
Курсовая работа
| Вид материала | Курсовая |
- Методические рекомендации по выполнению курсовых работ курсовая работа по «Общей психологии», 54.44kb.
- Курсовая работа Социокультурные лакуны в статьях корреспондентов, 270.94kb.
- Курсовая работа, 30.27kb.
- Курсовая работа тема: Развитие международных кредитно-финансовых отношений и их влияние, 204.43kb.
- Курсовая работа+диск + защита, 29.4kb.
- Курсовая работа+диск + защита, 118.7kb.
- Курсовая работа на математическом, 292.45kb.
- Методические указания к выполнению курсовой работы курсовая работа по курсу «Менеджмент», 159.91kb.
- Курсовая работа по предмету "Бухгалтерский учёт" Тема: "Учёт поступления и выбытия, 462.23kb.
- Курсовая работа по управлению судном, 128.72kb.
1 2
УЧРЕЖДЕНИЕ ОБРАЗОВАНИЯ
«Гродненский государственный университет имени Янки Купалы»
Математический факультет
Кафедра информатики и вычислительной техники
КУРСОВАЯ РАБОТА
Защита авторских прав в области программного обеспечения
Студента 4 курса 4 группы
Нестеренко В.В.
Научный руководитель:
Кандидат технических наук,
старший преподаватель кафедры
информатики и вычислительной
техники, Ливак Е.Н.
Гродно 2003
СОДЕРЖАНИЕ
Введение ……………………………………………………………………………….. 3
Цель работы … … … … … … … … … … … … … … … … … … … … … … … .. 4
Глава 1. Методы защиты авторских прав в области программного обеспечения ….5
- Обзор традиционных методов ………………………………………………5
1.1.1 Классификация защиты программного обеспечения ……………………5
1.1.2 Традиционные методы защиты от копирования ………………………...6
1.1.3 Базовые методы программной защиты …………………………………...7
- Технология SILDE идентификации программного обеспечения ………...9
1.2.1 Теоретические основы системы идентификации программ …………….9
1.2.2 Структура автоматизированной системы идентификации программ ...10
1.2.3 Построение и внедрение идентификационных меток первого типа ….11
1.2.4 Построение и внедрение идентификационных меток второго типа ….12
1.2.5 Построение и внедрение идентификационных меток третьего типа….13
1.2.6 Построение и внедрение идентификационных меток
четвертого типа…………………………………………………………..14
Глава 2. Стеганографические методы внедрения идентификаторов в файлы РЕ …16
2.1 Стеганографические методы для внедрения идентификаторов …………16
2.1.1 Методы для внедрения идентификационных меток первого типа ……16
2.1.2 Методы для внедрения идентификационных меток второго типа ……17
2.1.3 Методы для внедрения идентификационных меток третьего типа …...18
2.1.4 Методы для внедрения идентификационных меток четвертого типа…19
2.2 Стеганографические методы для внедрения специальных модулей ……20
Глава 3. Программная реализация ……………………………………………………22
3.1 Генерация идентификатора ………………………………………………..22
3.2 Программный модуль для встраивания идентификаторов в РЕ-файлы...24
3.3 Программный модуль для аутентификации программных продуктов….26
3.4. Специальный модуль для восстановления меток третьего типа ……….27
Заключение ……………………………………………………………………………..29
Список используемых источников …………………………………………………...30
Приложение. Экраны пользовательского интерфейса ……………………………31
ВВЕДЕНИЕ
Защита программного продукта от несанкционированного воспроизведения, использования и/или модификации направлена прежде всего на защиту авторских прав его создателя. В настоящее время в Республике Беларусь создана достаточная правовая база, позволяющая охранять права авторов компьютерных программ как на национальном, так и на международном уровне. Компьютерные программы Законом Республики Беларусь «Об авторском праве и смежных правах» (далее - Законом) относятся к объектам авторского права. «Компьютерные программы охраняются как литературные произведения, и такая охрана распространяется на все виды программ...» [2].
Для защиты программного обеспечения (ПО) используются, как правило, программные, аппаратные и программно-аппаратные средства. Традиционно они основаны либо на противодействии незаконному копированию программ, либо на противодействии попыткам запуска и/или исполнения незаконных копий продукта, включая кроме того меры противодействия попыткам нарушителя исследовать логику работы программы. Как показывает практика, методы защиты ПО, основанные на таком подходе, в различной степени затрудняют его нелегальное распространение и использование, но не решают проблему.
