
Дейт К. Д27 Руководство по реляционной субд db2/ Пер с англ и предисл. М. Р. Когаловского
| Вид материала | Руководство |
- Рич Р. К. Политология. Методы исследования: Пер с англ. / Предисл. А. К. Соколова, 6313.17kb.
- Рич Р. К. Политология. Методы исследования: Пер с англ. / Предисл. А. К. Соколова, 6313.29kb.
- Сорокин П. А. С 65 Человек. Цивилизация. Общество / Общ ред., сост и предисл., 11452.51kb.
- The guilford press, 6075kb.
- The guilford press, 6075.4kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Целостная часть реляционной, 213.79kb.
- Дэвид Дайчес, 1633.42kb.
- Mathematics and the search for knowledge morris kline, 498.28kb.
- Лекция №1: Стандарты языка sql, 1420.56kb.
- Курс лекций "Базы данных и субд" Ульянов В. С. Лекция. Манипулирование реляционными, 276.31kb.
ГЛАВА 1
ОБЗОР ВОЗМОЖНОСТЕЙ СИСТЕМЫ DB2
ВВЕДЕНИЕ
«DB2» — это аббревиатура «IBM Database 2». DB2 — подсистема операционной системы MVS1. Точнее, она представляет собой систему управления базами данных (СУБД) для этой операционной системы. Еще точнее, это долгожданная реляционная СУБД фирмы IBM для операционной системы MVS. DB2 является системой, которая позволяет любому числу пользователей MVS осуществлять доступ к любому числу реляционных баз данных с помощью реляционного языка, называемого SQL («Structured Query Language»).
Ряд программных продуктов фирмы IBM, предшествующих системе DB2, включает нереляционную (фактически иерархическую) СУБД для MVS, а именно систему IMS, и реляционную СУБД для операционных систем DOS/VSE и VM/CMS — систему SQL/DS. Однако в его составе не было предусмотрено каких-либо предложений относительно реляционной СУБД для MVS. (Мы должны будем позднее подробнее поговорить об IMS и SQL/DS.) В июне 1983 года была, однако, наконец объявлена реляционная система DB2 для операционной системы MVS. Цель настоящей книги — описать эту систему.
В чем смысл того факта, что некоторая система является реляционной? К сожалению, для правильного ответа на этот вопрос нужно сначала обсудить значительное количество предварительного материала. Поскольку такое обсуждение было бы неуместным в самом начале книги, отложим его на более позднее время (подробно этот вопрос рассматривается в разделе 1.4 и Приложении А). Однако, не дожидаясь такого обсуждения, попытаемся здесь дать ответ на поставленный вопрос «на скорую руку» в надежде, что такой ответ поможет снять те опасения, которые вначале испытывает читатель. Если говорить кратко, реляционной называется система, в которой:
а) пользователь воспринимает данные как таблицы (и только как таблицы);
б) операторы, имеющиеся в распоряжении пользователя (т. е. используемые для формулирования запроса), служат для генерации новых таблиц из старых. Например, будет иметься один оператор для выделения подмножества строк данной таблицы, а другой — для выделения подмножества столбцов. И, конечно, подмножество строк и подмножество столбцов некоторой таблицы в свою очередь сами являются таблицами Эти два момента иллюстрируются на рис 1.1. Данные (см. часть а) на рисунке) состоят из единственной таблицы, называемой ВИННЫЙ-ПОГРЕБ, с тремя столбцами и четырьмя строками. В части б) рисунка показаны два примера запросов — один из них имеет дело с операцией выделения подмножества строк, а другой — с операцией выделения подмножества столбцов.
Примечание. Эти два запроса являются фактически примерами предложения SELECT (выбрать) в структуризованном языке запросов SQL, упомянутом ранее. Язык SQL (обычно произносится «сиквел») представляет собой язык баз данных, поддерживаемый не только системой DB2, но и SQL/DS, а также несколькими программными продуктами, разработанными не фирмой IBM.
| ВИННЫЙ_ПОГРЕБ | ВИНО | ГОД | КОЛИЧЕСТВО_БУТЫЛОК |
| | Цинфандель Чардоней Каберне Рислинг | 77 82 76 82 | 10 6 12 9 |
а) Заданная таблица
- Подмножество строк
| SELECT FROM WHERE | ВИНО, ГОД, КОЛИЧЕСТВО_БУТЫЛОК ВИННЫЙ-ПОГРЕБ ГОД = 82; |
| РЕЗУЛЬТАТ: | ВИНО | ГОД | количество_бутылок |
| | Чардоней Рислинг | 82 82 | 6 9 |
- Подмножество столбцов
| SELECT FROM | ВИНО, КОЛИЧЕСТВО_БУТЫЛОК ВИННЫЙ_ПОГРЕБ, |
| РЕЗУЛЬТАТ: | вино | КОЛИЧЕСТВО_БУТЫЛОК |
| | Цинфандель Чардоней Каберне Рислинг | 10 6 12 9 |
б) Операторы (примеры)
Рис. 1.1. Структура данные и операторы в реляционной системе (примеры)
Далее, цель этой книги заключается в том, чтобы предоставить учебное и справочное пособие по реляционной системе DB2 и, в меньшей степени, по сопутствующим ей программным продуктам — QMF и DXT (см раздел 1 3), с углубленным рассмотрением материала. Она предназначена для конечных пользователей, прикладных программистов, администраторов баз данных и, вообще, для каждого, кто желает понять основные концепции системы DB2. Книга не предназначена для замены системной документации, предоставляемой фирмой IBM. Но она является исчерпывающим и удобным однотомным руководством по использованию этого программного продукта. Как отмечалось в предисловии, особое значение, несомненно, придается пользователю и, следовательно, внешним, а не внутренним характеристикам этого продукта, хотя время от времени обсуждаются также и различные внутренние его аспекты. Предполагается, что читатель имеет общее представление о структуре и целях систем баз данных, но от него не требуется каких-либо специальных знаний, в частности, знаний о реляционных системах. Все относящиеся к делу реляционные понятия вводятся в тексте там, где они необходимы. Кроме того, в Приложении А дается более формальная сводка этих понятий для справочных целей.
