
Информатика, вычислительная техника и инженерное образование. − 2011, №4 (6) раздел II. Искусственный интеллект и нечеткие системы
| Вид материала | Документы |
- Информатика, вычислительная техника и инженерное образование. − 2011, №4 (6) раздел, 247.88kb.
- «Информатика и вычислительная техника», 723.11kb.
- Рабочая программа дисциплины «Системы искусственного интеллекта» по направлению подготовки, 132.28kb.
- Рабочая программа дисциплины «Компьютерные системы поддержки принятия решений» по направлению, 133.4kb.
- Рабочая программа дисциплины «Теория систем» по направлению подготовки дипломированного, 142.63kb.
- Рабочая программа дисциплины «Компьютерная графика» по направлению подготовки дипломированного, 108.6kb.
- Рабочая программа дисциплины «Методы оптимизации» по направлению подготовки дипломированного, 132.79kb.
- Рабочая программа дисциплины «Параллельные вычислительные процессы» по направлению, 108.72kb.
- Рабочая программа дисциплины «Инструментальные средства 3D графики» по направлению, 112.55kb.
- Рабочая программа дисциплины «Теория принятия решений» по направлению подготовки дипломированного, 176.95kb.
Информатика, вычислительная техника и инженерное образование. − 2011, № 4 (6)
РАЗДЕЛ II. ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ И НЕЧЕТКИЕ СИСТЕМЫ
УДК 004.67
А.И. Долгий, Д.А. Кузменов
ПОИСК НЕЧЕТКО-ТЕМПОРАЛЬНЫХ ОБРАЗОВ В БАЗАХ ДАННЫХ ГЕОДИАГНОСТИЧЕСКИХ СИСТЕМ1
Предложенные в настоящей работе алгоритмы поиска частных нечетко-темпоральных структур основаны на идеях, применяемых в методе «априори», основным отличаем которых от классических алгоритмов поиска, является учет специфики баз данных нечетко-темпоральных признаков и темпоральное представление выявляемых видов частных структур, которые могут быть легко представлены в лингвистической форме, удобной для непосредственного использования в системах текстового резюмирования.
Поиск знаний; нечетко-темпоральные структуры; текстовое резюмирование.
A.I. Dolgiy, D.A. Kuzmenov
SEARCH FUZZY-TEMPORAL STRUCTURES IN DATABASES OF GEODIAGNOSTIC SYSTEMS
The algorithms of search offered in the present work private fuzzy-temporal structures are based on ideas applied in a method "a priori". The differences from classical algorithms of search, is that account of specificity of databases of fuzzy-temporal signs and temporal representation of revealed kinds of private structures which can be easily presented in the linguistic form for direct use in natural language generation systems.
Knowledge discovery, fuzzy-temporal structures, language generation systems.
В настоящей статье предлагается метод извлечения ассоциативных правил из баз данных временных рядов (БД ВР), ориентированный на специальный класс темпоральных структур нашедший широкое применение в системах текстового резюмирования [2]. Используемые в алгоритмах идеи представляют собой комбинацию известных методов к выявлению знаний из БД ВР не определенных заранее, но ориентированных на их использование в БД нечетко-темпоральных признаков геодиагностических систем (НТП ГДС).
В области поиска знаний выделяют несколько направлений, из которых важнейшими для нас (в контексте задач геодиагностики) являются: поиск аномалий, редко встречающихся, но представляющих интерес для пользователя событий и поиск мотивов, часто встречающихся образов, имеющих осмысленную интерпретацию в том или ином контексте.
Определение аномалий, часто еще называемое поиском «новинок», применяется для определения неисправностей при технологическом контроле объектов, диагностировании, определения сетевых атак и т.п., а в нашем случае – при диагностике почвенных покровов. Существующие методы поиска аномалий базируются на простой идее – интересные события-новинки обычно проявляют себя редко, а, следовательно, для определения аномалий можно создать модель нормального состояния ВР и входные данные, не соответствующие в достаточной мере модели, отмечать как аномальные.
Общая поисковая схема приведена на рис. 1, состоит из пяти этапов, охватывающих все основные операции, связанные с предобработкой и постобработкой данных. Алгоритмы поиска предполагаются в отдельности для каждого из этапов (рис. 1).

Рис. 1. Общая схема поиска знаний
Особенностью данной поисковой схемы является ее иерархический принцип организации в соответствии с иерархией представления основных уровней знаний в HFTI-модели [1], а также наличие обратных связей между различными иерархическими уровнями, что связано с необходимостью многократного повторения одних и тех же этапов в процессе поиска знаний. Межуровневые обратные связи (см. рис. 1) обозначены пунктирными линиями. После нахождения образов для одного уровня HFTI-модели необходимо провести аккуратную проверку результатов на предмет их полезности и интерпретационной пригодности для другого уровня. Промежуточные результаты могут давать подсказки касательно выявленных темпоральных отношений и структур в данных и могут навести на мысль о пересмотре ранее заданных параметров. Кроме того, полезно “фильтрование” результатов, позволяющее исключить из дальнейшего рассмотрения ложных или не релевантных результатов, сокращая тем самым пространство поиска для образов на последующих уровнях анализа.