Альтернативой традиционным подходам к защите авторских прав в области ПО является подход, основанный на сопровождении программного кода (каждой копии программы) скрытой информацией об управлении правами, которая может служить достоверной информацией, подтверждающей авторство на программу [1].
ЦЕЛЬ РАБОТЫ
Целью курсовой работы является реализация автоматизированной системы, предназначенной для идентификации программных продуктов с целью защиты авторских прав разработчиков.
Для достижения поставленной цели необходимо было решить следующие задачи:
1) Произвести анализ методов защиты авторских прав в области ПО.
2) Изучить технологию SILDE идентификации ПО.
3) Разработать и реализовать стеганографические методы для внедрения
идентификаторов в файлы в формате РЕ.
4) Разработать и реализовать стеганографический метод внедрения
специальных модулей в исполняемые файлы.
5) Разработать и реализовать криптографический алгоритм для генерации
идентификатора ПО.
6) Разработать пользовательский интерфейс.
7) Реализовать программный модуль, предназначенный для встраивания
идентификатора в РЕ-файлы.
8) Реализовать программный модуль, предназначенный для аутентификации
программных продуктов.
9) Разработать и реализовать драйвер для работы с ключевым носителем
(гибким магнитным диском).
ГЛАВА 1
МЕТОДЫ ЗАЩИТЫ АВТОРСКИХ ПРАВ В ОБЛАСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
- Обзор традиционных методов
1.1.1. Классификация защиты программного обеспечения
В соответствии с различными подходами к защите прав создателей компьютерных
программ, защиту программного обеспечения можно классифицировать следующим образом:
- защита от собственно незаконного копирования (воспроизведения);
- защита от незаконного использования;
- защита от исследования программ;
- идентификация программных продуктов.
Очевидно, что комплексный подход к защите программного продукта с использованием одновременно нескольких методов повышает надежность защиты. Именно поэтому чаще всего говорят о технологиях или системах защиты, основанных на том или ином подходе.
Технические средства защиты можно разделить на
- программные,
- аппаратные и
- программно-аппаратные средства.
Программными являются средства защиты, реализованные программным образом. Это
наиболее доступные средства.
Аппаратными называются средства защиты, использующие специальное аппаратное оборудование. Аппаратная защиты является самой надежной, но слишком дорога и рассчитана поэтому в основном на корпоративных заказчиков. В настоящее время многие фирмы и организации во всем мире работают над тем, чтобы сделать аппаратную защиту удобной и дешевой, а также рассчитанной и на массового индивидуального пользователя.
К программно-аппаратным средствам относят средства, комбинирующие программную и аппаратную защиту. Это наиболее оптимальные средства защиты. Они обладают преимуществами как аппаратных, так и программных средств.
1.1.2. Традиционные методы защиты от копирования
В связи с тем, что долгое время программные продукты распространялись посредством гибких магнитных дисков, наиболее развитыми являлись средства защиты программных продуктов, размещенные на гибких магнитных дисках. А методы защиты программных продуктов от копирования часто назывались методами защиты дисков от копирования или, коротко, методами защиты дисков.
Методы защиты гибких магнитных дисков от копирования базируются на следующем. На диск, содержащий защищаемую программу, помещается некоторая скрытая ключевая информация, называемая ключевым признаком или ключом. Иногда ключевой признак называют меткой диска. Диск, содержащий ключевой признак, называют ключевым диском. Очевидно, что отсутствие ключа на диске, на котором присутствует копия программы, свидетельствует о незаконности копии.
Практически для реализации защиты с помощью ключевого диска основной код программы дополняется модулем, задачей которого является проверка диска на наличие ключа или, другими словами, ключевое сравнение. При совпадении ключа с эталоном необходимо передать управление основному коду программы, в противном случае – завершить выполнение программы.
Методика защиты, основанная на использовании ключевых дисков, является традиционной. Прежде всего потому, что ключевой диск мог одновременно использоваться и как лицензионный. Кроме того, при всех своих недостатках этот тип защиты очень дешевый. Сегодня упомянутые методы, хорошо зарекомендовавшие себя при работе под управлением операционной системы DOS, используются все реже и реже. Во-первых, потому что на смену абсолютно незащищенной операционной системе DOS приходят операционные системы, поддерживающие все больше функций безопасности. Сегодня, например, операционная система Windows NT «не разрешает» прямой доступ к диску непривилегированному пользователю, поэтому хранение ключа на неиспользуемой или дополнительно отформатированной дорожке и аналогичные приемы нецелесообразны. Во-вторых, интенсивное развитие сетевых технологий диктует новые способы распространения программного обеспечения. Все чаще авторы распространяют свои продукты не на гибких магнитных дисках или современных компакт-дисках, а посредством передачи через компьютерную сеть. Поэтому традиционные методы защиты дисков становятся все менее актуальными. На смену им приходят другие методы и технологии защиты, многие из которых используют элементы традиционной защиты.
