
План Общие сведения о субд. Место бд при различной архитектуре вычислительной
| Вид материала | Документы |
- Комплекс программ, предназначенный для обеспечения определенного уровня эффективности, 735.51kb.
- Тезисы и план доклада м ривкина " Тенденции развития коммерческих субд", 9.85kb.
- Лекция 2 Работа с субд ms access, 167.82kb.
- План: Основные сведения, 549.41kb.
- Общие сведения о факультете, 22.83kb.
- И. А. Защита информации в субд. Лекция, 137.23kb.
- Инфологическое моделирование, 782.45kb.
- «Дискретная математика», 13.21kb.
- Курс, 1 поток, 5-й семестр лекции (34 часа), экзамен, 52.85kb.
- Статья 150. Оплата труда при выполнении работ различной квалификации, 21.02kb.
V. СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ
План
Общие сведения о СУБД.
Место БД при различной архитектуре вычислительной
системы.
Модели данных.
Язык манипулирования данными для реляционной
модели – SQL.
Концепции и возможности СУБД ACCESS.
Концепции и возможности СУБД Oracle.
Информация о СУБД MySQL.
Информация о СУБД Sybase.
Информация о СУБД Interbase.
Сравнение СУБД Postgres и MySQL.
Заключение.
Общие сведения о СУБД
Первые СУБД появились в конце семидесятых годов. К концу восьмидесятых годов СУБД стали основным инструментом для организации быстрого и эффективного доступа к данным. Компонентами системы БД являются СУБД, БД, описание схемы БД, язык описания данных (ЯОД), язык манипулирования данными (ЯМД). Дадим определения, используемых терминов.
База данных – это данные, организованные в виде набора записей определенной структуры и хранящиеся в файлах, где помимо самих данных, содержится описание их структуры.
СУБД – это программно–технологический комплекс, интегрирующий аппаратные средства, БД на технических носителях, программное обеспечение управления БД в самом широком смысле этого термина (операции выборки, линейных преобразований БД и других), а также программируемую логику и набор процедур.
Схема – коллекция объектов БД, содержащих таблицы, индексы, кластеры, представления, снимки – журналы репликации, последовательности, синонимы, пакеты. При проектировании больших БД выделяются подсхемы.
ЯОД – позволяет описать БД в терминах, принятых в конкретной СУБД
ЯМД – позволяет управлять данными (выбирать, сортировать, создавать и др.).
Индекс – дополнительно созданная таблица в БД, состоящая из индекса и ключевых полей основной таблицы, отсортированная по одному из них, позволяет извлекать данные быстро и эффективно.
Кластер – набор таблиц, которые физически хранятся как одна и имеют общие столбцы.
Кэш – область оперативной памяти, выделяемой для приложения, позволяет осуществить быстрый доступ к данным по ранее выполненным запросам.
Объекты схемы – это абстракция (логическая структура) составляющих базы данных.
Пакет – набор процедур, функций, переменных, констант, исключений и др.
View представление – виртуальная таблица, в состав атрибутов которой включены атрибуты из одной или более таблиц.
Процедура – это набор SQL – команд, который выполняет определенную задачу. Процедура может иметь входные параметры, но не имеет выходных.
Репликация – процесс синхронизации в распределенной БД снимков и представлений, на основе которых они созданы.
Снимки – это таблица, содержащая результат запроса с удаленной ЭВМ.
Транзакция – логически завершенный фрагмент последовательности действий (одна или более SQL–команд, завершенных фиксацией или откатом).
Триггер – блок инструкций SQL. Это механизм, позволяющий создавать процедуры, которые будут автоматически запускаться при выполнении команд INSERT, UPDATE или DELETE.
Характеристики некоторых СУБД даны в табл.15.
Таблица 15
Характеристики СУБД
| Характеристики | ORACLE | IBM DB2 | MS SQL | SYBASE |
| Язык программирования | Java, Delphi, PL/SQL | Java, SQL 2000 | Transact-SQL | Java, Transact-SQL |
| XML– библиотеки | Да | Да | Да | Да |
| Объектно–ориентированное проектирование | Да (через SQL) | Да (через SQL) | Нет | Да (через Java) |
| Мультимедийные типы данных | Да | Да | Ограниченно | Ограниченно |
| Enterprise JavaBeans | Да | Нет | Нет | Нет |
| CORBA | Да | Нет | Нет | Нет |
| Макс. размер таблиц | Не ограничено | 64 Гбайт | | Не ограничено |
| Макс. число таблиц | Не ограничено | Практически не ограничено | Не ограничено | Не ограничено |
| Макс. число таблиц на одно соединение | Не ограничено | 31 | Не ограничено | Не ограничено. |
| Макс. число пользователей | Не ограничено | Практически не ограничено | Не ограничено | Не ограничено |
| Рекомендуемая емкость оперативной памяти | Изменяемая величина | Локал: 550Кб. Удаленный: 250 Кб | - | 50 Кбайт |
Направление развития реляционных СУБД в последние годы заметно меняется. Если в предыдущее десятилетие они развивались, чтобы обеспечить быстрый доступ к алфавитно – цифровым данным, то теперь часто нужно хранить еще графические и звуковые данные. Существенно изменилась аппаратная среда – она стала сетевой. С развитием Web – технологий появилась необходимость поддерживать HTML – страницы, 3-, 4- и n-мерные данные. И все это можно создавать на основе БД.
Место БД при различной архитектуре
вычислительной системы
Долгое время использовался централизованный (персональный) вариант применения СУБД. Централизованная архитектура: СУБД и БД размещаются и функционируют на одном компьютере, а пользователи получают доступ к БД через терминал.
