
Постановка проблемы
| Вид материала | Задача |
- А. М. Проблемы перестройки фундаментального образования постановка проблемы, 220.23kb.
- Про повышение эффективности самостоятельного обучения студентов инженерно-педагогических, 123.26kb.
- Об особенностях проверки знаний студентов по общеинженерным дисциплинам с помощью тестов, 183.87kb.
- Общая характеристика проблемы, значимость проблемы для развития литературы, 18.24kb.
- Институциональные проблемы миниэкономики, 85.78kb.
- Ии инновационного развития высшего профессионального образования в современной России:, 192.62kb.
- Е. В. Обучение маркетингу образовательных компьютерных услуг: состояние проблемы постановка, 164.36kb.
- Материалы XIV международной конференции молодых ученых «Человек в мире. Мир в человеке:, 84.58kb.
- Реферат состоит: из трех глав, введения и заключения. Введение в котором определяется, 143.76kb.
- Задачи дискретного программирования Постановка проблемы, 14.8kb.
Применение теории многомерного семантического пространства (пространства понятий) в задачах поиска информации, перевода текстов, распознавания речи, путем использования отражения в многомерное семантическое пространство (пространства понятий).
Тактаев С.А.
mail@taktaev.com
Постановка проблемы
В настоящее время при решении задач поиска информации, перевода текстов, распознавания речи, возникает ряд проблем, связанных с распознаванием смысла, которые выражается, в частности, в невозможности адекватного распознавания полисемов, синонимов и омонимов в рамках используемых технологий.
Области поиска информации, перевода текстов, распознавания речи являются динамичными и перспективными областями.
Показательно, что в Microsoft уже несколько раз пыталась создать собственную всемирную поисковую систему, но не очень неудачно, что говорит о том, что эффективных алгоритмов поиска у них (пока) нет. Но внимание этому сектору в Microsoft уделяют очень большое. Вот слова Билла Гейтса: "Сегодня информацию очень трудно найти. Для ее хранения мы применяем тысячи разных способов. У нас есть разные пространства имен. Вы только подумайте, как много поисковых команд вы должны знать. Нам необходимо двигаться вперед по многим позициям. И я ставлю на первую строчку в этом перечне „легкость получения информации“ — именно на этом нужно сосредоточить научные разработки».
В силу молодости данного рынка, проводились только единичные исследования его объемов (Knowledge Management Software Global Industry Analysts проведенное Marketresearch в 2001 году), на рынке преобладают прогнозы. Эксперты сходятся во мнении, что это одна из самых динамичных отраслей ИТ, и в 2003 (!) году общий объем данного рынка в США составит 10-12 млрд. долл. По оценкам, доля продаж ПО в общем объеме рынка составит порядка 10%, или 1-1.2 млрд. долларов. Более того, рынок этих систем может стать одним из локомотивов роста продаж на IT рынке, считает Susan Feldman, IDC's research vice president, Content Technologies. Она же характеризует ближайшие 5 лет для этого рынка как годы "спурта", мощного рывка.
По данным Gartner, объем продаж телефонных систем распознавания голоса в 2003 г. составит $130 млн., при том что в 2002 г. этот показатель составлял $128 млн., а в 2000 г. - $140 млн. По утверждению аналитиков Gartner, это свидетельствует о созревании рынка. В частности, его рост стимулирует приход таких компаний, как Microsoft, IBM и Intel.
По данным аналитического исследования Speech Recognition Telephony Software: Worldwide 2002-2007, лидирующую позицию на мировом рынке продуктов по распознаванию голоса занимает Северная Америка – на долю этого региона приходится 61% мирового дохода в 2003 г. Доля Европы, Ближнего Востока и Африки составляет 26 %.
Самый обширный сегмент на рынке этих устройств в данный момент составляют call-центры и приложения для бизнес-порталов. Ожидается, что будет возрастать объем продаж других коммуникационных устройств.
По оценкам фирмы «ПРоМТ», Европейский рынок систем автоматизированного перевода оценивается сейчас в 8 млрд. долл. при темпах роста от 10 до 15% в год. В силу культурной специфики, наличия большого количества языков, именно в Европе сосредоточен основной рынок систем перевода. Второй по значимости рынок расположен в юго-восточной Азии, его размер составляет примерно 80% от европейского. Общий объем рынка, соответственно, составляет порядка 15 млрд. долл. Поэтому системы машинного перевода необходимы: ведь переводчиков просто не хватает. Бюджет любой крупной компании на локализацию продуктов - десятки миллионов долларов. Машинный перевод тесно связан с управлением Интернет-контентом.
