
Разработка математического и программного обеспечения идентификации объектов в базе данных на основе нестрогого соответствия
| Вид материала | Автореферат |
- С. Ю. Шавшина научный руководитель Е. Б. Золотухина,, 26.23kb.
- Курсовая работа, 328.85kb.
- Проектный практикум, 61.84kb.
- Заярный Виктор Вильевич разработка и исследование, 473.46kb.
- Учебно-методический комплекс дисциплины разработка и стандартизация программных средств, 362.73kb.
- Обзор методов идентификации людей, 100.6kb.
- Повышение надежности программного обеспечения ядерных радиационно-опасных объектов, 223.97kb.
- Разработка моделей, методов и программного обеспечения для поддержки коммуникационно-информационной, 184.2kb.
- Комплекс средств для создания программного обеспечения процессорных модулей, реализованных, 22.6kb.
- Сложность программы (мера сложности по длина, количество функций или модулей, данных, 24.74kb.
На правах рукописи
КАРАХТАНОВ Дмитрий Сергеевич
РАЗРАБОТКА МАТЕМАТИЧЕСКОГО И ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ИДЕНТИФИКАЦИИ ОБЪЕКТОВ В БАЗЕ ДАННЫХ
НА ОСНОВЕ НЕСТРОГОГО СООТВЕТСТВИЯ
Специальность: 05.13.11 – Математическое и программное обеспечение вычислительных машин, комплексов и компьютерных сетей
АВТОРЕФЕРАТ
диссертации на соискание учёной степени
кандидата технических наук
Воронеж - 2011

Работа выполнена в АНООВПО «Университет Российской академии образования» (г.Москва)
| Научный руководитель | кандидат технических наук, доцент Беленький Владимир Михайлович |
| Официальные оппоненты: | доктор технических наук, профессор Леденева Татьяна Михайловна; кандидат технических наук, доцент Федоркова Галина Олеговна |
| Ведущая организация | ГОУВПО «Московский энергетический институт (технический университет)» |
Защита состоится 26 мая 2011 года в 1100 часов в конференц-зале на заседании диссертационного совета Д 212.037.01 ГОУВПО «Воронежский государственный технический университет» по адресу: 394026, г. Воронеж, Московский просп., 14.
С диссертацией можно ознакомиться в научно-технической библиотеке ГОУВПО «Воронежский государственный технический университет».
Автореферат разослан «26» апреля 2011 г.
| Ученый секретарь диссертационного совета | | Барабанов В.Ф. |

ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность темы. Неуклонный рост объемов данных вызывает необходимость широкого использования передовых информационных технологий для эффективного управления потоками данных. При этом наибольшую значимость приобретают задачи создания эффективных инструментов оценки и контроля растущих потоков информации, оптимизации процедур обработки, агрегации, обобщения, поиска и анализа данных. Возрастает спрос на создание как корпоративных автоматизированных информационных систем (АИС), так и отдельных специализированных решений.
Автоматизированные информационные системы разрабатываются на основе информационно-аналитических баз данных, которые используются в качестве ключевого элемента системы и обеспечивают хранение и обработку всей совокупности данных, поступающих от подразделений и филиалов. С точки зрения технологий АИС представляет набор аппаратных средств, технологий, методов и алгоритмов, направленных на поддержку жизненного цикла информации и включающих три основных процесса: обработку данных, управление информацией и управление знаниями.
Вместе с тем, существуют факторы, сдерживающие развитие АИС. Для указанных процессов в различной степени характерны проблемы управления качеством данных, в том числе связанные с наличием как в запросах, так и непосредственно в базах данных орфографических и фонетических ошибок, ошибок ввода информации, а также отсутствием единых стандартов транскрипции с иностранных языков. В настоящее время универсальной методики их решения не существует, поскольку каждая проблема имеет собственную специфику. Вследствие этого задача текстового поиска в базах данных не может быть в полной мере решена только методами проверки на точное соответствие. Становится актуальной задача разработки специальных методов и технологий поиска с использованием нетривиальных решений, в том числе с использованием операций нестрогого соответствия.
Тематика диссертационной работы соответствует научному направлению ГОУВПО «Воронежский государственный технический университет» «Вычислительные комплексы и проблемно-ориентированные системы управления».
Цель и задачи исследования. Целью работы является разработка специального математического и программного обеспечения для реализации поисковых процедур и отождествления записей в базах данных.
Для достижения поставленной цели необходимо решить следующие задачи:
провести анализ моделей, методов и алгоритмов поиска и сравнения объектов в реляционной базе данных;
разработать и исследовать алгоритмы идентификации объектов в базе данных, учитывающие наличие ошибок операторского ввода;
создать специальное программное обеспечение, реализующее работу алгоритмов идентификации объектов в базе данных;
применить разработанное программное обеспечение к задаче идентификации и отождествления объектов внешних источников данных с базой данных бюро кредитных историй.
Методы исследования. Полученные результаты исследования базируются на использовании методов и средств системного анализа, теории принятия решений, методов компьютерного анализа, математического моделирования, методов модульного и структурного программирования.
Тематика работы соответствует п. 4 «Системы управления базами данных и знаний» и п. 7 «Человеко-машинные интерфейсы…» паспорта специальности 05.13.11 – «Математическое и программное обеспечение вычислительных машин, комплексов и компьютерных сетей».
Научная новизна. В диссертации получены следующие результаты, характеризующиеся научной новизной:
предложена функция релевантности, отличающаяся применением алгоритма нестрогого соответствия и позволяющая вычислить количественную оценку похожести строк;
создан и реализован алгоритм формирования сегментированного индекса по ключу фонетической похожести, обеспечивающий сокращение предварительной выборки похожих записей и, тем самым, ускоряющий поиск по образцу;
разработан алгоритм распознавания и устранения дублирующихся записей в БД на основе автоматического выбора схемы ручной или автоматической идентификации, позволяющий сохранить информационную целостность, а также снизить зашумленность данных, обусловленную наличием ошибок операторского ввода;
разработан алгоритм поиска по атрибутам на основе функции нестрогого соответствия, алгоритма фонетической похожести, расстояния Левенштейна, обеспечивающий поиск терминов, заданных в запросе и/или их расширений.
Практическая значимость работы заключается в создании процедур и функций, а также комплекса алгоритмов поиска и сравнения записей в БД, которые позволяют:
осуществлять расширенный поиск и выдачу информации на основе функций нестрогого соответствия;
идентифицировать записи баз данных, содержащих информацию о физических и юридических лицах;
проводить быструю оценку, обобщение и агрегацию, обеспечивать возможность интеллектуального анализа;
повысить уровень информационного обеспечения подразделений предприятия за счет снижения зашумленности данных общего информационного пространства.
Реализация и внедрение результатов работы. Разработанное алгоритмическое и программное обеспечение использовано: в информационной системе ООО «Банковские информационно-аналитические системы»; в автоматизированной системе ООО «Кредитное бюро Русский Стандарт»; в информационно-аналитической системе Кредитной дирекции ЗАО «Банк Русский Стандарт», что подтверждается актами о внедрении.
Апробация работы. Теоретические и практические результаты, полученные в процессе исследования, докладывались и обсуждались на: XIII научно-практической конференции «Реинжиниринг бизнес-процессов на основе современных информационных технологий. Системы управления процессами и знаниями» (СУЗ-РБП Москва, 2010); Международной научно-технической конференции «Современные информационные технологии» (Пенза, 2010); IV Международной научно-практической конференции «Информационные технологии в образовании, науке и производстве» (Серпухов, 2010); XIII Международной конференции «Проблемы управления безопасностью сложных систем» (Москва, 2010), XVI Международной открытой научной конференции «Современные проблемы информатизации» (Воронеж, 2011).
Публикации. По теме диссертационной работы опубликовано 13 научных работ, в том числе 2 – в изданиях, рекомендованных ВАК РФ. В работах, опубликованных в соавторстве и приведенных в конце автореферата, лично соискателю принадлежат: [1,11] – математическое обеспечение для устранения дубликатов записей в базе данных на основе нестрогого соответствия; [7,9] – алгоритм идентификации объектов в базах данных; [6] – результаты сравнительного анализа алгоритмов поиска; [13] – специальное программное обеспечение поиска и устранения дубликатов в базе данных.
Структура и объем работы. Работа состоит из введения, четырех глав, заключения, одного приложения и списка литературы из 216 наименований. Основная часть работы изложена на 145 страницах, содержит 25 рисунков, 37 таблиц.
