
Системантика
| Вид материала | Монография |
Содержание4. Машинный перевод 5. Индексирование документов и запросов |
4. Машинный перевод
Под переводом понимается смысловое преобразование текста с одного языка (естественного или искусственного) на другой. В основе любого перевода лежит моделирование речевой деятельности человека. Она состоит из двух взаимосвязанных и взаимопроникающих аспектов. Один аспект представляет знания субъекта речевой деятельности о мире, о реальности и о себе. Другой аспект представляет его знания о языке, на котором практически реализуется языковая коммуникация. В процессе общения задействуются их части, касающиеся предмета разговора. Обобщенная функциональная технология любого перевода в инвариантном к языкам виде может быть схематично представлена абстрактной блок-схемой (рис. 93).
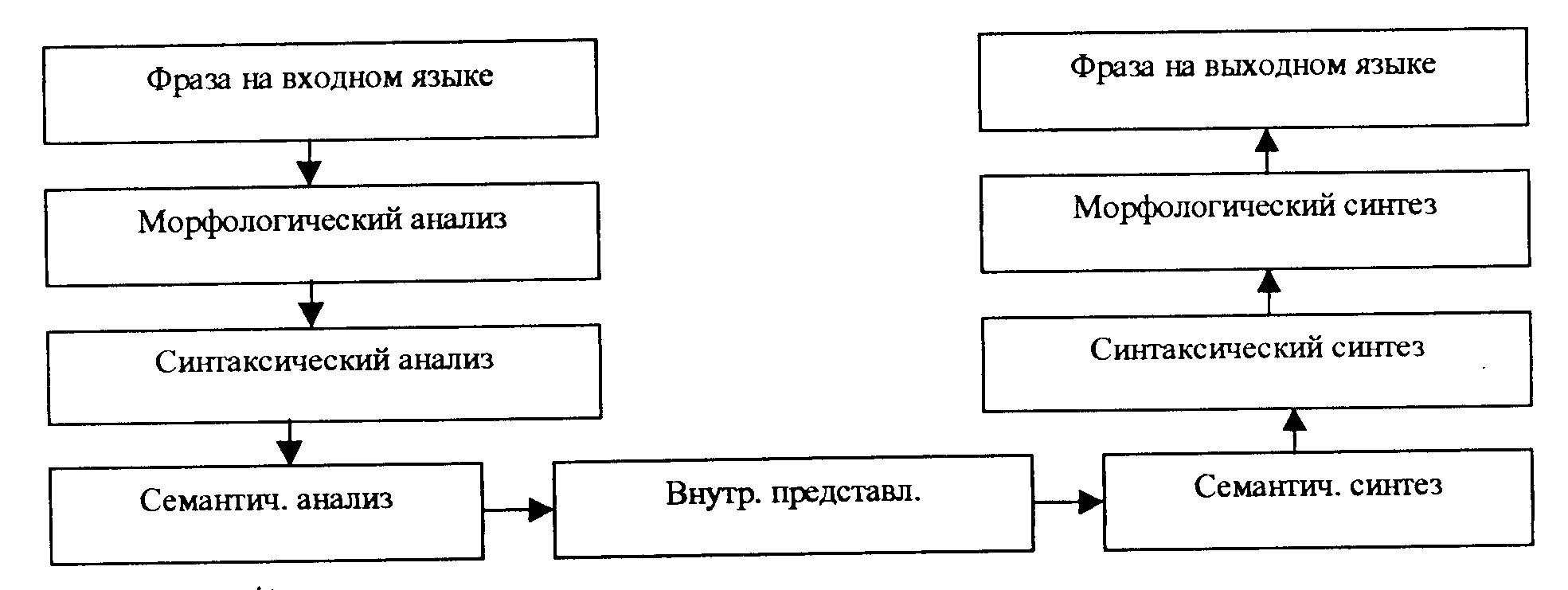
Рис. 93. Общая блок-схема дедуктивного машинного перевода
Машинный перевод – это выполнение показанных функций с помощью вычислительной техники. Традиционно он делится на два вида: дедуктивный и индуктивный.
Дедуктивный машинный перевод базируется на модели «текст – смысл – текст», основанной на пословной лексике и грамматических правилах. Такой перевод при сравнительно небольших словарях требует моделировать сложные грамматические процессы речевой деятельности человека.
