
Реферат «Возможности применения ит при исследовании языковой интерференции»
| Вид материала | Реферат |
- «Возможности применения современных информационных технологий при переводе», 248.88kb.
- Классификация сейсмических сигналов на основе нейросетевых технологий, 622.68kb.
- Реферат по курсу «Перспективные наукоемкие технологии» на тему : «Возможности применения, 207.02kb.
- Планирование в исследовании систем управления, 48.03kb.
- Методологические проблемы применения естественнонаучных методов в историческом исследовании:, 825.64kb.
- Программа дисциплины «Историческая текстология» для направления 030600. 68 «История», 507.52kb.
- Анализ возможности применения зарубежных инновационных технологий в розничной банковской, 124.63kb.
- Реферат по курсу «Безопасность труда» является аналогом раздела «Охрана труда» дипломной, 47.89kb.
- Возможности использования интернет-технологий в преподавании страноведения Германии, 149kb.
- Применения, возможности нанесения порошковых эмалей на изделия из металла, стекла,, 171.03kb.
Реферат
«Возможности применения ИТ при исследовании языковой интерференции»
Реферат 1
«Возможности применения ИТ при исследовании языковой интерференции» 1
1
Введение 2
Глава 1. Интерференция: история и методы 5
Глава 2. Лингвистика и ИТ 8
Глава 3. Применение ИТ при исследовании языковой интерференции 11
Синтаксический анализатор естественного текста на русском языке 11
NooJ 14
LeoBilingua 17
Заключение. 20
Список литературы к реферату 21
Список использованных источников 21
Список публикаций магистранта 22
Предметный указатель к реферату 24
Введение
Для современного языкознания проблема языковой интерференции является одновременно традиционной и актуальной, а изучение данного явления в условиях посреднической (переводческой) деятельности решает ряд вопросов, связанных с трудностями, возникающими при переводе Error: Reference source not found с одного естественного языка на другой. Рассматриваемый вопрос находится на стыке теории перевода и теории языковых контактов, последнее в свою очередь также представляет собой синтезированное знание (языковой контакт требует комплексного подхода, включая психологический, социальный и собственно лингвистический аспекты).
До недавнего времени феномен интерференции изучался только в рамках теории языковых контактов в условиях непосредственного языкового контакта при наблюдении двуязычных (или многоязычных) народов. Мы же предлагаем изучать интерференцию в переводе при наблюдении специфического «профессионального» двуязычия (или многоязычия) переводчиков. Целью такого исследования является выявление фактов интерференции, изучение её механизмов и причин (как собственно лингвистических, так и психологических/психофизиологических), а также разработка классификации так называемых «пиков сложности» (термин Т.Г. Никитченко) [9, с.13] и ее методическое применение.
В рамках данной темы особый интерес представляют вопросы билингвизма, интерференции, языкового контакта и перевода как частного случая языкового контакта.
Актуальность подобного исследования определяется тем, что объемы выполняемых переводов с каждым годом все увеличиваются, а недооценка явления интерференции при переводе приводит к появлению ряда ошибок, вплоть до срыва коммуникации. Кроме того, как замечает В.В. Алимов, преподавателей перевода готовить в ВУЗах очень сложно, и, в основном, ими становятся преподаватели иностранного языка, которые имеют какую-то теоретическую и практическую подготовку по переводу, и бывшие переводчики, которые не в полной мере владеют методикой преподавания, что, конечно, сказывается и на подготовке переводчиков, и на качестве пособий по переводу, подготовленных такими специалистами [1, с.21].
Наше исследование строится в основном на анализе полученного при переводе текста с целью выявления степени его соответствия нормам языка перевода (ЯП). При наличии отклонений от нормы анализировались возможные их причины, в первую очередь влияние исходного языка (ИЯ). В ряде случаев нам удалось установить прямое влияние структур (грамматических) исходного языка на систему языка перевода. Именно эти случаи и рассматриваются как примеры интерференции, определяемой здесь как деструктивная. Полученные результаты демонстрируют наиболее проблемные моменты («пики сложности») возникающие при переводе. Таким образом, изучение интерференции имеет свою практическую значимость: зная, что вызывает сложности при переводе, именно на этом следует делать акцент при подготовке (и самоподготовке) переводчиков.
Однако лингвистический анализ текста перевода на предмет присутствия в нем иноязычных элементов и структур – процесс довольно трудоемкий, который занимает много времени, при этом он дает небольшой объем фактического материала. А так как всякий научно значимый вывод делается с опорой на значительный объем материала, возникает необходимость автоматизировать и, тем самым, ускорить процесс анализа, чтобы он покрывал большее количество текстов за меньшее время.
Кроме того, проблема интерференции, рассматриваемой как иноязычные вкрапления в тексте перевода на лексическом и грамматическом (морфологическом и синтаксическом) уровнях, актуальна не только для переводов, выполняемых людьми, но в том числе и для машинного перевода.
Проблема компьютера состоит в том, что, обладая огромнейшими базами данных, он лишен (пока все еще) мышления, а проблема живого переводчика заключается в нехватке данных при наличии мышления. Компьютер не понимает языковых нюансов, намеков в тексте, того, что называется тонкой игрой слов, да и понять содержание текста в полной мере ему пока не под силу. Мышления как такового при машинном переводе не происходит: предложение расчленяется на части речи, в нем выделяются стандартные конструкции, слова и словосочетания переводятся по находящимся в памяти машины словарям. Затем переведенные части речи собираются по правилам другого языка [3].
