
А. В. Астрахов Научно-образовательный материал «Технология информационного поиска»
| Вид материала | Документы |
- Применение методов математической оптимизации в электроэнергетике Научно-образовательный, 20.69kb.
- Московский государственный открытый университет Научно-образовательный материал, 891.3kb.
- Программа Государственного экзамена, 860.55kb.
- 1. Исследование формы напряжения, 13.91kb.
- Аннотация ном научно-образовательный материал «вм моделирование временных рядов в среде, 34.87kb.
- Инициативный проект Российского семинара по оценке методов информационного поиска (ромип), 149.92kb.
- Аннотация к научно-образовательному материалу, 44.23kb.
- Н. А. Якушева Научно-образовательный материал, 324.11kb.
- Контрольная работа по дисциплине «Современные технологии программирования», 155.32kb.
- Системы контроля и учета электроэнергии, 24.58kb.
 | Серия изданий «Научно-образовательные и научно-информационные материалы МГТУ им. Н.Э. Баумана — национального исследовательского университета техники и технологий» |
Департамент образования города Москвы
Ассоциация московских вузов
Московский государственный технический университет
имени Н.Э. Баумана

Кафедра ИУ-10
«Защита информации»
А.В. Астрахов
Научно-образовательный материал
«Технология информационного поиска»

Москва
МГТУ им. Н.Э. Баумана
2011
В настоящее время структура, объемы и динамика информационного пространства, стремительный рост количества Интернет-ресурсов и постоянное совершенствование технологий скрытия информации, обуславливают актуальность развития поисковых технологий.
Большинство пользователей сети Интернет осуществляет поиск информации с помощью сетевых информационно-поисковых систем (ИПС). Доступ пользователей к современным информационным сетям, эффективное удовлетворение их информационных потребностей возможно только с помощью развитых средств навигации в этих сетях.
Основополагающими характеристиками ИПС являются полнота и релевантность результатов поиска. Полнота поиска тесно связана с оперативностью охвата информации системой.
Информационно-поисковые системы общего назначения обладают следующими недостатками:
- ранжирование результатов поиска производится по правилам заданным разработчиками поисковой системы. В первую очередь выводятся результаты по самым популярным источникам, которые чаще всего посещаются пользователями ИПС. Также разработчики сайтов стараются повысить их рейтинг;
- структура индекса поисковой системы неизвестна пользователю. Поэтому пользователь не знает, по каким источникам производится поиск информации;
- обновление индекса поисковой системы общего назначения может занимать длительное время;