1.1.3. Базовые методы программной защиты
Методы программной защиты, которые будут рассмотрены ниже, предназначены для противодействия попыткам запуска и/или исполнения программы незаконным пользователем. К базовым методам защиты программ от незаконного использования отнесем широко распространенные на практике методы. Это
- парольная защита;
- шифрование;
- а также группа методов, предназначенных для защиты условно-бесплатных программных продуктов.
Парольная защита
Самая распространенная защита программного обеспечения – защита на основе пароля. При реализации парольной защиты запуск приложения сопровождается запросом пароля и последующим сравнением введенного пароля с оригиналом.
Заметим, что парольная защита может быть рекомендована только при защите специализированного программного обеспечения, предназначенного для узкого круга пользователей. При широком использовании программ, защищенных таким образом, очень велика вероятность того, что хотя бы один законный пользователь сообщит пароль злоумышленнику, этого будет достаточно для того, чтобы сделать защищенное приложение общедоступным.
Шифрование
Шифрование – это обратимое преобразование информации с целью сокрытия ее содержания для неавторизованных лиц.
На основе шифрования на практике используются следующие механизмы защиты программ.
Шифрование кода программы. Код программы шифруется с тем, чтобы быть расшифрованным только во время выполнения программы.
Шифрование фрагмента (участка) программы. Для шифрования выбирается критический участок программы.
В обоих случаях может применяться как статическое, так и динамическое шифрование. При статическом шифровании весь код (фрагмент кода) один раз шифруется/дешифруется. В зашифрованном виде код постоянно хранится на внешнем носителе. В расшифрованном виде код присутствует в оперативной памяти. При динамическом шифровании последовательно шифруется/дешифруется процедуры (или отдельные фрагменты) программы или критического участка программы.
Методы защиты условно-бесплатного программного обеспечения
Отметим, что в связи с развитием сетевых технологий программное обеспечение стало все чаще распространяться как условно-бесплатное. Такой способ распространения предполагает временную эксплуатацию пользователем программного продукта. По результатам тестирования продукта пользователь решает, стоит ли его покупать.
На практике разработчики используют следующие принципы защиты:
- регистрационные коды;
- ограничение по времени;
- ограничение на число запусков;
- раздражающие экраны (Nag Screen).
Регистрационные коды.
Наиболее популярной является защиты, в основе которой лежит регистрация пользователя.
Разработчики предоставляют в распоряжение пользователя так называемую незарегистрированную версию – приложение, работающее либо в демонстрационном режиме, либо с ограниченными возможностями. После оплаты пользователь получает пароль и/или регистрационный номер, ввод которого обеспечивает работу приложения в полном объеме (версия приложения теперь называется зарегистрированной).
При реализации такой защиты авторы идут в основном двумя путями. В первом случае введенный пароль или регистрационный номер просто сравниваются с эталоном. Во втором случае (более надежная защита) – на основе пароля и/или регистрационного номера пользователя с помощью специальных механизмов генерируется регистрационный код. Приложение при этом дополняется модулем ввода пароля (регистрационного номера), механизмом генерации кода и сравнением полученного результата с оригинальным кодом.
Ограничение по времени заключается в том, что пользователь имеет возможность бесплатно эксплуатировать программное обеспечение либо в течение определенного времени с момента первого запуска, либо просто ограничен датой (временем) последнего возможного запуска. В этом случае приложение дополняется функциями чтения текущей даты (времени) и сравнения с эталонными.
При ограничении на число запусков имеется некий счетчик, который увеличивается (или уменьшается) при каждом запуске приложения до достижения им некоторого значения (или нуля). После чего приложение либо перестает запускаться, либо работает в демонстрационном режиме.
Идея раздражающих экранов заключается в том, что такого рода сообщения выводятся в виде окон многократно на протяжении всего сеанса работы с приложением. Пользователю для продолжения работы приходится постоянно отключать эти окна, что отвлекает и раздражает его. Рассчитывают авторы на то, что постоянное раздражение пользователя либо заставит его отказаться от работы с приложением, либо заплатить за программный продукт и зарегистрироваться.
Рассмотренные выше методы просты в реализации, поэтому используются достаточно широко. Но с другой стороны, они также являются и хорошо изученными с точки зрения взлома защиты, поэтому могут быть рекомендованы только в сочетании с другими механизмами.
