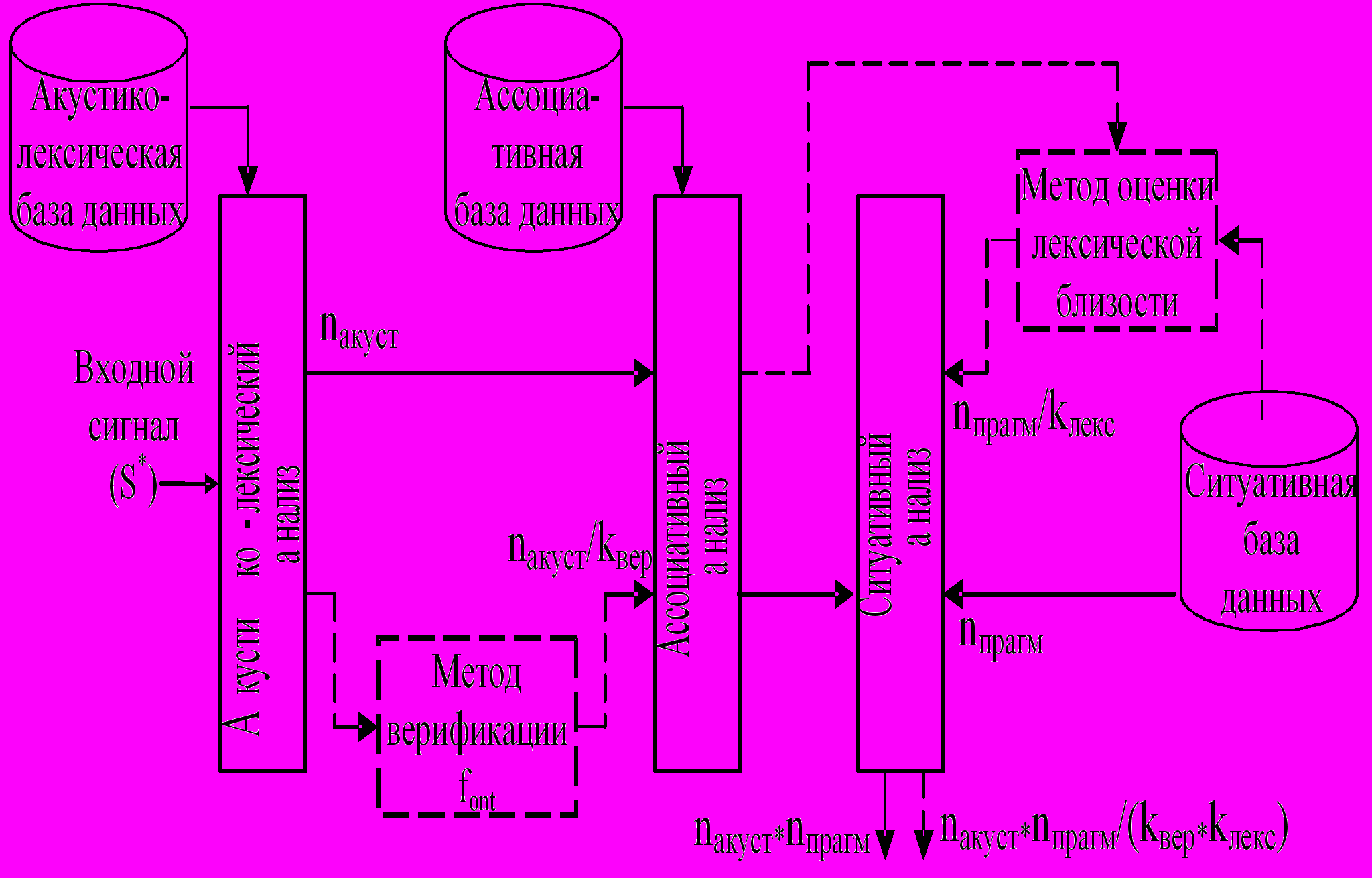
Рис. 5. Модификация модуля естественно-языковой обработки
Модификация проведена на основе разработанных методов, которые обеспечивают сокращение гипотез фраз выходящих с модуля ситуативного анализа по двум аспектам. Во-первых, сокращается количество гипотез, поступающих с уровня ассоциативного анализа, с коэффициентом kвер. Во-вторых, сокращается число канонических перефразировок, поступающих на ситуативный анализ, с коэффициентом kлекс. В результате, при сравнении всех nакуст/kвер гипотез фраз со всеми nпрагм/kлекс каноническими перефразировками с выхода модуля ситуативного анализа получается множество гипотез фраз размером: nакуст*nпрагм/(kвер*kлекс).
