
Дейт К. Д27 Руководство по реляционной субд db2/ Пер с англ и предисл. М. Р. Когаловского
| Вид материала | Руководство |
- Рич Р. К. Политология. Методы исследования: Пер с англ. / Предисл. А. К. Соколова, 6313.17kb.
- Рич Р. К. Политология. Методы исследования: Пер с англ. / Предисл. А. К. Соколова, 6313.29kb.
- Сорокин П. А. С 65 Человек. Цивилизация. Общество / Общ ред., сост и предисл., 11452.51kb.
- The guilford press, 6075kb.
- The guilford press, 6075.4kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Целостная часть реляционной, 213.79kb.
- Дэвид Дайчес, 1633.42kb.
- Mathematics and the search for knowledge morris kline, 498.28kb.
- Лекция №1: Стандарты языка sql, 1420.56kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Манипулирование реляционными, 276.31kb.
ГЛАВА 2
СТРУКТУРА СИСТЕМЫ
2.1. ОСНОВНЫЕ КОМПОНЕНТЫ
Внутренняя структура системы DB2 является весьма сложной, как и следует ожидать от системы, соответствующей современному уровню развития и обеспечивающей все функции, которыми обычно обладают современные СУБД (в том числе, например, управление восстановлением, параллельными процессами, санкционированием доступа и т. д.), и многое сверх того. Однако многие из этих функций не представляют непосредственного интереса для пользователя (в нашем понимании этого термина, т. е. конечного пользователя или прикладного программиста), хотя они и имеют решающее значение для общего функционирования системы. С точки зрения пользователя, систему можно фактически рассматривать как состоящую просто из четырех основных компонентов, которые называются следующим образом6:
Прекомпилятор (PRECOMPILER)
Генератор планов прикладных задач (BIND)
Супервизор стадии исполнения (RUNTIME SUPERVISOR)
Программа управления хранимыми данными (STORED DATA MANAGER).
Функции этих четырех компонентов в общих чертах заключаются и следующем.
Прекомпилятор
Прекомпилятор является препроцессором для языков прикладного программирования (ПЛ/1, КОБОЛ, ФОРТРАН и язык ассемблера). Его функция состоит в том, чтобы проанализировать исходный модуль на любом из этих языков, удалить из него все найденные предложения SQL, заменяя их предложениями CALL входного языка. На стадии исполнения эти предложения CALL будут передавать управление непосредственно супервизору времени исполнения. Из предложений SQL, которые ему встречаются, Прекомпилятор строит модуль запросов к. базе данных (DHRM), который используется в качестве входных данных для генератора планов прикладных задач, рассматриваемого ниже.
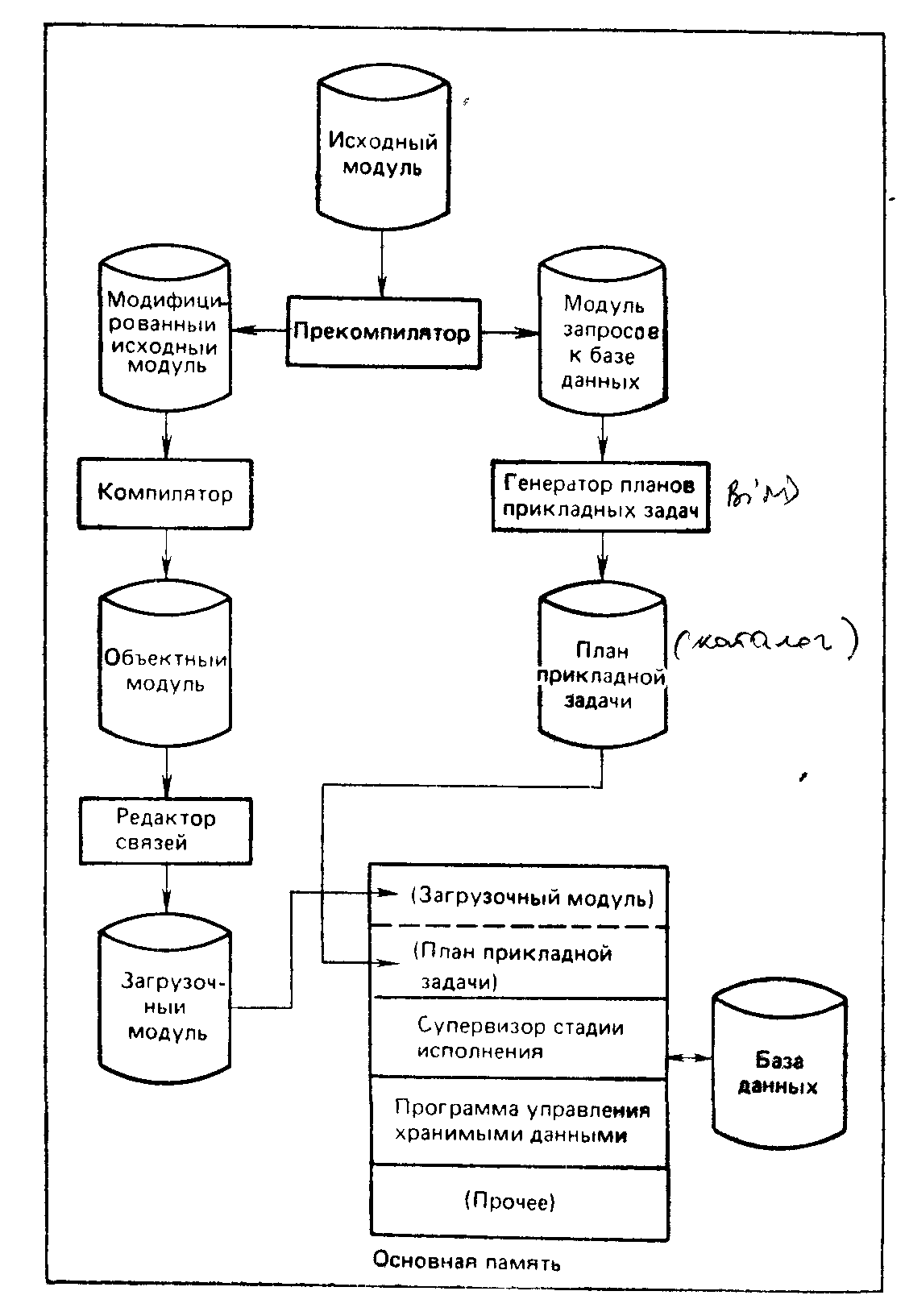
Рис. 2.1. Подготовка и исполнение прикладной задачи системы DB2 (общее представление)
Генератор планов прикладных задач
Функция генератора планов прикладных задач состоит в том, чтобы скомпилировать один или более DBRM и создать тем самым план прикладной задачи. План прикладной задачи содержит необходимые команды машинного кода, реализующие первоначальные предложения SQL, из которых были построены эти DBRM. Он включает, в частности, команды обращения к программе управления хранимыми данными (см. ниже).
Супервизор стадии исполнения
При исполнении прикладной программы супервизор стадии исполнения постоянно находится в основной памяти. Его функции заключаются в том, чтобы следить за исполнением прикладной программы. Когда прикладной программе потребуется выполнить некоторую операцию, связанную с базой данных (говоря нестрого, когда будет необходимо выполнить какое-либо предложение SQL), управление передается сначала супервизору стадии исполнения, который в свою очередь передает его соответствующей части плана прикладной задачи. План прикладной задачи, наконец, передает управление программе управления хранимыми данными.