Нахождение HFTI-образов включает в себя не только выявление фактов наличия образов, но также и определение их синтаксиса для формального представления в БЗ. Использование семиотических кортежей на всех уровнях HFTI-модели позволяет автоматически генерировать названия образов во время поиска и использовать их для лучшего осмысления результатов, повышая тем самым их интерпретационную пригодность выявленных образов.
Темпоральные структуры будем представлять в виде последовательного описания
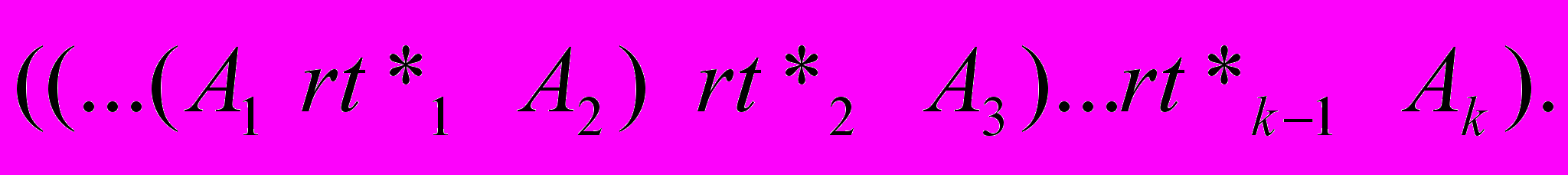 , в которых элементарные события представлены тройками
, в которых элементарные события представлены тройками  , где P – НТС в классе событий типов
, где P – НТС в классе событий типов 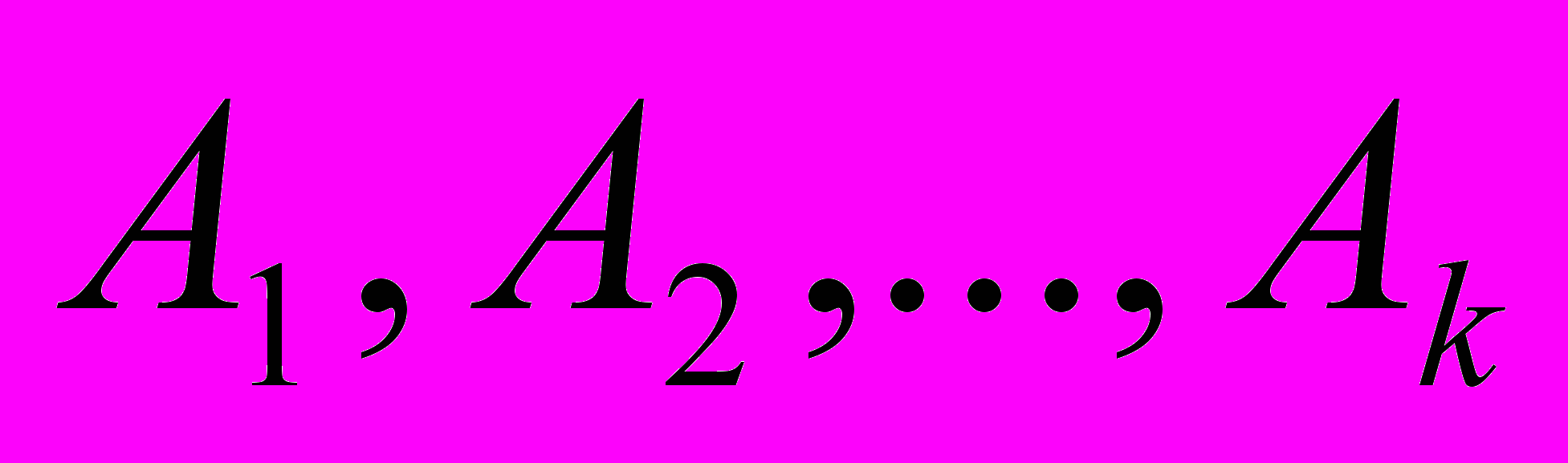 и отношений
и отношений 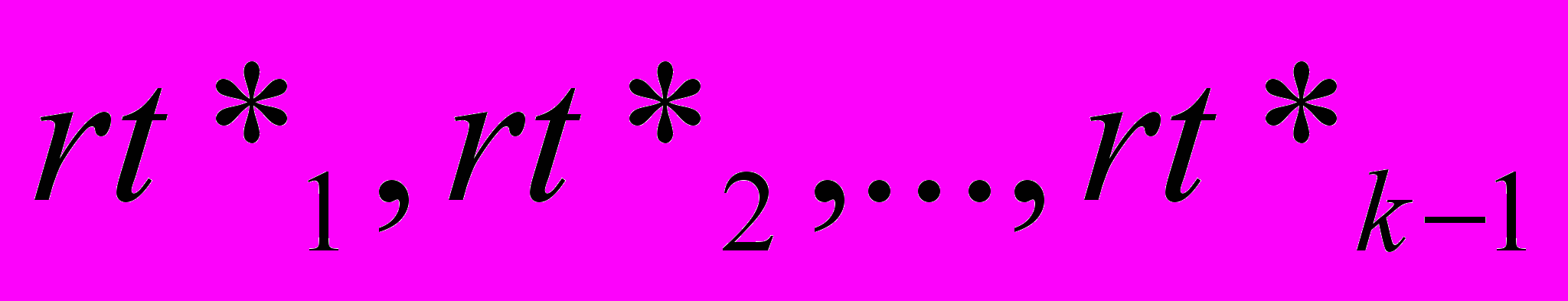 , где
, где  . Последовательность троек элементарных событий образует транзакционную БД D, в которой осуществляется поиск информативных образов.