1.2. Технология SILDE идентификации программного обеспечения
1.2.1. Теоретические основы системы идентификации программ
В качестве практического средства идентификации программ ниже предлагается автоматизированная система, предназначенная для создания и внедрения идентификационных меток в защищаемые программные продукты, а также для аутентификации программ. Автоматизированная система базируется на специально разработанной технологии идентификации программ [1], в основе которой лежат классические и оригинальные методы криптографии и компьютерной стеганографии и алгоритмы теории кодирования. Объектом защиты является исполняемый файл программы.
Наряду с основной задачей (сопровождением объекта защиты информацией об управлении правами) технология идентификации решает задачу обеспечения надежности как в целом самой системы идентификации программ, так и, в частности, надежности идентификационных меток, то есть обеспечивает конфиденциальность, целостность и доступность информации об управлении правами.
Проблема стойкости идентификационных меток к попыткам обнаружения и удаления (модификации) нарушителем решается с помощью используемых методов и механизмов создания и внедрения меток.
Отметим некоторые существенные особенности технологии идентификации программ.
- В программный код внедряется некоторое количество идентификационных меток различного типа, количество которых определяется на основе параметров защищаемого объекта и авторской информации.
- Идентификационные метки кодируются с использованием классических и специально разработанных криптографических алгоритмов.
- Для внедрения идентификационных меток применяются как традиционные, так и оригинальные стеганографические методы.
- Используется оригинальный психологический подход к защите идентификационных меток, базирующийся на индивидуальном психологическом барьере злоумышленника и его квалификации.
- Идентификационные метки закодированы таким образом, что в случае их модификации неавторизованными лицами позволяют обнаруживать этот факт, а также (по желанию пользователя системы) способны самовосстанавливаться.
1.2.2. Структура автоматизированной системы идентификации программ
Система идентификации программных продуктов является совокупностью обеспечивающей и функциональной подсистем.
Обеспечивающая подсистема идентифицирует объект защиты. Ее функции:
- создание идентификационных меток на основе авторской информации об управлении правами и других параметров;
- сохранение эталонной информации на отчуждаемый носитель;
- внедрение в защищаемый объект скрытой информации об управлении правами;
- внедрение в защищаемый объект специального модуля, обнаруживающего модификацию (удаление) меток и восстанавливающего их.
Функциональная подсистема производит аутентификацию программ. Она позволяет:
- считывать информацию об управлении правами, сопровождающую защищенный объект;
- устанавливать факт авторства посредством сравнения с предъявляемой эталонной информацией об управлении правами;
На основе определения содержания информации об управлении правами на защищаемый программный продукт строится идентификатор программы, представляющий собой уникальный цифровой код.
Идентификатор программы записывается на специальный отчуждаемый ключевой носитель и хранится у автора. В качестве ключевого носителя в рассматриваемой версии системы используется гибкий магнитный диск. Заметим, что в случае дополнения системы аппаратными средствами, в качестве ключевого носителя может быть использовано любое современное устройство, предназначенное для хранения персональной информации (магнитная карта, электронный ключ, жетон и т.п.).
Блок «АНАЛИЗ» принимает следующие решения:
- об используемых типах идентификационных меток;
- о количестве идентификационных меток, внедряемых в исполняемый файл;
- об используемых стеганографических методах и алгоритмах.
Часть подсистемы, производящая анализ параметров исполняемого файла - одна из наиболее ответственных.
В процессе анализа определяется
- общее количество байт, доступных для внедрения меток;
- смещения и размер отдельных участков файла, доступных для внедрения меток.
Технология идентификации программ предполагает внедрение идентификационных меток нескольких типов.
1.2.3. Построение и внедрение идентификационных меток первого типа
Идентификационные метки первого типа предназначены для обеспечения базовой мощности механизма защиты идентификационных меток. Они представляют собой зашифрованный с помощью одного из криптоалгоритмов идентификатор программы с последующим сжатием. В качестве ключа шифрования используется идентификатор автора.
Для внедрения идентификационных меток первого типа используются стеганографические методы, основанные на наличии неиспользуемых (зарезервированных) полей заголовков файлов в форматах EXE (формат исполняемых файлов DOS) и Portable Executable (формат исполняемых файлов Windows). Исследование форматов исполняемых файлов показало, что общий размер зарезервированных полей является достаточным для внедрения некоторого количества идентификационных меток первого типа.
1.2.4. Построение и внедрение идентификационных меток второго типа
Данный тип меток предназначен для обеспечения средней мощности механизма защиты идентификационных меток.
