
Методы цифрового анализа текстовых сообщений для идентификации спама
| Вид материала | Документы |
- Использование методов категоризации текстовых привязок и анализа графов для идентификации, 76.45kb.
- «Явление спама и борьба с ним», 264.65kb.
- Задачи и их решение Стандартные и нестандартные задачи Задачи «на работу» Задачи «на, 157.13kb.
- «Тайный смысл даты рождения: Нумерология и будущее.», 527.12kb.
- Федеральный закон, 98.81kb.
- Кий отчет, который содержит количественный и качественный анализ сообщений, попавших, 4199.36kb.
- «Система идентификации личности по отпечаткам пальцев. Подсистема анализа изображения», 1781kb.
- И. А. Терейковский Применение семантического анализа содержимого электронных писем, 279.31kb.
- Российская федерация федеральная служба по интеллектуальной собственности, патентам, 19.54kb.
- 1. А. Т. Фоменко. Методы статистического анализа нарративных текстов и приложения, 141.9kb.
Труды Научной конференции по радиофизике, ННГУ, 2006
Методы цифрового анализа текстовых сообщений для идентификации спама
С.В. Корелов, А.К. Крюков, Л.Ю. Ротков
Нижегородский госуниверситет
Рассматривается эффективность методов цифрового анализа сообщений (вычисление спектра, моментных функций и т.д.) для различения легальных рассылок от спама.
Существующие программы способны фильтровать трафик электронных писем и не допускать часть спама до почтовых ящиков. Их основные проблемы – потеря эффективности с течением времени (существует возможность приспособления к их работе) и необходимость держать алгоритм работы программы в тайне.
Сообщение может быть рассмотрено как сигнал x(n). К сигналам были применены методы цифровой обработки и определены вероятности ошибок (пропуск спама (ПЦ) и реакция на легальную рассылку как на спам (ЛТ)) для этих методов. В работе рассматривались русскоязычные сообщения. При различении использовался метод наименьших квадратов.
Методы и результаты:
1. Вычисление среднего значения.
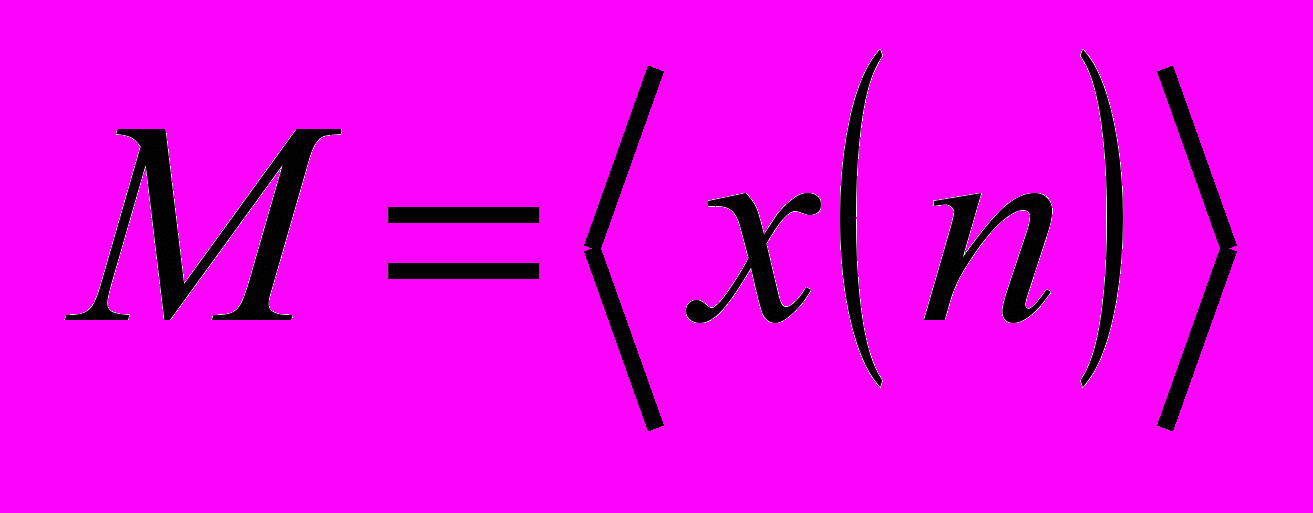 . Ошибки: pПЦ=0,32; pЛТ=0,25.
