4 Типология интеллектуальных систем
| Вид материала | Документы |
СодержаниеУтверждение g выводится из утверждения v и системы аксиом S с помощью фиксированного множества правил вывода R, если существует |
- И. А. Васильев дальневосточный государственный университет, Владивосток использование, 9.29kb.
- Введение Термин «системный», 143.75kb.
- О. Ю. Якубовская 2011 г. Дисциплина: Операционные системы (2 часть из 2) Специальность:, 45.21kb.
- 1. типология правовых систем, 2036.93kb.
- Конспект лекций по дисциплине "Программное обеспечение интеллектуальных систем". Для, 445.63kb.
- Темы курсовых работ История развития семиотики как науки о знаках Типология знаковых, 7.21kb.
- Сводный научный отчет за 2010 г по совместному проекту «Разработка объектно-ориентированных, 204.3kb.
- Ч. 3 Организационно-методическое сопровождение, 78.33kb.
- Ч. 3 Организационно-методическое сопровождение, 99.83kb.
- О. А. Невзорова Татарский государственный гуманитарно-педагогический университет, Казань, 32.16kb.
4.3. Типология интеллектуальных систем
Первой метапроцедурой, использованной в интеллектуальных системах, была метапроцедура "целенаправленный поиск на основе различия-сходства". Такая метапроцедура (сокращенно будем обозначать её ЦПРС) весьма распространена, когда человек ищет решение задачи, ответ которой есть отнесение или не отнесение какого-либо объекта к определенному классу объектов. Например, я хочу отождествить два изображения, показанные на рис.1 а). В моем распоряжении имеется группа преобразований, включающая повороты и перемещения по любым направлениям. Легко сообразить, что этих преобразований вполне достаточно, чтобы совместить между собой оба изображения.
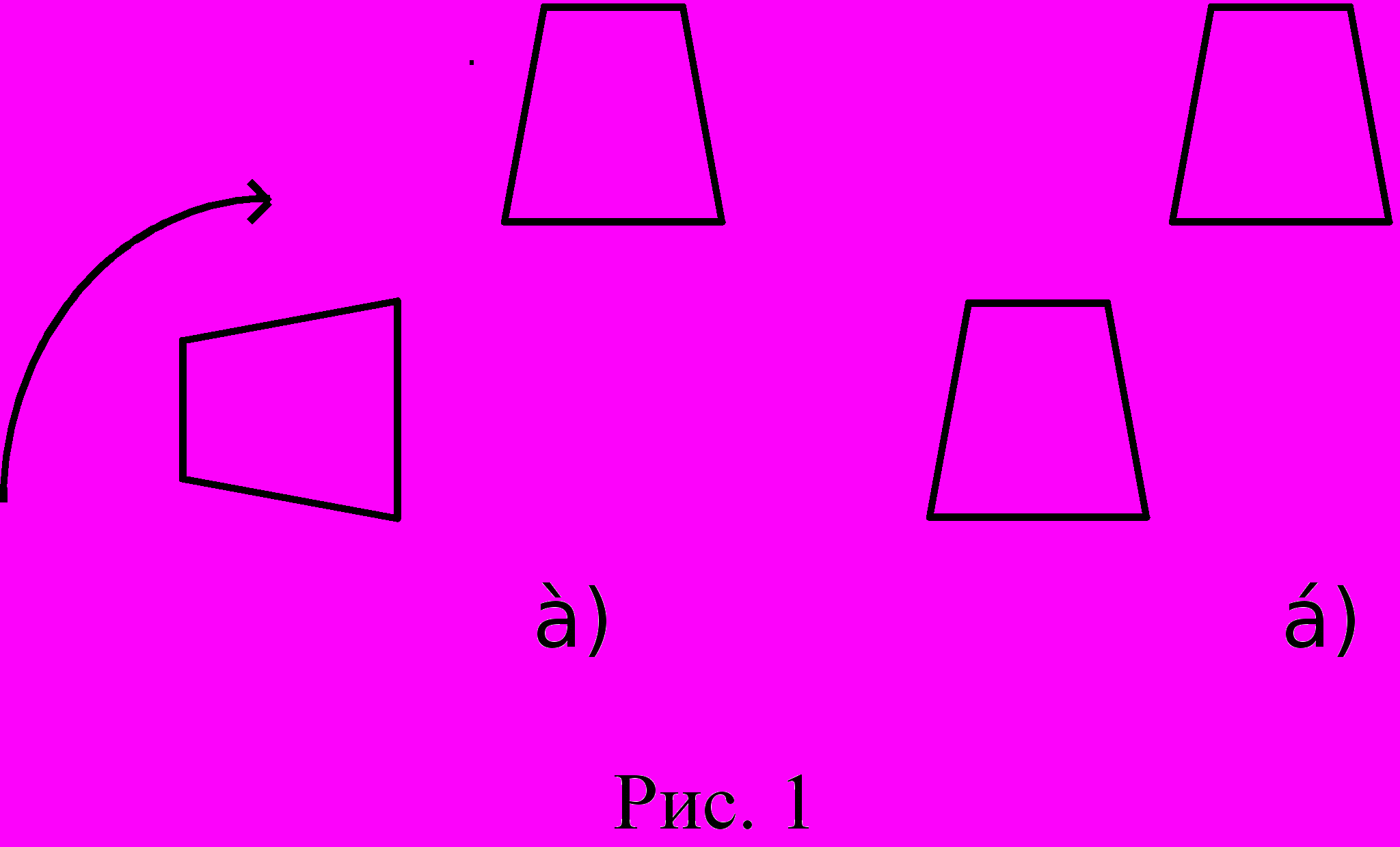
На этом простом примере легко продемонстрировать метапроцедуру ЦПРС. Прежде всего выявляются различие в изображениях. Единственное различие состоит в том, что одно из них повернуто относительно другого. Нахождение этого различия вызывает необходимость применить то преобразование, которое его устраняет, т.е. преобразование поворота. Применив его, мы получим ситуацию, показанную на рис.1 б). Для того, чтобы окончательно убедиться в тождественности изображений надо устранить различие в их местоположении. Оно устраняется имеющейся в моём распоряжении процедурой перемещения по плоскости.
Что показывает рассмотренный пример? Из него ясно видно, что метапроцедура ЦПРС состоит в повторении ряда однотипных шагов:
- выявить имеющиеся различия в объектах;
- выбрать одно из различий;
- найти процедуру, устраняющую это различие;
- если такой процедуры нет, то ответ отрицательный - объекты не одинаковы, конец процедуры;
- если такая процедура есть, то применить её;
- проверить остались ли различия в объектах;
- если различий нет, то ответ положительный - объекты одинаковы, конец процедуры;
- если различия есть, то перейти к началу ЦПРС.
Более интересный случай связан с использованием сходства. Если на множестве объектов каким-то образом задана процедура установления сходства (похожести), то возникает возможность переноса процедур, бывших успешными для устранения различий на одном множестве объектов, на множество объектов, сходных с ранее известными.
Как правило, сходство на объектах задается через сходство их призрачных структур. Посмотрим на рис.2. Легко видеть, что объекты 1, 2 и 5 сходны между собой, а объекты 3 и 4 образуют другой класс сходных объектов.
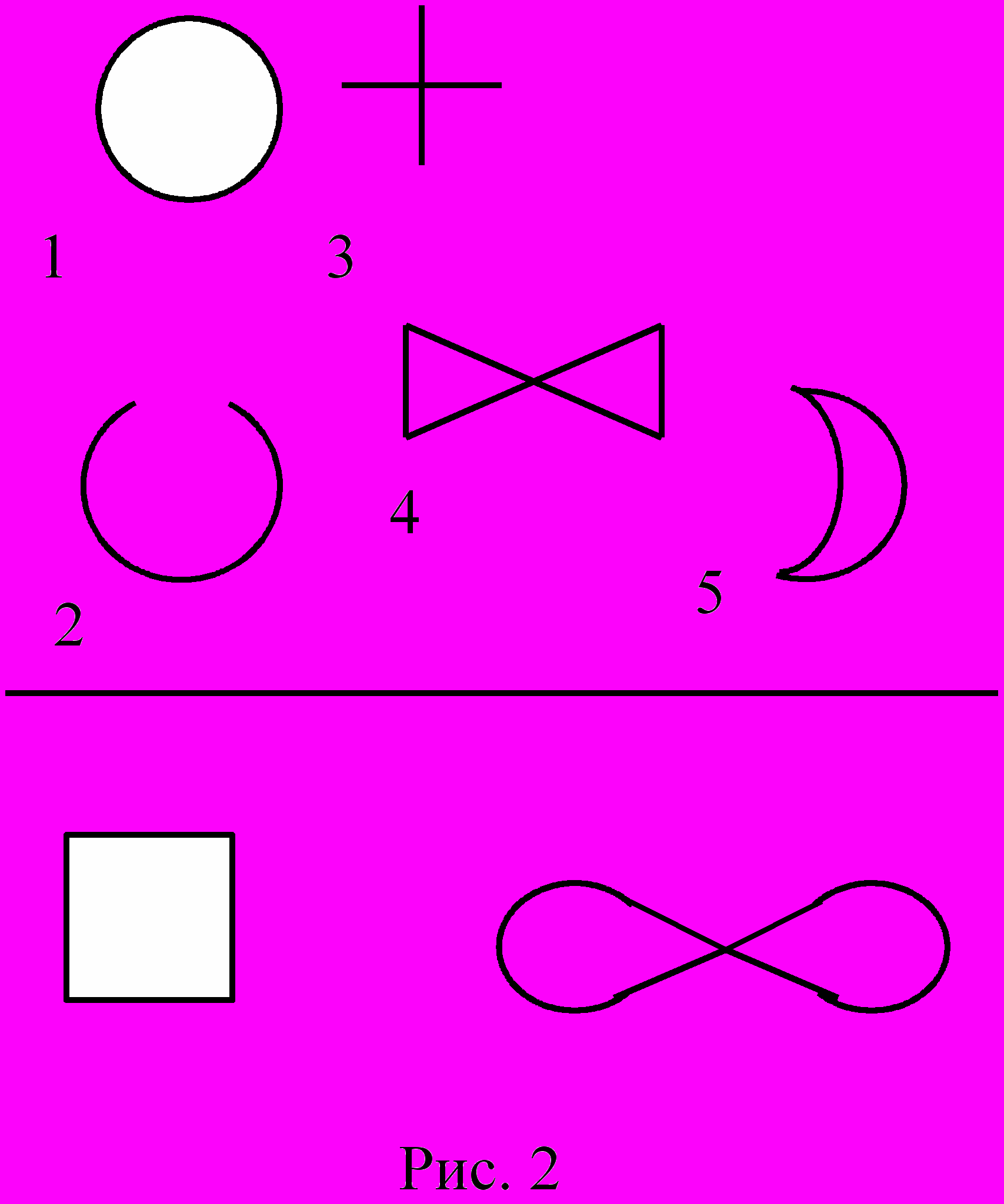
Почему напрашивается такое заключение? Объекты, показанные на рис.2, полностью характеризуются набором трех признаков: замкнутость - разомкнутость, наличие точек пересечения - отсутствие точек пересечения и криволинейность - прямолинейность. Какие-то из этих признаков нам кажутся более важными (так устроено наше зрительное восприятие, аккумулировавшее опыт многих поколений при выработке решений о сходстве-различии). Если теперь к пяти фигурам верхнего ряда добавить две фигуры из нижнего ряда, то могут возникнуть определенные сложности. Квадрат сходен и с объектами первого класса и с объектами второго, а восьмерка в горизонтальном положении весьма похожа на "бантик" и на фигуры из первого класса.
Приведенный пример должен дать почувствовать, что проблема выявления сходства-различия нетривиальна и разрешается не единственным образом. В случае ЦПРС объекты сходны, если их различия с некоторым эталонным объектом устраняются одинаковым (или почти одинаковым) набором процедур. Усложняя ситуацию ещё больше, можно ввести и на множестве процедур своё отношение сходства. Тогда задача станет намного богаче.
Наше весьма подробное рассмотрение ЦПРС позволяет почувствовать отличие метапроцедур от обычных процедур, воплощаемых в программах решения конкретных задач. Метапроцедуры направлены не на конкретные объекты, не на конкретные процедуры выявления сходства или различия объектов. Они применимы к самому широкому классу объектов. В качестве объектов могут выступать не только объекты физического мира или некоторые ментальные сущности, но и факты, события или ситуации. В этом случае в роли призначных структур могут выступать более сложные образования, которые могут обладать своей внутренней структурой.