Пусть идентификатор программы - последовательность десятичных цифр длины d: = (1 2 ... j ...d), где j {0..9}
Каждую десятичную цифру в данной последовательности запишем соответствующей двоичной тетрадой. Получаем последовательность длины 4*d в двоичном алфавите:
= (12 … j ... 4*d), где j {0,1}
Идентификационная метка второго типа строится на основе идентификатора программы с помощью функции Vi (i - номер метки), осуществляющей выбор n символов (где n кратно 3) из последовательности по заданному правилу и, следовательно, первоначально представляет собой последовательность символов длины n в двоичном алфавите:
Vi () = (1 2 ... j ... n) = i , где j {0,1}, n < 4*d. (1)
Затем n-битный блок i последовательно подвергается операциям
- перестановки Pi (i)
- поблочной подстановки S (Pi (i))
- сложению по модулю 2 с определенными операцией Wi битами результата операции подстановки, примененной для двоичной последовательности .
Таким образом, идентификационная метка второго типа с номером i строится с помощью функции Fi , где
Fi () = S (Pi (Vi ())) Wi (S ()).
Для внедрения идентификационных меток второго типа используются стеганографические методы, которые условно можно разделить на две группы.
- Методы, основанные на наличии полей заголовков файлов в форматах EXE и Portable Executable, изменение значений которых не влияет на корректную работу программы.
- Методы и алгоритмы, использующие принципы технологий внедрения файловых вирусов в исполняемые файлы в форматах EXE и PE.
1.2.5. Построение и внедрение идентификационных меток третьего типа
Третий тип меток (самовосстанавливающиеся метки) предназначен для обеспечения высокой мощности механизма защиты идентификационных меток.
Метки данного типа строятся на основе последовательности символов длины n в двоичном алфавите (1) следующим образом.
Последовательность разбивается на 3 части. Представим ее в виде:
= (12 ... k12 ... k12 ... k), где k = n/3.
Обозначим = (12 ... k); = (12 ... k); = (12 ... k).
Каждый из наборов , , в отдельности подвергается дальнейшему кодированию:
; ; .
Рассмотрим алгоритм кодирования на примере набора .
Критическим участком исполнимого файла назовем такую последовательность байт, в которой каждый бит существенно влияет на работоспособность файла, т. е. при изменении хотя бы одного бита в данной последовательности исполнимый файл либо не работает, либо работает некорректно.
По определенному правилу из некоторого критического участка исполнимого файла выбирается последовательность k байт
i = (i1i2 ... ij ... i8), i = [1..k]. (2)
К каждому набору i применяется функция m, которая удаляет символ с заданным номером m (m выбирается на основе идентификатора автора):
i = m(i) = (i1 ... i m-1 i m+1 ... i8), m [1..8]. (3)
К каждому набору i применяется функция Ij, которая для заданного j (j выбирается на основе идентификатора автора) преобразует бит ij по следующему правилу: ij = 0, если ij = i
ij = 1, если ij i где i . (4)
Получаем Ij(i) =i, i = [1..k], j [1..7].
Заметим, что в результате применения функции Ij наборы i и i могут различаться только в символе с номером j. Длина набора i равна 7.
Далее для каждого набора i строится код Хемминга: последовательность i кодируется набором
i = (i1i2i1i3i2i3i4i5i6i7), (5)
где i1, i2, i3, – контрольные биты;
i1, i2, i3, i4, i5, i6, i7 - биты последовательности i.
Так как значения информационных битов последовательности i известны (в силу выбора набора i), то для кодирования набора = (12 ... k) будем использовать последовательность, состоящую только из контрольных бит кода Хемминга, построенного для каждого i;
= (111213... i1i2i3 ... k1k2k3). (6)
Таким образом, каждые три бита последовательности контролирует соответствующий бит идентификационной метки. Заметим при этом, что длина кода составляет 4*k бит.
Идентификационные метки, внедряемые в исполняемый файл программы, строятся на основе наборов , , , , , и могут быть представлены в следующем виде:
M1 = ( ); M2 = ( ); M3 = ( ).
Длина каждой метки составляет 7*k бит.
1.2.6. Построение идентификационных меток четвертого типа
Идентификационные метки четвертого типа внедряются в исполняемый файл по желанию пользователя и предназначены для хранения в программном продукте непосредственно сведений об авторе (обычно имя автора, либо название фирмы-разработчика).
Сведения об авторе, предназначенные для сопровождения программного продукта, назовем идентификатором автора.
Для построения идентификационных меток четвертого типа производится следующая последовательность действий.