Но этого недостаточно для полноценного перевода. В зависимости от того или иного стиля и назначения текста одно и то же слово нередко имеет разные значения. В какой-то мере эта особенность учитывается в системах машинного перевода: предусмотрены сменные словари, иногда для каждого вида текста предусмотрен свой словарь. Если лексики одного машинного словаря не хватает и применяются несколько словарей одновременно, можно указать системе, из какого словаря нужно брать слово, если есть несколько вариантов его перевода. Наконец, программа сама может предлагать на выбор пользователю несколько вариантов перевода, и он выбирает подходящий вариант вручную. Могут возникнуть и проблемы с переводом слов в устойчивых словосочетаниях и фразеологизмах, но это вполне по силам компьютеру. На практике получившийся перевод похож на текст, написанный иностранцем. Это значит, что компьютер, сталкиваясь при переводе с проблемами языковой омонимии, полисемии, синонимии, не может их преодолеть, а установленные межъязыковые идентификации (соответствия) оказываются неверными (что обусловлено контекстом), т.е. он выбирает не те соответствия.
Человек в процессе перевода сталкивается с такими же проблемами. В.В. Алимов, опираясь на работы психологов и психолингвистов, говорит о наличии в памяти переводчика перцептивных эталонов (лексических, грамматических, стилистических и других, приобретенных во время обучения и другой деятельности). При переводе переводчик имеет дело на начальном этапе с процессом восприятия высказывания на исходном языке, которое на стадии идентификации заключается в сопоставлении воспринимаемых объектов с перцептивными эталонами на основе эталонов слов исходного языка и языка перевода. Если случается так, что на одном языке такие эталоны отсутствуют или недостаточно сформированы, переводчик с разной степенью осознаваемости использует перцептивные эталоны другого языка. Именно эту подмену перцептивных эталонов В.В. Алимов называет психической основой интерференции [1, c.12-13]. Таким образом, человек при переводе производит не выбор среди установленных соответствий (как это делает компьютер), а непосредственно устанавливает такие соответствия. Интерференция – результат неверно установленных или вообще не установленных идентификаций. Отсюда ясно, почему перевод художественных текстов не под силу компьютеру. Перевод художественного текста требует не выбора, а каждый раз нового установления соответствий. Такие тексты М.Ю. Лотман называет «нетривиальными», которые сами способны порождать новые тексты. «Если между кодом исходного текста и кодом перевода нет однозначного соответствия, то возникающий в результате такой трансформации текст будет в определенном отношении предсказуем, но одновременно и непредсказуем. Коды будут здесь выступать не как жесткие системы, а в качестве сложных иерархий, причем определенные уровни у них должны быть общими и образовывать пересекающиеся множества, но на других уровнях нарастает гамма непереводимости, разнообразных конвенций с разной степенью условности. Это исключает возможность при обратном переводе получить исходный текст, что и есть механизм возникновения новых текстов» [6]. Машинный перевод пока охватывает только «тривиальные» тексты, «идеальным текстом, с этой точки зрения, будет текст на мета- или искусственном языке» [6].
Глава 1. Интерференция: история и методы
Долгое время в лингвистике интерференция рассматривалась исключительно как результат непосредственного языкового контакта.
В конце XIX века в результате изучения языков в многонациональных государствах ученые пришли к выводу о том, что языки оказывают влияние друг на друга и происходит смешение языков. Одним из первых о смешенном характере языков начал говорить И.А. Бодуэн де Куртенэ. Под влиянием языков друг на друга ученый понимал конвергентную перестройку языков в ходе контактов. При этом основной была его мысль о том, что при языковом контакте происходит не только заимствование языковых единиц, но и сближение языков в целом.
Мысль И.А. Бодуэна де Куртенэ была продолжена Л.В.Щербой, исследовавшим восточно-лужицкое наречие. Эти исследования позволили ученому сделать выводы, которые имеют фундаментальное значение для современной теории языковых контактов. Именно работы Л.В.Щербы наметили программу изучения и описания языковых контактов как процесса интерференции. Сущность этого процесса определяется взаимным приспособлением языка говорящего и языка слушающего и соответствующим изменением норм обоих контактирующих языков.
В 1953 году вышла работа У. Вайнрайха «Языковые контакты», где самым подробным образом раскрывалось понятие «лингвистической интерференции». Именно после этой монографии термин «интерференция» получил широкое распространение. Согласно У. Вайнрайху, условием возникновения интерференции является языковой контакт. «Два языка, - пишет У.Вайнрайх, - находятся в контакте, если ими попеременно пользуется одно и то же лицо. Таким образом, местом осуществления контакта являются индивиды, пользующиеся языком». Следствием языкового контакта является интерференция, которую У. Вайнрайх определяет как «случаи отклонения от норм любого из языков, которые происходят в речи двуязычных в результате того, что они знают языков больше чем один» [2, с. 22].
Следующее определение интерференции дает Лингвистический энциклопедический словарь под редакцией В.Н. Ярцевой:
«Интерференция – результат взаимодействия языковых систем в условиях двуязычия, складывающегося либо при языковых контактах, либо при индивидуальном освоении неродного языка; выражается в отклонениях от нормы и системы второго языка под влиянием первого» [5, с.197].
В своей работе «Интерференция в переводе» В.В. Алимов также обращает внимание на тот факт, что на протяжении многих лет языковая интерференция рассматривалась как лингвистическое явление в результате непосредственного языкового контакта, в условиях посреднической деятельности интерференция практически не рассматривалась [1, с. 35]. В целом данное утверждение соответствует действительности, хотя стоит сказать, что идея о подобном подходе к изучению перевода и интерференции в посреднической деятельности высказывалась неоднократно в работах У. Вайнрайха, А. Мартине, Х. Шухардта, Ж. Мунена и др. Но практически все ученые смотрели довольно скептически на возможность такого исследования, предполагая, что «перевод, рассматриваемый как языковой контакт в случаях особого билингвизма, может предоставить в распоряжение лингвиста лишь весьма скупой урожай примеров интерференции по сравнению с тем, что может предоставить прямое наблюдение любого двуязычного народа» [8, с. 39].