ОСНОВНОЕ СОДЕРЖАНИЕ РАБОТЫ
Во введении дано обоснование актуальности темы диссертационной работы, сформулированы цель и задачи исследования, изложены основные положения, выносимые на защиту, научная новизна и практическая значимость полученных результатов.
В первой главе рассмотрены особенности объекта исследования, проблемы, возникающие при хранении, обработке и поиске в базах данных, а также исследованы алгоритмы поиска, их особенности, достоинства и недостатки.
Наиболее распространенным видом информационных ресурсов предприятий, работающих с персональной информацией, являются тексты на естественных языках. Этим обусловлено широкое применение в таких системах технологий текстового поиска. При организации поиска персональных данных клиентов возникают характерные проблемы, связанные с наличием как в запросах, так и в базе данных орфографических и фонетических ошибок, ошибок ввода информации, а также отсутствием единых стандартов транскрипции с иностранных языков. Однако универсальной методики организации текстового поиска не существует, поскольку каждая проблема имеет собственную специфику.
Вследствие указанных причин задача поиска в базах данных не может быть в полной мере решена только методами проверки на точное соответствие. Становится актуальной задача разработки специальных методов и технологий текстового поиска с использованием нетривиальных решений, в том числе с использованием операций нестрогого соответствия.
Проведенные исследования также показали, что задача установления соответствия между отдельными объектами в настоящее время не имеет удовлетворительного решения. Таким образом, возникает задача разработки алгоритмов выполнения специальных реляционных операций, возникающих в задаче отождествления записей.
На основе проведенных в первой главе исследований алгоритмов нестрогого соответствия сделаны выводы об их применении к задачам исследования, эти выводы представлены в таблице.
Сравнение алгоритмов
| Алгоритмы | Эффективность | Скорость | Размер дискового пространства | Итог |
| Расширенной выборки | Высокая | Высокая только при размере словаря до 500 тыс. записей. | Низкий | Не подходит, в связи с низкой скоростью на словарях от 5 млн. записей. |
| N-грамм | Высокая | Средняя, линейно зависит от длины строк. Возможно увеличить с помощью хэширования и индексирования. | Высокий | Подходит |
| Деревья поиска | Низкая | Высокая | Средний | Подходит как способ индексирования. |
| Расстояние между строк | Низкая | Выше среднего | Низкий | Подходит как способ сортировки, ранжирования результатов другого алгоритма |
| Хеширование по сигнатуре | Ниже среднего | Выше среднего | Средний | Подходит |
| Последовательный перебор | Высокая только при поиске с малым количеством опечаток по большому массиву текста или при сравнении на полное соответствие | Выше среднего | Низкий | Подходит |
Вторая глава посвящена разработке процедур, которые будут положены в основу решения поставленных задач.
Процедура определения функции релевантности.
Функция релевантности реализована на основе алгоритма сравнения подстрок и определяет близость строковых значений в процентах. Аргументами функции являются две строки и параметр сравнения (N), представляющий из себя максимальную длину подстрок, участвующих в сравнении.
В качестве результата функция возвращает процент релевантности, где 0% указывает на абсолютное несовпадение строк, а 100% на тождественное равенство. Функцию релевантности от двух строк Str1 и Str2 длиной v1 и v2 соответственно и максимальной длины подстрок N определим так:
Шаг 1. Формируем наборы всех возможных подстрок длиной вплоть до N:
Gj (i) = { gj1(i), … , gjk (i), … , gjn(i) };
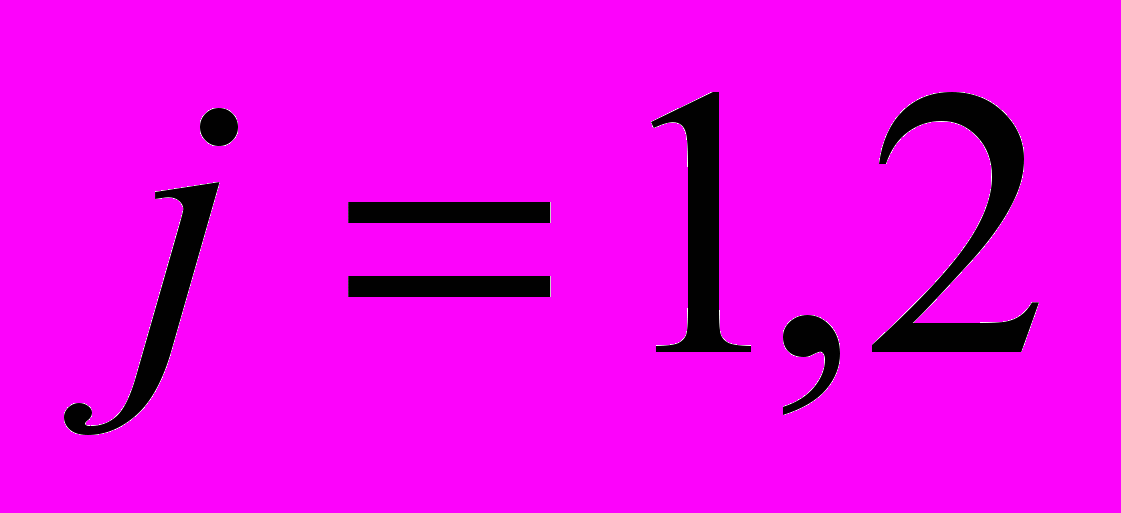 ; (1)
; (1)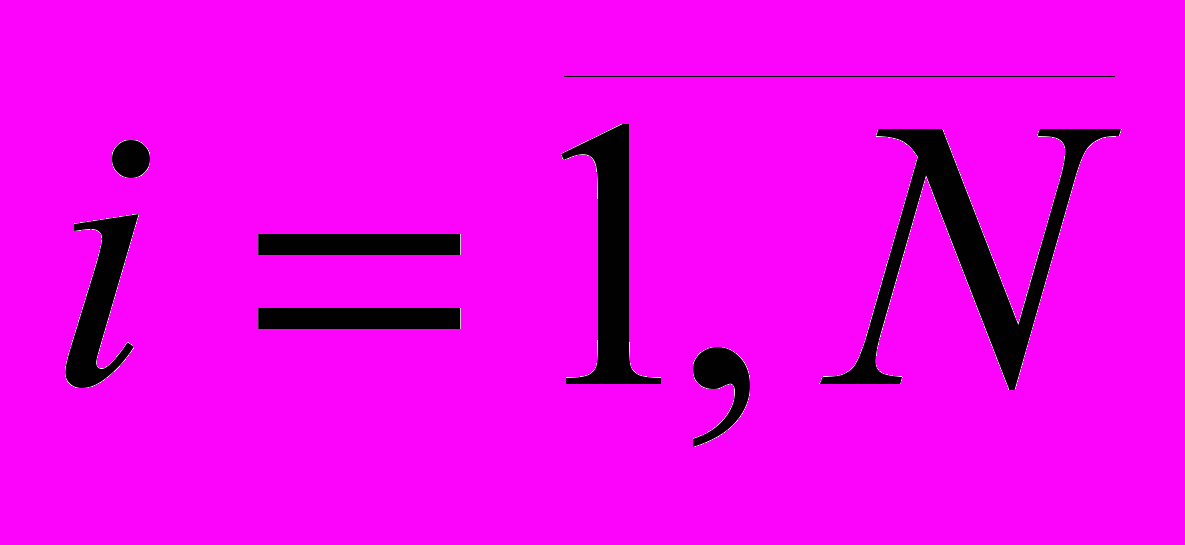 ;
;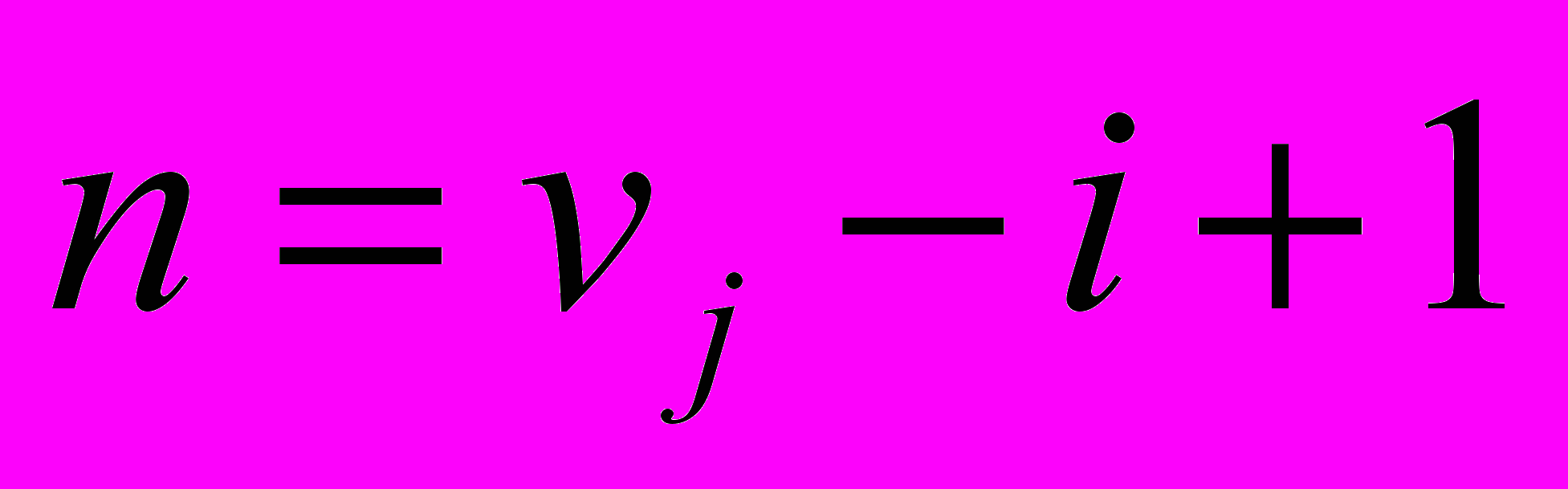
где i – длина подстроки;
j – номер входной строки;
n – количество подстрок длиной i в j-ом слове.