. Ошибки: pПЦ=0,32; pЛТ=0,25.2. Вычисление дисперсии.
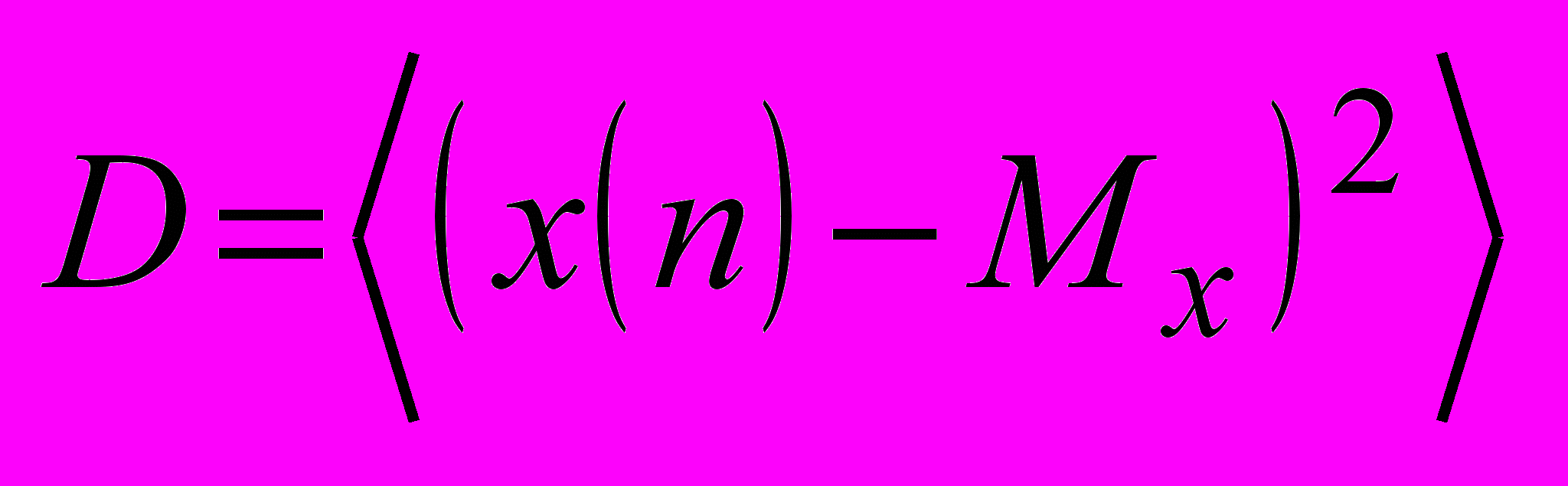 . Ошибки: pПЦ=0,20; pЛТ=0,10.
. Ошибки: pПЦ=0,20; pЛТ=0,10.3. Вычисление относительной частоты использования символов.
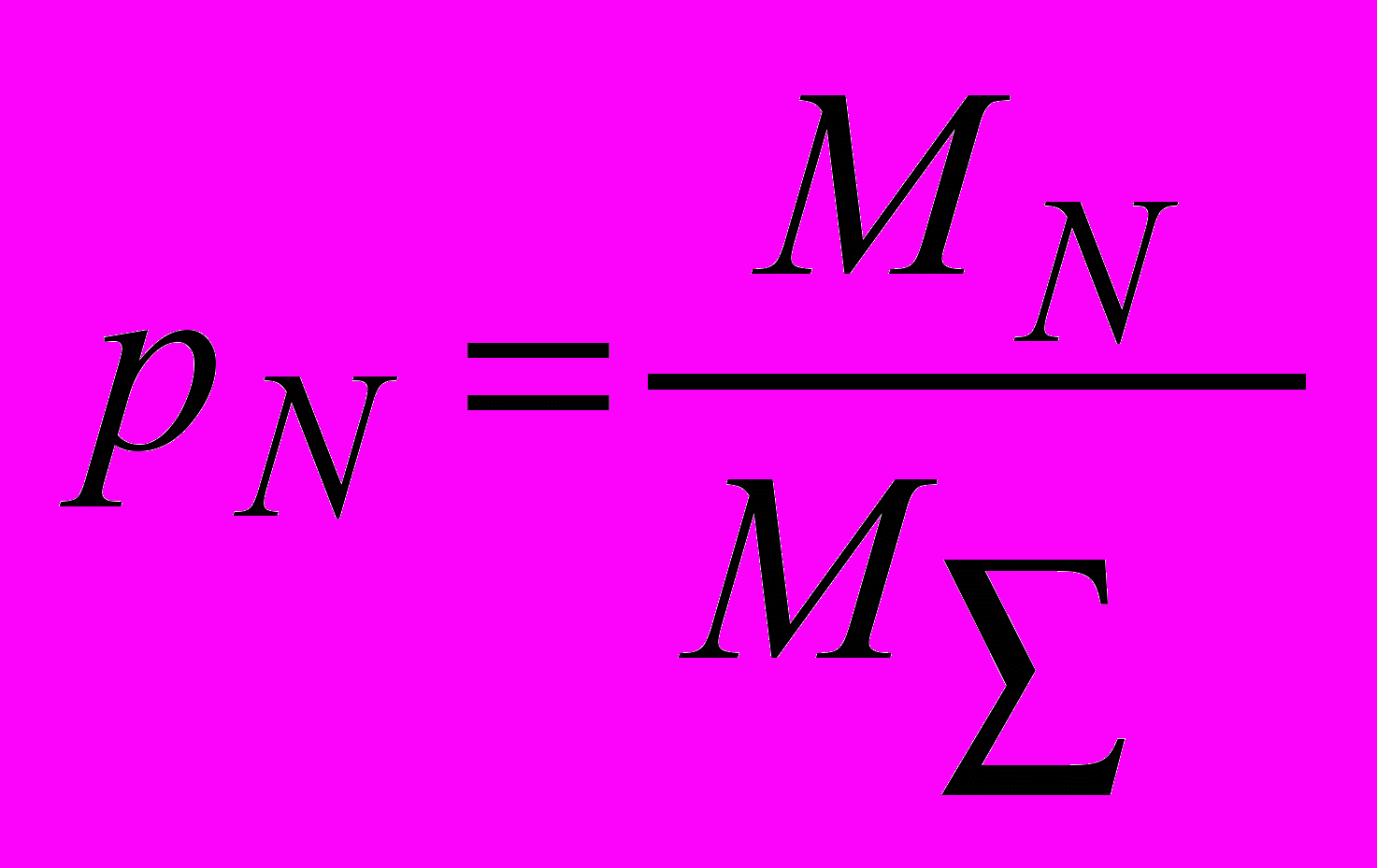 . Ошибки: pПЦ=0,22; pЛТ=0,04.