Программа управления хранимыми данными
Программу управления хранимыми данными можно рассматривать как весьма утонченный метод доступа. Она выполняет все обычные функции метода доступа, например выборку, поиск, обновление, поддержание индекса и т. д. В общих чертах программа управления хранимыми данными — это компонент, управляющий физическими базами данных. Когда во время исполнения его основной задачи необходимо выполнять более детальные функции, такие, как блокирование, запись в журнал, сортировку и т. п., он вызывает другие компоненты более низкого уровня.
На рис. 2.1 сказанное выше подытоживается в форме логической схемы. В следующем разделе основные шаги этого полного процесса будут рассмотрены более подробно.
2.2. ПОДРОБНОЕ ОБСУЖДЕНИЕ ЛОГИКИ УПРАВЛЕНИЯ
Рассмотрим сначала пример программы Р на языке ПЛ/1 (точнее, исходный модуль Р на языке ПЛ/1), которая включает плюс или более предложений SQL. Язык ПЛ/1 здесь взят для определенности. Суммарный процесс остается, по существу, неизменным и для других языков. Прежде чем программа Р может быть скомпилирована компилятором ПЛ/1, она должна быть обработана прекомпилятором (рис. 2.2). Примечание. Если Р содержит также какие-либо предложения CICS (вида ЕХЕС, СICS...;), то она должна быть также обработана препроцессором СICS. Прекомпилятор DB2 и препроцессор CICS могут исполнятся при этом в любом порядке.
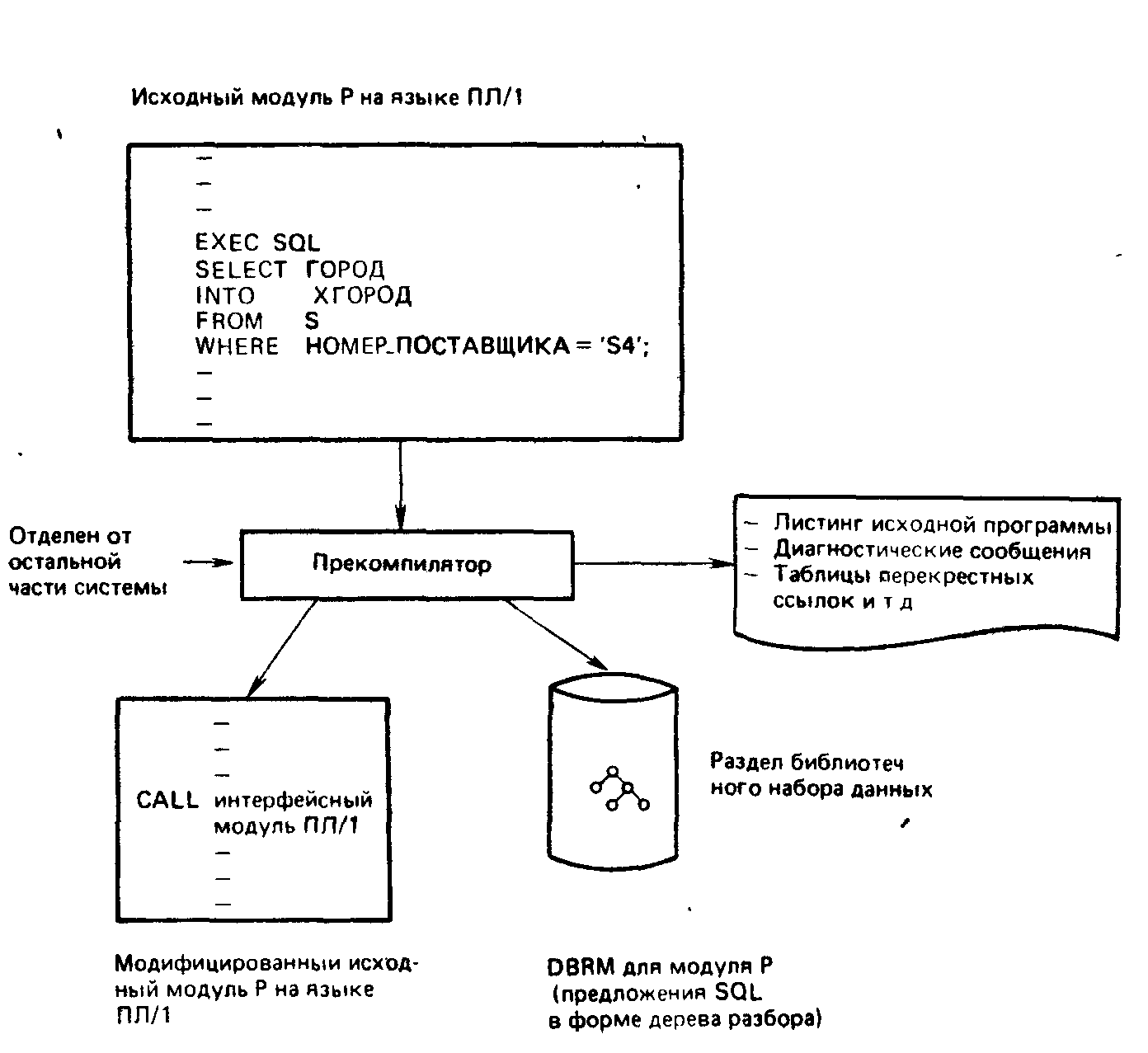
Рис. 2.2. Прекомпиляция
Как указывалось в предыдущем разделе, прекомпилятор DB2 удаляет все найденные им в Р предложения SQL и заменяет7 их предложениями CALL языка ПЛ/1. (Эти предложения CALL осуществляют обращения к интерфейсному модулю ПЛ/1—см. ниже.) Предложения SQL он использует при этом для построения модуля запросов к базе данных (DBRM) программы Р, который хранится вне этой программы как раздел библиотечного набора данных. В DBRM содержится копия первоначальных предложений SQL вместе с внутренней формой этих предложений в виде дерева разбора. Прекомпилятор формирует также листинг исходной программы, содержащий первоначальный исходный текст программы, диагностические сообщения, таблицы перекрестных ссылок и т. д.
Далее, модифицированный исходный модуль на языке ПЛ/1 компилируется и редактируется обычным образом за исключением того, что интерфейсный модуль языка ПЛ/1, который предоставляется системой DB2, должен быть частью входной информации для редактора связей. Условимся называть результат этого шага «загрузочным модулем Р на языке ПЛ/1».
Теперь мы подошли к шагу генератора планов прикладных задач (рис. 2.3).
В действительности, этот компонент является оптимизирующим компилятором. Он преобразует запросы высокого уровня к базе данных (на самом деле, предложения SQL) в оптимизированную машинную программу. Входной информацией для генератора служит множество, состоящее из одного или более DBRM. Таких модулей запросов будет несколько, если первоначальная программа на ПЛ/1 состоит более чем из одной внешней процедуры, т. е. включает несколько исходных модулей. Результат работы генератора, т. е. скомпилированный им код, называется планом прикладной задачи и он хранится в системной базе данных, называемой каталогом8 (о каталоге более подробно пойдет речь в главе 7). Таким образом, главные функции генератора типов прикладных задач состоят в следующем.