В
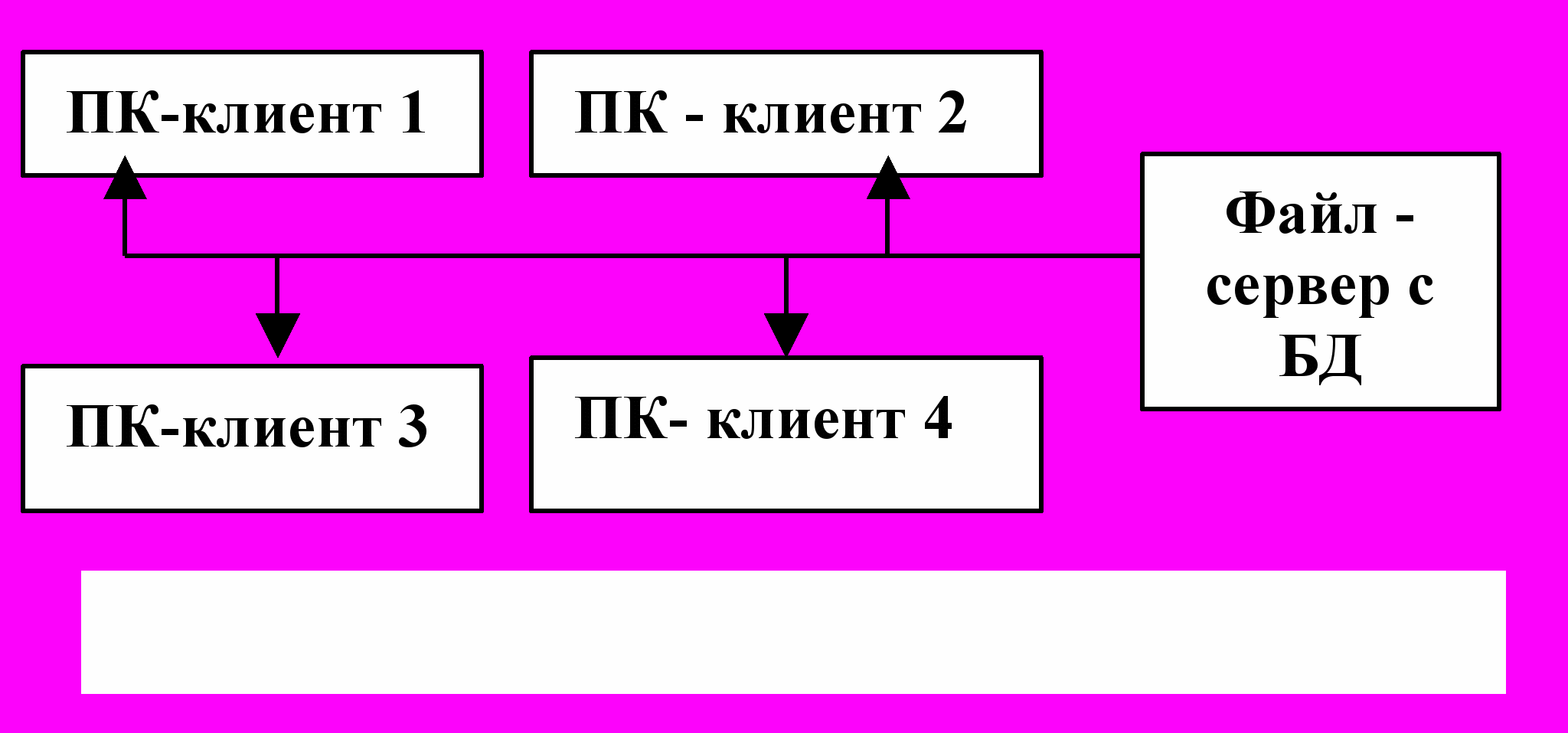
архитектуре «файл – сервер» (рис.8) БД хранится на сервере, а СУБД устанавливаются на каждой ЭВМ.
Рис.8. Архитектура файл – сервер
Производительность зависит от компьютера пользователя, при этом значительно загружается сеть для передачи данных.
В современных СУБД используется архитектура «клиент – сервер» (рис.9), когда БД хранится на сервере, а СУБД имеет клиентскую и серверную части.
Чтобы уменьшить еще объем передачи данных, которые должны подвергаться прикладной обработке, предлагается трехуровневая архитектура «тонкий клиент – сервер приложений – сервер БД» (рис.10). Тонкий клиент обеспечивает взаимодействие с пользователем через браузер, вся прикладная обработка выносится на сервер приложений, который обеспечивает формирование запроса к БД. Сервер БД и сервер приложений могут функционировать в различных ОС.
Р
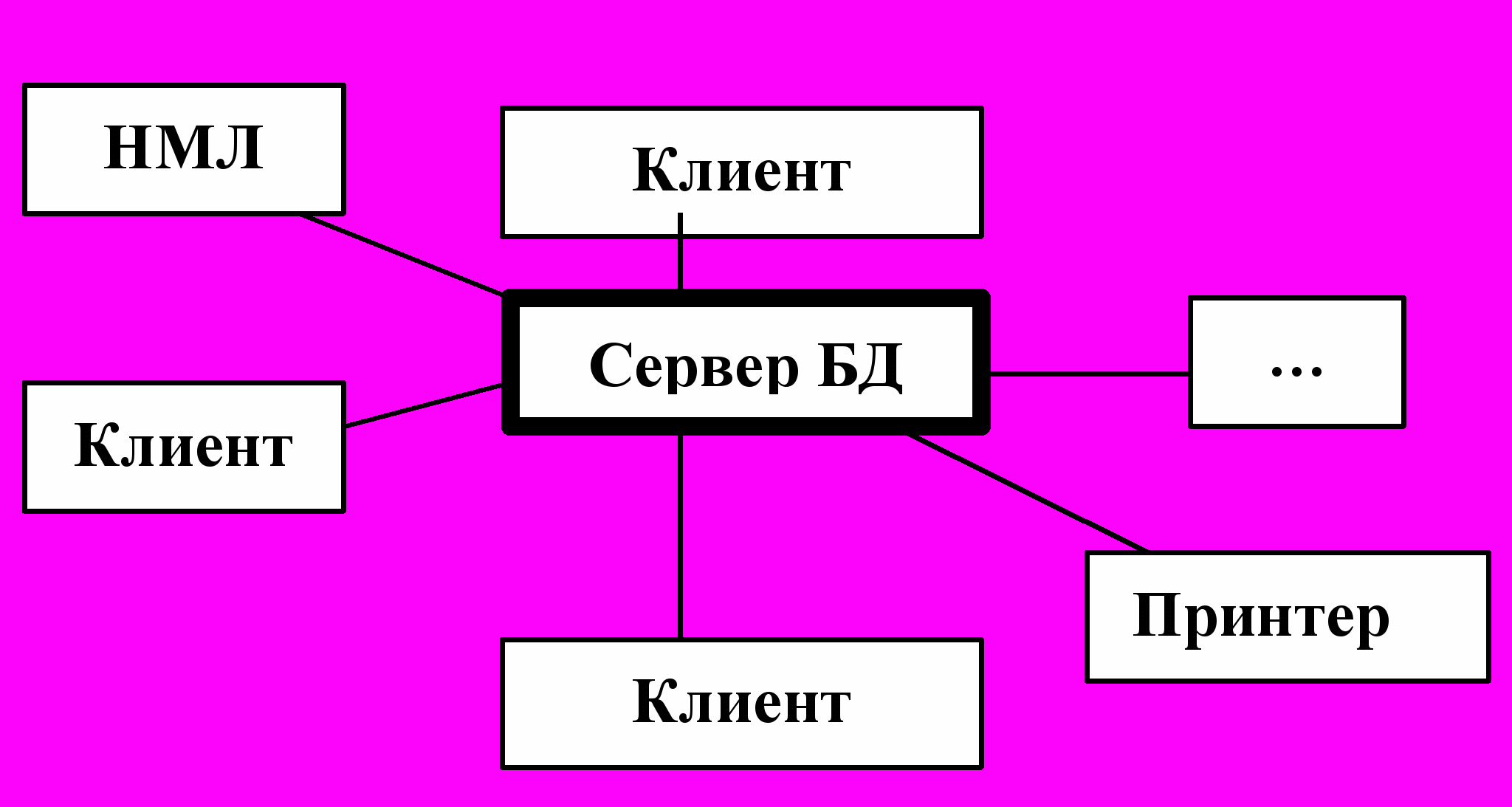
ис. 9. Клиент – серверная архитектура
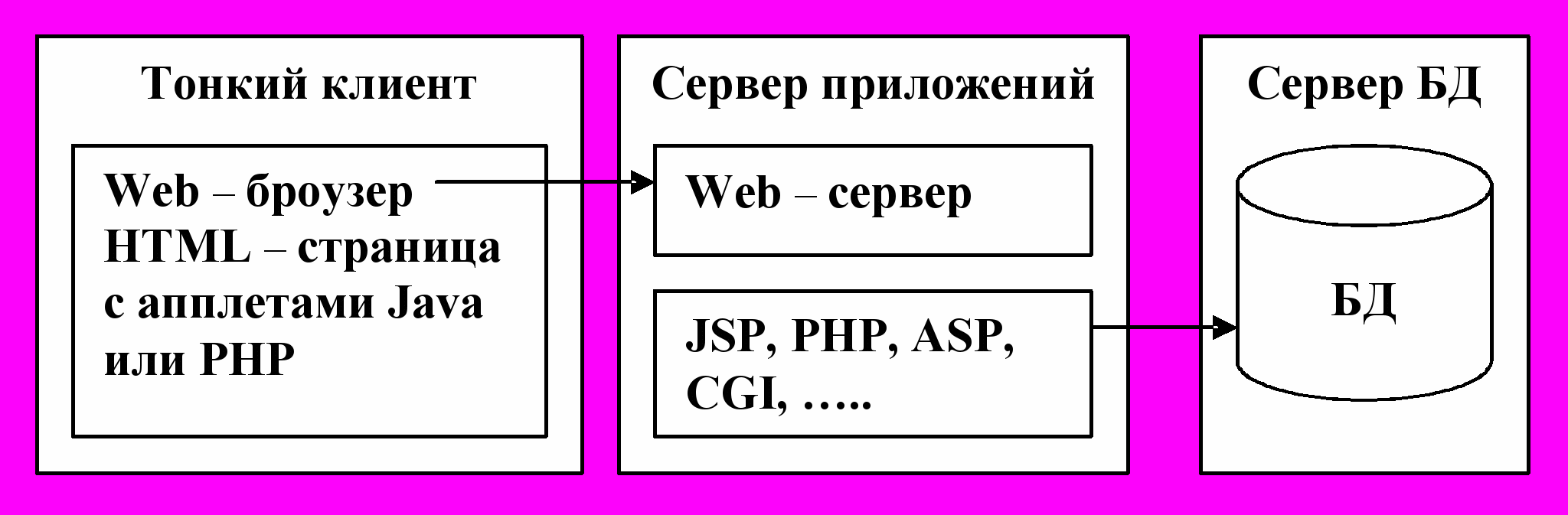 Рис. 10. Трехуровневая архитектура
Рис. 10. Трехуровневая архитектураМодели данных
В основе любой СУБД лежит определенная модель данных. Как правило, используются сетевая, иерархическая, реляционная модель или комбинация этих моделей.
Эти модели различаются в основном способами представления взаимосвязей между объектами. Старейшие системы основаны на иерархической модели данных. К ним относится, например, разработанная для больших ЭВМ СУБД «Ока». Реляционными СУБД являются DB2, Oracle, Paradox, Access, FoxPro и др. Сетевой является СУБД СЕТОР.
Иерархическая модель данных строится по принципу иерархии типов объектов, т. е. один тип объекта является главным, а остальные, находящиеся на низших уровнях иерархии,— подчиненными. Эта структура строится из узлов и ветвей. Узел представляет собой совокупность атрибутов данных, описывающих некоторый объект. Наивысший