В этой вводной главе представлен краткий обзор программного продукта DB2. В частности, в общих чертах рассматриваются варианты обстановки, в которой он функционирует, кратко обсуждаются некоторые связанные с ним продукты Высказывается также ряд идей в отношении того, что необходимо для создания баз данных системы DB2 и доступа к ним. Все эти вопросы и, конечно, многие другие рассматриваются в последующих главах.
1.2. ВАРИАНТЫ ОПЕРАЦИОННОЙ ОБСТАНОВКИ СИСТЕМЫ DB2
Система управления базами данных DB2 сконструирована для совместной работы с тремя другими подсистемами MVS — IMS, CICS и TSO2. На рис 1.2 показана эта совокупность программных компонентов.
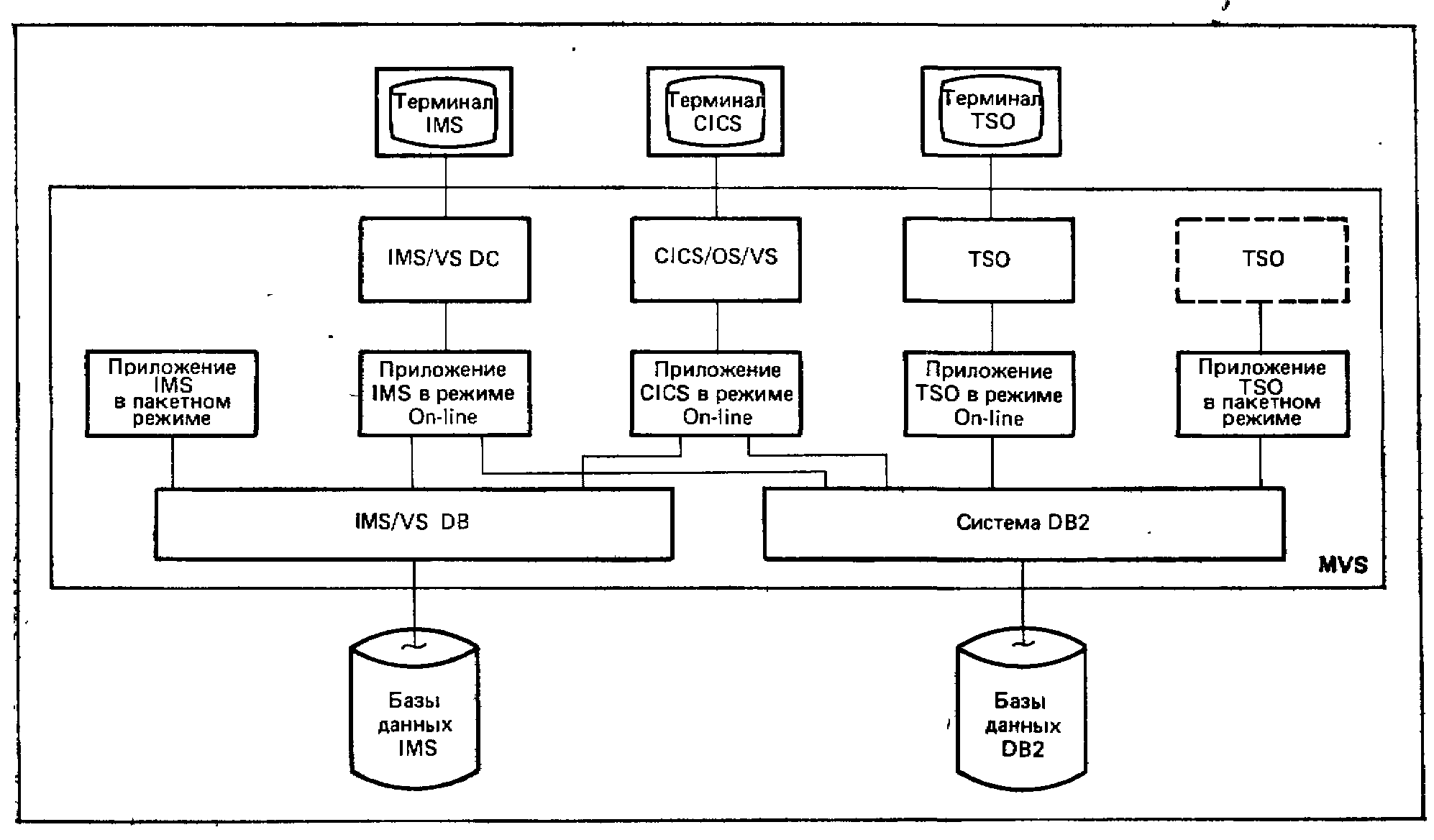
Рис. 1.2. Варианты операционной обстановки системы DB2
Этот рисунок можно интерпретировать следующим образом:
1. Любое заданное приложение (прикладная задача) DB2, т. е. любая прикладная программа, которая осуществляет доступ к одной или более базам данных DB2, будет исполняться под управлением в точности одной из трех подсистем IMS, CICS или TSO Иначе говоря, в точности одна из трех подсистем будет ответственной за обеспечение определенных необходимых системных услуг (которые обсуждаются в главе 11). Следовательно, можно разделить приложения DB2 на три непересекающиеся категории, а именно—на приложения IMS, CICS и TSO соответственно.
2. Вообще, любое заданное приложение (DB2 или иное) может факультативно использовать средства передачи данных IMS, CICS или TSO, когда они применимы, для связи с одним или более терминалами. Если это имеет место, такое приложение называется интерактивным (работающим в режиме On-line), в противном случае—пакетным (работающим в пакетном режиме). Приложения, исполняемые под IMS или CICS, должны быть интерактивными (см. п. 4 ниже). Приложения DB2, исполняемые под TSO, могут быть либо интерактивными, либо пакетными3.
3. Приложение DB2, исполняемое под IMS или CICS (но не TSO), может, помимо базы (баз) данных DB2, факультативно осуществлять доступ к одной или более базам данных IMS.
4. Пакетные приложения, исполняемые не под TSO, вообще не могут осуществлять доступа к базам данных DB2, как уже отмечалось выше в п. 2.
5. Приложения TSO вообще не могут осуществлять доступ к базам данных IMS, как уже отмечалось выше в п. 3.