С данным утверждением сложно спорить, тем более что результаты (их количество), полученные в ходе в том числе и наших исследований [1.- А., 2.-А], в целом свидетельствуют в пользу такой позиции. Однако, нельзя отрицать тот факт, что интерференция в переводе представляет особый интерес, связанный со спецификой переводческой деятельности, так как в данном случае мы можем наблюдать «сбои» при «профессиональном билингвизме» (А.Мартине), ведь у переводчика при переводе степень контроля информации на выходе должна быть заведомо гораздо выше, чем у обычного билингва при переключении с языка на язык. Возникает вопрос о том, почему, несмотря на осознанную установку избежать вторжения системы исходного языка в систему языка перевода, переводчик все-таки остается под влиянием исходного языка? Тем более удивительно, если подобная картина наблюдается при переводе на родной доминантный язык (коим в данном исследовании является русский). Все это лишь еще раз подтверждает значимость и необходимость изучения проблемы интерференции в переводе с целью прояснения механизмов и причин ее возникновения, а также выработки способов, которые позволили бы ее избежать.
Большой шаг в этом направлении уже был сделан в 1989 году, когда в Лейпциге вышел сборник «Интерференция в переводе» (Interferenz in der Translation). И хотя эта книга представляет собой сборник статей, довольно пестрый с точки зрения проблематики и методологии, и не дает комплексного анализа проблемы интерференции в переводе, здесь намечаются основные пути и направления исследований [14].
Однако проблема интерференции в переводе остается, на наш взгляд, мало изученной. И тот факт, что она не предоставляет исследователям значительного количества фактического материала, играет не последнюю роль в такой «непопулярности» данного феномена. Так или иначе, при изучении интерференции в переводе встает проблема анализа большого количества текстов. Желание облегчить и ускорить процесс обработки материала возникает само собой у всякого исследователя. Прогресс в сфере информационных технологий дает исследователям (в том числе лингвистам и литературоведам) необходимый инструментарий, который позволяет делать больше за меньшее время.
Глава 2. Лингвистика и ИТ
На стыке информатики и языкознания родилась компьютерная лингвистика, что обусловлено потребностью в общении с компьютером на естественном языке. Лингвистические технологии находят множество областей применения, начиная с несложных программ проверки орфографии, до более изощрённых алгоритмов, используемых в поисковых системах, программах автоматического реферирования, машинного перевода, экспертных системах. На современном этапе развития информатизации всех сфер деятельности человека практически от каждого профессионала требуются умения представления и обработки информации. Сегодня в сети Интернет представлены ряд бесплатных версий программ, связанных с анализом текстов и вычислительной лингвистикой. Все многообразие таких программ можно разделить на следующие группы:
- программы анализа и лингвистической обработки текстов;
- программы преобразования текстов;
- психолингвистические программы;
- системы обработки естественного языка;
- генераторы текстов и "говорящие" программы;
- словари и тезаурусы [4].
Основа исследования любого лингвиста - это работа с текстом, попытка взять из источника всю информацию, которая может содержаться в нем в явном или неявном виде. Однако зачастую бывает довольно трудно снять "неявную" информацию, выявить неочевидные при обычном рассмотрении связи. Компьютерный анализ текстов представляет собой одну из наиболее перспективных областей применения математических методов и ИТ в гуманитарном исследовании. Именно здесь существует большой спрос на современные программные средства компьютеризированного анализа текстовых структур и их компьютерной визуализации.
В Т.Н. Лукиных выделяет ряд основных методик, лежащих в основе практически всех программ по компьютеризованному текстовому анализу: контент – анализ, кластерный анализ, анализ стиля.
Контент - анализ. А.Н.Петров выделяет в понятии «контент-анализ» два различных метода: «метод для автоматической классификации документов по содержанию и метод для раскрытия значения слов и идей» [10]. В качестве исходного материала исследователь должен иметь оцифрованный /машиночитаемый текст в распознанном виде. Для осуществления «контент-анализа» изучаемый текст сводится к набору ограниченного количества лексических элементов, которые затем подвергаются счету и анализу. Метод применяется уже с 50-х гг. «Автоматическая классификация документов в течение ряда лет используется в историко-социальных науках и библиографических системах поиска. Текст, его резюме или заголовок служат основами классификации. Напротив, семантический контент - анализ нацелен на определение организации слов вокруг идей или понятий в большей степени, чем на организации текста. Суть подхода заключается в сведении изучаемого текста к ограниченному набору определенных элементов, которые затем подвергаются счету и анализу на базе фиксации частоты повторяемости символов и их корреляции друг с другом. Слова в тексте при этом классифицируются в соответствии с их дистанционными связями между собой. Для этого используется лингвистическая и статистическая техника, например кластерный анализ или анализ связей» [10]. На использовании контент-анализа построены программы TACT, ARRAS, TextPack, SYREX, SATO.
Кластерный анализ (анализ текста). Выявление и подсчет частот встречаемости лексических единиц (слов, словосочетаний), определение их связей между собой. Обычно используется как дальнейший этап работы с текстом после осуществления контент-анализа.
Анализ стиля. Предполагает выявление характерных грамматических и синтаксических конструкций, определение лексического запаса автора текста. Позволяет классифицировать текст по авторству. История современной статистической стилистики вообще восходит к 1851 году, когда было высказано мнение о том, что длина слов может быть доказательством различия стилей писателя [7].