Шаг 2. Каждому набору Gj (i) поставим в соответствие множество G*j (i) неповторяющихся элементов набора Gj (i), то есть повторяющимся элементам набора Gj (i) во множестве G*j (i) будет соответствовать один элемент:
-

;;
(2)
;
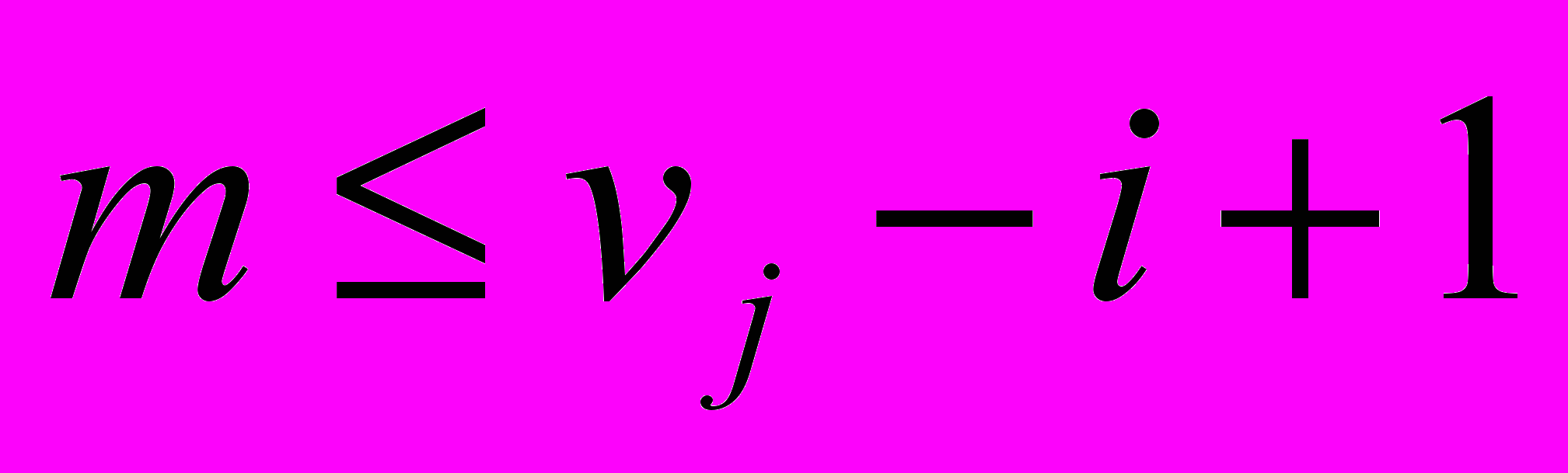
где m – количество неповторяющихся подстрок длиной i в j-ом слове.
Шаг 3. Значение функции релевантности
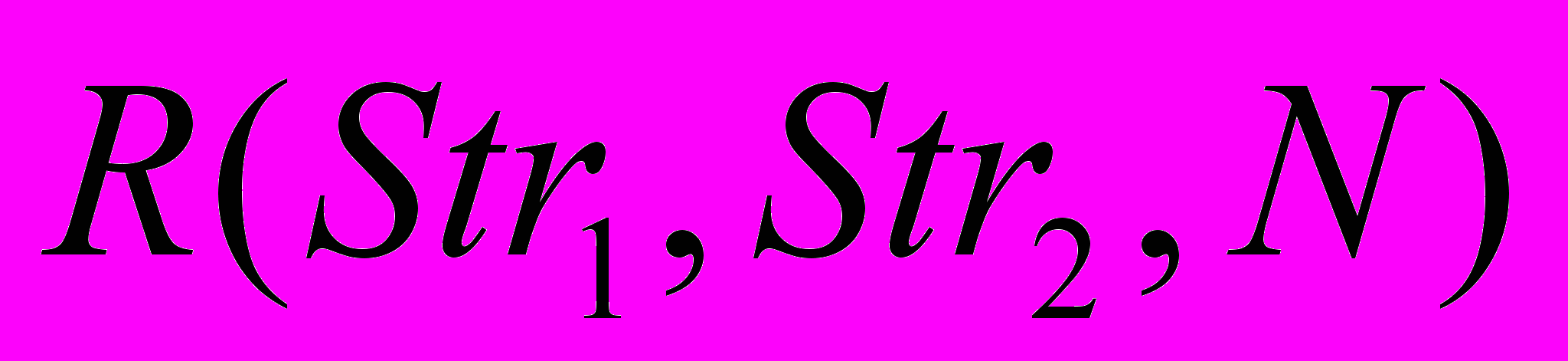 вычисляется по следующей формуле:
вычисляется по следующей формуле: | | 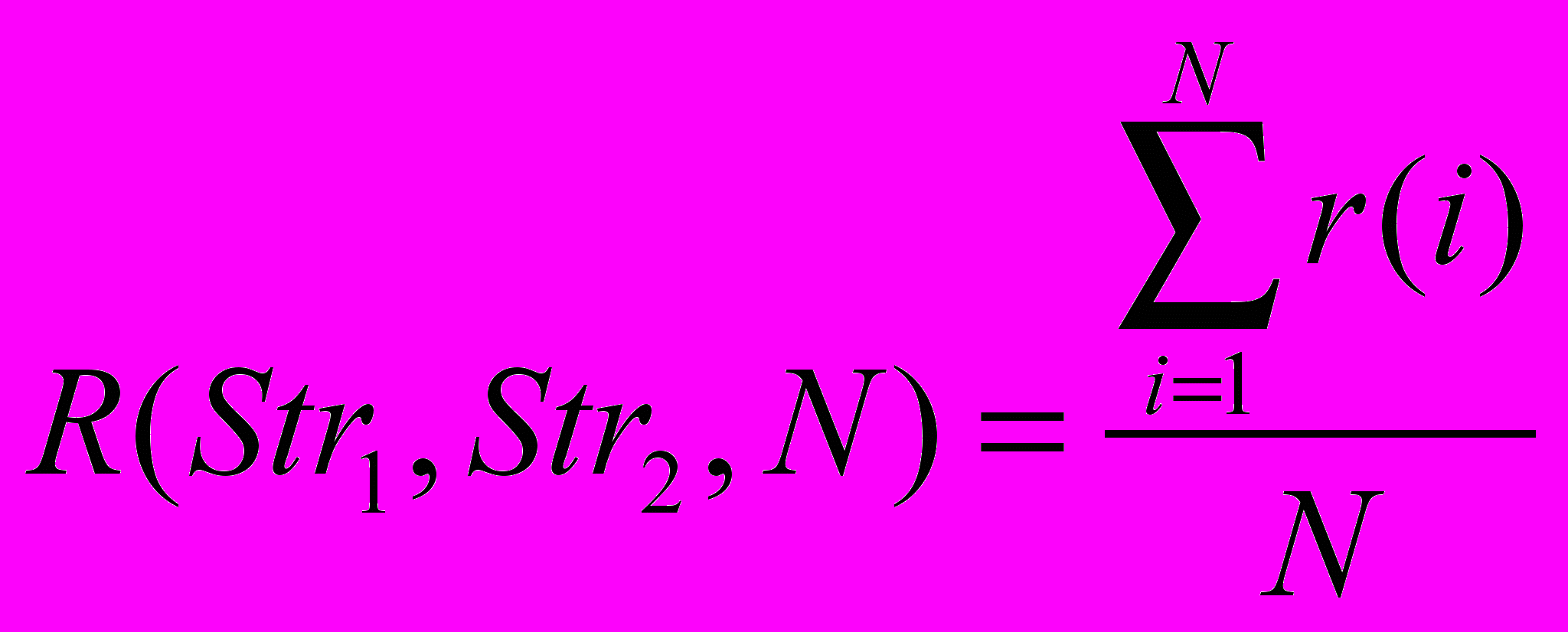 , , | (3) |
| где |  , , | (4) |
| |  , , | (5) |

элементов набора Gj (i), для которых есть равные во множестве G
 j (i).