узел в иерархической древовидной структуре называется корнем. Зависимые узлы располагаются на более низких уровнях дерева. Зависимые узлы могут добавляться как в вертикальном, так и в горизонтальном направлении без всяких ограничений. Связи (соединения) между узлами уникальны, поэтому иерархическая модель данных обеспечивает только линейные пути доступа к данным, а между главными и подчиненными типами объекта устанавливается линейная взаимосвязь “один ко многим». Каждый экземпляр корневого узла образует начало записи логической БД, т. е. иерархическая БД состоит из нескольких деревьев. К главным достоинствам иерархической модели данных можно отнести простоту понимания и использования. Недостатки модели – это громоздкие структуры при сложных БД и, как правило, хранение избыточных данных, например, описание одинаковых комплектующих (гайки, болты) в разных узлах (см. рис.11).
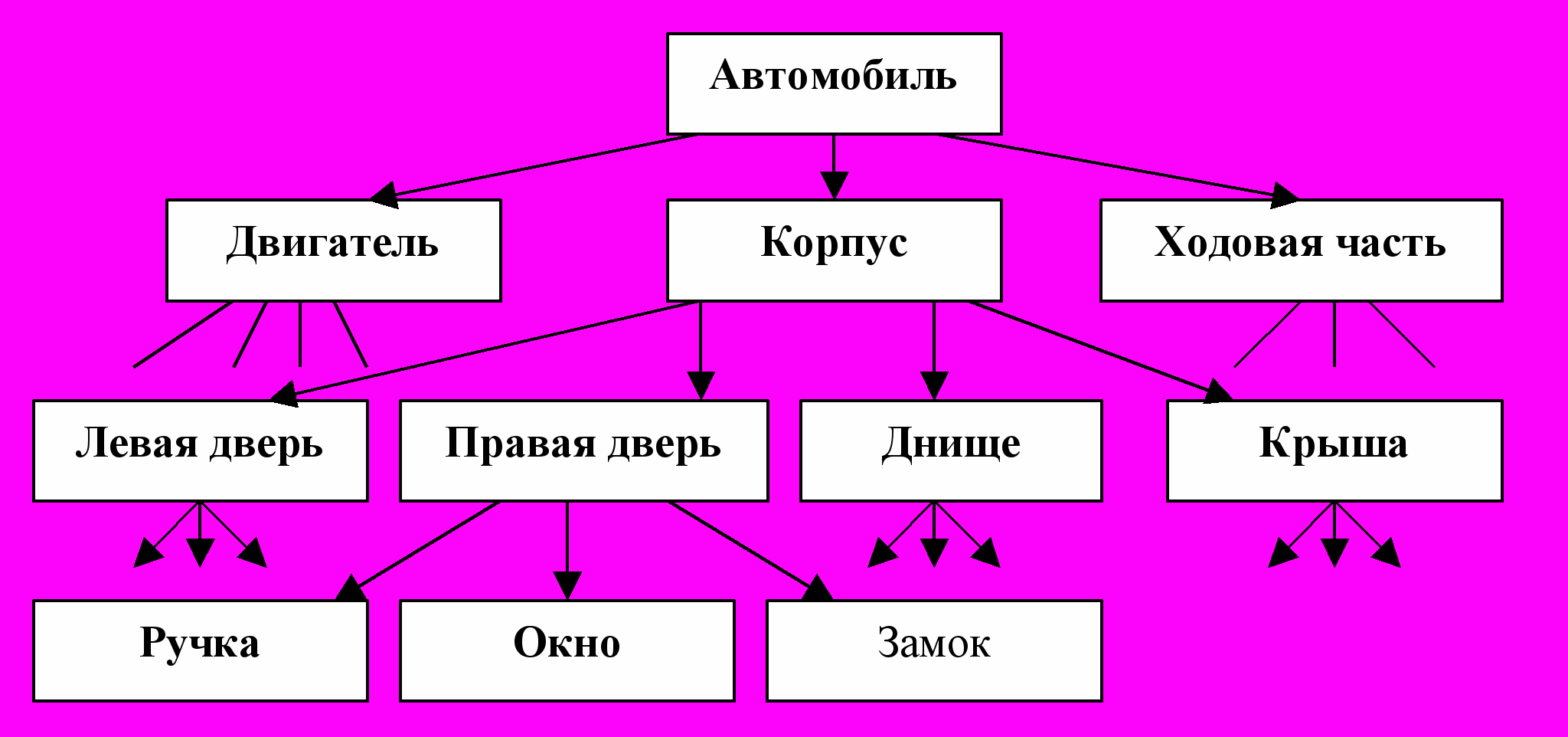
Рис. 11. Фрагмент иерархической БД
В сетевой модели данных (рис.12) понятия главного и подчиненных объектов несколько расширены. Любой объект может быть и главным, и подчиненным (в сетевой модели главный объект обозначается термином «владелец набора», а подчиненный — термином «член набора»). Один и тот же объект может одновременно выступать и в роли владельца, и в роли члена набора. Это означает, что каждый объект может участвовать в любом числе взаимосвязей. БД состоит из нескольких областей, каждая область содержит записи. В свою очередь запись состоит из полей, а набор, который объединяет записи, может размещаться в одной или нескольких областях. Достоинство сетевой модели – простота реализации часто встречающихся в реальном мире взаимосвязей, закладываемых в БД. Основной недостаток сетевой модели состоит в сложности управления данными, в том числе и возможная потеря независимости данных при реорганизации БД.
