
Методическое пособие по курсу " Передача информации" для студентов, обучающихся по направлению "Информатика и вычислительная техника" и по специальности
| Вид материала | Методическое пособие |
- «Информатика и вычислительная техника», 723.11kb.
- Методическое пособие по курсу "Моделирование" для студентов, обучающихся по направлению, 512.51kb.
- Рабочая программа дисциплины «Теория систем» по направлению подготовки дипломированного, 142.63kb.
- Рабочая программа дисциплины «Компьютерная графика» по направлению подготовки дипломированного, 108.6kb.
- Рабочая программа дисциплины «Методы оптимизации» по направлению подготовки дипломированного, 132.79kb.
- Рабочая программа дисциплины «Параллельные вычислительные процессы» по направлению, 108.72kb.
- Рабочая программа дисциплины «Теория принятия решений» по направлению подготовки дипломированного, 176.95kb.
- Рабочая программа дисциплины «Инструментальные средства 3D графики» по направлению, 112.55kb.
- Рабочая программа дисциплины «Системный анализ и исследование операций» по направлению, 161.5kb.
- Рабочая программа дисциплины «Проектирование интеллектуальных автоматизированных систем», 126.15kb.
3.2. Метод и средства кодирования
Применительно к циклическим кодам принято отводить под информационные символы k старших разрядов многочлена кода, а под проверочные символы n-k низших разрядов.
Применяется следующая процедура кодирования:
многочлен а(х), соответствующий k-разрядной комбинации информационных разрядов кода, умножается на хт, где т - степень образующего многочлена. Это соответствует добавлению к комбинации а(х) m нулей со стороны младших разрядов. Произведение a(x)xm делится на образующий многочлен g0(x). В общем случае при этом получаем некоторое частное q(x) и остаток r(x):
a(x)xm=q(x)g0(x) r(x).
Остаток прибавляется к а(х)хт. Поскольку степень остатка r(x) не превышает т-1, а в комбинации, соответствующей многочлену а(х)хт, т младших разрядов-нулевые, то указанная операция сложения равносильна приписыванию r(x) к а(х) со стороны младших разрядов.
Полученный многочлен f(x)=a(x)xm r(x)=q(x)g0(x) делится на g(x) без остатка и, следовательно, соответствует разрешенной комбинации кода.
Техническая реализация описанного процесса кодирования в случае двоичных кодов осуществляется посредством регистра сдвига с обратными связями, состоящего из ячеек памяти и сумматоров по модулю два. Сдвиг информации в регистре осуществляется импульсами, поступающими с генератора продвигающих импульсов, который на схеме, как правило, не указывается. На вход регистра поступают только коэффициенты многочленов, причем, начиная с коэффициента при переменной в старшей степени.
На рис.3.1 представлена схема, выполняющая деление произвольного многочлена (например, многочлена а(х)=ап-1хп-1+ап-2хп-2+,...,+а1(х)+а0) на некоторый фиксированный (например, образующий) многочлен
g(x)=gn-kхп-к+...+g1(x)+g0.
Обратные связи регистра соответствуют виду многочлена g0(x). КоличЕство включаемых в него сумматоров равно числу отличных от нуля коэффициентов g0(x), уменьшенному на единицу. Это объясняется тем, что сумматор сложения коэффициентов старших разрядов многочленов делимого и делителя в регистр не включается, так как результат сложения заранее известен (он равен нулю).
За первые m тактов коэффициенты многочлена-делимого заполняют регистр, причем коэффициент при х в старшей степени достигает крайней правой ячейки. На следующем такте единица делимого, выходящая из крайней ячейки регистра по цепи обратной связи, подается к сумматорам по модулю два, что равносильно вычитанию многочлена-делителя из многочлена-делимого. Если в результате предыдущей операции коэффициент при старшей степени х у остатка оказался равным нулю, то на следующем такте вычитания делителя не происходит. Коэффициенты делимого только сдвигаются вперед по регистру на один разряд, что находится в полном соответствии с тем, как это делается при делении многочленов столбиком.
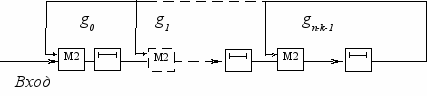
Рис. 3.1 Схема деления на произвольный многочлен.
Деление заканчивается с приходом последнего символа многочлена-делимого. При этом разность будет иметь более низкую степень чем делитель. Эта разность и есть остаток.
Рассмотренная схема деления многочленов может использоваться при декодировании. При кодировании она не применяется в силу того, что между информационными и проверочными символами образуется разрыв в m тактов.
Для кодирования используется схема, позволяющая разделить многочлен типа а(х)хm за к тактов. Она отличается от рассмотренной тем, что коэффициенты кодируемого многочлена участвуют в обратной связи не через m сдвигов, а сразу с первого такта.