. Последовательность троек элементарных событий образует транзакционную БД D, в которой осуществляется поиск информативных образов.Идея поисковых алгоритмов заключается в нахождении наиболее «типичных» образов в исследуемом ВР, где под критерием типичности понимается формализованная оценка поддержки образа (частоты его встречаемости или его мощности) во временном ряде. В нашем конкретном случае, определим поддержку НТС P в БД НТП D через отображение НТС Р в последовательности НТП S.
Определение 1. Элементарная НТС X имеет отображение в последовательности S, если в этой последовательности, возможно найти событие E типа X. Обозначим такое отображение, как
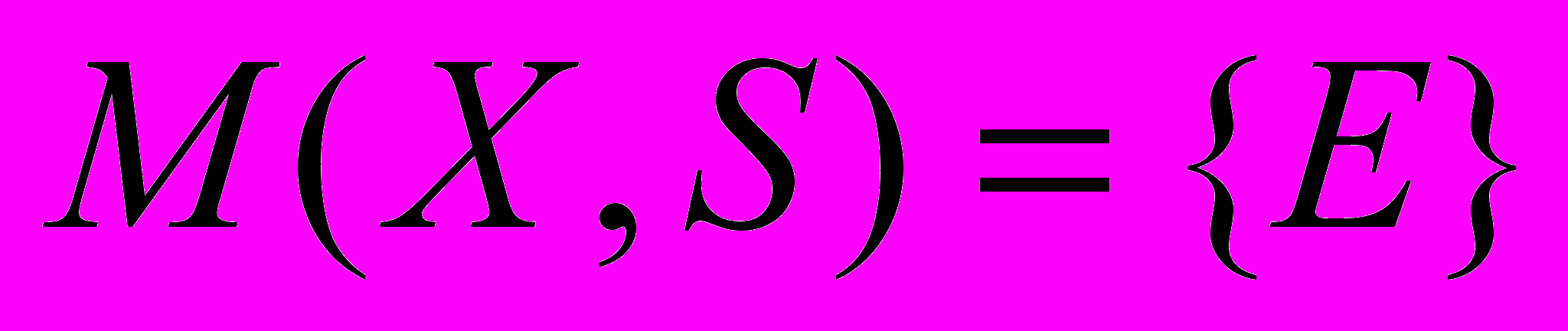 , тогда,
, тогда, 
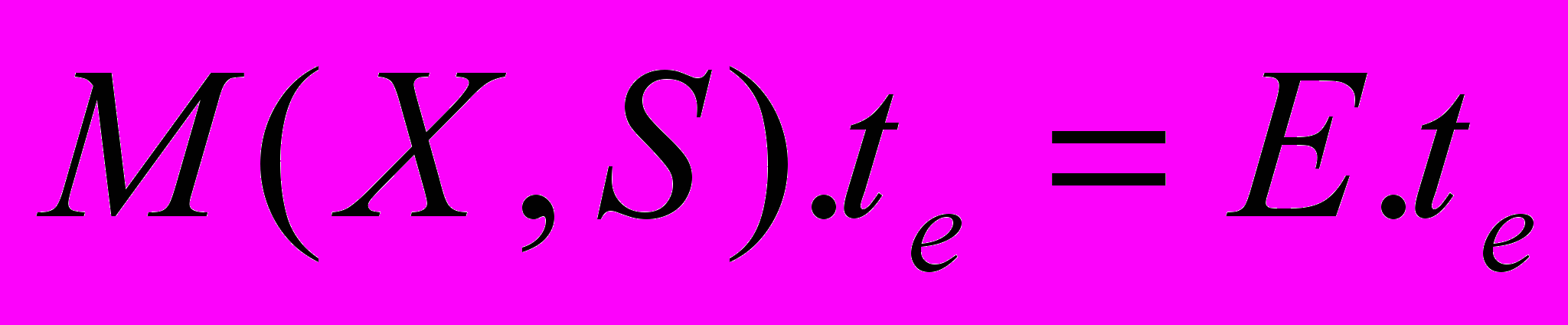 , после чего можно сказать, что X удерживается в S.