Метапроцедура ЦПРС была использована в простейшей форме в интеллектуальной системе GPS (General Problem Solving), которая стала первой из систем, относящихся к классу интеллектуальных. Система GPS имела трёх авторов А.Ньюэлла, Г.Самсона и Дж.Шоу. Первый был специалистом по компьютерам, второй психолог, а третий программистом. Это был первый творческий коллектив, продемонстрировавший тот факт, что создание тех систем, которые претендуют на интеллектуальность, есть междисциплинная, а не чисто математическая или программистская задача. Триумф GPS в середине 60-х годов сейчас даже трудно себе представить. И хотя надежды её создателей на то, что с помощью ЦПРС можно создать универсальный решатель задач не оправдались, система GPS вселила уверенность в возможность создания подлинно интеллектуальных систем.
Вторая метапроцедура обучения, близкая к ЦПРС, это обоснованный выбор из множества альтернатив (ОВМА). В различных видах человеческой деятельности часто приходится на некотором шаге выбирать одно из альтернативных продолжений этой деятельности. Например, размышляя о том, как провести выходной летний день, вы можете рассмотреть множество различных альтернативных планов. Среди них может числиться поездка в лес за грибами, купание и отдых на берегу озера, экскурсия в недалеко расположенный старинный монастырь или посещение городского музея. Это множество альтернатив ставит перед вами задачу выбора. Как он осуществляется? Вряд ли можно в теории учесть все нюансы принятия решения. На этот процесс влияют самые различные факторы. Если вы не умеете плавать и скучаете на пляже, то альтернативу, связанную с отдыхом на берегу озера вы отвергнете сразу. А если человек, чья компания для вас в данный момент дороже всего, скажет, что хотел бы полюбоваться картинами в музее, то выбор ваш предрешён. Другими словами, всё зависит от того контекста, в рамках которого совершается выбор.
Понятие "контекста" стало сейчас в работах по искусственному интеллекту использоваться весьма активно. Контекст это то, что предопределяет некоторое решение. Это может быть некоторая информация, относящаяся к делу (состояние погоды, например), эмоциональное состояние в момент выбора, воздействие окружающих людей, выражаемое в их мнениях и действиях (не хотел ввязываться в драку, но заставили).
Во общем случае, можно говорить о двух видах контекста: ограничивающем и дифференцирующем.
Ограничивающий контекст отсекает часть альтернатив (в пределе оставляя лишь одну альтернативу и лишая индивида свободы выбора).
В случае дифференцирующего контекста альтернативы взвешиваются некоторыми предпочтениями или им присваиваются приоритеты.
Использование дифференцирующего контекста, случай наиболее сложный и интересный. Именно он позволяет включить ОВМА в состав метапроцедур обучения в интеллектуальных системах. Но прежде чем говорить об этом, необходимо ввести ещё одну важную для интеллектуальных систем метапроцедуру - метапроцедуру аргументации (А).
Метапроцедура аргументации является основой человеческих рассуждений. Процесс аргументации опирается на аргумент. Аргументы бывают двух типов: аргументы за и аргументы против (или аргументы и контраргументы). Если есть некоторое положение H, которое надо аргументировать, то выбирается множество аргументов, релевантное H.
Термин "релевантное" широко употребляется в психологии, лингвистике и пограничной для этих двух дисциплин науке психолингвистике. Но в разных науках этот термин интерпретируется различным образом. Для специалистов в области искусственного интеллекта наиболее подходит истолкование термина "релевантный", которое принято в лингвистике: "X называется релевантным Y, если X связано с Y и увеличивает наши знания об Y или его значение в некоторой ситуации
Заметим, что интерпретация этого термина не является конструктивной. Как на самом деле узнать, увеличивает ли X знание об Y или его значение в некоторой ситуации? Пока это остаётся тайной за семью печатями. Проблема конструктивного определения термина "релевантность" находится в центре внимания тех специалистов в искусственном интеллекте, кто занимается системами понимания текстов на естественном языке (или его ограниченном подмножестве) или проблемами поиска в базе знаний информации, необходимой для решения конкретной задачи. Успехов в решении этой проблемы пока мало.
Поэтому ограничимся пока констатацией того факта, что можно как-то оценить релевантность аргументов и контраргументов некоторому положению H. Будем предполагать, что аргументы и контраргументы взвешены некоторыми весами важности. Как и в случае ЦПРС, Где вводились приоритеты на процедуры, устраняющие различия, в метапроцедуре А назначение значений весов важности дело субъективное. Одному человеку данный аргумент или контраргумент может показаться весьма важным, а другой даже не примет его во внимание, или посчитает, что он не релевантен H.
Но если такие веса q назначены, то метапроцедура А может быть описана следующей последовательностью шагов:
- выбрать множество M1 аргументов, релевантных H;
- подсчитать qi выбранных аргументов;
iM1
-выбрать множество контраргументов M2, релевантных H;
- подсчитать qi выбранных контраргументов;
iM2
- найти h= qi - qi;
iM1 iM2
- сравнить h с априорно заданным m, если h ³ m, то принять H (считать его подтвержденным), если h < m, то отвергнуть H (считать его неподтвержденным);
- процедура А закончена.
Значение m столь же субъективно, как и значения весов важности. Для каждого человека оно связано не только с текущими обстоятельствами. в которых происходит аргументация принятия или непринятия H, не только с тем, что именно принятие или неприятие данного H означает для человека (легко видеть, что если H - согласие на венчание, то ситуация эта куда более значима для индивида, чем если бы H означало решение о покупке видеоаппаратуры). Но, как и во всех подобных случаях, связанных с миром человека, в системах искусственного интеллекта m, как и h назначаются априорно, а затем корректируются в процессе работы системы.
Обучение (или адаптация) в метапроцедуре А происходит как раз за счёт корректировок значений весов важности и порога принятия решения H.
Вернемся теперь к ОВМА. Очевидно. что ОВМА состоит из следующих шагов:
- сформировать множество альтернатив N1;
- провести процедуру А для каждой альтернативы из N1;
- сформировать множество принятых альтернатив N2;
- если в N2 один элемент, то выбор совершён, ОВМА закончена;
- если в N2 не один элемент, то повторить второй шаг данной процедуры с увеличенным значением m.
Важную роль для интеллектуальных систем играет процедура логического вывода (ЛВ), часто заменяющая процедуру аргументации. Суть процедуры ЛВ поясняет следующее определение:
Утверждение g выводится из утверждения v и системы аксиом S с помощью фиксированного множества правил вывода R, если существует цепочка v, v1, v2, . . . , vn, g, в которой каждый элемент, кроме первого, либо является аксиомой, либо получается из предшествующих ему элементов цепочки путем применения правил вывода из R.
На рис.4 дана иллюстрация этого определения. Роль v играет утверждение: "Имеется фигурка 1". в качестве g фигурирует утверждение: "Надо получить фигурку 2". Множество аксиом S пусто. Множество R состоит из трех правил: выбрать из множества L любой элемент и поставить его на подставку b; поставить элемент x из L на элемент y из L; снять элемент x из L с элемента y из L (x и y - любые (возможно одинаковые) элементы из L).
Серия преобразований, помеченная на рис.4 единицей в кружочке, демонстрирует наикратчайшее решение задачи. Сначала снимается элемент "шляпа", потом ставится элемент "голова" и, наконец, ставится элемент "шляпа". Процедура ЛВ закончена. Но ниоткуда не следует, что система, использующая ЛВ, поступит именно так. Ведь для того, чтобы найти кратчайший вывод надо располагать какой-то априорной информацией о разумном выборе элементов из L и выборе правил из R. Такая информация может появиться, если в системе есть метапроцедура ЦПРС. Сравнивая фигурки 1 и 2 ЦПРС определит различие между ними и на основании своей таблицы найдет последовательность процедур (правил вывода), которые устраняют замеченные различия в фигурках.
Я, конечно, опускаю многие детали и не фиксирую внимание на ряде трудностей, связанных с симбиозом ЛВ и ЦПРС. Например, ЦПРС должна суметь описать различия в фигурках на каком-то разумном языке. В рассматриваемом примере это мог быть язык пространственных отношений. Тогда отличие фигурки 2 от фигурки 1 могло быть сформулировано так: "В фигурке 2 между элементами "шляпа" и "тело" расположен элемент "голова". Но даже после нахождения подобного описания различия всё равно возникает задача превращения его в план применения правил вывода, т.е. возникает известная в искусственном интеллекте задача целенаправленного планирования действий. Для решения задач такого типа используется ещё одна метапроцедура, которая так и называется: целенаправленное планирование действий (ЦПД).
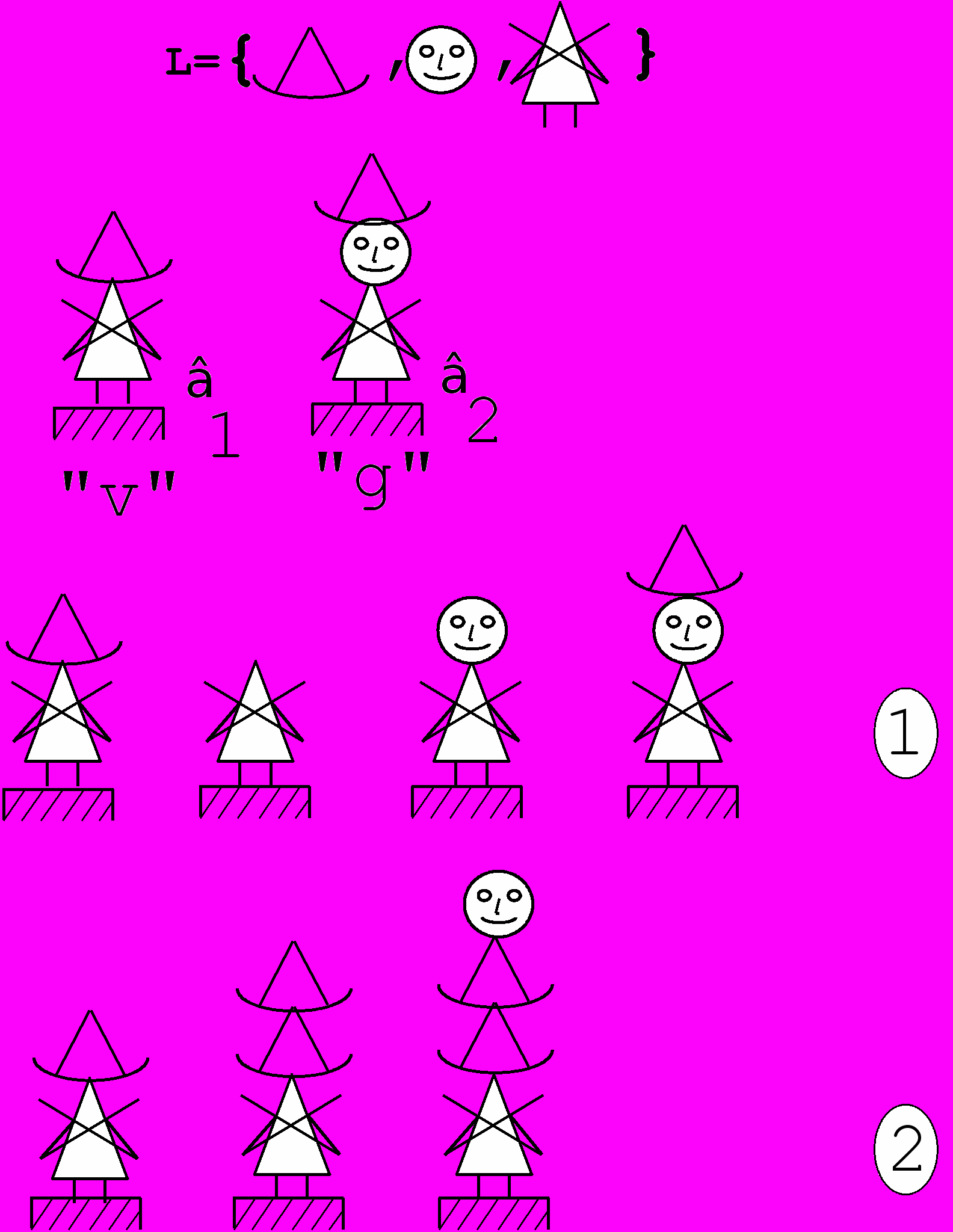
Рис.4
Если же метапроцедуру ЛВ не поддерживать другими метапроцедурами, то результат её деятельности может быть весьма хаотическим и даже бесконечным. И появление последовательностей. подобных последовательности, обозначенной на рис.4 двойкой в кружочке. вполне реально.
