
Тема «Введение в Data Mining»
| Вид материала | Лекция |
- Рассматриваются вопросы применения методов Data Mining, в частности алгоритмов кластеризации, 30.76kb.
- Удк 681. 3: 519 применение методов data mining для формирования базы знаний экспертной, 78.88kb.
- Методическое пособие применение средств Data Mining при исследовании социальных явлений, 263.8kb.
- О. В. Белова Новосибирск: Научно-учебный центр психологии нгу, 1996 Введение Тема Тема, 1006.61kb.
- О. В. Белова Новосибирск: Научно-учебный центр психологии нгу, 1996 Введение Тема Тема, 1005.33kb.
- Fusion Data Modeler 1 Построение приложений для обработки запросов пользователей выполняется, 34.3kb.
- С. В. Попов Введение в методологию март 1992 года, Мытищи Попов , 622.83kb.
- 1 Group Album Data, 196.62kb.
- Data Storage Institute (Singapore), почетным профессором Университета им. Иоганна Кеплера, 263.38kb.
- Структурно курс состоит из 15 тем: Тема Введение. Предмет, цели и задачи курса Тема, 140.87kb.
Курс «Базы данных» Лекция № 13
| КУРС «Базы данных» *** Тема «Введение в Data Mining» |
| «За последние годы, когда, стремясь к повышению эффективности и прибыльности бизнеса, при создании БД все стали пользоваться средствами обработки цифровой информации, появился и побочный продукт этой активности — горы собранных данных... И вот все больше распространяется идея о том, что эти горы полны золота» |
| |
| |
| |
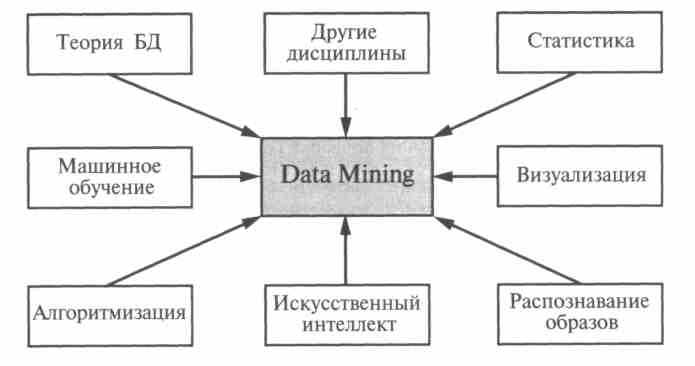 Data Mining — мулыпидисциплинарная область, возникшая и развивающаяся на базе таких наук, как прикладная статистика, распознавание образов, искусственный интеллект, теория баз данных и др., |
| |
| |
| |
| Термин Data Mining получил свое название из двух понятий: поиска ценной информации в большой базе данных (data) и добычи горной руды (mining). Оба процесса требуют или просеивания огромного количества сырого материала, или разумного исследования и поиска искомых ценностей. |
| |
| |
| Термин Data Mining часто переводится как добыча данных, извлечение информации, раскопка данных, интеллектуальный анализ данных, средства поиска закономерностей, извлечение знаний, анализ шаблонов, «извлечение зерен знаний из гор данных», раскопка знаний в базах данных, информационная проходка данных, «промывание» данных. Понятие «обнаружение знаний в базах данных» (knowledge discovery in databases, KDD) можно считать синонимом Data Mining |
| |
| |
| |
| Сегодня появились новые научные методы и специализированные инструменты, сделавшие горную промышленность намного более точной и производительной. Data Mining для данных развилась почти таким же способом. Старые методы, применявшиеся математиками и статистиками, отнимали много времени, чтобы в результате получить конструктивную и полезную информацию. |
| |
| |