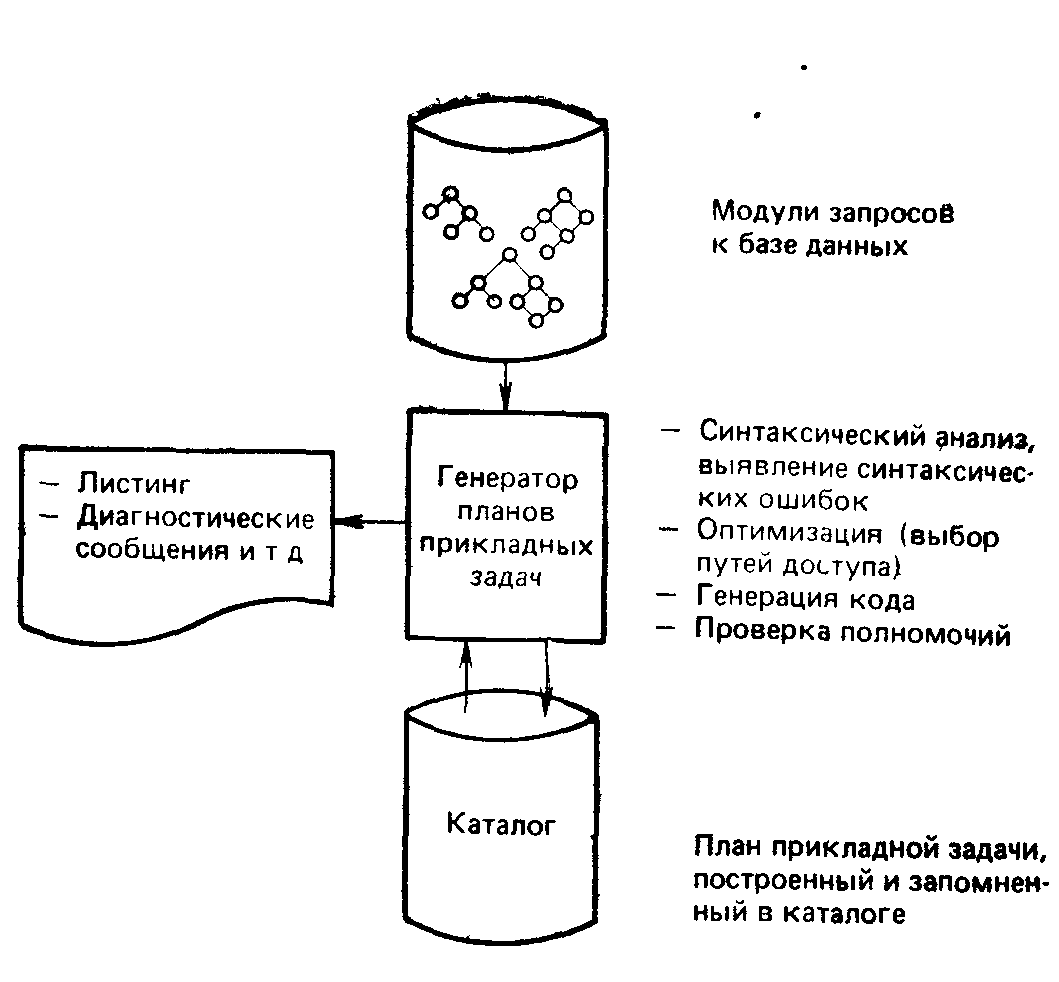
Рис. 2.3. Генератор планов прикладных задач
Выявление синтаксических ошибок
Генератор планов прикладных задач исследует предложения SQL во входных DBRM, осуществляет их синтаксический анализ и выдает сообщения обо всех синтаксических ошибках, которые он обнаружил. Такие проверки необходимы несмотря на то, что подобные проверки уже выполнялись прекомпилятором, поскольку прекомпилятор отделен от остальной части системы DB2. Его исполнение возможно, даже если DB2 недоступна. Он может даже исполняться на другой машине, и его выходные данные автоматически не защищаются. Поэтому нельзя предполагать, что входные данные генератора представляют собой достоверные результаты работы прекомпилятора — пользователь мог построить недопустимый «DBRM» с помощью некоторого другого механизма.
Оптимизация
Важной составной частью генератора планов прикладных задач является оптимизатор. Функция оптимизатора состоит в том, чтобы выбрать для каждого обрабатываемого им манипулятивного предложения SQL оптимальную стратегию реализации этого предложения. Напомним, что предложения манипулирования данными, например SELECT, специфицируют только то, что хочет получить пользователь, а не как добраться до этих данных. Путь доступа, позволяющий добраться к этим данным, будет выбираться оптимизатором. Таким образом, программы независимы от таких путей доступа (дальнейшее обсуждение этой важной проблемы см. в заключении этого раздела).
Рассмотрим в качестве примера предложение SELECT из исходного модуля Р на языке ПЛ/1, приведенного на рис. 2.2. Даже в этом очень простом случае имеется, по крайней мере, два способа выполнения требуемого поиска: 1) путем физически последовательного просмотра (хранимой версии) таблицы S до тех пор, пока не будет найдена запись для поставщика S4; 2) если имеется индекс по столбцу НОМЕР_ПОСТАВЩИКА этой таблицы, что, вероятно, будет иметь место по причинам, которые подробно обсуждаются в Приложениях А и В, то используя этот индекс и, таким образом, непосредственно приходя к записи S4. Оптимизатору предстоит выбрать, какую из этих двух стратегий принять. Обычно оптимизатор будет делать свой выбор на основе следующих соображений: на какие таблицы ссылается данное предложение SQL (их может быть более одной), насколько велики эти таблицы, какие имеются индексы, каковы селективные их возможности, каким образом данные физически группируются на диске, какова форма фразы WHERE в запросе и т. п. Генератор планов прикладных задач будет далее генерировать машинный код, который тесно связан с выбранной оптимизатором стратегией, т. е. в большой степени зависит от нее. Если, например, оптимизатор принимает решение использовать индекс X, то в плане прикладной задачи будут иметься команды машинного языка, которые явно обращаются к индексу X.
Генерация кода
Это процесс фактического построения плана прикладной задачи.
Проверка полномочий
Генератор планов прикладных задач осуществляет также проверку полномочий. Иными словами, он проверяет, позволяется ли лицу, выполняющему генерацию (т. е. пользователю, вызывающему генератор — см. главу 14), производить требуемые в DBRM операции, которые должны быть включены в план прикладной задачи. Вопросы санкционирования доступа будут подробно рассматриваться в главе 9.
Мы подошли, наконец, к процессу исполнения. Поскольку первоначальная программа теперь в действительности разбита на две части (загрузочный модуль и план прикладной задачи), эти две чисти должны быть на стадии исполнения каким-либо образом снова собраны вместе. Рассмотрим, как она работает (см. рис. 2.4).