Разновидностью ЛВ является правдоподобный логический вывод (ПЛВ).Если в ЛВ результат применения правил вывода из R детерминирован, то в ПЛВ они приводят к тому или иному результату лишь с некоторой долей достоверности. Каждое правило в ПЛВ снабжается собственным весом правдоподобия (или коэффициентами уверенности). Это приводит к тому, что окончательный вывод (результат вывода) также является лишь правдоподобным.
Заметим, что вопреки широко распространённому заблуждению, регноз, т.е. рассмотрение прошлого, также имеет ветвящийся (а не линейный) характер. Линейность (одна определенная цепочка) возникает лишь в предельном случае, когда о течении процесса в прошлом всё до конца известно. Но этом случае нет нужды ни в ЛВ, ни тем более в ПЛВ. Всё известно и так.
Нелинейность прогноза и регноза доставляет в прогнозирующих и диагностирующих процедурах массу неприятностей. С разрешением их имеет дело метапроцедура поиск каузальных зависимостей (ПКЗ).
ПКЗ всегда тесно связана с ПЛВ и часто не отделяется от неё. Но полезно выделить её, ибо она играет весьма важную роль в интеллектуальных системах и может использоваться самостоятельно, без метапроцедуры ПЛВ. Каузальные зависимости могут иметь различный характер. Простейшими из них являются зависимости "причина-следствие" (при прогнозе) и "следствие-причина" (при регнозе). Другим примером каузальной связи может служить связь по логической выводимости (X логически следует из Y). Но есть и много других каузальных связей, которые надо учитывать при работе интеллектуальных систем (сопутствовать, влиять, препятствовать и т.п.).
Сравним между собой метапроцедуры А и ПЛВ. С точки зрения оценки правдоподобия окончательного утверждения они принципиально отличаются друг от друга. В аргументации оценка правдоподобия результата получается путем сложения весов важности (носит аддитивный характер), а для ПЛВ используется мультипликативная оценка правдоподобия результата. Это значит, что для А важны все аргументы и контраргументы, сколь бы мал из вес важности не был. Ибо даже незначительная добавка за или против может перевесить чашу весов по принятию решения в процедуре аргументации. В ПЛВ же элементы с малым значением весов правдоподобия учитывать не надо. Они будут только портить (уменьшать) глобальную оценку правдоподобия. Вывод этот имеет немаловажное значение при работе баз знаний интеллектуальных систем. При использовании А в базе надо стараться хранить все аргументы и контраргументы, которые имеются. В случае же использования ПЛВ хранить в базе знаний утверждения с малыми значениями весов правдоподобия нерационально. Их использование в процедуре ПЛВ приведёт к резкому снижению правдоподобности окончательного результата.
Последняя метапроцедура обучения среди рассматриваемых, но не последняя среди известных сегодня метапроцедур, называется обучение классификации на примерах (ОКП).
Для того, чтобы ОКП работала необходимо иметь множество примеров и контрпримеров объектов, фактов, событий или ситуаций относящихся к некоторому опреде-ленному классу и не относящихся к нему. На рис.5 а)
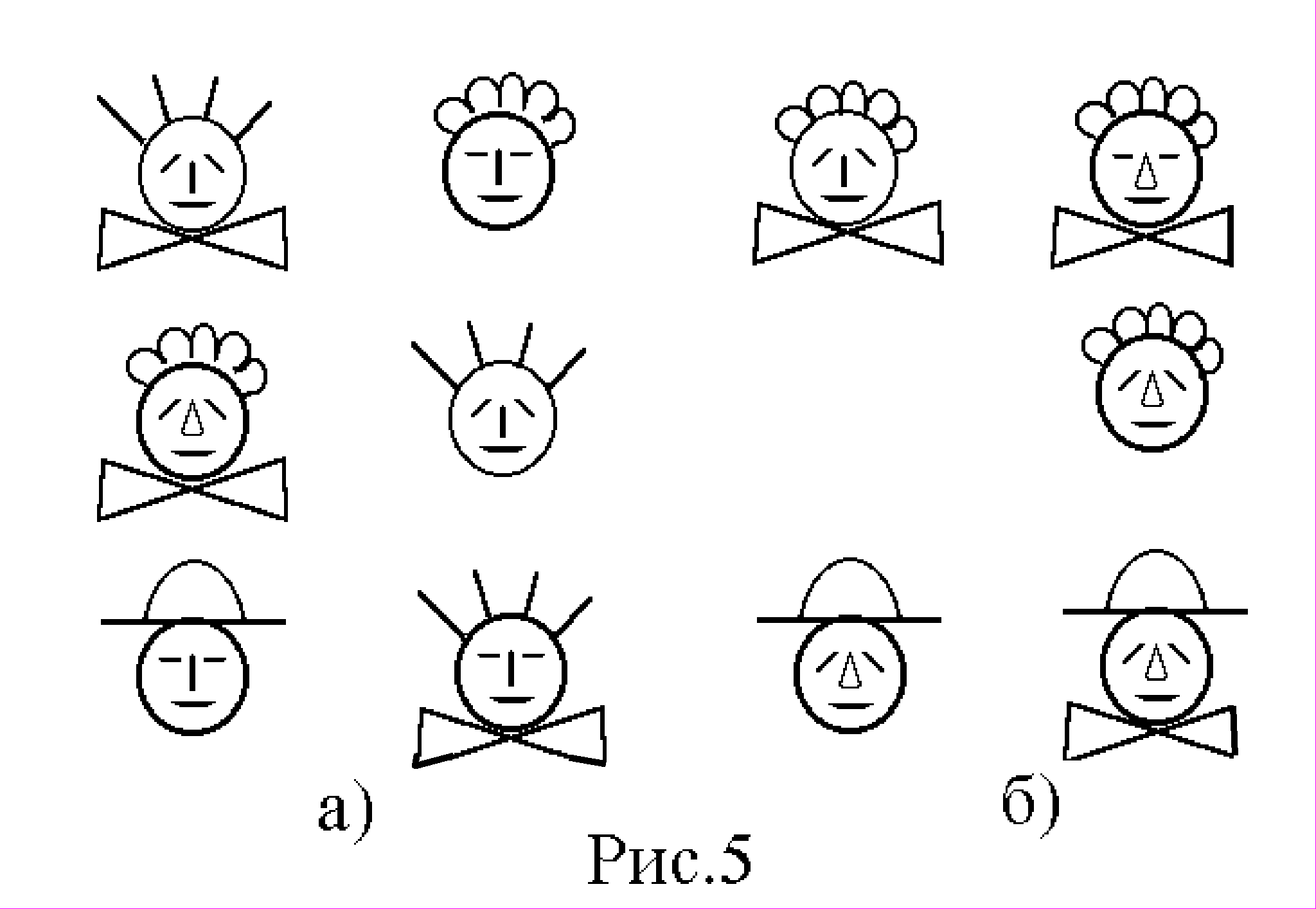 показаны для конкретной задачи, где будет применяться ОКП, две группы изображений. Слева группа примеров, справа - контрпримеров. На рис.5 б) показаны изображения, образующие экзаменационную выборку. В отличие от обучающей выборки, показанной на рис.5 а), экзаменационная выборка используется после завершения работы ОКП. Она служит для проверки качества работы этой метапроцедуры.
показаны для конкретной задачи, где будет применяться ОКП, две группы изображений. Слева группа примеров, справа - контрпримеров. На рис.5 б) показаны изображения, образующие экзаменационную выборку. В отличие от обучающей выборки, показанной на рис.5 а), экзаменационная выборка используется после завершения работы ОКП. Она служит для проверки качества работы этой метапроцедуры.По сути, ОКП является дальнейшим развитием идей выявления сходства/различия, с которыми мы с вами уже сталкивались при обсуждении метапроцедуры ЦПРС. Выполнение ОКП состоит из следующих шагов:
- найти сходство среди примеров, описать это сходство в виде некоторого утверждения;
- проверить, не удовлетворяет ли какой-нибудь представитель из группы контрпримеров сформулированному утверждению;
- если такого представителя из группы контрпримеров нет, то принять построенное утверждение за классифицирующее (решающее) правило; первая часть процедуры ОКП завершена;
- если имеются контрпримеры, удовлетворяющие найденному утверждению, то найти для каждого такого контрпримера его отличие от каждого из примеров, описать это различие в виде некоторого утверждения;
- объединить утверждение о сходстве на группе примеров с утверждением о различиях между примерами и контрпримерами, перейти ко второму шагу ОКП.
После завершения первой части процедуры ОКП начинается её вторая часть, последовательность шагов которой имеет следующий вид:
- для каждого примера из экзаменационной выборки проверить его принадлежность к формируемому классу с помощью классифицирующего правила, полученного в первой части ОКП;
- если все примеры из экзаменационной выборки классифицируются верно (их правильная классификация на примеры и контрпримеры известна априорно до начала работы ОКП), то вторая часть работы ОКП завершена;
- если для некоторых элементов экзаменационной выборки результат классификации неверен, то добавить эти элементы в группы примеров и контрпримеров (в соответствии с априорным знанием о них) и вновь повторить первую часть ОКП.
Экзамен правильности работы ОКП можно повторять неоднократно, если экзаменационная выборка достаточно велика.
Посмотрим, как будет действовать ОКП на конкретном примере, показанном на рис.5. При этом нам придётся пока не формализовать саму процедуру поиска сходства и различия. Будем для простоты считать, что компьютерная система умеет это делать на том же уровне, что и мы.
Постараемся обнаружить сходство в рожицах левого столбца на рис.5 а) (т.е. сходство для группы примеров). В рисунках использованы пять отличительных признаков: характер волос, расположение бровей, форма носа, наличие или отсутствие банта и наличие или отсутствие шляпы. К сожалению, все эти признаки в группе примеров принимают весь спектр возможных значений. Это свидетельствует о том, что одним отличительным признаком тут не обойтись. Чтобы не томить слушателей, укажу искомое утверждение сразу: "рожица принадлежит к группе примеров, если у неё брови наклонены и есть бант или на рожице надета шляпа".
Проверим, не удовлетворяет ли какой-нибудь из контрпримеров этому утверждению. Проверка показывает, что всё в порядке. Сформулированное утверждение можно принять за классифицирующее правило. Перейдём теперь ко второй части ОКП, к экзамену.
Экзаменационные примеры удовлетворяют построенному нами классифицирующему правилу, а вот с контрпримерами дело обстоит хуже. Последняя рожица правого столбца на рис.5 б) согласно классифицирующему правилу должна принадлежать формируемому классу. Её наличие среди контрпримеров экзаменационной выборки говорит о необходимости коррекции классифицирующего правила.
В рожице, вызвавшей конфликтную ситуацию, одновременно присутствуют два условия, присутствующих в классифицирующем правиле. Здесь присутствует и шляпа, и наклоненные брови, и бант. Значит надо внести в классифицирующее правило запрет на это. Тогда утверждение, определяющее классифицирующее правило будет звучать следующим образом: "Рожица принадлежит к искомому классу, если у неё либо наклонены брови и есть бант, либо имеется шляпа, но не одновременно и то и другое".
Такое классифицирующее правило работает безотказно и на обучающей, и на экзаменационной выборках. А что оно будет делать на иных объектах-рожицах сказать заранее нельзя. Но если обучающая и экзаменационная выборки были достаточно представительны на множестве возможных рожиц, то есть надежда на разумность сформулированного классифицирующего правила.
Восемь метапроцедур, только что введённых нами, позволяют дать достаточно содержательную классификацию видов интеллектуальных систем. Она сведена в следующую таблицу.

Приведенные в таблице девять видов интеллектуальных систем лишь самые основные виды таких систем. Всё время появляются новые типы систем искусственного интеллекта, что свидетельствует о перспективности данного направления. Например, сейчас активно формируется класс интеллектуальных систем, предназначенных для повышения уровня управления технологическими процессами на производстве. Повышается интеллектуальный уровень систем делопроизводства и т.д. Искусственный интеллект расширяет свою экспансию на всё новые области деятельности людей.
Рассмотрим введенные нами типы интеллектуальных систем.
Класс систем ИИС - это класс давно известных информационно-поисковых систем (ИПС), внедрявшихся в различных отраслях и областях знаний с самого начала появления вычислительных машин. Интеллектуализация таких систем потребовалась, когда поиск по запросам стал производиться не на основе универсальных классификаций хранимых документов (примером такой универсальной классификации служит используемая до сих пор УДК - универсальная десятичная классификация, с помощью которой кодируются книги, сборники, статьи и другая печатная продукция), а на основе анализа документов и выдачи документов релевантных запросу.