, после чего можно сказать, что X удерживается в S.Составная НТС (X rel Y), в которой Y – элементарный НТС и
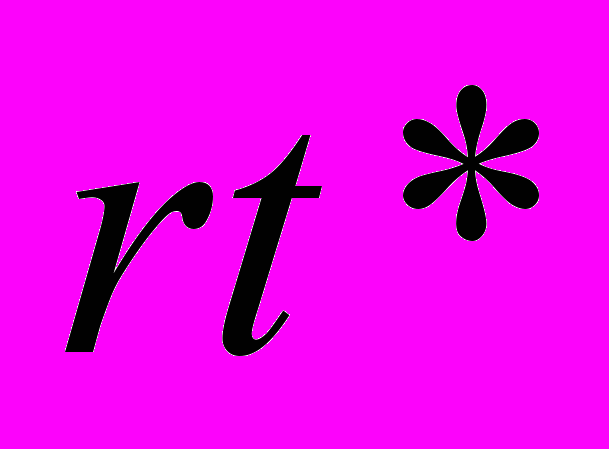
 RTP имеет отображение
RTP имеет отображение  в последовательности S, если X имеет отображение
в последовательности S, если X имеет отображение  в S и возможно найти событие
в S и возможно найти событие  типа Y в S, которое может быть отображено, как
типа Y в S, которое может быть отображено, как 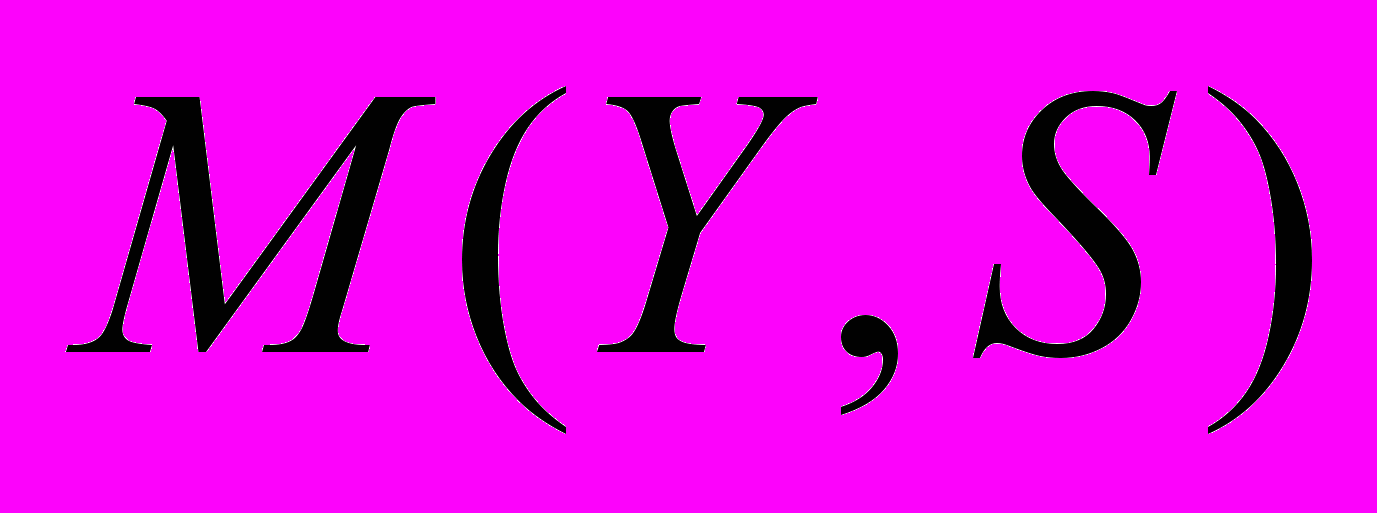 , так что если рассмотреть некоторое событие Z c начальным временем
, так что если рассмотреть некоторое событие Z c начальным временем  и конечным временем
и конечным временем 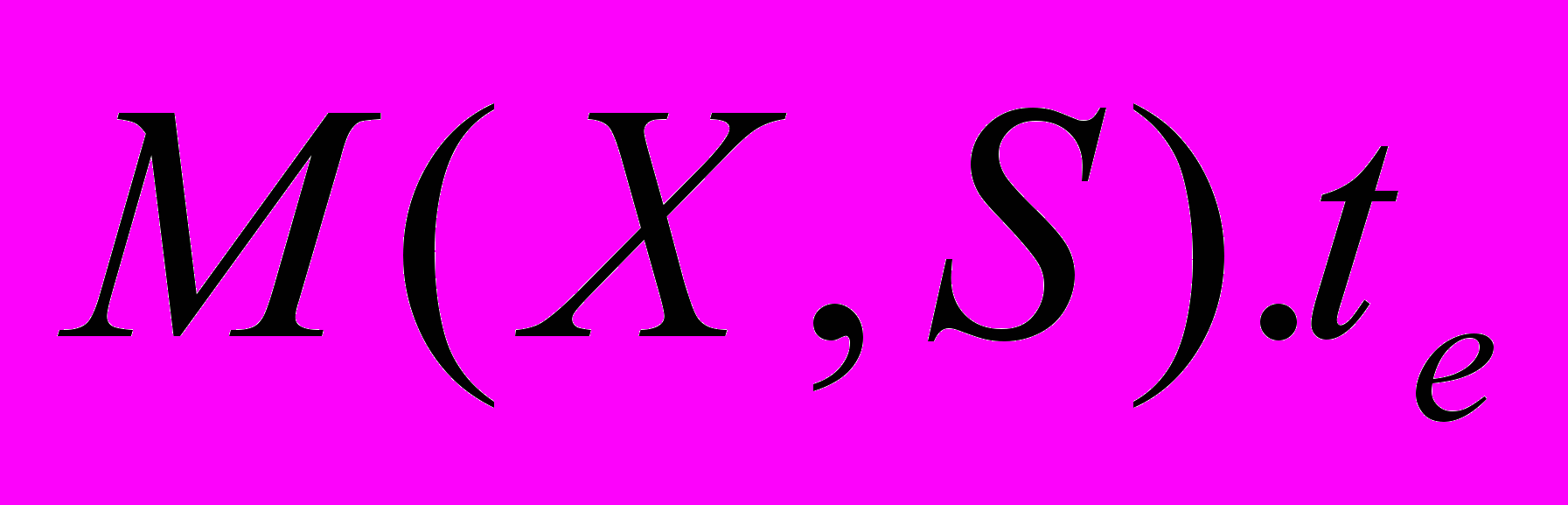 , выражение Z E будет истинно.