Лингвисты в настоящий момент владеют значительным инструментарием для текстового анализа и даже для генерации текстов. Так, на сайте РВБ (Русская виртуальная библиотека) размещен каталог лингвистических программ и ресурсов Сети (ссылка скрыта) [11]. Данный каталог включает в себя описание программ, связанных с анализом текстов и вычислительной лингвистикой, а также соответствующих ресурсов, доступных сегодня в глобальной сети Интернет. По словам авторов, упор при составлении каталога делался на бесплатные программы, доступные для загрузки или использования в режиме on-line. Также описаны коммерческие версии некоторых наиболее интересных программ. Тематически каталог разбит на следующие разделы:
1 - программы анализа и лингвистической обработки текстов(ex.: TextAnalyst, АОТ и др.);
2 - программы преобразования текстов (TextTransformer, XReplacer);
3 - психолингвистические программы (ПСИ-Офис, ВААЛ-мини);
4 - генераторы текстов (RWC);
5 - системы обработки естественного языка и машинного перевода (Автоматический словарь Мультитран, Google Переводчик);
6 - каталоги и коллекции ресурсов (Каталог программ по вычислительной лингвистике, Справочно-информационный портал "Русский язык", LTI Projects, The Linguist List);
7 - словари и тезаурусы (ФЭБ словари, словари Ожегова и Зализняка, WordNet, толковый словарь Merriam-Webster);
8 - поисковые машины и системы полнотекстового поиска (ARM Engine, Convera Retrierval Ware);
9 - системы синтеза и распознавания речи (Sakrament Text-to-Speech Engine, Text-To-Speech Converter for MS Word, BookMania).
Это перечень лишь некоторых программ, которые могут быть использованы лингвистами при обработке текстов.
Глава 3. Применение ИТ при исследовании языковой интерференции
Говоря о возможностях применения ИТ при исследовании языковой интерференции в переводе, следует отметить, что, на наш взгляд, это можно осуществлять как на этапе изучения самого явления интерференции (1), так и на этапе ее преодоления (2).
Обычно текст, полученный в ходе машинного перевода, подвергается дополнительной обработке – производится корректирующий анализ человеком-переводчиком. Мы же пытаемся применить машинный анализ к тексту перевода, произведенному человеком.
Нам, к сожалению, ничего не известно о существовании программ, которые были бы разработаны специально для лингвистического анализа текстов перевода на предмет интерференции, т.е. для такого анализа, в ходе которого текст перевода одновременно проверялся бы на соответствие нормам (стилистическим, грамматическим и т.д.) языка перевода и сопоставлялся с текстом исходного языка с целью выявления их структурных совпадений. Тогда случаи типа «норма нарушена»+«структуры совпадают» с определенной долей вероятности можно было бы рассматривать как факты интерференции. Вообще, теоретически все случаи укладывались бы в четыре группы:
норма нарушена + структуры совпадают = интерференция;
норма нарушена + структуры не совпадают = ошибка, вызванная не влиянием ИЯ (а, например, недостаточным владением ЯП);
норма не нарушена + структуры совпадают = типологическое сходство ИЯ и ЯП;
норма не нарушена + структуры не совпадают = типологическое расхождение ИЯ и ЯП.
Однако, на наш взгляд, можно использовать уже существующие и доступные нам средства обработки текстов.
Синтаксический анализатор естественного текста на русском языке
В качестве одного из таких средств можно рассматривать «Синтаксический on-line анализатор естественного текста на русском языке» (ссылка скрыта) [13].
Синтаксический анализатор естественного текста на русском языке обрабатывает предложения с большим количеством слов (100 и более). При этом ошибочность разбора оценивается как 20% от общего числа связей, связываемость слов в предложении составляет около 70% от общего числа связей. Синтаксический анализатор выполняет разбор предложения и связывает слова в нем на основе синтаксических правил, не используя при этом знания о мире. Поэтому после разбора предложения пользователю выдаются избыточные варианты связывания слов. Эти избыточные варианты должны быть проверены самим человеком, так как именно человек имеет знания о мире и может правильно осуществить семантическое связывание слов в предложении. Данный анализатор, по мнению его автора, может быть полезен патентоведам, изобретателям для выявления ошибок синтаксических и смысловых в формуле изобретения, юристам, для выявления ошибок синтаксиса или двойственности смысла в предложении, всем кому необходимо правильно составить текст на русском языке.
Мы попытались применить его к исследуемым текстам (которые уже были до этого обработаны вручную) с целью выявления отклонений от синтаксической нормы русского языка. Программа во многих случаях указала на несвязанные элементы предложений, однако ей не удалось выявить все случаи структурных нарушений, относимые нами к синтаксической интерференции.
Ex.: Оформление глагольного управления, временных, пространственных и других отношений во французском и русском языках реализуется различными средствами. Под влиянием французского языка происходит их переоформление в русскоязычных текстах:
(…) сосчитать на пальцах одной руки (вместо пересчитать по пальцам). - (…) se compter sur les doigts de la main [Архитектурные шедевры, серия 10]
Часть исходного предложения:
сосчитать на пальцах одной руки
часть предложения: (* сосчитать на пальцах одной руки *)
---сосчитать[1](предлог)на[2](чём)пальцах[3](чего)руки[5](какой)одной[4]
несвяз: сосчитать[1],
== в предл. слов всего:5, слов несвязано:1, из них предлогов:0, время обр: 0.000 с
сосчитать[1] на[2] пальцах[3] одной[4] руки[5]
Французский – аналитический язык, русский – синтетический. При анализе перевода французских аналитических конструкций со значением каузативности (побуждение к действию или создание определенного состояния объекта) на русский язык были выявлены случаи использования аналитических конструкций, представляющих собой кальки с французского:
Уклон железнодорожной колеи сделал бы сложным (вместо усложнил) торможение и разгон локомотивов. – Une pente a l’approche de la gare rendrait difficile le freinage et le démarrage des trains [Архитектурные шедевры, серия 11].