j (i).Для определения оптимального значения N был проведен эксперимент на тестовой выборке из 8 млн. строк, на основе которого можно сделать следующие частные выводы: эффективность функции при всех N>4 дает лучшие результаты на относительно длинных строках, при N = 3 наиболее эффективна на словах длиной от 8 до 26 букв, при N= 2, от 4 до 18 букв при N= 1 до 6 букв.
Таким образом:
- На коротких строках, средняя длина которых не превышает 30 символов, наиболее эффективно использовать совокупную оценку, получаемую из оценок при работе функции при N = 1,…,4. При этом значение функции при N≥5 можно отбросить как примерно идентичное значению функции при N = 4.
- При линейном увеличении значения N от 4 субъективная оценка точности не растет при увеличении длины слова, что говорит о том, что на длинных реквизитах достаточно использования функции сравнения при N =4. Также в пользу этого решения свидетельствует тот факт, что диапазон субъективно правильных решений при N =4 начинается с длины слова равной 26, а при увеличении N эта граница повышается.
Далее процедура вычисления функции релевантности была ускорена с помощью префиксного десятичного кода. Идея заключается в следующем: перекодировать текстовые данные в цифровые с целью уменьшения объема хранения и, как следствие, увеличить скорость поиска. Для этого построен префиксный десятичный код на основе информации о частоте появления символов в базах данных. В результате тестирования прирост скорости составил 27,8%.
Процедура вычисления расстояния Левенштейна.
Пусть S1 и S2 — две строки длиной M и N соответственно, тогда расстояние Левенштейна d(S1,S2) вычисляется по формуле
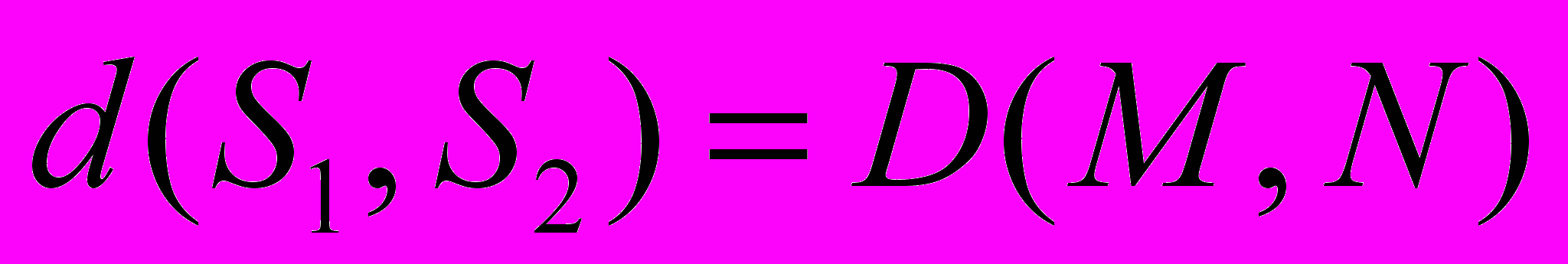 , при этом элементы:
, при этом элементы:| 0 | если i =1, j = 1, |
| i | если i >1, j = 1, |
| j | если i =1, j > 1, |
| min( D (i, j –1) + 1, D (i – 1, j) + 1, D (i –1, j–1) + m(S1[i], S2[j]) ) | если i >1, j > 1, |
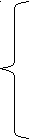
D
(6)
(i,j)=
где
| 0, если | S1[i] = S2[j], |
| | |
| 1, если | S1[i] ≠ S2[j]. |
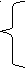
m(S1[i], S2[j])=
Процедура приближенного поиска.
Алгоритм приближенного поиска по длинным строкам на основе преобразованного известного алгоритма точного поиска «SHIFT-AND» работает так: пусть P - шаблон поиска длины n, а T - строка поиска длины m. Положим, что отыскиваются не только все вхождения P в T, но и вхождения в T всех возможных префиксов шаблона P.
Cоставим матрицу R, в которой для любой позиции анализируемого текста будет показано, является ли эта позиция концом хотя бы одной из подстрок P. Элементы матрицы R определяются следующим образом:
 1, если R[i–1, j–1] = 1 и pi = tj ,
1, если R[i–1, j–1] = 1 и pi = tj ,R[ i, j ] = (7)
0, если R[i–1, j–1] ≠ 1.
При этом полагаем R[0, j] = 1, R [i, 0] = 0 (
 ,
,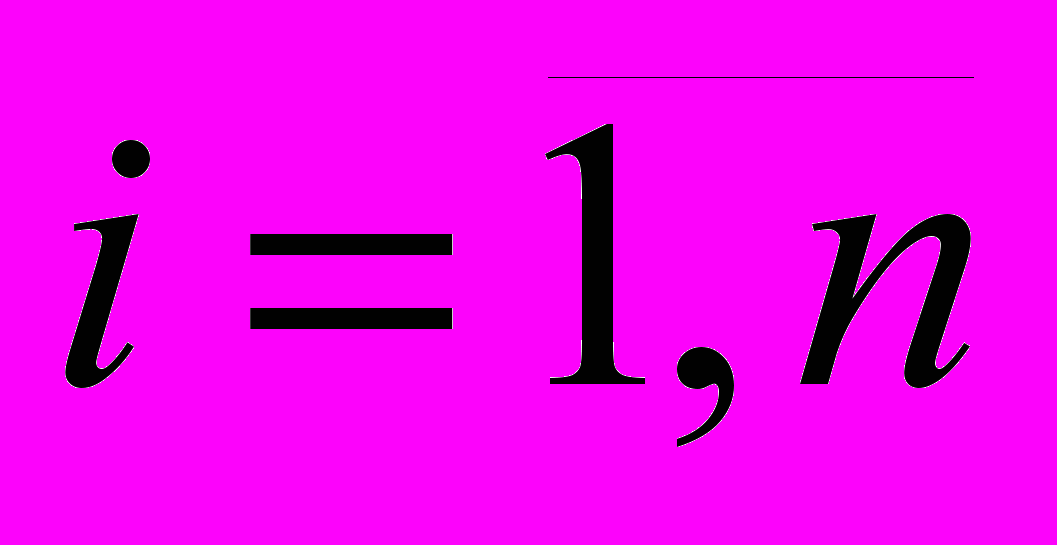 ).
).Для того чтобы найти все вхождения шаблона с одной несовпадающей буквой, необходимо построить матрицу R2 на основе R следующим образом:
Пусть R [ j ] — j-й столбец матрицы R,
RT[ j ] = ( r (1, j), … , r (k, j) , … , r (n, j) ), где n - длина шаблона поиска, тогда для формирования матрицу R2 нужно выполнить следующие действия.