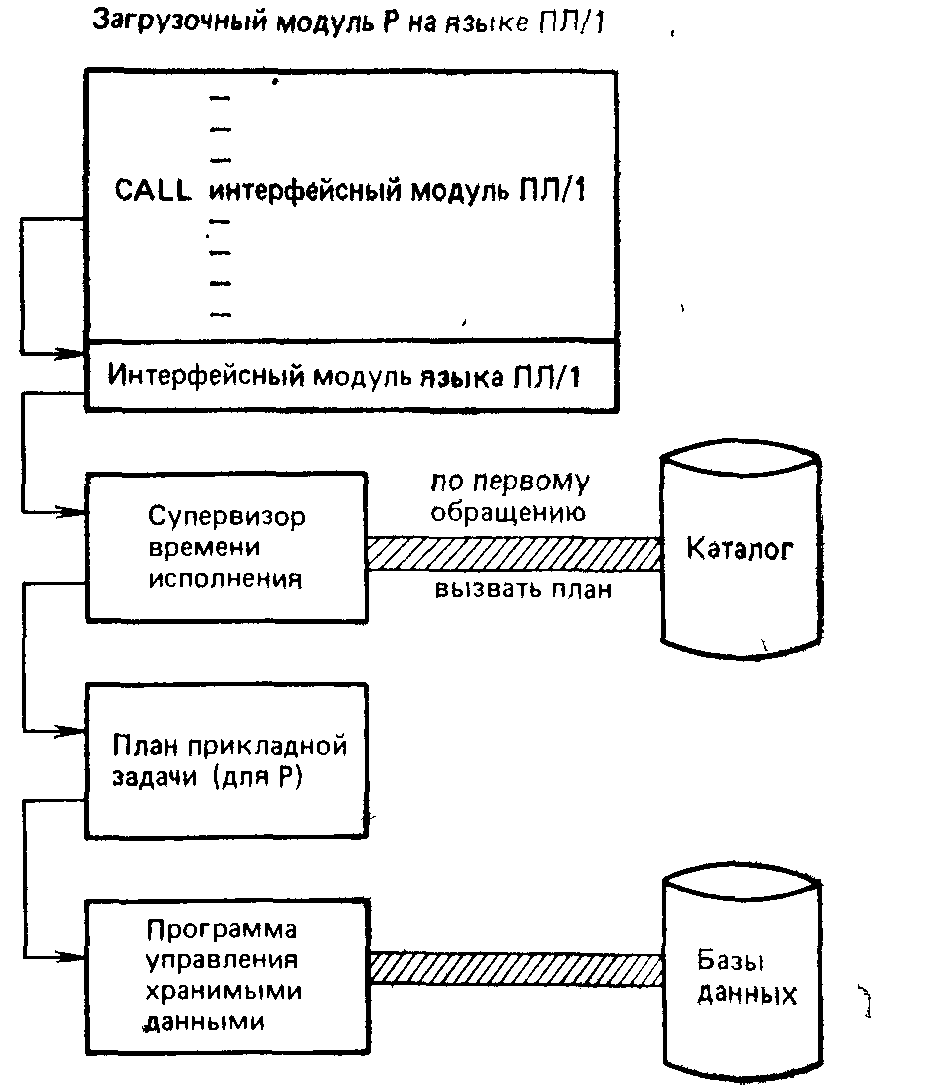
Рис. 2.4. Процесс исполнения
Сначала в основную память загрузится загрузочный модуль Р на языке ПЛ/1 и он обычным образом начиняет исполняться. В конце концов, он достигает первого обращения к интерфейсному модулю языка ПЛ/1. Этот модуль получает управление и в свою очередь передает управление супервизору стадии исполнения. Далее, супервизор стадии исполнения производит поиск плана прикладной задачи в системном каталоге, загружает его в основную память и передает ему управление. План прикладной задачи в свою очередь вызывает программу управления хранимыми данными, которая выполняет необходимые операции над фактически хранимыми данными и возвращает результаты в подходящем виде программе на языке ПЛ/1.
До сих пор в нашем обсуждении умалчивался один чрезвычайно важный момент, который мы теперь поясним. Прежде всего, как уже говорилось, DB2—это компилирующая система. В отличии от нее большинство других систем управления базами данных и, без сомнения, все системы нереляционного типа, насколько известно автору, являются, по существу, интерпретирующими. Далее, компиляция, несомненно, имеет преимущества с точки зрения производительности. Она почти всегда будет давать лучшие характеристики времени исполнения, чем интерпретация. Однако она страдает следующим важным недостатком: возможно, что решения, принятые в процессе компиляции «компилятором» (фактически генератором планов прикладных задач), более не имеют силы на стадии исполнения. Эту проблему иллюстрирует следующий простой пример.
1. Предположим, что программа Р компилируется в понедельник, и генератор планов прикладных задач принимает решение использовать в стратегии для Р индекс, например, индекс X. Тогда план прикладной задачи для Р будет включать, как говорилось ранее, явные обращения к X.
2. В четверг некоторый обладающий полномочиями пользователь издает предложение DROP INDEX X;
3. В пятницу некоторый пользователь пытается исполнить программу Р. Что при этом происходит?
При этом происходит следующее. Когда уничтожается индекс, DB2 исследует все планы прикладных задач в каталоге с тем, чтобы установить, какие из них зависят от этого индекса, если они вообще зависят от индексов. Каждый из таких планов, который он обнаружил, помечается как «недействительный». Когда супервизор стадии исполнения осуществляет выборку такого плана для исполнения, он обнаруживает маркер «недействительный» и поэтому вызывает генератор планов прикладных задач для продуцирования нового плана, т. е. для того, чтобы выбрать какую-либо иную стратегию доступа, а затем перекомпилировать первоначальные предложения SQL, которые были сохранены в каталоге, в соответствии с этой новой стратегией. Если перекомпиляция была успешной, старый план заменяется в каталоге новым, и супервизор стадии исполнения продолжает работу уже с новым планом. Таким образом, весь процесс перегенерации (или «автоматического связывания», как его называют) является «прозрачным для пользователя». Единственный эффект, который может наблюдаться,— это незначительная задержка исполнения первого предложения SQL в программе.
Заметим, что та перекомпиляция, о которой здесь говорилось, это перекомпиляция SQL, а не ПЛ/1. Перекомпилируется не программа на языке ПЛ/1, которая стала недействительной вследствие уничтожения индекса, а лишь план прикладной задачи.
Теперь можно видеть, каким образом становится возможной независимость программ от физических путей доступа, или более определенно, каким образом возможно создавать и уничтожать такие пути доступа без необходимости в то же время изменять программы. Как указывалось ранее, предложения манипулирования данными языка SQL, например SELECT и UPDATE, никогда не включают какого-либо явного упоминания о таких путях доступа. Вместо этого в них просто указывается, в каких данных заинтересован пользователь. Выбор пути, позволяющего добраться до этих данных, а также замена его другим путем, если старый путь более не существует,— это обязанности системы, а в действительности—генератора планов прикладных задач. Будем говорить, что система типа DB2 обеспечивает высокую степень физической независимости данных: пользователь и пользовательские программы не зависят от физической структуры хранимой базы данных. Достоинство такой системы—весьма значительное достоинство—состоит в том, что можно делать изменения в физической базе данных, например по соображениям производительности, не имея необходимости делать какие-либо соответствующие изменения в прикладных программах. В системе, не обладающей такой независимостью, прикладные программисты вынуждены уделять довольно значительную часть времени—доля 50 процентов является весьма типичной—для внесения в существующие программы изменений, которые становятся необходимыми просто вследствие изменений в физической базе данных. Напротив, в системе типа DB2 эти программисты могут сосредоточиться исключительно на производстве новых прикладных задач.