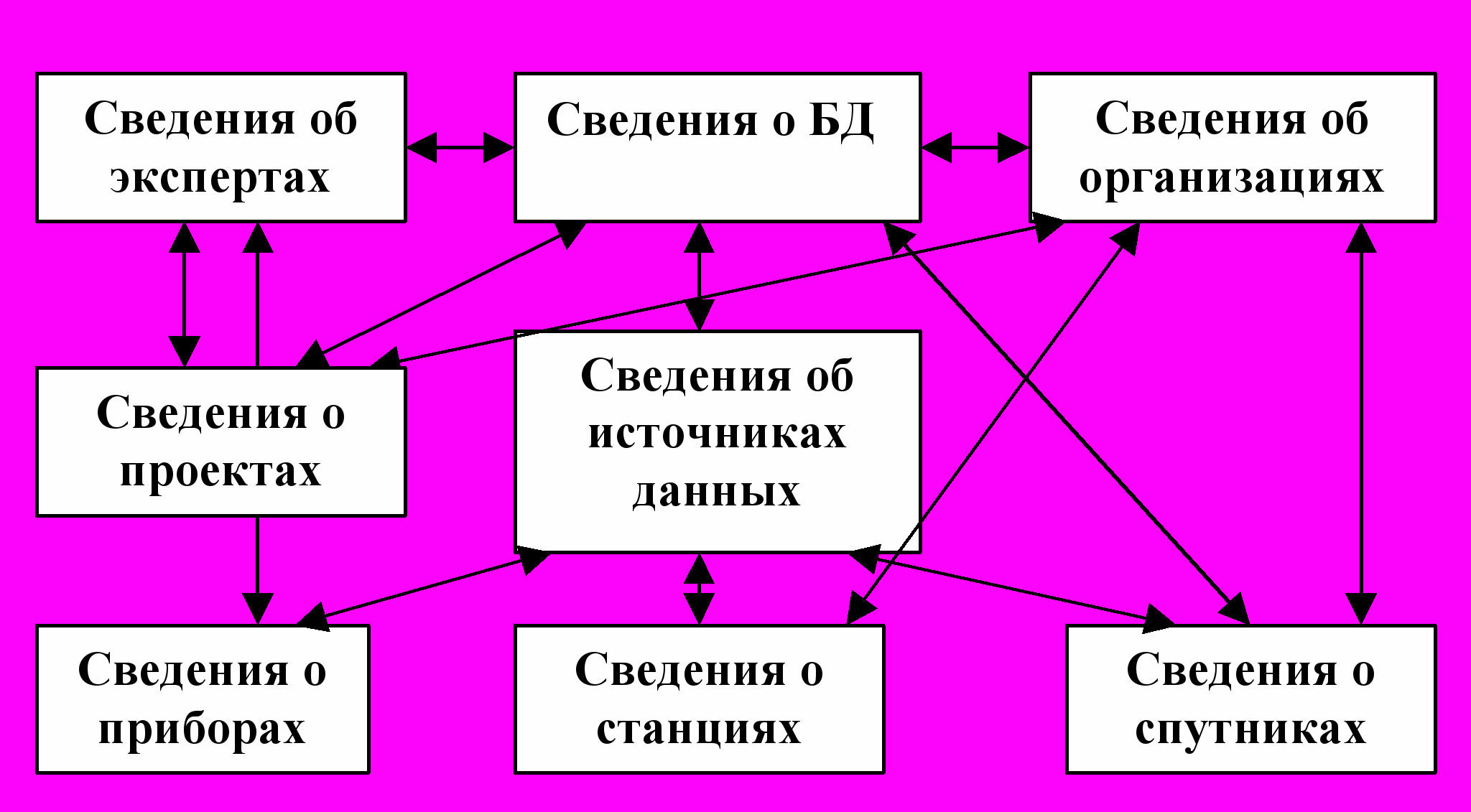
Рис. 12. Фрагмент сетевой БД для метаданных
В реляционной модели данных (рис. 13) объекты и взаимосвязи между ними представляются с помощью таблиц. Взаимосвязи также рассматриваются в качестве объектов (таблицы связей). Каждая таблица представляет один объект. В терминологии реляционной модели таблица называется отношением. Каждый столбец в таблице является атрибутом. Значения в столбце выделяются из домена, т. е. домен – суть множества значений, которые может принимать некоторый атрибут. Строки таблицы называются кортежами.
О базе данных, построенной таким образом, говорят, что она построена в первой нормальной форме, причем для каждого атрибута всех таблиц фиксирован тип и формат данных. Соединение данных из разных таблиц обеспечивается операторами языка SQL. К достоинствам реляционной модели следует отнести простоту общения пользователя с моделью.