, выражение Z E будет истинно.В этом случае
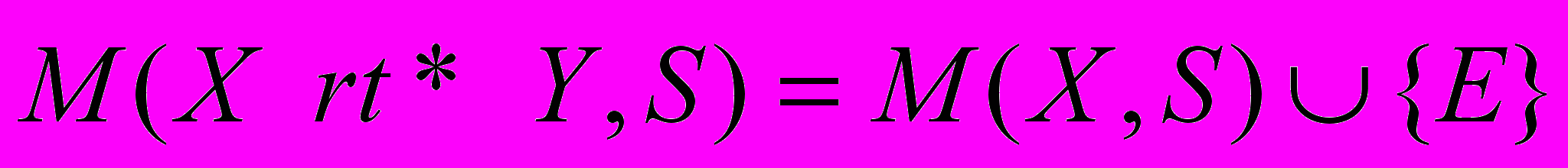 и можно сказать, что отношение (X rel Y) удерживается в S. Отображение M((X Y),S) имеет соответствующий временной интервал:
и можно сказать, что отношение (X rel Y) удерживается в S. Отображение M((X Y),S) имеет соответствующий временной интервал: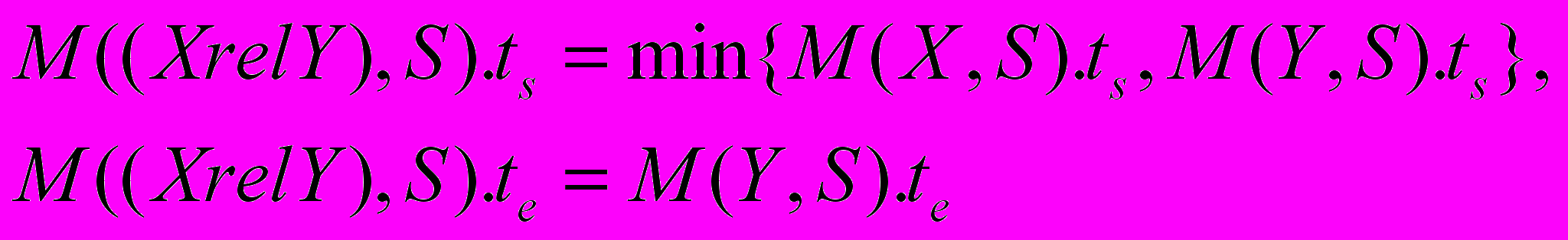
Определение 2. Поддержку НТС P в БД НТП D опишем следующим выражением:

где M – отображение НТС Р в рассматриваемой последовательности НТП S.
Поддержка k-элементного множества – это поддержка НТС в k-элементном множестве. Устойчивое k-элементное множество – это k-элементное множество, поддержка которого превышает некоторое пороговое значение, называемое минимальной поддержкой, поэтому support(P,D)≥min_sup.
Рассмотрим БД НТП D, представленную в табл. 1. Каждый набор содержит идентификатор радарограммы, значения выявленных в ней НТП и интервалы их проявления. Для облегчения последующей работы с БД НТП в [3,4] были предложены различные варианты структур представления БД, именуемые «список последовательностей» и «список элементов» соответственно. При разработке алгоритмов выявления НТС выяснилось, что основным недостатком формата «списка последовательностей» является необходимость полного обхода всей БД при очередной итерации цикла. Эта проблема решается при использовании формата «список элементов», так как такая структура БД позволяет вычислять уровень поддержки k-элементных множеств посредством прямой композиции столбцов. Размер списка и количество кандидатов уменьшается с увеличением длины формируемой последовательности, что способствует уменьшению вычислительной сложности.
Таблица 1
БД НТП
| Идентификация радарограммы | НТП | Начальное время | Конечное время |
| 1 | А | 1 | 100 |
| 1 | B | 50 | 150 |
| 1 | D | 100 | 250 |
| 1 | C | 150 | 200 |
| 1 | B | 200 | 250 |
| 2 | A | 1 | 100 |
| 2 | B | 50 | 175 |
| 2 | D | 100 | 250 |
| 2 | C | 175 | 225 |
| 3 | A | 1 | 75 |
| 3 | B | 150 | 175 |
| 3 | D | 150 | 300 |
| 3 | C | 175 | 275 |
Таблица 2
БД НТП в формате списка последовательностей
| Идентификация радарграммы | Список последовательностей |
| 1 | (А,1,100), (B,50,150), (D,100,250), (C,150,200), (B, 200, 250) |
| 2 | (А, 1, 100), (B, 50, 175), (D, 100, 250), (C, 175, 225) |
| 3 | (А, 1, 75), (B, 150, 175), (D, 150, 300), (C, 175, 275) |
Таблица 3
БД НТП в формате списка элементов
| Элемент | A | B | C | D |
| | (1,1,100) (2, 1, 100) (3, 1, 75) | (1,50,150) (1, 200, 250) (2, 50, 175) (3, 150, 175) | (1,150,200) (2, 175, 225) (3, 175, 275) | (1,100,250) (2, 150, 300) (3, 100, 250) |
Основной стратегией предлагаемого метода выявления НТС из БД НТП, является использование идеи алгоритма «априори» [3].