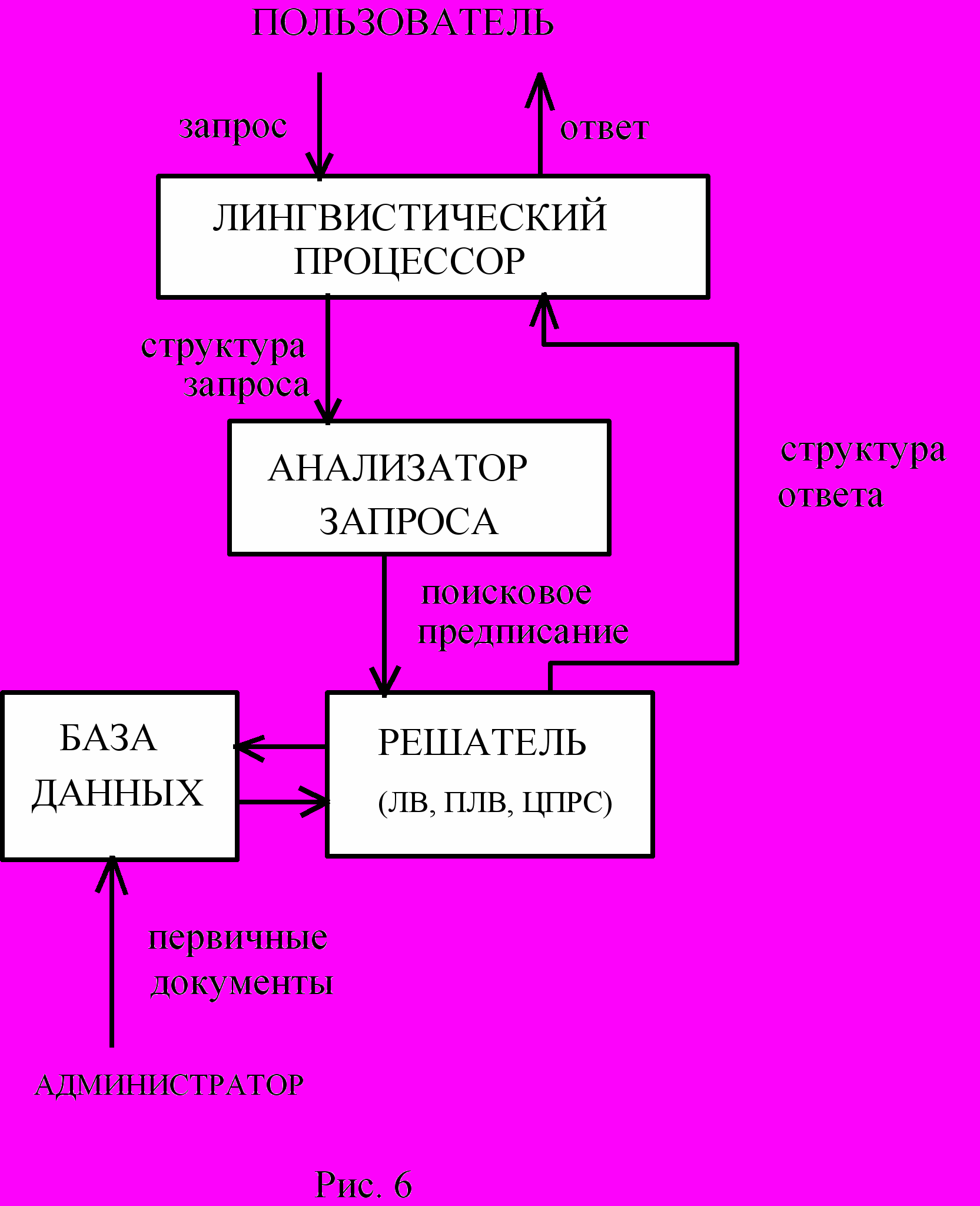
Мы уже говорили о релевантности знаний некоторому тексту. Отмечали, что проблема поиска релевантных знаний ещё далека от своего разрешения. Поэтому в ИИС эта проблема решается лишь частично. Для этого используются метапроцедуры ЦПРС или ПЛВ. Метапроцедура ЛВ используется для пополнения содержания запроса или для пополнения содержания документа. Общая структура ИИС показана на рис.6.
Лингвистический процессор преобразует запрос на естественном языке в запись на внутреннем формализованном языке системы. Лингвистический процессор, являющийся частным случаем системы текстовой обработки (СТО), может быть более или менее сложным в зависимости от допускаемой системой сложности запросов. Об особенностях работы этого блока ИИС мы будем говорить позже, когда речь пойдёт о СТО.
На выходе лингвистического процессора кроме самого запроса формируется ещё некоторая дополнительная информация, которая может помочь при поиске нужной информации (например, добавляется информация из тезауруса предметной области, если таким тезаурусом снабжён лингвистический процессор). Анализатор запроса превращает текст запроса на внутреннем языке системы в систему команд на поиск. Решатель, используя поисковое предписание, может прямо обратиться в базу данных. Если в ней обнаружится нужная для ответа информация, то она через решатель выводится пользователю. Если же таким простейшим путём информация не находится, то решатель, использует процедуру ЛВ, расширяя с её помощью поисковое предписание и ту информацию из базы данных, которая сходна с нужной. Во втором случае подключается метапроцедура ЦПРС. Наконец, в наиболее сложных случаях, ИИС может использовать метапроцедуру ПЛВ. В результате её срабатывания пользователю может быть выдан ответ лишь с некоторой степенью правдоподобия соответствующий его запросу.
Интеллектуальные базы данных близки к ИИС. Их основное отличие от ИИС состоит в стандартизации формы представления информации, хранимой в памяти. Блок-схема ИБД, в основном совпадает с рис.6. Отличие состоит в том, что в ИБД нет необходимости в анализаторе запроса. В решателе же вместо ЦПРС используется процедура аргументации.
Системы пополнения и формирования баз знаний постепенно занимают всё большее место в семействе интеллектуальных систем. Это объясняется тем, что для многих задач необходимо иметь формализованное описание предметной области, в которых решается эта задача. Генерация такого описания и есть основная цель СПФБЗ.
Типовая структура СПФБЗ показана на рис.7. Блок общения с экспертами является специфическим, встречающимся только в интеллектуальных системах данного типа. Правда, тоже самое касается и остальных блоков, показанных на рис.7, кроме лингвистического процессора и базы знаний. В блоке общения с экспертами содержатся различные процедуры, реализующие ту или иную стратегию общения с конкретными экспертами, весьма часто в нём хранятся и специальные тестирующие психологические процедуры, с помощью которых оценивается тип эксперта и подбираются наиболее удобные для него процедуры общения.
Происходит это в полуавтоматическом режиме при активном участии инженера по знаниям - ключевой фигуры в СПФБЗ. Инженер по знаниям обладает сведениями о том, как знания представляются в базе знаний и какие именно знания о предметной области нужны для системы. Поэтому, как опытный дирижёр, инженер по знаниям направляет весь сценарий общения и старается добиться от экспертов максимального удовлетворения поставленных целей по формированию базы знаний.
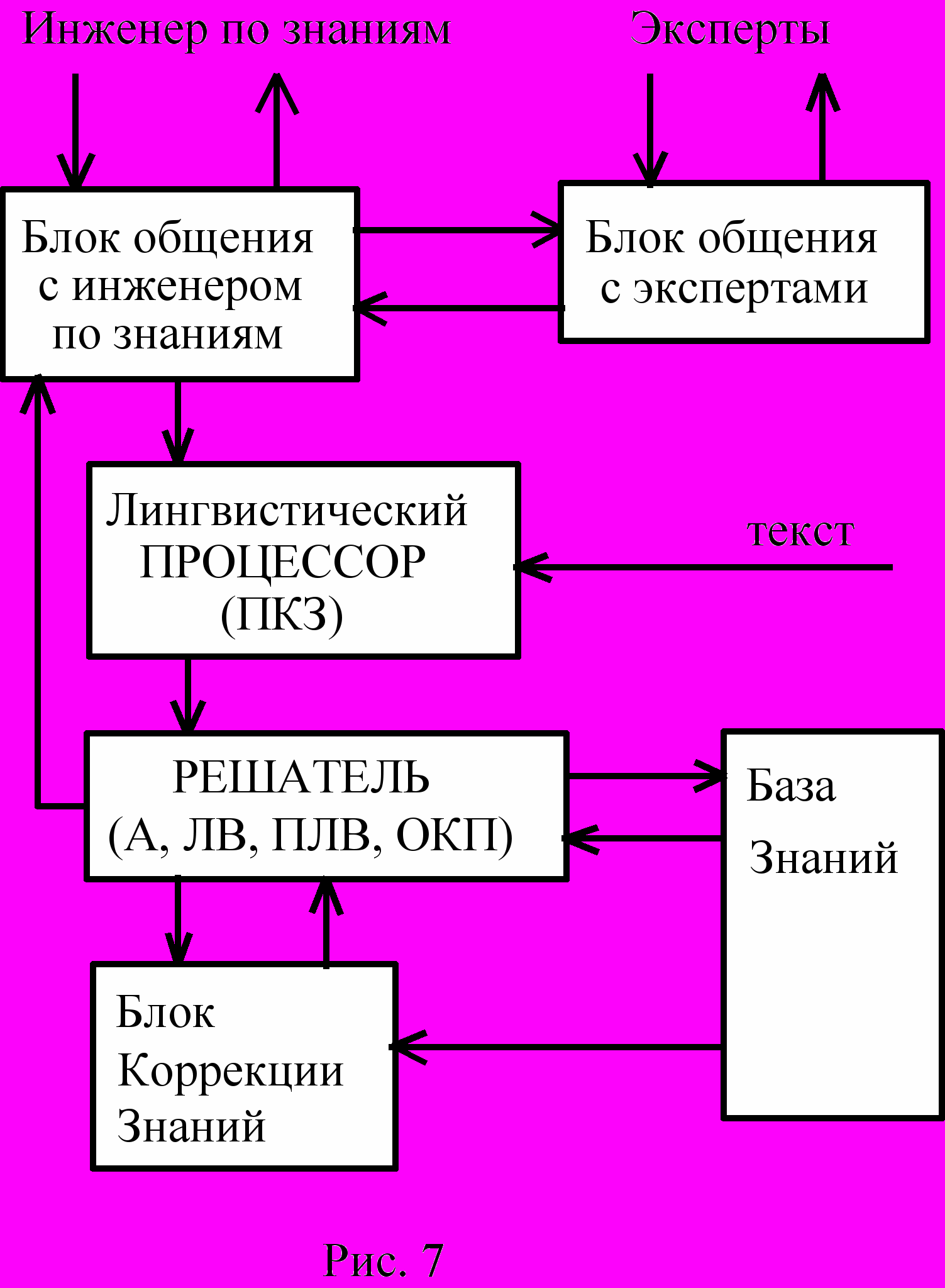
В блоке общения с инженером по знаниям имеется набор процедур, выполняющих управляющую роль по отношению к блоку общения с экспертами.
Лингвистический процессор, с которым мы уже встречались при описании ИИС, преобразует текстовые сообщения на естественном языке, полученные от экспертов или непосредственно из вводимых в систему документов, во внутреннее представление, принятое в СПФБЗ. В лингвистическом процессоре, кроме обычных лингвистических процедур (о них мы вскоре поговорим) реализуется метапроцедура ПКЗ. С её помощью из текстов извлекаются и фиксируются все каузальные связи, играющие важную роль при выполнении метапроцедур А, ЛВ и ПЛВ, реализуемых в решателе.
Решатель кроме указанных метапроцедур реализует ещё метапроцедуру ОКП. С помощью этих процедур решатель пополняет информацию, помещаемую в базу знаний. В этой лекции я не могу говорить о том, как он это делает. Это тема отдельной лекции, в которой логические метапроцедуры должны быть проанализированы со всей необходимой тщательностью.
Кроме пополнения информации, поступающей в базу знаний и хранящуюся в ней, решатель участвует в проверке корректности знаний. Новые знания, записываемые в базу знаний, могут вызвать появление в ней противоречий. Часть противоречий может быть устранена автоматически решателем, в более трудных случаях, когда система этого сделать не может, решатель обращается к инженеру по знаниям, прося его вмешательства в этот процесс.
Под системами текстовой обработки понимается весьма широкий спектр различных систем. Далеко не все они имеют отношение к системам искусственного интеллекта. Разнообразные текстовые редакторы, чеккеры, исправляющие ошибки, системы для постановки произношения в неродном языке и многие другие системы такого уровня я не буду включать в класс СТО. Интеллектуальность систем, входящих в СТО, связана с тем, что эти системы в той или иной мере "понимают" текст на естественном языке, с которым они работают.