Р
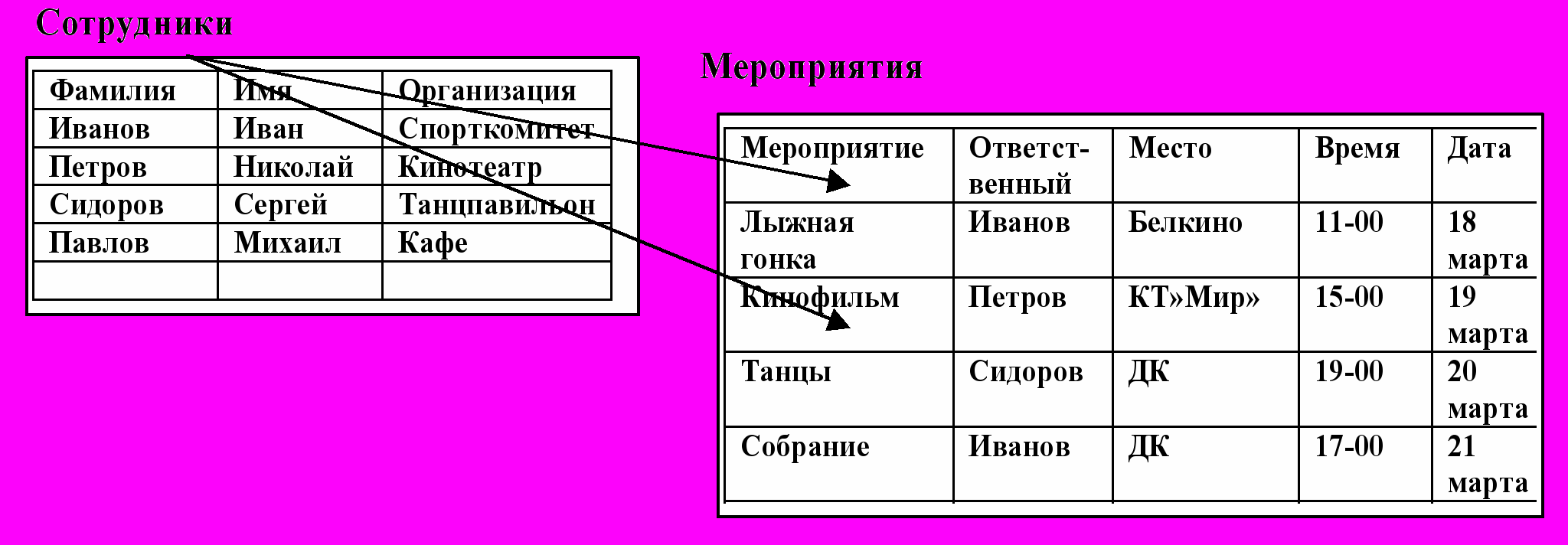 ис. 13. Отношения между таблицами
ис. 13. Отношения между таблицами Недостаток модели – рядовые реляционные системы работают медленнее систем, базирующихся на сетевой или иерархической модели данных. Первичный ключ – это столбец, значения которого во всех строках отличаются. Он может объединять несколько столбцов. В некоторых СУБД первичный ключ может задаваться системой
(ACCESS, Oracle). Связь реализуется при помощи внешнего ключа (это столбец таблицы, значения которого совпадают со значениями первичного ключа другой таблицы). Важным моментом является также использование значения NULL в таблицах реляционной БД. NULL – это отсутствующее значение, отсутствие информации в поле. Это поле обрабатывается особым образом.
Объектно – реляционные БД. Реляционные модели данных и созданные на их основе реляционные СУБД имеют ограниченный набор типов данных и хранят информацию в двумерных таблицах. Сложные структуры данных должны быть разбиты и распределены между этими таблицами. При этом логические связи между таблицами не хранятся. Новый подход к моделям данных – разрешение использования данных сложной структуры (например, графические, гипертекстовые, пространственные данные) в виде отдельных объектов, между которыми устанавливаются различного рода связи. В свою очередь эти логические связи определяются как объекты и вносятся в структуру модели. Такие модели называют объектно–ориентированными моделями данных. Эта модель используется в СУБД Oracle, Informix, PostgreSQL. Здесь применяются концепции объектно – ориентированного программирования (полиморфизм, инкапсуляция, наследование).
Постреляционная модель – это качественное и количественное расширение реляционной модели. Если в реляционных моделях используется первая нормальная форма, то в постреляционных моделях данные описываются не первой нормальной формой, не требуется определять для поля специфический тип и длину. Благодаря этому, можно задать таблицу, в которую вложены другие таблицы. Если всю информацию свести в одну большую таблицу, такая таблица неизбежно будет содержать пустые клетки или избыточные данные, при использовании нескольких таблиц потребуется выполнять весьма ресурсоемкую операцию соединения, снижая тем самым эффективность работы СУБД.
Моделью многомерной БД (рис.14) является многомерный куб, где на измерениях определены некоторые иерархии, а в клетках этого куба находятся числовые значения. Операции извлечения данных из такого куба описываются в терминах поворотов, срезов, и иерархического "схлопывания" измерений с агрегированием значений (суммирование, взятие среднего и др.). Эта схема хорошо ложится на табличную организацию данных. Наиболее известный программный продукт этого класса – это Oracle Express Server.
Язык манипулирования данными для реляционной модели – SQL
Язык SQL включает следующие основные команды:
- определение и создание схем и таблиц;
- поиск и выборка данных;
- операции реляционной алгебры (объединение, пересечение, разница);
- изменение данных (вставить, изменить, удалить);
- создание View представлений и др.
Определение схемы:
Create Schema
Authorization
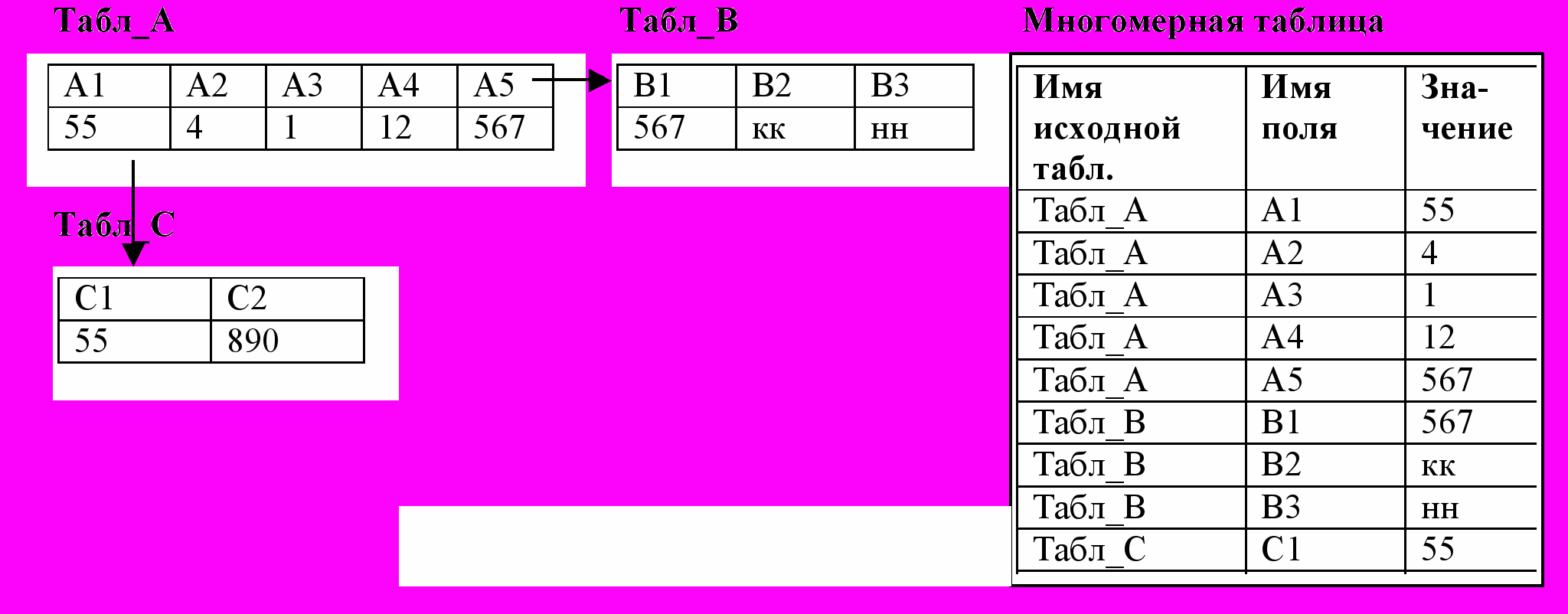 Рис. 14. Многомерная схема БД
Рис. 14. Многомерная схема БД
Определение таблиц включает:
- присвоение имени;
- определение типа данных (Integer – целое; Numeric – число; Decimal – десятичное; Real – действительное; Float – с плавающей запятой; Character; Character varying; Bit; Date);
- определение полей с ограничительными условиями;
- определение ограничительных условий на таблицу.
