
Методы цифрового анализа текстовых сообщений для идентификации спама
| Вид материала | Документы |
- Использование методов категоризации текстовых привязок и анализа графов для идентификации, 76.45kb.
- «Явление спама и борьба с ним», 264.65kb.
- Задачи и их решение Стандартные и нестандартные задачи Задачи «на работу» Задачи «на, 157.13kb.
- «Тайный смысл даты рождения: Нумерология и будущее.», 527.12kb.
- Федеральный закон, 98.81kb.
- Кий отчет, который содержит количественный и качественный анализ сообщений, попавших, 4199.36kb.
- «Система идентификации личности по отпечаткам пальцев. Подсистема анализа изображения», 1781kb.
- И. А. Терейковский Применение семантического анализа содержимого электронных писем, 279.31kb.
- Российская федерация федеральная служба по интеллектуальной собственности, патентам, 19.54kb.
- 1. А. Т. Фоменко. Методы статистического анализа нарративных текстов и приложения, 141.9kb.
АСПЕКТЫ ПРИМЕНЕНИЯ ГЕНЕТИЧЕСКИХ КАРТ ДАННЫХ
ДЛЯ ИДЕНТИФИКАЦИИ ИСПОЛНЯЕМОГО КОДА ПРОГРАММ
Д.Л.Туренко
Нижегородский госуниверситет
Реконструкция (reverse engineering) алгоритмов программ в целом или отдельных процедур по их исполняемому коду является важной составляющей при анализе уязвимостей программного обеспечения (ПО), идентификации вредоносных программ, а также поиске ошибок при программировании.
Задачу восстановления алгоритмов можно свести к задаче идентификации их реализаций и решать с использованием средств автоматизированного анализа исполняемого кода. Например, в средствах антивирусной защиты идентификация вредоносных программ производится по их сигнатурам, т.е. устойчивым характерным последовательностям байтов в исполняемом коде. При этом новые реализации компьютерных вирусов, как правило, не могут быть обнаружены, пока их сигнатуры не внесены в базу данных антивирусного ПО.
Каждому алгоритму может соответствовать целый класс его реализаций в виде исполняемого кода для заданной аппаратно-программной вычислительной среды. При этом реализации из одного класса могут не иметь общей сигнатуры в узком смысле. В предыдущих работах [1-3] предложены подходы к расширению понятия сигнатуры с использованием математических моделей (ММ) в виде управляющих ориентированных графов и генетических карт (ГК) данных.

Рис. 1
Исходными данными для построения ММ ГК является конечная последовательность отсчетов дискретной динамической системы – «текст» [4], который может быть получен из исполняемого кода с различными степенями абстракции (рис. 1):
- в виде последовательности байт;
- в виде последовательности кодов машинных команд;
- в виде последовательности типов машинных команд.
Базовыми параметрами ММ ГК являются: БП=(q,n), где
q – число уровней квантования «текста»,
n– размерность фазового пространства ДДС.
Оптимальные базовые параметры ММ ГК определяются условием минимальности числа точек фазового пространства N=qn и задают разбиение множества всех конечных дискретных последовательностей на классы эквивалентности [5], которое может быть использовано для экспресс-идентификации исполняемого кода.
Базовые параметры и алгоритм «нарезки» определяют разбиение «текста» длины M на I+1 участков («генов») длин mi и J [4]:
M=m1+m2+…+mI+J
при этом последовательность длин «генов» обладает свойством сигнатуры «текста» (в широком смысле), что может быть использовано для его идентификации.
Для экспериментальной проверки данного подхода были разработаны программные средства предварительной подготовки данных, определения оптимальных базовых параметров, построения и сравнения ГК исполняемого кода. В ходе экспериментов производился поиск сигнатур стандартных библиотечных функций в последовательности длин «генов» исполняемого кода исследуемых тестовых программ.
Установлено, что сигнатура блока исполняемого кода может отличаться от соответствующей подпоследовательности длин «генов» исследуемой программы несколькими первыми и последним участком. Таким образом, при условии достаточного числа «генов» можно успешно определять границы искомой процедуры или делать вывод об ее отсутствии в исследуемой программе.
На основе полученных результатов сделан вывод о применимости данного подхода при условии использования одинаковых средств разработки (компилятора языка программирования) для исследуемых программ и искомых процедур.