6. Все приложения IMS, CICS и TSO могут исполняться параллельно и даже могут совместно использовать одну и ту же базу данных (одни и те же базы данных) DB2.
Читателей, не знакомых с IMS и/или с CICS и/или с TSO, мы хотим ободрить следующим: для того чтобы понимать возможности DB2, нет необходимости в знакомстве с этими подсистемами. Достаточно понимать, что программа, использующая возможности DB2, должна функционировать под управлением в точности одного из компонентов — IMS, CICS или TSO, а не их совокупности. Заметим, однако, что приложение TSO может исполняться как пакетное приложение TSO в одном случае и как интерактивное приложение TSO — в другом. Предложения ввода/ вывода в программе могут быть связаны с обычными наборами данных в одном случае и с терминалом — в другом, если, конечно, программа записана таким образом, что она готова к любой из этих возможностей.
1.3. ПРОГРАММНЫЕ ПРОДУКТЫ, СВЯЗАННЫЕ С DB2
Ряд других программных продуктов фирмы IBM является более или менее тесно связанным с DB2. Основные из них рассматриваются ниже.
SQL/DS (Structured Query Language/Data System)
Как уже указывалось, SQL/DS — это реляционная СУБД для операционных систем DOS/VSE и VM/CMS. Она принадлежит «семейству» DB2 в том смысле, что в обеих системах используется по существу один и тот же язык SQL. Если говорить точнее, в обеих системах — одни и те же предложения манипулирования данными и большинство предложений определения данных, которые различаются некоторыми незначительными деталями. Однако формат хранимых данных в этих системах не одинаков, но предоставляются утилиты, помогающие осуществлять передачу данных из базы данных SQL/DS в базу данных DB2 и наоборот4.
Примечание. SQL/DS включает как части базового продукта:
а) интерактивный интерфейс запросов и генератора отчетов, называемый ISQL («Interactive SQL»); и
б) средство «DL/1 Extract» для копирования специфицированных данных из базы данных DL/1-DOS в базу данных SQL/DS, так что к ним можно осуществлять доступ через интерфейс ISQL (DL/1-DOS является по существу урезанной версией системы IMS для операционной системы DOS/VSE. DL/1—язык доступа К базам данных, используемый как в DL/1-DOS, так и в IMS).
В отношении указанных возможностей DB2 в определенной мере отличается от SQL/DS. Базовый продукт DB2 также включает интерактивный интерфейс, в некоторой степени близкий к ISQL, называемый DB2I («DB2 Interactive»). Однако DB2I в действительности предназначен для профессионалов в области обработки данных, например для прикладных программистов, а не для случайных пользователей. Настоящий интерфейс для конечных пользователей DB2 обеспечивается отдельным периферийным продуктом, называемым QMF (см. подробности ниже). Аналогично, функции «DL/1 Extract» реализуются в обстановке DB2 другим отдельным продуктом — DXT (и снова подробности см. ниже).
QMF (Query Management Facility)
QMF (Query Management Facility) — развитое периферийное средство спецификации запросов и генерации отчетов как для DB2 (под TSO), так и для SQL/DS (под DOS/VSE или VM/CMS).
Заметим, Что это отдельный программный продукт. С точки зрения DB2 это фактически не что иное, как интерактивное приложение TSO. QMF позволяет конечным пользователям вводить случайные запросы либо на языке SQL, либо на языке QBE (Query-By-Example), и продуцировать разнообразные форматизированные отчеты из результатов обработки таких запросов. Он похож, таким образом, на встроенный интерфейс спецификации запросов/генерации отчетов ISQL, предоставляемый SQL/DS в качестве части базового продукта. Однако предоставляемый QMF диапазон возможностей значительно превосходит возможности ISQL. В частности, ISQL не поддерживает языка QBE.
Более подробная информация о QMF приводится в главе 15.
DXT (Data Extract)
DXT (Data Extract) — это универсальная программа копирования данных. Она позволяет скопировать в последовательный файл специфицированное подмножество данных заданной базы данных системы IMS либо набора данных VSAM или SAM. При этом копирование осуществляется в формате, подходящем для загрузки (с помощью соответствующей утилиты загрузки) в базу данных системы DB2 либо SQL/DS. В главе 15 содержится более подробная информация относительно DXT.
1.4. DB2: РЕЛЯЦИОННАЯ СИСТЕМА
Базы данных системы DB2 являются реляционными. Реляционная база данных это такая база данных, которая воспринимается ее пользователями как совокупность таблиц (и ничего иного, кроме таблиц). Пример такой базы данных (поставщики и детали) показан на рис. 1.3.
Нетрудно видеть, что эта база данных состоит из трех таблиц, а именно: S, Р и SP.
- Таблица S представляет поставщиков. Каждый поставщик имеет номер, уникальный для этого поставщика, фамилию— не обязательно уникальную, значение рейтинга или состояния и местонахождение (город). Для целей примера предположим, что каждый поставщик находится в точности в одном городе.
- В таблице Р представлены детали (точнее, виды деталей). Каждый вид деталей имеет уникальный номер детали, название, цвет, вес и место (город), где хранятся детали этого вида. Вновь для целей примера предположим, что каждый вид деталей имеет в точности один цвет и хранится на складе только одного города.
- Таблица SP представляет поставки деталей. Она служит для того, чтобы в некотором смысле связать между собой две другие таблицы. Например, первая строка этой таблицы на рис. 1.3 связывает определенного поставщика из таблицы S (а именно, поставщика S1) с определенной деталью из таблицы Р (а именно, с деталью P1). Иными словами, она представляет поставку деталей вида Р1 поставщиком по фамилии S1 и объем поставки, равный 300 деталям. Таким образом, для каждой поставки имеется номер поставщика, номер детали, и количество деталей. Для целей примера снова предположим, что может существовать не более одной поставки в любой заданный момент времени для заданного поставщика и заданной детали. Итак, комбинация значений НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ является уникальной для заданной поставки относительно множества поставок, представленных в текущий момент времени в таблице.