Сначала уточним, что мы предполагаем за утверждением, что система "понимает" некоторый текст.
Интеллектуальная система понимает текст, если с позиции носителя языка, на котором написан текст, она правильно отвечает на все вопросы, которые, по мнению этого носителя языка, относятся к тому, о чём говорится в тексте.
В этом рабочем определении феномена "понимания" нет сколько-нибудь объемлющего определения. До сих пор ни в философии, ни в лингвистике, ни в психологии такого определения нет. Но для целей нашей лекции такое частное определение "понимания" оказывается достаточным. Заметим также, что в приведённом определении явно присутствует субъективный момент. Правильность ответов системы должен определять некоторый субъект-эксперт. Но иного пути проверки правильности ответов просто нет.
Дальнейшее изложение будет проводиться на фоне иллюстративного примера, использующего довольно простой текст. Вот этот текст: “Вечером Наташа пошла в кино. Она купила билет на последний сеанс, начинавшийся в девять часов. После кино она сидела с подругой на лавочке во дворе дома до тех пор, пока мама не позвала её домой, сказав, что уже около двенадцати".
Введём понятие уровня понимания. Будем говорить, что система реализует первый уровень понимания, если она в состоянии правильно ответить на любые вопросы, ответы на которые содержатся в явном виде в тексте. Вот примеры таких вопросов: "На какой сеанс купила Наташа билет?", "когда начинался последний сеанс?", "В какое время мама позвала Наташу домой?"
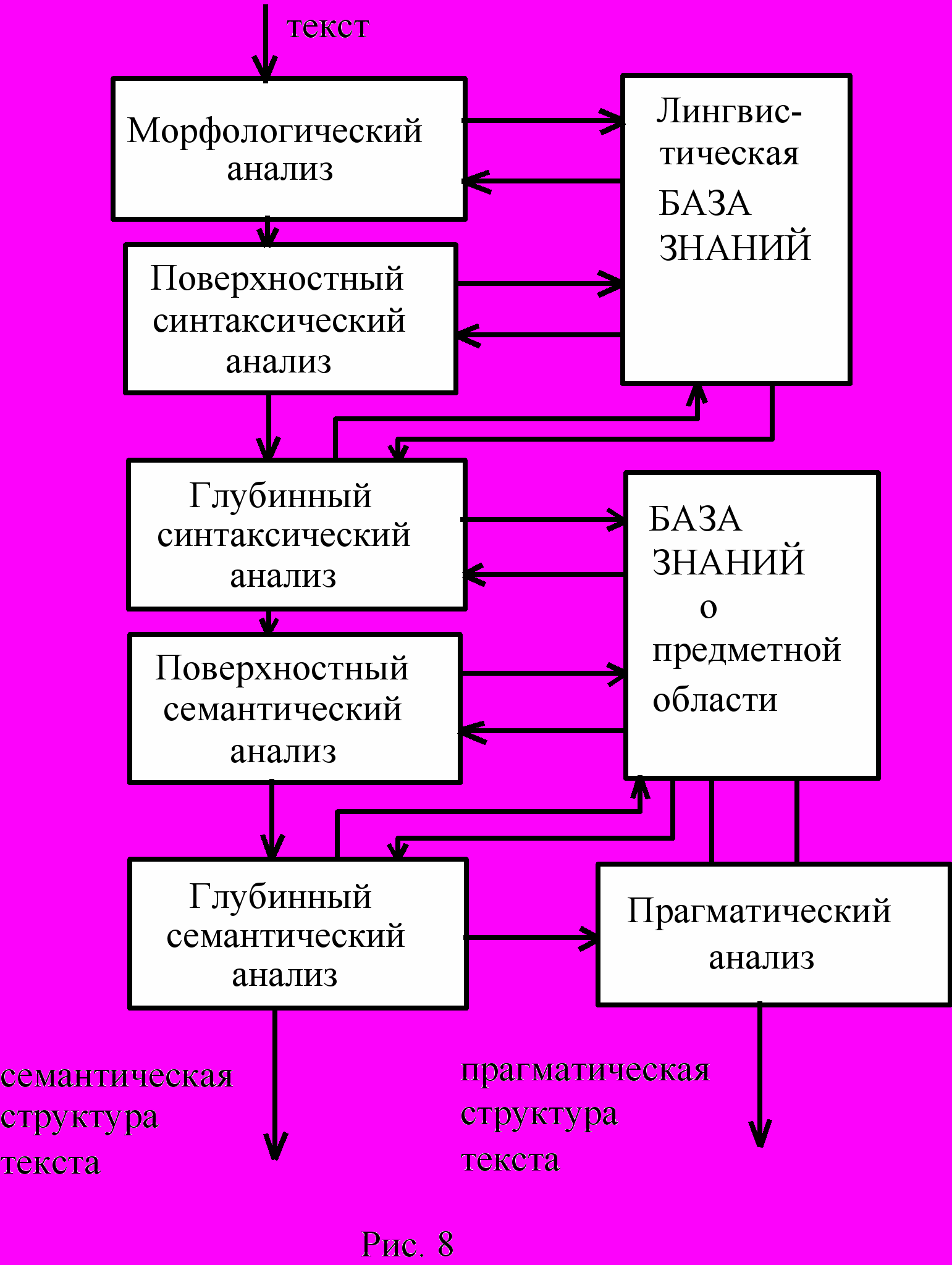
Для ответов на это уровне используется лингвистический процессор со специальной системой переформулирования. На рис.8 показаны основные этапы работы такого процессора. На уровне морфологического анализа для всех слов, входящих в текст, определяется их класс (глагол, существительное, наречие и т.п.) и находятся все грамматические характеристики этих слов (падеж, склонение, время и т.п.). Эта информация поступает на уровень поверхностного синтаксического анализа. На этом уровне происходит построение поверхностной синтаксической структуры фраз, входящих в текст. она напоминает те структуры, которые строятся на уроках русского языка в школе.
Оба эти блока работают с лингвистической базой знаний, в которой хранится вся необходимая информация о морфологии и синтаксисе русского (или иного) языка.
Блок глубинного синтаксического анализа и работающий в тесном контакте с ним блок поверхностного семантического анализа взаимодействуют с двумя базами: лингвистической базой знаний и базой знаний о предметной области. Эти блоки переводят поверхностную синтаксическую структуру предложений во внутреннее представление системы. Для слов, входящих в предложение, они формируют так называемые глубинные падежи или роли.
Рассмотрим две фразы: "Саксофонист исполнил трудную партию" и "трудная партия была исполнена саксофонистом". В первой фразе "саксофонист" стоит в именительном падеже, а "партия" в винительном. Во второй фразе - "партия" в именительном, а "саксофонист" - в творительном. Но это поверхностное синтаксическое различие. Если пренебречь тонким эффектом, связанным с употреблением пассивной конструкции, то обе эти фразы описывают одну и туже ситуацию. А именно описание ситуации, скрытой за текстом, и входит в задачу блоков глубинного синтаксического и поверхностного семантического анализа.
Поэтому вместо поверхностных синтаксических падежей и других характеристик уровня языка они вводят глубинные характеристики. Для обеих рассмотренных нами фраз они припишут "саксофонисту" субъективный падеж, а "партии" - объективный падеж, они восстановят элипсис (умолчание), допущенный в этих фразах ("на саксофоне") и припишут слову "саксофон" инструментальный падеж. После этого обе фразы будут представлены в виде:
(СУБЪЕКТ: саксофонист); (ОРУДИЕ ДЕЙСТВИЯ: саксофон); (ОБЪЕКТ ДЕЙСТВИЯ: трудная партия); (ДЕЙСТВИЕ: исполнил).
Это одна из наиболее простых форм представления семантической структуры предложения.
Блок глубинного семантического анализа связывает между собой семантические структуры предложений текста в единую семантическую структуру текста. Для этого он использует межфразные связи, присутствующие в тексте или подразумеваемые из его содержания.
После этого наступает очередь прагматического анализа. Его задача выявить из глубинной семантики текста те задачи, которые он ставит или те процедуры, которые он описывает. Добавляя к этой информации знания о предметной области и решаемых в ней задачах, блок прагматического анализа формирует на выходе прагматическую структуру текста, на основе которой будет формироваться задание для системы.
В нашем случае, когда лингвистический процессор используется для формирования ответов, задаваемых по тексту, блок прагматического анализа содержит так называемую систему переформулирования. Она похожа на систему формирования поискового предписания в интеллектуальных информационных системах. По этому предписанию в тексте находятся нужные предложения и с помощью специальных стандартных шаблонов по найденным предложениям формируется ответ.
Заметим, что блок-схема лингвистического процессора, показана на рис.8, является наиболее полной. В конкретных реализациях часть блоков может отсутствовать.
Итак, для понимания на первом уровне в СТО достаточно иметь лингвистический процессор. Но не все вопросы относятся к этому уровню. Например, на вопросы: "Что делала Наташа Раньше: ходила в кино или гуляла с подругой?" или "Кино находится во дворе?" с помощью одного лингвистического процессора ответить нельзя, ибо в тексте нет прямой информации, которую можно было бы для этого использовать. Ответы на такие вопросы, которые относятся ко второму уровню понимания, формируются с помощью решателя, в котором реализованы метапроцедуры ЛВ и ПЛВ. В частности, для нахождения ответа на первый из вопросов необходимо с помощью ЛВ и средств временной логики определить отношение "быть раньше" между событиями посещения кино и прогулкой. А для ответа на второй вопрос с помощью той же процедуры ЛВ надо использовать правила вывода, характерные для пространственной логики. Поэтому в систему понимания, работающую на втором уровне, надо кроме лингвистического процессора включить ещё и решатель.
Однако, на втором уровне нельзя получить ответ, например, на такой вопрос, связанный с третьим уровнем понимания: "Где была Наташа в десять часов вечера?". Ответа на него в тексте нет, а логические средства вывода вряд ли тут в чём-нибудь могут помочь. Наш ответ: "В кино". опирается не на логику рассуждений, а на знание сущности объекта "кино". Мы имеем немало сведений о том, что это такое. Мы знаем, что в кино показывают кинофильмы, знаем, что процесс показа одного кинофильма называется "сеанс". И мы знаем среднюю продолжительность сеанса. Во всяком случае она более часа. А так как сеанс начался (согласно тексту) в девять вечера, то в десять вечера Наташа должна была быть в кино.
Значит на третьем уровне понимания мы обращаемся к нашим знаниям о предметной области, к которой относится текст. И при этом умеем находить в базе знаний сведения, релевантные тексту и вопросу, заданному нам. О проблеме релевантности мы уже упоминали. Ещё раз отметим, что в настоящий момент она не имеет удовлетворительного решения.
Существуют вопросы, требующие для своего ответа и иных средств. Например, ответ на вопрос: "Пошла ли Наташа домой, когда мама позвала её?", относящийся к четвёртому уровню понимания, требует определённой информации о характере конкретной Наташи и о её взаимоотношениях с матерью. Если такой информации нет, то ответ может быть весьма неопределённым, например: "Скорее всего пошла".
Формирование таких ответов требует метапроцедуры ПЛВ. Вопросы более высокого уровня понимания я рассматривать не буду (например, вопросы, связанные с ситуацией, к которой "привязан" текст и которая в самом тексте не присутствует, или связанные с метафорическим или аллегорическим истолкованием текста). В современных интеллектуальных системах, как правило, ограничиваются первыми четырьмя уровнями понимания.