1. Построить столбцы промежуточной матрицы
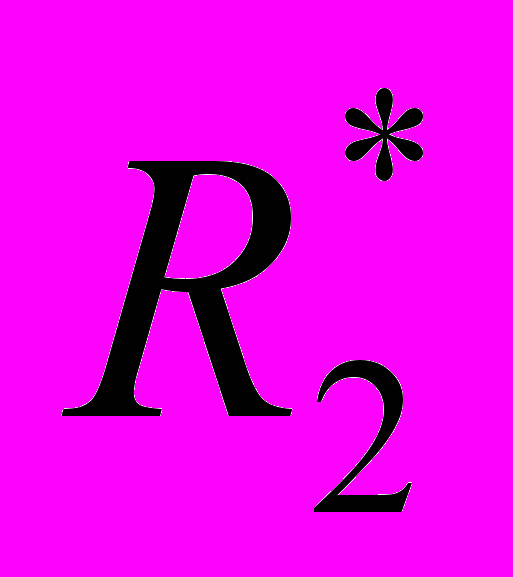 с помощью операции логического сдвига столбцов матрицы R:
с помощью операции логического сдвига столбцов матрицы R: 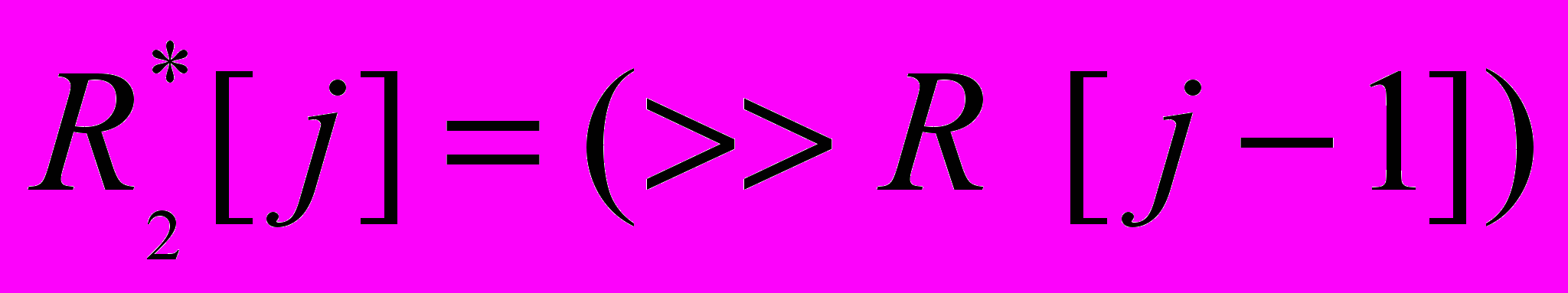 , (8)
, (8)где >> — операция логического сдвига такая, что
если
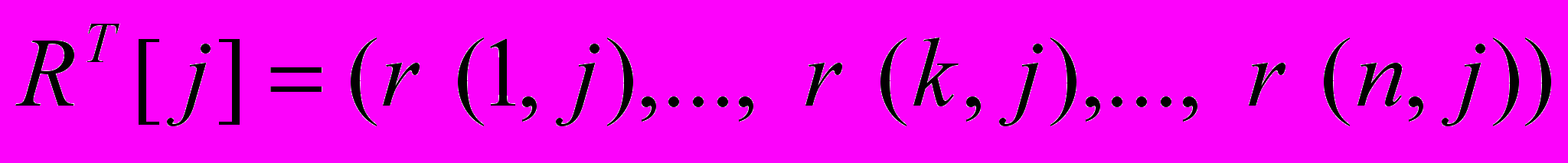 , то
, то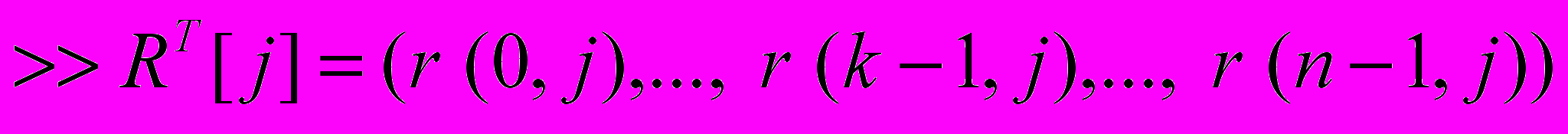 .
.2. Применить к построенной с помощью операции сдвига промежуточной матрице
формулу (7) по верхнему чтению: 1, если R2 [ i–1, j–1] = 1, pi = tj ,[ i, j ] = (9)[ i, j ], если R2 [ i–1, j–1] ≠ 1,
1, если R2 [ i–1, j–1] = 1, pi = tj ,[ i, j ] = (9)[ i, j ], если R2 [ i–1, j–1] ≠ 1,при этом полагаем R2 [0, j] = 1, R2 [i, 0] = 0 (
,).Если требуется, чтобы допускалось более одного несовпадения символов, это не составит большой проблемы. Для этого нужно ввести по одной дополнительной таблице для каждого несовпадения и проводить аналогичные преобразования одной таблицы в другую.
Процедура формирования ключа фонетической похожести.
Процедура позволяет находить один ключ для похожих фамилий. Этот ключ отличается от фонетической записи, но в целом преобразования соответствуют русской фонетике и графике:
- Гласные пишутся те, что слышатся на их месте в безударном слоге.
- Согласные оглушаются в слабой позиции.
- Исключаются подряд идущие символы.
- Типичные концовки фамилий заменяются спецсимволами и цифрами. Схожие окончания преобразуются в один спецсимвол.
- Исключаются Ъ, Ь и дефисы между частями двойных фамилий.
Для апробации предложенных процедур был проведен вычислительный эксперимент, который показал:
- Предложенный алгоритм построения функции релевантности на основании алгоритма сравнения подстрок показал хорошие результаты как по эффективности, так и по скорости поиска.
- Использование сегментированного индекса по ключу фонетической похожести сократило время поиска по фамилии на 1-2 порядка.
- Применение разработанного алгоритма приближенного поиска сделало возможным проведение поиска ключевых слов в длинных строках, без учета опечаток как в шаблоне, так и в строке поиска.
- Характерной особенностью всех полученных результатов является относительная стабильность в точности.
В третьей главе на основе разработанных процедур был построен комплекс алгоритмов для решения следующих проблем:
- устранение дубликатов,
- идентификация физических лиц,
- поиск по отдельным атрибутам с учетом опечаток.
Общий принцип алгоритма устранения дубликатов следующий:
- На вход поступает массив данных, который требуется добавить в БД, с условием исключения дублирующихся данных.
- Производится вычисление значения функции релевантности каждой строки входного массива с каждой строкой БД.
- Если значение функции:
- выше границы автоматической идентификации (Па), после которой количество распознанных дубликатов становится практически равным 100%, то соответствующая входная строка объявляются дубликатом;
- ниже границы ручной идентификации (Пр), то строки, от которых вычисляется функция, объявляются разными и анализ продолжается;
- выше Пр, но ниже Па, то такие строки отправляются в лог принятия решений для обработки аналитиком.
- Если у какой-либо строки входного массива все значения функции ниже Пр, то данная строка объявляется новой и добавляется в БД.
Алгоритм поиска и устранения дубликатов показан на рис.1.