. Ошибки: pПЦ=0,22; pЛТ=0,04.4. Вычисление спектральных характеристик сигнала с занулённым средним (200 отсчётов):
4.1. Sin-преобразование. Ошибки: pПЦ=0,11; pЛТ=0,47.
4.2. Cos-преобразование. Ошибки: pПЦ=0,42; pЛТ=0,44.
4.3.
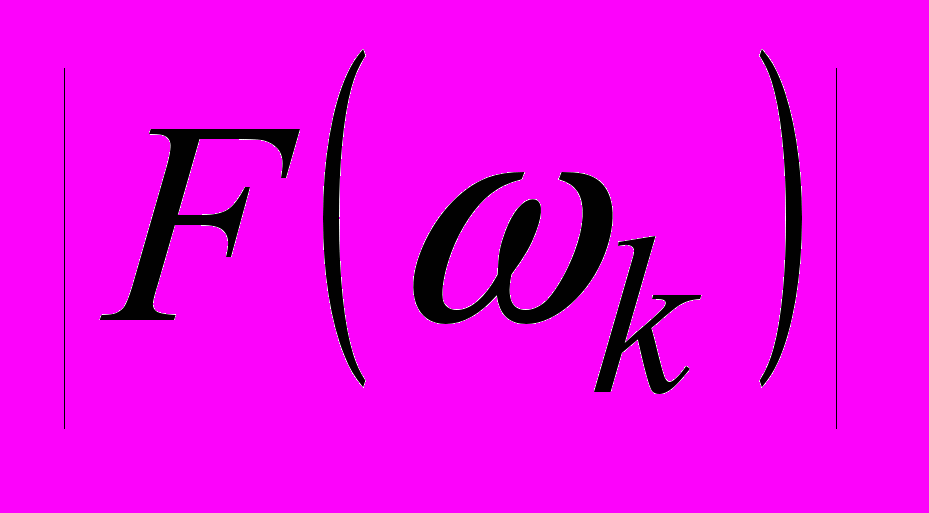 – модуль спектра. Ошибки: pПЦ=0,13; pЛТ=0,15.