Create Schema DDD
Authorization Name
Domain definitions
Create TABLE Name_table1 (
Worker_ID ITEM_IDENTIFIER Primary key
Worker_name Character (12)
Foreign KEY SUPV_ID REFERENCES Name_table1
On DELETE SET NULL)
Create TABLE Name_table2 )
Поиск
SELECT name_1 FROM Name_table1 WHERE name_2='XXXX'
Операторы сравнения: =, >, <, <=, >=
Булевы операции: AND, OR, NOT
WERE name_3 BETWEEN 10 and 15
WERE name_ 4 LIKE (''AAA%')
N_date + interval '14' DAY
N_date + interval '7' * Num_weeks (дата = текущая дата плюс 7 умноженное на число недель)
Многотабличные запросы:
SELECT name_поля FROM Name_table1, Name_table2 WHERE Name_table1.Worker_ID=Name_table2.Worker_ID
Name_Id=435
Результат: объединение полей двух таблиц при условии Name_Id = 435.
Встроенные функции: SUM, AVG, COUNT, MAX, МIN
SELECT max (Name_1), Min (Name_2)
From Name_table1
Where Name_3=15
Подзапросы:
SELECT Name_1 FROM Name_table1 WHERE Name_3 = or >
(SELECT max (Name_2)
From Name_table1)
Операции реляционной алгебры: UNION – объединение, INTERSECT – пересечение, EXCEPT – разница. Применяются для двух таблиц, которые должны быть совместимы (одинаковые число столбцов и типы данных в них).
(SELECT *
FROM (TABLE Name_table1 UNION TABLE Name_table2)
Операции изменения данных: INSERT – вставить,
UPDATE – изменить, DELETE – удалить
INSERT INTO Name_Table_2
SELECT Name_1, Name_3, Name_4
From Name_Table_1
WERE Name_5=3
Совместное использование SQL c традиционными языками программирования (Си, Паскаль, др.)
OPEN File_1
EXEC SQL
DECLARE File_1
FOR
SELECT *
FROM Table_1
WERE Name_2= nn
END–EXEC
CLOSE File_1
Создание View – представлений данных
CREATE VIEW Table_V
AS SELECT Name_2, Name_3, Name_4, Name_5
FROM Table_1
Подборку документов по SQL можно найти по адресу: ссылка скрыта
Концепции и возможности СУБД ACCESS
В Microsoft Access поддерживаются три способа создания БД. Имеется возможность создать пустую БД, а затем добавить в нее таблицы, формы, отчеты и другие объекты. Можно создать таблицу, формы и отчеты с помощью Мастера и Конструктора. Во всех случаях есть возможность в любое время изменить и расширить созданную БД по числу таблиц и полей.
У таблицы задаются свойства, обязательность заполнения полей, условия на предельные значения атрибутов, маска ввода, связи между таблицами; настраивается оформление или оформление указывается по умолчанию; можно увеличить ширину столбца, изменить структуру таблицы. У окон настраивается расположение, отображение и просмотр объектов.
Большая часть данных, представленных в форме, берется из таблицы или запроса. Другая информация, не связанная ни с таблицей, ни с запросом, хранится в макете формы.
В форме отчетов задается вставка даты, построения диаграмм, подготовки отчета. При этом надо использовать Конструктор или Мастер отчетов.
С помощью запросов можно просматривать, анализировать и изменять данные из нескольких таблиц. Они также используются в качестве источника данных для форм и отчетов. Наиболее часто используется запрос на выборку. При его выполнении данные, удовлетворяющие условиям отбора, выбираются из одной или нескольких таблиц и выводятся в определенном порядке. Перекрестный запрос вычисляет сумму, среднее значение, число элементов и значения других статистических функций, группируя данные и выводя их в компактном виде. Перекрестный запрос создается с помощью соответствующего Мастера или в Конструкторе запросов.
Условие отбора задается с помощью другого поля, сравнением на содержание текста или значение числа.
Отчет — это гибкое и эффективное средство для организации данных при выводе на печать. С помощью отчета имеется возможность вывести необходимые сведения в том виде, в котором требуется. Больше всего сведений в отчете берется из базовой таблицы, запроса или инструкции SQL, являющихся источниками данных для отчета. Другие сведения вводятся при разработке отчета.
Макросом называют набор из одной или более макрокоманд, выполняющих определенные операции, такие как открытие форм или печать отчетов. С помощью Макросов можно определить горячие клавиши, создание БД с помощью окна и др. Макросы могут быть полезны для автоматизации часто выполняемых задач.
Модуль – это набор объявлений и процедур – приложение на языке VBA – Visual Basic for Applications, используемом также в Excel, Word, PowerPoint. При создании первой процедуры обработки события для формы или отчета автоматически создается связанный с ней модуль формы или отчета. Для просмотра модуля, формы или отчета достаточно нажать кнопку «Программа», которая находится на панели инструментов в режиме конструктора. В процедурах модулей форм и отчетов могут содержаться вызовы процедур, добавленных в стандартные модули.
Событие – это определенное действие, которое происходит или возникает в определенном объекте. Microsoft Access реагирует на большое число различных событий: нажатие кнопки мыши, изменение данных, открытие или закрытие форм и т. д. Обычно события возникают вследствие действий пользователя. С помощью процедур обработки события или макроса возможно определение собственных откликов на события, происходящие в форме, отчете или элементе управления.
Анализатор быстродействия исследует всю БД, дает рекомендации по ее улучшению, а также осуществляет это улучшение.
Другие операции в СУБД ACCESS представлены ниже.
Работа с данными: ввод, выделение, замена, копирование, поиск, редактирование, сортировка, определение формата поля, отсутствующих – Null или пустых строк.
Создание индекса: определение ключа, свойств, создание индекса для одного или нескольких полей.
Получение справки: по содержанию или предметному указателю, контекстному поиску, по теме, включить Помощника, совет дня.
Операции с файлами: восстановление закрытой и открытой БД, преобразование БД, сжатие, установка папки по умолчанию, защита БД на уровне пользователя, ограничение прав пользователя, пароль БД, создание файла рабочей группы, шифровка/дешифровка, резервное копирование.
Построение законченного приложения для работы пользователя низкой квалификации: построение кнопочной формы, определение параметров запуска приложения, построение пользовательского меню и панелей инструментов, связывание меню и панелей инструментов с формами и отчетами.
Концепции и возможности СУБД Oracle
Oracle является законодателем в области новых направлений развития СУБД. Вот далеко не полный список таких "пионерских" достижений:
- первая коммерческая SQL СУБД;
- поддержка множества вычислительных платформ;
- поддержка архитектуры клиент/сервер;
- поддержка модели записи нескольких версий (Multi–version Read Consistency);
- поддержка кластерной архитектуры;
- поддержка распределенных транзакций;
- поддержка активных бизнес – правил;
- поддержка параллельной обработки;
- оптимизация работы с хранилищами данных4
- поддержка всего спектра Multimedia;
- поддержка объектно–реляционной модели;
- поддержка Messaging.