Предложенный подход к идентификации может быть использован для декомпозиции объемного и сложного исполняемого кода на программные блоки и их распознавания. При этом эффективность данного подхода будет определяться полнотой базы данных сигнатур эталонных процедур (алгоритмов).
- Туренко Д.Л., Кирьянов К.Г. // Вестник ННГУ. Серия Радиофизика. Вып. 1(2). –Н. Новгород: ННГУ, 2004, с.37.
- Туренко Д.Л. // Тр. Девятой научн. конф. по радиофизике. 7 мая 2005 г. –Н. Новгород: ТАЛАМ, 2005, с.320.
- Туренко Д.Л. // Вестник ННГУ. Серия Радиофизика. –Н. Новгород: ННГУ, 2005, направлено в печать.
- Кирьянов К.Г. Генетический код и тексты: динамические и информационные модели сложных систем // Ред. Л.Ю. Ротков, А.В. Якимов. –Н. Новгород: ТАЛАМ, 2002, 100с.
- Кирьянов К.Г., Туренко Д.Л. // Тр. НГТУ. Том 56. Серия Информационные технологии. Вып. 2. –Н. Новгород: НГТУ, 2005, с.65.
Сравнение подходов к оценке
расстояния единственности криптосистем
А.А.Горбунов, К.Г.Кирьянов
Нижегородский госуниверситет
Для оценки одного из таких из важнейших параметров криптосистем (КС) с закрытым ключом, характеризующих меру теоретической стойкости шифров, как расстояние единственности (РЕ) Шеннона [1], многими авторами, например в работе [2], использовались разнообразные подходы в зависимости от различной априорной информации о математической модели (ММ) шифратора КС.