- поиск информации на локальном компьютере и в локальной сети предприятия не возможен;
- с помощью информационно-поисковых систем общего назначения невозможно производить поиск по базам данных.
Все указанные недостатки обуславливают потребность разработки собственной информационно-поисковой системы, которая будет производить поиск информации по заданному множеству документов а также будет иметь возможность подключения к базам данных.
-
Математические модели ИП
Информационный поиск (IR) – это процесс поиска в большой коллекции (хранящейся, как правило, в памяти компьютеров) некоего неструктурированного материала (обычно документа), удовлетворяющего информационным потребностям.
К информационному поиску относятся и такие задачи, как навигация пользователей по коллекции документов и фильтрация документов, а также дальнейшая обработка найденных документов.
Цель ИП — разработать систему, выполняющую поиск по произвольному запросу (ad hoc retrieval). Это самая распространенная задача информационного поиска. Цель системы - найти в коллекции документы, которые являются наиболее релевантными по отношению к произвольным информационным потребностям, сообщаемых системе при помощи однократных, инициированных пользователем запросов. Информационная потребность (information need) — это тема, о которой пользователь хочет знать больше. Ее следует отличать от запроса, т.е. от того, что пользователь вводит в компьютер, пытаясь выразить свою информационную потребность. Документ называется релевантным (relevant), если, с точки зрения пользователя, он содержит ценную информацию, удовлетворяющую его информационную потребность.
В последние годы основным двигателем прогресса является веб, открывший возможность публиковать информацию десяткам миллионов пользователей. Это множество публикаций осталась бы недоступным, если бы информацию было невозможно найти, сопроводить аннотацией и проанализировать так, чтобы каждый пользователь мог быстро найти необходимые ему релевантные и исчерпывающие сведения.
В основу традиционных методов положены три главных подхода, первый из которых базируется на теории множеств (булева модель), второй – на векторной алгебре (векторно-пространственная модель), а третий на теории вероятностей (вероятностная модель). Эти подходы могут применяться на практике и в каноническом виде, однако у них есть общий недостаток, обусловленный предположением, что содержание документа определяется множеством слов и устойчивых словосочетаний – термов (англ. - Terms), которые входят в него без учета взаимосвязей, как «мешок со словами» (от англ. Bag of Words), и, более того, считаются независимыми. Конечно же, такое предположение ведет к потере содержательных оттенков, тем не менее оно позволяет реализовать поиск и группирование документов по формальным признакам.