Идентификатор автора представляется в виде последовательности символов
(a1 a2... an), (3.10)
где n – длина идентификатора автора в байтах.
Из критического участка исполняемого файла выбирается последовательность байт длины 10*n. Данная последовательность представляется в виде набора n слов длины 10, и символы каждого слова располагаются в виде матрицы B:
B = bij , (3.11)
где i = 1..n, j = 1..10.
Далее, на основе идентификатора программы (3.1), в каждой строке матрицы В значение элемента с номером i заменяется на соответствующее значение символа идентификатора автора - ai, то есть выполняются следующие замены:
b [i, i] = ai = b[i, i], для i = 1.. n (3.12)
Таким образом, получается матрица B = bij .
Элементы матрицы B, не изменяющие своих значений в результате замен (3.12), будем называть информационными байтами.
Далее для каждой строки матрицы В строятся коды Рида-Соломона. Дополнительные (контрольные) элементы, предназначенные для обнаружения и исправления одной ошибки (одного байта), вычисляются в соответствии со следующими формулами:
rdi,1 = 10 bi1 + 9 bi2 + 8 bi3 + ... + bi10
rdi,2 = - 11 bi1 - 10 bi2 - 9 bi3 - ... - 2 bi10 (3.13)
Для обнаружения и модификации ошибочного байта используются следующие вычисления:
Z = bi1 + bi2 + ... + bi10 + rdi,1 + rdi,2
N = bi1 + 2 bi2 + 3 bi3 + ... + 10 bi10 + 11 rdi,1 + 12 rdi,2 (3.14)
Nош = N / Z,
где Z – значение ошибки, Nош – номер ошибочного байта.
Заметим, что Z=0, если байт модифицирован не был. Для получения оригинального значения модифицированного байта необходимо из его значения вычесть значение ошибки Z.
Так как при модификации /удалении идентификатора автора нарушителем в каждой строке матрицы В может измениться только один байт, контрольные значения (3.13) позволят обнаружить и исправить ошибку с помощью вычислений (3.14).
Так как значения информационных байтов матрицы B не изменятся (в силу их выбора) при модификации или удалении нарушителем идентификационной метки четвертого типа, для кодирования ai символа идентификатора автора будем использовать только значения rdi,1 и rdi,2.
Подчеркнем, что для кодирования с возможностью восстановления каждого байта идентификатора автора в соответствии с алгоритмом (3.10) – (3.13), необходимо четыре байта для хранения дополнительных (контрольных) значений (длина каждого равна 2 байтам). Относительно большая избыточность в данном случае оправдана следующими обстоятельствами:
- при внедрении в объект кодирующая информация сжимается;
- формат исполняемого файла позволяет хранить дополнительную информацию такого объема.
ГЛАВА 2
СТЕГАНОГРАФИЧЕСКИЕ МЕТОДЫ ВНЕДРЕНИЯ
ИНФОРМАЦИИ В ИСПОЛНЯЕМЫЕ ФАЙЛЫ «РЕ»
2.1. Стеганографические методы для внедрения идентификаторов
Для внедрения идентификаторов в исполняемые файлы «Portable Executable» были разработаны и реализованы стеганографические методы и алгоритмы.
2.1.1. Методы для внедрения идентификационных меток первого типа
Идентификационные метки первого типа внедряются в исполняемый файл следующим образом.
Первая метка разбивается на части и каждая часть записывается в зарезервированные и неиспользуемые поля заголовка РЕ файла: по 4 байта в поля TimeDate, Pointer to COFF Table, COFF table size, Reserved и LoaderFlags. Эти поля в заголовке не используются, и их изменение не влияет на загрузку программы.
Для записи второй метки первого типа используется свободное место между заголовками MZ и РЕ. В некоторых случаях бывает недостаточно имеющегося свободного места. В таких случаях производится перестройка исполняемого файла. Она осуществляется следующим образом.
Необходимо переместить заголовок РЕ на определенное количество байт от заголовка MZ. При этом возможны два случая:
1) места между заголовком РЕ и первым сегментом в файле достаточно для перемещения заголовка, в этом случае перемещается заголовок, при этом производится модификация в MZ заголовке смещения, и получается место для записи метки;
2) места между РЕ-заголовком и первым сегментом в файле недостаточно: перемещаются все сегменты в файле на расстояние FileAlign из заголовка РЕ, после чего перемещается сам заголовок на необходимое количество байт, изменяется смещение в MZ заголовке, после чего модифицируются поля РЕ заголовка и таблица сегментов (к полю Physical Offset каждого сегмента добавляется FileAlign).