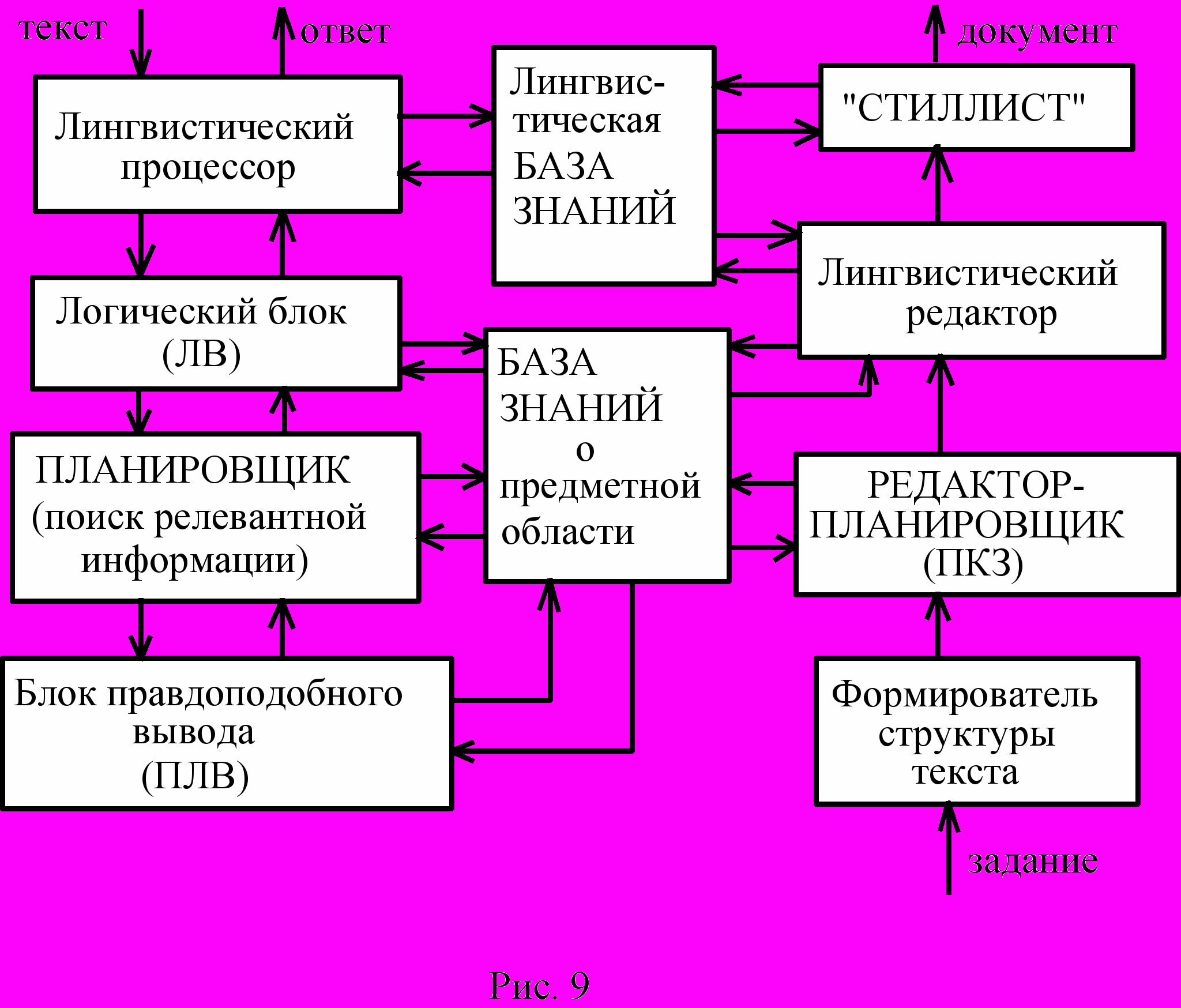
В левой части рис.9 показана СТО, предназначенная для понимания текстов, до четвёртого уровня включительно. Решатель, который до сих пор изображался в виде одного прямоугольника, на этом рисунке детализирован.
В правой части этого рисунка показана СТО, предназначенная для синтеза текстов документов. Этапы синтеза в какой-то мере повторяют в обратном порядке этапы работы СТО для понимания текстов. По заданию на синтез с помощью специальных сценариев порождается общая структура документов. Делает это специальный блок. Затем эта структура заполняется сначала редактором - планировщиком ролями и другими элементами глубинной семантической структуры. Потом, как бы повторяя этап поверхностного синтаксического анализа и морфологического анализа, лингвистический процессор заполняет роли глубинной структуры конкретными элементами. Наконец, "стилист" приводит текст синтезированного документа в приемлемый вид.
Наше рассмотрение напоминает скачку "галопом по Европам", но другого пути у нас нет. Системы СТО заслуживают ряд специальных лекций.
Несколько в стороне от рассмотренных систем находятся системы анализа и синтеза речевых сообщений. Иногда их (в силу значительной специфики) вообще рассматривают вне искусственного интеллекта.
Интеллектуальные системы поддержки принятия решения (ИСППР) в настоящее время развиваются весьма бурно. Это объясняется рядом причин. Основные из них связаны с активным проникновение интеллектуальных систем в экономику, социологию и политику, т.е. в области человеческой деятельности, где принятие решений в сложных ситуациях играет основную роль.
Центральной задачей в системах такого рода является оценка возможных альтернатив и выбор одной из них в качестве принимаемого решения. Структура ИСППР показана на рис.10.
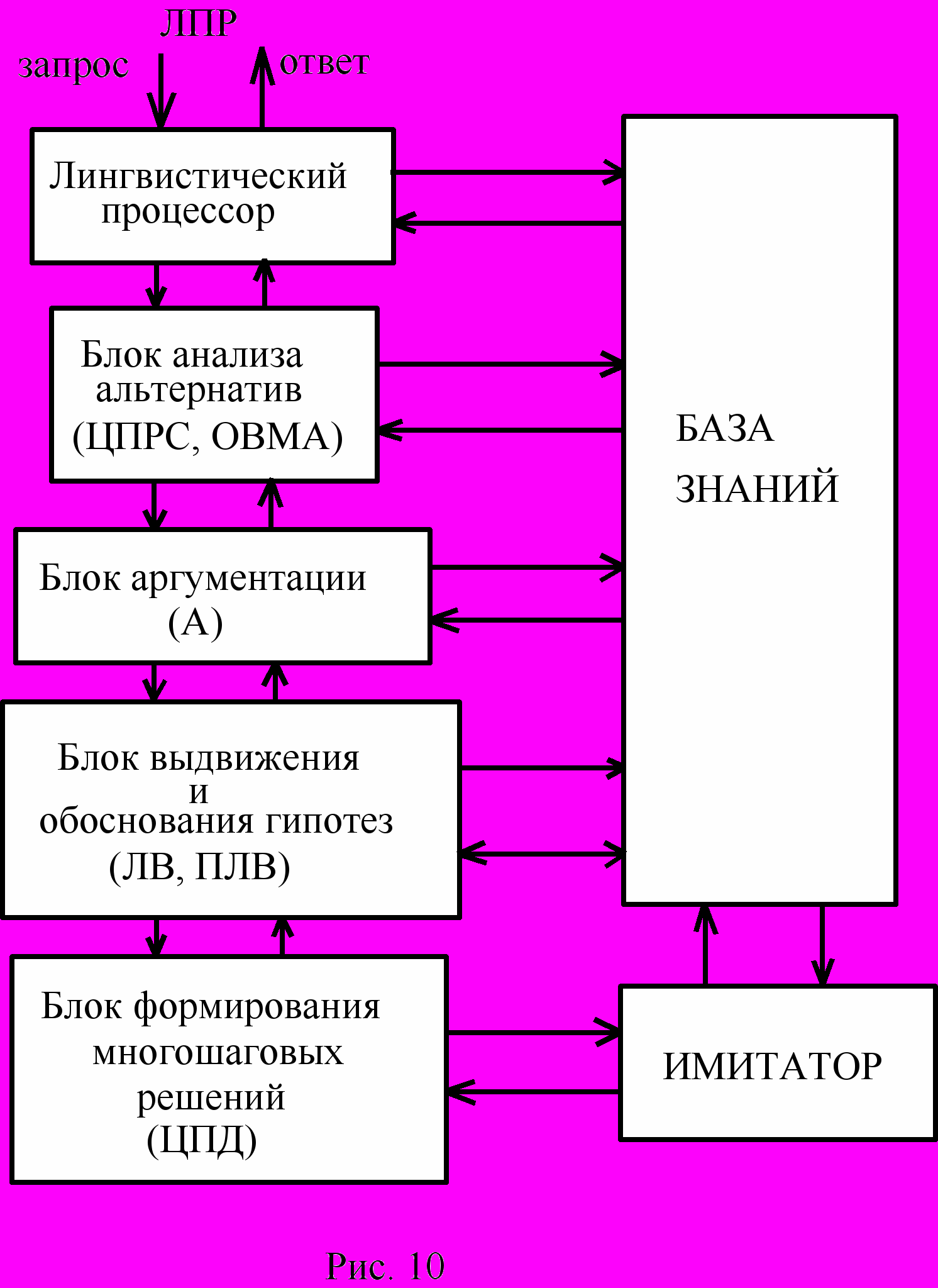
После обработки запроса, поступающего в систему на естественном языке и превращения его во внутреннее представление, начинает работать блок анализа альтернатив. Если ЦПРС или ОВМА приводят к однозначному решению, то оно выдаётся в качестве рекомендации лицу принимающему решение (ЛПР). Если же информации для принятия однозначного решения недостаточно, то начинают работать блок аргументации и блок выдвижения и обоснования гипотез. Блок аргументации ищет в базе знаний дополнительные аргументы и контраргументы для имеющегося множества альтернатив, а блок выдвижения и обоснования гипотез формирует новые альтернативы, которые выводятся с помощью метапроцедур ЛВ и ПЛВ из знаний, имеющихся в базе знаний. На основе сходства-различия вновь выдвинутых альтернатив метапроцедура ЦПРС приписывает этим альтернативам некоторые решения.
Часто ЛПР интересуется не единичным сиюминутным решением, а цепочкой решений. Качество результата при этом, конечно, зависит от всей цепочки принятых решений. Такие цепочки с помощью метапроцедуры ЦПД формирует блок формирования многошаговых решений. Отбор цепочек по критерию качества получаемого решения происходит на основе оценки результатов имитационного моделирования развития текущей ситуации в условиях принятия рекомендуемых системой решений. Для моделирования используется специальный блок "имитатор".
Автоматизированные обучающие системы (АОС) стали создаваться, как только появились компьютеры. Сначала они были примитивными, использовались для контроля успеваемости или базировались на методе программированного обучения. АОС постепенно совершенствовались, заимствовали всё новое, что появлялось в системах, предназначенных для информационного обслуживания, управления, проектирования. Начиная со второй половины 80-х годов в АОС стали проникать элементы искусственного интеллекта. В них появился естественно-языковой интерфейс, база знаний, оставив воспоминания об АОС лишь в истории.
Общая блок-схема ИОС приведена на рис.11. Лингвистический процессор, осуществляющий естественно-языковый интерфейс с учеником и преобразующий входную информацию во внутренне представление системы, нам уже знаком. Мы с ним имели дело неоднократно. Но в ИОС этот блок обладает некоторой особенностью. Она связана с тем, что характер диалога, осуществляемого с обучаемым, зависит от самого обучаемого, вернее от того психологического типа, к которому данный обучаемый относится. Для того, чтобы определить тип обучаемого, ИОС в начале работы с ним с помощью специальных психологических тестов определяет его тип и затем использует это знание в двух целях: для выбора формы диалога, наиболее подходящей для этого типа, и для выбора темпа обучения и характера выдачи заданий. Поэтому блок "модель обучаемого" связан также с решателем.