| S | НОМЕР_ПОСТАВЩИКА | ФАМИЛИЯ | СОСТОЯНИЕ | ГОРОД |
| | S1 S2 S3 S4 S5 | Смит Джонс Блейк Кларк Адамс | 20 10 30 20 30 | Лондон Париж Париж Лондон Атенс |
| Р | НОМЕР_ДЕТАЛИ | НАЗВАНИЕ | ЦВЕТ | ВЕС | ГОРОД |
| | Р1 Р2 РЗ Р4 Р5 Р6 | гайка болт винт винт кулачок блюм | красный зеленый голубой красный голубой красный | 12 17 17 14 12 19 | Лондон Париж Рим Лондон Париж Лондон |
| SP | НОМЕР_ПОСТАВЩИКА | НОМЕР_ДЕТАЛИ | КОЛИЧЕСТВО |
| | S1 S1 S1 S1 S1 S1 S2 S2 S3 S4 S4 S4 | Р1 Р2 РЗ Р4 Р5 Р6 Р1 Р2 Р2 Р2 Р4 Р5 | 300 200 400 200 100 100 300 400 200 200 300 400 |
Рис. 1.3. База данных поставщиков и деталей (пример)
Конечно, этот пример чрезвычайно прост. Он значительно проще любого реального примера, с которым, вероятно, можно встретиться на практике. Тем не менее, он достаточен для того, чтобы проиллюстрировать большинство вопросов, которые нам необходимо рассмотреть в этой книге. Поэтому мы будем использовать этот пример как основу для большинства (но не всех) примеров, приводимых в последующих главах, и следует потратить немного времени, чтобы хорошо с ним здесь разобраться.
Примечание. Нет ничего плохого в использовании более описательных имен (таких, как ПОСТАВЩИКИ, ДЕТАЛИ и ПОСТАВКИ) вместо весьма кратких— S, Р и SP. В действительности, на практике вообще нужно рекомендовать описательные имена (Именно так мы поступили при переводе, заменив имена столбцов таблиц этого и других примеров, представленные в виде аббревиатур английских названий, на более понятные русскому читателю содержательные имена.— Примеч. Пер.). Но конкретно в случае базы данных поставщиков и деталей эти три таблицы упоминаются в тексте настолько часто, что представляются более желательными очень краткие имена. Часто повторяемые длинные имена стали бы надоедливыми.
Два возникающих в связи с этим примером вопроса заслуживают, чтобы сказать о них здесь явно.
— Заметим, во-первых, что все значения данных являются атомарными, т. е. в каждой таблице в каждой позиции на пересечении строки и столбца всегда имеется в точности одно значение данных и никогда не бывает множества значений. Таким образом, например, в таблице SP (если для простоты рассматривать только два первых ее столбца) имеем:
-
НОМЕР_ПОСТАВЩИКА
НОМЕР_ДЕТАЛИ
.
S2
S2
.
S4
S4
S4
.
.
Р1
Р2
.
Р2
Р4
Р5
.
Вместо:
-
НОМЕР_ПОСТАВЩИКА
НОМЕР_ДЕТАЛИ
.
S2
.
S4
.
.
.
{PI. P2)
.
(Р2, Р4, Р5}
.
.
Столбец НОМЕР_ДЕТАЛИ во втором варианте этой таблицы представляет то, что иногда называется «повторяющейся группой». Повторяющаяся группа — это столбец, который содержит множество значений данных (в различных строках могут быть различные количества значений) вместо ровно одного значения в каждой строке. Реляционные базы данных не допускают повторяющихся групп. Второй вариант приведенной выше таблицы нельзя было бы использовать в реляционной системе.
— Во-вторых, отметим, что полное информационное содержание базы данных представляется в виде явных значений данных. Такой метод представления (в виде явных значений в позициях столбцов и строк таблиц) является единственным методом, имеющимся в распоряжении в реляционной базе данных. В частности, не существует каких-либо «связей» или указателей, соединяющих одну таблицу с другой. Так, имеется связь между строкой S1 таблицы S и строкой Р1 таблицы Р (поставщик S1 поставляет деталь Р1). Но эта связь представляется не с помощью указателей, а благодаря существованию в таблице SP строки, в которой значение номера поставщика равно S1, а значение номера детали равно Р1. Напротив, в системах нереляционного типа (например, в IMS) такая информация обычно представляется с помощью некоторого рода физической связи или указателя, который является явным образом видимым для пользователя.
Читатель может здесь заинтересоваться, почему такая база данных, как приведенная на рис. 1.3, называется «реляционной», Ответ простой: «отношение» — «relation» — просто математический термин для обозначения таблицы (точнее, таблицы определенного специфического вида—подробно об этом идет речь в главе 3). Таким образом, можно, например, сказать, что база данных, приведенная на рис. 1.3, состоит из трех отношений. Фактически в значительной мере можно считать термины «отношение» и «таблица» синонимами. Реляционные системы берут свое начало в математической теории отношений. Это не означает, конечно, что необходимо быть математиком для того, чтобы использовать реляционную систему. Но это означает, что существует значительное количество теоретических результатов, которые можно применять для решения практических проблем использования баз данных, например проблемы проектирования баз данных.
Если правильно то, что отношение—это только таблица, то почему не называть его просто таблицей и не довольствоваться этим? Ответ заключается в том, что мы очень часто это делаем (и обычно так и будем делать в этой книге). Однако стоит затратить немного времени для того, чтобы понять, почему сначала был введен термин «отношение». Кратко объяснение состоит в следующем. Реляционные системы базируются на так называемой реляционной модели данных. Реляционная модель в свою очередь является абстрактной теорией данных, которая основана, в частности, на упомянутой выше математической теории. Основы реляционной модели были первоначально сформулированы доктором Э. Ф. Коддом из фирмы IBM. В конце 1968 года Кодд, математик по образованию, впервые ясно понял, что можно использовать математику для придания надежной основы и строгости области управления базами данных, которая до настоящего времени была слишком несовершенной в указанных аспектах. Идеи Кодда были впервые широко опубликованы в ставшей теперь классической работе [10]. С тех пор эти идеи (к настоящему времени принятые почти повсюду) оказали весьма широкое влияние на технологию баз данных почти во всех ее аспектах, а в действительности также и на другие области, например на область искусственного интеллекта и обработку текстов на естественных языках.