Основой работы алгоритма идентификации физических лиц (ФЛ) является условие:
-
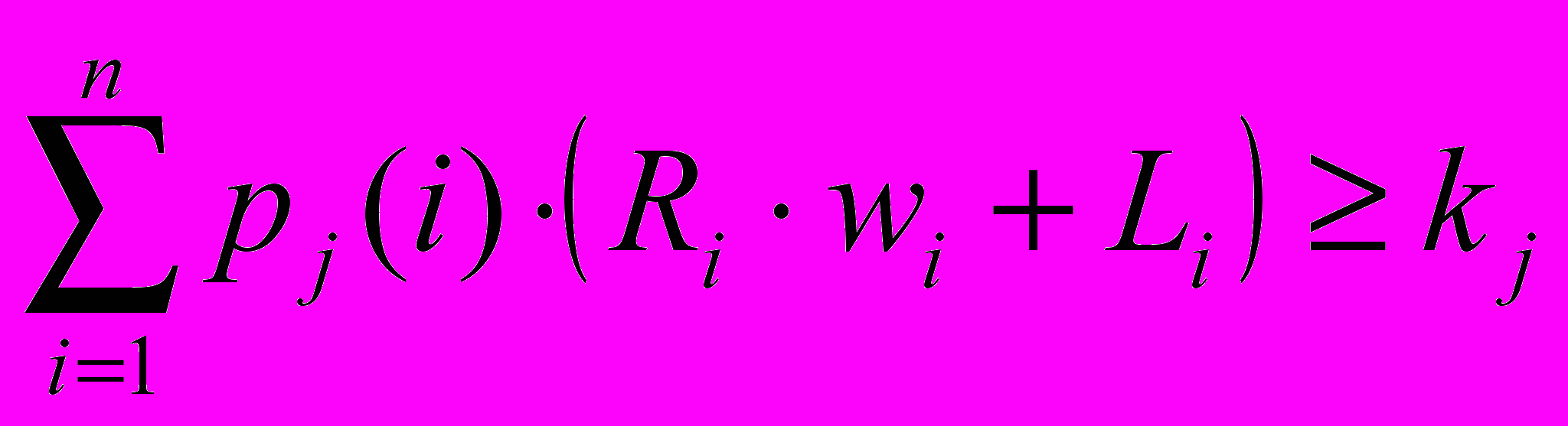 ;
;
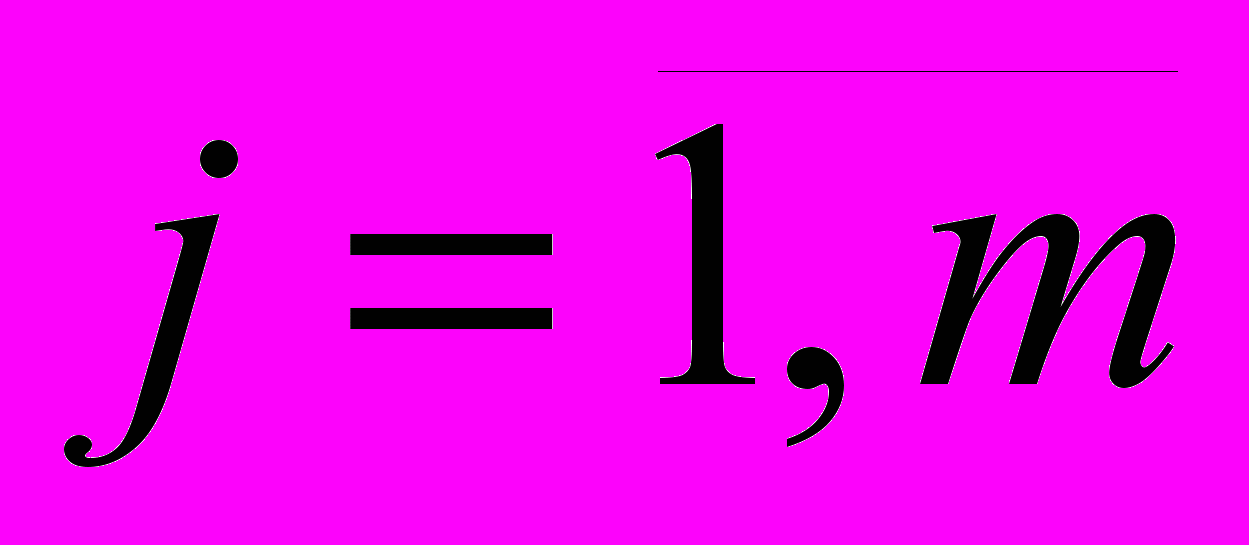 ;
;
(10)
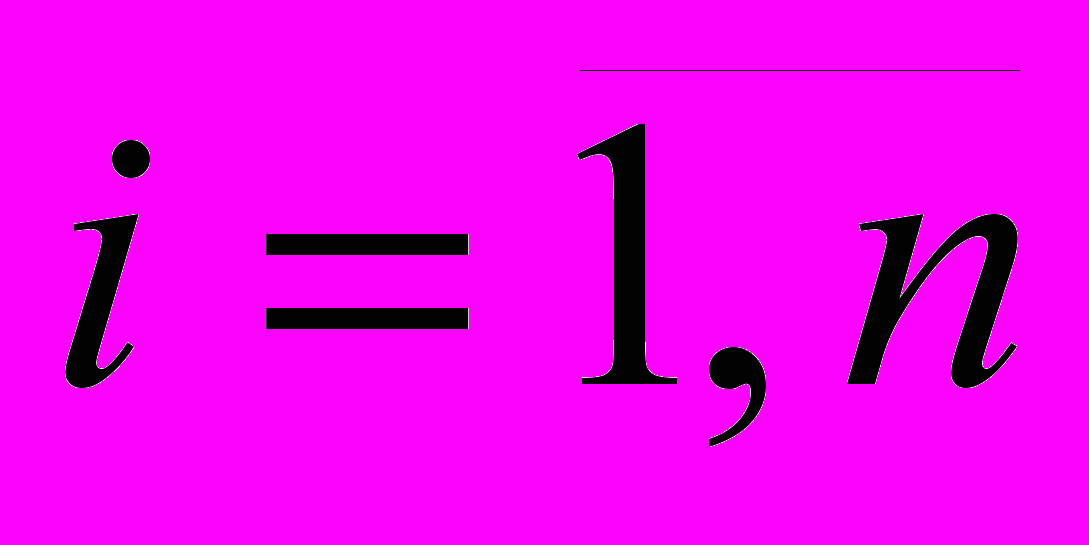 ,
,
где wi – вес реквизита. Зависит от полноты, достоверности и актуальности реквизита. Определяет значимость реквизита для идентификации ФЛ.
pj (i) – элемент правила идентификации. Правило – сочетание реквизитов ФЛ, по которым происходит сравнение. pj (i) = 1, если i–й реквизит входит в j–е правило, pj (i) = 0, если не входит.
kj – порог идентификации правила. Необходим для исключения записей, не прошедших идентификацию правилам. Если порог преодолело несколько записей, то автоматизировано идентифицировать гражданина невозможно. Такая ситуация отрабатывается оператором.
Ri – результат работы функции релевантности от i–х реквизитов.
Li –



Ф
И
повышающий коэффициент, рассчитанный на основании расстояния Левенштейна между i-ми реквизитами.
m –
Ф
И
количество правил.
n –
Ф
И
количество реквизитов, участвующих в сравнении.
При этом, если (10) верно хотя бы для одного j, то реквизиты ФЛ прошли идентификацию по правилу j и считаются похожими. Данные записи поступают на рассмотрение аналитику, в противном случае записи считаются разными и сравнение продолжается.

Рис. 1. Алгоритм поиска и устранения дубликатов
Алгоритм поиска по отдельным атрибутам с учетом опечаток работает следующим образом:
Если данные о клиенте вводятся напрямую сотрудником и включен блок расширенного поиска, то первым делом, пока вводятся остальные данные, с помощью алгоритма фонетической похожести анализируется фамилия и формируется предварительная подборка похожих фамилий клиентов уже существующих в базе данных. Далее, по мере заполнения формы информацией о клиенте эта подборка анализируется при помощи функции релевантности и урезается за счет не прошедших порог идентификации записей. После этого оператору выводится всплывающая подсказка с оставшимися в подборке записями, отсортированными в порядке убывания расстояния между вводимой и найденными фамилиями.
Если осуществляется поиск по каким-либо реквизитам и включен блок расширенного поиска, то сначала определяется, участвует ли фамилия в запросе. Если участвует, то с помощью алгоритма фонетической похожести эта фамилия преобразуется и осуществляется предварительный поиск в том модуле, куда адресован запрос. Далее результаты этого предварительного поиска анализируются с применением других строк запроса и функции релевантности, постепенно урезая результаты выборки. Если на фамилии запрос заканчивается и результаты этого запроса содержат меньше 80 строк, то результаты выдаются пользователю, также отсортированные в порядке убывания расстояния Левенштейна. Если же фамилия не участвует в запросе, то поиск сразу начинается с вычисления релевантности.
Если происходит поиск ключевых слов по текстовым полям, то используется приближенный поиск в случае включенного использования блока расширенного поиска и алгоритм «SHIFT-AND» в случае не включенного. Схема работы поиска по отдельным атрибутам представлена на рис. 2.
Таким образом:
- Разработан алгоритм отождествления объектов и устранения дублирующейся информации, который позволяет производить объединение записей в автоматическом режиме, сохранить информационную целостность, а также снизить зашумленность данных, обусловленную наличием ошибок операторского ввода.
- Разработан алгоритм идентификации физических лиц с использованием правил идентификации и функции релевантности, позволяющий оценить степень похожести персональных данных, тем самым снизив вероятность их дублирования.