В самой общей формулировке, данной Шенноном в [1], предполагается, что среднее число текстов u = uL длины L, которые могут быть зашифрованы в заданный шифротекст y = yL, равно
R(L) = 2 H(u|y), (1)
где H(u|y) – «средняя условная энтропия» [1] открытого текста u КС при перехваченном шифротексте y.
Расстояние единственности шифра по открытому тексту при этом определяется как минимальный корень L = n0 уравнения (если такие корни существуют).
Ru(L) = 2 H(u/y) = 1 (2)
Аналогично определяют расстояние единственности шифра по ключу k [1,2]:
Rk(L) = 2 H(k/y) = 1. (3)
Прямой подсчет энтропийных функций в (2) и (3), как правило, затруднителен, т. к. информация о значениях вероятностей для всех возможных текстовых последовательностей длины L на входе и выходе шифратора КС, обычно недоступна или неполна. Поэтому для расчета на практике величины расстояния единственности был предложен ряд подходов в [2,3], оценивающих эти характеристики при выполнении различных условий, ограничивающих класс ММ исследуемых шифров.
| Условия, накладываемые на класс ММ шифраторов КС | Оценка РЕ n0 [2] |
| 1. При условиях случайного и равновероятного выбора ключа k(i) (модель «случайного шифра») и расшифрования на нем криптограммы yL вероятность получить содержательный текст равна 2 HL / quL; r(L) = |K|2HL/quL – среднее число открытых текстов при расшифровании шифротекста длины L на всех ключах k(i)K . | r(L=n0) = 1 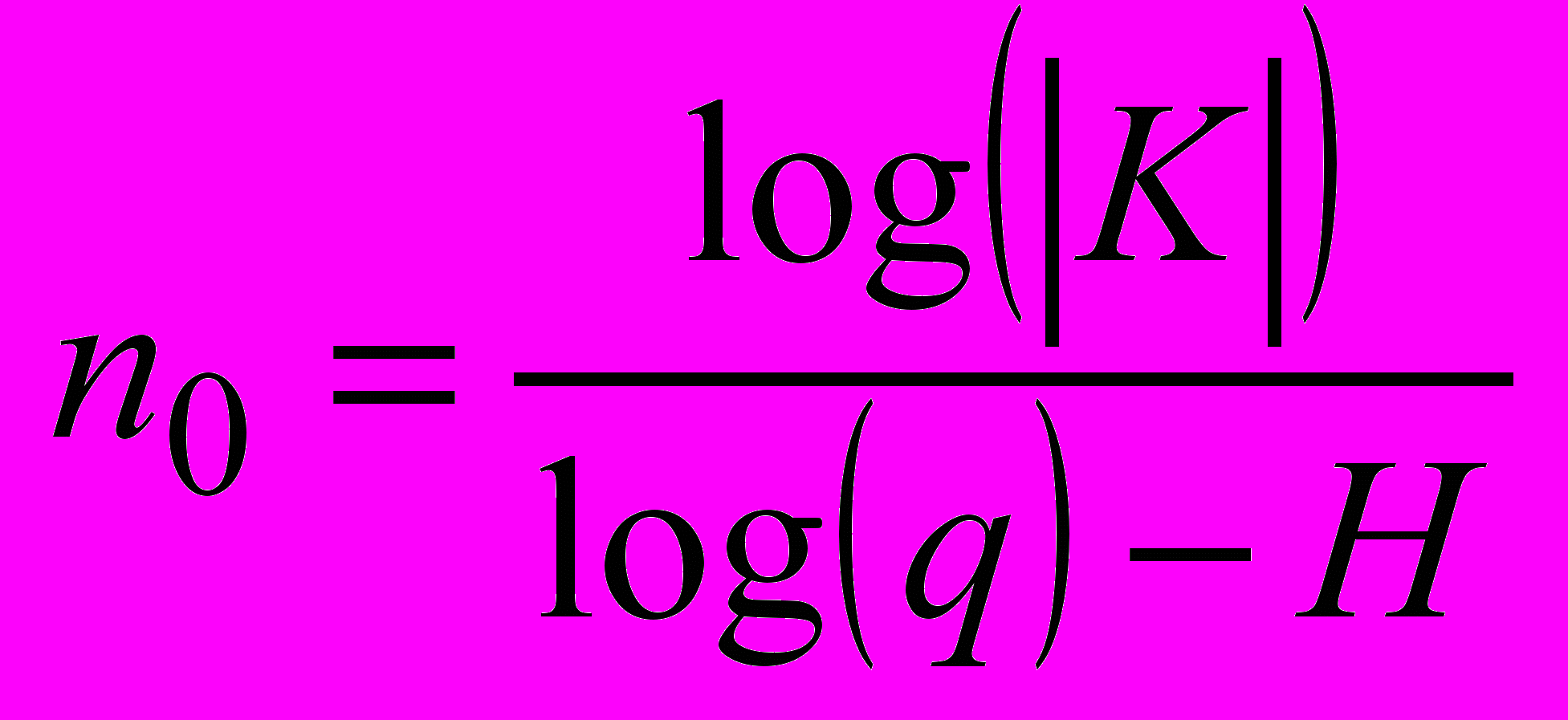 |