Далее, реляционная модель, первоначально предложенная Коддом, требовала очень осмотрительного использования определенных терминов, например самого термина «отношение», которые не были хорошо известными в то время в сфере обработки данных, хотя эти концепции в некоторых случаях существовали. Неприятность, однако, заключалась в том, что были очень нечеткими многие более известные термины. Им недоставало точности, необходимой для формальной теории такого рода, какая была предложена Коддом. Рассмотрим, например, термин «запись». В различных ситуациях этот термин может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т. д. Поэтому в формальной реляционной модели вообще не используется термин «запись». Вместо этого в ней используется термин «кортеж» (сокращение для «кортеж длины п»), которому было дано точное определение, когда Кодд впервые ввел его. Мы не приводим здесь это определение. Для наших целей достаточно сказать, что термин «кортеж» приблизительно соответствует понятию экземпляра плоской записи (точно так же, как термин «отношение» приблизительно соответствует понятию таблицы). Если Вы желаете изучить какие-либо более формальные публикации по реляционным системам баз данных, следует, конечно, познакомиться и с формальной терминологией. Но в этой книге мы не пытаемся быть очень формальными и будем по большей части придерживаться таких терминов, как «запись», которые являются достаточно хорошо знакомыми. На рис. 1.4 приведены термины, которые мы будем использовать наиболее часто (таблица, запись, строка, поле, столбец). Для справки в каждом случае дается также соответствующий формальный термин. Заметим, что термины «запись» и «строка»
| Формальный реляционный термин | Неформальные эквиваленты |
| отношение кортеж атрибут | таблица запись, строка поле, столбец |
Рис. 1.4. Некоторые термины
мы используем как равнозначные. Аналогично используются термины «поле» и «столбец». Заметим также, что мы, следовательно, принимаем по определению, что «запись» означает «экземпляр записи», а «поле» означает «тип поля».
1.5. ЯЗЫК SQL
На рис. 1.3 представлено состояние базы данных поставщиков и деталей в некоторый конкретный момент времени. Это — фотография базы данных. В противоположность этому на рис. 1.5 показана структура этой базы данных. Она показывает, как эта база данных определена или описана5.
CREATE TABLE S
-
(НОМЕР_ПОСТАВЩИКА
CHAR (5),
ФАМИЛИЯ
CHAR (20),
СОСТОЯНИЕ
SMALLINT.
ГОРОД
CHAR (15));
CREATE TABLE P
-
(НОМЕР_ДЕТАЛИ
CHAR (5),
НАЗВАНИЕ
CHAR (20),
ЦВЕТ
CHAR (7),
ВЕС
SMALLINT,
ГОРОД
CHAR (15));
CREATE TABLE SP
-
(НОМЕР_ПОСТАВЩИКА
CHAR (5)
НОМЕР_ДЕТАЛИ
CHAR (6)
КОЛИЧЕСТВО
INTEGER);
Рис. 1.5. База данных поставщиков и деталей (определение данных)
Нетрудно видеть, что определение базы данных в рассматриваемом примере включает по одному предложению CREATE TABLE (СОЗДАТЬ ТАБЛИЦУ) для каждой из трех составляющих ее таблиц. CREATE TABLE представляет собой пример предложения определения данных языка SQL. Каждое предложение CREATE TABLE специфицирует имя таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов (а также, возможно, некоторую дополнительную информацию, не иллюстрируемую данным примером).
В данный момент детальное описание предложения CREATE TABLE не является нашей задачей. Оно будет приведено позже, в главе 3. Однако с самого начала необходимо подчеркнуть, что CREATE TABLE — выполняемое предложение. (Фактически, как мы увидим позднее, каждое предложение SQL является выполняемым.) Если три представленные на рис. 1.5 предложения CREATE TABLE будут введены с терминала в точности так, как они показаны, система в действительности тотчас же построит эти три таблицы. Конечно, сначала эти таблицы будут пустыми. Каждая из них будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Мы можем, однако, немедленно приступить к вставке таких строк данных, возможно, с помощью предложения INSERT языка SQL, которое будет обсуждаться в главе 6. Буквально за несколько минут работы мы можем получить в свое распоряжение, вероятно, небольшую, но тем не менее полезную и пригодную к использованию базу данных и можем начать делать с нею некоторые полезные вещи. Таким образом, этот простой пример сразу же показывает одно из достоинств реляционных систем вообще и системы DB2 в частности — они являются очень легкими для использования. Конечно, легкость «вступления в контакт» это лишь один аспект легкости использования вообще. В результате пользователь может работать очень продуктивно. Позже мы увидим много других достоинств.
Примечание. Хотя это в действительности и не имеет никакого отношения к теме данного параграфа (к языку SQL), целесообразно, между прочим, упомянуть, что DB2 разрабатывалась, в частности, с целью создания легко устанавливаемой системы. Это означает, что не только легко в любое время «установить» или создать новую базу данных, но прежде всего легко установить также и полную систему. Иными словами, процесс построения необходимых библиотечных наборов данных DB2, специфицирующих требуемые параметры системы, определяющих некоторые характеристики системы по умолчанию и т. п. намеренно сделан настолько простым, насколько это возможно. Для верификации корректности функционирования установки системы предоставляются контрольные примеры программ. Полная процедура установки системы обычно занимает от одного до двух рабочих дней.
Теперь вернемся к примеру. После создания трех наших таблиц и загрузки в них некоторых записей можно начать делать с ними полезную работу, используя предложения манипулирования данными языка SQL. Одна из вещей, которую мы можем делать,— это поиск данных, специфицируемый в языке SQL с помощью предложения SELECT. Пример поиска данных приведен на рис. 1.6.
SELECT ГОРОД Результат: ГОРОД
FROM S Лондон
WHERE НОМЕР-ПОСТАВЩИКА == 'S4';
а) Интерактивный (DB2I)
ЕХЕС SQL SELECT ГОРОД Результат: ХГОРОД
INTO :X ГОРОД Лондон
FROM S
WHERE НОМЕР_ПОСТАВЩИКА =='S4';
б) Встроенный в ПЛ/1 (может использоваться также КОБОЛ, ФОРТРАН или Ассемблер).