Для случая g0(x)=x3+x2+1 и а(х)=а3+1 схема кодирующего устройства приведена на рис. 3.2.
В исходном состоянии ключ К1 находится в положении 1, а ключ К2 замкнут. Информационные символы одновременно поступают как в линию связи, так и в регистр сдвига, где за к тактов образуется остаток. Затем ключ К2 размыкается, ключ К1 переходит в положение 2 и остаток выводится в канал связи.
Процесс формирования кодовой комбинации шаг за шагом представлен в табл. 3.1, где черточками отмечены освобождающиеся ячейки, занимаемые новыми информационными символами.
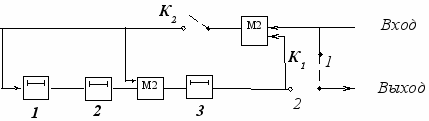
Рис. 3.2 Схема кодирующего устройства.
Таблица 3.1
-
N такта
Вход
Состояние ячеек регистров
Выход
1
2
3
1
1
1
0
1
1
2
0
1
1
1
01
3
0
1
1
0
001
4
1
1
1
0
1001
5
0
-
1
1
01001
6
0
-
-
1
101001
7
0
-
-
-
1101001
3.3. Метод и средства декодирования
Рассмотрим устройства декодирования, в которых для обнаружения и исправления ошибок производится деление произвольного многочлена f(x), соответствующего принятой комбинации, на образующий многочлен кода g0(x). В этом случае при декодировании могут использоваться те же регистры сдвига, что и при кодировании.
Символы подлежащей декодированию кодовой комбинации, возможно содержащей ошибку, последовательно, начиная со старшего разряда, вводятся в п-разрядный буферный регистр сдвига и одновременно в схему деления, где за п тактов определяется остаток, который в случае непрерывной передачи сразу же переписывается в регистры второй аналогичной схемы деления (рис.3.3).
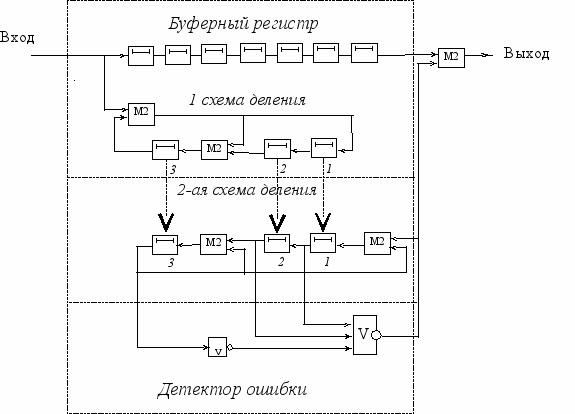
Рис. 3.3. Схема декодирующего устройства.
Начиная с (п+1)-го такта, в буферный регистр и первую схему деления начинают поступать символы следующей кодовой комбинации. Одновременно на каждом такте буферный регистр покидает один символ, а в регистре второй схемы деления появляется кодовый остаток (синдром). Детектор ошибок, контролирующий состояние ячеек этого регистра, представляет собой комбинаторно-логическую схему, построенную с таким расчетом, чтобы она отмечала все те синдромы (“выделенные синдромы”), которые появляются в регистре, когда каждый из ошибочных символов занимает крайнюю правую ячейку в буферном регистре. Выделенный синдром - это остаток на п-м такте в случае возникновения ошибки в старшем разряде кодовой комбинации. При последующем сдвиге детектор формирует сигнал “1”, который воздействует на сумматор коррекции и исправляет искаженный символ.
Одновременно по цепи обратной связи сигнал “1” с выхода детектора подается на входной сумматор регистра, изменяя выделенный синдром так, чтобы он либо соответствовал более простому типу ошибки, которую еще надлежит исправить, либо все ячейки декодирующего регистра должны оказаться в нулевом состоянии. Если в результате автономных сдвигов состояние регистра не окажется нулевым, это означает, что произошла неисправимая ошибка.
Таблица 3.2
-
N такта
Вход
Состояние ячеек регистров
Выход после коррекции
1
2
3
1
1
1
0
1
2
0
1
1
1
3
0
1
1
0
4
0
0
1
1
5
0
1
0
0
6
1
1
1
1
7
1
0
1
1
8
0
1
0
0
1
9
0
0
1
0
01
10
0
0
0
1
001
11
0
0
0
0
1001
12
0
0
0
0
01001
13
0
0
0
0
101001
14
0
0
0
0
1101001
Для декодирования кодовых комбинаций, разнесенных по времени с передачей, достаточно одной схемы деления, осуществляющей декодирование за 2п тактов.