| 2. При условии (qy)L < |uL||K| , где uL, yL – начальные отрезки шифруемого текста u и шифротекста y, соответственно; yL, при котором число решений уравнения шифрования относительно неизвестной пары (uL, k) всегда больше единицы. | 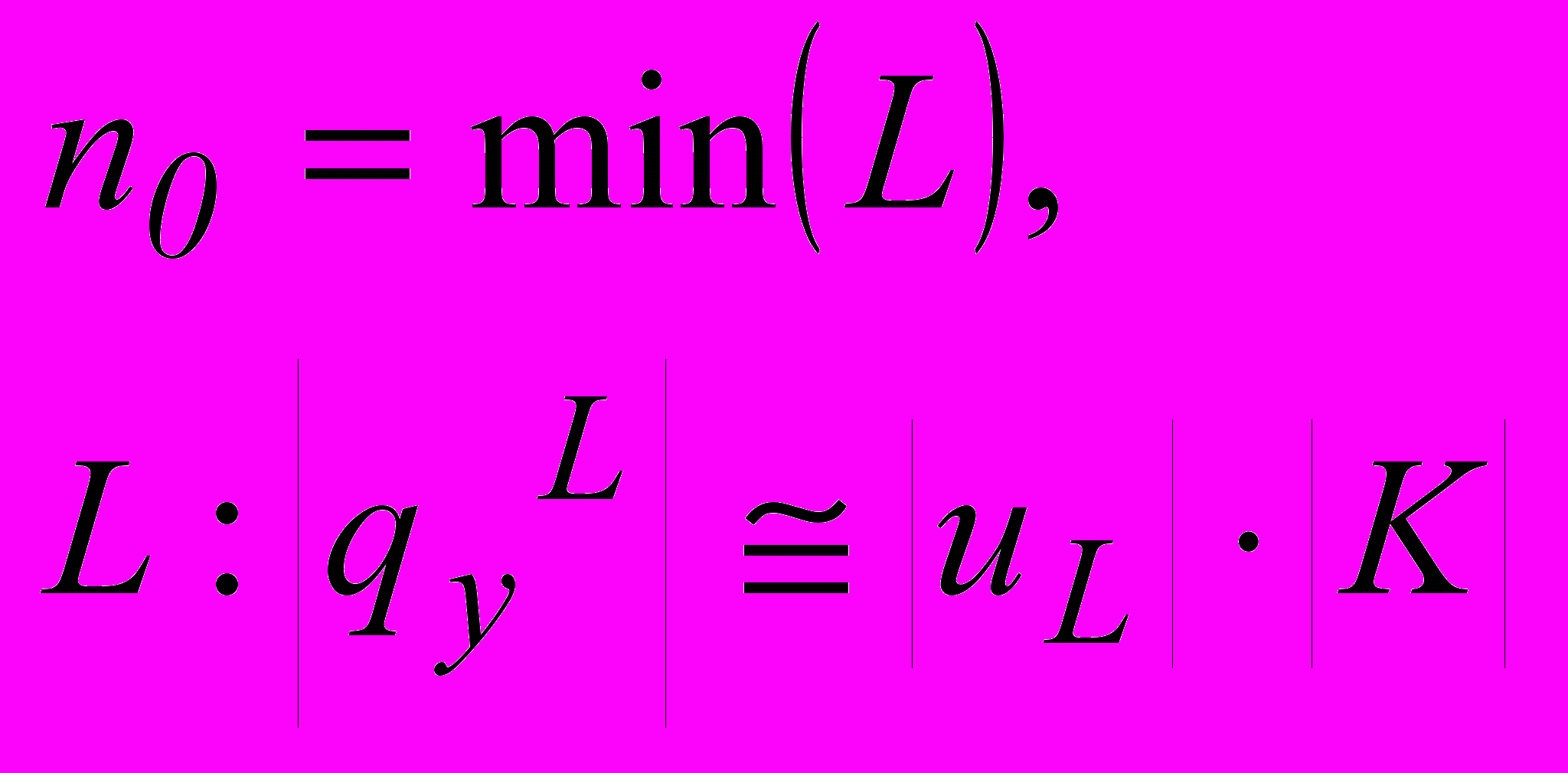 |
| 3. При условиях: мощность множества открытых текстов длины L равна |UL|2HL; все варианты сообщений u(i) и y(i) длины L равновероятны; мощность множества шифротекстов |Y| оценивается как VL, где V=V(L) . | 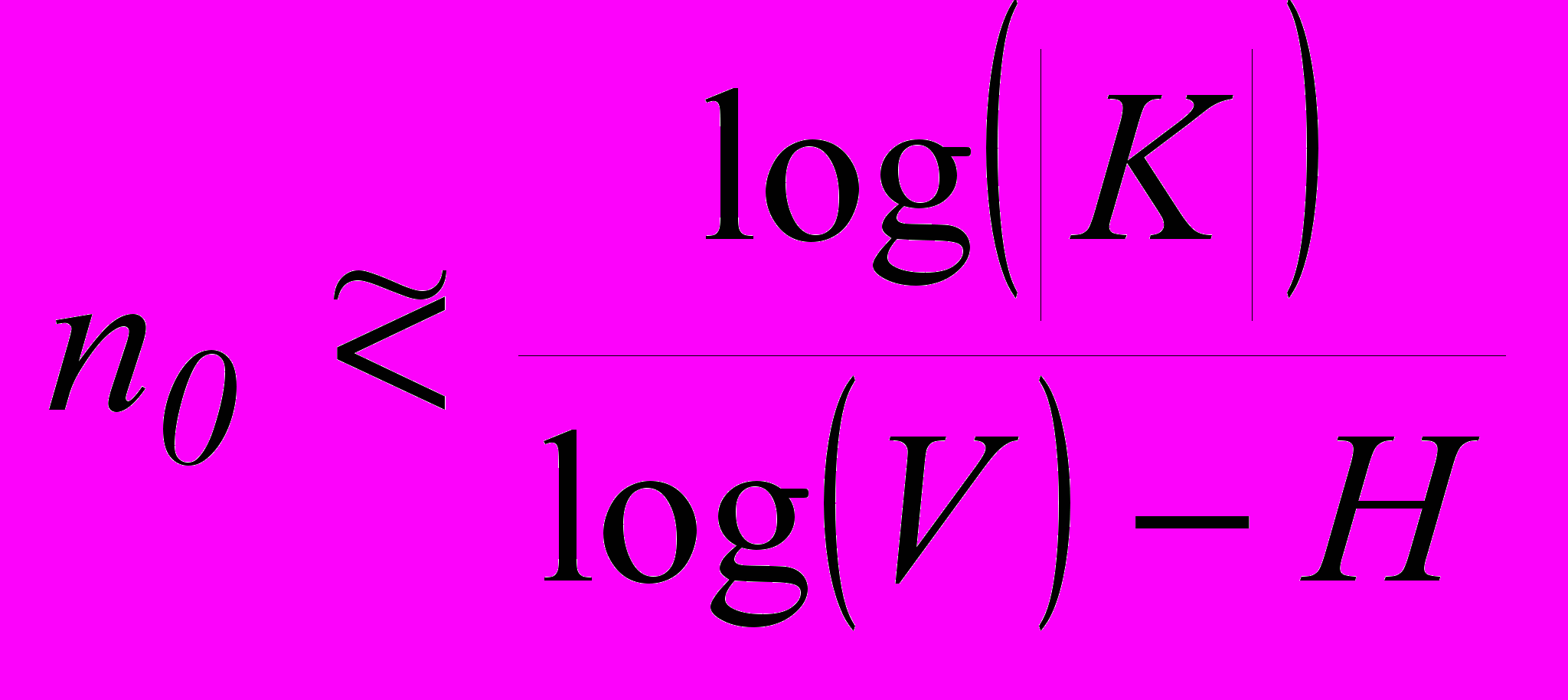 |
В таблице использованы следующие обозначения: H – удельная энтропия на один символ открытого текста; qu , qy – число символов в алфавитах открытого и шифротекста; K – множество всех допустимых ключей шифра.
Из описания приведенных выше подходов [2], по-видимому, следует, что при их применении для оценки величины расстояния единственности требуется знать некоторые вероятностные характеристики входных и выходных текстов шифра (например, удельную энтропию H), достоверно определяемых эмпирически по значительному объему реализаций этих текстовых последовательностей.