Поиск информации
В настоящее время в поисковых системах используется релевантная модель оценки соответствия исследуемого документа поисковому запросу. Данная модель практически не справляется с решением задач распознавания и поиска омонимов (грамматических, и особенно- лексических), синонимов и многозначных слов. Это обусловлено тем, что в основу релевантной модели поиска положен лингвистический подход и ряд оценочных синтетических критериев (таких как положение слов на странице), а перечисленные выше языковые артефакты не могут быть распознаны без понимания смысла поискового запроса.
Данное ограничение релевантной модели уже сейчас существенно снижает эффективность поискового механизма и закрывает возможности для дальнейшего повышения качества поиска. Соответственно, для преодоления этого нужно переходить к прямой оценке смыслового соответствия (пертинентности) поискового запроса и исследуемого документа.
Перевод
В настоящее время в системах автоматизированного перевода используется сугубо лингвистическая модель выбора перевода исходного текста. Данная модель практически не справляется с решением задач перевода омонимов (грамматических, и особенно- лексических), специальных терминов (классический пример “hard disk driver” - «тяжелый дисковый водитель») и многозначных слов.
То есть, при переводе слова - омонима «ключ» на английский язык надо точно определить смысловой контекст и выбрать правильный перевод (key, wrench, spring), а при переводе полисема нужно опять же правильно определить смысловой оттенок и выбрать правильный перевод (какой ключ – дверной или гаечный?).
Это обусловлено тем, что в основе лингвистической модели лежит (что естественно) анализ слов, а одни и те же понятия могут обозначаться различными словами (синонимы), а разные понятия одинаковыми словами (омонимы, полисемы), то есть современные алгоритмы осуществляют перевод без учета смыслового (семантического) контекста.
Данное ограничение лингвистической модели уже сейчас существенно снижает эффективность переводных систем и закрывает возможности для дальнейшего повышения качества перевода. Соответственно, для преодоления этого нужно переходить к прямой оценке смыслового соответствия переводимого текста и результата перевода.
Распознавание речи
При распознавании устной речи возникают проблемы, близкие к проблемам перевода.
То есть, существуют слова, близкие по звучанию, по набору фонем. Например, «шесть» и «шерсть» в русском языке. Человек достаточно легко справляется с различением таких слов за счет понимания контекста, в котором они произнесены, тогда как существующие алгоритмы различить такие наборы звуков практически не могут. Ведь для распознавания речи нужно не только слышать ее, но еще и понимать о чем идет речь. Человек, используя смысловой контекст, восстанавливает («домысливает») нерасслышанные фонемы, в то время как существующие алгоритмы этот контекст просто не могут учитывать.
Наличие эти проблем обусловлено опять же механистическим подходом к распознаванию фонем и символов – делается попытка распознать их как дискретные элементы, не учитывая семантических, смысловых, взаимосвязей.
Для решения этих проблем предлагается использовать новый теоретический подход – координатное представление семантического пространства.
Координатная теория семантического пространства (пространства понятий)
Координатная Теория пространства понятий (семантического пространства, далее - КТПП) – раздел теории информации, целью которого является проведение математического анализа смысла понятий. Данный теоретический подход является оригинальным и разрабатывается автором с 1995 года. В настоящее время материалы теории оформляются для защиты в кандидатской диссертации.
Новаторским подходом в данной теории является интеграция и развитие существующий подходов, таких как: «семиосферы» Ю.Лотмана, формального языка БД Cyc (ссылка скрыта), и подхода Web Ontology Language (OWL), разрабатываемый под руководством Тима Бернса Ли (ссылка скрыта). Концепция координатной теории представляется более продуктивной, поскольку открывает возможности расчета семантических расстояний между понятиями, что необходимо в решении задач распознавания смысла в построении систем искусственного интеллекта. Более того, по мнению автора, именно отсутствие координатного подхода и не позволило решить до сих пор качественно задачи распознавания, связанные с учетом смыслового контекста, что является одним из основных препятствий на пути создания систем искусственного интеллекта.
В данной теории понятие - это класс объектов окружающего мира - предметов, их состояний, свойств и происходящих процессов. Предлагается провести систематизацию понятий в абстрактном многомерном пространстве - Пространстве понятий, (семантическом пространстве, далее – ПП), где каждое понятие будет соответствовать многомерной области в этом пространстве.