Часть исходного предложения:
уклон железнодорожной колеи сделал бы сложным торможение и разгон локомотивов
часть предложения: (* уклон железнодорожной колеи сделал бы сложным торможение и *)
---уклон[1](чего)колеи[3](какой)железнодорожной[2]
...уклон[1](глагол)сделал[4](что)и[8](что)торможение[7]
...................сделал[4](что)колеи[3]
часть предложения: (* разгон локомотивов *)
{и[8]}разгон[9](чего)локомотивов[10]
несвяз:бы[5], сложным[6],
== в предл. слов всего:10, слов несвязано:2, из них предлогов:0, время обр: 0.000 с
уклон[1] железнодорожной[2] колеи[3] сделал[4] бы[5] сложным[6] {и[8]}торможение[7] и[8] {и[8]}разгон[9] локомотивов[10]
Однако рассматриваемая программа не сумела распознать отмеченные нами ранее в ходе анализа факты избыточной идентификации (соотнесенности) грамматических структур, где грамматическая форма преобладает над смысловым наполнением.
Ex.: Приведенная ниже конструкция, скорее всего, ассоциируется с конструкцией être éclairé + par + предмет (источник света), которая переводится на русский язык как ‘освещенный чем-либо’ (обязательно указание источника света). Напимер: éclairé par une lampe – освещенный лампой, éclairé par le soleil – ‘освещенный солнцем’ и т.д. В результате избыточнй идентификации происходит экстраполяция данного значения на другие аналогичные конструкции без учета их семантики:
Голые стены освещены одним вертикальным окном. - Des murs nus, éclairés par une fente où rentre la lumière du jour [Архитектурные шедевры, серия 1].
Часть исходного предложения:
голые стены освещены одним вертикальным окном .
часть предложения: (* голые стены освещены одним вертикальным окном . *)
---стены[2](глагол)освещены[3](чем)окном[6](каким)одним[4]
...................................окном[6](каким)вертикальным[5]
...стены[2](какие)голые[1]
несвяз:
== в предл. слов всего:6, слов несвязано:1, из них предлогов:0, время обр: 0.000 с
голые[1] стены[2] освещены[3] одним[4] вертикальным[5] окном[6]
NooJ
Рассмотрим еще одну программу, которая показалась нам довольно любопытной и которую, как нам кажется, можно использовать при анализе некоторых видов языковой интерференции.
NooJ ( разработчик– Макс Сильберштейн\Max Silberstein). NooJ является оупенсорсным продуктом, для формализации лингвистических данных. Система включает в себя морфологический и синтаксический анализатор, а также удобные средства для разметки корпуса вручную. В NooJ встроена система визуального написания грамматик, которая позволяет создавать различные системы анализа текста. Подробное описание, руководство пользователя, электронные учебники, последние наработки и сама программа доступны (бесплатно) в Сети ссылка скрыта [16].
Мы не будем описывать здесь все возможности данной программы, а рассмотрим, как она может быть использована при изучении языковой интерференции. В качестве примера возьмем частный случай интерференции французского и немецкого языков на уровне присловных связей, наблюдаемой в швейцарской контактной зоне [2.-A]. Известно, что на территории многоязычных государств в результате языковых контактов происходит смешение языков. Так, в ходе анализа статей в швейцарских франкоязычных газетах Le Temps, Le Matin нам встретился случай ненормативного (согласно французской академической норме) глагольного управления attendre sur ‘ждать кого-л., чего-л.’, что является калькой с немецкого warten auf j-n [2.-A]. Наша задача состоит в том, чтобы проверить, единичное (случайное) ли это употребление или его можно рассматривать как устоявшийся факт языка, закрепленный в его письменной форме (в языке прессы). Для этого мы анализируем корпус франко-швейцарсикх текстов, используя NooJ. Программа производит лексический, морфологический и синтаксический анализ. В результате получаем следующие характеристики: characters (знаки), tokens (символы), digrams (биграммы - группы из двух последовательных символов), ambiguities (неоднозначные слова), unambiguous words (однозначные слова) с их количеством и частотностью их употребления.