Оценка РЕ n0 в рамках предложенного в работе [3] подхода осуществляется через базовые параметры (БП) открытого u, зашифрованного y и совместного uy текстов шифратора КС. ММ шифратора в этом случае строилась как дискретная динамическая система в форме синхронного детерминированного дискретного автомата, входной и выходной текстовые сигналы которого могут быть как скалярными, так и векторными.
По аналогии с условной энтропией Шеннона, в терминах базовых параметров следующее выражение «c выхода на вход » (функция ненадежности) выражается через соответствующие энтропии:
E(u/y) = E(uy) – E(y) = nuyklog(quy) + r(nuylog(quy) – nylog(qy)), (4)
где {k, (qu, nu)}, {r, (qy, ny)}, {(k+r), (quy, nuy)} – размерности и БП соответственно входного, выходного и совместного сигналов шифратора.
Из условия E(u/y) = 0, при котором неопределенность открытого текста обращается в нуль, находится размерность ny* Источника шифротекста, однозначным образом воспроизводящего шифротекст на участке одного «гена»:
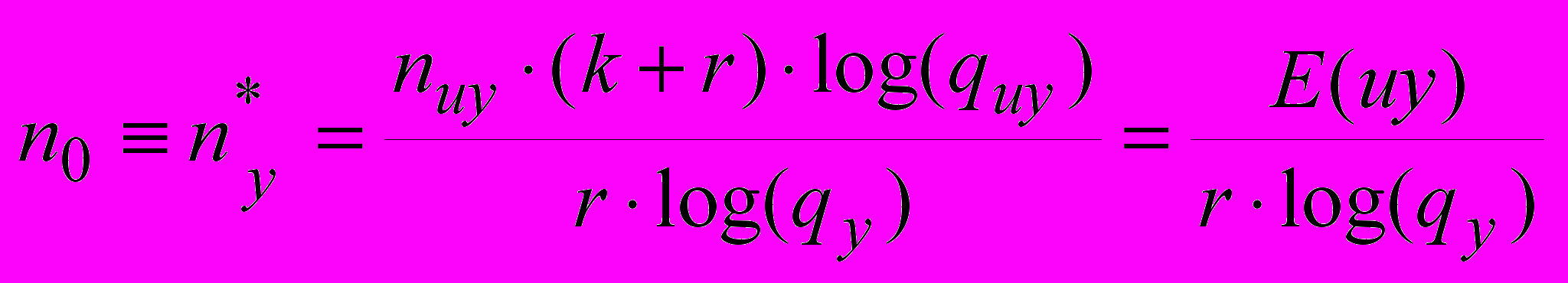 . (5)
. (5)Предложенный подход [3] позволяет производить оценку параметров «функции ненадежности» и «расстояния единственности» для шифратора КС в форме ММ синхронного детерминированного дискретного автомата через измеряемые практически БП его входного, выходного и взаимного (вместо ненаблюдаемого внутреннего) текстов, которые, в отличие от рассмотренных выше подходов [2], могут являться как скалярными, так и векторными последовательностями.