Определения
Понятие – область абстрактного многомерного пространства понятий (подпространство), соответствующая классу объектов в реальном мире, понятие может быть описано как набор атомарных признаков, каждый их которых представляет собой отрезок на оси координат измерения семантического пространства.
Класс (домен) – группа объектов, имеющая одинаковые признаки, значимые для причисления объекта к этому классу (для распознавания объектов как представителей класса).
Пространство понятий (семантическое пространство) – это абстрактное пространство, которое состоит из одномерных пространств, каждое из которых разбито на отрезки, содержащие в себе определенный атомарный признак (свойство, характеристику) понятия - класса. Семантическое пространство, по сути, является отражением представлений человечества о той или иной области окружающего мира.
Процесс в данной работе рассматривается как вектор абстрактной «семантической» силы, которая изменяет признаки (т.е. координаты) у предметов, т.е. перемещает объект в пространстве понятий. Аналогично понятиям и признакам, также существует и иерархическая структура классов для процессов. Процесс, который меняет только один атомарный признак, считается атомарным (базовым).
Таким образом, подойдя к описанию пространства понятий «от процессов», можно сказать, состояние предмета в наборе процессов и определяет текущее положение этого предмета- объекта в пространстве понятий и его текущую принадлежность к определенным классам.
Поскольку атомарный процесс активирует или дезактивирует один признак, то можно отождествить этот процесс с этим признаком, соотнести его с некоей функцией, то есть перейти от векторного представления к функциональному. По суперпозиции, можно разложить каждый процесс на набор атомарных процессов, а значит и функцию предмета можно представить как набор векторов атомарных процессов. Следовательно, чтобы объект обрел нужные функции, то есть обрел принадлежность к требуемым классам, то есть появился в нужной области пространства понятий, надо осуществить ряд атомарных процессов над его компонентами, суперпозиция (векторная сумма) которых и даст желаемую функцию.
Основные свойства
Многомерность семантического пространства определяется наличием у понятий множества признаков, которые и задают их положение в пространстве.
Неоднородность семантического пространства подразумевает различную насыщенность понятиями различных областей пространства, что определяется неравномерным исследованием тех или иных областей деятельности. Неоднородностью пространства объясняется наличие разрешенных и запрещенных областей.
Анизотропность семантического пространства подразумевает различную информационную протяженность его измерений и является следствием его неоднородности и подразумевает что количество значений признаков в измерениях различно.
Размерность Понятие можно представить в виде двух векторов, первый из которых является набором координат гиперплоскости, отражающей минимальные значения координат границ области этого понятия («нижней» гиперплоскости), а второй, соответственно, координатами гиперплоскости, ограничивающей максимальные значения этих же координат («верхней» гиперплоскости).
Теоретически размерность ПП стремится к бесконечности, на практике, можно считать, для каждого конкретного понятия значительная часть координат стремится к нулю. То есть, проекция конкретной многомерной области какое то измерение ничтожно мала (что означает, что данное понятие, в данном контексте, не имеет значимого смысла) . Следовательно, для расчетов и рассуждений данное измерение для данного понятия можно считать вырожденным, пустым, свернутым и координатные данные, сопоставленные с этим измерением в расчетах можно принять нулевыми. Если это измерение вырождено для целого домена, то, очевидно, эти координаты можно опустить в расчетах, указав в каком домене ведутся вычисления.
Таким образом, свернутая, (расчетная) форма представления пространства понятий, будет выглядеть так:
N = {
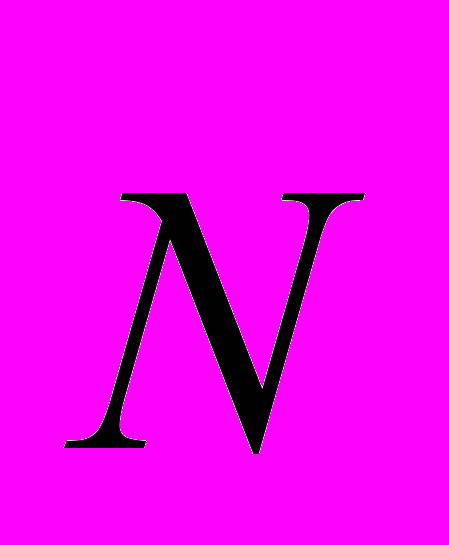 min, max}, или
min, max}, илиN= {
{x1,x2,…,xk}, {x1’,x2’,…,xk’}, илиN{{x1,x1’},{x2,x2’},…, |{xk,xk’}|}, где N – понятие, k-мерная область в n- мерном пространстве, где n – натуральное число, и k –натуральное число k
В дальнейшем, для рассуждений и расчетов, будет использоваться свернутая форма представления пространства понятий. Произведенная оценка n составляет порядка n~50 000.