Общую структуру метода разделим на две фазы:
1) формирование «кандидатов»;
2) формирование устойчивых k-элементных множеств.
Принцип работы метода заключается в последовательной итерационной реализации предложенных фаз до тех пор, пока процедуре поиска новых k-элементных множеств не удастся сформировать ни одного нового кандидата Ск, удовлетворяющего пороговому значению поддержки.
Остановимся более подробно на каждой из фаз. Фаза генерации кандидатов начинается с рассмотрения списка элементов устойчивых (k-1)-элементных множеств Lk-1, найденных при предыдущей итерации. Очередной кандидат Ск генерируется путем объединения одного элемента из списка Lk-1 с другим элементом из списка L1, в котором содержатся элементарные НТС, состоящие из одного НТП (табл. 3).
Таблица 4
Устойчивые 2х-элементные множества
-
Элемент
кол.
Элемент
кол.
Элемент
кол.
А накладывается на B
2
А до B
2
C в течение D
3
(1, 1, 150)
(1, 1, 175)
(1, 1, 250)
(1, 1, 175)
(1, 100, 250)
(2, 100, 250)
(3, 150, 300)
Таблица 5
Кандидаты в 3х-элементные множества
| Составная часть | Элементарная часть |
| А накладывается на B | C |
| А накладывается на B | D |
| А до B | C |
| А до B | D |
| … | … |
При каждой итерации цикла производится отсеивание кандидатов Ск, не удовлетворяющих следующему условию:
Условие 1. Пусть bi – (k-1)-элементное множество −
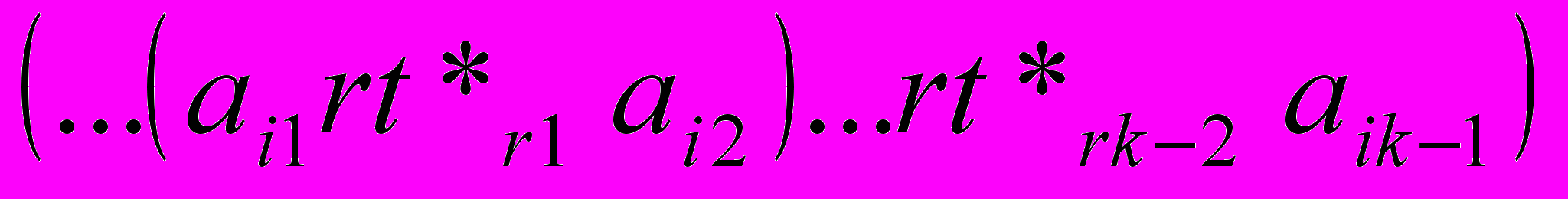 , где
, где  . Если
. Если 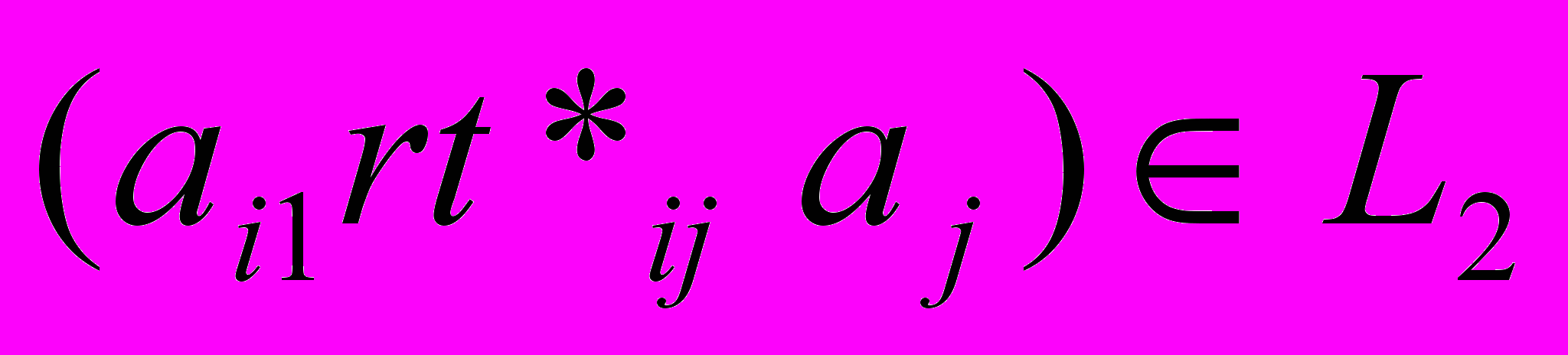 или
или 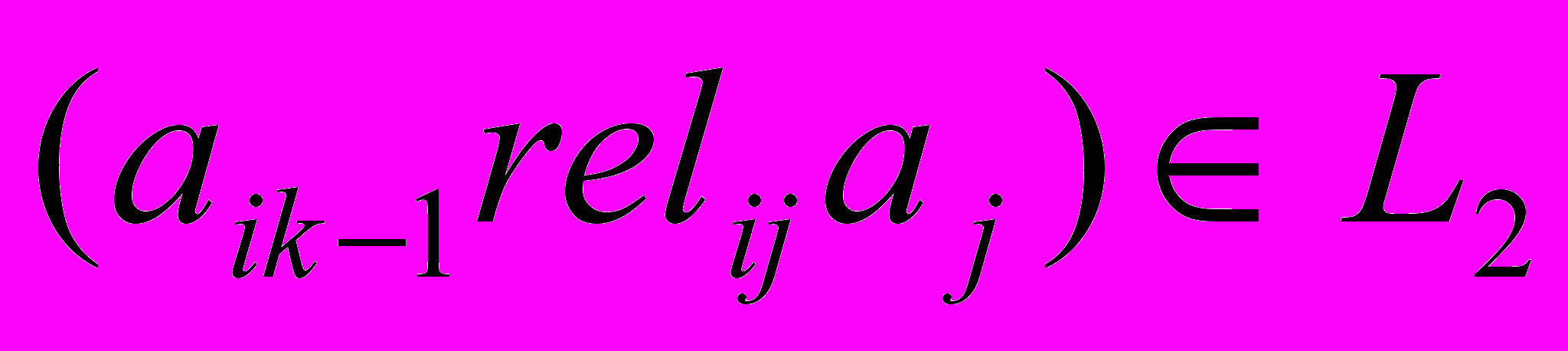 для всех
для всех  , то кандидат
, то кандидат  принимается.