Все объекты БД (таблицы, представления, индексы, сегменты отката, временные сегменты) хранятся в единой физической БД, но в различных табличных пространствах.
Фирма Oracle выпускает полнофункциональный набор средств для создания приложений масштаба предприятий, предоставляющий полный спектр возможностей для распространения информации в Web. Для реализации комплексных решений имеется широкий набор программных продуктов:
для создания БД (Oracle Database Server, Enterprise Edition, Database Personal Edition, Database Lite);
средства разработки (Oracle Programmer, Internet Developer Suite, Designer, Developer, JDeveloper, XML Developer's Kit);
средства поддержки принятия решений (Oracle Express Server , Analyzer, Web Agent и Web Publisher);
средства распространения информации в Web (Oracle Internet Developer Suite, Application Server OmniPortlet и Web Clipping);
средства создания хранилищ данных (Oracle DataMart Suite, Warehouse Builder, Discoverer Plus);
средства администрирования и управления СУБД (Tuning Pack, Diagnostics Pack и Change Management Pack);
средства электронной коммерции (Oracle Marketing, Interaction Center, Sales, Service)
В СУБД встроены средства эффективного создания и поддержки работы очень больших (до 512 Pb) БД (VLDB), хранилищ данных, средств поддержки многомерных OLAP–технологий и алгоритмов (анализ данных), Data Mining (автоматическое исследование данных) с сохранением всех преимуществ коммерческой СУБД, средств проектирования и выполнения процедур извлечения, согласования, очистки, передачи и загрузки данных (ETL), средств персонализации, работа с XML. Сервер Oracle является не только объектно–реляционным, но и позволяет хранить и обрабатывать XML данные, поддерживает многомерное представление данных для анализа, выдает оперативные рекомендации, реагируя на работу пользователей с приложением. Имеются специальные механизмы хранения, индексирования, построения XML, View и т.д., которые позволяют не только эффективно хранить, но и запрашивать и изменять эти данные и их части. Причем традиционные SQL – операции умеют работать как с реляционными данными, так и с XML – файлами.
В СУБД развиты Web – технологии, файловая система (IFS), виртуальная Java машина, работа с динамическими Web – сервисами, средства проектирования и реализации порталов и хранилищ данных.
Программное обеспечение Oracle работает и использует все преимущества самых разных аппаратных платформ и операционных систем (на сетевых компьютерах, носимых миниатюрных компьютерах, телевизионных приставках, персональных компьютерах, рабочих станциях, миникомпьютерах, кластерах, мэйнфреймах и т.д.).
Открытые стандарты Oracle 9i Application Server, обладающий открытой архитектурой и готовый к любым интеграционным процессам, поддерживает все стандарты для J2EE, веб – сервисов и XML.
Enterprise Manager позволяет выполнять следующие задачи:
- настройка и администрирование одного или более экземпляров БД Oracle;
- распределять программное обеспечение;
- отслеживать события нескольких экземпляров;
- выполнять резервное копирование и восстановление;
- обычные задачи администрирования пользователей.
База данных разделяется на одно или более логических частей, называемых табличными пространствами. Табличные пространства используются для логической группировки данных между собой. Сегментирование групп по табличным пространствам упрощает администрирование этих групп. Каждое табличное пространство состоит из одного или более файлов данных. Используя несколько файлов данных для одного табличного пространства, можно распределить их по разным дискам, увеличив тем самым скорость ввода–вывода и, соответственно, производительность системы.
Таким образом, БД Oracle состоит из табличных пространств, которые, в свою очередь, состоят из файлов данных. А файлы данных могут быть разбросаны по нескольким физическим дискам.
В процессе создания БД Oracle автоматически создается табличное пространство SYSTEM. Хотя для небольших БД может хватить этого табличного пространства, следует создавать дополнительные табличные пространства для пользовательских данных. В словаре данных содержится информация о таблицах, индексах, кластерах и т.д.
При создании табличного пространства, можно указать минимальное число определения – экстент, а также число экстентов, добавляемых при заполнении уже определенных. Это распределение позволяет контролировать пространство хранилища БД.
При работе с СУБД Oracle необходимо организовать выполнение таких функций как восстановление после сбоев, перехват ошибок, а также обеспечить целостность данных и др. Это можно устроить посредством контрольных точек, журналирования и архивирования.
В СУБД Oracle была введена технология секционирования (partitioning), которая позволяет загружать большие таблицы и индексы по частям, а не как единое целое, и дает существенный выигрыш в производительности СУБД.
Параллельный сервер СУБД Oracle позволяет разделить доступ к базе данных между разными серверными процессами (Oracle instance), причем каждый из процессов может обрабатывать конкурирующие транзакции. Различные серверные процессы, работающие с одной и той же базой данных, могут быть запущены на разных машинах, формируя тем самым отдельный кластер. Это резко повышает надежность работы системы, поскольку параллельный сервер в состоянии выявить аварийную ситуацию, произошедшую с одной из машин кластера, практически мгновенно, после чего база данных продолжает оставаться доступной через серверный процесс, запущенный на другой машине.
Репликация – это процесс копирования и поддержания объектов БД на множестве серверов, составляющих распределенную информационную систему. Изменения, производимые на одном сервере системы, затем передаются на удаленные серверы. Репликации позволяют пользователю получить быстрый доступ к разделяемой информации и организовать синхронизацию данных. Репликации в среде Oracle могут происходить по двум схемам: мастер–мастер и мастер–snapshot.
В первом случае два или несколько серверов БД функционируют как равные части единой системы. При такой конфигурации клиентские приложения могут изменять данные на любом из серверов – серверы СУБД Oracle автоматически синхронизируют данные во всех объектах репликаций, гарантируя при этом глобальную целостность данных и поддержку конкурирующих транзакций.
Подборку документов по СУБД Oracle можно найти по адресу: ссылка скрыта.
Информация о СУБД MySQL
СУБД MySQL является одной из самых известных, надежных и быстрых из всего семейства существующих СУБД. Исходные коды скомпилированы под множество платформ и разнообразные утилиты можно найти на сайте ссылка скрыта.
СУБД MySQL разработана компанией TcX. Эта СУБД является идеальным решением для малых и средних приложений. СУБД MySQL рассматривается как основа для проектов, не требующих высоких требований к сохранности данных: форумы, системы ведения статистики посещаемости и т.д. Наиболее полно возможности сервера проявляются на Unix–серверах, где есть поддержка многопоточности, что дает значительный прирост производительности. MySQL – сервер является бесплатным для некоммерческого использования. MySQL – это компактный многопоточный сервер SQL БД, широко распространенный в качестве SQL – движка сайтов благодаря удачному сочетанию пользовательских свойств, открытым исходным кодам и хорошей технической поддержке. Исходный язык MySQL – C, что во многом определяет его слабые и сильные стороны. Краткий перечень положительных свойств СУБД MySQL:
- поддерживается неограниченное количество пользователей, одновременно работающих с БД;
- количество строк в таблицах может достигать 50млн;
- быстрое выполнение команд;
- простая и эффективная система безопасности.