Другие свойства семантического пространства:
Иерархическая структура Понятия также структурированы иерархически – каждое понятие уровня иерархии Z входит в один или несколько классов уровня Z-1, Z>0. Понятие уровня иерархии Z также включает в себя один или несколько классов уровня Z+1.
Наследование. Понятия уровня иерархии Z является подобластью (поддоменом) класса уровня Z-1, то есть наследует признаки класса уровня Z-1.
- Теорема о размерности корпусов документов Размерность любого корпуса документов не превышает размерности семантического пространства и при увеличении числа документов до бесконечности стремится к размерности семантического пространства.
- Следствие Конкретная область реального мира описывается областью семантического пространства с конечным числом измерений и, следовательно, может быть описана конечным объемом информации.
Инкрементное увеличение информации Понятия уровня иерархии Z имеет одну или несколько дополнительных координат (дополнительных признаков) по отношению к классу уровня Z-1. Именно эти признаки и позволяют отличить и сгруппировать понятия.
- теорема об инкрементности информации. Каждое понятие может быть определено как набор других понятий, плюс некая доля дополнительной информации, выраженная в действии. Понятие
 i+1 может быть представлено как i+1=i +
i+1 может быть представлено как i+1=i + 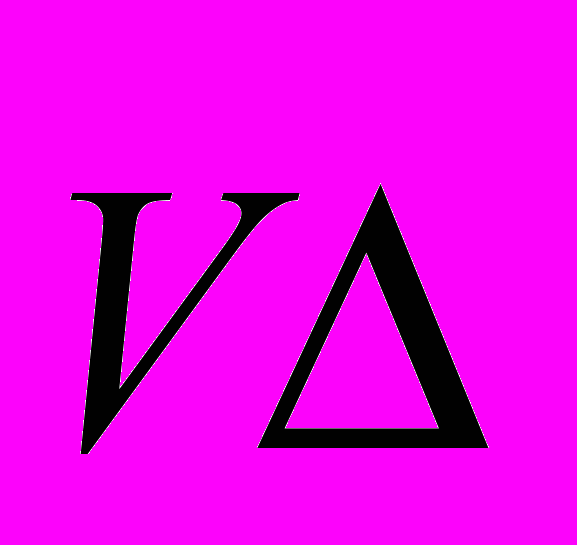 , где - дополнительная информация, создаваемая неким процессом создающим новый, дополнительный признак, причем с ростом i , |
, где - дополнительная информация, создаваемая неким процессом создающим новый, дополнительный признак, причем с ростом i , | | 0.
| 0.
- Следствие 1 – Чем больше понятий определено в заданной области пространства понятий, тем меньше требуется дополнительной ( не описанной в предыдущих понятиях) информации для определения нового (еще не определенного ) понятия в этой области.
- Следствие 2. Для каждого нового понятия требуется ввод дополнительной информации, и, если эта информация до их пор не была зафиксирована в каком то виде, то для ее ввода необходимо вмешательство человека.
Отражение в семантическое пространство
Основная идея отражения состоит в том, чтобы каждому понятию–классу окружающего мира сопоставить абсолютные координаты в пространстве понятий, сделать его положение исчислимым относительно положения других понятий. В общем случае, слова естественного языка не соответствуют однозначно понятиям-классам.
Пусть задана некая область пространства N{{x1,x1’},{x2,x2’},…, {xn,xn’}} соответствующая понятию E(entity) . Тогда отражением E N, будет
E N =
{{x1},{x2},…, {xn,}} + O{0,0,0….0), где O – точка отсчета, а - вектор создания для Е. То есть, для каждой области N можно задать свой вектор создания, по сути – вектор от точки отсчета O до области N, соответствующей E.Очевидно, вектор создания соответствует действиям (процессам), выполняемым в реальном мире, чтобы получить объект, соответствующий конкретному понятию. Вектор создания является суммой векторов действий-процессов, и отражает количество и структуру информации, переданной объекту, принадлежащему данному классу при его создании.