– модуль спектра. Ошибки: pПЦ=0,13; pЛТ=0,15.4.4. Сумма отсчётов
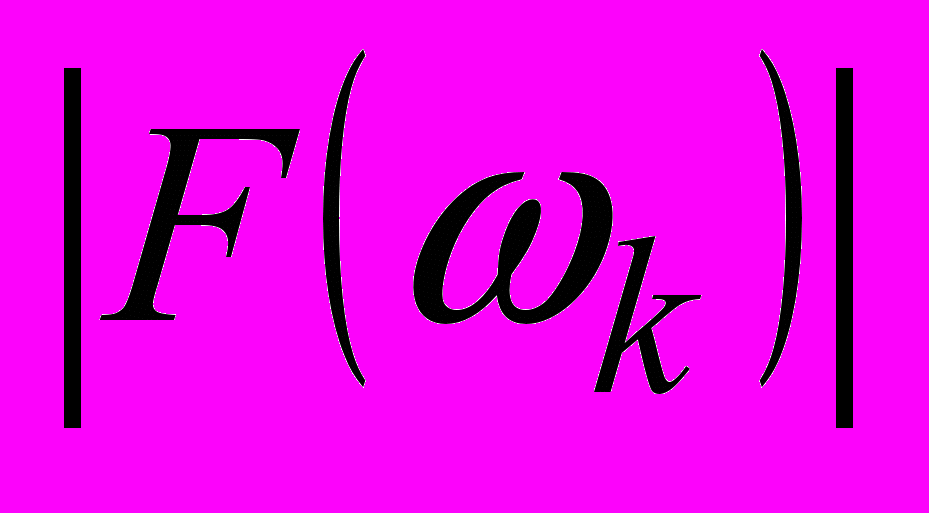 в 5 выделенных спектральных диапазонах (ωmax=200): ω=0..3: Ошибки: pПЦ=0,15; pЛТ=0,66.
в 5 выделенных спектральных диапазонах (ωmax=200): ω=0..3: Ошибки: pПЦ=0,15; pЛТ=0,66.ω=4..15: Ошибки: pПЦ=0,17; pЛТ=0,67.
ω=16..49: Ошибки: pПЦ=0,25; pЛТ=0,69.
ω=50..99: Ошибки: pПЦ=0,5; pЛТ=0,02.
ω=100..200: Ошибки: pПЦ=0,42; pЛТ=0,02.
5. Вычисление АКФ письма как стационарного сигнала, нормированной на длину (1000 отсчётов). Усреднённые АКФ приведены на рисунках.
Ошибки: pПЦ=0,0494; pЛТ=0,0263.
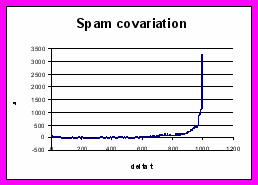 |  |
На данных выборках (232 легальных письма и 204 – спамерских) наиболее эффективным методом идентификации спама оказался метод ковариационной функции. Вероятно, на других выборках легальных рассылок и спама будут эффективны другие методы (спектр …). На основании изученного может быть построен самообучающийся анти-спам фильтр, применяющий совокупность данных методов. Каждый метод в зависимости от истории эффективности работы может иметь свой вес при принятии решения о принадлежности рассылки к спаму. Данный метод не налагает ограничений на количество объектов (цифровых образцов) легальных рассылок и спама и есть основания полагать, что система не потеряет эффективность при накоплении большого количества материала для обучения из-за усреднений.
Таким образом, можно фильтровать до 96% спама с ошибочным принятием решения для 2-5% легальных рассылок.
Наиболее перспективными направлениями разработки системы являются применение новых методов обработки сигналов и создание интеллектуальной системы принятия решений о принадлежности рассылки к спаму.
- Гольденберг Л.М., Матюшкин Б.Д., Поляк М.Н. Цифровая обработка сигналов. Учебное пособие, 1990, М: Радио и связь, 257с.