Пусть
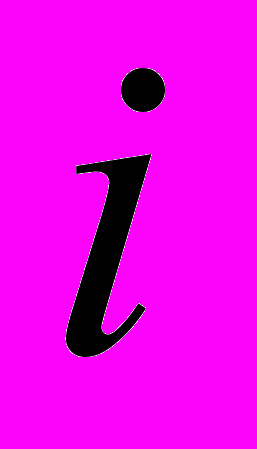 – индекс терма
– индекс терма 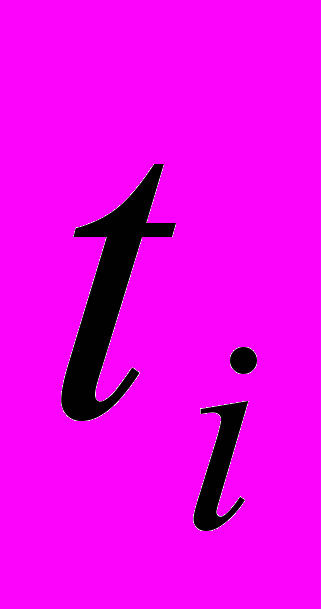 из словаря
из словаря 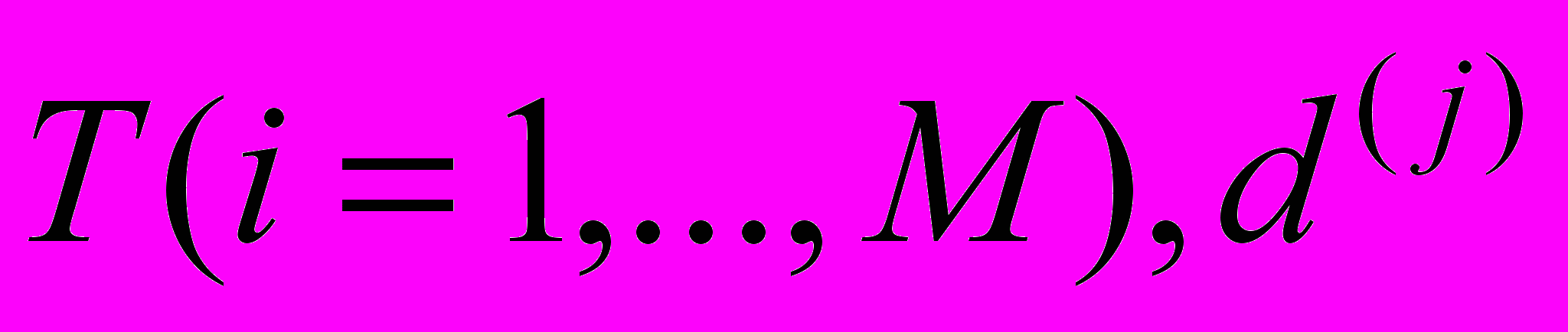 – документ принадлежащий множеству документов
– документ принадлежащий множеству документов 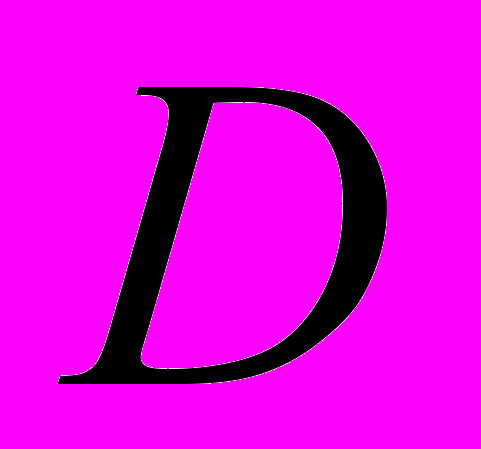 , a
, a 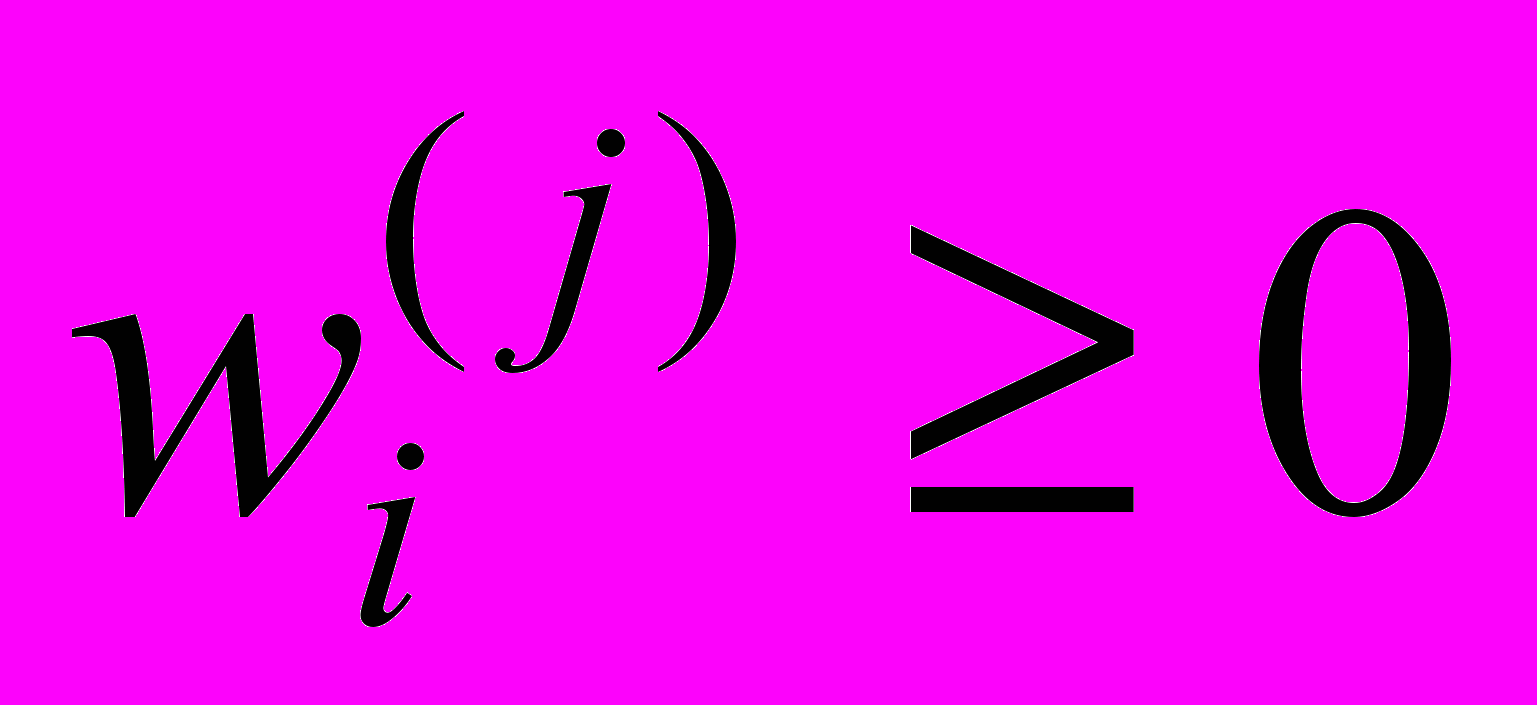 – вес, ассоциированный с парой
– вес, ассоциированный с парой 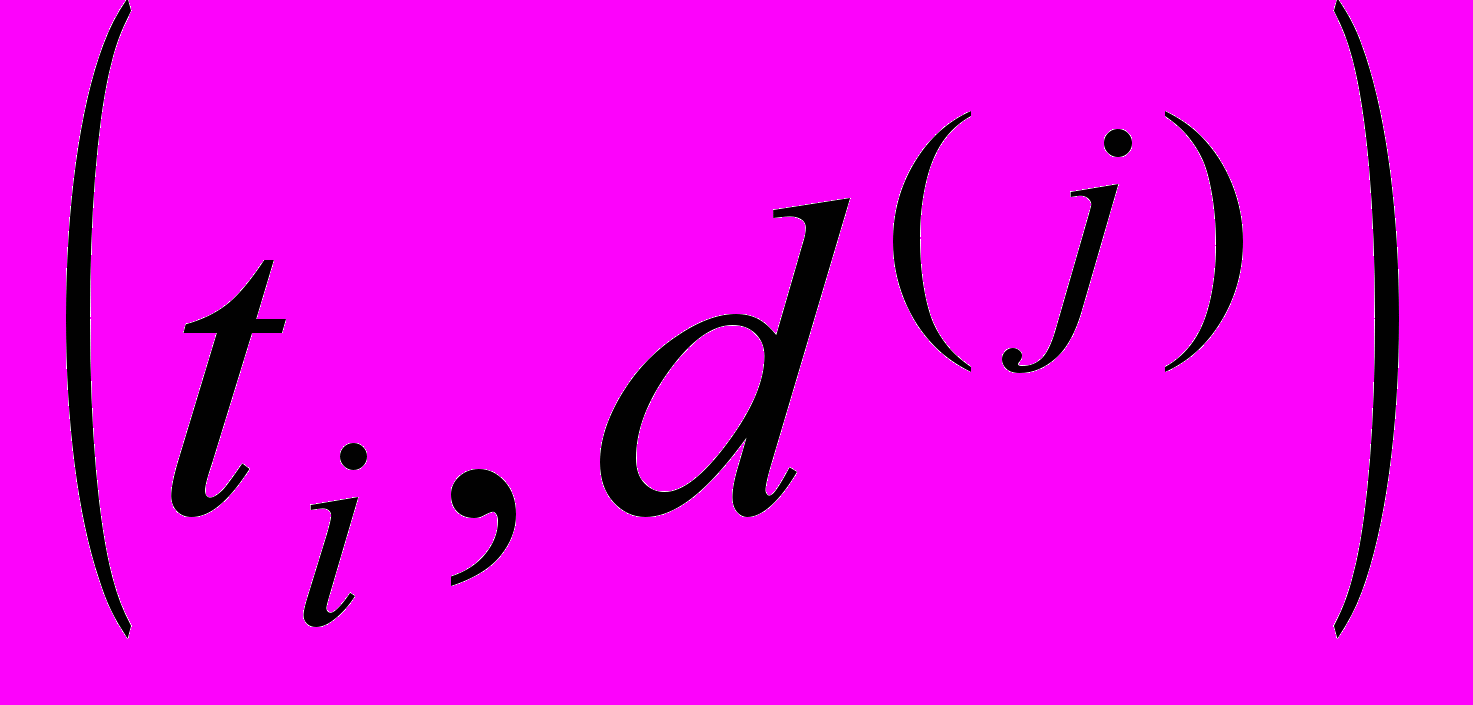 .
.Для каждого терма
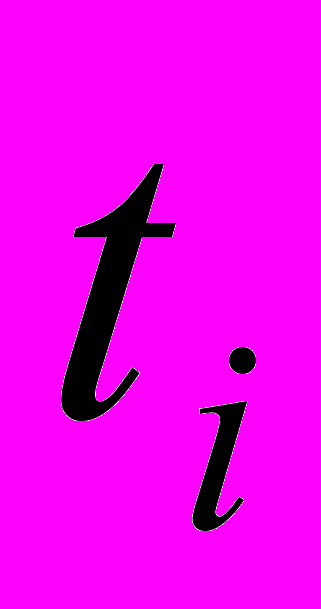 , который не входит в документ
, который не входит в документ 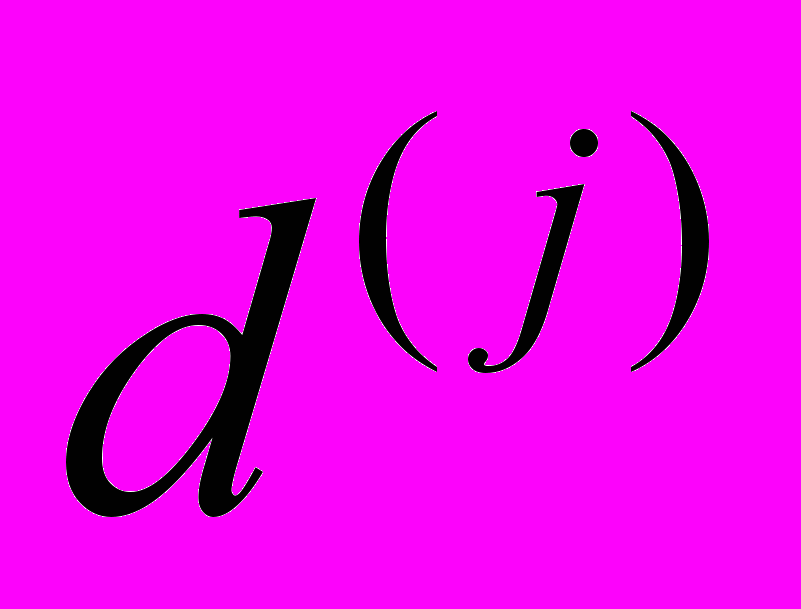 , его вес равен нулю:
, его вес равен нулю: 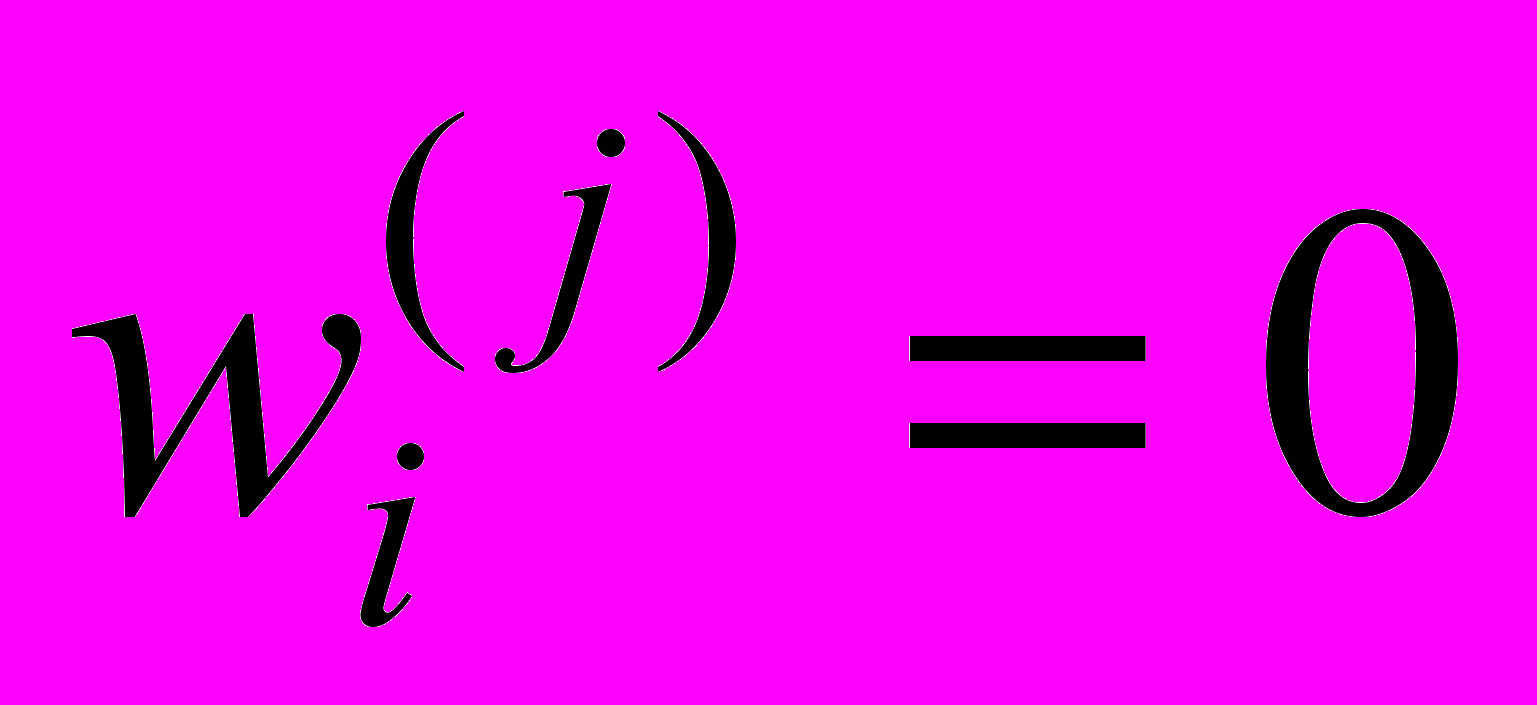 . Документ будем рассматривать как вектор
. Документ будем рассматривать как вектор 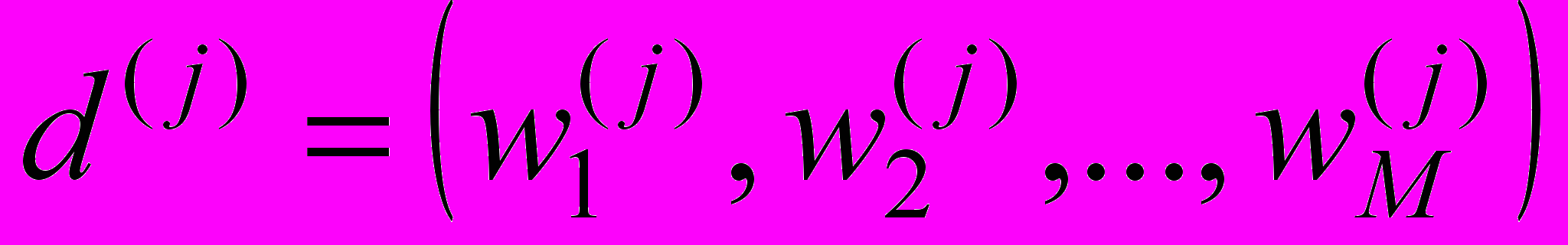 .
.Введем также в рассмотрение инверсную функцию
 , соответствующую индексу терма , которая определяется следующим образом:
, соответствующую индексу терма , которая определяется следующим образом: 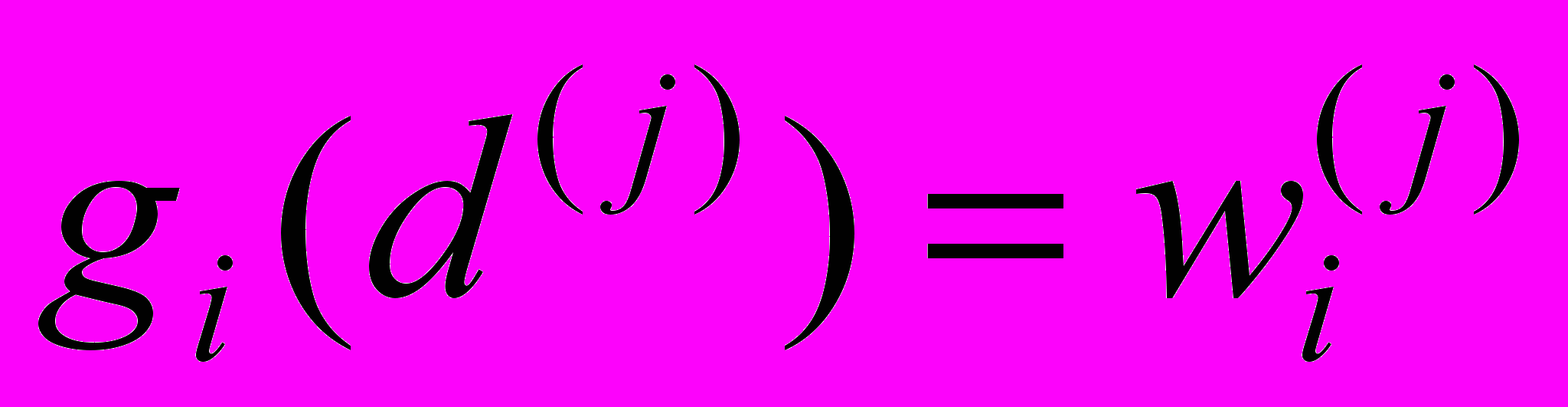 .
.Булев поиск
Модель булева поиска — это модель информационного поиска, в ходе которого можно обрабатывать любой запрос, имеющий вид булева выражения, т.е. выражения, в котором термы используются в сочетании с операциями AND, OR и NOT. В рамках этой модели документ рассматривается просто как множество слов.
Булева модель базируется на теории множеств и математической логике. Популярность этой модели связана, прежде всего, с простотой ее реализации, которая позволяет индексировать и выполнять поиск в больших документальных массивах.
В рамках булевой модели документы и запросы представляются в виде множества термов – ключевых слов и устойчивых словосочетаний. Каждый терм представлен как булева переменная: 0 (терм из запроса не присутствует в документе) или 1 (терм из запроса присутствует в документе). При этом весовые значения терма в документе принимает лишь два значения:
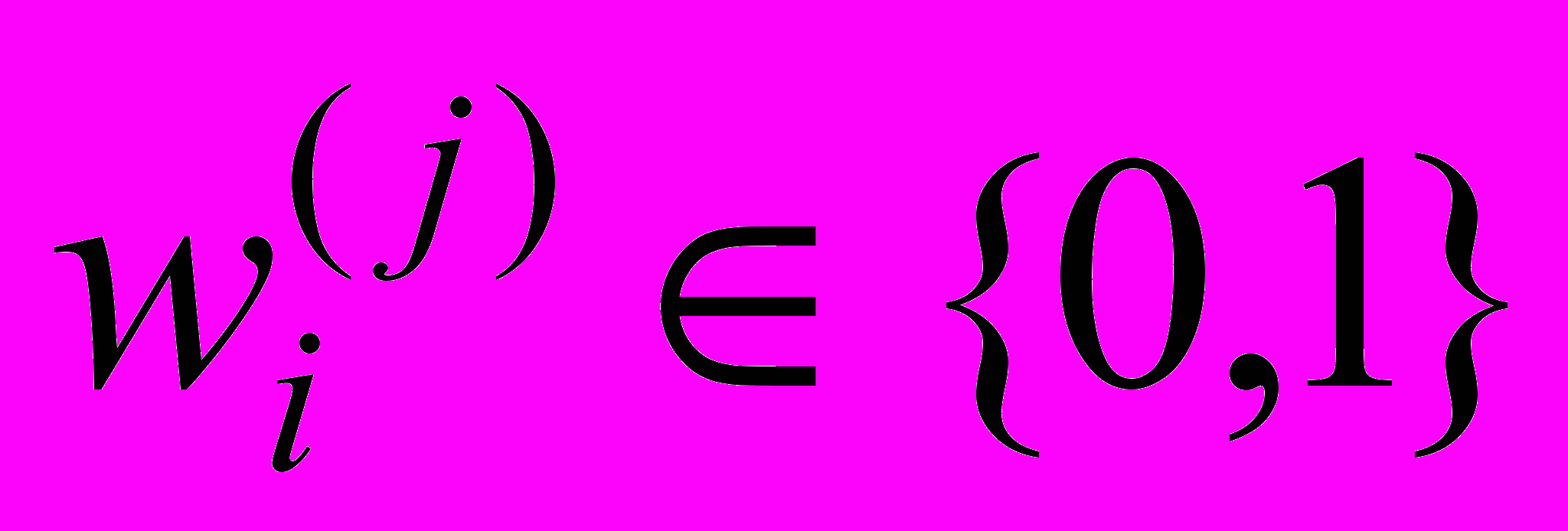
В булевой модели запрос пользователя представляет собой логическое выражение, в котором термы связываются логическими операторами конъюнкции
 (AND, ˄) дизъюнкции (OR, ˅) и отрицания (NOT, ¬). Известно, что любое логическое выражение можно представить дизъюнкцией некоторых выражений, соединенных между собой операцией конъюнкции (дизъюнктивной нормальной формой, ДНФ - dnf).