| IT-команды увлеклись мифом о том, что средства Data Mining просты в использовании. Предполагается, что достаточно запустить такой инструмент на терабайтной базе данных, и моментально появится полезная информация. На самом деле, успешный Data Mining проект требует понимания сути деятельности, знания данных и инструментов, а также процесса анализа данных. Data Mining не может заменить аналитика. Сложность разработки и эксплуатации приложения Data Mining. Квалификация пользователя. Извлечение полезных сведений невозможно без хорошего понимания сути данных. Сложность подготовки данных. Большой процент ложных, недостоверных или бессмысленных результатов. Высокая стоимость. Наличие достаточного количества репрезентативных данных. |
| |
| |
| Классификация видов данных Реляционные данные — это данные из реляционных баз (таблиц). Многомерные данные — это данные, представленные в кубах OLAP. Метаданные (Metadate) — это данные о данных. В состав метаданных могут входить: каталоги, справочники, реестры. Метаданные содержат сведения о составе данных, содержании, статусе, происхождении, местонахождении, качестве, форматах и формах представления, условиях доступа, приобретения и использования, авторских, имущественных и смежных с ними правах на данные и др. |
| |
| |
| Классификация стадий Data Mining Стадия 1. Выявление закономерностей (свободный поиск). Стадия 2. Использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование). Стадия 3. Анализ исключений - стадия предназначена для выявления и объяснения аномалий, найденных в закономерностях. |
| |
| |
| |
| |
| Классификация технологических методов Data Mining
Методы этой группы: кластерный анализ, метод ближайшего соседа, метод k-ближайшего соседа, рассуждение по аналогии.
Методы этой группы: логические методы; методы визуализации; методы кросс-табуляции; методы, основанные на уравнениях. |
| |
| |
| |
| |
| Статистические методы Data Mining
|
| |
| Кибернетические методы Data Mining
|
| |
| Алгоритм
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Сравнительная характеристика методов Data Mining | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
| Задачи Data Mining Классификация (Classification). Краткое описание. Наиболее простая и распространенная задача Data Mining. В результате решения задачи классификации обнаруживаются признаки, которые характеризуют группы объектов исследуемого набора данных — классы; по этим признакам новый объект можно отнести к тому или иному классу Методы решения. Для решения задачи классификации могут использоваться методы: ближайшего соседа (Nearest Neighbor); k-ближайшего соседа (k-Nearest Neighbor); байесовские сети (Bayesian Networks); индукция деревьев решений; нейронные сети (neural networks). |
| |
| Задачи Data Mining 2. Кластеризация (Clustering). Краткое описание. Кластеризация является логическим продолжением идеи классификации. Это задача более сложная, особенность кластеризации заключается в том, что классы объектов изначально не предопределены. Результатом кластеризации является разбиение объектов на группы. Пример метода решения задачи кластеризации: обучение «без учителя» особого вида нейронных сетей — самоорганизующихся карт Кохонена. |
| |
| |