принимается.Например, при формировании очередного кандидата на основе двухэлементной НТС «С в течение D» и НТП А, необходимо установить все возможные темпоральные отношения между ними. В априорных данных, полученных при предыдущей итерации, не было зафиксировано ни одного устойчивого двухэлементного множества типа «C
A» или «D A». В связи с этим, по Условию 1, возможность существования кандидата «С в течение D» с А исключается для поколения устойчивых трехэлементных множеств.Далее алгоритм переходит к фазе формирования устойчивых k-элементных множеств, которая в свою очередь делится еще на два этапа: подсчет поддержки для кандидатов и генерация устойчивых k-элементных множеств. На первом этапе, определяются уровни поддержки для сгенерированных кандидатов, а именно определяется количество последовательностей НТП поддерживающих каждое темпоральное отношение между составными частями в каждом кандидате. Далее сравниваются конечные значения времени для всех элементов Lk-1 и L1, после чего определяются темпоральные отношения между составными и элементарными частями k-элементного множества, которое определяется как устойчивое, в случае, если уровень его поддержки превышает пороговое значение.
Для повышения эффективности и скорости вычислений в предлагаемом методе анализ БД НТП осуществляется с применением хеширования. В частности, для хранения списка элементов
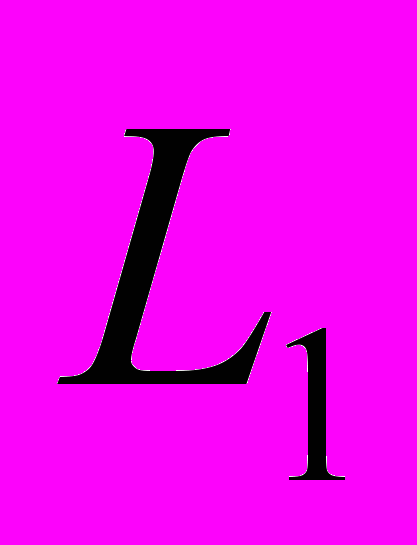 для каждого типа НТП и списка элементов
для каждого типа НТП и списка элементов 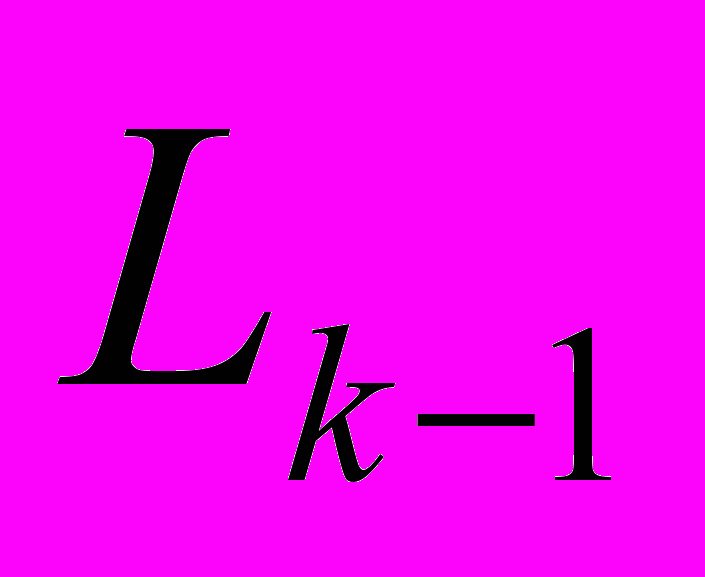 для (k-1)-элементных множеств формируются деревья хеширования.