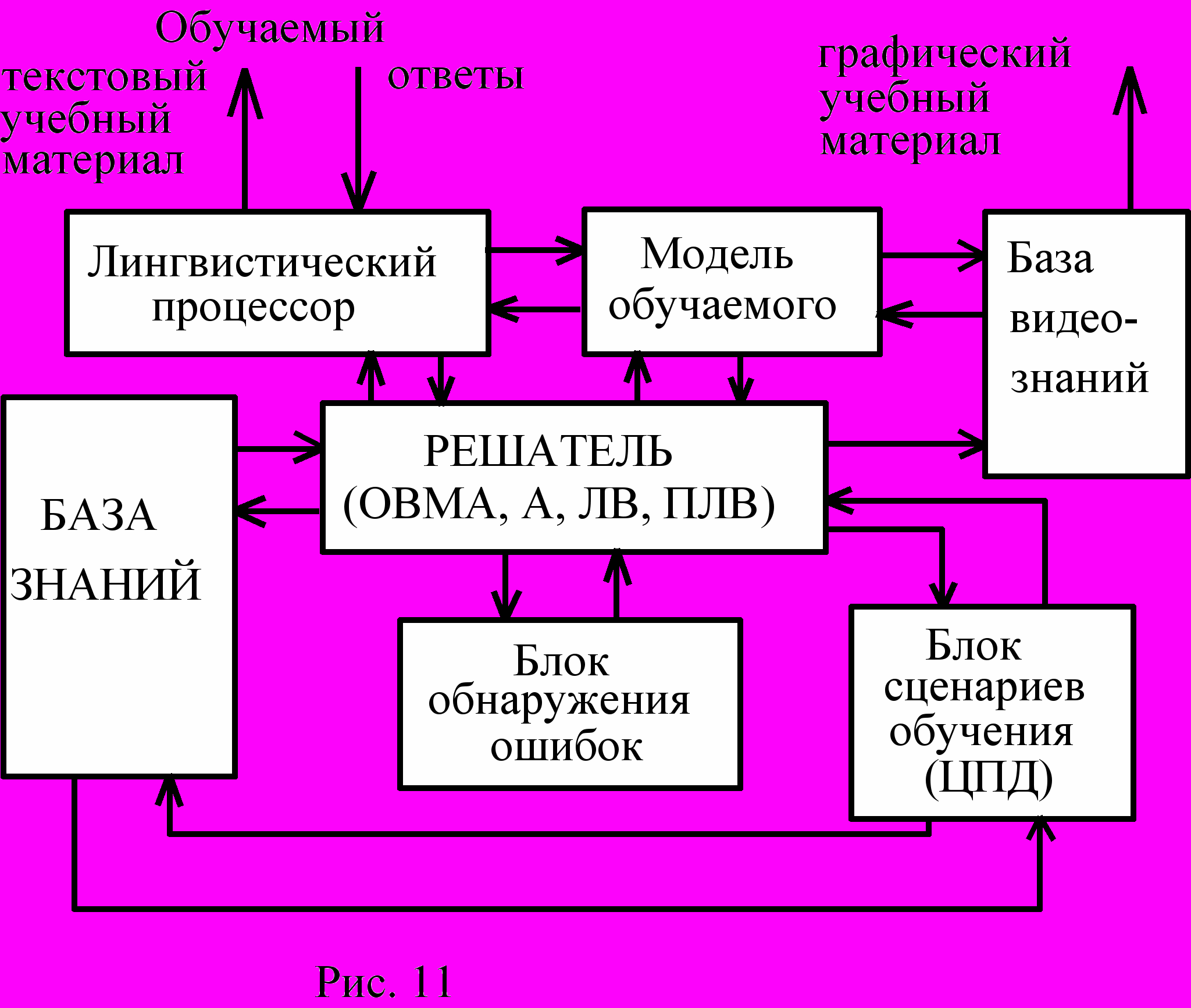
Решатель, как всегда составляет "мозг" интеллектуальной системы. Он выдает очередные порции обучаемого материала, как в виде текста через лингвистический процессор, так и в виде видеосюжетов из специальной базы видеознаний. Если в ИОС использована мультимедиа технология, то обучаемому могут выдаваться и дополнительные акустические сигналы (музыка, речь, шум и т.п.).
Основная и наиболее трудная задача, решаемая в ИОС, это обнаружение ошибок в ответах обучаемого, анализ ошибок и принятие решения о дальнейшем течении процесса обучения. Эту работу осуществляет решатель (с помощью метапроцедур ОВМА, ЛВ, А и ПЛВ) совместно с двумя специальными блоками: блоком обнаружения ошибок и блоком сценариев обучения. К сожалению, не существует типологии ошибок, делаемых людьми в процессе обучения. Люди могут использовать нестандартные, непредусмотренные заранее в ИОС методы решения задач. Обнаружение ошибки может потребовать логического вывода или доказательства. Сам характер ошибки может нести информацию о просчетах в сценарии обучения. Разрешение всех вопросов, связанных с этим - дело ближайших лет развития ИОС.
Экспертные системы - наиболее известный класс интеллектуальных систем. С их появления, собственно говоря, и началось внедрение интеллектуальных систем в различные сферы человеческой деятельности. Пока ЭС наиболее распространенный тип систем искусственного интеллекта. Тем более удивительно, что для этого класса систем нет точного описания, позволяющего отделить ЭС от систем остальных типов.
Скорее всего, в ближайшем будущем этот класс систем распадется на несколько самостоятельных видов интеллектуальных систем. Среди них наверняка будут присутствовать диагностические системы, устанавливающие некоторый факт, а часто и причину появления этого факта; мониторинговые системы, осуществляющие слежение за определенными параметрами или ситуациями, управляющие системы. Но пока ЭС рассматриваются как единый класс интеллектуальных систем.
На рис.12 приведена типовая схема ЭС. Из четырех блоков, показанных на этом рисунке, три нам уже хорощо известны. В конкретных ЭС лингвистический процессор не обязательно выполнен по полной схеме (рис.8), скорее используется лишь некоторая часть его блоков. В решателе также могут использоваться не все процедуры. В простейших ЭС все может ограничиваться лишь метапроцедурой ЦПРС. В более сложных ЭС (как правило, в ЭС диагностического типа) используются метапроцедуры ЛВ и ПЛВ, реже А. В ЭС управляющего типа чаще встречается ОВМА и А, а также ЦПД. В мониторинговых ЭС наиболее часто используются ОВМА и ПКЗ.
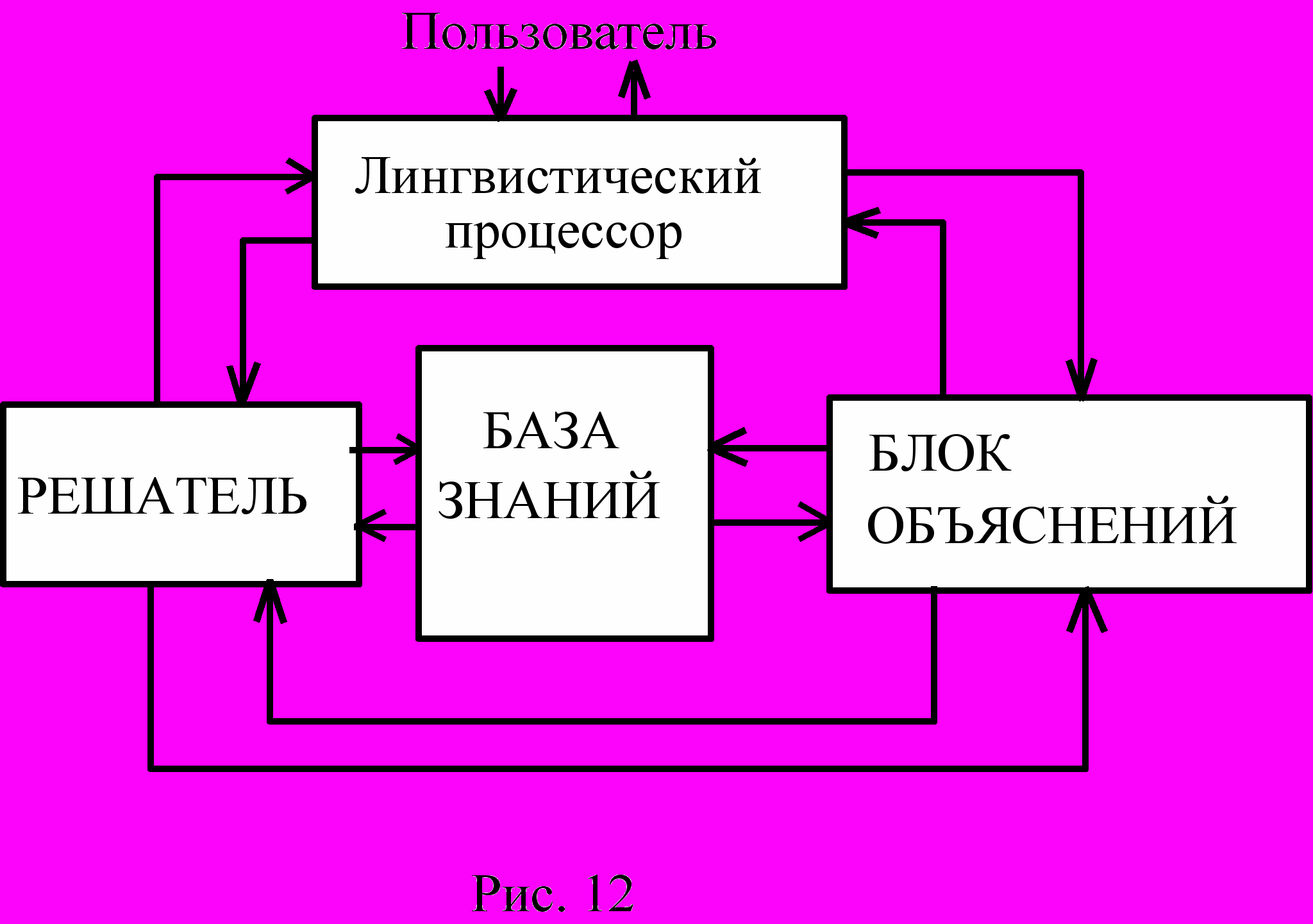
Новым для нас блоком является блок объяснения. Его задача выдать пользователю объяснение и обоснование полученного системой решения. Объяснения могут быть разного типа. КАК-объяснения помогают пользователю понять, каким путем система получила результат. В современных ЭС объяснения такого типа, как правило, заключается в выдаче пользователю трека, отражающего шаги работы решателя. Иногда выдается весь трек, но такое объяснение ненаглядно. Кроме того, в этом случае довольно большой объем рабочей памяти может быть занят запоминаемым системой треком. Чаще выдают лишь узловые участки трека, к которым заранее могут быть заготовлены текстовые объяснения. Всегда выдаются участки трека, на которых система применяла метапроцедуру ОВМА.
ПОЧЕМУ-объяснения возникают тогда, когда пользователь, получив ответ, интересуется: "А почему решением должно быть А, а не В?". В этом случае ЭС должна сравнить свой трек решения с тем треком, который был бы реализован, если бы решением было В. Сравнивая эти два трека (С момента их расхождения) система обосновывает свой выбор трека, ведущего к решению А.
В некоторых ЭС делались попытки использовать другие типы объяснений (например, ЗАЧЕМ-объяснения, говорящие о локальных целях системы или КАКОЙ-объяснения, связанные с оценкой прогноза дальнейшего развития событий). Но такие типы объяснения оказались слишком непростыми в реализации и в большинстве ЭС они отсутствуют.
Сейчас прослеживается явная тенденция отказа от изготовления жестких, ориентированных на узкую предметную область ЭС. Вместо них строятся системы-оболочки, которые представляют собой набор инструментальных средств, с помощью которых можно построить конкретную ЭС. Вся процедура при этом отдаленно напоминает сборку какого-то устройства из элементов детского конструктора. В процессе "сборки" можно выбирать те или иные метапроцедуры для будущего решателя, менять параметры в мета процедурах (веса важности, пороги и т.п.), фиксировать удобную для данных конкретных применений ЭС форму представления знаний в базе знаний.
В дальнейшем наше внимание будет уделено преимущественно экспертным системам.
Блок-схема интеллектуальной системы автоматизированного проектирования показана на рис.13. Системы автоматизации проектирования (САПР) возникли еще до бурного развития интеллектуальных систем. На первом этапе их основными задачами были расчеты, нужные проектировщику и освобождение его от утомительной и чреватой многими ошибками работы по подготовке документации на проектируемые изделия. Такие САПР работали на ЭВМ, не имевших удобного интерфейса персональных компьютеров, что лишало проектировщика возможности работать в прямом взаимодействии с системой проектирования.
Интеллектуализация САПР шла по двум основным направлениям: развивался естественно-языковый интерфейс, поддерживаемый развитыми средствами графического отображения и в САПР включались решатели с богатым набором возможностей. Результатом развития первого направления интеллектуализации САПР стало появление в ее структуре лингвистического процессора, базы видеознаний и блока прямого манипулирования. Второе направление интеллектуализации заставило включить в САПР решатель, блок оценки альтернатив и блок компановки
.

В ИСАПР лингвистический процессор выполняет такие же функции, что и в интеллектуальных системах других типов. Решатель реализует чаще всего метапроцедуры ЦПРС и А. Блок оценки альтернатив отделен от решателя. Сделано это потому, что в САПРах метапроцедура ОВМА опирается не на процедуру аргументации, как в ранее рассматривавшихся системах, а на оценки, получаемые в результате прикидочных или полных расчетов. Например, выбирая конструкцию моста через реку из множества типовых решений (альтернатив), необходимо сделать специальные контрольные расчеты, по результатам которых можно ранжировать предпочтения тех или иных типов мостов.
В САПР часто приходиться компоновать результирующее изделие из ряда типовых или ранее спроектированных частей. Важность этой операции для САПР заставила иметь в их структуре специальный блок компоновки, реализующий мощную по своим возможностям метапроцедуру ЦПД. Иногда вместо компоновки изделия решается задача его разборки. САПР, которые сталкиваются с задачами такого рода, имеют возможность как бы "обращать" метапроцедуру ЦПД и находить с помощью обращенной метапроцедуры допустимые варианты разборки изделия.