Внедрение меток первого типа проиллюстрировано на рисунке 2.1.
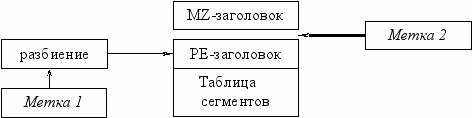
Рис. 2.1 Внедрение меток первого типа.
2.1.2. Методы для внедрения идентификационных меток второго типа
Для внедрения идентификационных меток второго типа используется алгоритм, аналогичный предыдущему.
Первая метка записывается в поля РЕ-заголовка, изменение которых не влияет на корректную работу программы. Четыре байта записываются в поле контрольной суммы (CheckSum), а пятый байт записывается в поле LinkMajor (старший номер версии использовавшегося при создании линкера).
Четыре байта второй метки записываются в поле Base of Data, пятый байт в поле LinkMinor (младший номер версии использовавшегося при создании линкера). Поле Base of Data содержит относительный виртуальный адрес (RVA) сегмента данных, оно установлено верно, но не влияет на загрузку программы и ее корректную работу.
Третья метка также внедряется в заголовок. Четыре байта записываются в поля UserMajor и UserMinor. Эти поля указывают на пользовательский номер версии и не влияют на работу программы. Пятый байт записывается в поле Size of Init Data (размер секции инициализированных данных). Изменение поля не влияет на работу программы.
Внедрение меток второго типа проиллюстрировано на рисунке 2.2.
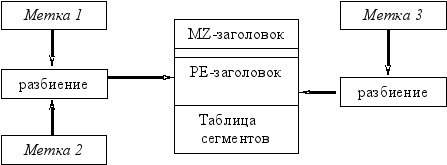
Рис. 2.2 Внедрение меток второго типа.
2.1.3. Методы для внедрения идентификационных меток третьего типа
Для внедрения идентификационных меток третьего типа (самовосстанавливающиеся метки) используются оригинальные методы, в основе которых лежат алгоритмы и механизмы внедрения в исполняемые файлы компьютерных вирусов.
Первая метка записывается в сегмент кода следующим образом.
Для того, чтобы определить место в файле для записи метки выполняются следующие вычисления.
Возможны два случая.
1). Виртуальный размер сегмента кода меньше его физического размера на величину, которая больше размера метки. В этом случае метка записывается по смещению
Physical Offset of code segment + Vitrual Size.
В этом случае модифицируется только виртуальный размер сегмента кода (увеличивается на длину метки).
2). Разность между физическим размером сегмента и его виртуальным размером меньше длины метки. В этом случае производится перестройка исполняемого файла. Все сегменты, следующие за сегментом кода, перемещаются вперед на величину FileAlign из заголовка. В случае, если разность между физическим размером сегмента кода и его виртуальным размером положительна, то метка записывается по смещению
Physical Offset of code segment + Vitrual Size,
иначе по смещению
Physical Offset of code segment + Physical Size.
Производятся корректировки полей таблицы сегментов. Виртуальный размер сегмента кода увеличивается на длину метки, а физический размер на величину FileAlign. Физические смещения всех перемещенных сегментов увеличиваются на величину FileAlign, после чего корректируется поле ImageSize заголовка РЕ.
Вторая метка записывается в предпоследний сегмент аналогичным методом. В случае, если хватает места, просто записывается метка и увеличивается VirtualSize сегмента, иначе перемещается последний сегмент на величину FileAlign и делаются соответствующие корректировки полей.
Третья метка записывается непосредственно в программный код. Делается это следующим образом.
Находится адрес первого вызова API-функции. С этого адреса копируется [длина метки] + 4 байт во вспомогательный программный код, который внедряется в конец сегмента. После чего по найденному адресу вызова API-функции записывается инструкция перехода на вспомогательный код и сразу за ней идентификационная метка.
Вспомогательный код работает следующим образом.
После запуска программы и загрузки ее в память вспомогательный код первым получает управление, после чего восстанавливает прежние данные и передает управление программе.
Внедрение меток третьего типа проиллюстрировано на рисунке 2.3.
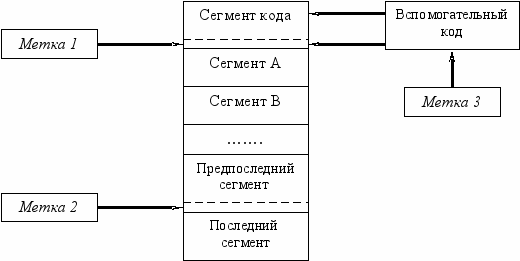
Рис. 2.3 Внедрение меток третьего типа.