Ещё один момент, касающийся предыдущего вопроса. Наш пример был связан с уничтоженным индексом и это, вероятно, наиболее частый случай на практике. Однако аналогичная последовательность событий имеет место при удалении любого объекта, а не только индекса, а также когда отменяются полномочия пользователя (см. главу 9). Поэтому, например, уничтожение какой-либо таблицы приведет к тому, что все планы, которые обращаются к этой таблице, будут помечены как недействительные. Конечно, автоматическая перегенерация будет работать лишь в том случае, если ко времени, когда ее следует выполнять, была создана другая таблица с тем же именем, что и у старой (и, вероятно, не тогда, когда имеются значительные различия между старой и новой таблицами).
В заключение данной главы отметим, что SQL всегда компилируется в DB2 и никогда не интерпретируется, даже если предложения в запросе вводятся через интерактивный интерфейс DB2I или через QMF. Иными словами, если ввести, например, предложение SELECT с терминала, то этот оператор будет компилироваться, и для него сгенерируется план прикладной задачи. Далее этот план будет исполняться. Наконец, после того как исполнение будет завершено, этот план будет удален. Практический опыт показал, что даже в интерактивном случае при компиляции почти всегда достигается лучшая общая производительность, чем при интерпретации. Достоинство компиляции состоит в том, что процесс физического доступа к требуемым данным осуществляется скомпилированной программой, т. е. программой, которая хорошо приспособлена для конкретного запроса, а не универсальной интерпретирующей программой. Недостаток состоит, конечно, в том что имеются затраты, связанные с компиляцией, т. е. с подготовкой этой хорошо приспособленной программы. Но указанное преимущество почти всегда перевешивает этот недостаток, причем иногда поразительным образом. Только в случае чрезвычайно простого запроса затраты на выполнение компиляции могут быть больше, чем потенциальная экономия. В качестве примера мог бы служить следующий простой запрос: «Осуществить выборку записи поставщика для поставщика S1». Здесь запрашивается единственная конкретная запись при заданном значении для поля, которое уникально идентифицирует эту запись. Обратим внимание, что такой запрос в действительности совсем не использует средств уровня множеств языка SQL.
УПРАЖНЕНИЯ
2.1. Укажите четыре основных компонента системы DB2. Начертите диаграмму, показывающую полный процесс подготовки и исполнения программы в DB2.
2.2. Перечислите четыре главных функции генератора планов прикладных задач.
2.3. Дайте определение физической независимости данных. Объясните, как DB2 обеспечивает такую независимость. Почему желательна физическая независимость данных?
ГЛАВА 3
ОПРЕДЕЛЕНИЕ ДАННЫХ
3.1. ВВЕДЕНИЕ
В этой главе довольно подробно рассматриваются предложения определения данных SQL. Удобно разделить эти предложения на два больших класса, которые весьма грубо можно охарактеризовать как логический и физический. Предложения «логического» класса должны иметь дело с объектами, которые на самом деле представляют интерес для пользователей, например с базовыми таблицами и представлениями, а «физического»— с объектами, которые представляют интерес, главным образом, для системы, например дисковые тома. Нет нужды говорить о том, что в действительности дело обстоит не настолько ясно, насколько предусматривается в этой простой классификации—некоторые «логические» предложения включают параметры, которые по своей природе в действительности являются «физическими», и наоборот. Кроме того, некоторые предложения не попадают строго в какую-либо одну из этих категорий. Тем не менее такая классификация удобна как вспомогательное средство для понимания, и мы будем ее сейчас использовать. В данной главе рассматривается только «логическое» определение данных.
Ниже перечислены основные предложения логического определения данных:
CREATE TABLE CREATE VIEW CREATE INDEX
(создать таблицу) (создать представление) (создать индекс)
ALTER TABLE
(изменить таблицу)
DROP TABLE DROP VIEW DROP INDEX
(уничтожить таблицу) (уничтожить представление) (уничтожить индекс)
(Примечание. Имеется также предложение ALTER INDEX (изменить индекс), но оно полностью попадает в «физическую» категорию. Предложения ALTER VIEW (изменить представление) нет.) Обсуждение предложений CREATE VIEW и DROP VIEW отложим до восьмой главы. Остальные указанные выше предложения рассматриваются в настоящей главе.
3.2. БАЗОВЫЕ ТАБЛИЦЫ
Базовая таблица — (важный) специальный случай более общего понятия «таблица». Поэтому давайте начнем с того, что несколько уточним это более общее понятие.
Определение
В реляционной системе таблица состоит из строки заголовков столбцов и нуля или более строк значений данных (число строк данных может быть каждый раз разным). Для заданной таблицы:
а) Строка заголовков столбцов специфицирует один или более столбцов, задавая наряду с прочим тип данных для каждого из них;
б) Каждая строка данных содержит в точности одно значение данных для каждого из столбцов, специфицированных в строке заголовков столбцов. Кроме того, все значения в заданном столбце имеют один и тот же тип, а именно: тип данных, специфицированный для этого столбца в строке заголовков столбцов.
В связи с предыдущим определением следует коснуться двух моментов.
1. Отметим, что в этом определении нет никакого упоминания об упорядочении строк. Строго говоря, строки реляционной таблицы считаются неупорядоченными. (Отношение — это математическое множество—множество строк, а множество в математике не обладает каким-либо упорядочением.) Как мы увидим, можно, однако, задавать некоторый порядок для этих строк, когда осуществляется их выборка в ответ на запрос, но такое упорядочение следует считать не чем иным, как удобством для пользователя. Оно не существенно для понятия таблицы.
2. В отличие от строк столбцы таблицы предполагаются упорядоченными слева направо. (По крайней мере, они считаются упорядоченными таким образом в большинстве систем, в том числе в DB2). В таблице S, например (рис. 1.3), столбец НОМЕР-ПОС-ТАВЩИКА — первый столбец, ФАМИЛИЯ — второй столбец и т. д. Однако на практике существует очень немного ситуаций, когда такое упорядочение слева направо является существенным. Подобных ситуаций можно избегать при некоторой дисциплине, и это рекомендуется делать, как будет показано позднее.
Обратимся теперь, в частности, к базовым таблицам. Базовая таблица — это автономная именованная таблица. Под «автономностью» понимается то, что эта таблица существует сама по себе в отличие от представления, которое существует не само по себе, а является производным от одной или нескольких базовых таблиц. Представление служит просто альтернативным способом рассмотрения этих базовых таблиц. Под «именованной» понимается, что этой таблице с помощью соответствующего предложения CREATE явно задается некоторое имя в отличие от таблицы, которая строится как результат запроса и не имеет сама по себе какого-либо явного имени. Такая таблица существует в течение непродолжительного времени. Примерами такого рода неименованных таблиц служат две таблицы результатов, приведенные на рис. 1.1.
Предложение CREATE TABLE
Теперь мы в состоянии подробно обсудить предложение CREATE TABLE. Это предложение имеет следующий общий формат:
CREATE TABLE имя—базовой—таблицы
(определение—столбца [, определение—столбца] . . . )
[другие—параметры];
Здесь «определение—столбца» в свою очередь имеет формат:
имя—столбца тип—данных [NOT NULL]
Факультативные «другие — параметры» имеют дело главным образом с проблемами физического хранения и кратко обсуждаются в главе 13. Примечание. В этой книге прямые скобки в синтаксических определениях используются для того, чтобы указать, что конструкции, заключенные в эти скобки, являются необязательными (т. е. могут быть опущены). Многоточие указывает, что непосредственно предшествующая ему синтаксическая единица факультативно может повторяться один или более раз. Конструкции, представленные прописными буквами, должны быть записаны в точности так, как показано. Наконец, конструкции, представленные строчными буквами, должны заменяться конкретными значениями, выбранными пользователем.