Рис. 1.6. Пример поиска данных в базе данных
Довольно важная особенность реализации языка SQL в системе DB2 (и, между прочим, в SQL/DS) заключается в том, что один и тот же язык предоставляется через два различных интерфейса, а именно через интерактивный интерфейс (DB2I в случае системы DB2) и через интерфейс прикладного программирования. На рис. 1.6,а показан пример использования интерактивного интерфейса DB2I. Пользователь вводит с терминала предложение SELECT, а система DB2 отвечает через ее компонент DB2I, показывая непосредственно на терминале результат «Лондон». На рис 1.6,б показано фактически то же самое предложение SELECT, встроенное в прикладную программу (в примере—в программу на языке ПЛ/1). В этом втором случае указанное предложение будет исполняться, когда будет исполняться программа, а результат «Лондон» будет возвращаться не на терминал, а программной переменной ХГОРОД (благодаря фразе INTO в предложении SELECT; переменная ХГОРОД представляет собой как раз область ввода в программе). Таким образом, SQL представляет собой и интерактивный язык запросов и язык программирования в обстановке базы данных. Это замечание относится ко всему языку SQL, т. е. любое предложение SQL, которое может быть введено с терминала, может быть альтернативно встроено в программу. Отметим, в частности, что приведенное замечание относится даже к таким предложениям, как CREATE TABLE. Вы можете создавать таблицы из прикладной программы, если это имеет смысл н вашей прикладной задаче и если Вы обладаете полномочиями на выполнение таких операций. Предложения языка SQL могут быть встроены в программы, записанные на любом из следующих языков: ПЛ/1, КОБОЛ, ФОРТРАН и язык ассемблера IBM/370. (Помимо этого фирма IBM объявила о своем намерении поддерживать в будущем БЭИСИК и АПЛ).
Примечание. На рис. 1.6,б префикс EXEC SQL необходим для того, чтобы отличить данное предложение SQL от предложений языка ПЛ/1, которые его окружают. Кроме того, чтобы обозначить область ввода, необходима, как мы видим, фраза INTO; указанная в этой фразе переменная должна иметь в качестве префикса двоеточие с тем, чтобы отличать ее от имени столбца в SQL. Конечно, не совсем точно, что предложение SELECT является одним и тем же для обоих интерфейсов. Но это вполне справедливо, если отвлечься от незначительных различий в деталях.
Теперь мы в состоянии понять, как выглядит система DB2 для пользователя. Под «пользователем» мы понимаем здесь либо конечного пользователя, работающего в интерактивном режиме терминала, либо прикладного программиста, пишущего программы на ПЛ/1, КОБОЛе, ФОРТРАНе или на языке ассемблера. (Заметим, между прочим, что мы будем использовать термин «пользователь» всюду в этой книге в каком-либо одном или в обоих этих смыслах). Как уже разъяснялось, каждый такой пользователь будет использовать SQL для того, чтобы оперировать таблицами (см. рис. 1.7).
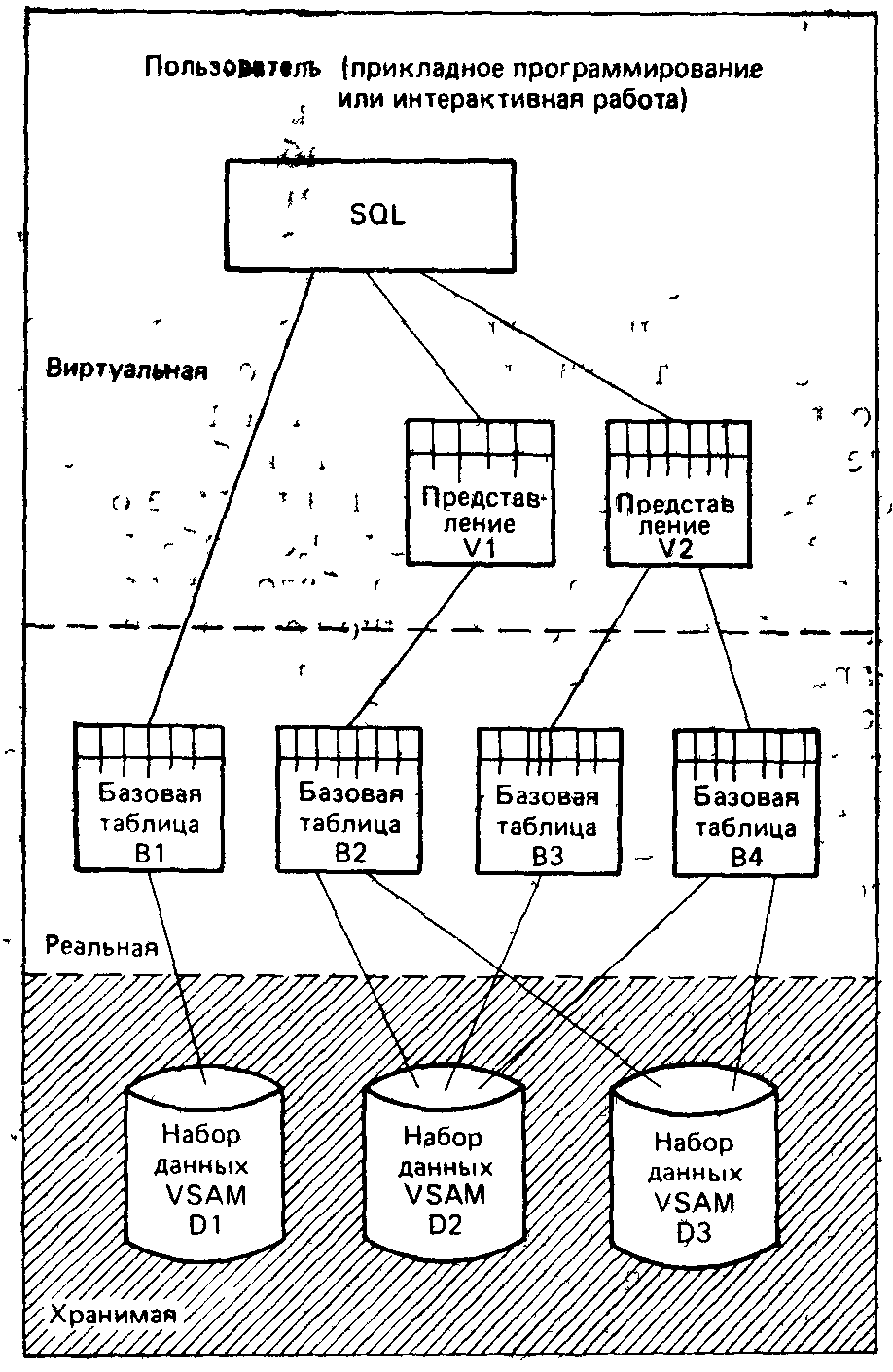
Рис. 1.7. База данных системы DB2 в восприятии отдельного пользователя
Первое соображение, касающееся рис. 1.7, состоит в том, что обычно множество пользователей обоих видов будет оперировать одними и теми же данными в одно и то же время. Система DB2 будет автоматически использовать необходимые средства управления (см. главу 11) с тем, чтобы обеспечить защиту всех этих пользователей друг от друга, т. е. гарантировать, что обновления, осуществляемые одним пользователем, не могут привести к некорректному результату операций, выполняемых другим пользователем.