2.1.4. Методы для внедрения идентификационных меток четвертого типа
Для внедрения идентификационных меток четвертого типа в файле создается дополнительный сегмент, в который записывается построенная идентификационная метка.
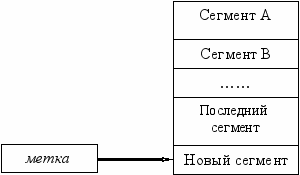
Рис. 2.4 Внедрение метки четвертого типа.
2.2. Стеганографические методы для внедрения специальных модулей
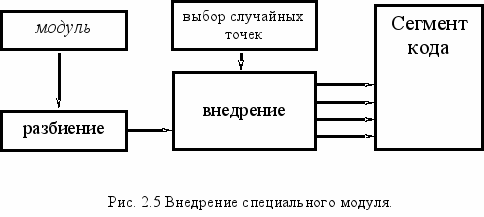
По желанию пользователя в исполняемый файл программы внедряется специальный модуль, предназначенный для восстановления модифицированных и/или удаленных нарушителем меток третьего типа.
Для внедрения модуля были разработан и реализован специальный стеганографический алгоритм, в основе которого лежат механизмы внедрения в программы компьютерных вирусов.
Подавляющее большинство вирусов внедряются в исполняемые файлы РЕ следующим образом. Вирусный код записывается в последний сегмент файла, изменяется адрес точка входа в программу, корректируются поля последнего сегмента и поля заголовка РЕ. Такой способ является наиболее простым с точки зрения реализации. Его даже можно назвать классическим. Однако такой способ внедрения имеет серьезный недостаток: внедренный модуль очень легко обнаруживается. Например, в антивирусных программах при эвристическом анализе такого файла будет выдано предупреждение о том, что файл возможно заражен неизвестным вирусом. К тому же многие нарушители защиты программного обеспечения владеют методами обнаружения модуля, внедренного в последний сегмент программы.
В разработанном стеганографическом алгоритме внедрения модуля не используются «классические» методы, поэтому он является более сложным с точки зрения реализации, но и более эффективным.
Алгоритм основан на разбиении модуля на части и внедрении каждой из них по отдельности в кодовый сегмент программы. Рассмотрим этот процесс более подробно.
В кодовом сегменте программы случайным образом выбираются четыре адресные точки. Модуль разбивается на четыре части, и каждая из них записывается по адресу выбранной точки с перемещением оставшейся части сегмента вперед. Все сегменты, следующие за сегментом кода перемещаются вперед на расстояние, которое вычисляется следующим образом.
Пусть N – размер внедряемого модуля, тогда искомой величиной будет
[N/FileAlign]+FileAlign.
В таблице сегментов увеличивается поле PhysicalOffset каждого сегмента на найденную величину. Поле PhysicalSize сегмента кода увеличивается на величину
[( N-PhysicalSize+VirtualSize)/FileAlign]+FileAlign.
Поле VirtualSize сегмента кода увеличивается на N. Поле ImageSize заголовка РЕ увеличивается на величину
[N/ObjectAlign]+ObjectAlign.
Точка входа в программу не изменяется, изменяются только первые несколько байт в точке входа, вместо которых записывается следующий переход на модуль:
Push address
Jmp dword ptr [esp]
где address – это адрес первой части модуля.
Внедрение специального модуля проиллюстрировано на рисунке 2.5.
ГЛАВА 3
ПРОГРАММНАЯ РЕАЛИЗАЦИЯ
3.1. Генерация идентификатора
Идентификатор программы представляет собой уникальный цифровой код, сгенерированный на основе характеристик, описывающих как создателя программы, так и непосредственно программный продукт.
Идентификатор программы строится на основе следующих составляющих:
1) информация об авторе программного продукта;
2) информация о программном продукте;
3) клавиатурный почерк автора программы.
Построение идентификатора изображено на рисунке 3.1.
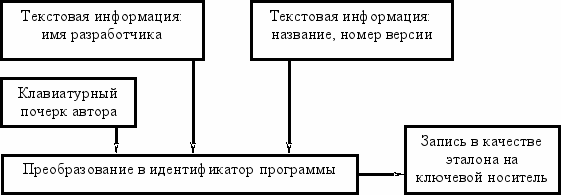
Рис. 3.1 Построение идентификатора программы.
Непосредственно преобразование в идентификатор программы происходит с использованием разработанного в курсовой работе алгоритма криптопреобразования по следующей схеме:
Текстовая информация
криптопреобразование


Клавиатурный почерк
ключ