(AND, ˄) дизъюнкции (OR, ˅) и отрицания (NOT, ¬). Известно, что любое логическое выражение можно представить дизъюнкцией некоторых выражений, соединенных между собой операцией конъюнкции (дизъюнктивной нормальной формой, ДНФ - dnf).Поиск по слову в базе данных системы такой архитектуры осуществляется в соответствии с алгоритмом:
1. Происходит обращение к словарной таблице, по которой определяется, входит ли слово в состав словаря базы данных, и если входит, то определяется ссылка в инверсной таблице на цепочку появлений этого слова в документах.
2. Происходит обращение к инверсной таблице, по которой определяются номера документов, содержащих данное слово, и координаты всех вхождений слова в текстах базы данных.
3. По номеру документа происходит обращение к записи таблицы указателей текстов. Каждая запись этого файла соответствует одному документу в базе данных.
4. По номеру документа происходит прямое обращение к фрагменту текстовой таблицы – документу, после чего следует вывод найденного документа.
Приведенный алгоритм охватывает случай, когда запрос состоит из одного слова. Если же в запрос входит не одно слово, а некоторая их комбинация, то в результате выполнения поиска по каждому из этих слов запроса формируется массив записей, которые соответствуют вхождению этого слова в базу данных. После окончания формирования массивов результатов поиска происходит выявление релевантных документов путем выполнения теоретико-множественных операций над записями этих массивов в соответствии с правилами булевой логики.
Достоинства и недостатки булевой модели.
Основным достоинством булевой модели является простота ее реализации. Главными недостатками модели являются:
- Отсутствие возможности ранжирования найденных документов по степени релевантности, поскольку отсутствуют критерии ее оценки
- Сложность использования – не каждый пользователь может свободно оперировать булевскими операторами при формулировке своих запросов.
Векторный поиск
Альтернативой модели булева поиска являются модели поиска с ранжированием (ranked retrieval models), например модель векторного пространства, в рамках которых пользователи в основном применяют свободные текстовые запросы (free text queries), т.е. набирают одно или несколько слов, а не используют строгие языковые конструкции с операторами; система же сама решает, какие документы лучше других удовлетворяют этим запросам.
При работе с большими коллекциями документов итоговое количество документов, соответствующих запросу, может быть таким большим, что человек просто не в состоянии просмотреть их все. Соответственно, одной из важных задач поисковых машин является ранжирование документов по степени их соответствия запросу. Для решения этой задачи поисковые машины для каждого найденного документа вычисляют его степень соответствия заданному запросу, т.е. (вычисленная) релевантность (score).
В векторной модели поиска каждому терму, обнаруженному в документе присваивается вес, зависящий от количества появлений этого терма в данном документе. Мы хотим оценить соответствие между термом запроса t и документом d, основываясь на весе терма t в документе d. Проще всего положить этот вес равным количеству вхождений терма t в документ d. Эта схема взвешивания называется частотой терма (term frequency) и обозначается как tft,d, где индекс t обозначает терм, а индекс d – документ.
Для документа d набор весов tf (или определенных с помощью любой другой весовой функции, которая ставит в соответствие количеству появлений терма t в документе d некое положительное действительное число) можно интерпретировать как дайджест документа, выраженный в числовом виде. Эта модель в научной литературе называется мешком слов (bag of words model). В рамках этой модели точный порядок следования термов в документе игнорируется, а основное значение придается количеству вхождений каждого терма в документ (в противоположность булеву поиску).
Такой подсчет частоты терма имеет серьезный недостаток: при ранжировании документа по запросу все термы считаются одинаково важными. На самом деле некоторые термы имеют малую или нулевую различительную силу при определении релевантности. Например, коллекция документов об автомобильной промышленности, скорее всего, содержит терм "авто" практически в каждом документе. Для того чтобы устранить указанный недостаток, мы введем механизм ослабления влияния терма, который встречается в коллекции слишком часто, чтобы его имело смысл учитывать при определении релевантности документов. На ум сразу же приходит идея снизить веса у термов с высокой частотой в коллекции (collection frequency), представляющей собой общее количество вхождений терма в коллекцию. Идея состоит в том, чтобы уменьшить вес терма tf на коэффициент, который увеличивается по мере увеличения его частоты в коллекции.
Вместо этого чаще встречается использование документной частоты df, (document frequency), представляющей собой количество документов в коллекции, содержащих терм t. Это объясняется тем, что, пытаясь найти различия между документами с целью их ранжирования по запросу, лучше использовать статистические показатели именно самих документов (например, количество документов, содержащих заданный терм), чем статистические показатели коллекции в целом.
Достоинства и недостатки векторной модели поиска.
Векторно-пространственная модель представления данных обеспечивает системам, построенным на ее основе такие возможности как:
- Обработку запросов неограниченной длины
- Простоту реализации режима поиска подобных документов
- Сохранение результатов поиска с возможностью выполнения уточняющего запроса
Основным недостатком этой модели является расчет массивов высокой размерности.
Вероятностная модель поиска
В данной модели поиска вероятность того, что документ релевантен запросу основывается на предположении, что термы запроса по-разному распределены среди релевантных и нерелевантных документов. При этом используются формулы расчета вероятности, базирующиеся на теореме Байеса.
Основной вопрос, который решается с помощью модели: как велика вероятность того, что документ d релевантен запросу q. Релевантность при этом рассматривается как вероятность того, что данный документ может оказаться интересным пользователю. Функционирование модели базируется как на экспертных оценках, получаемых в результате обучения модели, которые признают документы из учебной коллекции релевантными/нерелевантными, так и на последующих оценках вероятности того, что документ является релевантным запросу исходя из состава его термов.
Если для запроса известны эти оценки вероятностей для всех документов, то документы можно сортировать по ним и выводить пользователям в нисходящем порядке. То есть вероятностная модель поиска предусматривает определение вероятностей соответствия запросу для документов, сортировку и предоставление документов с ненулевой вероятностью пользователю.
С самого начала в вероятностной модели использовалось упрощение, которое допускает независимость вхождения в документ любой пары термов (поэтому такой подход называется «наивным» байесовским).
При этом в вероятностной модели поиска предполагается наличие учебных наборов релевантных и нерелевантных документов, выбранных пользователем или полученных автоматически при каком-то начальном предположении. Вероятность того, что поступивший документ является релевантным, рассчитывается на основании соотношения появления термов в релевантном и нерелевантном массиве документов.
В случае применения экспертных оценок процесс поиска является итерационным (в реальных системах, использующих элементы вероятностой модели, как экспертные оценки могут рассматриваться, например, предпочтения пользователей при выборе интересующих их документов). На каждом шаге итерации, благодаря режиму обратной связи, определяется множество документов, отмеченных пользователем как удовлетворяющих его информационным потребностям.
Рассмотрим основу модели, а именно байесовский подход, более детально. Пусть X, Y – два независимых события,
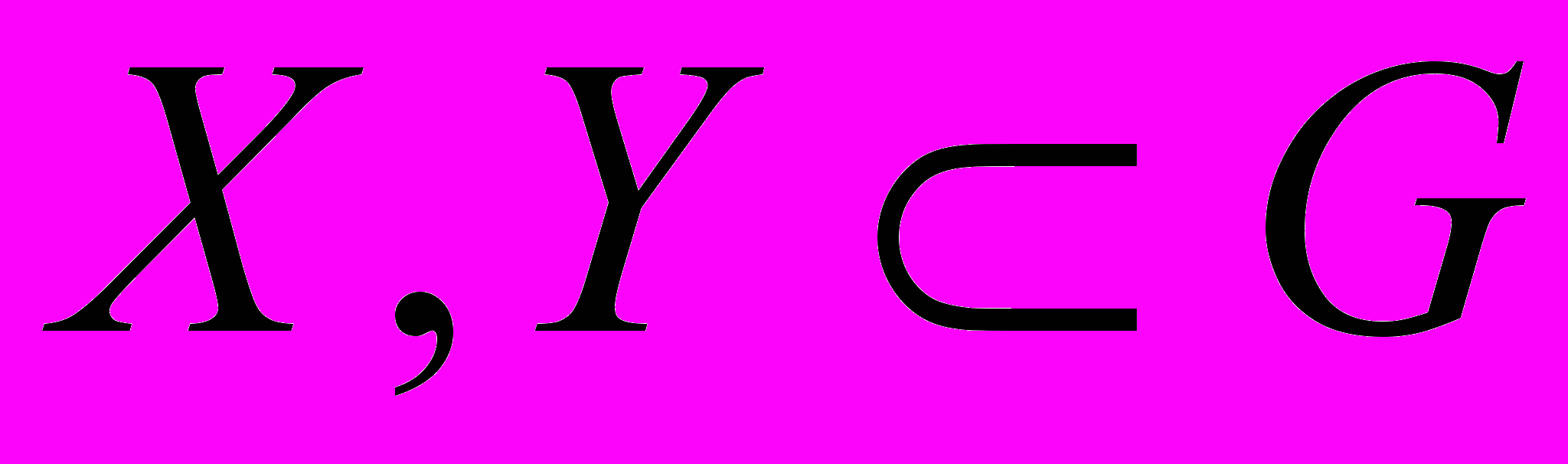 , G базовое вероятностное пространство.