Ниже приведен пример предложения CREATE TABLE для таблицы S, теперь уже в полном виде:
CREATE TABLE S
-
(НОМЕР_ПОСТАВЩИКА
CHAR (5) NOT NULL,
ФАМИЛИЯ
CHAR (20),
СОСТОЯНИЕ
SMALLINT,
ГОРОД
CHAR (15));
Результат этого предложения состоит в том, что создается новая пустая базовая таблица, названная xyz.S, где xyz — имя, под которым известен системе пользователь, издающий предложение CREATE TABLE (см. главу 9). В системный каталог при этом помещается статья, описывающая эту таблицу. Пользователь xyz может обращаться к таблице по ее полному имени xyz.S или по сокращенному имени S. Другие пользователи должны обращаться к ней только по ее полному имени. Данная таблица состоит из четырех столбцов с именами xyz.S.НОМЕР_ПОСТАВЩИКА, xyz.S.ФАМИЛИЯ, хуг.S.СОСТОЯНИЕ и хуг.S.ГОРОД, имеющих указанные в определении типы данных. (Типы данных будут рассматриваться ниже). Пользователь xyz может обращаться к этим столбцам по их полным или по сокращенным именам: S.HOMEP-ПОСТАВЩИКА, S.ФАМИЛИЯ, S.СОСТОЯНИЕ и S.ГОРОД. Другие пользователи должны применять только полные имена столбцов. Заметим, однако, что независимо от того, включается ли в имя часть «xyz», часть «S» может быть опущена, если это не приводит к двусмысленности, но ее включение никогда не является ошибкой. Вообще относительно имен справедливы следующие правила. Имена пользователей, например xyz, являются уникальными во всей системе. Имена таблиц (неуточненные) уникальны для пользователя. Имена столбцов (неуточненные) уникальны для таблицы9. Под «таблицей» здесь понимаются как базовые таблицы, так и представления. Таким образом, представление не может иметь такое же имя, как и базовая таблица.
После того как таблица создана, в нее могут быть введены данные с помощью предложения INSERT (вставить) языка SQL, которое обсуждается в главе 6, или утилиты загрузки системы DB2, рассматриваемой в главе 14.
Типы данных
| Система DB2 | поддерживает следующие типы данных: |
| INTEGER | — двоичное целое число, занимающее полное машинное слово, 31 бит со знаком |
| SMALLINT | — двоичное целое число, занимающее полуслово, 15 бит со знаком |
| DECIMAL (p, q) | — упакованное десятичное число, включающее р цифр и знак (0 < р < 16); предполагается q цифр справа от десятичной точки (q < р; если q = 0, она может быть опущена) |
| FLOAT | — число n с плавающей точкой, занимающее двойное слово и представленное шестнадцатеричной мантиссой f с точностью до 15 знаков (—1 < f < +1) и двоичным целочисленным порядком е (—65<е < +64) таким образом, что n= = f* (16 * * е); примерный диапазон значений (По абсолютной величине — Примеч. пер.) n — от 5.4Е—79 до 7.2Е + 75; см. также ниже пояснения для констант типа FLOAT |
| CHAR (n) | — литерная строка фиксированной длины из n литер (О < n < 255) |
| VARCHAR (n) | — литерная строка переменной длины, не превышающей n литер (0 < n; максимальное значение n зависит от ряда факторов, но в общем случае должно быть меньше, чем «размер страницы» — 4К либо 32K — пространства, содержащего данную таблицу — см. главу 13)10. |
Константы
Хотя это и в некоторой степени отступление от основной темы данной главы, сейчас удобно рассмотреть различные виды констант, которые поддерживаются в DB2:
| целочисленная | — записывается как десятичное целое число со знаком или без знака, без десятичной точки; примеры: 4 —95 +364 О |
| десятичная | — записывается как десятичное число со знаком или без знака, с десятичной точкой; примеры: 4,0 —95.7 +364.05 0.007 |
| с плавающей точкой | — записывается как десятичная константа, за которой следует буква Е с последующей целочисленной константой; примеры: 4ЕЗ —95.7Е46 +364Е—5 0.7Е1 (примечание: выражение хЕу представляет значение х*(10**у)) |
| строковая | — записывается либо как строка литер, заключенная в одиночные кавычки, либо как строка пар шестнадцатеричных цифр, представляющих рассматриваемые литеры в коде EBCDIC, заключенная в одиночные кавычки, которой предшествует буква X; примеры: '123 Main St.' 'PIG' X'F1F2F340D481899540E2A34B' X'D7C9C7' (первый и третий примеры представляют одно и то же значение, так же как второй и четвертый) |
Неопределенное значение
Вернемся теперь к основной теме данной главы. Система DB2 поддерживает концепцию неопределенного значения данных. Фактически любой столбец может содержать неопределенное значение, если в определении этого столбца в предложении CREATE TABLE явным образом не специфицировано NOT NULL (неопределенное значение не допускается). Неопределенное значение— это специальное значение, которое используется для того, чтобы представлять «неизвестное значение» или «неприменимое значение». Это не то же самое, что пробел или ноль. Например, запись поставки может содержать неопределенное значение поля КОЛИЧЕСТВО (известно, что поставка имела место, но неизвестен объем поставки). Запись поставщика может также содержать неопределенное значение в столбце СОСТОЯНИЕ (может быть, например, что СОСТОЯНИЕ не соотносится по некоторой причине поставщикам в Сан-Хосе).
Вернемся к предложению CREATE TABLE для базовой таблицы S. Мы специфицировали NOT NULL только для столбца НОМЕР_ПОСТАВЩИКА. Результатом этой спецификации является гарантия того, что запись каждого поставщика в базовой таблице S всегда будет содержать какой-либо реальный (отличный от неопределенного значения) номер поставщика. Напротив любое из значений ФАМИЛИЯ, СОСТОЯНИЕ и ГОРОД или все они могут быть неопределенными в той же самой записи. (Причины нашего требования о том, чтобы номера поставщиков не имели неопределенных значений, станут ясны в Приложениях А и В.)
Столбец, который может принимать неопределенные значения, физически представляется в хранимой базе данных двумя столбцами: самим столбцом данных и скрытым столбцом индикатора с длиной значений в один байт, который хранится как префикс к столбцу фактических данных. Значение X'FF' в столбце индикатора указывает, что соответствующее значение в столбце данных следует игнорировать, т. е. принять его за неопределенное значение. Значение Х'00' в столбце индикатора указывает, что в качестве соответствующего значения столбца данных следует принять его действительное значение.
Более подробно о неопределенных значениях пойдет речь в главах 4, 5, 6 и 10, а также в Приложении В.
Предложение ALTER TABLE
Точно так же, как в любое время можно с помощью предложения CREATE TABLE создать новую базовую таблицу, можно также в любое время изменить существующую базовую таблицу, добавляя к ней справа новый столбец. Для этого используется предложение ALTER TABLE:
ALTER TABLE имя—базовой— таблицы
ADD имя—столбца тип—данных;
Например:
ALTER TABLE S
ADD СКИДКА SMALLINT;
Это предложение добавляет к таблице S столбец СКИДКА. Все существующие записи таблицы S расширяются с четырех значений полей данных до пяти, и во всех случаях новое пятое поле принимает неопределенное значение. Спецификация NOT NULL в предложении ALTER TABLE не допускается. Заметим, между прочим, что только что описанное расширение существующих записей, не означает, что в это время физически обновляются записи в базе данных. Изменяется лишь хранимое в каталоге, описание таблицы. Отдельные записи физически не изменяются до тех пор, пока они в следующий раз не станут целевыми для предложения UPDATE языка SQL (см. главу 6).