- Разработана система правил и весов, являющаяся основой для принятия решения при идентификации физических лиц.
- Разработан комплекс алгоритмов поиска по атрибутам на основе функции релевантности, алгоритма фонетической похожести, расстояния Левенштейна, обеспечивающий поиск терминов, заданных в запросе и/или их расширений - терминов, имеющих схожее написание. Поиск позволяет находить трудные для написания слова, а также слова или запросы с орфографическими ошибками.

Рис. 2. Алгоритм поиска по отдельным атрибутам с учетом опечаток
Ч
 етвертая глава посвящена результатам реализации и внедрения разработанных алгоритмов и созданному на их основе программному модулю «Автоматизация поиска дубликатов в базе данных». Разработанные программные средства внедрены в автоматизированную информационную систему «Бюро кредитных историй» (АИС БКИ). С помощью АИС БКИ анкетные данные потенциального заемщика проверяются на наличие в базах данных системы. В этом процессе «Автоматизация поиска дубликатов в базе данных» используется при каждом пополнении баз данных, используемых в работе АИС БКИ.
етвертая глава посвящена результатам реализации и внедрения разработанных алгоритмов и созданному на их основе программному модулю «Автоматизация поиска дубликатов в базе данных». Разработанные программные средства внедрены в автоматизированную информационную систему «Бюро кредитных историй» (АИС БКИ). С помощью АИС БКИ анкетные данные потенциального заемщика проверяются на наличие в базах данных системы. В этом процессе «Автоматизация поиска дубликатов в базе данных» используется при каждом пополнении баз данных, используемых в работе АИС БКИ. Изначально информация поступает из коммерческих организаций – информационных партнеров, других БКИ, а также из государственных органов. Далее полученные данные проходят предварительную очистку, приводятся к нужному формату и аккумулируются в промежуточной базе данных. Следующим шагом становится пополнение основных баз с помощью разработанного программного модуля. Структура программного модуля «Автоматизация поиска дубликатов в базе данных» показана на рис. 3.
Программный модуль состоит из следующих основных блоков:
- Блок распараллеливания потоков информации. Для ускорения пополнения баз данных было решено организовать работу модуля в несколько потоков. Для этого в каждую из пополняемых таблиц было добавлено поле DATE_INSERT с типом данных TIMESTAMP(6), которое заполняется значением функции CURRENT_TIMESTAMP при вставке записей в таблицу. Далее, перед началом передачи данных в пополняемых таблицах находится дата последней вставки LAST_DATE_INSERT. После этого из таблиц-источников выбираются все записи, у которых значение поля DATE_INSERT больше, чем LAST_DATE_INSERT. Именно эти записи считаются новыми. Далее с помощь того же поля DATE_INSERT новые записи разбиваются на партиции, количество которых можно установить через интерфейс администратора в блоке управления. При этом каждая партиция становится отдельным потоком данных, передаваемым в следующие блоки модуля.
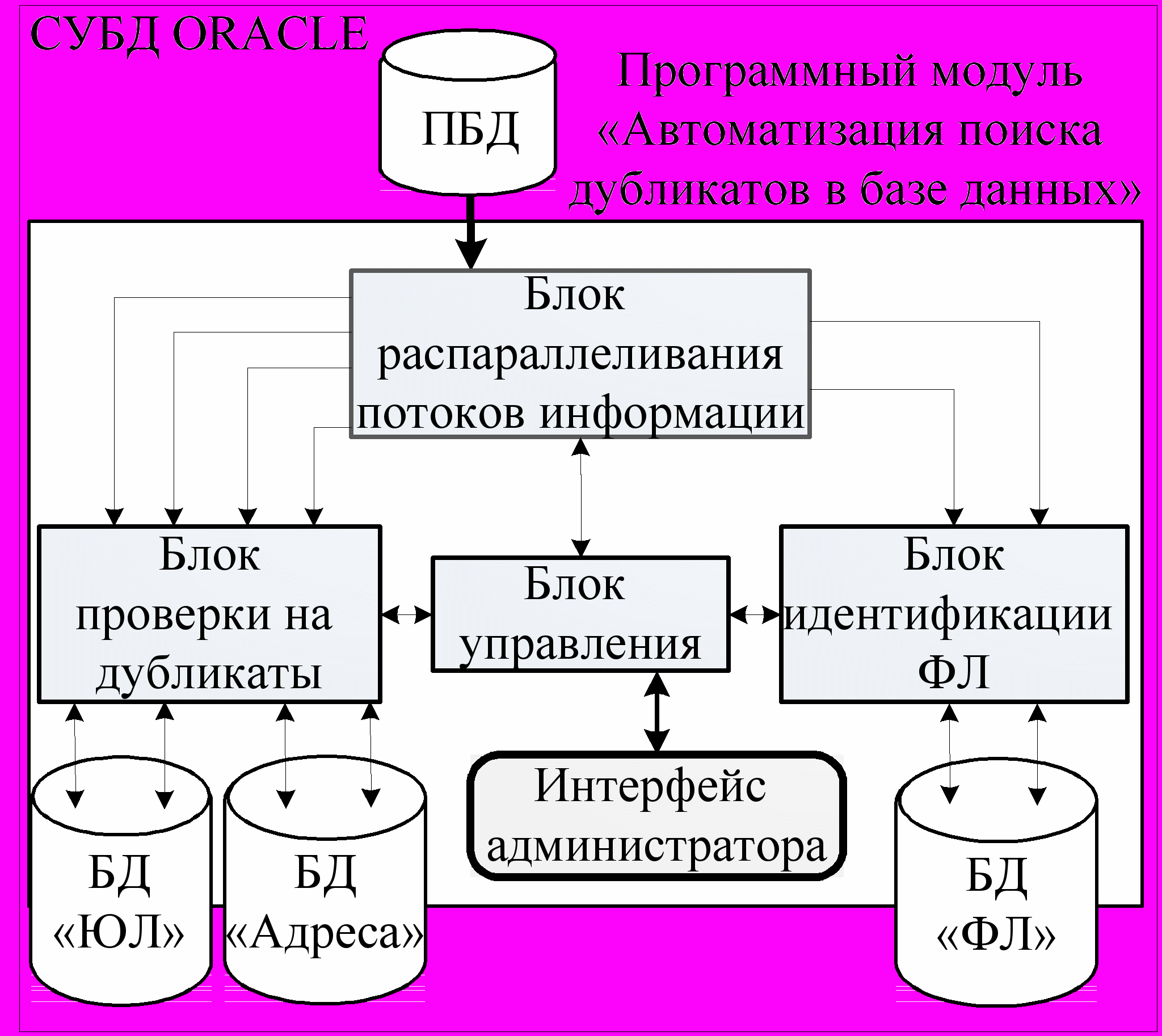
Рис. 3. Структура программного модуля
- Блок проверки на дубликаты. Блок проверки на дубликаты представляет собой пакет процедур и функций, вызываемый из блока распараллеливания столько раз, сколько потоков данных было сформировано. В итоге работы блока записи либо признаются новыми и тогда добавляются в нужную базу данных, либо признаются дубликатом и вносятся с соответствующей пометкой в лог выявленных дубликатов, либо решение о добавлении/удалении принять не удалось, и тогда данная запись попадает в лог принятия решения и хранится там до обработки аналитиком-администратором.
- Блок идентификации ФЛ. Работа блока идентификации ФЛ в целом похожа на работу блока проверки на дубликаты, за исключением различий в пополняемых базах данных.
- Блок управления. С помощью интерфейса администратора через блок управления можно в широких пределах настроить работу модуля. В блоке распараллеливания потоков информации можно настроить количество потоков, а также количество записей в потоке. Для блока идентификации ФЛ и блока проверки на дубликаты блок управления служит источником пороговых коэффициентов для работы алгоритмов идентификации, а также хранилищем логов принятия решения, лога выявленных дубликатов и общего лога работы модуля. Кроме этого блок управления содержит процедуры и функции, отвечающие за логику обработки аналитиком-администратором исключений, содержащихся в логе принятия решений.
Для оценки общей эффективности от внедрения в БКИ «Русский стандарт» было решено взять показатель нахождения ошибок кредитными инспекторами и специалистами по андерайтингу во время работы с базой данных. Сравнивались показатели за 2008 и 2009 годы, в итоге были получены данные, свидетельствующие об общей положительной тенденции снижения уровня зашумленности данных. Так, снижение показателя зашумленности данных уже в первый месяц внедрения составило 2,47 %, а пика достигло в октябре, получив значение 11,18%, то есть уменьшился почти в 3,5 раза по отношению к показателю аналогичного периода 2008 года. Средний показатель снижения зашумленности за год составил 5,3 %. (рис. 4).