, G базовое вероятностное пространство.Вероятность X при условии Y определяется таким образом:
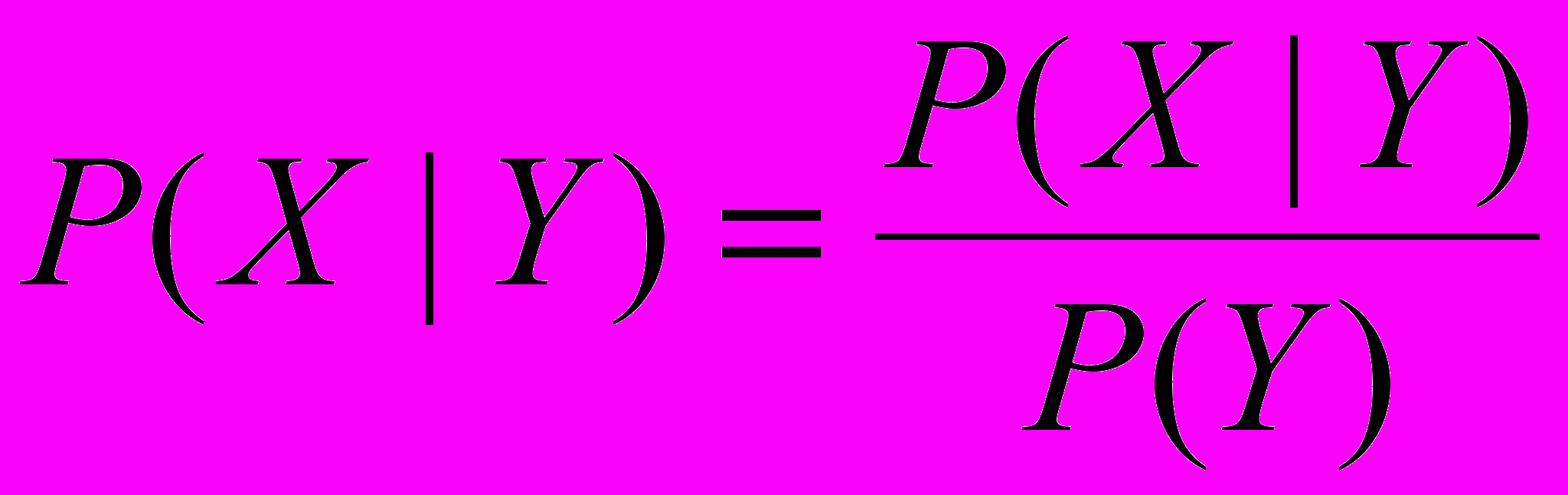 (1.9)
(1.9)Известно, что из этого соотношения следует формула Байеса:
; 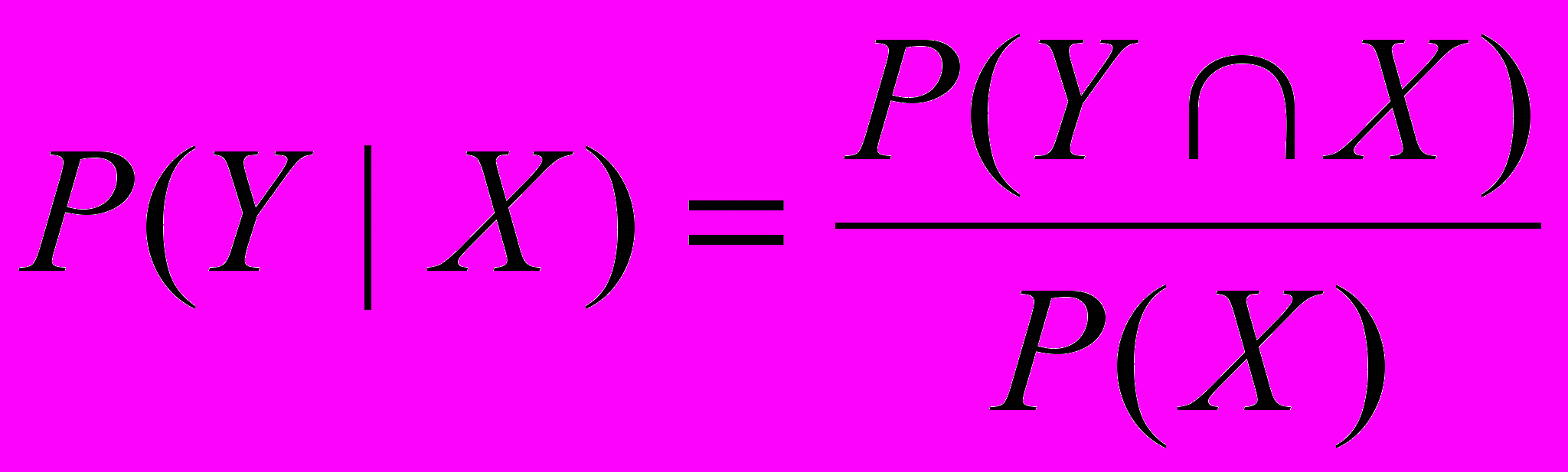 ; (1.10)
; (1.10)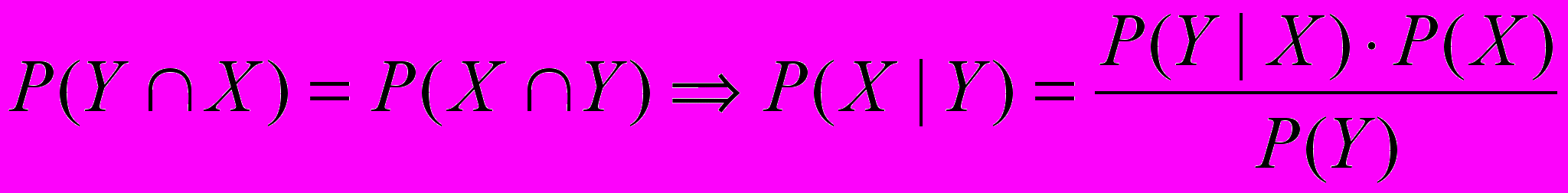 (1.11)
(1.11)Рассмотрим условные вероятности двух событий, а именно того, что документ релевантен (R) запросу -
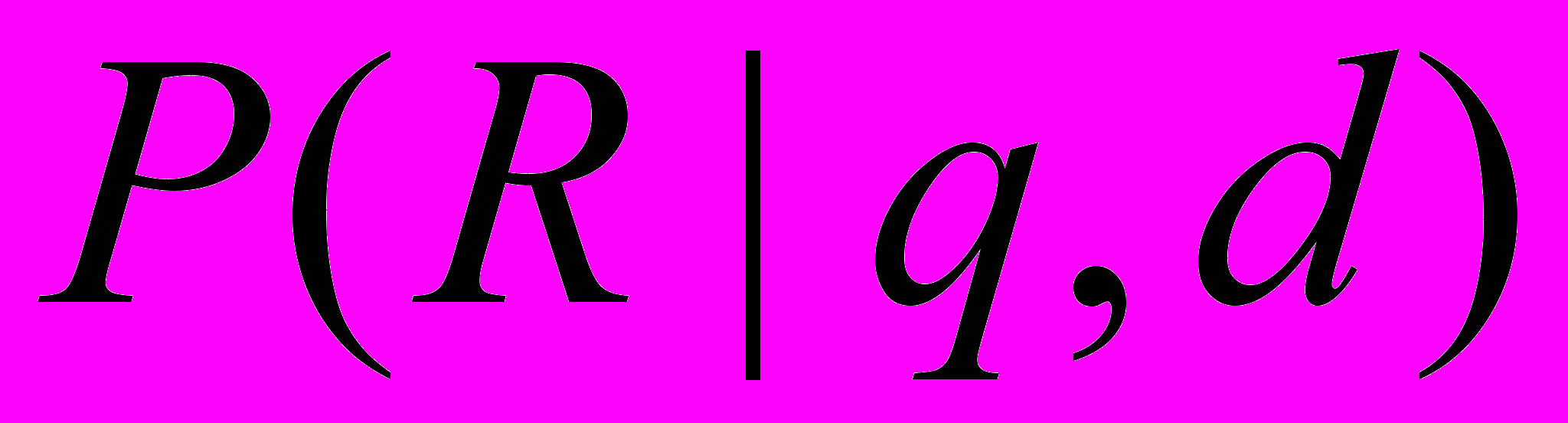 , где q - запрос, d - документ, а также того, что документ нерелевантен
, где q - запрос, d - документ, а также того, что документ нерелевантен  запросу -
запросу - 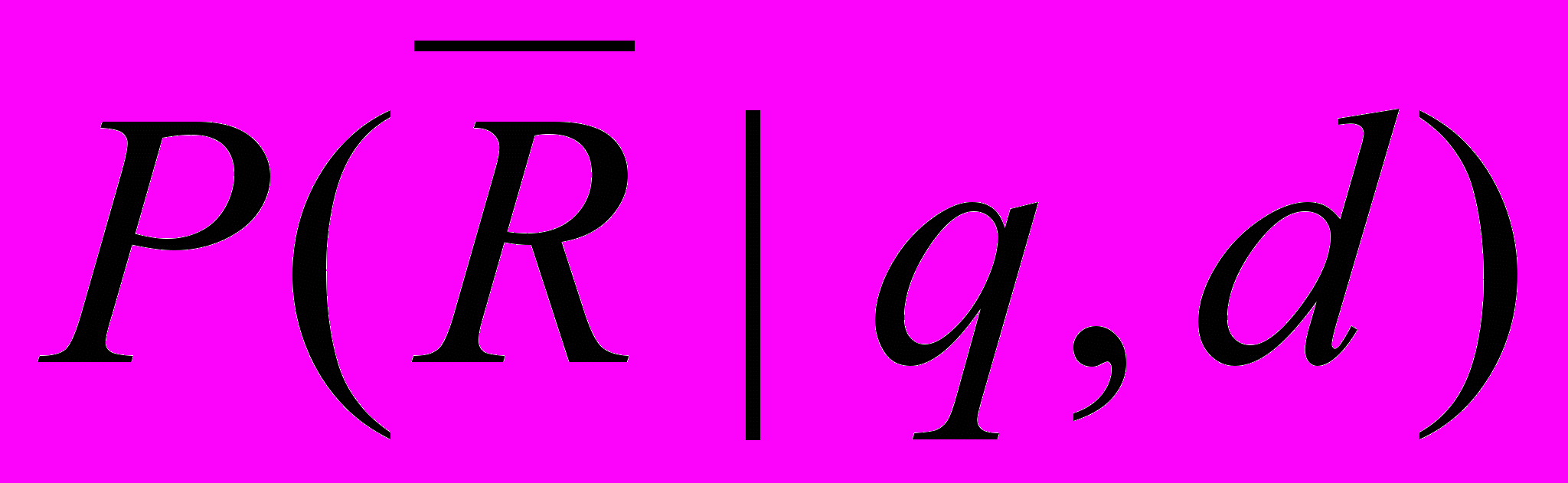 .