Предложение DROP TABLE
Существующую базовую таблицу можно в любое время уничтожить с помощью предложения:
DROP TABLE имя—базовой—таблицы;
Специфицированная базовая таблица удаляется из системы (точнее, из каталога удаляется описание этой таблицы). Автоматически удаляются также все индексы и представления, определенные над этой базовой таблицей.
3.3. ИНДЕКСЫ
Подобно базовым таблицам индексы создаются и уничтожаются путем использования предложений определения данных языка SQL. Однако CREATE INDEX и DROP INDEX (а также alter INDEX и некоторые предложения управления данными) вообще являются единственными предложениями в языке SQL, в которых имеются ссылки на индексы. Другие предложения, в частности предложения манипулирования данными, такие, как SELECT, намеренно не включают каких-либо таких ссылок. Решение о том, использовать или не использовать какой-либо индекс при обработке некоторого конкретного запроса в языке SQL, принимается не пользователем, а системой DB2 (фактически оптимизатором — составной частью генератора планов прикладных задач), как указывалось в главе 2.
Предложение CREATE INDEX имеет следующий общий формат:
CREATE [UNIQUE] INDEX имя—индекса
ON имя—базовой—таблицы (имя—столбца [упорядочение]
[имя—столбца [упорядочение]] . . .)
[другие—параметры] ;
Факультативные «другие — параметры» имеют отношение к проблемам физического хранения, как и в случае предложения CREATE TABLE. Каждая спецификация «упорядочение» представляет собой либо ASC (возрастание), либо DESC (убывание). Если не специфицировано ни ASC, ни DESC, то по умолчанию предполагается ASC. Последовательность указания имен столбцов в предложении CREATE INDEX соответствует обычным образом упорядочению от старшего к младшему. Например, предложение
CREATE INDEX X ON В (Р, Q DESC, R)
создает индекс с именем Х над базовой таблицей В, в котором статьи упорядочиваются по возрастанию значений R в рамках убывающих значений Q в рамках возрастающих значений Р. Столбцы Р, Q и R не обязательно должны быть смежными. Не обязательно также, чтобы все они имели один и тот же тип данных. Наконец, не обязательно, чтобы все они были фиксированной длины.
После того как индекс создан, он автоматически поддерживается (программой управления хранимыми данными) с тем, чтобы отражать все обновления базовой таблицы, до тех пор, пока этот индекс не будет уничтожен.
Факультативный параметр UNIQUE (уникальный) в предложении CREATE INDEX специфицирует, что никаким двум записям к индексируемой базовой таблице не позволяется принимать одно и то же значение для индексируемого поля (или комбинации полей) в одно и то же время. В случае базы данных поставщиков и деталей, например, мы специфицировали бы, вероятно, следующие индексы с параметром UNIQUE:
CREATE UNIQUE INDEX XS ON S (НОМЕР_ПОСТАВЩИКА);
CREATE UNIQUE INDEX XP ON P (НОМЕР_ДЕТАЛИ);
CREATE UNIQUE INDEX XSP ON SP (НОМЕР_ПОСТАВЩИКА,
НОМЕР_ДЕТАЛИ);
Индексы, подобно базовым таблицам, могут создаваться и уничтожаться в любое время. В приведенном примере, однако, нам хотелось бы, вероятно, создать индексы XS, XP и XSP в то же время, когда создаются сами базовые таблицы S, Р и SP. Если же эти базовые таблицы будут непустыми в то время, когда издается предложение CREATE INDEX, ограничения уникальности могут уже оказаться нарушенными. Попытка создания индекса с параметром UNIQUE над таблицей, которая в настоящее время не удовлетворяет ограничению уникальности, будет завершаться неудачно.
Примечание. Два неопределенных значения считаются равными друг другу для целей индексирования с параметром UNIQUE. Смысл этого довольно загадочного замечания состоит в том, что неопределенные значения не всегда рассматриваются как эквивалентные друг другу во всех контекстах. Обсуждение этого вопроса содержится в главе 4.
Над одной и той же базовой таблицей может быть построено любое число индексов. Например, другой индекс для таблицы S:
CREATE INDEX XSC ON S (ГОРОД);
В этом случае не было специфицировано UNIQUE, поскольку множество поставщиков может находиться в одном и том же городе.
Предложение уничтожения индекса имеет вид:
DROP INDEX имя—индекса;
в результате индекс уничтожается, т. е. его описание удаляется из каталога. Если какой-либо существующий план прикладной задачи зависит от этого уничтоженного индекса, то (как указывалось в главе 2) этот план будет помечен как недействительный супервизором стадии исполнения. Когда этот план будет в дальнейшем вызываться для исполнения, супервизор стадии исполнения автоматически вызовет генератор планов прикладных задач с тем, чтобы сгенерировать заменяющий его план, который поддерживал бы первоначальные предложения SQL, не используя исчезнувший теперь индекс. Этот процесс полностью скрыт от пользователя.
Поскольку уже говорилось о том, что система DB2 осуществляет автоматическую перегенерацию планов прикладных задач, если уничтожается существующий индекс, читатель может пожелать узнать, будет ли также выполняться автоматическая перегенерация, если создается какой-нибудь новый индекс. Ответ отрицателен, этого не делается. Причина такого положения вещей заключается в отсутствии в этом случае какой-либо гарантии относительно того, что перегенерация на самом деле будет полезной. Автоматическая перегенерация могла бы означать просто много не необходимой работы, т. к. существующие планы прикладных задач могут быть уже основанными на оптимальной стратегии. Иная ситуация с предложением DROP. Некоторый план просто не будет работать, если он предусматривает использование несуществующего индекса. И в этом случае перегенерация является необходимой. Следовательно, если создается новый индекс и имеется некоторый план, который, как Вы подозреваете, целесообразно заменить, то запрос на явную перегенерацию этого плана на Вашей ответственности. Явная перегенерация обсуждается в главе 14.
3.4. ОБСУЖДЕНИЕ
Возможность исполнения предложений определения данных в любое время делает систему DB2 очень гибкой. В более старых (нереляционных) системах добавление нового типа объекта, например нового типа записей, нового индекса или нового поля, представляет собой операцию, выполнить которую не так легко. Оно требует обычно приведения всей системы в состояние остановки, разгрузки базы данных, изменения и перекомпиляции определения базы данных и, наконец, перезагрузки базы данных к соответствии с этим измененным определением. В такой системе весьма желательно выполнить процесс определения данных раз и навсегда, прежде чем начать их загрузку и использование. Это означает, что: а) для того чтобы система была установлена и стала действующей, могут потребоваться в буквальном смысле месяцы или даже годы работы высококвалифицированных специалистов и б) после того как система стала функционировать, может быть трудно и дорого, а может быть и невозможно, исправить ранние ошибки проектирования.