для (k-1)-элементных множеств формируются деревья хеширования. Для L1 в качестве «ключа» хеширования используется значение типа НТП, а для составной части Lk-1 − значения типов всех НТП входящих в ее состав и всех темпоральных отношений между ними, путем простой конкотенации. В листовые узлы дерева хеширования заносятся устойчивые k-элементные множества I и отображения НТС в I. Отображения сохраняются в форме списка элементов с идентификатором радарограммы и начальным и конечным временем. В качестве «ключей» для поиска очередного кандидата Ск используется его составная и элементарная части, после чего из дерева хеширования извлекаются соответствующие элементы
и . Рассмотрим НТС Р для устойчивого (k-1)-элементного множества и НТС Р* для одноэлементного множества. Извлекая из дерева хеширования начальные и конечные точки отображений Р и Р*, можно идентифицировать все темпоральные отношение между ними. Причем при очередной идентификации счетчику поддержки текущего кандидата Ск инкрементируется 1. Значения этого счетчика присутствует в каждом узле дерева хеширования в качестве дополнительной информации и не превышают размер используемого подмножества темпоральных отношений Алена (7 отношений).
Вторая подфаза предназначена для формирования устойчивых k-элементных множеств. В таблице (см. табл. 4) приведен неполный список устойчивых двухэлементных множеств. После идентификации всех темпоральных отношений между составными частями Сk, итерационно формируются список Lk на основе Lk-1 и L1 с соответствующими темпоральными отношениями. Результирующий временной интервал k-элементного множества формируется по принципу объединения интервалов (k-1)-элементного множества и одноэлементного множества. Например, как представлено в таблице (см. табл. 4), начальное и конечное время присутствия составного образа «А накладывается на В» −{[5, 12],[8, 15]}.
Предложенный в настоящей статье подход к выявлению НТС является одной из модификаций алгоритма «априори». Основным отличием данного метода от классических алгоритмов поиска часто встречающихся товаров в потребительской корзине, является учет специфических особенностей работы с БД НТП ГДС и темпоральное представление извлекаемых ассоциативных правил [6]. Несмотря на использование в предложенном алгоритме хеширования для выявления НТС из больших БД НТП, вычислительные затраты растут экспоненциально. Одним из возможных вариантов решения указанной проблемы может быть применение эволюционных алгоритмов.
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
- Долгий А.И. Интеллектуальные модели и комплексы программ обработки темпоральной информации в базах данных геодиагностических систем на железнодорожном транспорте // Диссертация. − Ростов-на-Дону: Изд-во РГУПС, 2008.
- Kam P.-S., Fu A.W. Discovering temporal patterns for interval-based events. In Y. Kambayashi, M. K. Mohania, and A. M. Tjoa, editors, Proceedings of the 2nd International Conference on Data Warehousing and Knowledge Discovery (DaWaK'00), pages 317{326. Springer, 2000.
- Agrawal R., Lin K.I., Sawhney H.S., Shim K. Fast similarity search in the presence of noise, scaling, and translation in times-series databases. In U. Dayal, P. M. D. Gray, and S. Nishio, editors, Proceedings of the 21st International Conference on Very Large Data Bases (VLDB'95), pages 490{500. Morgan Kaufmann, 1995.
- Zaki M.J. Fast mining of sequential patterns in very large databases. Technical report 668 of the Department of Computer Science, University of Rochester, Nov 1997.
- R. Agrawal, R. Srikant. Fast Discovery of Association Rules, In Proc. of the 20th International Conference on VLDB, Santiago, Chile, September 1994.
- Долгий И.Д., Долгий А.И., Ковалев С.М., Хатламаджиян А.Е. Интеллектуальные модели выявления нечетких темпоральных признаков в базах данных геодиагностических систем // Труды Международных научно-технических конференций «Интеллектуальные системы» (AIS’08) и «Интеллектуальные САПР» (CAD-2008). – М.: Физматлит, 2008. − Т. 1.
Долгий Александр Игоревич
ФГБОУ ВПО РГУПС.
Е-mail: adolgy@list.ru,
344038, г. Ростов-на-Дону, пл. Народного Ополчения, 2.
Тел.: +7-928-148-90-97.
Кафедра «Автоматика и телемеханика на железнодорожном транспорте»; кандидат технических наук, доцент
Кузменов Денис Анатольевич
ФГБОУВПО РГУПС.
E-mail: kuzmenov@gmail.com
344038, г. Ростов-на-Дону, пл. Народного Ополчения, 2.,
Тел.: +7-951-505-88-17.
Кафедры «Автоматика и телемеханика на железнодорожном транспорте», аспирант
Dolgiy Alexander Igorevich
RSTU.
E-mail: adolgy@list.ru
2, sq. NarodnogoOpolcheniya, Rostov-on-Don, 344038.
Phone: +7-928-148-90-97.
PhD, the Associate Professor of chair «Automatics and telemechanics on railway transportation».
Kuzmenov Denis Anatolievich
RSTU.
E-mail: kuzmenov@gmail.com
2, sq. NarodnogoOpolcheniya, Rostov-on-Don, 344038
Phone: +7-951-505-88-17.
Postgraduate student of chair «Automatics and telemechanics on railway transportation».
1 Работа выполнена при поддержке РФФИ (проект №11-07-00172-а).