Отметим далее, что на рисунке также представлены таблицы двух видов, а именно: базовые таблицы, и представления. Базовая таблица это «реальная» таблица, т. е. таблица, которая существует физически в том смысле, что в одном или более наборах данных VSAM существуют физически хранимые записи и, возможно, физические индексы, которые непосредственно представляют эту таблицу в памяти. В противоположность этому представление является «виртуальной таблицей», т. е. таблицей, которая непосредственно не существует в физической памяти, но для пользователя выглядит так, как будто она существует. Представления можно считать различными способами видения «реальных» таблиц. Тривиальный пример: данный пользователь мог бы располагать представлением базовой таблицы поставщиков, в котором видимы только те поставщики, которые находятся в Лондоне. Представления определяются на основе одной или более базовых таблиц. Способ их определения рассматривается в главе 8.
Примечание. Сказанное в предыдущем абзаце не следует интерпретировать таким образом, что базовая таблица физически хранится как таблица, т. е. как множество физически смежных хранимых записей, каждая из которых представляет собой просто непосредственную копию какой-либо строки базовой таблицы. Существуют многочисленные различия между базовой таблицей и ее представлением в среде хранения. Некоторые из них будут позднее обсуждаться. Дело в том, что пользователи всегда могут считать базовые таблицы «физически существующими», не касаясь того, каким образом эти таблицы на самом деле реализованы в памяти. Фактически проблема реляционных баз данных в полном ее объеме заключается в том, чтобы дать пользователям возможность иметь дело с данными в форме таблиц самих по себе, а не в виде представлений таких таблиц в среде хранения. Как уже говорилось в разделе 1.4, реляционная база данных—это база данных, которая воспринимается ее пользователями как совокупность таблиц. Это совсем не база данных, в которой данные физически хранятся, как таблицы.
Представления, как и базовые таблицы, могут быть созданы в любое время. То же самое справедливо и для индексов. Уже указывалось, что предложение CREATE TABLE служит для создания «реальных» или базовых таблиц. Имеется аналогичное предложение CREATE VIEW (создать представление) для создания представлений или «виртуальных» таблиц и аналогичное предложение CREATE INDEX (создать индекс) для создания индексов. Подобным же образом базовые таблицы (а также представления и индексы) могут быть «уничтожены» (иначе говоря, разрушены) в любое время с использованием предложений DROP TABLE (уничтожить таблицу), DROP VIEW (уничтожить представление) или DROP INDEX (уничтожить индекс). Относительно индексов заметим для строгости, что хотя пользователь (т. е. некоторый пользователь, вероятно, администратор базы данных— см. главу 9) ответствен за их создание и уничтожение, он не является ответственным за их сохранность, когда эти индексы должны использоваться. Индексы никогда не упоминаются в предложениях манипулирования данными языка SQL, например в SELECT. Решение о том, использовать ли или не использовать какой-либо конкретный индекс при обработке, например, определенного предложения SELECT, принимается системой, а не пользователем. Этот вопрос более подробно обсуждается в главе 2.
Пользовательский интерфейс системы DB2 — это язык SQL. Мы уже указывали, что:
а) SQL может использоваться как в интерактивной, так и во встроенной обстановке и
б) он обеспечивает не только функции определения данных, но и функции манипулирования данными (как будет видно далее, он фактически обеспечивает также некоторые функции «управления данными»).
Выше мы уже касались главных функций определения данных:
CREATE TABLE
CREATE VIEW
CREATE INDEX
DROP TABLE
DROP VIEW
DROP INDEX
Главными функциями манипулирования данными являются (на самом деле, если на время игнорировать некоторые функции, относящиеся только к встроенному SQL, то это полный перечень таких функций):
SELECT (выбрать)
UPDATE (обновить)
DELETE (удалить)
INSERT (вставить)
Приведенные ниже примеры (рис. 1.8) предложений SELECT и UPDATE иллюстрируют важный момент, заключающийся в том, что предложения манипулирования данными языка SQL обычно оперируют одновременно полным множеством записей, а не просто одной записью. Если принять данные из примера на рис. 1.3, то предложение SELECT, приведенное на рис. 1.8 а, возвращает множество, Состоящее из четырех значений, а не из одного. В то же время, предложение UPDATE (рис. 1.8,б) изменяет две записи, а не одну. Другими словами, SQL является языком уровня множеств.
а) SELECT НОМЕР_ПОСТАВЩИКА Результат: НОМЕР_ПОСТАВЩИКА
FROM SP S1
WHERE НОМЕР_ДЕТАЛИ = 'Р2' S2
S3
S4
б) UPDATE S Результат: удвоенное состояние для
поставщиков S1 и S4
SET СОСТОЯНИЕ == 2*СОСТОЯНИЕ
WHERE ГОРОД = 'Лондон';
Рис. 1.8. Примеры манипулирования данными для языка SQL
Языки уровня множеств, такие, как SQL иногда характеризуются как «непроцедурные» на том основании, что пользователи специфицируют что, а не как (т. е. они указывают, какие данные необходимо иметь, не специфицируя процедуру для их получения). Иными словами, процесс «навигации» в физической базе данных с целью определения местонахождения требуемых данных выполняется автоматически системой, а не вручную пользователем. Однако «непроцедурный» в действительности не очень хороший термин, поскольку как процедурность, так и непроцедурность не являются абсолютными. Лучший способ выразить это — сказать, что некоторый язык А является более либо менее процедурным, чем некоторый другой язык В. Возможно, более хорошим способом выражения этого обстоятельства является утверждение о том, что некоторый язык, например SQL, находится на более высоком уровне абстракции, чем такой язык, как КОБОЛ (или DL/1). Иными словами, системе приходится в связи с языком типа SQL иметь дело с большим числом деталей, чем для языка типа КОБОЛ (или, например, DL/1). По существу, это такое повышение уровня абстракции, которое является причиной возросшей производительности, обеспечиваемой реляционными системами, такими, как DB2.