Сложность детектора ошибок зависит от числа выделенных синдромов. Для кода, исправляющего одиночные ошибки, простейший детектор получается в случае использования схемы деления второго типа (см.рис.3.3). Поскольку неискаженная кодовая комбинация делится на g0(x) без остатка, то для отыскания выделенного синдрома достаточно разделить на g0(x) вектор ошибки с единицей в старшем разряде. Остаток, получающийся на п-м такте, и является искомым выделенным синдромом. Он содержит единицу в старшем разряде и нули во всех остальных разрядах. Только при таком синдроме детектор должен формировать на выходе сигнал коррекции.
В зависимости от номера искаженного разряда после первых тактов будем получать различные остатки. Вследствие этого выделенный синдром будет появляться в регистре схемы деления через различное число последующих тактов, обеспечивая исправление искаженного символа.
В табл. 3.2, шаг за шагом, представлен процесс исправления ошибки, для случая, когда сформированная в табл. 3.1 кодовая комбинация 1101001 поступила на вход декодирующего устройства с искаженным символом в 4-ом разряде.
3.2 Описание лабораторной работы
Лабораторная работа включает схемы для исследования циклических кодов. На изображенных схемах тактовые цепи не указаны.
Представленные схемы деления позволяют закодировать информационные разряды кодом (7,4) с образующим многочленом g(x)= x3+x+1, рассчитанным на исправление одиночных ошибок, и кодом (7,3) с образующим многочленом g(x)= (x+1)(x3+x2+1) = x4+x2+x+1, рассчитанным на исправление одиночных и двойных смежных ошибок. Заданные значения информационных разрядов записываются в регистр числа. Влияние помехи в канале связи имитируется сложением кодовой комбинации с вектором ошибки, формируемым в регистре помехи.
Для обоих указанных кодов предусмотрены схемы декодирования, с помощью которых можно проследить последовательность остатков в декодирующем регистре. Непосредственное исправление ошибок обеспечивается узлом коррекции в виде детектора ошибки и сумматора по модулю два. Декодирующее устройство рассчитано на поступление кодовых комбинаций разнесенных во времени.
3.3 Описание программного обеспечения
Для выполнения лабораторной работы необходимо запустить программу 103.exe. В появившемся меню нужно выбрать тип кода и нажать клавишу “Enter”, последовательно ввести информационные символы и вектор помехи. После ввода всех последовательностей символов, появится сообщение “Вы хотите повторить ввод? (y/n)”. Если что-то было введено не верно, нажмите “y” и повторите ввод, если же все правильно, нажмите “n”. Проследите процесс кодирования, декодирования и коррекции ошибок по тактам, используя клавишу “Enter”. Когда декодированная последовательность появиться на выходе схемы, появиться сообщение “Нажмите клавишу ESC”. Нажав клавишу “ESC” вы попадете обратно в меню.
Для выхода из программы выберете в меню пункт “Выход”.
3.3 Задание
Выполняется при домашней подготовке
1. Изучить рекомендованную литературу, теоретическую часть работы, а также описание и порядок проведения лабораторной работы.
2. Составить таблицу, отражающую процесс кодирования четырехзначной комбинации информационных символов кодом (7,4).
3. Составить таблицу, отражающую процесс декодирования полученной при кодировании кодовой комбинации в предположения воздействия заданного вектора ошибки в любом разряде при g(x)=x3+x+1.
4. Выполнить пункты 2 и 3 для циклического кода (7,3) при g(x)=x4+x2+x+1.
Выполняется в лаборатории
- Для циклического кода (7,4) установить в регистре числа заданную кодовую комбинацию информационных символов и проследить формирование кодовой комбинации, и ее прохождение через декодирующее устройство.
- Установив в регистре помехи вектор ошибки в одном разряде, проследить процесс декодирования и коррекции кодовой комбинации.
- Выполнить пункты 1 и 2 для циклического кода (7,3), исправляющего две смежные ошибки.
Требования к отчету
Отчет должен включать:
- Исходные последовательности для кодирования, вектора ошибок.
- Схемы кодирования и декодирования для исследуемых кодов.
- Таблицы, отражающие процесс кодирования и декодирования для кодов (7,4) и (7,3).
Контрольные вопросы
1. Какова математическая основа циклического кода?
2. Какие требования предъявляются к образующему многочлену?
3. Как определить выделенные синдромы?
- Влияет ли тип схем деления на синдром ошибки? Почему?
ЛИТЕРАТУРА
- Дмитриев В.И. Прикладная теория информации. – M.: Высш. шк., 1989. – 320 с. (С. 239–274).
- Темников Ф.Е., Афонин В.А., Дмитриев В.И. Теоретические основы информационной техники. – М.: Энергия, 1979. – 512с. (С. 172–204).
Лабораторная работа № 104
ПОСТРОЕНИЕ И РЕАЛИЗАЦИЯ РЕКУРРЕНТНЫХ КОДОВ
Целью данной работы является усвоение принципов построения и технической реализации кодирующих и декодирующих устройств рекуррентных кодов.