- Шеннон К. Работы по теории информации и кибернетике. Пер. Писаренко В.Ф.– М.: Иностранная литература, 1963.
- Бабаш А.В., Шанкин Г.П. Криптография. – М.: СОЛОН-Р, 2002.
- Горбунов А.А., Кирьянов К.Г. //Вестник ННГУ им. Н.И. Лобачевского. Серия «Радиофизика». 2005. Вып. 1 (3). С. 185.
Использование систем синхронизации генераторов ПСП
в детекторах ошибок устройств контроля
цифровых каналов связи.
В.В.Акулов1), К.Г.Кирьянов2)
1)ФГУП ННИПИ «Кварц», 2) Нижегородский госуниверситет.
В работе рассмотрены уравнения динамики и примеры практического использования систем синхронизации генераторов ПСП в анализаторах ошибок (устройствах измерения верности передачи информации в цифровых трактах) при контроле каналов связи.
Детектор ошибок решает следующие задачи:
- формирование внутренней тест-последовательности;
- синхронизация внутренней тест-последовательности с входной внешней тест-последовательностью;
- выделение ошибок из входной тест-последовательности путем сравнения входной внешней и внутренней тест-последовательностей;
- подсчет количества ошибок счетчиком ошибок.
Тест-последовательность подается на объект контроля, с которого поступает на анализатор ошибок, для проверки качества работы объекта контроля. В качестве тест-последовательности наиболее часто используется псевдослучайная последовательность (ПСП) максимальной длины (М-последовательность).
Известны устройства для детектирования ошибок [1,2], в которых используются систематические свойства М-последовательностей, которые позволяют достаточно точно проводить измерение количества ошибок. Недостатком таких устройств является недостаточная помехоустойчивость – невозможность синхронизации при приеме входной внешней М-последовательности с большим средним по времени коэффициентом ошибок
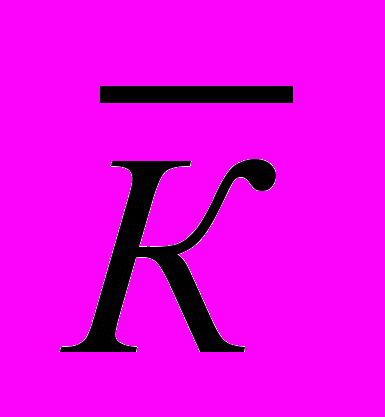 ош. вх. max . На основании анализа уравнений динамики систем синхронизации генераторов ПСП предложены детекторы ошибок с возможностью измерения коэффициентов ошибок от 0 до 1, повышенной надежности и минимальным временем входа в синхронизм.
ош. вх. max . На основании анализа уравнений динамики систем синхронизации генераторов ПСП предложены детекторы ошибок с возможностью измерения коэффициентов ошибок от 0 до 1, повышенной надежности и минимальным временем входа в синхронизм.- Авторское свидетельство СССР № 1251335 кл. Н04В3/46, 1985 г. В. С. Балан, М.С Гроссман. Устройство для детектирования ошибок.
- Заявка на изобретение СССР № 4832472/09 (059243) от 29.05.90 г., МК.5 Н04В3/46. Устройство для детектирования ошибок.
- К.Г.Кирьянов, В. В. Акулов, А. С. Меднов, АС №1709542