Моделью индуктивного перевода является модель «текст – текст». Он осуществляется на переводных соответствиях фраз и выражений. Переводным соответствием называют пару, образованную отрезком входного текста и отрезком выходного текста, между которыми существует отношение смысловой эквивалентности. Это могут быть отдельные слова, словосочетания, фразы и возможно более длинные контекстные выражения. Переводное соответствие можно понимать как единицу перевода, взятую в динамике трансляционного процесса, различаемую в условиях конкретного текста, в рамках данной пары языков. В таком переводе основной переводной единицей выступают фразы, которые, с одной стороны, естественны для двуязычного общения людей, но, с другой стороны, требуют больших фразеологических словарей. Следует иметь в виду, что природе естественного языка присуща универсальная соразмерность сложности грамматических правил и объемов унитермных грамматических словарей. Для перевода текстов конкретных предметных областей упрощение грамматических правил вызывает необходимость существенного увеличения объемов фразеологических словарей. Для преодоления возникающей коллизии идут по пути объединения индуктивного и дедуктивного методов, обеспечивающих сочетание пословного и фразеологического перевода. В них доминантными единицами перевода выступают фразы. Но если при фразеологическом переводе остаются не охваченные эталонной фразой непереведенные слова, что влияет на качество перевода, то возможен и пословный перевод. Для таких систем машинного перевода кроме фразеологического словаря необходим и пословный.
В качестве примера такой системы можно привести систему RETRANS, находящуюся в промышленной эксплуатации1.
Система RETRANS построена на индуктивно-дедуктивном принципе фразеологического машинного перевода с автоматическим составлением двуязычных фразеологических машинных словарей по текстам, которые являются переводами друг друга (по биллингам). Созданы русско-английский и англо-русский политематические фразеологические машинные словари объемом 2,6 миллиона словарных статей или словари на бумажных носителях объемом 80 томов по 1 000 страниц каждый. При установленной необходимости повышения точности перевода после фразеологической фильтрации по кодам система аналогичным образом, автоматически по тексту выделяет непереведенные слова, составляет пословные словари и отождествляет по ним отдельные слова переводимого текста также по кодам.
Коды выступают единым целостным машинным носителем смысла переводимого двуязычного текста, а словари при этом выполняют роль смысловых фильтров.
5. Индексирование документов и запросов
Процесс перевода основного содержания документа и запроса с естественного языка на информационно-поисковый с одновременным свертыванием текста при максимальном сохранении смысла получил название индексирования. Иными словами, индексирование – это выражение центральной темы текста средствами информационно-поискового языка, процесс составления поискового образа документа и запроса.
Процесс составления поисковых образов документов состоит из двух этапов:
1) анализ содержания документа и выявление главной темы (ключевых слов);
2) выбор терминов, входящих в поисковые образы документов (замена ключевых слов терминами информационно-поискового языка).
Анализ содержания документа проводится в определенной последовательности по единой схеме. Схема способствует повышению качества и постоянства индексирования. Выявление содержащейся в документе информации проводится по следующим смысловым аспектам:
определение предмета или темы;
описание основных характеристик предмета;
установление элементов предмета и их отношений;
установление связей предмета с другими предметами;
установление области применения предмета.
Эти смысловые аспекты составляют элементы формализованной модели свернутого содержания документа. В соответствии с этими смысловыми аспектами осуществляется выбор ключевых слов.
Выбор терминов, входящих в поисковые образы документов, находится в зависимости от принятого информационно-поискового языка. Наиболее распространенными являются языки классификационного и дескрипторного типа или их комбинации.
Процесс индексирования с помощью классификации представляет собой процесс соотнесения содержания текста документа со смысловым содержанием рубрик классификатора. При этом возможна замена выделенных ключевых понятий синонимичными или нижестоящими и вышестоящими. Подобный процесс выполняется для каждого выделенного понятия. Отождествленные с ключевыми понятиями рубрики записываются в поисковый образ документа (см. рис. 94).
Методика индексирования запросов определяется типом запроса и характером информации, ожидаемой в качестве ответа. В этом смысле выделяют два типа запросов:
1) запросы, ориентированные на получение информации по определенному предмету с указанием интересующих характеристик – так называемые многоаспектные узкоспециализированные запросы;
2) запросы обобщающего или обзорного типа, ориентированные на получение информации по группе предметов или по какой-либо теме.