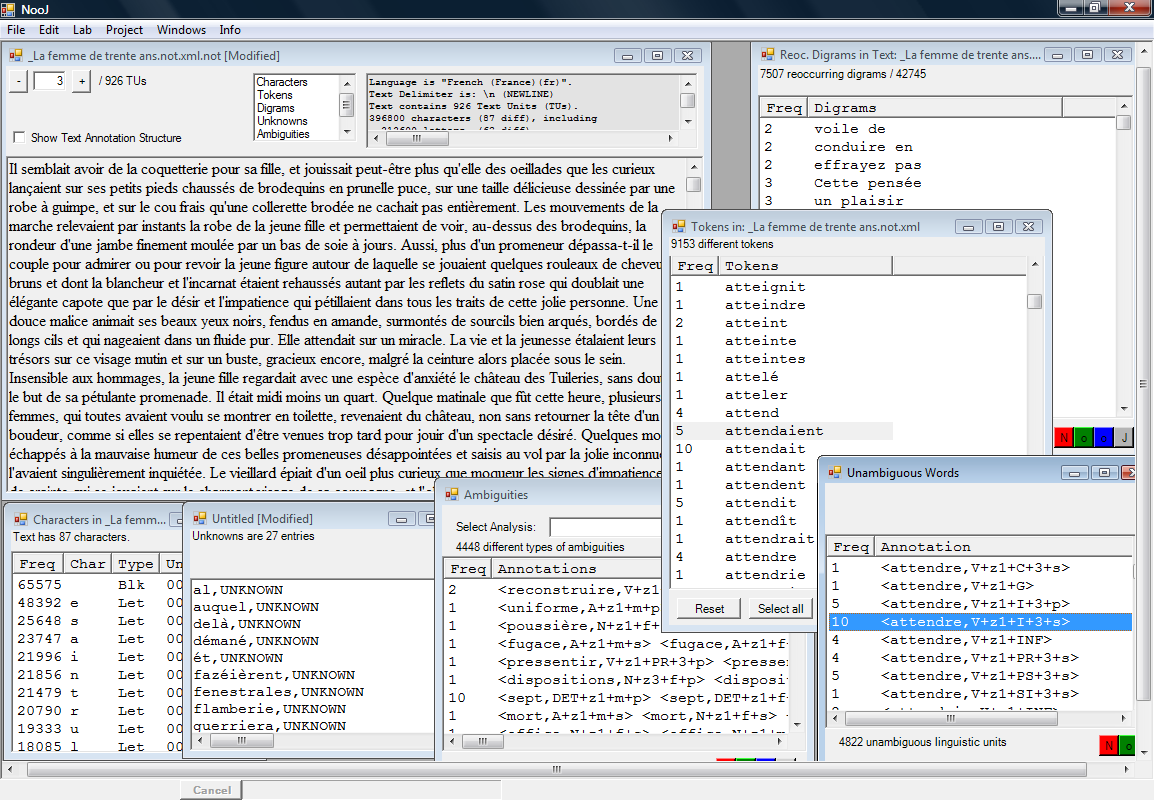
Далее в перечне (алфавитном) tokens находим все словоформы нужного нам глагола attendre ->FILTER->N. Рассматриваемая программа способна выдавать все дистрибуции заданного элемента в анализируемом тексте (или корпусе).
->FILTER
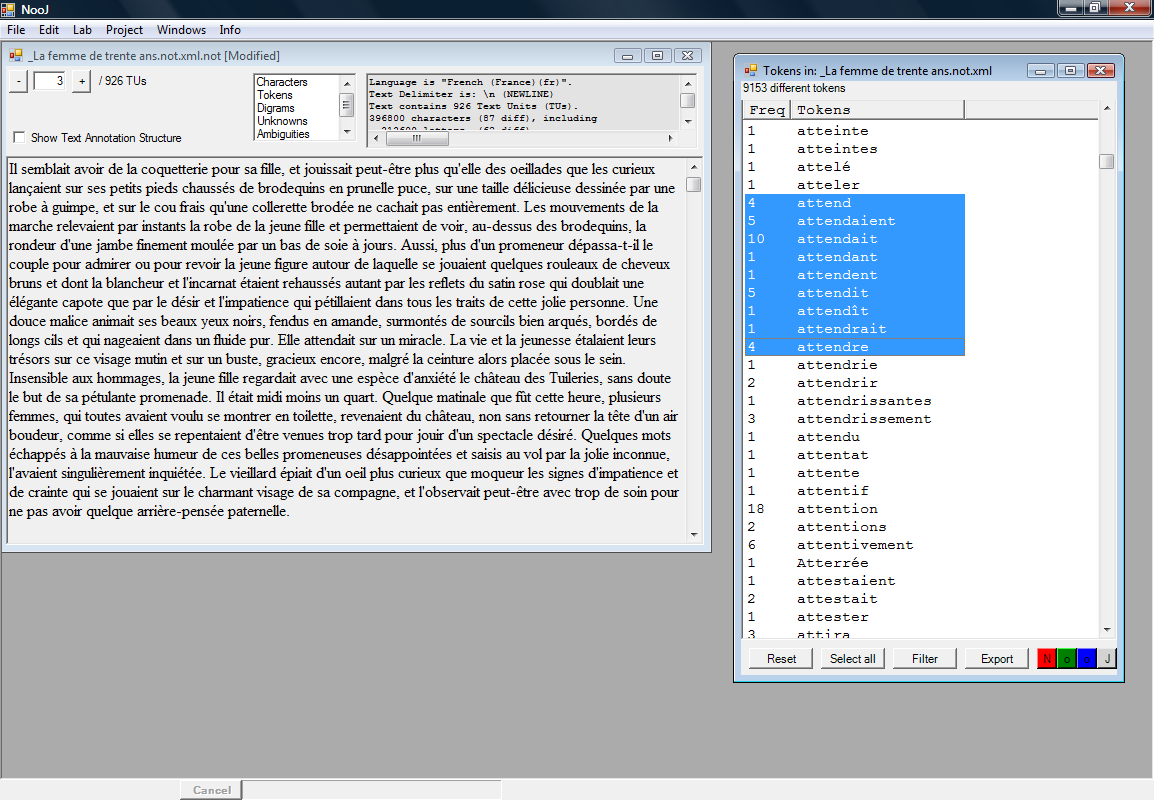
->N

Далее мы анализируем уже полученный на выходе список дистрибуций. Мы видим, что attendre sur - не случайное употребление, а элемент, вошедший в систему швейцарского французского языка.
LeoBilingua
Целью изучения феномена интерференции является разработка методик ее преодоления. Когда речь идет об интерференции в переводческой деятельности, путь к ее преодолению лежит через отработку навыков переключения (Code-Switching) с языка на язык и установки верных межъязыковых соответствий. Очень любопытным в этом отношении является описание методик, разработанных доктором филологии Лин Веем (Lin Wei) [17]. На материале английского, японского и китайского языков, Лин Вей разработал ряд мультимедийных программ для тренинга переводчиков. Языком перевода в данном случае являлся китайский. Упражнения были разделены на три уровня: семантический, синтаксический и уровень дискурса.