Процесс отражения текста, закодированного в любых кодах – языковых, музыкальных, визуальных в семантическое пространство есть процесс восстановления по входному коду исходных семантических отношений в виде понятий и процессов и может быть проведен двумя способами:
1. путем анализа уже накопленных знаний о структуре естественных языков (семантика, морфология, грамматика), а также – знаниями о связях слов и понятий естественного языка (словари, тезаурусы), однако, данный подход представляется сложным в реализации, так как семантические корни многих слов естественных языков не соответствуют их смыслу и тем понятиям, которые они обозначают.
2. путем поиска соответствий между словами языков и понятиями. Этот путь предполагает наличие исходной карты семантического пространства, в которой будут увязаны термины языка (языков) и понятия. При наличии такой карты, возможные варианты понятий могут быть просто выбраны «по карте». Однако, в силу неоднозначности исходных кодов, при процессе отражения результат нуждается в верификации путем проверки попадания результата в запрещенные или разрешенные области.
Разрешенные и запрещенные области и действия
Область семантического пространства, в которой определено понятие считается разрешенной или заполненной областью. Если провести над понятием операцию вида:
i+1=i +  j где i+1, i - произвольные области понятий, а j - произвольный вектор,
j где i+1, i - произвольные области понятий, а j - произвольный вектор, истинна, то есть после выполнения некоего действия над понятием, мы получаем определенное понятие, то данное действия с понятием является разрешенным, так как в реальном мире оно соответствует некоей реальной операции над реальным объектом, приводящей к реальному результату.
если Ложна, то данное сочетание является еще неописанным в пространстве понятий, «белым пятном» . Ложность выражения не означает неосуществимости данной операции, но дает ресурс для поиска новых решений, открытий и изобретений. Возможно, раньше никто не задумывался о возможности такой операции и такого результата. Такая область считается «запрещенной» или «пустой» областью.
Проверка на разрешенные и запрещенные области позволяет точно выяснить, является ли полученное понятие осмысленным (описанным в карте семантического пространства) или нет.
Применение КТПП для решения задач требующих распознавания смысла
Поиск информации
С точки зрения теории семантического пространства (пространства понятий), оценка информационного соответствия между одним документом (поисковым запросом) и другим (исследуемым документом) есть проекция пространства первого на пространство второго. И чем больше эта проекция, тем больше смысл исследуемого документа соответствует смыслу поискового запроса.
Перевод
С другой стороны, имея отражения различных языков в пространство понятий, можно построить прямое сопоставление между понятиями, описанными на одном естественном языке, областью, сопоставленной данному слову в пространстве понятий и слову, обозначающему такое же понятие на втором (третьем, пятом) языке.
Преимуществом такого подхода является то, что сам координатный механизм КТПП имеет встроенную защиту от ошибок, связанных с близкими по значению словами, омонимами и полисемами.
Поскольку отражение в пространство понятий происходит со всем контекстом, то сразу выясняется в какой (тематической) области пространства находятся понятия исходного текста. Расчет же точного положения производится с использованием механизма алгебры понятий, что позволяет проверить попадание понятия в разрешенную или запрещенную область, что позволяет решить проблему полисемии и омонимии еще до перевода.
А, зная, в какой области семантического пространства находится понятие, обозначаемое переводимым словом, можно сразу выбрать правильный перевод, то есть построить обратное соответствие понятий и слов целевого языка.
Это позволит получить осмысленный перевод с одного языка на другой.
Распознавание речи
Здесь, как и в задаче перевода, проблема распознавания решается отражением семантическое пространство для тех гипотез значений, которые наиболее вероятны для звучаний и написаний распознаваемых слов. Изначально рассматриваются все варианты слов, которые могут быть получены из распознанной информации. Так как отражение проводится вместе с предыдущим контекстом, то сразу можно выбрать то понятие, которое наиболее семантически близко к данному контексту и по нему ( если нужно) восстановить то слово, которое требуется распознать.
Заключение
Как видно из изложенного доклада, теоретический подход координатного представления семантического пространства является очень продуктивным и позволяет решить те проблемы, которые без него в принципе неразрешимы. Развитие данной технологии позволит существенно улучшить показатели качества работы систем поиска информации, перевода текстов, распознавания речи, то есть позволит получить достаточно быстрый (2-3 года) экономический эффект от инвестиций в данную область.
Наша исследовательская группа открыта для обсуждения всех мнений и предложений. Полная версия теории изложена на сайте ссылка скрыта .