1.6. РЕЗЮМЕ
Этим разделом завершается данная вводная глава. В ней был приведен краткий обзор DB2, реляционной системы управления базами данных фирмы IBM для операционной системы MVS. Было пояснено в общих чертах, что такое реляционная система. Рассмотрена реляционная (табличная) структура данных и описаны некоторые из имеющихся в SQL операторов для работы с данными в такой табличной форме. В частности, мы коснулись вопроса о трех категориях предложений SQL (определение данных, манипулирование данными и управление данными) и привели примеры из первых двух категорий. Напоминаем читателю, что:
а) все предложения SQL являются выполняемыми; б) каждое предложение SQL, которое может быть введено с терминала, может быть также встроено в программу на языке ПЛ/1, КОБОЛ, ФОРТРАН или на языке ассемблера; в) предложения манипулирования данными SQL (SELECT, UPDATE и т. д.) оперируют над множествами. Наконец, были рассмотрены также различные варианты операционной обстановки., в которых может исполняться прикладная задача системы DB2, а именно: IMS, CICS и TSO. В следующей главе мы познакомимся с внутренней структурой и с основными компонентами DB2.
УПРАЖНЕНИЯ
1.1. В чем смысл утверждения, что DB2 — реляционная система?
1.2. При условии, что приняты данные из примера на рис. 1.3, найдите результат
каждого из следующих предложений SQL.
а)SELECT ФАМИЛИЯ
FROM S
WHERE СОСТОЯНИЕ = 30;
б) SELECT НОМЕР_ПОСТАВЩИКА, НОМЕР_ДЕТАЛИ
FROM SP
WHERE КОЛИЧЕСТВО > 200;
в) UPDATE SP
SET КОЛИЧЕСТВО = КОЛИЧЕСТВО + 300
WHERE КОЛИЧЕСТВО < 300;
г) DELETE
FROM P
WHERE ЦВЕТ = 'Голубой'
OR ГОРОД = 'Париж';
д) INSERT
INTO SP (НОМЕР_ПОСТАВЩИКА, НОМЕР—ДЕТАЛИ,
КОЛИЧЕСТВО)
VALUES ('S3', 'Р1’, 500);
1.3. Постройте диаграмму, иллюстрирующую различные категории прикладных программ системы DB2 и различные варианты операционной обстановки, в которых они могут исполняться.
1.4. Что обозначают следующие акронимы:
SQL, DB2, DB2I, QMF, DXT?
1.5. Что такое повторяющаяся группа?
1.6. Определите термины отношение и реляционная база данных.
1.7. Приведите возможное предложение CREATE TABLE для таблицы ВИННЫЙ— ПОГРЕБ (рис. 1.1). Запишите встроенное предложение SQL для программы на языке ПЛ/1, которое обеспечит выборку числа бутылок цинфанделя 1977 г. из этой таблицы.
1.8. Определите термины базовая таблица и представление.
1.9. Как Вы понимаете термин "автоматическая навигация”?
ОТВЕТЫ К НЕКОТОРЫМ УПРАЖНЕНИЯМ
1.1. Реляционная система, такая, как DB2, это система, в которой данные воспринимаются как таблицы (и только как таблицы), а операторы, которые имеются в распоряжении пользователя, представляют собой операторы, которые генерируют новые таблицы из старых.
1.2.
а) ФАМИЛИЯ
Блейк
Адамс
-
б)
НОМЕР_ПОСТАВЩИКА
НОМЕР_ДЕТАЛИ
S1
P1
S1
P3
S2
P1
S2
P2
S3
P4
S3
P5
-
в)
НОМЕР_ПОСТАВЩИКА
НОМЕР_ДЕТАЛИ
КОЛИЧЕСТВО
S1
Р2
500
S1
Р4
500
S1
Р5
400
S1
Р6
400
S3
Р2
500
S4
Р2
500
(Показаны только модифицированные строки);
г) Из таблицы Р удалены строки поставщиков Р2, РЗ и Р5;
д) В таблицу SP вставлена строка S3/P 1/500.
1.5. Повторяющаяся группа с концептуальной точки зрения представляет собой столбец таблицы, который содержит в каждой строке множество значений данных (в разных строках различное число значений). В реляционной базе данных повторяющиеся группы не допускаются.
1.6. Отношение — это таблица (без повторяющихся групп). Реляционная база данных является такой базой данных, которая воспринимается ее пользователями как совокупность отношений. Примечание. Более точные определения приведены в Приложении А.
1.7. CREATE TABLE ВИННЫЙ_ПОГРЕБ
(ВИНО CHAR (16),
ГОД INTEGER,
КОЛИЧЕСТВО_БУТЫЛОК INTEGER);
EXEC SQL SELECT КОЛИЧЕСТВО_БУТЫЛОК
INTO : ХБУТЫЛОК
FROM ВИННЫЙ_ПОГРЕБ
WHERE ВИНО = 'Цинфандель'
AND ГОД = 77;
1.8. Базовая таблица представляет собой «реальную» таблицу. Она некоторым образом непосредственно представлена в памяти. Представление это «виртуальная» таблица, которая не имеет какого-либо непосредственного воплощения ее самой в памяти. Представление подобно окну, через которое можно наблюдать данные (или некоторое подмножество данных) одной или более образующих его таблиц, возможно, в какой-либо реорганизованной структуре.
1.9. «Автоматическая навигация» означает, что система берет на себя ответственность за поиск в физической базе данных, позволяющий определить местоположение данных, которые запрашиваются пользователем. Пользователи специфицируют, что они хотят, а не как получить то, что они хотят.