Методика индексирования запросов первой группы мало чем отличается от методики индексирования документов. Методика индексирования запросов второй группы состоит в разбиении запроса на подзапросы с их последующим индексированием и объединением результатов в один поисковый образ.
Аналогичны процедуры индексирования на языке дескрипторного типа.
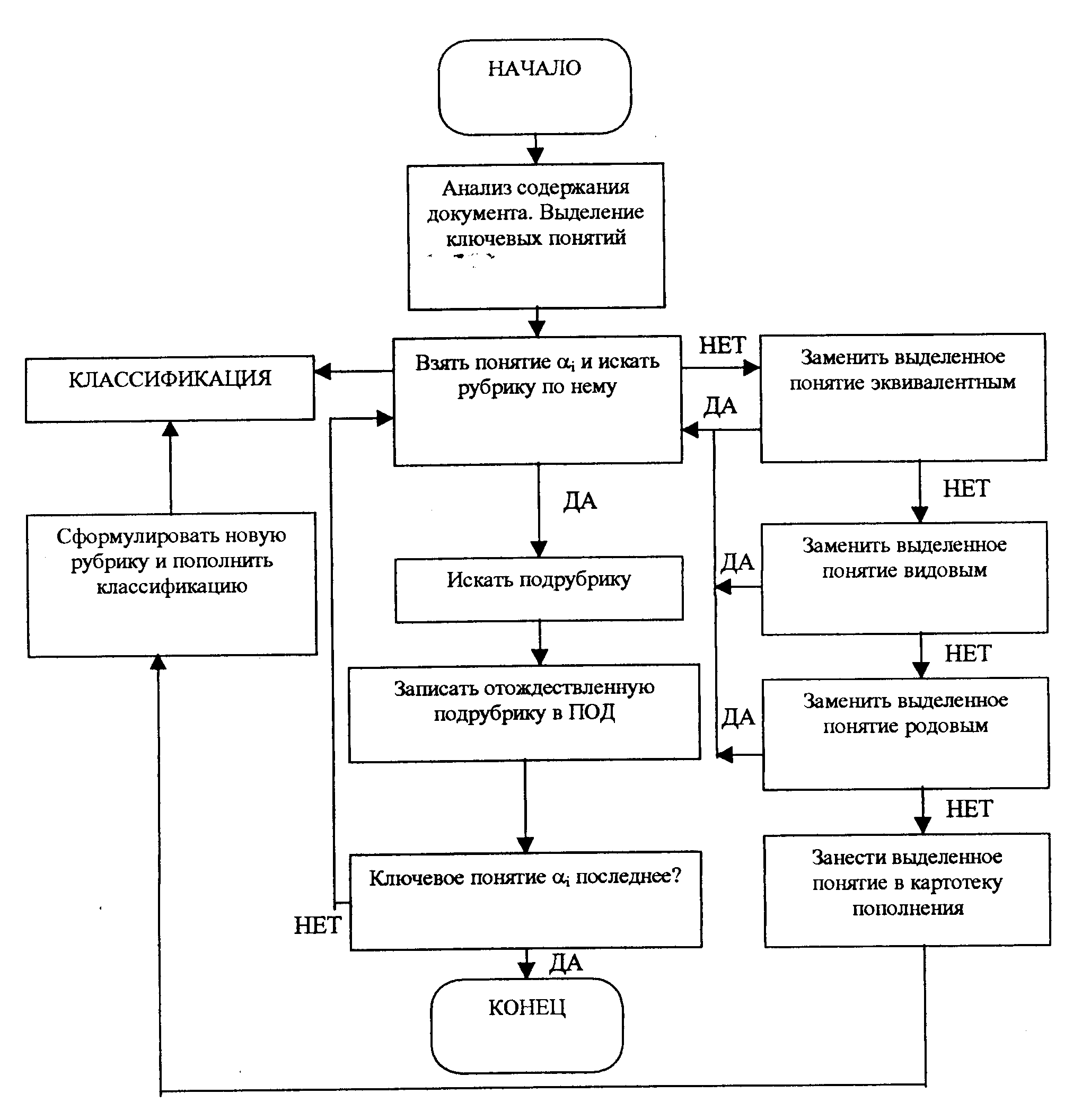
Рис. 94. Схема индексирования на классификационных ИПЯ