СУБД MySQL поддерживает язык запросов SQL в стандарте ANSI 92, и, кроме этого, имеет множество расширений к этому стандарту, которых нет ни в одной другой СУБД. Одной из самых серьезных проблем СУБД MySQL по сегодняшний день остается неразвитость используемого диалекта SQL.
Отсутствие оператора «Объединение – UNION» и подзапросов дает себя знать при конструировании запросов, а отсутствие встроенных процедур и триггеров вынуждает реализовывать бизнес–логику системы не средствами сервера БД, а с применением внешнего по отношению к базе языка программирования Web – страниц.
Отсутствие некоторых конструкций типа подзапросов – это более неприятная вещь, вынуждающая программиста писать специальную процедуру в иных местах, где можно было бы обойтись одним запросом. При этом необходимо вручную делать то, что обычно автоматически делается сервером: формировать временную таблицу, помещать туда результаты, а потом использовать их в следующем запросе. СУБД MySQL поддерживает средства, упрощающие эту работу: в частности, поддерживает временные таблицы, локальные для данного соединения и автоматически удаляющиеся при его закрытии, а также создание таблиц в оперативной памяти. В более простых случаях, когда результат выполнения подзапроса представляет собой одну запись, для хранения промежуточных значений можно использовать переменные СУБД MySQL.
Подборку документов по СУБД MySQL можно найти по адресу: ссылка скрыта.
Информация о СУБД Sybase
Sybase EAServer 4.0 – самый открытый, высокоэффективный, масштабируемый и надежный сервер приложений для корпоративных, портальных и Интернет–решений, использующих многоуровневые архитектуры, полностью поддерживает стандарт Java 2 Enterprise Edition (J2EE)™ 1.3 (ссылка скрыта).
Sybase EAServer – это оптимальный выбор для разработки приложений, благодаря надежности и способности адаптироваться к существующей архитектуре и поддерживать высокопроизводительные, масштабируемые и распределенные web – приложения. Sybase EAServer поддерживает стандарт J2EE 1.3, представляющий собой набор технологических и концептуальных решений, скрывающих от конечного разработчика сложность низкоуровневой реализации серьезных корпоративных приложений, обеспечивая управление транзакциями, жизненным циклом програм-много обеспечения, кэшированием ресурсов и др.
Sybase EAServer поддерживает широкий спектр совместно используемых компонентных моделей, включая CORBA® 2.3/IIOP 1.2, ActiveX® /COM, Enterprise JavaBeans™, Java® Servlets и PowerBuilder® NVO. Sybase EAServer поддерживает большинство языков программирования и инструментальных средств – Java™,C/C++, Visual Basic® и PowerBuilder, может функционировать на базе подавляющего большинства корпоративных платформ – Microsoft® Windows NT/2000, Sun® Solaris™, HP-UX® IBM AIX®, а также Red Hat® Linux.
Информация о СУБД InterBase
Borland Software выпустила кроссплатформенную встраиваемую СУБД InterBase. Одной из особенностей версии 7.1 является поддержка Windows Server 2003, что свидетельствует о поддержке платформы Microsoft.Net. Последняя версия обеспечивает возможность автоматического восстановления после сбоев и оптимизирована для встраивания в распределенные приложения. В числе особенностей InerBase 7.1 – упрощенные процедуры инсталляции и сопровождения. Улучшен модуль управления InterBase - Console Performance Monitor: усовершенствован интерфейс, позволяющий управлять процессами СУБД, отображающий уровни ее загруженности и информацию о деятельности пользователей. Имеется поддержка многопроцессорных систем. InterBase 7.1 выпущена в версиях для Windows, Linux и Solaris.
Сравнение СУБД Postgres и MySQL
Обе СУБД сравнительно просты в установке и настройке, но у Postgres настроек больше и, соответственно, для его "доведения до ума" потребуется больше усилий. У PostgreSQL больше "продвинутых" функций, которые сильно облегчают жизнь, например, JOIN, VIEW и т.п. MySQL очень хорошо и быстро работает с простыми выборками (SELECT), но значительно быстрее "ложится" если в таблицу часто что-то пишется: при записи блокируется вся таблица, а не одна строка, как в Postgres. Устойчивость обоих СУБД примерно одинакова. Недостатком Postgres можно считать сравнительно большое время, которое он тратит на установление соединения с клиентом, но при использовании persistent connections (т.е. подключений, которые не закрываются при окончании работы скрипта).
В целом обе СУБД активно двигаются навстречу друг другу – Postgres увеличивает производительность, а MySQL добавляет функциональности, стараясь при этом не слишком затормозиться. На сайте MySQL, впрочем, есть таблицы сравнения функциональности и производительности разных СУБД, в которых ясно показано, что MySQL превосходит конкурентов. Несомненным плюсом MySQL является ее значительно большая популярность, что связано с более простой установкой и наличием готового дистрибутива для Windows (PostgreSQL под Windows поставить тоже можно, но это требует некоторых ухищрений).
Заключение
Представлены общие сведения о СУБД, роль СУБД при создании информационных систем, место БД при различной архитектуре вычислительной системы. Рассмотрены модели данных – иерархическая, сетевая, реляционная и постреляционная модели данных, многомерная схема. Даны краткие сведения о языке описания данных, языке манипулирования данными для реляционной модели – SQL, а также информация о продуктах СУБД ACCESS и СУБД Oracle.
При выборе СУБД можно применить следующие критерии оценки:
- надежность БД;
- продолжительность незапланированного простоя;
- скорость поиска и масштабируемость БД;
- время отклика при первоначальной регистрации в системе, выполнении наиболее типичных транзакций, наиболее типичных запросов;
- количество одновременно работающих пользователей на один сервер БД, на одного администратора БД.
Литература
- MS SQL Server. ссылка скрыта, ссылка скрыта, ссылка скрыта, ссылка скрыта.
- Власов А.И, Лыткин С.Л., Яковлев В.Л., Краткое практическое руководство разработчика информационных систем на базе СУБД ORACLE / МГТУ им. Н.Э.Баумана. – М., 2000. ссылка скрыта.
- ссылка скрытаИзд-во: Вильямс, 2002.
- ссылка скрыта Изд.: Питер, 2002.
- Дейв Энсор, Йен Стивенсон. Oracle – 8: Рекомендации разработчикам. – Киев: Изд. Гр. BHV. – 1998. – 125 с.
- Кириллов В.В. Основы проектирования реляционных баз данных / ссылка скрыта. ссылка скрыта. ссылка скрыта.
- Кузнецов С.Д. Основы современных баз данных, информационно–аналитические материалы ссылка скрыта // ссылка скрыта
- ссылка скрыта Изд-во: Питер, 2002.
Вопросы для самопроверки
- Почему база данных улучшает обмен данными между приложениями?
- Каковы Важнейшие характеристики СУБД?
- Основные компоненты системы БД.
- Концепция БД: от файловых систем до БД.
- Назовите краткие характеристики современных СУБД.
- Понятия схемы, логический и физический уровни представления данных.
- Какие модели данных Вы знаете?
- Концепции и возможности языка SQL.
- Архитектура "клиент-сервер".
- Концепции и возможности СУБД Oracle, ACCESS.