Напротив, в DB2 можно создать и загрузить совсем немного базовых таблиц, а затем немедленно начать использовать эти данные. Позднее постепенно могут добавляться новые базовые таблицы и новые поля, не оказывая какого-либо влияния на существующих пользователей базы данных. Можно также проводить эксперименты с результатами использования или отказа от каких-либо конкретных индексов, опять-таки совсем не оказывая влияния на существующих пользователей, не считая, конечно, производительности. Более того, как будет показано в главе 8, при определенных условиях можно даже произвести реструктуризацию базы данных, например перенести некоторое поле из одной таблицы в другую, и все же не затронуть логики существующих программ. Короче говоря, нет необходимости в осуществлении полного процесса проектирования базы данных, прежде чем с помощью системы можно будет сделать какую-либо полезную работу. Нет также и необходимости в том, чтобы получать все прямо с первого раза. Система DB2 снисходительна.
Предостережение. Не следует полагать, однако, что снисходительность системы означает отсутствие необходимости проектирования базы данных. Конечно, проектирование базы данных все же необходимо. Однако:
— не обязательно выполнять его полностью единовременно;
— не требуется, чтобы оно было совершенным с первого раза;
— можно взяться за логическое и физическое проектирование раздельно;
— если изменяются потребности, то проект может быть также изменен сравнительно безболезненно;
— в системе, подобной DB2, становятся осуществимыми многие новые приложения, типичным образцом которых являются небольшие прикладные задачи, требующие, например, базу данных сотрудников или отделов. Подобные приложения просто никогда не рассматривались в обстановке более старых (нереляционных) систем, поскольку эти системы были слишком сложны для того, чтобы такие приложения имели смысл с экономической точки зрения.
УПРАЖНЕНИЯ
3.1. На рис. 3.1 приведены некоторые примеры значений данных для базы данных, содержащей информацию, касающуюся поставщиков (таблица S), деталей (таблица Р) и проектируемых изделий (таблица J). Поставщики, детали и изделия уникально идентифицируются при этом соответственно номером поставщика, номером детали и номером изделия. Смысл записей таблицы SPJ состоит в том, что специфицированый поставщик поставляет специфицированную деталь для специфицированного проектируемого изделия в специфицированном количестве. Комбинация НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ и НОМЕР_ИЗДЕЛИЯ уникально идентифицирует такие записи. Напишите для этой базы данных соответствующее множество предложений CREATE TABLE.
Примечание. Эта база данных будет использоваться в ряде упражнений в последующих главах.
3.2. Запишите множество предложений CREATE INDEX для базы данных из упражнения 3.1 таким образом, чтобы привести в действие требуемые ограничения уникальности.
3.3. В чем состоят основные достоинства индексов? В чем их основные недостатки?
3.4. «Уникальность» поля или комбинации полей — логическое свойство, но оно реализуется в системе DB2 с помощью индекса, который является физической конструкцией. Выскажите Ваше мнение по этому вопросу.
ОТВЕТЫ К НЕКОТОРЫМ УПРАЖНЕНИЯМ
3.1. CREATE TABLE S
(НОМЕР_ПОСТАВЩИКА CHAR(5) NOT NULL,
ФАМИЛИЯ CHAR(20),
СОСТОЯНИЕ SMALLINT,
ГОРОД CHAR(15));
| S | НОМЕР_ПОСТАВЩИКА | ФАМИЛИЯ | СОСТОЯНИЕ | ГОРОД |
| | S1 S2 S3 S4 S5 | Смит Джонс Блейк Кларк Адамс | 20 10 30 20 30 | Лондон Париж Париж Лондон Атенс |
| P | НОМЕР_ДЕТАЛИ | НАЗВАНИЕ | ЦВЕТ | BEС | ГОРОД |
| | Р1 Р2 РЗ Р4 Р5 Р6 | Гайка Болт Винт Винт Кулачок Блюм | Красный Зеленый Голубой Красный Голубой Красный | 12 17 17 14 12 19 | Лондон Париж Рим Лондон Париж Лондон |
| J | НОМЕР_ИЗДЕЛИЯ | НАЗВАНИЕ | ГОРОД |
| | J 1 J2 J3 J4 J5 J6 J7 | Сортировщик Перфоратор Считыватель Консоль Сортировочно-подборочная машина Терминал Лента | Париж Рим Атенс Атенс Лондон Осло Лондон |
| SPJ | НОМЕР_ПОСТАВЩИКА | НОМЕР_ ДЕТАЛИ | НОМЕР_ ИЗДЕЛИЯ | КОЛИЧЕСТВО |
| | S1 S1 S2 S2 S2 S2 S2 S2 S2 S2 S3 S3 S4 S4 S5 S5 S5 S5 S5 S5 S5 S5 S5 S5 | Р1 Р1 РЗ РЗ РЗ РЗ РЗ РЗ РЗ Р5 РЗ Р4 Р6 Р6 Р2 Р2 Р5 Р5 Р6 Р1 РЗ Р4 Р5 Р6 | J1 J4 J1 J2 J3 J4 J5 J6 J7 J2 J1 J2 J3 J7 J2 J4 J5 J7 J2 J4 J4 J4 J4 J4 | 200 700 400 200 200 500 600 400 800 100 200 500 300 300 200 100 500 100 200 100 200 800 400 500 |
Рис. 3.1. База данных поставщиков, деталей, изделий
CREATE TABLE P
(НОМЕР_ДЕТАЛИ CHAR(6) NOT NULL,
НАЗВАНИЕ CHAR(20),
ЦВЕТ CHAR(7),
ВЕС SMALLINT,
ГОРОД СHAR(15));
CREATE TABLE J
(НОМЕР_ИЗДЕЛИЯ CHAR(4) NOT NULL,
НАЗВАНИЕ CHAR(10),
ГОРОД CHAR(15));
CREATE TABLE SPJ
(НОМЕР_ПОСТАВЩИКА CHAR(5) NOT NULL,
НОМЕР_ДЕТАЛИ CHAR(6) NOT NULL,
НОМЕР_ИЗДЕЛИЯ CHAR(4) NOT NULL,
КОЛИЧЕСТВО INTEGER);
3.2. CREATE UNIQUE INDEX XS ON S (НОМЕР_ПОСТАВЩИКА);
CREATE UNIQUE INDEX XP ON P (НОМЕР_ДЕТАЛИ);
CREATE UNIQUE INDEX XJ ON J (НОМЕР_ИЗДЕЛИЯ);
CREATE UNIQUE INDEX XSPJ ON SPJ (НОМЕР_ПОСТАВЩИКА.
НОМЕР_ДЕТАЛИ,
НОМЕР_ИЗДЕЛИЯ);
3.3. Достоинства индексов заключаются в следующем:
а) Они ускоряют прямой доступ, основанный на заданном значении для индексированного поля (комбинации полей). Без индекса потребовался бы последовательный просмотр.
б) Они ускоряют последовательный доступ, основанный на индексированном поле (комбинации полей). Без индекса потребовалась бы сортировка.
в) В системе DB2 индексы со спецификацией UNIQUE служат, в частности, для реализации ограничений уникальности. Недостатки индексов заключаются в следующем:
а) Они занимают пространство памяти в базе данных. В сильно индексированной базе данных это пространство легко может превысить тот объем пространства памяти, которое занимают сами данные.
б) В то время как индекс, вполне возможно, ускорит операции выборки данных, он будет вместе с тем замедлять операции обновления. Исполнение любого предложения INSERT или DELETE над индексированной таблицей или UPDATE по индексированному полю (комбинации полей) потребует сопутствующего обновления индекса.
3.4. Дела обстоят неважно. Система DB2 совсем не в такой мере обеспечивает независимость данных, в какой следовало бы.