Особое внимание в последнее время в САПР уделяется системе визуальной поддержке проектирования. Эта система содержит не только развитые средства машинной графики, в которой наглядно отражаются процессы компоновки и разборки, высвечиваются отдельные детали или проектные документы, но и средства, позволяющие проектировщику непосредственно на экране производить определенные манипуляции. С помощью экранной "руки" ("манипулятора"), управляемой с помощью мышки или клавиатуры, проектировщик может непосредственно на экране строить различные варианты технических решений, визуально оценивать их, производить сборку и разборку, выбирать масштабы и т.п. Такие системы прямого манипулирования создают для проектировщика иллюзию реального процесса проектирования или конструирования.
Системы автоматизации научных исследований (САНИ, часто из-за неблагозвучности сокращения сокращаются как АСНИ) в отличие от САПР развиваются более медленными темпами. Первые АСНИ были системы, предназначенные для обработки экспериментальных результатов, получаемых (при исследовании) в быстро протекающих процессов. В основном, это были процессы, которыми интересовались физики. Вслед за этим появились САНИ для исследователей-химиков. А затем САНИ стали внедряться и в другие экспериментальные исследования (биология, геология, метеорология и многие другие естественно-научные дисциплины) С конца 80-х годов САНИ появились в гуманитарных науках (прежде всего в археологии, а затем в истории, филологии и т.п.). Такое победное шествие САНИ объясняется быстрой эволюцией их в сторону интеллектуальных систем
На рис.14 показана одна из возможных блок-схем ИСАНИ. Большинство блоков, изображенных на этом рисунке уже неоднократно объяснялись при рассмотрении различных типов интеллектуальных систем. Поэтому я остановлюсь лишь на тех из них, которые выполняют в ИСАНИ функции, не встречавшиеся ранее в других системах.
Блок сценариев эксперимента действует в прямом контакте с исследователем и решателем. Сценарий эксперимента обычно носит динамический характер. Конкретная его реализация связана с целями эксперимента и полученными по ходу эксперимента результатами. Если, например, просматривая треки от пролета элементарных частиц через пузырьковую камеру и отождествляя их с эталонными, хранящимися в базе знаний, решатель обнаружит трек новой природы, то он может прервать эксперимент и обратиться к исследователю за консультацией. Изменение сценария может происходить и по инициативе исследователя, сообщающего о желательных изменениях решателю ИСАНИ.
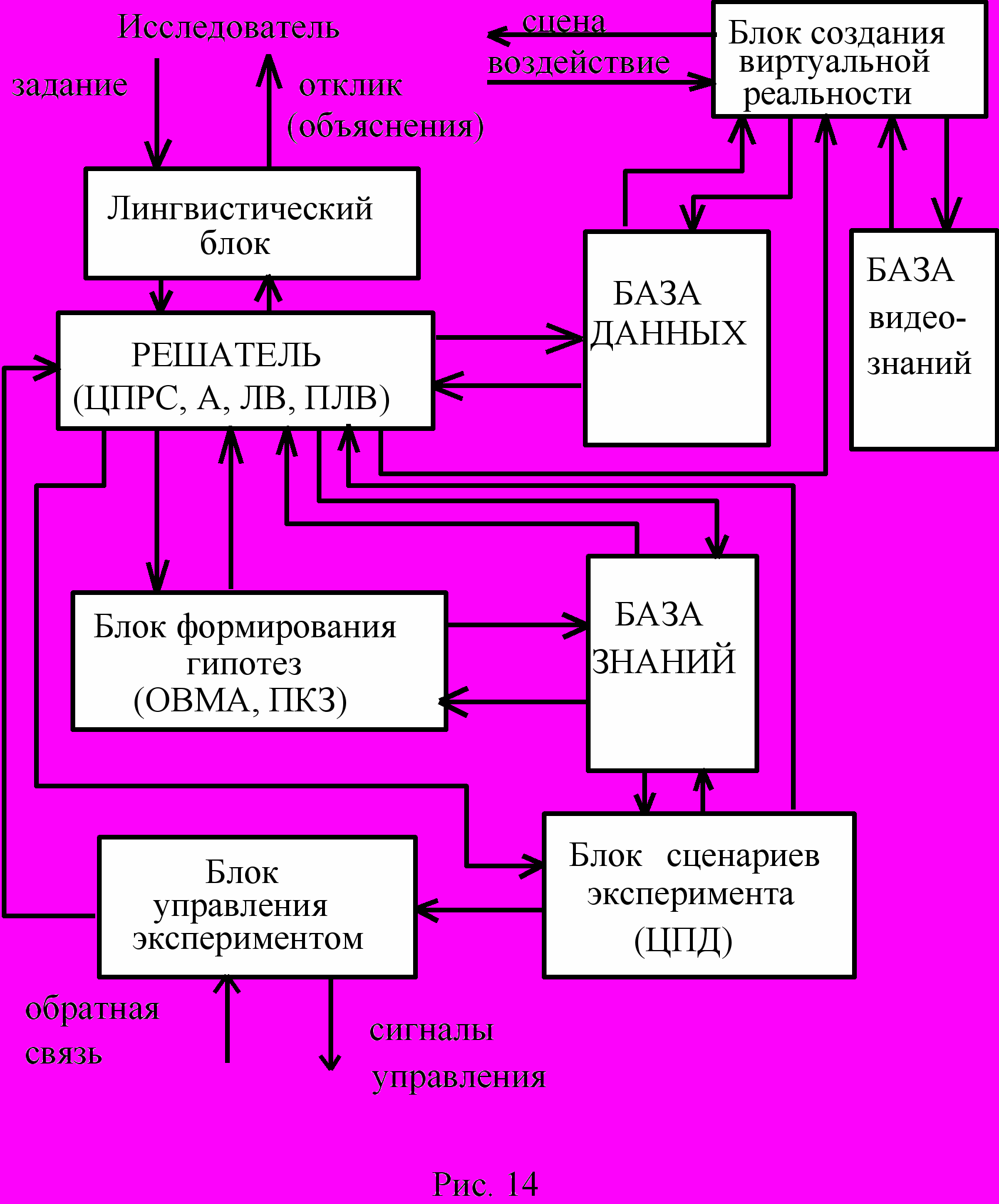
В ИСАНИ (а теперь и в ИСАПР и ИОС) сейчас активно используется новая технология работы с трехмерными зрительными сценариями, названная технологией виртуальной реальности (виртуальных миров).
Для создания ощущения виртуальной реальности, как реальности истинной, используются специальные технические средства: видеошлем и "перчатки данных". Видеошлем, одеваемый на голову, содержит встроенные внутрь шлема дисплей и технические системы, отслеживающие направление взгляда пользователя. В зависимости от поворота головы и движения глаз меняется то, что видит пользователь. В более сложных (пока чисто экспериментальных) случаях имитируется перемещение человека в трехмерной сцене. Для этого используются системы стереоскопического зрения, специальные системы изменения масштабов объектов сцены, системы изменения освещенности и т.п. В хороших системах у пользователя возникает ощущение полного погружения в виртуальную реальность. Изменение в этой "несуществующей действительности" можно осуществлять с помощью "перчатки данных". Эта перчатка одевается на руку пользователя. Перчатка снабжена датчиками тактильных усилий, что позволяет управлять объектами в трехмерной сцене: брать их, перемещать, ломать и т.д. "Перчатка данных" в отличие от систем прямого манипулирования, о которых я говорил, когда рассказывал об интеллектуальных САПР, имеет каналы обратной связи, что порождает иллюзию реальных действий в виртуальной реальности.
В ИСАНИ средства технологии виртуальной реальности имеют большое будущее. Они помогут исследователю путешествовать внутри организма, перемещаясь по кровеносным сосудам вместе с током крови. Они сделают пространство молекул сложных веществ видимыми "изнутри". С их помощью можно воздействовать непосредственно на воздушные струи, порождаемые в виртуальном мире трубы для аэродинамической продувки авиационных и космических кораблей (в одной из существующих уже сейчас систем можно перемещать эти струи, воздействуя на них "перчаткой данных"). По мнению многих исследователей, виртуальные реальности в ИОС, ИСАПР и ИСАНИ дадут грандиозный скачек в повышении эффективности использования подобных систем.
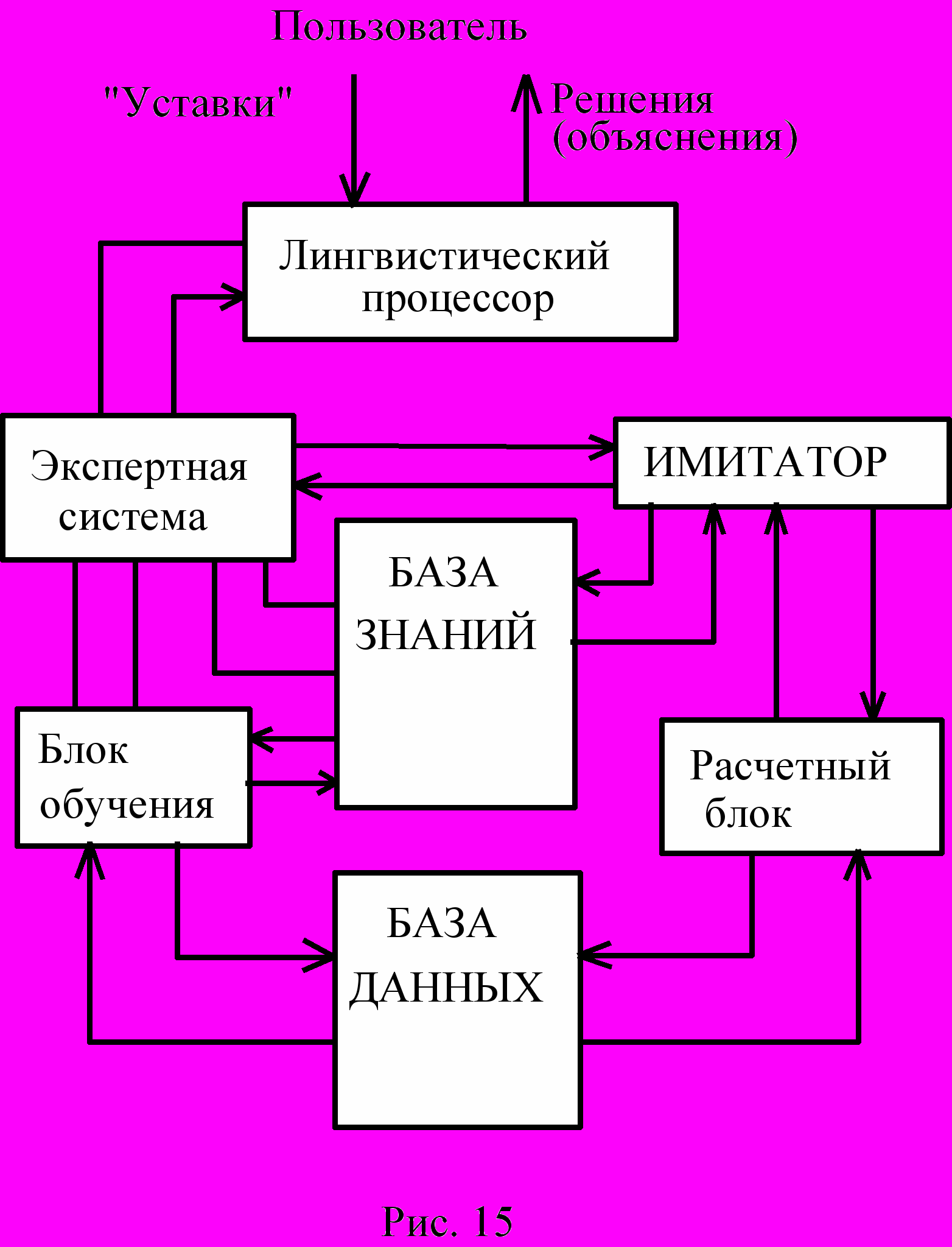
Мы рассмотрели девять типов интеллектуальных систем, которые сейчас, в начале XXI века, определяют прагматическую сущность исследований в области искусственного интеллекта. Новые времена приведут к появлению и широкому внедрению и других типов интеллектуальных систем. Как раз сейчас бурно развиваются работы по созданию интеллектуальных систем оперативного управления техническими системами. И часто называют гибридными системами. Они и на самом деле представляют собой объединение в единую систему ЭС, системы имитационного моделирования, обучающей системы и расчетного блока (рис.15).
Такие системы обладают возможностями автоматизированных систем управления технологическими производствами (АСУПТ), "звездный час" которых был в начале 70-х. Но к этим возможностям они добавляют возможности экспертных систем.