Таким образом, общий коэффициент сокращения числа гипотез, не вызывающий при этом потери правильной гипотезы, равен kвер*kлекс, что привело к ускорению работы ситуативного анализа и интегральной модели понимания речи в целом, например, на 50% для модели голосового управления самолетом.
В четвертой главе приводятся данные по реализации разработанных алгоритмов в экспериментально-исследовательских моделях речевого диалога. Создана модель представления естественного языка для системы голосового управления самолетом. Фрагмент онтологии устройств управления самолетом представлен на рисунке 6.

Рис. 6. Фрагмент онтологии устройств управления самолетом
Наличие однотипных устройств вызывало избыточность в представлении голосовых команд (перефразировок), поэтому была использована онтология устройств управления самолета. Сокращение числа гипотез входной фразы для этой задачи в среднем составило 10%, kвер = 1,02.
В рамках разработанной модели также был реализован метод оценки лексической близости возможных ситуативных переходов при ситуативном анализе. Метод позволил снизить объем перебора канонических перефразировок на 80%, kлекс =5. Таким образом, общий коэффициент сокращения числа гипотез kвер*kлекс = 5,1 без потери качества понимания. Однако, с учетом временных затрат на лексический анализ общий выигрыш в скорости ситуативной обработки составил 50% от базовой модели.
На рисунке 7 представлен интерфейс системы голосового доступа к системе «Автомаркет». Задача, поставленная перед системой, состояла в заполнении формы поиска популярных японских автомобилей. Поскольку пользователь не всегда сохраняет строгую последовательность при перечислении характеристик автомобиля, было необходимо, чтобы система адекватно реагировала на различные варианты фраз, содержащие избыточную или преждевременную, с точки зрения системы, информацию.
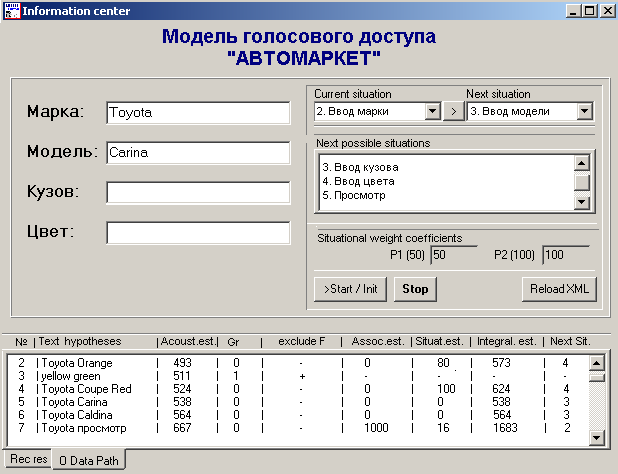
Рис. 7. Экспериментальная модель голосового доступа к информационной системе «Автомаркет»
Внесение онтологии ПО в модель представления естественного языка позволило устранить семантическую неоднозначность использования терминов ПО. Онтология содержит 146 терминов предметной области. Использование онтологии позволило избежать избыточности ситуативной модели более чем на 98%. Использование метода верификации онтологического подмножества позволило исключить около 40% семантически-неверных гипотез входной фразы до ситуативного и ассоциативного анализа. В результате процесс обработки речи ускорился почти в 2 раза. Однако, наличие большого числа акустически похожих словосочетаний, которые удовлетворяют требованиям верификации, привело к снижению качества понимания речи до 94%.
Таким образом, с помощью разработанных в диссертационной работе методов и программных модулей были созданы эффективные средства человеко-машинного взаимодействия на основе автоматического ввода речи. Естественность взаимодействия пользователя с прикладной системой понимания речи была обеспечена за счет возможности использования широкого спектра понятий и терминов предметной области.