| Задачи Data Mining 3. Ассоциация (Associations). Краткое описание. В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности между связанными событиями в наборе данных. Отличие ассоциации от двух предыдущих задач Data Mining: поиск закономерностей осуществляется не на основе свойств анализируемого объекта, а между несколькими событиями, которые происходят одновременно. Наиболее известный алгоритм решения задачи поиска ассоциативных правил — алгоритм Apriori. |
| |
| |
| Задачи Data Mining 4. Последовательность (Sequence), или последовательная ассоциация (sequential association). Краткое описание. Последовательность позволяет найти временные закономерности между транзакциями. Задача последовательности подобна ассоциации, но ее целью является установление закономерностей не между одновременно наступающими событиями, а между событиями, связанными во времени (т.е. происходящими с некоторым определенным интервалом во времени). Другими словами, последовательность определяется высокой вероятностью цепочки связанных во времени событий. Фактически, ассоциация является частным случаем последовательности с временным лагом, равным нулю. Эту задачу Data Mining также называют задачей нахождения последовательных шаблонов (sequentialpattern). Правило последовательности: после события X через определенное время произойдет событие Y Пример. После покупки квартиры жильцы в 60% случаев в течение двух недель приобретают холодильник, а в течение двух месяцев в 50% случаев приобретается телевизор. Решение данной задачи широко применяется в маркетинге и менеджменте, например, при управлении циклом работы с клиентом (Customer Lifecycle Management). |
| |
| |
| Задачи Data Mining 5. Прогнозирование (Forecasting). Краткое описание. В результате решения задачи прогнозирования на основе особенностей исторических данных оцениваются пропущенные или же будущие значения целевых численных показателей. Для решения таких задач широко применяются методы математической статистики, нейронные сети и др. 6. Определение отклонений или выбросов (Deviation Detection), анализ от клонений или выбросов. Краткое описание. Цель решения данной задачи — обнаружение и анализ данных, наиболее отличающихся от общего множества данных, выявление так называемых нехарактерных шаблонов. |
| |
| |
| Задачи Data Mining 7. Оценивание (Estimation). Задача оценивания сводится к предсказанию непрерывных значений признака. 8. Анализ связей (Link Analysis) — задача нахождения зависимостей в наборе данных. 9. Визуализация (Visualization, Graph Mining). В результате визуализации создается графический образ анализируемых данных. Для решения задачи визуализации используются графические методы, показывающие наличие закономерностей в данных. Пример методов визуализации — представление данных в 2-D и 3-D измерениях. 10. Подведение итогов (Summarization) — задача, цель которой — описа ние конкретных групп объектов из анализируемого набора данных. |
| |
| |
| От данных к решениям 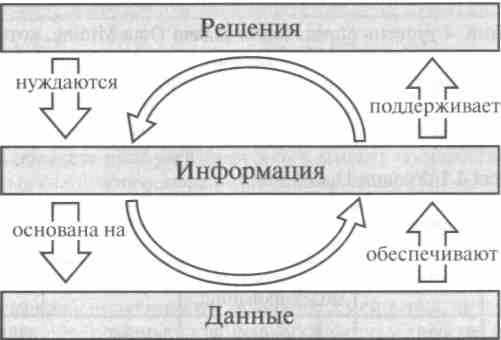 |
| |
| От задачи к приложению
| |||||||||||||||
| Уровни Data Mining |
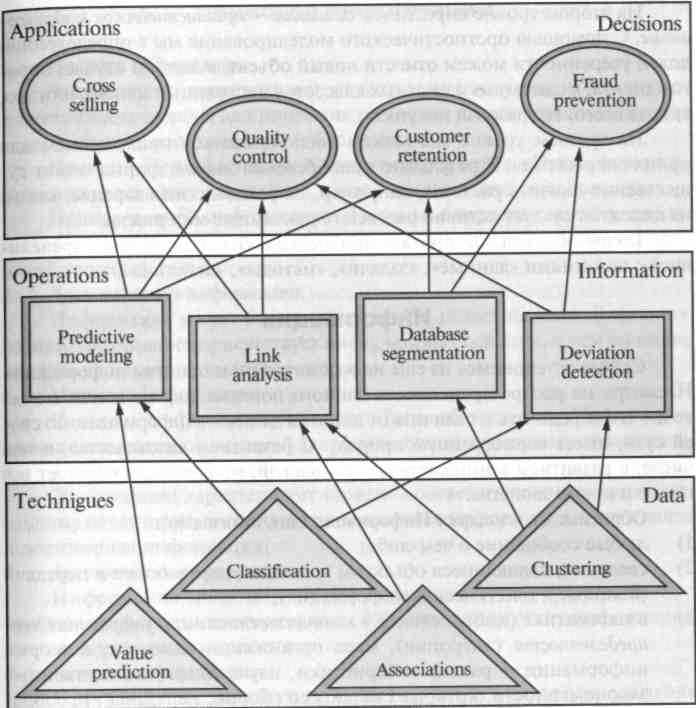 |
| Задачи, действия, приложения |
| |
| |
| |
| |
© НИЯУ МИФИ Кафедра «Информатика и процессы управления», 2010 стр.