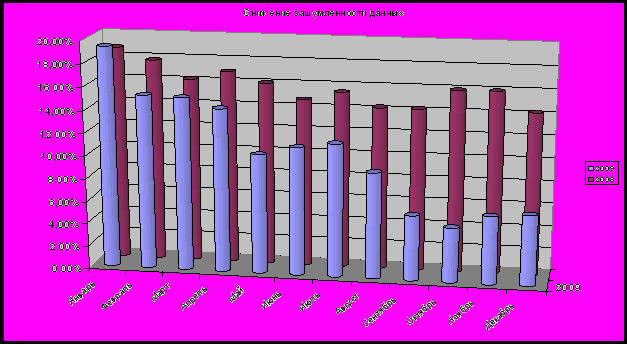
Рис. 4. Снижение зашумленности данных
В ООО «БИАС» был внедрен алгоритм устранения дубликатов, аналогичный внедренному в ООО «Кредитное бюро Русский стандарт».
Но главные результаты были получены при работе алгоритма идентификации физических лиц: количество отброшенных записей при отождествлении с использованием операции нестрогого соответствия сократилось в 13-14 раз, а количество отождествленных записей увеличилось на 35%-44% (рис. 5).
Это значительно повысило эффективность работы по проверке реестров и сэкономило много часов рабочего времени.
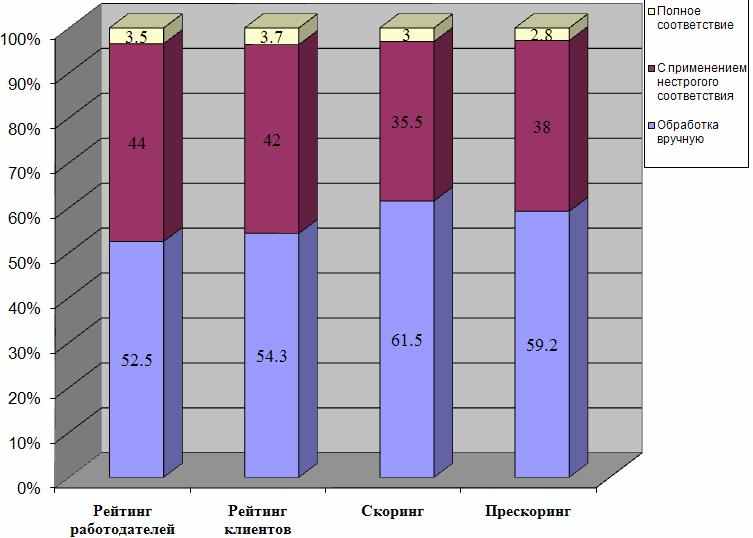
Рис. 5. Увеличение количества отождествленных записей
ОСНОВНЫЕ РЕЗУЛЬТАТЫ РАБОТЫ
Основные результаты, полученные в ходе научного исследования, заключаются в следующем:
- Разработана процедура вычисления функции релевантности записей в базах данных, отличающаяся применением алгоритма сравнения подстрок и позволяющая вычислить количественную оценку похожести строк.
- Разработан алгоритм распознавания и устранения дубликатов записей при поступлении в базу данных из множественных источников со слабоструктурированной информацией, позволяющий сохранить информационную целостность, а также снизить зашумленность данных, обусловленную наличием ошибок операторского ввода.
- Разработан алгоритм поиска по атрибутам, идентификации физических лиц с использованием правил идентификации, функции релевантности, алгоритма фонетической похожести, расстояния Левенштейна для оценки степени близости данных.
- Разработан алгоритм ускорения работы процедуры вычисления функции релевантности на основе префиксного кода, позволяющий сократить время выполнения операции вычисления релевантности в среднем на 27,8 %.
- Разработана процедура формирования ключа фонетической похожести, позволяющая сократить предварительную выборку похожих записей и тем самым на 25-30% ускорить работу поиска по фамилии.
- Проведено проектирование специального программного обеспечения компонент идентификации объектов в базах данных, обеспечивающих сокращение времени поиска и идентификации объектов в корпоративных информационных системах на 25-30%.
- Компоненты математического и программного обеспечения прошли государственную регистрацию в ФГНУ «Центр информационных технологий и систем органов исполнительной власти».
Основные результаты диссертации опубликованы
в следующих работах:
Публикации в изданиях, рекомендованных ВАК РФ
- Беленький В.М. Решение задачи поиска и устранение дубликатов в базе данных с помощью операций нестрогого соответствия / В.М. Беленький, Д.С. Карахтанов // Системы управления и информационные технологии: научно-технический журнал. 2010. №4(42). С. 70-73.
- Карахтанов Д.С. Особенности и результаты программной реализации средств автоматизации поиска дубликатов в базе данных / Д.С. Карахтанов // Системы управления и информационные технологии: научно-технический журнал. 2011. №1.1(43), - С. 144-146.
Статьи и материалы конференций
- Карахтанов Д.С. Использование алгоритмов нечеткого поиска при решении задач обработки массивов данных в интересах кредитных организаций / Д.С. Карахтанов // Аудит и финансовый анализ, 2010. №2. С.223-235.
- Карахтанов Д.С. Анализ российского рынка кредитных историй, продукты и сервисы, предоставляемые бюро кредитных историй в России / Д.С. Карахтанов // Аудит и финансовый анализ, 2010. №1. С. 130 - 147.
- Карахтанов Д.С. Решение задачи идентификации записей в базе данных с помощью операций нестрогого соответствия / Д.С. Карахтанов // Информационные технологии моделирования и управления, 2010. № 6(65). - С. 788-794.
- Беленький В.М. Анализ поисковых алгоритмов при решении задач идентификации объектов в слабоструктурированных базах данных / В.М. Беленький, Д.С. Карахтанов // Молодой ученый, 2010. Т. 1. №8(19). С. 150 - 155.
- Беленький В.М. Повышение безопасности информации при устранении дубликатов в базах данных / В.М. Беленький, Д.С. Карахтанов // Проблемы управления безопасностью сложных систем: сб. тр. Междунар. науч.-практ. конф. – М.: ИПУ РАН, 2010. С. 244-247.
- Карахтанов Д.С. Реализация алгоритма Metaphone для кириллических `фамилий средствами языка PL/SQL / Д.С. Карахтанов // Молодой ученый, 2010, Т. 1. №8(19). С. 162 - 168.
- Беленький В.М. Использование алгоритмов нечеткого поиска при решении задачи устранения дубликатов в массивах данных / В.М. Беленький, Д.С. Карахтанов // Информационные технологии в образовании, науке и производстве: сб. тр. Междунар. науч.-практ. конф.– Серпухов, 2010. Ч. 2. Вып. 4. С. 391-394.
- Карахтанов Д.С. Программная реализация алгоритма Левенштейна для устранения опечаток в записях баз данных / Д.С. Карахтанов // Молодой ученый, 2010. Т. 1. №8(19). С. 158 - 162.
- Беленький В.М. Функция нестрогого сопоставления записей баз данных в условиях наличия ошибок операторского ввода / В.М. Беленький, Д.С. Карахтанов // Современные проблемы информатизации в анализе и синтезе технологических и программно-телекоммуникационных систем: сб. тр. Воронеж: Научная книга, 2011. - Вып. 16. - С. 395-397.
- Карахтанов Д.С. Реализация фонетического алгоритма для индексирования кириллических фамилий по их звучанию / Д.С. Карахтанов // Современные проблемы информатизации в моделировании и социальных технологиях: сб. тр.. Воронеж: Научная книга, 2011. - Вып. 16. - С. 241-246.
- Беленький В.М. Программный модуль «Автоматизация поиска дубликатов в базе данных» / В.М. Беленький, Д.С. Карахтанов. - М.: ФГНУ ЦИТИС, 2010. - инв. № ВНТИЦ 50201001685 от 23.12.2010.
Подписано в печать 22.04.2011.
Формат 60x84/16. Бумага для множительных аппаратов.
Усл. печ. л. 1,0. Тираж 85 экз. Заказ № ____
ГОУВПО «Воронежский государственный технический университет»
394026 Воронеж, Московский просп., 14