Заключение
В области понимания речи наиболее актуальными являются проблемы связанные с разрешением естественно-языковой неоднозначности, а также использованием информации об иерархии понятий определенной предметной области (ПО).
В результате проведенной работы был разработан метод верификации онтологического подмножества с использованием онтологии предметной области, которая вносит информацию об иерархии понятий, а также за счет метода оценки лексической близости ситуативных переходов был усовершенствован ситуативный анализ, позволяющий устранить смысловую неоднозначность высказывания.
- Внесение онтологии предметной области и использование метода верификации онтологического подмножества позволило учесть иерархические связи между терминами предметной области и проверить их семантическую связность. За счет предварительного отсечения гипотез, содержащих семантически не связные понятия, удалось существенно ускорить процесс обработки речи. Кроме того, обеспечена естественность взаимодействия пользователя с прикладной системой понимания речи за счет возможности использования широкого спектра понятий и терминов предметной области.
- Метод оценки лексической близости ситуативных переходов позволил оценить релевантность анализируемой гипотезы конкретному ситуативному переходу без перебора всех перефразировок, и таким образом, ускорил процесс разрешения семантической неоднозначности при ситуативном анализе.
- На основе разработанных методов была проведена модификация базовой модели интегрального понимания, в результате чего появилась возможность разрешать семантическую неоднозначность высказываний, содержащих термины различных уровней обобщения, без избыточного представления ситуативной информации.
Кроме того, методы, изложенные в диссертационной работе, были использованы при проведении ряда научно-исследовательских работ. В дальнейшем разработанные методы и программные средства будут использованы при создании перспективных интеллектуальных приложений человеко-машинного взаимодействия.
Список публикаций по теме диссертации
- Yuri Kosarev, Izolda Lee, Andrey Ronzhin, Jesus Savage. State of the Art in Speech Understanding. International Workshop SPECOM’2001, Moscow: Moscow State Linguistic University, 2001, pp. 241-250.
- Ю.А. Косарев, И.В. Ли, А.Л. Ронжин, Е.А. Скиданов, J. Savage «Обзор методов понимания речи и текста», Труды СПИИРАН / Под ред. Р.М. Юсупова вып. 1 т. 2 – СПб.: «Анатолия», 2002, C. 157-195.
- Ronzhin, Yu. Kosarev, I. Lee, A. Karpov. Continuous Speech Recognition Suitable for Robust Speech Understanding. International Workshop SPECOM’2002, St. Petersburg: “Evropeiski Dom”, 2002, pp. 47-52.
- Yuri Kosarev, Izolda Lee, Andrey Ronzhin, Alexey Karpov, Jesus Savage, Fred Haritatos. Robust Speech Understanding for a Voice Control System. International Workshop SPECOM’2002, St. Petersburg: “Evropeiski Dom”, 2002, pp. 13-18.
- А. Ронжин, Ю. Косарев, И. Ли, А. Карпов. Метод распознавания слитной речи на основе анализа сигнала в скользящем окне и теории размытых множеств. / Научно-теоретический журнал «Искусственный интеллект», №4. – Донецк, Украина, 2002, C. 256-263.
- Andrey Ronzhin, Yuri Kosarev, Alexey Karpov, Izolda Lee. Elaboration of the intellectual speech interface provided accuracy, robustness and adaptability. International Workshop SPECOM'2003, Moscow, Russia, October 2003, pp. 231-236.
- Yuri Kosarev, Andrey Ronzhin, Alexey Karpov, Izolda Lee. Approaches to creation of situational databases for integral speech understanding models. International Workshop SPECOM'2003, Moscow, Russia, October 2003, pp. 114-118.
- Lee I.V., Ronzhin A.L., Karpov A.A. Semantic-pragmatic processing of natural language for automatic speech understanding systems. International Workshop SPECOM'2004, Russia, 2004, St. Petersburg, Publishing house “Anatolya”, 2004, pp.488-494.
- Ли И.В., Ронжин А.Л., Карпов А.А. Учет иерархии понятий предметной области в системах автоматического понимания речи. / Научно-теоретический журнал «Искусственный интеллект», Донецк, Украина, 2004.