.В рамках вероятностной модели вводится понятие квоты релевантности как меры близости документа запросу -
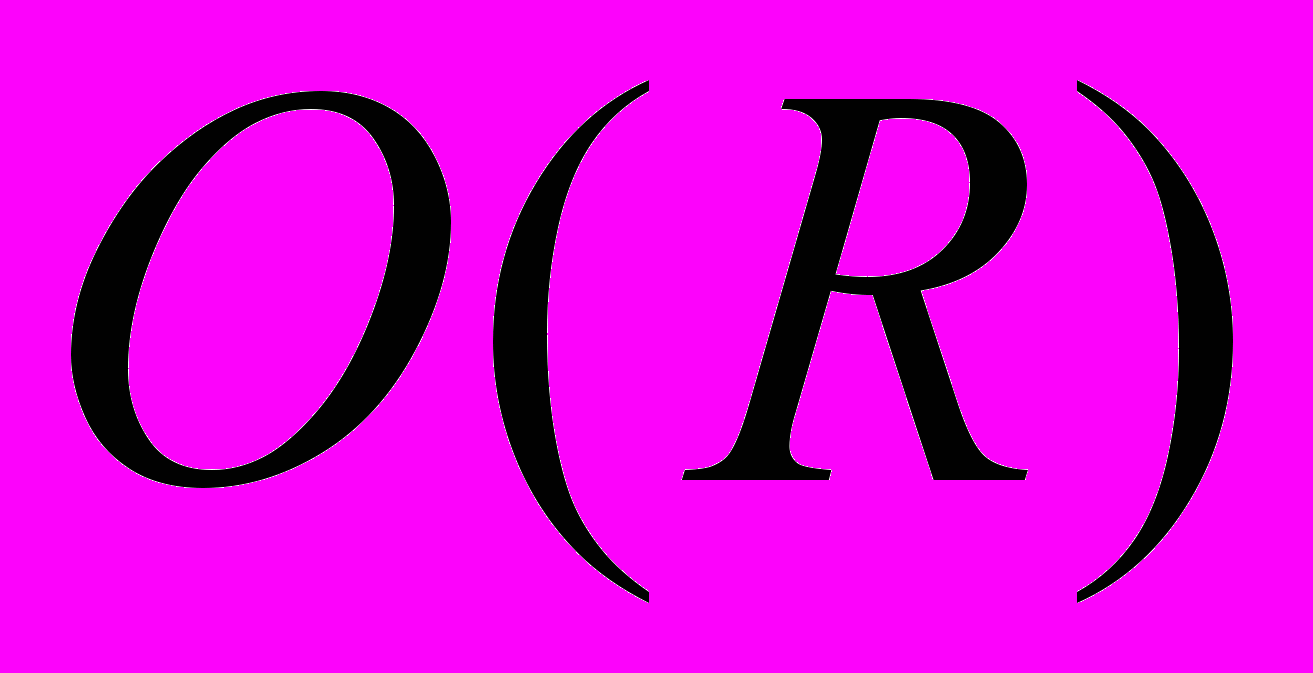 :
: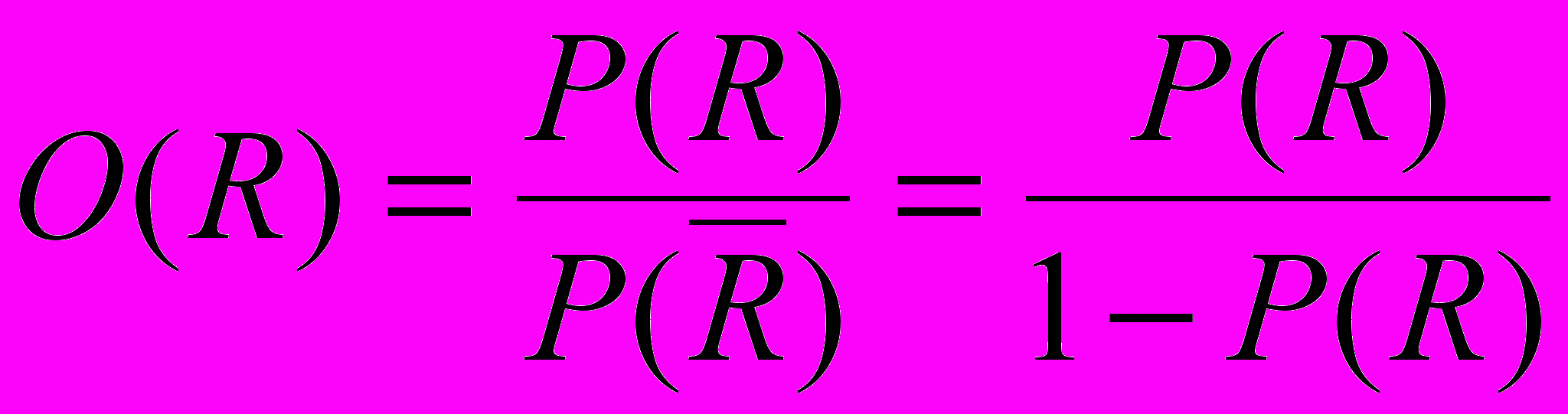 (1.12)
(1.12)Очевидно, что квота меньше, чем 1 для вероятности
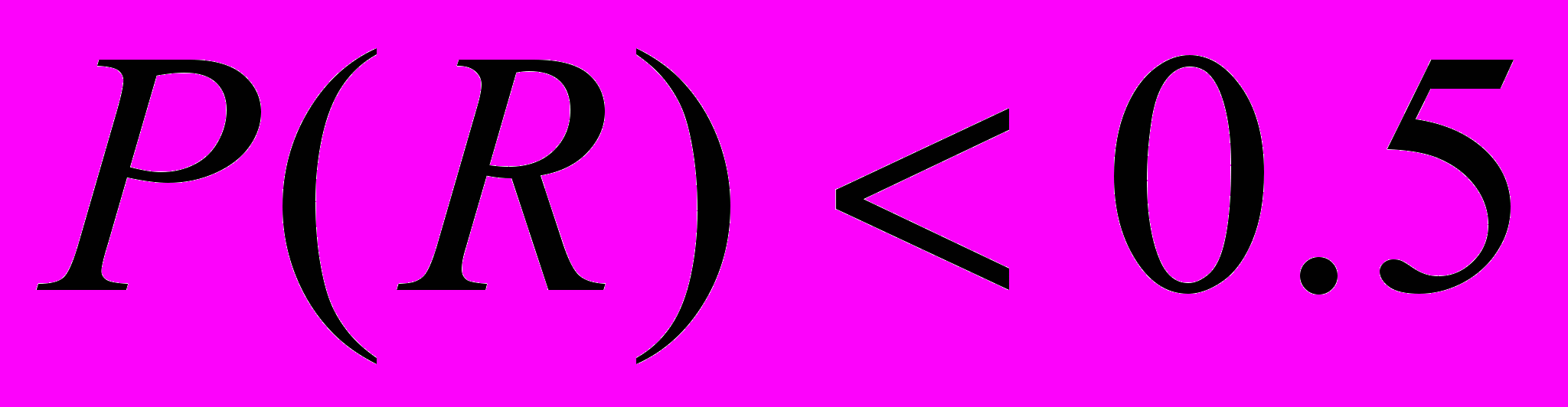 и больше 1 для вероятности
и больше 1 для вероятности 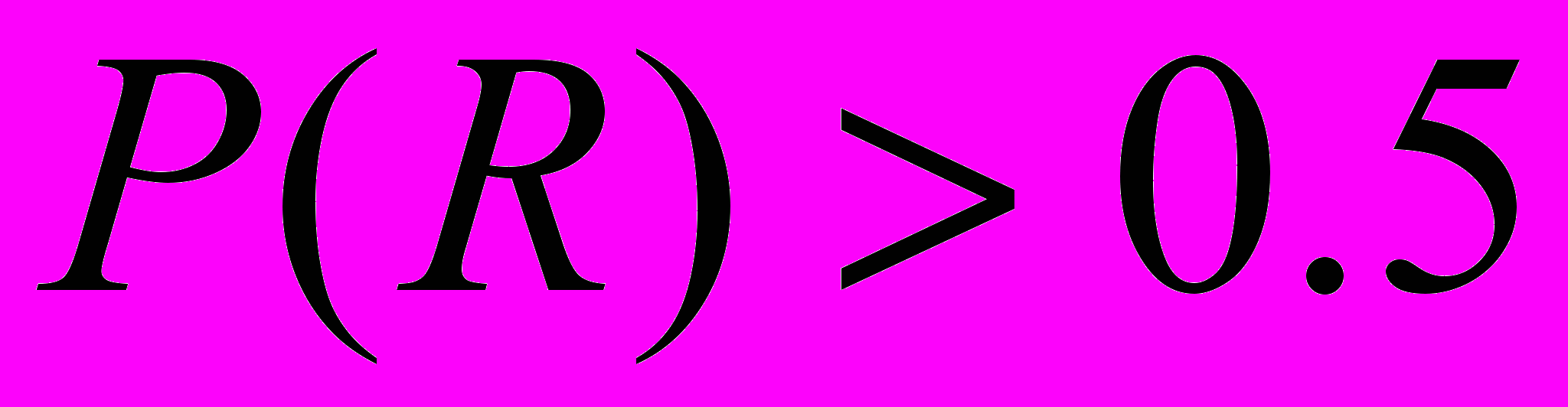
Определим квоту того события, что документ релевантен запросу:
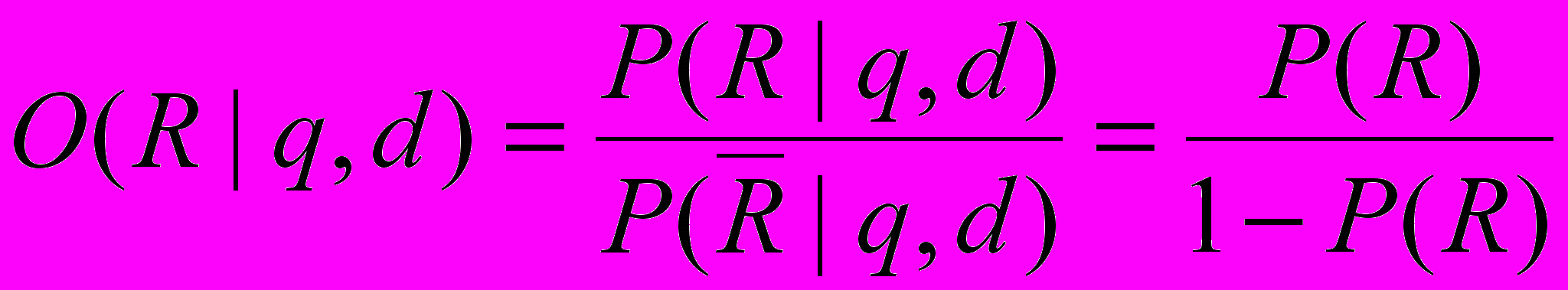 (1.13)
(1.13)Для числителя этой формулы справедливо:
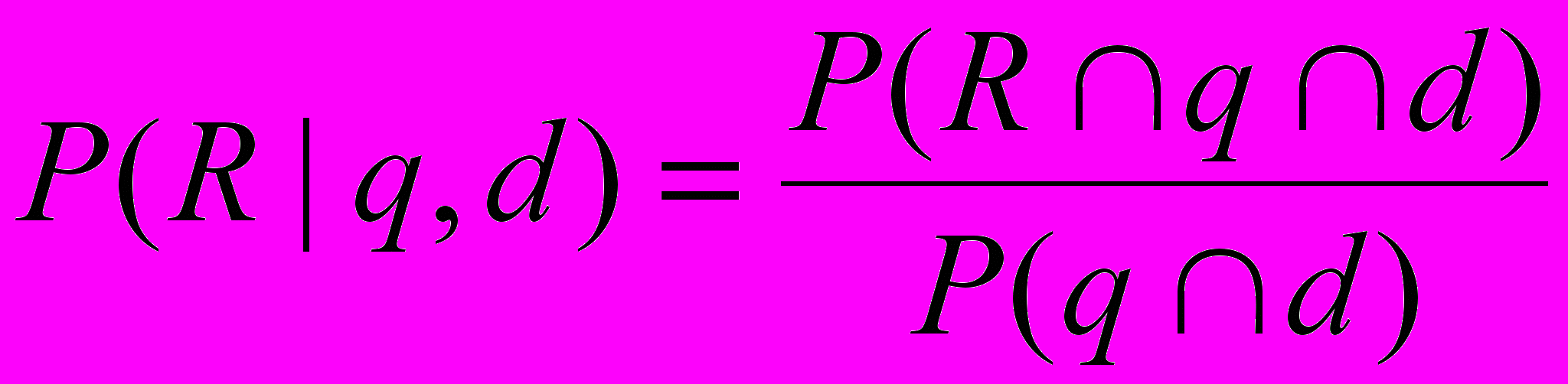 (1.14)
(1.14)Величина
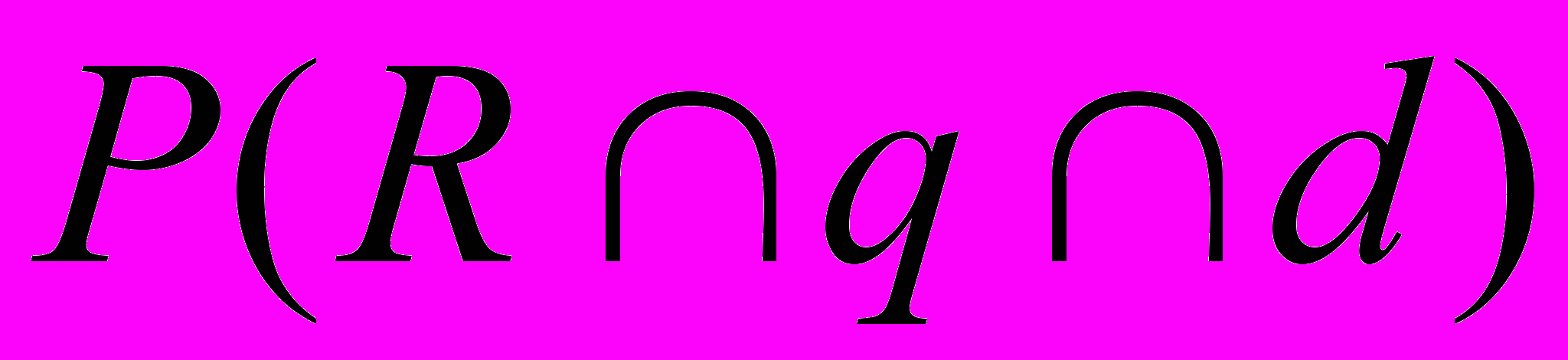 в приведенном выражении интерпретируется как вероятность события, заключающегося в том, что документ d релевантен запросу q, а величина
в приведенном выражении интерпретируется как вероятность события, заключающегося в том, что документ d релевантен запросу q, а величина 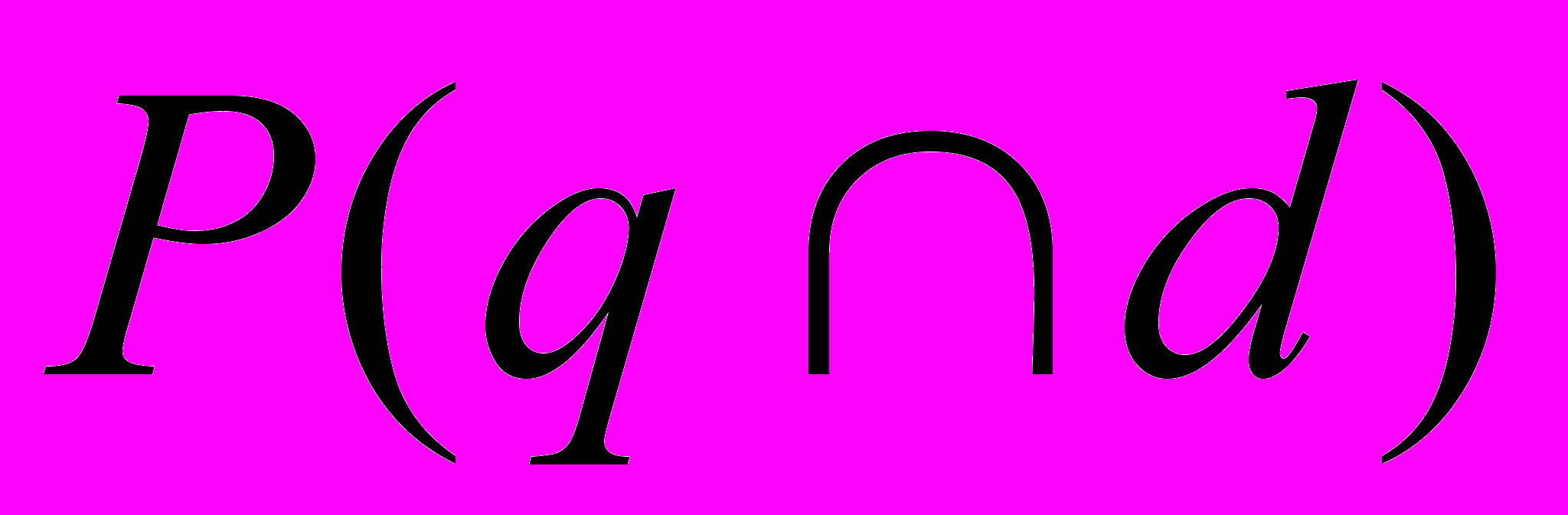 - вероятность того, что по запросу q будет выдан документ d. аюИспользуя формулу Байеса для числителя и знаменателя получаем:
- вероятность того, что по запросу q будет выдан документ d. аюИспользуя формулу Байеса для числителя и знаменателя получаем: (1.15)
(1.15)Подставляя выражения
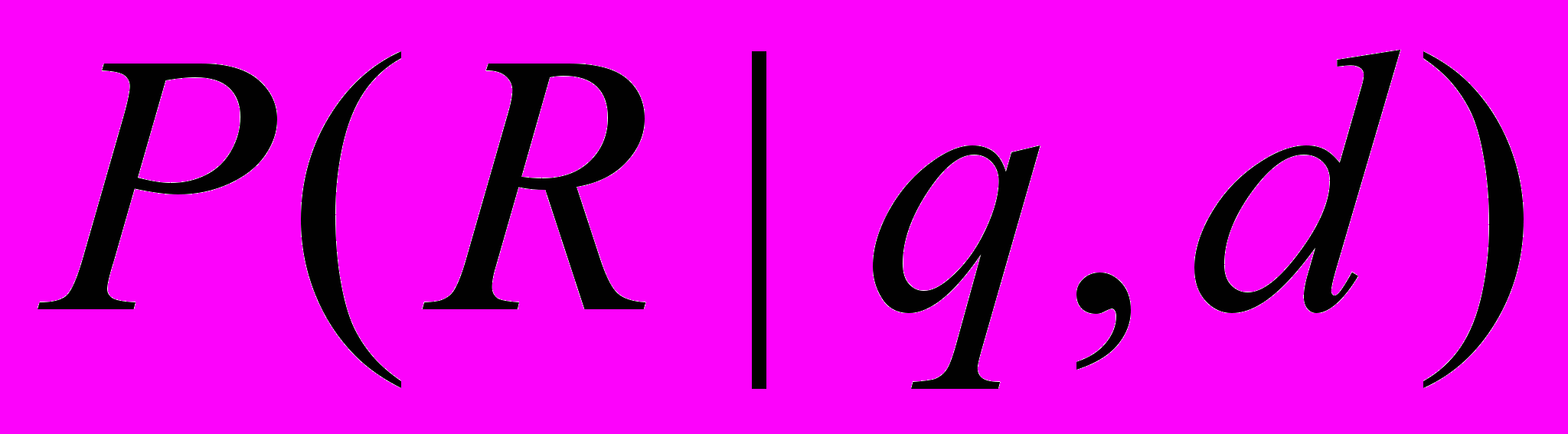 и в числитель и знаменатель формулы для квоты релевантности, получаем:
и в числитель и знаменатель формулы для квоты релевантности, получаем: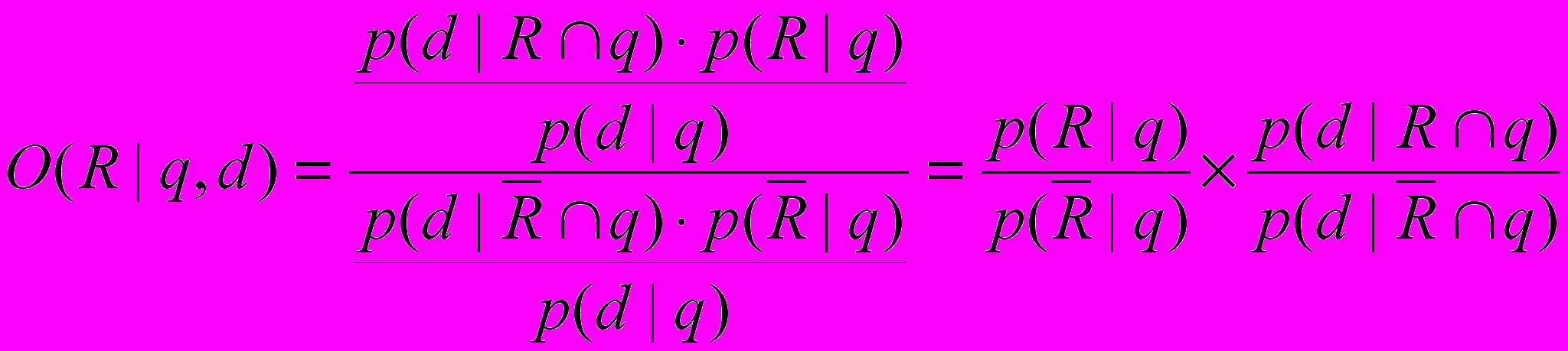 (1.16)
(1.16)Достоинства и недостатки вероятностной модели поиска
Недостатками модели является низкая вычислительная масштабируемость (т.е. резкое снижение эффективности при росте объемов данных), а также необходимость постоянного обучения системы.
Оценка информационного поиска
Для оценки стандартным способом информационно-поисковой системы по произвольным запросам необходима тестовая коллекция, состоящая из трех компонентов.
1.Коллекция документов.
2.Набор тестовых информационных потребностей, выраженных в виде запросов.
3.Набор оценок релевантности, представленных, как правило, в виде бинарных утверждений релевантный и нерелевантный относительно каждой пары «запрос-документ».