Однако первый этап совершенствования навыков перевода сводится так или иначе к сопоставлению языков (ИЯ/ПЯ) и текстов (ИТ/ТП).
LeoBilingua (ссылка скрыта) [15] - бесплатная программа, позволяющая генерировать билингва-текст (текст из двух синхронных половинок на разных языках). Это программа для соединения двух текстов в один, параллельный текст. Если в качестве исходных взять текст на иностранном языке и его перевод, то, по мнению авторов, получается средство для изучения иностранного языка. Как нам кажется, это хорошее средство не столько для изучения языка, сколько для совершенствования навыков перевода. Изучающее чтение и одновременное сравнение переводов являются для переводчиков одним из важных методов отработки профессиональных навыков. Можно для этой цели использовать отдельные тексты, но обычно это неудобно. LeoBilingua устраняет эти неудобства, соединяя текст из двух файлов в один билингва-текст. Программа сопоставляет друг другу абзацы из обоих текстов, позволяя показать рядом именно соответствующие абзацы. LeoBilingua предоставляет возможность корректировки обоих текстов по мере составления билингвы. Сам процесс объединения текстов можно выполнять в "ручном" режиме, то есть по одному абзацу, или автоматически. В автоматическом режиме программа приближённо контролирует соответствие абзацев и прерывает выполнение, если обнаружит подозрительное расхождение. Если абзацы действительно не совпадают, можно исправить один из текстов. При этом программа автоматически возвращается в билингва-тексте к тому месту, которое не затронуто изменением, чтобы оттуда продолжить работу.
Полученный параллельный текст (билингву) можно сохранить в её оригинальном формате XML и просматривать затем в браузере, а можно преобразовать в какой-нибудь другой формат, например HTML или MS Word.
Исходные тексты (оригинал и перевод) программа принимает в формате RTF (Rich Text Format) или в виде текстовых файлов (неформатированный текст). Программу характеризует гибкий пользовательский интерфейс: настройка внешнего вида, использование подключаемых преобразований, а также наличие подробной справочной документации на русском языке. Из недостатков программы следует отметить то, что она не умеет использовать файлы формата MS Word (*.doc). Однако формат RTF очень распространён, в нём могут сохранять файлы многие текстовые редакторы, в том числе MS Word и Open Office.
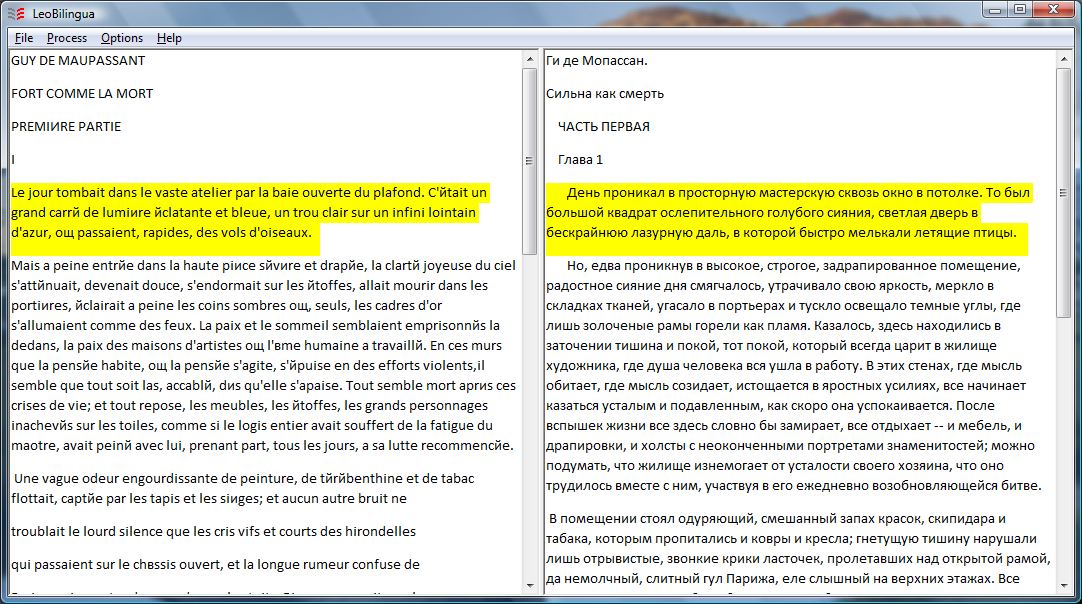
Таким образом, данная программа может быть использована при самоподготовке переводчиков.
Заключение.
Перевод – особый вид речевой деятельности, возможный только при смешанном типе продуктивного двуязычия, включающий в себя умение переводчика воспринимать информацию, данную ему в рамках одного кода (исходного языка), и воспроизводить ее средствами другого кода (языка перевода), добиваясь при этом максимальной эквивалентности оригинала и его перевода. Переводчик, являясь билингвом по определению, вынужден все время сопоставлять языки и искать в них соответствия, чтобы выработать строгую систему эквивалентов.
В процессе своей профессиональной деятельности переводчик осуществляет постоянное переключение с одного языка на другой, суть которого, вероятно, заключается в изменении установки на использование того или иного языка. Успешное переключение гарантирует произведение правильного текста. Следствием неудачного переключения является языковая интерференция, которая может возникать на всех уровнях языка.
Явление интерференции имеет психофизиологические и лингвистические причины. Среди предполагаемых причин языковой интерференции с наибольшей долей уверенности можно выделить недостаточную или избыточную идентификацию элементов и функций языков, контактирующих в сознании билингва, а в качестве лингвистических причин интерференции следует рассматривать расхождения и сходства контактирующих языков.