Обнаружение аномального поведения процесса на основе системы вызовов
С.В. Корелов, А.С Пуртов, Л.Ю. Ротков
Нижегородский госуниверситет
Процесс обнаружения аномального поведения Вычислительной Системы (ВС) включает в себя четыре этапа (Рис. 1).
 |
| Рис. 1 |
В работе мы рассмотрим первые три этапа обнаружения вторжения.
1) На этапе сбора данных, мы используем технологию перехвата системных вызовов.
2) На этапе анализа нами использованы принципы искусственных иммунных систем.
3) Режим обнаружения атаки предполагает работу СОА в реальном времени.
Разделим все возможные варианты поведения процесса на два режима: нормальный (соответствует работе системы в штатном режиме); и на аномальный (может соответствовать как атаке, вторжению, так и просто неправильной работе самого процесса).
В качестве данных, используемых для анализа поведения процесса, нами была выбрана Последовательность Системных Вызовов (ПСВ).
Перехват системной функции API заключается в изменении некоторого адреса в памяти процесса или некоторого кода в теле функции таким образом, чтобы при вызове этой самой API-функции управление передавалось не ей, а нашей функции, подменяющей системную [3]. Эта функция, работая вместо системной, выполняет какие-то запланированные нами действия (в применении к данной задаче, нас интересует лишь сам факт вызова функции). Фактически, прием заключается в замене адреса функции в таблице импорта на адрес функции-двойника. Как известно, большинство приложений вызывает функции из dll через таблицу импорта, представляющую собой после загрузки exe файла в память списки адресов функций, импортируемых из различных dll.
При перехвате API через таблицу импорта необходимо:
- узнать адрес перехватываемой функции
- запомнить этот адрес где-нибудь и записать на его место адрес функции-двойника.
Перехваченные функции образуют некую последовательность, каждую функцию кодируем двоичным алфавитом. Таким образом, последовательность функций превращается в бинарную строку, которую «нарезаем» плавающим окном на слова длины l. Из этих слов формируется словарь, соответствующий штатному режиму работы процесса.
На этапе обнаружения атаки мы используем иммунологические принципы [1]. Таким образом, алгоритм обнаружения состоит из четырёх основных шагов:
1) Определить множество S как набор «своих » образцов (в нашей работе под S мы понимаем словарь, состоящих из слов длины l).
2) Произвести набор рецепторов R такой, что каждый рецептор Ri R не соответствует никакому образцу s S.
3) Применить набор R к контролю поведения процесса в реальном времени.
4) Если при этом хотя бы один рецептор активируется, это означает, что d D является аномалией в данной системе.
Основной особенностью данного алгоритма является то, что он не требует никакой предшествующей информации об аномалии.
Наиболее эффективный алгоритм генерации детекторов предложил польский учёный Weirzchon [2]. Основной идеей любого алгоритма генерации набора детекторов является тот факт, что он состоит из слов длины l, не имеющих вхождений в набор защищаемых данных.
В нашей модели процесс активации рецептора может быть определён следующим образом. Предположим, что есть две строки Ri и x, где Ri – рецептор, а x – интересующая нас строка данных. Введём функцию match(Ri,x), такую что:

Мы будем использовать правило r-contigous сравнения строк: match(Ri,x)=TRUE, если строки Ri и x совпадают по крайней мере в r-смежных битах.
Итак, после формирования словарей и соответствующих им наборов детекторов, мы приступаем к следующему этапу построения СОА – непосредственному наблюдению за работой приложения в режиме реального времени. На этом этапе, так же как и на этапе формирования словарей, мы перехватываем функции, вызываемые приложением. Далее по тому же правилу кодируем их в бинарную строку и «нарезаем» на слова длины l (слова «нарезаются» по принципу плавающего окна). Каждое полученное слово сравнивается со сформированным ранее набором детекторов. Как и было упомянуто ранее, равенство строки (из перехваченной последовательности) строке из набора детекторов соответствует обнаружению аномалии.
- Forest S., Perelson A., Allen L., Cherukuri R. Self-nonself discrimination in a computer. In: Proceedings of the 1994 IEEE Symposium on Research in Security and Privacy, 1994, pp. 202-212, Los Alamos, CA.
- Weirzchon S. Generating optimal repertoire of antibody strings in an artificial immune system. // Intelligent Information Systems, 2000:119-133.
- Pietrek M. Windows95 System programming secrets.