Стандартный подход к оценке информационно-поисковых систем опирается на понятие релевантных и нерелевантных документов. В соответствии с информационными потребностями пользователей документ из тестовой коллекции проходит бинарную классификацию: релевантный или нерелевантный. Это решение эталонной оценкой релевантности. Коллекция из тестовых документов и набор информационных потребностей должны иметь достаточный объем: оценку следует усреднять по действительно большой совокупности тестов, поскольку результаты поиска сильно отличаются для разных документов и информационных потребностей. В качестве первого очень грубого приближения достаточным минимумом считается набор из 50 информационных потребностей.
Релевантность оценивается по отношению к информационной потребности, а не по запросу.
Документ является релевантным, если он соответствует заданной информационной потребности, а не просто содержит все слова из запроса. На практике эту тонкость часто не понимают, поскольку информационная потребность неочевидна. Тем не менее, она существует. По однословному запросу системе трудно понять, в чем заключается информационная потребность. Тем не менее, пользователю она известна. И он может оценивать полученные результаты на основе их релевантности своей информационной потребности. Для того чтобы оценить систему, необходимо явно сформулировать информационную потребность, относительно которой мы будем судить о релевантности или нерелевантности найденных документов.
Многие системы содержат разные веса (часто называемые параметрами), с помощью которых можно настроить их производительность. При оценке таких систем не следует учитывать результаты поиска по тестовой коллекции, полученные путем подбора параметров, обеспечивающих максимум производительности для данной коллекции. Это объясняется тем, что такая настройка завышает ожидаемую производительность системы, поскольку веса специально настраиваются так, чтобы обеспечить максимальную производительность на конкретном множестве запросов, а не на случайной их выборке. В таких случаях правильно было бы сформулировать одну или несколько рабочих тестовых коллекций документов и подбиравть параметры для них. После этого система с настроенными параметрами проходит испытание на тестовой коллекции. Результаты, полученные при таком тестировании, можно рассматривать как несмещенную оценку производительноси системы.