Лингвистический анализ текста перевода на предмет присутствия в нем иноязычных элементов и структур – процесс довольно трудоемкий, который занимает много времени, при этом он дает небольшой объем фактического материала. Однако на данном этапе развития ИТ лингвисты владеют значительным инструментарием для текстового анализа. В сети Интернет представлены ряд бесплатных версий программ, связанных с анализом текстов и вычислительной лингвистикой. Данные программы могут применяться и при исследовании феномена языковой интерференции, что можно осуществлять как на этапе изучения самого явления интерференции, так и на этапе ее преодоления.
Список литературы к реферату
Список использованных источников
- Алимов, В. В. Интерференция в переводе (на материале профессионально ориентированной межкультурной коммуникации и перевода в сфере профессиональной коммуникации): учебное пособие / В.В. Алимов. – М.: КомКнига, 2005. – 232 с.
- Вайнрайх, У. Языковые контакты / У. Вайнрайх. - Киев: «Вища школа», 1979. – 268 с.
- Васильев, А. Компьютер на месте переводчика / А. Васильев // [Электронный ресурс]. - Режим доступа: ссылка скрыта. - дата доступа: 29.11.2008.
- Всеволодова, А. В. Применение информационных технологий при обучении лингвистов / А.В. Всеволодова// [Электронный ресурс]. – 2003 – Режим доступа: ссылка скрыта. - Дата доступа: 5.12.2008.
- Лингвистический энциклопедический словарь / гл. ред. В.Н. Ярцева. - М.: Большая Российская энциклопедия, 2002. – 709 с.
- Лотман, М.Ю. Мозг - текст - культура - искусственный интеллект. / М.Ю. Лотман// [Электронный ресурс]. – Режим доступа: ссылка скрыта. - Дата доступа: 7.10.2008.
- Лукиных, Т.Н. Компьютеризированный анализ текста / Т.Н. Лукиных// Историография клиометрики (учебное пособие). [Электронный ресурс] – Томск, 2003 – Режим доступа: ссылка скрыта. - Дата доступа: 5.12.2008.
- Мунен, Ж. Теоретические проблемы перевода. Перевод как языковой контакт / Ж. Мунэн // Вопросы теории перевода в зарубежной лингвистике: сб. ст. / отв. ред. В. Н. Комиссаров. - М.: Прогресс, 1978. - С. 36-41.
- Никитченко, Т. Г. Субъективный фактор в художественном тексте: лингвистический и психологический аспекты на материале перевода: автореф. диссертации … канд. фил. наук: 10.02.19 / Т.Г. Никитченко; Кубанский гос. ун-т. - Краснодар, 2000. – 19 с.
- Петров, А.Н. Компьютерный анализ текста. Историография метода / А.Н. Петров// Круг идей: модели и технологии исторической информатики: труды III конференции ассоциации «История и компьютер» [Электронный ресурс]. – Режим доступа: ссылка скрыта. - Дата доступа: 5.12.2008.
- Русская виртуальная библиотека [Электронный ресурс]. – Режим доступа: ссылка скрыта. - Дата доступа: 17.11.2008.
- Сайт РВБ [Электронный ресурс]. – Режим доступа: ссылка скрыта. - Дата доступа: 10.12.2008.
- Синтаксический on-line анализатор естественного текста на русском языке [Электронный ресурс]. – Режим доступа: ссылка скрыта. - Дата доступа: 14.12.2008.
- Interferenz in der Translation/ Herausgegeben von Heide Schmidt. – VEB Verlag Enzyklopädie. – Leipzig, 1989. – 144 p.
- LeoBilingua [Электронный ресурс]. – Режим доступа: ссылка скрыта. - – Дата доступа: 14.12.2008.
- NooJ [Электронный ресурс]. – Режим доступа: ссылка скрыта. – Дата доступа: 14.12.2008.
- Wei, L. Positive Transfer: A Neuropsychological Understanding of Interpreting and the Implications for Interpreter Training / L. Wei // [Электронный ресурс]. - Режим доступа: apid.com/Journal/21interpret.htm. - Дата доступа: 10.12.2008
Список публикаций магистранта
- – А. Савко, М.В. Грамматическая интерференция в переводах аудио-медиальных текстов с французского на русский язык / М.В. Савко // Материалы докладов XV Междунар. конф. студентов, аспирантов и молодых ученых «Ломоносов», Москва, 8-11 апреля 2008 г. / Моск. гос. ун-т; отв. ред.: И.А. Алешковский, П.Н. Костылев. [Электронный ресурс] — М.: Издательство МГУ; СП МЫСЛЬ, 2008.
- – А. Савко, М.В. Интерференция французского и немецкого языков в швейцарской контактной зоне: некоторые тенденции/ М.В. Савко// Идеи. Поиски. Решения: материалы I Республиканской науч. практ. конф. , Минск 28 марта 2008 г., г. Минск : в 2 т. Бел. гос. ун-т/ ред. Нижнева Н.Н. – Т.1. – Мн.: БГУ, 2008. - стр. 40-44.
Предметный указатель к реферату
б
билингвизм 2
и
интерференция 1, 2, 3, 4, 5, 6, 7, 11, 12, 14, 17, 20
информационные технологии 7
исходный язык (ИЯ) 2, 3, 4, 11, 20
И
ИТ 8
к
кластерный анализ 9
компьютерный анализ 8
контент - анализ 9
м
машинный перевод 3, 11
п
перевод 2, 3, 4, 6, 7, 8, 10, 11, 12, 17, 18, 20
перцептивный эталон 4
т
текст перевода 3, 11
теория перевода 2
теория языковых контактов 2, 5
я
язык перевода 2, 4, 20
языковой контакт 2, 5, 6