Оценка результатов поиска
Итак, как оценить качество системы, имея все эти ингредиенты? Чаще всего для оценки информационного поиска используются два показателя: точность (precision) и полнота (recall). Они определены для простого случая, когда информационно-поисковая система возвращает набор документов, соответствующих запросу. Позднее мы покажем, как эти показатели распространить на ранжированные результаты поиска.
Предложения по выбору базовой модели информационного поиска для реализации макета
В качестве основной модели для разработки макета лучше всего подходит векторно-пространственная модель поиска. Она обеспечивает такие возможности как:
- Обработку запросов неограниченной длины
- Простоту реализации режима поиска подобных документов
- Сохранение результатов поиска с возможностью выполнения уточняющего запроса
Эти возможности наилучшим образом соответствую требованиям разрабатываемой информационно-поисковой системы.
Таким образом, по результатам исследований, проведенных в рамках данного раздела, можно сделать следующие выводы:
1.В рамках ДАННОЙ РАБОТЫ были рассмотрены основные положения теории информационного поиска, принципы построения информационно-поисковых систем и их функционирования. Была разработана структура информационно-поисковой системы.
2.В качестве основной модели для разработки макета была выбрана векторно-пространственная модель поиска.
Список использованной литературы
- Андрейчиков А.В., Андрейчикова О.Н. Интеллектуальные информационные системы: Учебник. – М.: Финансы и статистика, 2004. – 424 с.: ил.
- Барсегян А.А., Куприянов М.С., Степаненко В.В., Холод И.И. Технологии анализа данных. Data Mining, Visual Mining, Text Mining, OLAP – 2е изд., перераб. и доп. – СПБ.: БХВ-Петербург, 2007 г. – 384с.: ил.
- Башмаков А.И., Башмаков И.А. Интеллектуальные информационные технологии: Учеб. пособие. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2005. – 304 с.: ил.
- Брайчевский С.М., Ландэ Д.В. Современные информационные потоки: актуальная проблематика // Научно-техническая информация. Сер. 1. Вып. 11. – 2005. - С. 21-33.